TL;DR#
Current methods for human motion generation and editing are often task-specific and lack efficiency. This limits progress in applications like virtual reality and animation. A unified approach is needed that can handle various tasks with fine-grained control and knowledge sharing.
MotionLab introduces a novel Motion-Condition-Motion paradigm to solve this problem. It uses a unified framework based on rectified flows to learn mappings between source and target motions guided by conditions. Key improvements include the MotionFlow Transformer, Aligned Rotational Position Encoding, Task Instruction Modulation, and Motion Curriculum Learning. MotionLab shows significant improvements in efficiency and generalization across multiple benchmarks compared to previous state-of-the-art models.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MotionLab, a unified framework for human motion generation and editing, addressing the limitations of existing isolated approaches. This offers significant advancements in efficiency and generalization for various motion-related tasks. The novel Motion-Condition-Motion paradigm and accompanying techniques open exciting avenues for future research in human-motion understanding and control, particularly within fields like virtual reality, animation, and robotics.
Visual Insights#

🔼 Figure 1 showcases MotionLab’s capabilities in human motion generation and editing. It compares MotionLab’s performance to several state-of-the-art (SOTA) models across various tasks, including text-based and trajectory-based motion generation and editing, as well as motion style transfer and in-betweening. The figure visually demonstrates MotionLab’s ability to generate and edit human motions based on different types of conditions (text, trajectories, and other motions). All motions are represented using the SMPL model, with transparent motions signifying the source motion or condition, and the opaque motions representing the resulting target motion. The results highlight MotionLab’s superior versatility, performance, and efficiency compared to previous SOTA methods. Additional qualitative results can be found on the project’s website and in the paper’s appendix.
read the caption
Figure 1. Demonstration of our MotionLab’s versatility, performance and efficiency. Previous SOTA refer to multiple expert models, including MotionLCM (Dai et al., 2025), OmniControl (Xie et al., 2023), MotionFix (Athanasiou et al., 2024), CondMDI (Cohan et al., 2024) and MCM-LDM (Song et al., 2024). All motions are represented using SMPL (Loper et al., 2023), where transparent motion indicates the source motion or condition, and the other represents the target motion. More qualitative results are available in the website and appendix.
| Method | text-based generation | text-based editing | trajectory-based generation | trajectory-based editing | in-between | style transfer |
| MDM (Tevet et al., 2023) | ||||||
| MLD (Chen et al., 2023) | ||||||
| OmniControl (Xie et al., 2023) | ||||||
| MotionFix (Athanasiou et al., 2024) | ||||||
| CondMDI (Cohan et al., 2024) | ||||||
| MCM-LDM (Song et al., 2024) | ||||||
| MotionGPT (Jiang et al., 2023) | ||||||
| MotionCLR (Chen et al., 2024) | ||||||
| Ours |
🔼 Table 1 compares several existing methods for human motion generation and editing, highlighting their capabilities across various tasks. The tasks include text-based and trajectory-based motion generation and editing, in-between motion generation, and motion style transfer. Each method’s performance is represented using checkmarks (✓) to indicate whether it was trained for the specific task, an ‘x’ to indicate it wasn’t trained for the task, and a hyphen (-) to show that while not explicitly trained, zero-shot implementation might be possible. This table provides a concise overview of the state-of-the-art in unified human motion processing before introducing the proposed MotionLab framework.
read the caption
Table 1. Summary of different methods focusing on motion generation and editing. ✓✓\checkmark✓ indicates that the method has been trained for the task, ×\times× indicates that the method has not been trained, and −-- indicates that the method has not been trained but can be implemented in a zero-shot manner.
In-depth insights#
Unified Motion Model#
A unified motion model, as described in the research paper, aims to consolidate diverse human motion tasks such as generation and editing under a single framework. This is achieved by introducing the Motion-Condition-Motion paradigm, which uses source motion, condition, and target motion to predict target movement. This elegantly handles different tasks; generation uses a null source while editing utilizes the original motion. The model’s success relies heavily on the MotionFlow Transformer, leveraging rectified flows to efficiently map source to target motions while being guided by conditions. Key innovations include Aligned Rotational Position Encoding for time synchronization and Task Instruction Modulation to distinguish tasks effectively, improving efficiency and avoiding task-specific modules. The curriculum learning strategy enhances generalization by introducing tasks progressively in order of difficulty. Overall, the proposed unified motion model demonstrates a significant advance in versatility, efficiency and performance compared to existing separate models. Future improvements could involve incorporating more detailed body parts like fingers and facial features to increase realism and broaden practical application.
MCM Paradigm#
The Motion-Condition-Motion (MCM) paradigm, as proposed in the research paper, presents a novel and unified approach to human motion generation and editing. Its core strength lies in its conceptual elegance: framing diverse tasks – from text-based generation to complex style transfers – under a single, intuitive paradigm. By defining each task as a transformation from a source motion, guided by a condition, to a target motion, MCM elegantly unifies tasks previously treated in isolation. This unification offers crucial advantages: facilitating knowledge sharing between tasks, thereby potentially improving performance on data-scarce tasks, and enabling more efficient model architectures. The paradigm’s success hinges on the effectiveness of the proposed MotionLab framework, which utilizes rectified flows and specialized techniques like Aligned Rotational Position Encoding to handle multiple modalities and temporal synchronization. While the paradigm’s effectiveness is demonstrated, potential challenges remain, particularly in scaling to extremely high-resolution data or incorporating diverse motion qualities such as finger movements or facial expressions. Nevertheless, MCM represents a significant step toward a more holistic and efficient approach to human motion modeling, potentially impacting various fields, from computer graphics to robotics.
MotionFlow Xformr#
The conceptualization of “MotionFlow Xformr” suggests a novel transformer architecture specifically designed for human motion processing. Its core innovation likely lies in integrating rectified flows, enabling efficient and robust learning of motion dynamics. This contrasts with traditional diffusion models, offering a potential advantage in speed and stability. The architecture likely processes motion data as a sequence of tokens, with the transformer layers capturing temporal dependencies and relationships between different body parts. The name suggests that the model focuses on learning the flow of motion, possibly incorporating techniques to explicitly model and predict the trajectory of motion in the future. Multi-modality is implied; the transformer may accept not only raw motion data but also textual descriptions or other contextual information (such as style or trajectory targets), making the model versatile for diverse tasks such as motion generation, editing, and style transfer. The use of attention mechanisms within the transformer architecture is also likely, facilitating informed information processing among different parts of the motion sequence and conditioning modalities. The efficacy of this approach hinges on the effectiveness of the rectified flow integration, the design of the attention mechanisms, and the overall architecture’s capacity to handle various input and output representations of human motion.
