TL;DR#
Current generative video models struggle with creating realistic motion due to their focus on visual fidelity over motion coherence. This often results in videos with unnatural or physically impossible movements. The pixel-based training objective used in these models does not prioritize temporal consistency, leading to these limitations.
VideoJAM tackles this problem by introducing a novel framework that instills a strong motion prior into the video generation process. It does so by simultaneously predicting both the visual appearance and the corresponding motion from a single representation. Furthermore, VideoJAM uses a unique ‘Inner-Guidance’ mechanism that leverages the model’s own evolving motion predictions to further guide the generation towards temporal coherence. This approach significantly boosts motion coherence, surpasses existing models, and improves overall video quality.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of current video generation models: incoherent motion. By introducing VideoJAM, researchers gain a new tool to improve video generation significantly and provides a new framework for generating temporally consistent videos. This opens exciting new avenues in video editing, visual effects, and other areas reliant on high-quality video generation.
Visual Insights#

🔼 Figure 1 showcases example videos generated using the VideoJAM model, highlighting its ability to generate high-quality videos with coherent motion across diverse motion types. The model takes text descriptions as input and produces videos that accurately reflect the described motion, improving on the limitations of previous video generation models that often struggle with realistic and fluid movement. The examples demonstrate various scenarios, ranging from a ballet dancer twirling to a skateboarder performing jumps, illustrating VideoJAM’s versatility.
read the caption
Figure 1: Text-to-video samples generated by VideoJAM. We present VideoJAM, a framework that explicitly instills a strong motion prior to any video generation model. Our framework significantly enhances motion coherence across a wide variety of motion types.
| Human Eval | Auto. Metrics | ||||
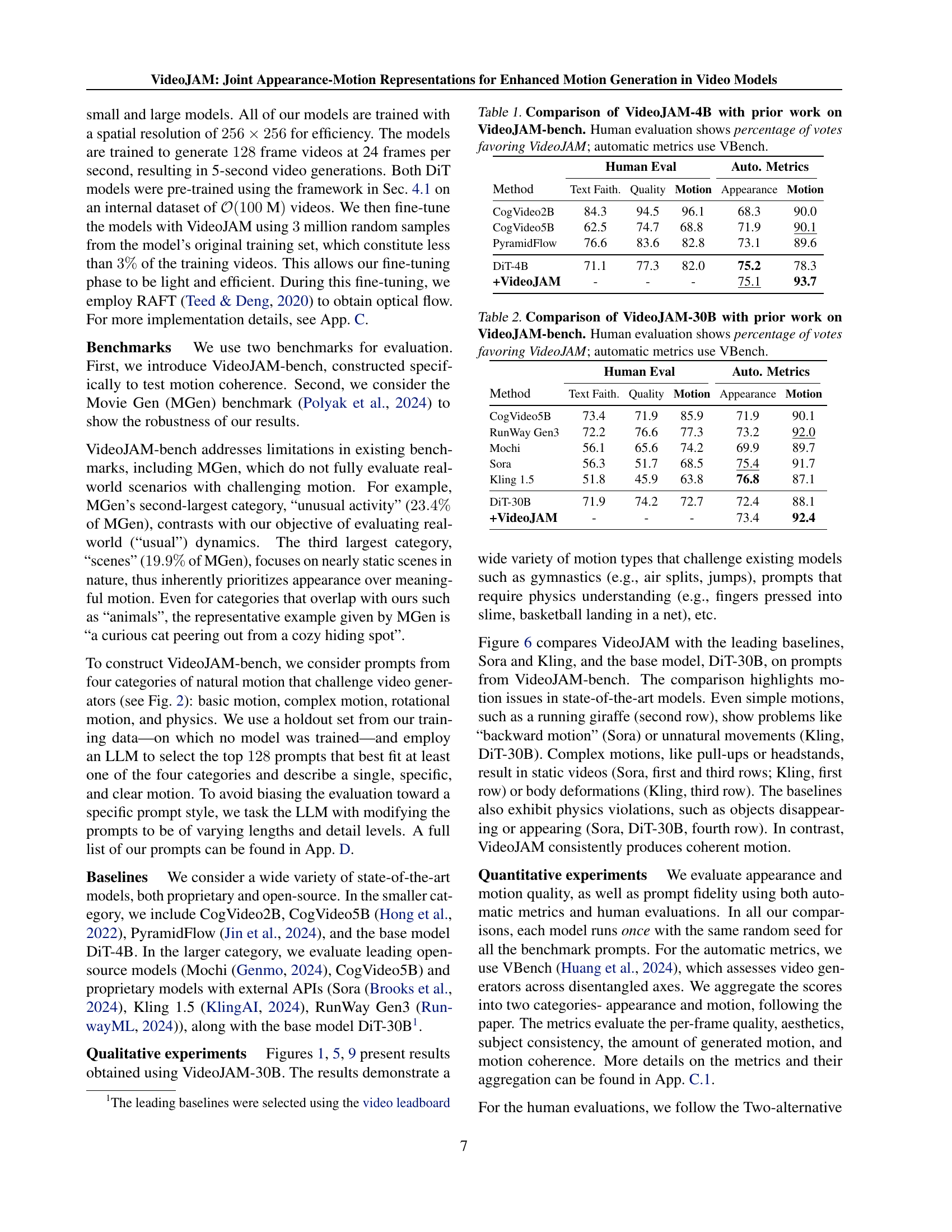
| Method | Text Faith. | Quality | Motion | Appearance | Motion |
| CogVideo2B | 84.3 | 94.5 | 96.1 | 68.3 | 90.0 |
| CogVideo5B | 62.5 | 74.7 | 68.8 | 71.9 | 90.1 |
| PyramidFlow | 76.6 | 83.6 | 82.8 | 73.1 | 89.6 |
| DiT-4B | 71.1 | 77.3 | 82.0 | 75.2 | 78.3 |
| +VideoJAM | - | - | - | 75.1 | 93.7 |
🔼 This table presents a quantitative comparison of the VideoJAM-4B model against several other video generation models on the VideoJAM-bench benchmark. The benchmark specifically assesses motion coherence in generated videos. The table shows the results of both human evaluations (percentage of participants preferring VideoJAM) and automated evaluations using VBench, a metric that scores multiple video qualities including text fidelity, visual quality, motion, and appearance. This allows for a comprehensive comparison across different aspects of video generation quality and motion coherence.
