TL;DR#
Current advancements in code generation models heavily rely on supervised fine-tuning, but the potential of reinforcement learning (RL) remains largely unexplored due to the scarcity of reliable reward signals and large-scale datasets. This paper introduces AceCoder, a novel approach that leverages automated large-scale test-case synthesis to construct preference pairs from existing code data, thereby training reward models with a Bradley-Terry loss. These reward models, along with test-case pass rates, are used to conduct RL, resulting in consistent performance improvements across multiple coding benchmarks.
AceCoder demonstrates significant performance gains, particularly for smaller models (7B), achieving results comparable to larger models (236B). The RL training significantly boosts performance on HumanEval and MBPP. The paper also highlights the importance of using well-formed questions and well-filtered test cases. The introduced ACECODE-89K dataset, containing 89K coding questions and 300K test cases, is a significant contribution to the field, fostering future research in RL for code generation.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical challenge of reliable reward signal generation for reinforcement learning in code generation models. By introducing a novel automated test-case synthesis pipeline and a large-scale dataset (ACECODE-89K), it opens new avenues for applying RL to improve code generation models significantly, potentially surpassing the performance of solely SFT-based models. This work is highly relevant to the current trend of enhancing large language models with RL, and its findings and dataset are valuable resources for future research in this area.
Visual Insights#

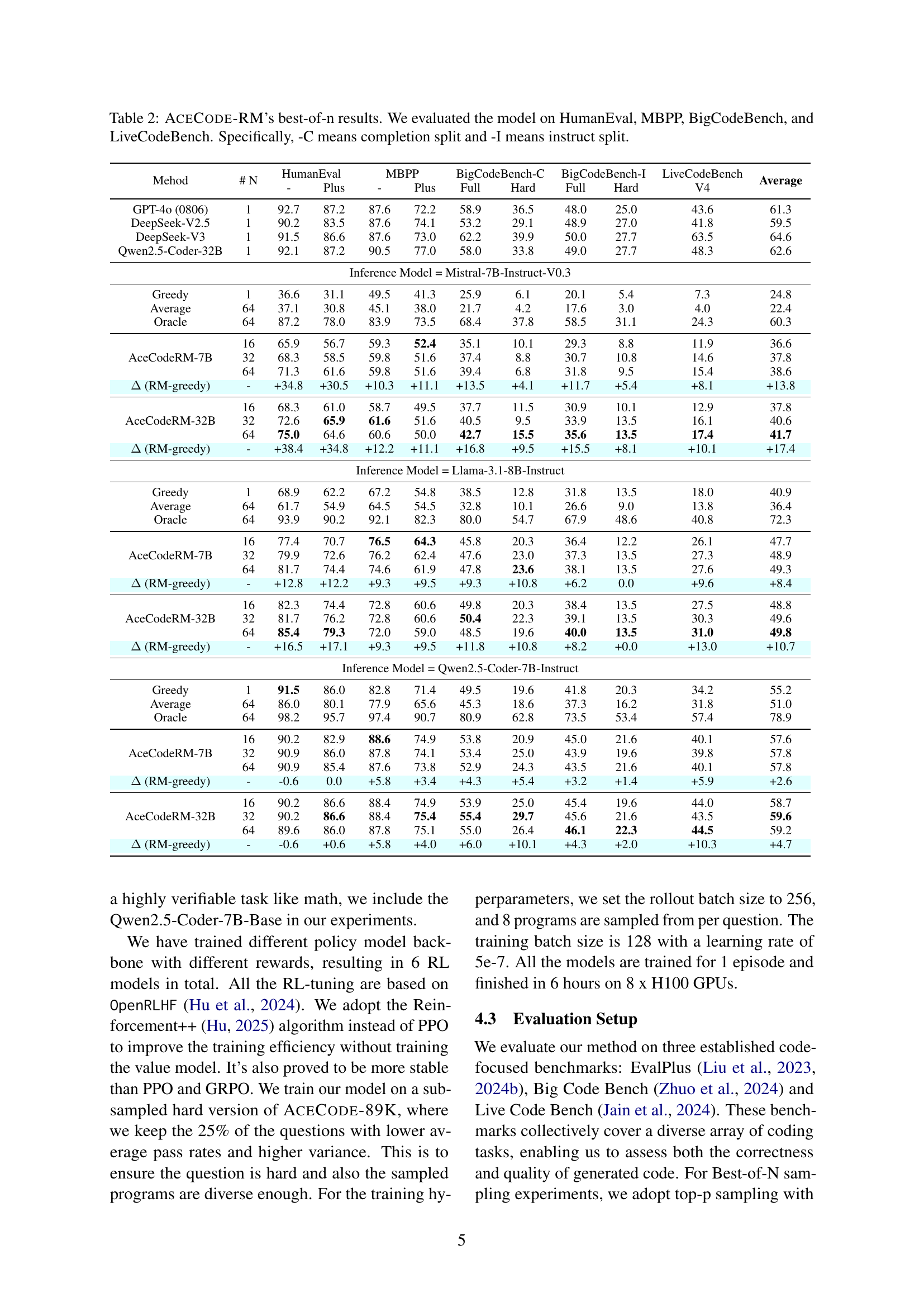
🔼 The figure illustrates the workflow of the ACECODER model. It begins with a seed code dataset, which is processed to generate well-formed coding questions and their corresponding test cases. A filtering step then removes noisy or unreliable test cases. The remaining, high-quality test cases are used to create positive and negative program pairs based on their pass/fail rates. These pairs are then used to train reward models, which are subsequently employed in reinforcement learning (RL) to improve the code generation model’s performance.