Curriculum Learning#
The research paper employs curriculum learning as a crucial training strategy for its unified human motion generation and editing framework. This approach is particularly important because the model is designed to handle multiple diverse tasks simultaneously. Starting with simpler tasks and gradually progressing to more complex ones, curriculum learning helps the model learn foundational knowledge before tackling more challenging aspects. This prevents catastrophic forgetting and ensures that the model effectively shares information across diverse tasks. The hierarchical nature of the curriculum, where foundational concepts are established first, enables smoother and more efficient knowledge integration. Specifically, the curriculum starts with simpler tasks like reconstructing masked source motions, enhancing the model’s comprehension of motion characteristics before proceeding to more challenging tasks involving text, trajectory, and style, fostering a seamless knowledge transfer. The ultimate aim is to achieve enhanced generalization and performance across all tasks, demonstrating the effectiveness of curriculum learning in training sophisticated, unified models.
Future Research#
Future research directions stemming from this MotionLab framework could explore several promising avenues. Expanding the model’s capabilities to handle more nuanced and complex human motion is crucial, encompassing fine-grained finger and facial movements for enhanced realism and expressivity. This would involve incorporating larger and more diverse datasets capturing these intricate details. Another key area is improving the efficiency and scalability of the model, particularly for real-time applications such as virtual reality and interactive simulations. This necessitates exploring optimized architectures and training strategies. Furthermore, investigating the potential for cross-modal generation and editing would unlock new possibilities, allowing users to seamlessly combine different input modalities (text, audio, video) to achieve a broader spectrum of creative control over human motion. Finally, rigorous evaluations on more diverse and challenging datasets, including those with different cultural backgrounds and motion styles, are vital to fully assess the model’s robustness and generalizability. This work could incorporate metrics beyond those employed in the current research, providing a more comprehensive evaluation framework.
More visual insights#
More on figures

🔼 Figure 2 illustrates the key difference between the trajectory in diffusion models and rectified flows. Diffusion models generate a trajectory from noise (x₀) to data (x₁) that is not linear and changes velocity as the process evolves. This is shown mathematically as xt = √(1-αt¯)x0 + √αt¯ϵ. In contrast, rectified flows create a trajectory with constant velocity, moving linearly from x₀ to x₁. This is represented by xt = (1-t)x₀ + tx₁. This linear trajectory is what makes rectified flows more robust and efficient for learning, as indicated by Zhao et al. (2024).
read the caption
Figure 2. Demonstration of the difference trajectory between diffusion models and rectified flows. This difference lies in that the trajectory of diffusion models is based on xt=(1−αt¯)x0+αt¯ϵsubscript𝑥𝑡1¯subscript𝛼𝑡subscript𝑥0¯subscript𝛼𝑡italic-ϵx_{t}=\sqrt{(1-\overline{\alpha_{t}})}x_{0}+\sqrt{\overline{\alpha_{t}}}\epsilonitalic_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = square-root start_ARG ( 1 - over¯ start_ARG italic_α start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT end_ARG ) end_ARG italic_x start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT + square-root start_ARG over¯ start_ARG italic_α start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT end_ARG end_ARG italic_ϵ, while the trajectory of rectified flows is based on xt=(1−t)x0+tx1subscript𝑥𝑡1𝑡subscript𝑥0𝑡subscript𝑥1x_{t}=(1-t)x_{0}+tx_{1}italic_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = ( 1 - italic_t ) italic_x start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT + italic_t italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT. This distinction leads to more robust learning by maintaining a constant velocity, contributing to model’s efficiency (Zhao et al., 2024).

🔼 Figure 3 is a two-part illustration detailing the architecture of MotionLab, a unified framework for human motion generation and editing. (a) shows the overall system, highlighting the input modalities (source motion, condition, task instruction) fed into the core MotionFlow Transformer (MFT). The MFT processes these inputs to generate the target motion. (b) zooms in on a single MFT block, showcasing its internal components: joint attention mechanisms for cross-modal interaction, condition paths for modality-specific processing, and aligned rotational position encoding for temporal synchronization. The figure visually represents the flow of information within the MotionLab framework.
read the caption
Figure 3. Illustration of our MotionLab and the detail of its MotionFlow Transformer (MFT).
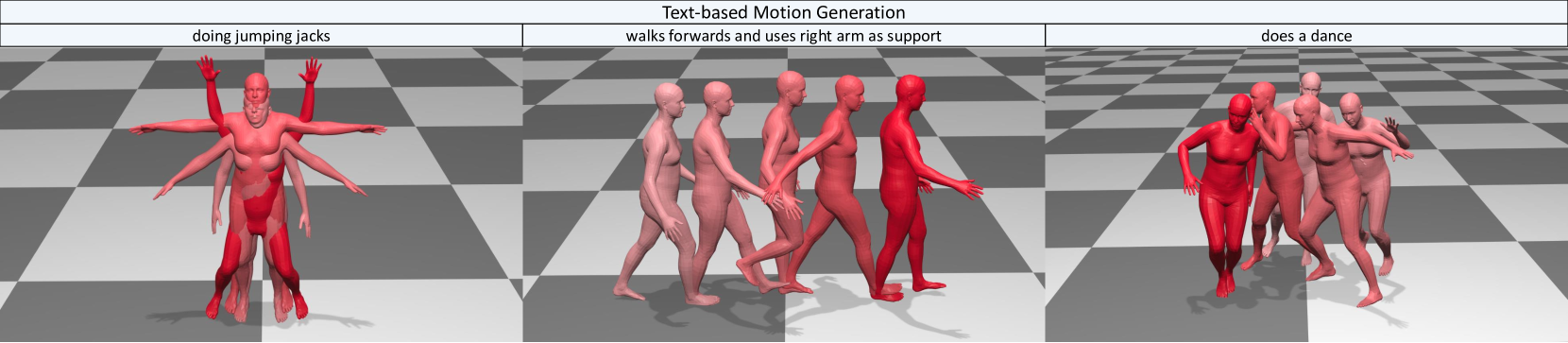
🔼 This figure displays qualitative results from the MotionLab model for text-based human motion generation. Multiple examples are shown, each demonstrating the model’s ability to generate a realistic 3D human motion sequence from a given text prompt. To enhance clarity and visualize the temporal progression of each generated motion, the color scheme of the 3D models changes gradually from light to dark colors as the motion unfolds.
read the caption
Figure 4. Qualitative results of MotionLab on the text-based motion generation. For clarity, as time progresses, motion sequences transit from light to dark colors.