read the caption
Table 1: Comparison of VideoJAM-4B with prior work on VideoJAM-bench. Human evaluation shows percentage of votes favoring VideoJAM; automatic metrics use VBench.
In-depth insights#
Motion Incoherence#
The concept of ‘Motion Incoherence’ in generative video models highlights a critical limitation: the inability to realistically and consistently depict movement. Current models often prioritize visual fidelity over accurate motion, leading to artifacts such as objects passing through each other, limbs contorting unrealistically, or repetitive, unnatural movements. This is primarily because conventional training methods focus on pixel-level reconstruction, neglecting the temporal coherence crucial for fluid, believable motion. VideoJAM addresses this directly by incorporating an explicit motion prior, teaching the model to predict both the appearance and the motion simultaneously. This joint representation forces the model to consider both aspects during generation, dramatically improving motion coherence. The use of ‘Inner-Guidance’, where the model’s predicted motion itself dynamically guides subsequent predictions, further enhances the realism and consistency of generated movements, resulting in a significant advancement over existing methods. The core issue, however, remains the inherent difficulty of modeling the complexities of physics and real-world dynamics within the current video generation paradigm, presenting a significant challenge for future research.
VideoJAM Framework#
The VideoJAM framework is a two-unit system designed to enhance motion coherence in video generation models. The training unit introduces a joint appearance-motion representation, modifying the model’s objective function to predict both generated pixels and their corresponding motion simultaneously. This encourages the model to learn a more holistic understanding of the relationship between appearance and movement, thus improving generation quality. The inference unit, Inner-Guidance, dynamically steers generation using the model’s own evolving motion prediction as a feedback mechanism. This innovative approach ensures the generation remains aligned with the intended motion, even in complex scenarios where other methods might fail, leading to significantly improved coherence. Unlike methods relying on fixed, external signals, VideoJAM’s Inner-Guidance leverages the model’s internal predictions as a dynamic guidance signal, resulting in more realistic and nuanced movement. Overall, the framework is both efficient and versatile, adaptable to a variety of pre-trained video generation models with minimal changes. This is achieved through two linear layers, which is computationally efficient and easily adaptable to various architectures. VideoJAM’s architecture promotes seamless integration of appearance and motion, resulting in improved coherence and overall video quality.
Inner-Guidance#
The proposed Inner-Guidance mechanism is a crucial innovation within the VideoJAM framework, directly addressing the limitations of existing approaches in leveraging motion predictions for coherent video generation. Unlike methods relying on fixed external signals, Inner-Guidance cleverly utilizes the model’s own evolving motion predictions as a dynamic guidance signal. This is significant because it allows the model to iteratively refine its generations, ensuring temporal consistency and accuracy. The mechanism cleverly addresses the inherent dependency of motion signals on model weights and other conditions, solving the challenges posed by prior work’s assumptions of independence. This adaptive nature of Inner-Guidance is particularly important for complex motions and scenarios where precisely controlled temporal coherence is vital, resulting in a significant improvement of generated video quality. Its integration within the broader framework represents a substantial advancement in achieving realistic and temporally coherent video generation.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a video generation model, this would involve progressively disabling features like text guidance, the inner-guidance mechanism, or the optical flow prediction to isolate their effects on overall video quality, motion coherence, and other relevant metrics. The results of such a study reveal the relative importance of each component, highlighting which parts are crucial for achieving high-quality and coherent video generation and which parts may be less essential or even detrimental. For example, removing text guidance might decrease the relevance of the generated video to the input prompt, whereas disabling inner-guidance would likely reduce motion coherence and increase the likelihood of unnatural or physically implausible movement. Similarly, removing optical flow prediction might impair the models ability to learn spatiotemporal dynamics. By carefully analyzing the impact of each ablation, researchers can gain valuable insights into the models’ inner workings and optimize its design for superior performance. The ablation study’s findings provide a quantitative and qualitative understanding of the model’s architecture and guide future development efforts. It is a crucial step in validating the models effectiveness and robustness.