read the caption
Figure 1: Overall Workflow of our model: We start from the seed code dataset to create well-formatted questions and corresponding test cases. Then we adopt strong models like filter the noisy test cases. Finally, we adopt these test cases to harvest positive and negative program pairs for reward model training and RL.
| Subset | Evol | OSS | Stack Python | Overall |
| Before Filtering | ||||
| # Examples | 36,256 | 37,750 | 50,000 | 124,006 |
| # Avg Test Cases | 19.33 | 17.21 | 18.27 | 18.27 |
| After Filtering | ||||
| # Examples | 27,853 | 26,346 | 35,223 | 89,422 |
| # Avg Test Cases | 14.77 | 16.11 | 15.79 | 15.56 |
| # Pairs | 89,089 | 91,636 | 126,784 | 307,509 |
🔼 This table presents a statistical overview of the ACECODE-89K dataset, both before and after the application of a filtering process on its test cases. It shows the number of examples, the average number of test cases per example, and the number of positive and negative program pairs created for training. The ‘before filtering’ section displays the initial dataset statistics, while the ‘after filtering’ section highlights the characteristics of the dataset after removing noisy or unreliable test cases. This filtered dataset is the one used in the subsequent experiments.
read the caption
Table 1: Dataset statistics of AceCode-89K before and after test-case filtering.
In-depth insights#
RL in Code Generation#
Reinforcement learning (RL) presents a powerful paradigm for advancing code generation, offering a potential solution to the limitations of supervised fine-tuning. RL’s ability to learn from interactions and optimize for complex reward functions is particularly well-suited to the nuanced and multifaceted nature of code evaluation. Unlike supervised methods which rely heavily on large, correctly labeled datasets, RL can learn from less structured feedback, such as pass/fail test results. This makes RL particularly attractive for scenarios where comprehensive labelled data is scarce or expensive to obtain, a frequent challenge in code generation. A key challenge, however, lies in designing effective reward functions that accurately capture code quality. Reward functions must balance multiple criteria, such as correctness, efficiency, and readability, and ideally adapt to different coding tasks and problem complexities. Furthermore, the computational cost of RL training remains a significant hurdle. The development of efficient RL algorithms and reward shaping techniques are crucial for making RL a practical tool for large-scale code generation. Ultimately, the successful integration of RL in code generation hinges on the careful design of reward functions and the development of efficient training methodologies.
Test-Case Synthesis#
The concept of automated test-case synthesis is a crucial aspect of the research paper, significantly enhancing the training process of code generation models. Instead of relying on manually created test cases, which are often costly and time-consuming to produce, the proposed method automatically generates a large number of test cases. This is achieved by leveraging a large language model (LLM) to rewrite coding problems into a standardized format. The LLM also generates multiple test cases for each rewritten problem, effectively augmenting the training data. This automated approach addresses the limitations of traditional supervised fine-tuning methods by providing a more extensive and reliable dataset for model training, thereby improving the robustness and generalizability of the resulting code generation models. The generated test-cases, further filtered for quality and accuracy, form a core component of a new dataset (ACECODE-89K) that facilitates the training of both reward models and the code generation models themselves, demonstrating the effectiveness of this automated synthesis technique.
Reward Model Training#
The core of reward model training in this research lies in leveraging automatically generated, large-scale test cases to create a reliable reward signal for reinforcement learning in code generation models. Instead of relying on costly human evaluation, the authors synthesize test cases from existing code datasets, then use a Bradley-Terry model to train a reward model. This innovative approach addresses a major limitation in existing code-generation RL research: the scarcity of high-quality reward data. The use of Bradley-Terry loss for preference learning is particularly insightful, enabling effective training from pairwise comparisons of program pass rates. The resulting reward model guides subsequent reinforcement learning stages, significantly improving the performance of the base coding models on standard benchmarks. This method’s strength hinges on its automated pipeline for creating robust and scalable training data, pushing the boundaries of RL applications in the code generation domain.