🔼 This figure showcases the capabilities of MotionLab in text-based motion editing. It presents several examples where a source motion (shown transparently) is modified based on a textual instruction. The resulting edited motion, generated by MotionLab, is displayed alongside the source motion for direct comparison. This illustrates how MotionLab can accurately and naturally alter existing motion sequences according to textual descriptions, allowing for fine-grained control over the editing process.
read the caption
Figure 5. Qualitative results of MotionLab on the text-based motion editing. The transparent motion is the source motion, and the other is the generated motion.

🔼 Figure 6 showcases examples of human motion generated by MotionLab using trajectory-based input. The system takes a target trajectory as input (represented by red spheres for the pelvis, right hand, and right foot) and generates a full 3D human motion sequence that follows that trajectory. This demonstrates MotionLab’s ability to generate realistic and accurate motion sequences conditioned on specified joint movements over time.
read the caption
Figure 6. Qualitative results of MotionLab on the trajectory-based motion generation. The red balls are the trajectory of the pelvis, right hand and right foot.
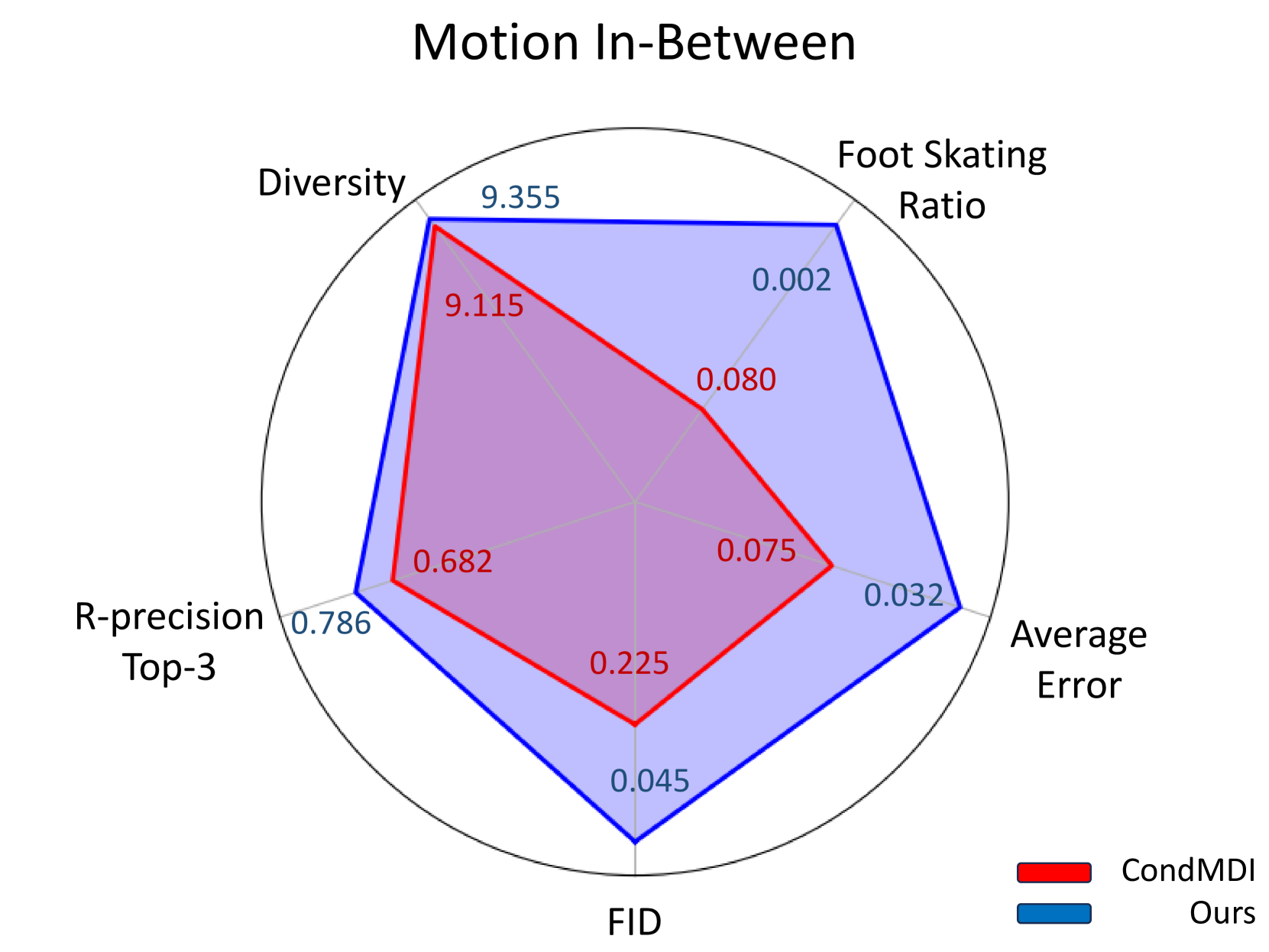
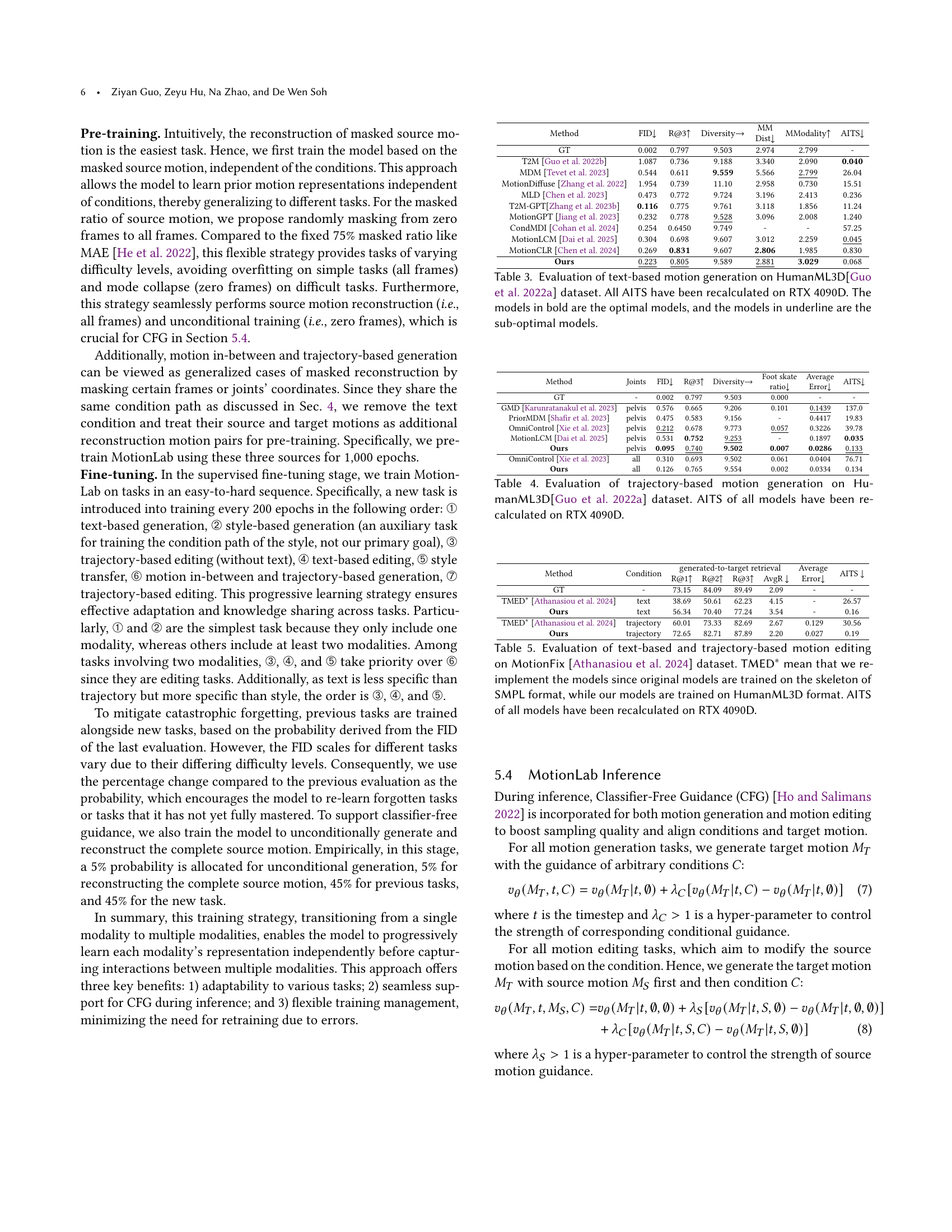