Future Work#
Future research directions stemming from this VideoJAM model could explore several promising avenues. Improving motion coherence in complex scenarios, such as those involving occlusions or intricate interactions between multiple objects, remains a key challenge. Investigating more sophisticated motion representations, perhaps leveraging physics-based modeling, could enhance the realism and accuracy of generated videos. Expanding the model’s capabilities beyond text-to-video generation is also crucial, including applications like video editing, style transfer, or even video inpainting. Addressing the computational cost of training and inference, particularly for high-resolution video generation, is necessary for practical applications. Lastly, exploring methods for better control over generated motion, allowing users to specify nuanced details such as speed, trajectory, or style, would enhance the usability and creative potential of the technology. Furthermore, rigorous evaluation benchmarks that capture the subtleties of motion quality could guide future development efforts.
More visual insights#
More on figures

🔼 Figure 2 showcases examples of motion incoherence produced by the DiT-30B video generation model. Panel (a) demonstrates failure in generating basic, repetitive motions like jogging, showing the model’s inability to accurately represent repeated actions such as foot placement. Panel (b) highlights problems with complex motions, such as gymnastics, illustrating issues like severe body deformation. Panel (c) illustrates difficulties with physical accuracy, with an example of a hula hoop passing unrealistically through a person, defying the laws of physics. Finally, panel (d) displays the model’s struggle with rotational motions, showing its inability to produce simple, repetitive rotational movements.
read the caption
Figure 2: Motion incoherence in video generation. Examples of incoherent generations by DiT-30B (Peebles & Xie, 2023). The model struggles with (a) basic motion, e.g., jogging (stepping on the same leg repeatedly); (b) complex motion e.g., gymnastics; (c) physics, e.g., object dynamics (the hoop passes through the woman); and (d) rotational motion, failing to replicate simple repetitive patterns.

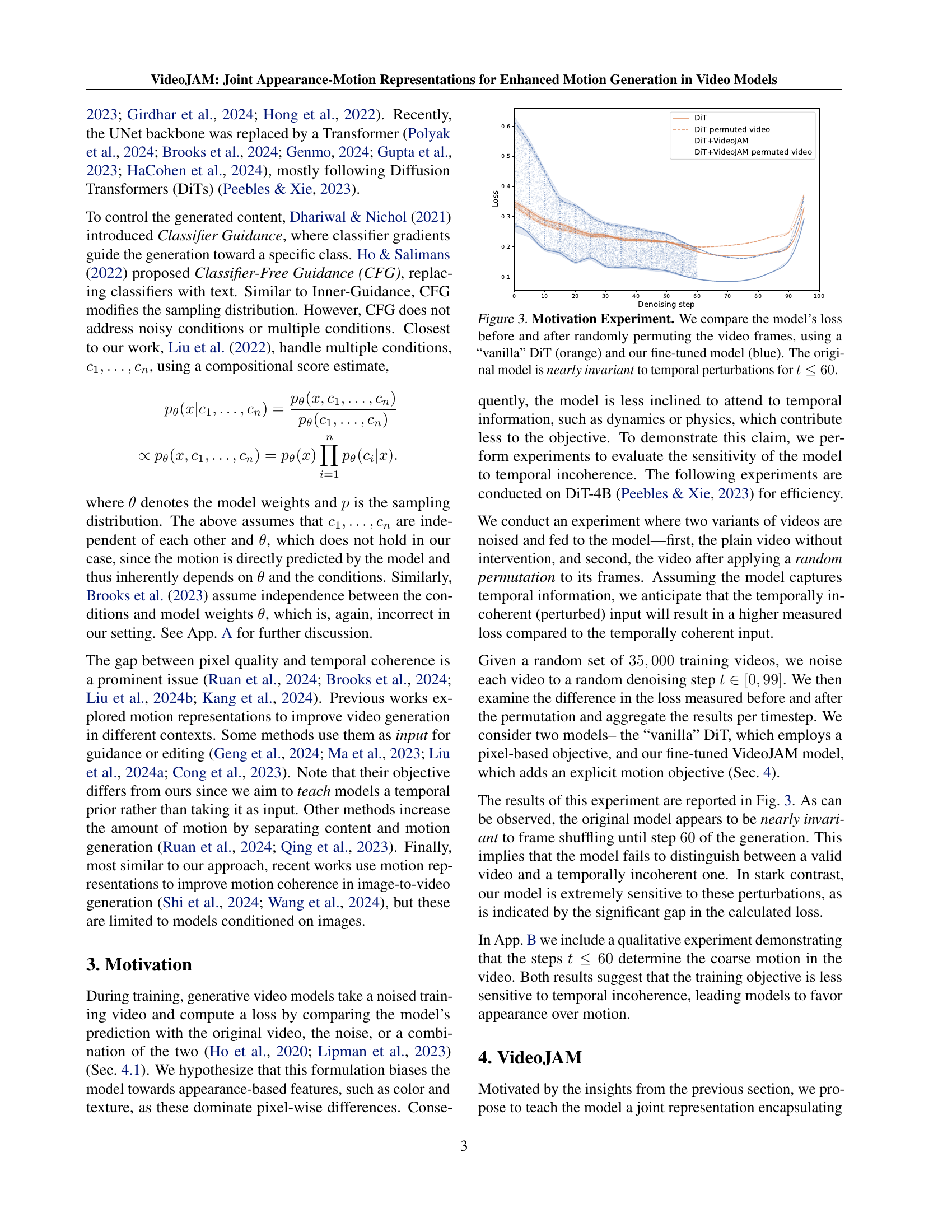
🔼 This figure displays the results of an experiment designed to assess the sensitivity of video generation models to temporal coherence. Two versions of videos were used: original videos and videos with frames randomly permuted. These videos were input to two models: a standard Diffusion Transformer (DiT) and the same model after fine-tuning with the VideoJAM method. The loss, a measure of the difference between model predictions and the original video, was calculated for each model at various denoising steps (t). The experiment reveals that the original DiT model shows almost no difference in loss between the original and the permuted videos until denoising step 60. This indicates that the model is largely unaffected by temporal inconsistencies until a late stage of the generation process. Conversely, the VideoJAM model exhibits a significant difference in loss, demonstrating its increased sensitivity to temporal coherence.