Reinforcement Learning#
The research paper explores the use of reinforcement learning (RL) in enhancing code generation models. A key challenge addressed is the lack of reliable reward signals in the code domain, traditionally hindering RL’s effectiveness. The proposed solution leverages automated large-scale test-case synthesis. This approach generates extensive (question, test-cases) pairs, enabling the construction of robust reward models using pass rates as feedback signals. The study demonstrates significant improvements in model performance on various coding benchmarks (HumanEval, MBPP, etc.) by integrating this RL method. Best-of-N sampling techniques further enhance efficiency. Interestingly, starting RL training directly from a base model (without supervised fine-tuning) yields impressive results, highlighting the method’s potential for effective model optimization. Overall, the findings suggest that integrating automated test-case synthesis with RL offers a powerful strategy to advance code generation models, overcoming limitations of traditional supervised fine-tuning methods.
Future of Coder LLMs#
The future of Coder LLMs hinges on addressing current limitations and leveraging emerging technologies. Improved reward models are crucial for effective reinforcement learning, enabling more sophisticated code generation and debugging capabilities. Larger, more diverse datasets are needed to enhance generalization and reduce biases. Advanced techniques like program synthesis and automated test-case generation will play a key role in creating more robust and reliable models. Integration with development tools and seamless incorporation into existing workflows will be essential for broader adoption. The future also includes focus on specific coding tasks, such as program repair, optimization, and code documentation, creating specialized, highly efficient LLMs. Addressing ethical concerns, including bias mitigation and security vulnerabilities, will be paramount. Ultimately, Coder LLMs will become indispensable tools for software development, drastically increasing productivity and accessibility, making advanced programming techniques available to a broader range of users.