🔼 Figure 7 presents a quantitative comparison of motion in-between generation results between the proposed MotionLab model and the CondMDI model (Cohan et al., 2024) using the HumanML3D dataset (Guo et al., 2022a). The figure displays a comparison across four key metrics: Fréchet Inception Distance (FID), R-precision (top 3), average error, and foot skating ratio. Lower FID values indicate better generation quality, higher R-precision indicates higher accuracy, lower average error reflects better fidelity to target motion, and lower foot skating ratio shows better physical plausibility. The bar chart visually demonstrates that MotionLab significantly outperforms CondMDI across all metrics, showcasing its superior performance in generating smooth and realistic in-between motions.
read the caption
Figure 7. Comparison of the motion in-between with CondMDI (Cohan et al., 2024) on HumanML3D (Guo et al., 2022a), which shows that our model outperforms CondMDI.

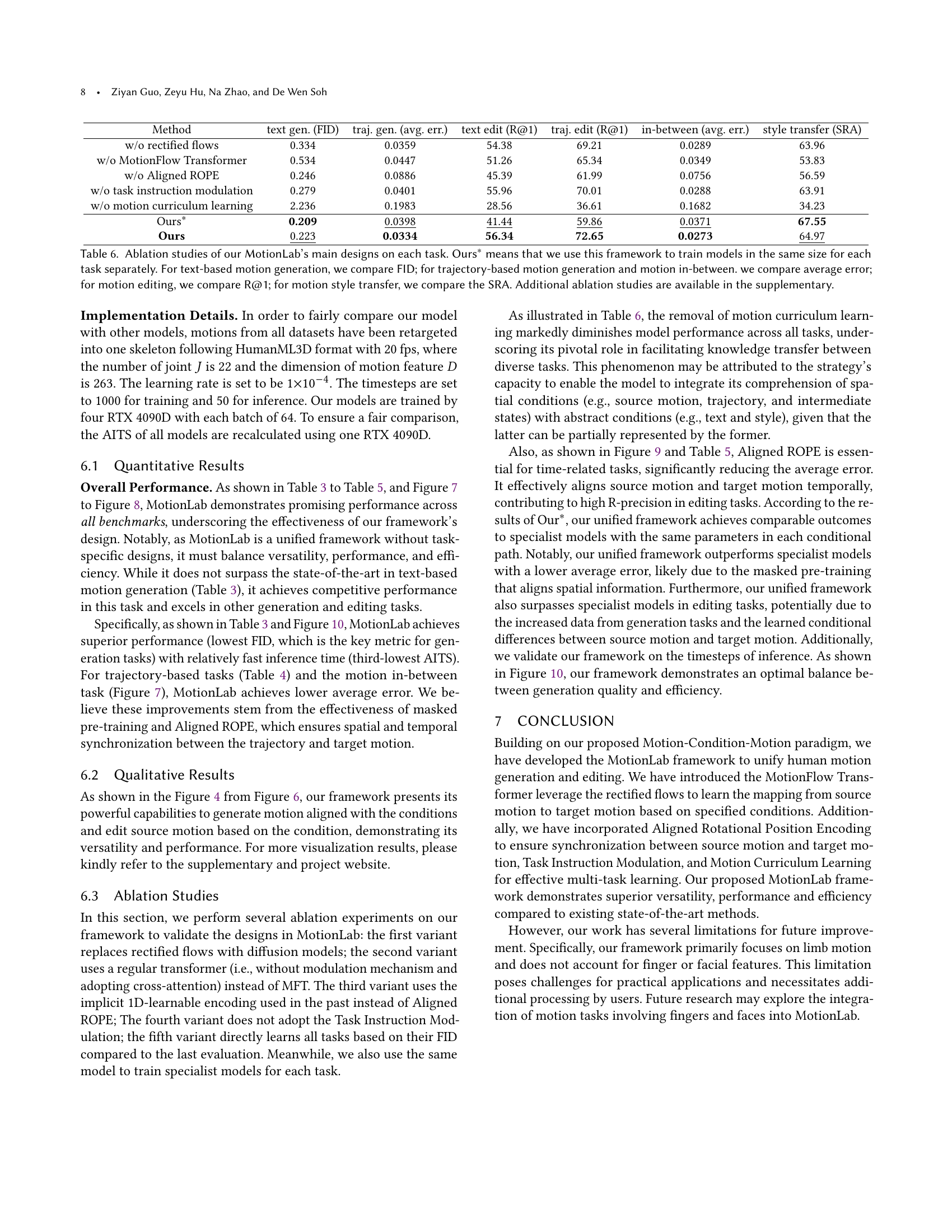
🔼 Figure 8 presents a quantitative comparison of motion style transfer performance between the proposed MotionLab model and the state-of-the-art MCM-LDM model. The comparison uses a subset of the HumanML3D dataset and evaluates two key aspects of style transfer: semantic preservation (measured by Content Recognition Accuracy or CRA) and style accuracy (measured by Style Recognition Accuracy or SRA). The bar chart visually demonstrates that MotionLab achieves superior performance in both CRA and SRA compared to MCM-LDM, indicating a stronger ability to retain the original meaning of the source motion while effectively adapting the style from a target motion.