read the caption
Figure 3: Motivation Experiment. We compare the model’s loss before and after randomly permuting the video frames, using a “vanilla” DiT (orange) and our fine-tuned model (blue). The original model is nearly invariant to temporal perturbations for t≤60𝑡60t\leq 60italic_t ≤ 60.

🔼 VideoJAM is composed of two units: a training unit and an inference unit. The training unit takes an input video (x1) and its motion representation (d1) as input. Both are noised and combined into a single latent representation using a linear layer (W+in). A diffusion model processes this combined representation. Two linear projection layers then predict both the appearance and the motion from this joint representation. The inference unit uses the model’s own noisy motion prediction as a dynamic guidance signal to steer the video generation toward temporal coherence at each step. This is achieved through a mechanism called ‘Inner-Guidance’.
read the caption
Figure 4: VideoJAM Framework. VideoJAM is constructed of two units; (a) Training. Given an input video x1subscript𝑥1x_{1}italic_x start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT and its motion representation d1subscript𝑑1d_{1}italic_d start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT, both signals are noised and embedded to a single, joint latent representation using a linear layer, Win+subscriptsuperscriptW𝑖𝑛\textbf{W}^{+}_{in}W start_POSTSUPERSCRIPT + end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_i italic_n end_POSTSUBSCRIPT. The diffusion model processes the input, and two linear projection layers predict both appearance and motion from the joint representation. (b) Inference. We propose Inner-Guidance, where the model’s own noisy motion prediction is used to guide the video prediction at each step.

🔼 Figure 5 showcases various video clips generated using the VideoJAM-30B model. The examples highlight the model’s capacity to generate diverse and complex motions, ranging from simple actions like running to more intricate movements like acrobatics. The improved physics simulation capabilities are also demonstrated, with a clip illustrating a dog successfully jumping over a hurdle, a task that many previous video generation models have struggled with. The figure emphasizes the enhanced motion coherence and realistic physics achieved by VideoJAM.
read the caption
Figure 5: Text-to-video results by VideoJAM-30B. VideoJAM enables the generation of a wide variety of motion types, from basic motion (e.g., running) to complex motion (e.g., acrobatics), and improved physics (e.g., jumping over a hurdle).

🔼 Figure 6 presents a qualitative comparison of video generation results between VideoJAM-30B and three leading baselines (Sora, Kling, and DiT-30B). The comparison uses prompts selected from the VideoJAM-bench dataset, designed to challenge video generation models with various motion types. The results highlight the limitations of the baselines, which frequently exhibit motion incoherence and inconsistencies with the laws of physics. Specific issues demonstrated by the baselines include backward motion (Sora), unnatural motion (Kling), objects passing through each other (DiT), and objects spontaneously appearing or disappearing (Sora, DiT). These problems were observed in both basic motions (e.g., jogging) and complex motions (e.g., gymnastics). In contrast, VideoJAM-30B consistently generated videos with temporally coherent motion that adhered to the laws of physics.
read the caption
Figure 6: Qualitative comparisons between VideoJAM-30B and the leading baselines- Sora, Kling, and DiT-30B on representative prompts from VideoJAM-bench. The baselines struggle with basic motion, displaying “backward motion” (Sora, 2nd row) or unnatural motion (Kling, 2nd row). The generated content defies the basic laws of physics e.g., people passing through objects (DiT, 1st row), or objects that appear or evaporate (Sora, DiT, 4th row). For complex motion, the baselines display static motion or deformations (Sora, Kling, 1st, 3rd row). Conversely, in all cases, VideoJAM produces temporally coherent videos that better adhere to the laws of physics.