More visual insights#
More on tables
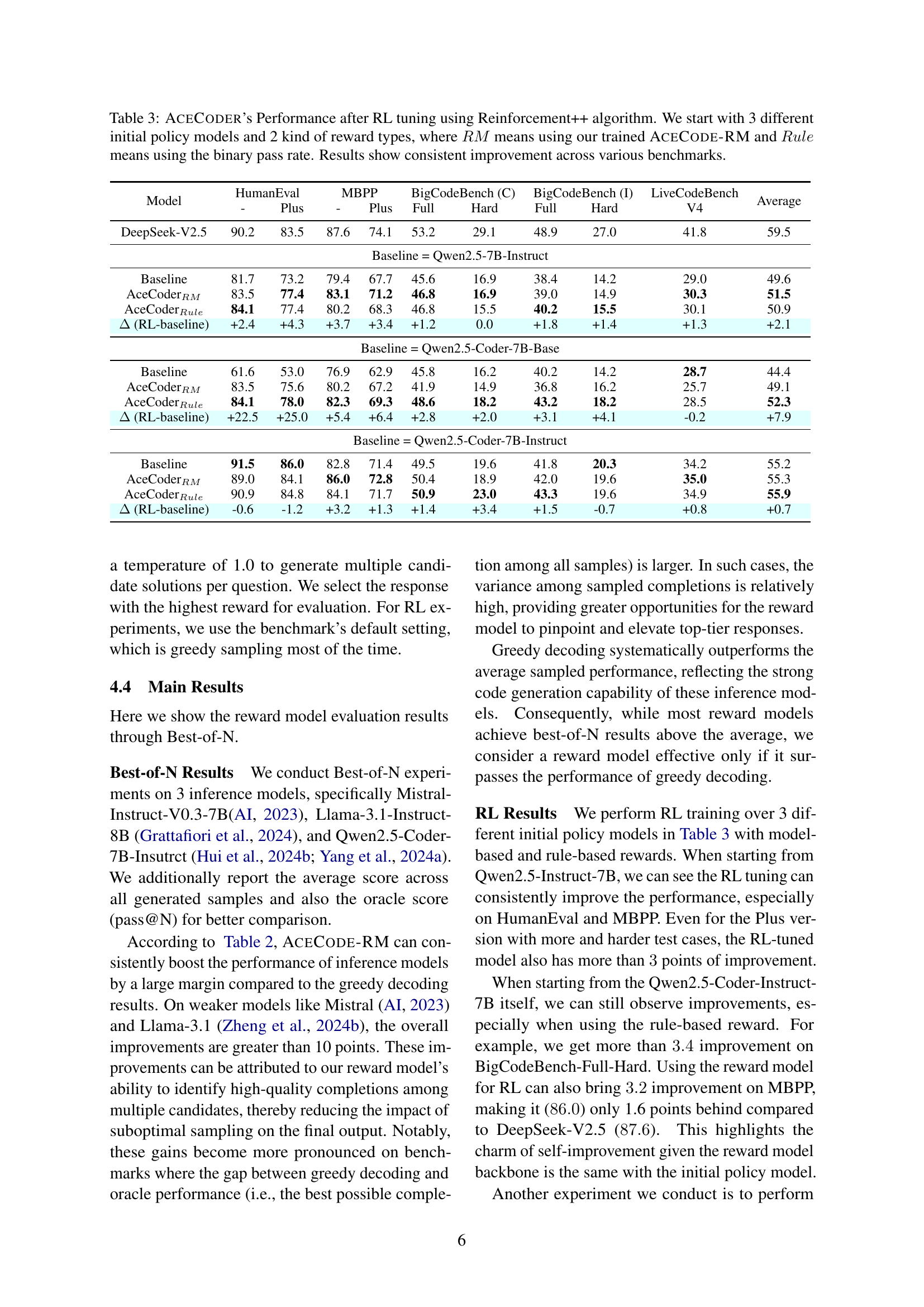
| Mehod | # N | HumanEval | MBPP | BigCodeBench-C | BigCodeBench-I | LiveCodeBench | Average | ||||
| - | Plus | - | Plus | Full | Hard | Full | Hard | V4 | |||
| GPT-4o (0806) | 1 | 92.7 | 87.2 | 87.6 | 72.2 | 58.9 | 36.5 | 48.0 | 25.0 | 43.6 | 61.3 |
| DeepSeek-V2.5 | 1 | 90.2 | 83.5 | 87.6 | 74.1 | 53.2 | 29.1 | 48.9 | 27.0 | 41.8 | 59.5 |
| DeepSeek-V3 | 1 | 91.5 | 86.6 | 87.6 | 73.0 | 62.2 | 39.9 | 50.0 | 27.7 | 63.5 | 64.6 |
| Qwen2.5-Coder-32B | 1 | 92.1 | 87.2 | 90.5 | 77.0 | 58.0 | 33.8 | 49.0 | 27.7 | 48.3 | 62.6 |
| Inference Model = Mistral-7B-Instruct-V0.3 | |||||||||||
| Greedy | 1 | 36.6 | 31.1 | 49.5 | 41.3 | 25.9 | 6.1 | 20.1 | 5.4 | 7.3 | 24.8 |
| Average | 64 | 37.1 | 30.8 | 45.1 | 38.0 | 21.7 | 4.2 | 17.6 | 3.0 | 4.0 | 22.4 |
| Oracle | 64 | 87.2 | 78.0 | 83.9 | 73.5 | 68.4 | 37.8 | 58.5 | 31.1 | 24.3 | 60.3 |
| AceCodeRM-7B | 16 | 65.9 | 56.7 | 59.3 | 52.4 | 35.1 | 10.1 | 29.3 | 8.8 | 11.9 | 36.6 |
| 32 | 68.3 | 58.5 | 59.8 | 51.6 | 37.4 | 8.8 | 30.7 | 10.8 | 14.6 | 37.8 | |
| 64 | 71.3 | 61.6 | 59.8 | 51.6 | 39.4 | 6.8 | 31.8 | 9.5 | 15.4 | 38.6 | |
| (RM-greedy) | - | +34.8 | +30.5 | +10.3 | +11.1 | +13.5 | +4.1 | +11.7 | +5.4 | +8.1 | +13.8 |
| AceCodeRM-32B | 16 | 68.3 | 61.0 | 58.7 | 49.5 | 37.7 | 11.5 | 30.9 | 10.1 | 12.9 | 37.8 |
| 32 | 72.6 | 65.9 | 61.6 | 51.6 | 40.5 | 9.5 | 33.9 | 13.5 | 16.1 | 40.6 | |
| 64 | 75.0 | 64.6 | 60.6 | 50.0 | 42.7 | 15.5 | 35.6 | 13.5 | 17.4 | 41.7 | |
| (RM-greedy) | - | +38.4 | +34.8 | +12.2 | +11.1 | +16.8 | +9.5 | +15.5 | +8.1 | +10.1 | +17.4 |
| Inference Model = Llama-3.1-8B-Instruct | |||||||||||
| Greedy | 1 | 68.9 | 62.2 | 67.2 | 54.8 | 38.5 | 12.8 | 31.8 | 13.5 | 18.0 | 40.9 |
| Average | 64 | 61.7 | 54.9 | 64.5 | 54.5 | 32.8 | 10.1 | 26.6 | 9.0 | 13.8 | 36.4 |
| Oracle | 64 | 93.9 | 90.2 | 92.1 | 82.3 | 80.0 | 54.7 | 67.9 | 48.6 | 40.8 | 72.3 |
| AceCodeRM-7B | 16 | 77.4 | 70.7 | 76.5 | 64.3 | 45.8 | 20.3 | 36.4 | 12.2 | 26.1 | 47.7 |
| 32 | 79.9 | 72.6 | 76.2 | 62.4 | 47.6 | 23.0 | 37.3 | 13.5 | 27.3 | 48.9 | |
| 64 | 81.7 | 74.4 | 74.6 | 61.9 | 47.8 | 23.6 | 38.1 | 13.5 | 27.6 | 49.3 | |