read the caption
Figure 8. Comparison of the motion style transfer with MCM-LDM (Song et al., 2024) on a subset of HumanML3D (Guo et al., 2022a). This shows that our model has a stronger ability to preserve the semantics of source motion and a stronger ability to learn the style of style motion.

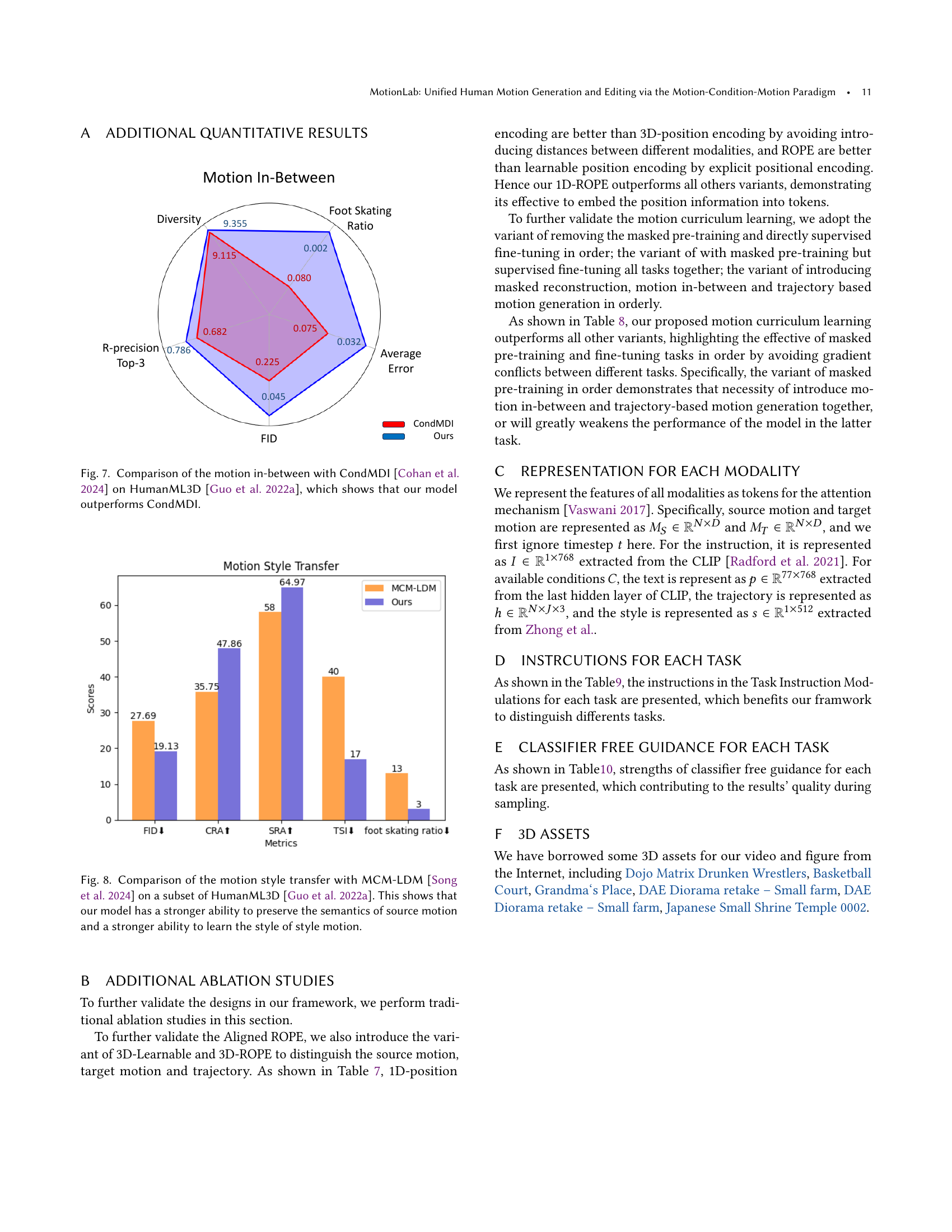
🔼 This figure shows an ablation study on the motion in-between task, comparing different positional encoding methods used in MotionLab. Three versions of the same motion in-between task are shown, using different positional encoding strategies: 1D-learnable position encoding (beige), Aligned ROPE (purple), and the original keyframes from the input (gray). The visual differences highlight that Aligned ROPE significantly improves the quality of the generated motion compared to the other methods. The improved temporal alignment between the generated motion and the input keyframes demonstrates the importance of Aligned ROPE for motion in-between tasks.
read the caption
Figure 9. Ablation results of MotionLab on the motion in-between. Beige motion is use 1D-learnable position encoding, purple motion use Aligned ROPE, and gray motions are the poses provided in keyframes, demonstrating the importance of Aligned ROPE.