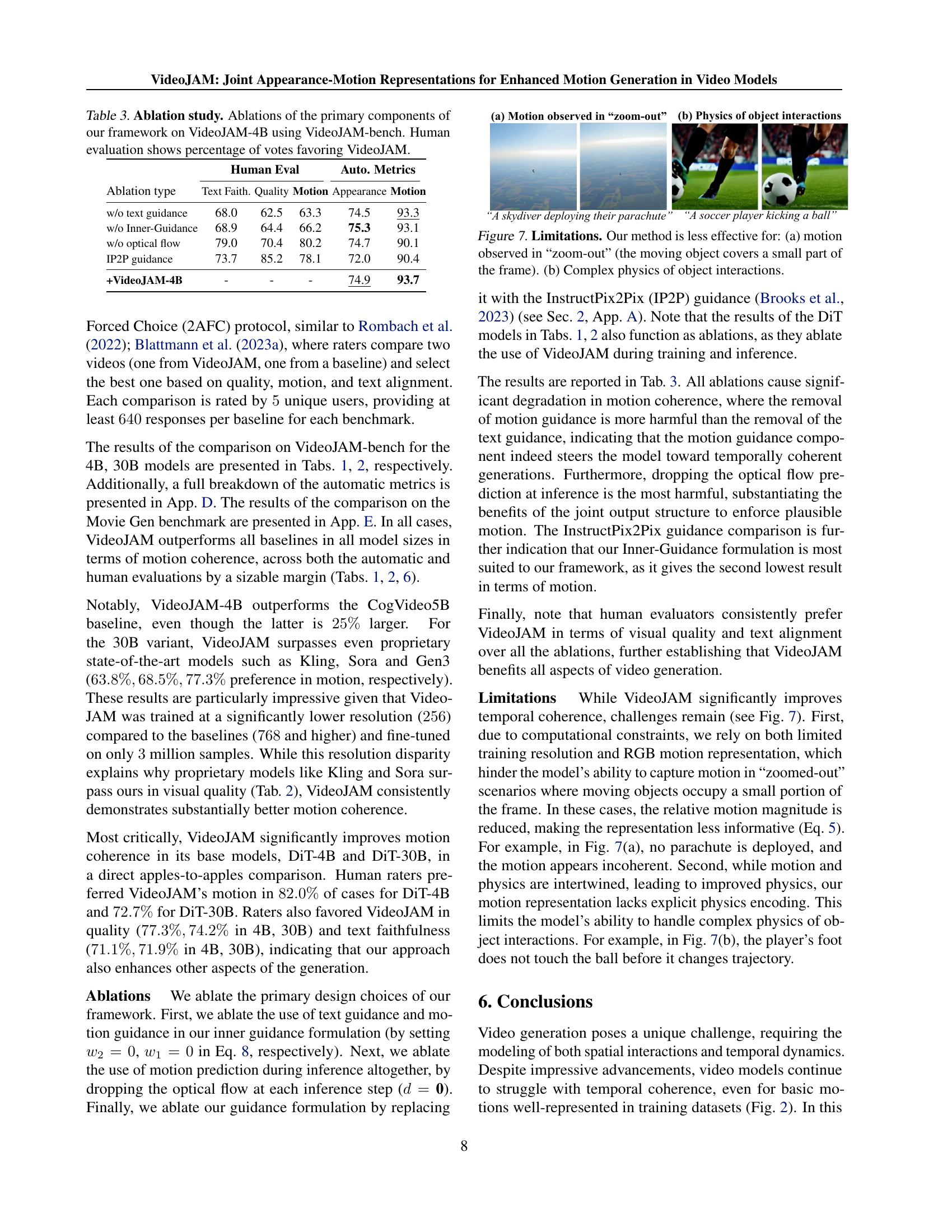
🔼 Figure 7 demonstrates the limitations of the VideoJAM model. Specifically, it shows that VideoJAM’s performance is reduced when the motion is observed from a distance where the moving object occupies only a small portion of the frame (a ‘zoom-out’ effect). This limitation is due to the lower resolution of motion representation at inference time. The figure also highlights the model’s difficulty with complex physical interactions between objects, illustrating that the model struggles to accurately represent realistic interactions, such as a soccer player kicking a ball.
read the caption
Figure 7: Limitations. Our method is less effective for: (a) motion observed in “zoom-out” (the moving object covers a small part of the frame). (b) Complex physics of object interactions.

🔼 This figure shows the results of an experiment designed to understand how different timesteps in the video generation process affect the final output. Three sets of videos were noised at timesteps 20, 60, and 80, then the generation process was continued. The figure shows the appearance and motion of the video at these different timesteps. The results indicate that by timestep 60, the coarse motion and overall structure of the generated video have largely been determined, while finer details continue to be refined in subsequent steps.
read the caption
Figure 8: Qualitative motivation. We noise input videos to different timesteps (20,60,8020608020,60,8020 , 60 , 80) and continue the generation. By step 60606060, the video’s coarse motion and structure are mostly determined.
More on tables
| Human Eval | Auto. Metrics | ||||
| Method | Text Faith. | Quality | Motion | Appearance | Motion |
| CogVideo5B | 73.4 | 71.9 | 85.9 | 71.9 | 90.1 |
| RunWay Gen3 | 72.2 | 76.6 | 77.3 | 73.2 | 92.0 |
| Mochi | 56.1 | 65.6 | 74.2 | 69.9 | 89.7 |
| Sora | 56.3 | 51.7 | 68.5 | 75.4 | 91.7 |
| Kling 1.5 | 51.8 | 45.9 | 63.8 | 76.8 | 87.1 |
| DiT-30B | 71.9 | 74.2 | 72.7 | 72.4 | 88.1 |
| +VideoJAM | - | - | - | 73.4 | 92.4 |
🔼 This table presents a quantitative comparison of the VideoJAM-30B model against several state-of-the-art video generation models on the VideoJAM-bench benchmark. The benchmark specifically targets motion coherence in generated videos. The comparison includes both human evaluation (percentage of votes favoring VideoJAM over competing models for aspects like text faithfulness, quality, and motion) and automatic metrics from VBench (measuring various aspects of video generation quality, including motion and appearance).