| (RM-greedy) | - | +12.8 | +12.2 | +9.3 | +9.5 | +9.3 | +10.8 | +6.2 | 0.0 | +9.6 | +8.4 |
| AceCodeRM-32B | 16 | 82.3 | 74.4 | 72.8 | 60.6 | 49.8 | 20.3 | 38.4 | 13.5 | 27.5 | 48.8 |
| 32 | 81.7 | 76.2 | 72.8 | 60.6 | 50.4 | 22.3 | 39.1 | 13.5 | 30.3 | 49.6 | |
| 64 | 85.4 | 79.3 | 72.0 | 59.0 | 48.5 | 19.6 | 40.0 | 13.5 | 31.0 | 49.8 | |
| (RM-greedy) | - | +16.5 | +17.1 | +9.3 | +9.5 | +11.8 | +10.8 | +8.2 | +0.0 | +13.0 | +10.7 |
| Inference Model = Qwen2.5-Coder-7B-Instruct | |||||||||||
| Greedy | 1 | 91.5 | 86.0 | 82.8 | 71.4 | 49.5 | 19.6 | 41.8 | 20.3 | 34.2 | 55.2 |
| Average | 64 | 86.0 | 80.1 | 77.9 | 65.6 | 45.3 | 18.6 | 37.3 | 16.2 | 31.8 | 51.0 |
| Oracle | 64 | 98.2 | 95.7 | 97.4 | 90.7 | 80.9 | 62.8 | 73.5 | 53.4 | 57.4 | 78.9 |
| AceCodeRM-7B | 16 | 90.2 | 82.9 | 88.6 | 74.9 | 53.8 | 20.9 | 45.0 | 21.6 | 40.1 | 57.6 |
| 32 | 90.9 | 86.0 | 87.8 | 74.1 | 53.4 | 25.0 | 43.9 | 19.6 | 39.8 | 57.8 | |
| 64 | 90.9 | 85.4 | 87.6 | 73.8 | 52.9 | 24.3 | 43.5 | 21.6 | 40.1 | 57.8 | |
| (RM-greedy) | - | -0.6 | 0.0 | +5.8 | +3.4 | +4.3 | +5.4 | +3.2 | +1.4 | +5.9 | +2.6 |
| AceCodeRM-32B | 16 | 90.2 | 86.6 | 88.4 | 74.9 | 53.9 | 25.0 | 45.4 | 19.6 | 44.0 | 58.7 |
| 32 | 90.2 | 86.6 | 88.4 | 75.4 | 55.4 | 29.7 | 45.6 | 21.6 | 43.5 | 59.6 | |
| 64 | 89.6 | 86.0 | 87.8 | 75.1 | 55.0 | 26.4 | 46.1 | 22.3 | 44.5 | 59.2 | |
| (RM-greedy) | - | -0.6 | +0.6 | +5.8 | +4.0 | +6.0 | +10.1 | +4.3 | +2.0 | +10.3 | +4.7 |
🔼 Table 2 presents the performance of the AceCode-RM reward model using best-of-n sampling on four code generation benchmarks: HumanEval, MBPP, BigCodeBench (both completion and instruction splits), and LiveCodeBench. The table shows the model’s performance across various difficulty levels, including ‘Plus,’ ‘Full,’ and ‘Hard’ variations for some benchmarks. The results are compared against a greedy baseline and, in some cases, against oracle performance for context.
read the caption
Table 2: AceCode-RM’s best-of-n results. We evaluated the model on HumanEval, MBPP, BigCodeBench, and LiveCodeBench. Specifically, -C means completion split and -I means instruct split.
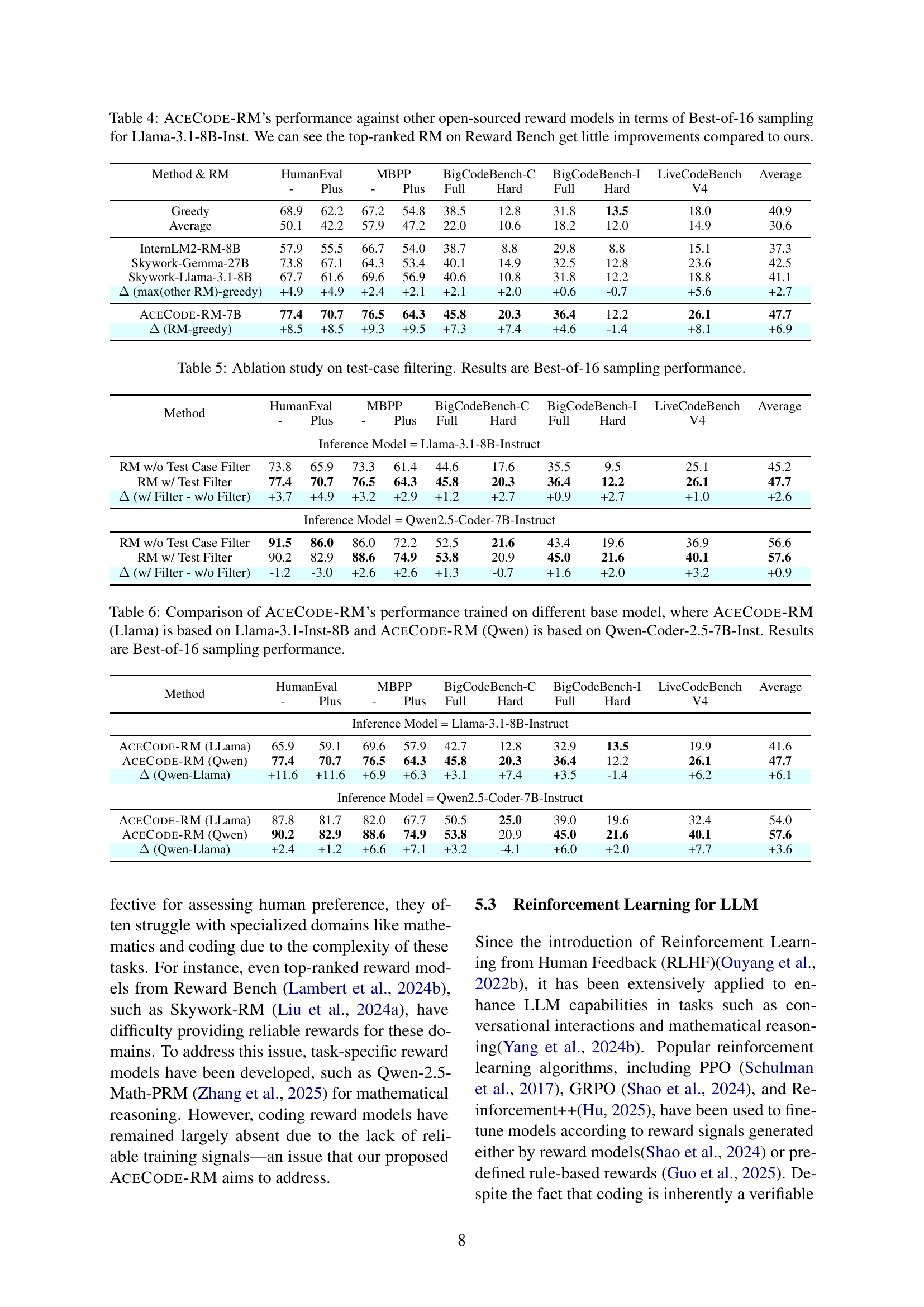