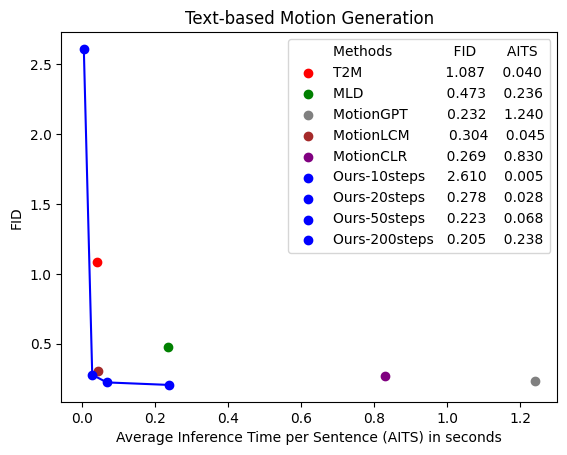
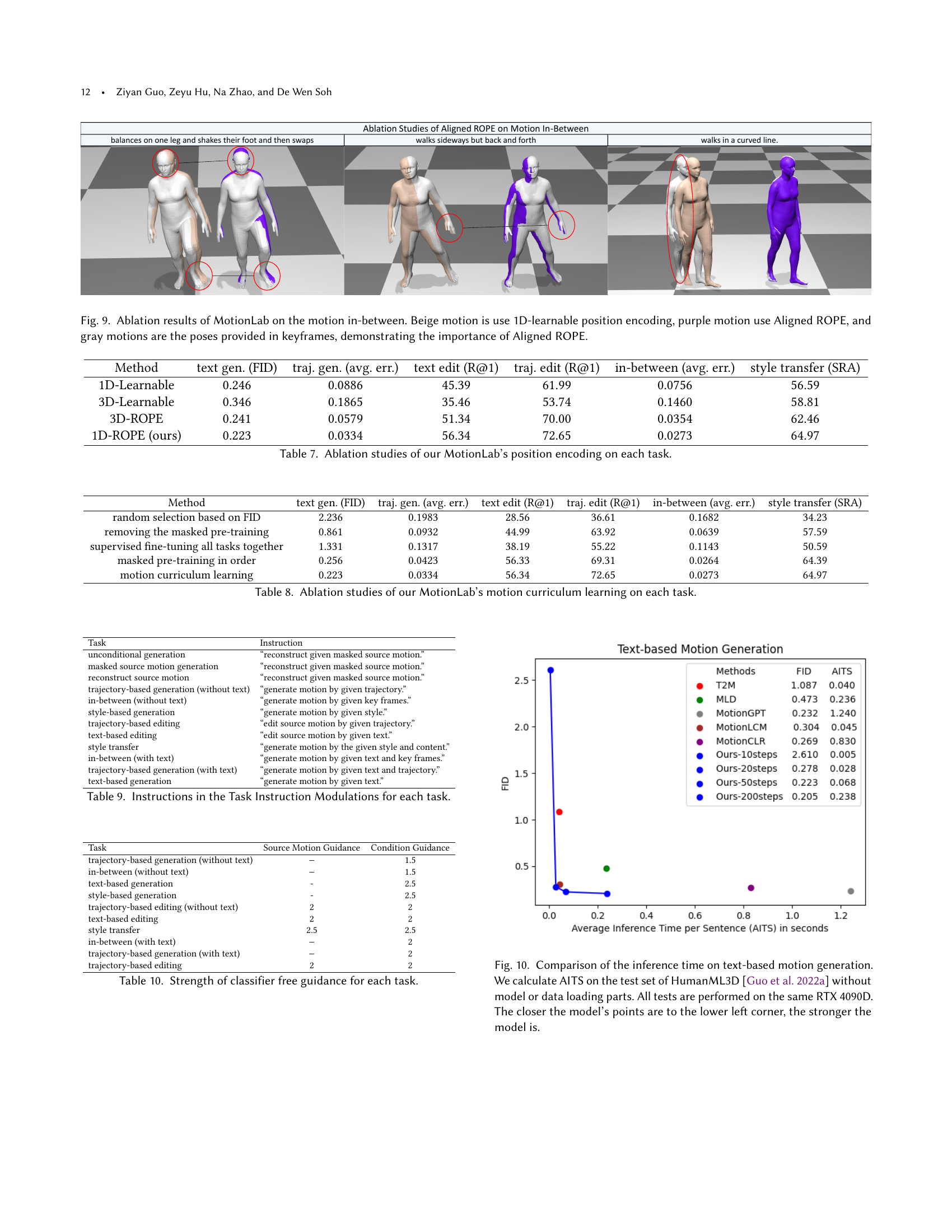
🔼 Figure 10 presents a comparison of inference time for text-based human motion generation. The experiment measured Average Inference Time per Sample (AITS) using the HumanML3D dataset (Guo et al., 2022a). The testing excluded model and data loading times, and all tests ran on the same RTX 4090D GPU for consistent comparison. The graph plots FID (Fréchet Inception Distance, lower is better) against AITS (lower is better). The closer a model’s point is to the lower-left corner of the plot, indicating both high generation quality (low FID) and fast inference (low AITS), the stronger the model is deemed to be.
read the caption
Figure 10. Comparison of the inference time on text-based motion generation. We calculate AITS on the test set of HumanML3D (Guo et al., 2022a) without model or data loading parts. All tests are performed on the same RTX 4090D. The closer the model’s points are to the lower left corner, the stronger the model is.
More on tables
| Task | Source Motion | Condition | Target Motion |
| unconditional generation | |||
| masked reconstruction | masked source motion | source motion | |
| reconstruction | complete source motion | source motion | |
| text-based generation | text | ||
| trajectory-based generation | text/joints’ coordinates | ||
| motion in-between | text/poses in keyframes | ||
| text-based editing | text | ||
| trajectory-based editing | text/joints’ coordinates | ||
| style transfer | style motion |
🔼 This table categorizes various human motion tasks (unconditional generation, masked reconstruction, reconstruction, text-based generation, trajectory-based generation, motion in-between, text-based editing, trajectory-based editing, style transfer) within the Motion-Condition-Motion paradigm. For each task, it specifies whether a source motion is required, what type of condition is used (text, trajectory, style, or none), and whether a target motion is generated. This organization helps to clarify the relationships between different motion tasks and how they are unified under a common framework.
read the caption
Table 2. Structuring human motion tasks within our Motion-Condition-Motion paradigm.