read the caption
Table 2: Comparison of VideoJAM-30B with prior work on VideoJAM-bench. Human evaluation shows percentage of votes favoring VideoJAM; automatic metrics use VBench.
| Human Eval | Auto. Metrics | ||||
|---|---|---|---|---|---|
| Ablation type | Text Faith. | Quality | Motion | Appearance | Motion |
| w/o text guidance | 68.0 | 62.5 | 63.3 | 74.5 | 93.3 |
| w/o Inner-Guidance | 68.9 | 64.4 | 66.2 | 75.3 | 93.1 |
| w/o optical flow | 79.0 | 70.4 | 80.2 | 74.7 | 90.1 |
| IP2P guidance | 73.7 | 85.2 | 78.1 | 72.0 | 90.4 |
| +VideoJAM-4B | - | - | - | 74.9 | 93.7 |
🔼 This table presents the results of an ablation study conducted on the VideoJAM-4B model using the VideoJAM-bench benchmark. The study investigates the impact of various components of the VideoJAM framework on the model’s performance. Specifically, it examines the effects of removing text guidance, Inner-Guidance, the optical flow component, and replacing Inner-Guidance with the InstructPix2Pix (IP2P) guidance. The results, evaluated through both automatic metrics (using VBench) and human evaluation (percentage of votes favoring VideoJAM), show the contribution of each component to the model’s motion coherence and overall quality. Lower scores indicate less preference for the VideoJAM model compared to the ablation variants.
read the caption
Table 3: Ablation study. Ablations of the primary components of our framework on VideoJAM-4B using VideoJAM-bench. Human evaluation shows percentage of votes favoring VideoJAM.
| Appearance Metrics | Motion Metrics | |||||
|---|---|---|---|---|---|---|
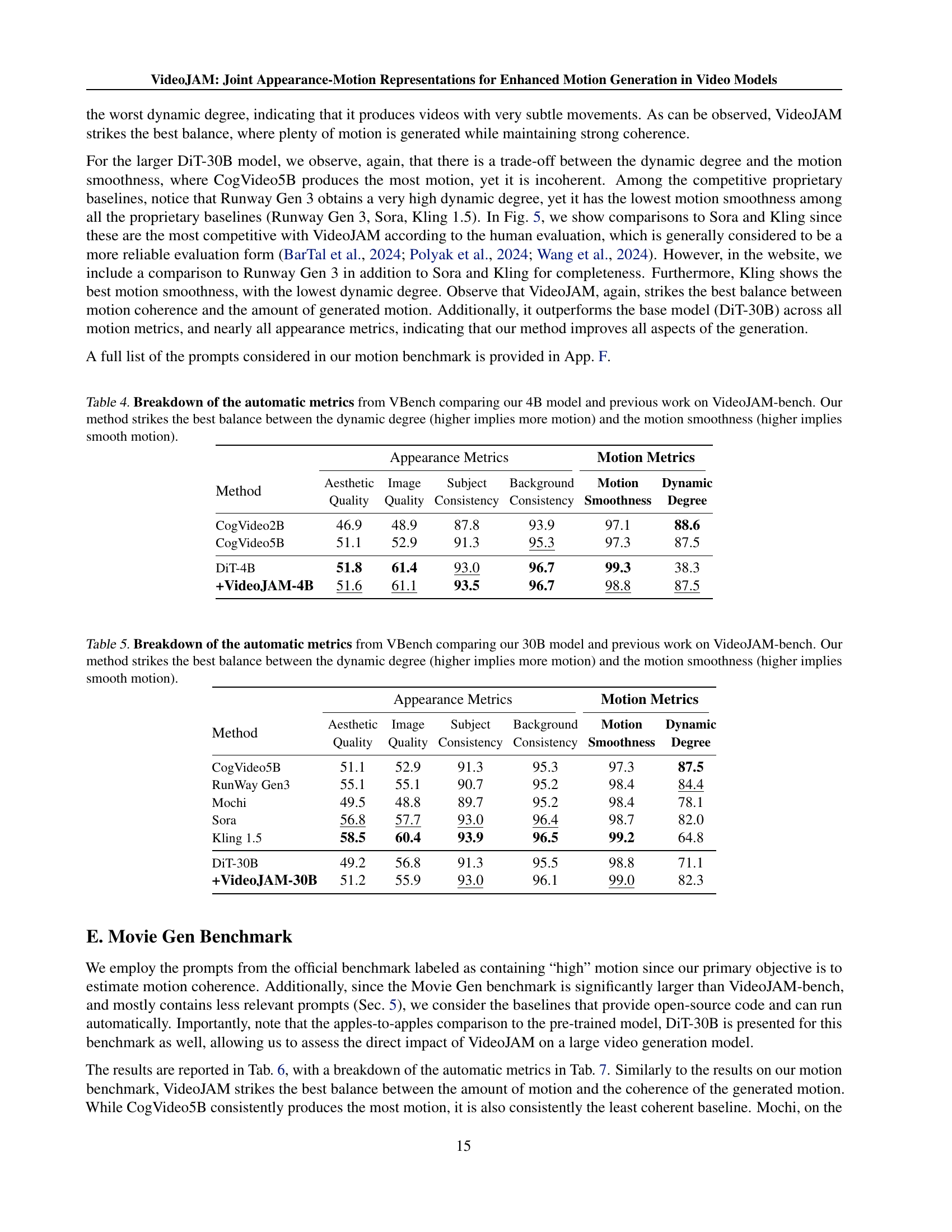
| Method | Aesthetic | Image | Subject | Background | Motion | Dynamic |
| Quality | Quality | Consistency | Consistency | Smoothness | Degree | |
| CogVideo2B | 46.9 | 48.9 | 87.8 | 93.9 | 97.1 | 88.6 |
| CogVideo5B | 51.1 | 52.9 | 91.3 | 95.3 | 97.3 | 87.5 |
| DiT-4B | 51.8 | 61.4 | 93.0 | 96.7 | 99.3 | 38.3 |
| +VideoJAM-4B | 51.6 | 61.1 | 93.5 | 96.7 | 98.8 | 87.5 |
🔼 Table 4 presents a detailed breakdown of the automatic metrics generated by VBench, a tool used to evaluate video generation models. The metrics are categorized into appearance and motion qualities. Appearance is assessed by aesthetic quality, image quality, subject consistency, and background consistency. Motion quality is evaluated using motion smoothness and dynamic degree scores. The table compares the performance of the VideoJAM-4B model against other existing models on the VideoJAM-bench benchmark. The results highlight VideoJAM-4B’s ability to achieve the optimal balance between the amount of motion (dynamic degree) and the coherence of that motion (smoothness).