| Model | HumanEval | MBPP | BigCodeBench (C) | BigCodeBench (I) | LiveCodeBench | Average | ||||
| - | Plus | - | Plus | Full | Hard | Full | Hard | V4 | ||
| DeepSeek-V2.5 | 90.2 | 83.5 | 87.6 | 74.1 | 53.2 | 29.1 | 48.9 | 27.0 | 41.8 | 59.5 |
| Baseline = Qwen2.5-7B-Instruct | ||||||||||
| Baseline | 81.7 | 73.2 | 79.4 | 67.7 | 45.6 | 16.9 | 38.4 | 14.2 | 29.0 | 49.6 |
| AceCoderRM | 83.5 | 77.4 | 83.1 | 71.2 | 46.8 | 16.9 | 39.0 | 14.9 | 30.3 | 51.5 |
| AceCoderRule | 84.1 | 77.4 | 80.2 | 68.3 | 46.8 | 15.5 | 40.2 | 15.5 | 30.1 | 50.9 |
| (RL-baseline) | +2.4 | +4.3 | +3.7 | +3.4 | +1.2 | 0.0 | +1.8 | +1.4 | +1.3 | +2.1 |
| Baseline = Qwen2.5-Coder-7B-Base | ||||||||||
| Baseline | 61.6 | 53.0 | 76.9 | 62.9 | 45.8 | 16.2 | 40.2 | 14.2 | 28.7 | 44.4 |
| AceCoderRM | 83.5 | 75.6 | 80.2 | 67.2 | 41.9 | 14.9 | 36.8 | 16.2 | 25.7 | 49.1 |
| AceCoderRule | 84.1 | 78.0 | 82.3 | 69.3 | 48.6 | 18.2 | 43.2 | 18.2 | 28.5 | 52.3 |
| (RL-baseline) | +22.5 | +25.0 | +5.4 | +6.4 | +2.8 | +2.0 | +3.1 | +4.1 | -0.2 | +7.9 |
| Baseline = Qwen2.5-Coder-7B-Instruct | ||||||||||
| Baseline | 91.5 | 86.0 | 82.8 | 71.4 | 49.5 | 19.6 | 41.8 | 20.3 | 34.2 | 55.2 |
| AceCoderRM | 89.0 | 84.1 | 86.0 | 72.8 | 50.4 | 18.9 | 42.0 | 19.6 | 35.0 | 55.3 |
| AceCoderRule | 90.9 | 84.8 | 84.1 | 71.7 | 50.9 | 23.0 | 43.3 | 19.6 | 34.9 | 55.9 |
| (RL-baseline) | -0.6 | -1.2 | +3.2 | +1.3 | +1.4 | +3.4 | +1.5 | -0.7 | +0.8 | +0.7 |
🔼 This table presents the performance of the AceCoder model after reinforcement learning (RL) fine-tuning using the Reinforcement++ algorithm. The experiment starts with three different pre-trained language models (LLMs) as baselines. For each baseline, two reward methods were used for RL training: AceCode-RM (a custom reward model trained by the authors) and Rule (a simple binary reward based on whether the generated code passes the test cases). The table shows the performance improvements achieved across four benchmarks (HumanEval, MBPP, BigCodeBench-C, BigCodeBench-I, and LiveCodeBench) for each combination of baseline LLM and reward method. The ‘Average’ column provides a mean score across all benchmarks, allowing for an overall comparison of the different RL training setups.