| Method | FID | R@3 | Diversity | MM Dist | MModality | AITS |
| GT | 0.002 | 0.797 | 9.503 | 2.974 | 2.799 | - |
| T2M (Guo et al., 2022b) | 1.087 | 0.736 | 9.188 | 3.340 | 2.090 | 0.040 |
| MDM (Tevet et al., 2023) | 0.544 | 0.611 | 9.559 | 5.566 | 2.799 | 26.04 |
| MotionDiffuse (Zhang et al., 2022) | 1.954 | 0.739 | 11.10 | 2.958 | 0.730 | 15.51 |
| MLD (Chen et al., 2023) | 0.473 | 0.772 | 9.724 | 3.196 | 2.413 | 0.236 |
| T2M-GPT(Zhang et al., 2023b) | 0.116 | 0.775 | 9.761 | 3.118 | 1.856 | 11.24 |
| MotionGPT (Jiang et al., 2023) | 0.232 | 0.778 | 9.528 | 3.096 | 2.008 | 1.240 |
| CondMDI (Cohan et al., 2024) | 0.254 | 0.6450 | 9.749 | - | - | 57.25 |
| MotionLCM (Dai et al., 2025) | 0.304 | 0.698 | 9.607 | 3.012 | 2.259 | 0.045 |
| MotionCLR (Chen et al., 2024) | 0.269 | 0.831 | 9.607 | 2.806 | 1.985 | 0.830 |
| Ours | 0.223 | 0.805 | 9.589 | 2.881 | 3.029 | 0.068 |
🔼 Table 3 presents a comprehensive comparison of various text-based human motion generation models on the HumanML3D dataset. The models are evaluated across multiple metrics: Fréchet Inception Distance (FID), which measures the similarity of generated motion distributions to real motion; Recall@3 (R@3), indicating the proportion of generated motions that correctly match the textual description; Diversity, representing the variety of generated motions; Average Inference Time per Sample (AITS), showing the computational efficiency; and Average Inference Time per Sentence (AITS), which shows the computational efficiency. The table highlights the best-performing model (in bold) and the close contenders (underlined), giving a complete overview of the performance of different models in generating human motion based on text descriptions. All AITS values were recalculated using an RTX 4090D GPU for consistency.
read the caption
Table 3. Evaluation of text-based motion generation on HumanML3D(Guo et al., 2022a) dataset. All AITS have been recalculated on RTX 4090D. The models in bold are the optimal models, and the models in underline are the sub-optimal models.
| Method | Joints | FID | R@3 | Diversity | Foot skate ratio | Average Error | AITS |
| GT | - | 0.002 | 0.797 | 9.503 | 0.000 | - | - |
| GMD (Karunratanakul et al., 2023) | pelvis | 0.576 | 0.665 | 9.206 | 0.101 | 0.1439 | 137.0 |
| PriorMDM (Shafir et al., 2023) | pelvis | 0.475 | 0.583 | 9.156 | - | 0.4417 | 19.83 |
| OmniControl (Xie et al., 2023) | pelvis | 0.212 | 0.678 | 9.773 | 0.057 | 0.3226 | 39.78 |
| MotionLCM (Dai et al., 2025) | pelvis | 0.531 | 0.752 | 9.253 | - | 0.1897 | 0.035 |
| Ours | pelvis | 0.095 | 0.740 | 9.502 | 0.007 | 0.0286 | 0.133 |
| OmniControl (Xie et al., 2023) | all | 0.310 | 0.693 | 9.502 | 0.061 | 0.0404 | 76.71 |
| Ours | all | 0.126 | 0.765 | 9.554 | 0.002 | 0.0334 | 0.134 |
🔼 Table 4 presents a comprehensive evaluation of trajectory-based motion generation methods using the HumanML3D dataset (Guo et al., 2022a). It compares various models on key metrics: Average Error (measuring the discrepancy between generated and actual motion joint positions), R@3 (retrieval precision indicating the percentage of successful retrieval of motion from generated data), and Diversity (measuring the variety of generated motions). The table also includes AITS (average inference time per sample), calculated using an RTX 4090D GPU for consistent benchmarking. The ‘pelvis’ and ‘all’ columns refer to evaluating the metrics based on the pelvis joint only or all joints respectively. This allows for a granular analysis of performance across different aspects of trajectory-based motion generation.
read the caption
Table 4. Evaluation of trajectory-based motion generation on HumanML3D(Guo et al., 2022a) dataset. AITS of all models have been recalculated on RTX 4090D.
| Method | Condition | generated-to-target retrieval | Average Error | AITS | |||
| R@1 | R@2 | R@3 | AvgR | ||||
| GT | - | 73.15 | 84.09 | 89.49 | 2.09 | - | - |
| TMED∗ (Athanasiou et al., 2024) | text | 38.69 | 50.61 | 62.23 | 4.15 | - | 26.57 |
| Ours | text | 56.34 | 70.40 | 77.24 | 3.54 | - | 0.16 |
| TMED∗ (Athanasiou et al., 2024) | trajectory | 60.01 | 73.33 | 82.69 | 2.67 | 0.129 | 30.56 |
| Ours | trajectory | 72.65 | 82.71 | 87.89 | 2.20 | 0.027 | 0.19 |
🔼 Table 5 presents a comparison of text-based and trajectory-based motion editing methods on the MotionFix dataset. Since the original MotionFix models were trained using the SMPL skeleton, the authors re-implemented these models using the HumanML3D skeleton for a fair comparison. The table shows results for Recall@1, Recall@2, Recall@3, and average recall, along with the average inference time per sample (AITS) which has been recalculated on an RTX 4090D GPU. The results highlight the performance improvements achieved by the proposed MotionLab method.
read the caption
Table 5. Evaluation of text-based and trajectory-based motion editing on MotionFix (Athanasiou et al., 2024) dataset. TMED∗ mean that we re-implement the models since original models are trained on the skeleton of SMPL format, while our models are trained on HumanML3D format. AITS of all models have been recalculated on RTX 4090D.