read the caption
Table 4: Breakdown of the automatic metrics from VBench comparing our 4B model and previous work on VideoJAM-bench. Our method strikes the best balance between the dynamic degree (higher implies more motion) and the motion smoothness (higher implies smooth motion).
| Appearance Metrics | Motion Metrics | |||||
| Method | Aesthetic | Image | Subject | Background | Motion | Dynamic |
| Quality | Quality | Consistency | Consistency | Smoothness | Degree | |
| CogVideo5B | 51.1 | 52.9 | 91.3 | 95.3 | 97.3 | 87.5 |
| RunWay Gen3 | 55.1 | 55.1 | 90.7 | 95.2 | 98.4 | 84.4 |
| Mochi | 49.5 | 48.8 | 89.7 | 95.2 | 98.4 | 78.1 |
| Sora | 56.8 | 57.7 | 93.0 | 96.4 | 98.7 | 82.0 |
| Kling 1.5 | 58.5 | 60.4 | 93.9 | 96.5 | 99.2 | 64.8 |
| DiT-30B | 49.2 | 56.8 | 91.3 | 95.5 | 98.8 | 71.1 |
| +VideoJAM-30B | 51.2 | 55.9 | 93.0 | 96.1 | 99.0 | 82.3 |
🔼 This table presents a detailed breakdown of automatic metrics from the VBench benchmark, comparing the performance of the VideoJAM-30B model against other state-of-the-art video generation models on the VideoJAM-bench dataset. The metrics are categorized into appearance metrics (aesthetic quality, image quality, subject consistency, background consistency) and motion metrics (motion smoothness, dynamic degree). The dynamic degree score indicates the amount of motion in the generated video, while motion smoothness measures the coherence and realism of that motion. The table highlights that VideoJAM-30B achieves the optimal balance between these two factors: generating videos with a significant amount of motion while maintaining high levels of smoothness and coherence, surpassing other models which either lack motion or exhibit incoherent movement.
read the caption
Table 5: Breakdown of the automatic metrics from VBench comparing our 30B model and previous work on VideoJAM-bench. Our method strikes the best balance between the dynamic degree (higher implies more motion) and the motion smoothness (higher implies smooth motion).