read the caption
Table 3: AceCoder’s Performance after RL tuning using Reinforcement++ algorithm. We start with 3 different initial policy models and 2 kind of reward types, where RM𝑅𝑀RMitalic_R italic_M means using our trained AceCode-RM and Rule𝑅𝑢𝑙𝑒Ruleitalic_R italic_u italic_l italic_e means using the binary pass rate. Results show consistent improvement across various benchmarks.
| Method & RM | HumanEval | MBPP | BigCodeBench-C | BigCodeBench-I | LiveCodeBench | Average | ||||
| - | Plus | - | Plus | Full | Hard | Full | Hard | V4 | ||
| Greedy | 68.9 | 62.2 | 67.2 | 54.8 | 38.5 | 12.8 | 31.8 | 13.5 | 18.0 | 40.9 |
| Average | 50.1 | 42.2 | 57.9 | 47.2 | 22.0 | 10.6 | 18.2 | 12.0 | 14.9 | 30.6 |
| InternLM2-RM-8B | 57.9 | 55.5 | 66.7 | 54.0 | 38.7 | 8.8 | 29.8 | 8.8 | 15.1 | 37.3 |
| Skywork-Gemma-27B | 73.8 | 67.1 | 64.3 | 53.4 | 40.1 | 14.9 | 32.5 | 12.8 | 23.6 | 42.5 |
| Skywork-Llama-3.1-8B | 67.7 | 61.6 | 69.6 | 56.9 | 40.6 | 10.8 | 31.8 | 12.2 | 18.8 | 41.1 |
| (max(other RM)-greedy) | +4.9 | +4.9 | +2.4 | +2.1 | +2.1 | +2.0 | +0.6 | -0.7 | +5.6 | +2.7 |
| AceCode-RM-7B | 77.4 | 70.7 | 76.5 | 64.3 | 45.8 | 20.3 | 36.4 | 12.2 | 26.1 | 47.7 |
| (RM-greedy) | +8.5 | +8.5 | +9.3 | +9.5 | +7.3 | +7.4 | +4.6 | -1.4 | +8.1 | +6.9 |
🔼 This table compares the performance of AceCode-RM, a reward model for code generation, to other existing open-source reward models. The comparison is done using the Llama-3.1-8B-Inst model and the Best-of-16 sampling method on several benchmarks (HumanEval, MBPP, BigCodeBench-C, BigCodeBench-I, LiveCodeBench). The results show that AceCode-RM significantly outperforms the other reward models, achieving substantial improvements over greedy decoding in various benchmarks. The table highlights AceCode-RM’s effectiveness in identifying and selecting high-quality code generation outputs.
read the caption
Table 4: AceCode-RM’s performance against other open-sourced reward models in terms of Best-of-16 sampling for Llama-3.1-8B-Inst. We can see the top-ranked RM on Reward Bench get little improvements compared to ours.
| Method | HumanEval | MBPP | BigCodeBench-C | BigCodeBench-I | LiveCodeBench | Average | ||||
| - | Plus | - | Plus | Full | Hard | Full | Hard | V4 | ||
| Inference Model = Llama-3.1-8B-Instruct | ||||||||||
| RM w/o Test Case Filter | 73.8 | 65.9 | 73.3 | 61.4 | 44.6 | 17.6 | 35.5 | 9.5 | 25.1 | 45.2 |
| RM w/ Test Filter | 77.4 | 70.7 | 76.5 | 64.3 | 45.8 | 20.3 | 36.4 | 12.2 | 26.1 | 47.7 |
| (w/ Filter - w/o Filter) | +3.7 | +4.9 | +3.2 | +2.9 | +1.2 | +2.7 | +0.9 | +2.7 | +1.0 | +2.6 |
| Inference Model = Qwen2.5-Coder-7B-Instruct | ||||||||||
| RM w/o Test Case Filter | 91.5 | 86.0 | 86.0 | 72.2 | 52.5 | 21.6 | 43.4 | 19.6 | 36.9 | 56.6 |
| RM w/ Test Filter | 90.2 | 82.9 | 88.6 | 74.9 | 53.8 | 20.9 | 45.0 | 21.6 | 40.1 | 57.6 |
| (w/ Filter - w/o Filter) | -1.2 | -3.0 | +2.6 | +2.6 | +1.3 | -0.7 | +1.6 | +2.0 | +3.2 | +0.9 |
🔼 This table presents the results of an ablation study investigating the impact of test-case filtering on the performance of reward models. It compares the performance (measured using Best-of-16 sampling) of reward models trained with and without a filtering step that removes unreliable test cases generated by a large language model. The comparison is shown across multiple code generation benchmarks (HumanEval, MBPP, BigCodeBench-C, BigCodeBench-I, and LiveCodeBench), evaluating performance on both the ‘Plus’ (more challenging problems) and ‘Full’ versions of the datasets where applicable. The table highlights the improvement in reward model performance achieved by incorporating the test-case filtering process.