| Method | text gen. (FID) | traj. gen. (avg. err.) | text edit (R@1) | traj. edit (R@1) | in-between (avg. err.) | style transfer (SRA) |
| w/o rectified flows | 0.334 | 0.0359 | 54.38 | 69.21 | 0.0289 | 63.96 |
| w/o MotionFlow Transformer | 0.534 | 0.0447 | 51.26 | 65.34 | 0.0349 | 53.83 |
| w/o Aligned ROPE | 0.246 | 0.0886 | 45.39 | 61.99 | 0.0756 | 56.59 |
| w/o task instruction modulation | 0.279 | 0.0401 | 55.96 | 70.01 | 0.0288 | 63.91 |
| w/o motion curriculum learning | 2.236 | 0.1983 | 28.56 | 36.61 | 0.1682 | 34.23 |
| Ours∗ | 0.209 | 0.0398 | 41.44 | 59.86 | 0.0371 | 67.55 |
| Ours | 0.223 | 0.0334 | 56.34 | 72.65 | 0.0273 | 64.97 |
🔼 This table presents the results of ablation studies conducted on the MotionLab model. It shows the impact of removing key components of the model (rectified flows, MotionFlow Transformer, Aligned ROPE, task instruction modulation, and motion curriculum learning) on the performance of various motion generation and editing tasks. The performance metrics used vary depending on the specific task. For example, FID is used for text-based generation, average error is used for trajectory-based generation and motion in-between tasks, R@1 is used for motion editing tasks, and SRA is used for motion style transfer tasks. The table also includes a comparison to a baseline model where the same framework is used to train separate models for each task (denoted as ‘Ours*’). This allows for assessing the benefits of the unified multi-task learning approach. Further details can be found in the supplementary materials.
read the caption
Table 6. Ablation studies of our MotionLab’s main designs on each task. Ours∗ means that we use this framework to train models in the same size for each task separately. For text-based motion generation, we compare FID; for trajectory-based motion generation and motion in-between. we compare average error; for motion editing, we compare R@1; for motion style transfer, we compare the SRA. Additional ablation studies are available in the supplementary.
| Method | text gen. (FID) | traj. gen. (avg. err.) | text edit (R@1) | traj. edit (R@1) | in-between (avg. err.) | style transfer (SRA) |
| 1D-Learnable | 0.246 | 0.0886 | 45.39 | 61.99 | 0.0756 | 56.59 |
| 3D-Learnable | 0.346 | 0.1865 | 35.46 | 53.74 | 0.1460 | 58.81 |
| 3D-ROPE | 0.241 | 0.0579 | 51.34 | 70.00 | 0.0354 | 62.46 |
| 1D-ROPE (ours) | 0.223 | 0.0334 | 56.34 | 72.65 | 0.0273 | 64.97 |
🔼 This table presents the results of ablation studies conducted on MotionLab, focusing on the impact of different position encoding methods on various tasks. It compares the performance metrics (FID for text-based generation, average error for trajectory-based generation and motion in-between, R@1 for text and trajectory-based editing, and SRA for style transfer) achieved using different position encoding techniques: 1D-learnable, 3D-learnable, 3D-ROPE, and the proposed 1D-ROPE (Aligned ROPE). The results highlight the effectiveness of the proposed Aligned ROPE in improving the overall performance across all tasks.
read the caption
Table 7. Ablation studies of our MotionLab’s position encoding on each task.
| Method | text gen. (FID) | traj. gen. (avg. err.) | text edit (R@1) | traj. edit (R@1) | in-between (avg. err.) | style transfer (SRA) |
| random selection based on FID | 2.236 | 0.1983 | 28.56 | 36.61 | 0.1682 | 34.23 |
| removing the masked pre-training | 0.861 | 0.0932 | 44.99 | 63.92 | 0.0639 | 57.59 |
| supervised fine-tuning all tasks together | 1.331 | 0.1317 | 38.19 | 55.22 | 0.1143 | 50.59 |
| masked pre-training in order | 0.256 | 0.0423 | 56.33 | 69.31 | 0.0264 | 64.39 |
| motion curriculum learning | 0.223 | 0.0334 | 56.34 | 72.65 | 0.0273 | 64.97 |
🔼 This table presents the results of ablation experiments conducted on the MotionLab model to assess the impact of the motion curriculum learning strategy. It shows the performance of MotionLab on several key tasks (text-based generation, trajectory-based generation, text-based editing, trajectory-based editing, motion in-between, and style transfer) when different aspects of the curriculum learning are removed or modified. This allows for a quantitative understanding of the contribution of this training strategy to the model’s overall performance and versatility. Metrics reported include FID (Fréchet Inception Distance), Average Error, R@1 (recall at rank 1), and Style Recognition Accuracy (SRA), depending on the specific task.
read the caption
Table 8. Ablation studies of our MotionLab’s motion curriculum learning on each task.
| Task | Instruction |
| unconditional generation | “reconstruct given masked source motion.” |
| masked source motion generation | “reconstruct given masked source motion.” |
| reconstruct source motion | “reconstruct given masked source motion.” |
| trajectory-based generation (without text) | “generate motion by given trajectory.” |
| in-between (without text) | “generate motion by given key frames.” |
| style-based generation | “generate motion by given style.” |
| trajectory-based editing | “edit source motion by given trajectory.” |
| text-based editing | “edit source motion by given text.” |
| style transfer | “generate motion by the given style and content.” |
| in-between (with text) | “generate motion by given text and key frames.” |
| trajectory-based generation (with text) | “generate motion by given text and trajectory.” |
| text-based generation | “generate motion by given text.” |
🔼 This table details the specific instructions used in the Task Instruction Modulation component of the MotionLab model. These instructions serve as task-specific guidance for the model, ensuring it appropriately performs different human motion tasks. Each row represents a task (e.g., unconditional generation, text-based generation, motion editing), and the instruction column provides the text prompt used to guide the model’s behavior for that task. The instructions are designed to be easily understood and can be directly fed to a CLIP model to generate the embedding needed by MotionLab.
read the caption
Table 9. Instructions in the Task Instruction Modulations for each task.
| Task | Source Motion Guidance | Condition Guidance |
| trajectory-based generation (without text) | 1.5 | |
| in-between (without text) | 1.5 | |
| text-based generation | - | 2.5 |
| style-based generation | - | 2.5 |
| trajectory-based editing (without text) | 2 | 2 |
| text-based editing | 2 | 2 |
| style transfer | 2.5 | 2.5 |
| in-between (with text) | 2 | |
| trajectory-based generation (with text) | 2 | |
| trajectory-based editing | 2 | 2 |
🔼 This table shows the strength of classifier-free guidance used for each task in the MotionLab framework. Classifier-free guidance is a technique used to improve the quality of generated results. The values in the table represent the hyperparameter λ controlling the strength of the guidance. A higher value indicates stronger guidance. The tasks are categorized into generation and editing tasks, further broken down by the type of conditioning used (text, trajectory, etc.). The values help demonstrate how the optimal guidance strength varies based on task complexity and conditioning modality.
read the caption
Table 10. Strength of classifier free guidance for each task.
Full paper#