| Human Eval | Auto. Metrics | ||||
|---|---|---|---|---|---|
| Method | Text Faith. | Quality | Motion | Appearance | Motion |
| CogVideo5B | 61.4 | 77.0 | 78.7 | 70.8 | 88.8 |
| Mochi | 53.5 | 59.4 | 69.1 | 70.4 | 85.1 |
| DiT-30B | 60.3 | 64.6 | 66.1 | 70.5 | 87.3 |
| +VideoJAM-30B | - | - | - | 73.7 | 90.8 |
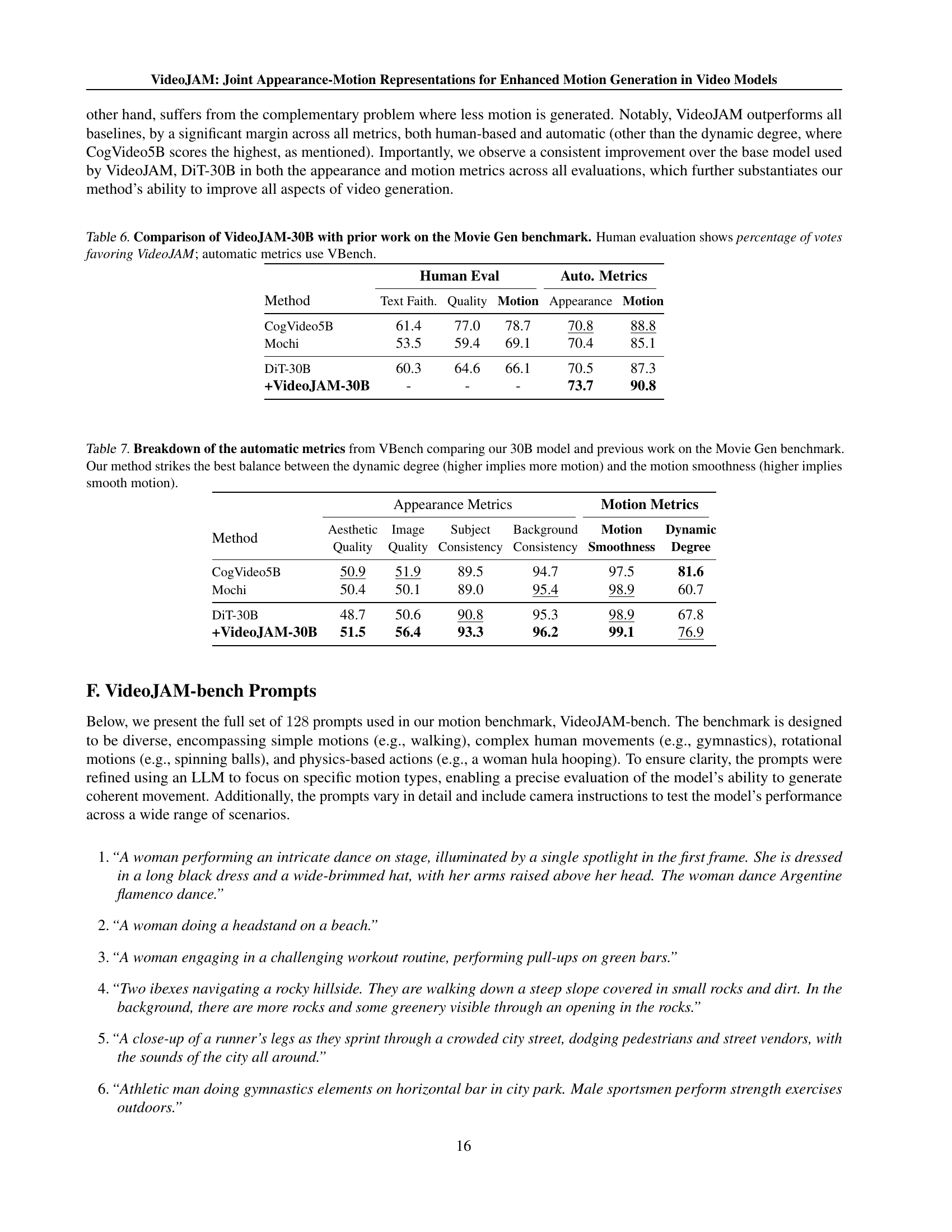
🔼 This table presents a quantitative comparison of VideoJAM-30B’s performance against other state-of-the-art video generation models on the Movie Gen benchmark. The comparison includes both human evaluation (percentage of votes favoring VideoJAM-30B for various aspects of video quality) and automatic evaluation using VBench metrics (assessing text faithfulness, quality, motion, and appearance). This allows for a comprehensive assessment of VideoJAM-30B’s strengths and weaknesses relative to existing methods.
read the caption
Table 6: Comparison of VideoJAM-30B with prior work on the Movie Gen benchmark. Human evaluation shows percentage of votes favoring VideoJAM; automatic metrics use VBench.
| Appearance Metrics | Motion Metrics | |||||
|---|---|---|---|---|---|---|
| Method | Aesthetic | Image | Subject | Background | Motion | Dynamic |
| Quality | Quality | Consistency | Consistency | Smoothness | Degree | |
| CogVideo5B | 50.9 | 51.9 | 89.5 | 94.7 | 97.5 | 81.6 |
| Mochi | 50.4 | 50.1 | 89.0 | 95.4 | 98.9 | 60.7 |
| DiT-30B | 48.7 | 50.6 | 90.8 | 95.3 | 98.9 | 67.8 |
| +VideoJAM-30B | 51.5 | 56.4 | 93.3 | 96.2 | 99.1 | 76.9 |
🔼 Table 7 presents a detailed breakdown of the automatic metrics from the VBench benchmark, focusing on the comparison between VideoJAM-30B and other state-of-the-art models on the Movie Gen dataset. The metrics are categorized into appearance (aesthetic quality, image quality, subject consistency, background consistency) and motion (motion smoothness, dynamic degree) aspects. VideoJAM-30B’s performance is highlighted to demonstrate its ability to achieve the best balance between generating sufficient motion (higher dynamic degree) and maintaining smooth, coherent movement (higher motion smoothness), surpassing other models that either lack sufficient motion or suffer from incoherent movement artifacts.
read the caption
Table 7: Breakdown of the automatic metrics from VBench comparing our 30B model and previous work on the Movie Gen benchmark. Our method strikes the best balance between the dynamic degree (higher implies more motion) and the motion smoothness (higher implies smooth motion).
Full paper#