read the caption
Table 5: Ablation study on test-case filtering. Results are Best-of-16 sampling performance.
| Method | HumanEval | MBPP | BigCodeBench-C | BigCodeBench-I | LiveCodeBench | Average | ||||
| - | Plus | - | Plus | Full | Hard | Full | Hard | V4 | ||
| Inference Model = Llama-3.1-8B-Instruct | ||||||||||
| AceCode-RM (LLama) | 65.9 | 59.1 | 69.6 | 57.9 | 42.7 | 12.8 | 32.9 | 13.5 | 19.9 | 41.6 |
| AceCode-RM (Qwen) | 77.4 | 70.7 | 76.5 | 64.3 | 45.8 | 20.3 | 36.4 | 12.2 | 26.1 | 47.7 |
| (Qwen-Llama) | +11.6 | +11.6 | +6.9 | +6.3 | +3.1 | +7.4 | +3.5 | -1.4 | +6.2 | +6.1 |
| Inference Model = Qwen2.5-Coder-7B-Instruct | ||||||||||
| AceCode-RM (LLama) | 87.8 | 81.7 | 82.0 | 67.7 | 50.5 | 25.0 | 39.0 | 19.6 | 32.4 | 54.0 |
| AceCode-RM (Qwen) | 90.2 | 82.9 | 88.6 | 74.9 | 53.8 | 20.9 | 45.0 | 21.6 | 40.1 | 57.6 |
| (Qwen-Llama) | +2.4 | +1.2 | +6.6 | +7.1 | +3.2 | -4.1 | +6.0 | +2.0 | +7.7 | +3.6 |
🔼 This table compares the performance of two versions of the AceCode-RM reward model. One version is trained using the Llama-3.1-Inst-8B base model (AceCode-RM (Llama)), and the other is trained using the Qwen-Coder-2.5-7B-Inst base model (AceCode-RM (Qwen)). The table shows the performance of each model across different benchmarks and metrics (HumanEval Plus, MBPP Plus, BigCodeBench-C Full/Hard, BigCodeBench-I Full/Hard, and LiveCodeBench V4) using best-of-16 sampling. This allows for a direct comparison of the impact of the base model choice on the reward model’s effectiveness.
read the caption
Table 6: Comparison of AceCode-RM’s performance trained on different base model, where AceCode-RM (Llama) is based on Llama-3.1-Inst-8B and AceCode-RM (Qwen) is based on Qwen-Coder-2.5-7B-Inst. Results are Best-of-16 sampling performance.
| system: |
| You are an AI assistant that helps people with python coding tasks. |
| user: |
| You are the latest and best bot aimed at transforming some code snippet into a leetcode style question. You will be provided with a prompt for writing code, along with a reference program that answers the question. Please complete the following for me: |
| 1. Come up with a leetcode style question which consists of a well-defined problem. The generated question should meet the following criteria: |
| a. The question is clear and understandable, with enough details to describe what the input and output are. |
| b. The question should be solvable by only implementing 1 function instead of multiple functions or a class. Therefore, please avoid questions which require complicated pipelines. |
| c. The question itself should not require any access to external resource or database. |
| d. Feel free to use part of the original question if necessary. Moreover, please do not ask for runtime and space complexity analysis or any test cases in your response. |
| 2. Based on the modified question that you generated in part 1, you need to create around 20 test cases for this modified question. Each test case should be independent assert clauses. The parameters and expected output of each test case should all be constants, **without accessing any external resources**. |
| Here is the original question: |
| {instruction} |
| Here is the reference program that answers the question: |
| “‘python |
| {program} |
| “‘ |
| Now give your modified question and generated test cases in the following json format: |
| {"question": …, "tests":["assert …", "assert …"]}. |
🔼 This table details the prompt engineering used to convert existing code examples into LeetCode-style questions and their corresponding test cases. The prompt instructs an AI assistant to create a well-defined coding problem (LeetCode style), which includes a clear description of inputs and outputs, can be solved with a single function, avoids needing external resources, and provides a set of around 20 independent test cases (assert statements) with constant inputs and outputs.
read the caption
Table 7: Prompt Used for Converting Seed Code Dataset into LeetCode-style Questions and Test Cases
Full paper#