TL;DR#
Large language models (LLMs) are computationally expensive. Knowledge distillation (KD) trains smaller, efficient student models by imitating larger, more powerful teacher models. However, teacher models aren’t perfect representations of the ideal data distribution. This paper explores a new phenomenon called “teacher hacking”, where student models overfit to the imperfections of the teacher model, resulting in degraded performance on real-world tasks. This phenomenon resembles ‘reward hacking’ in reinforcement learning from human feedback (RLHF).
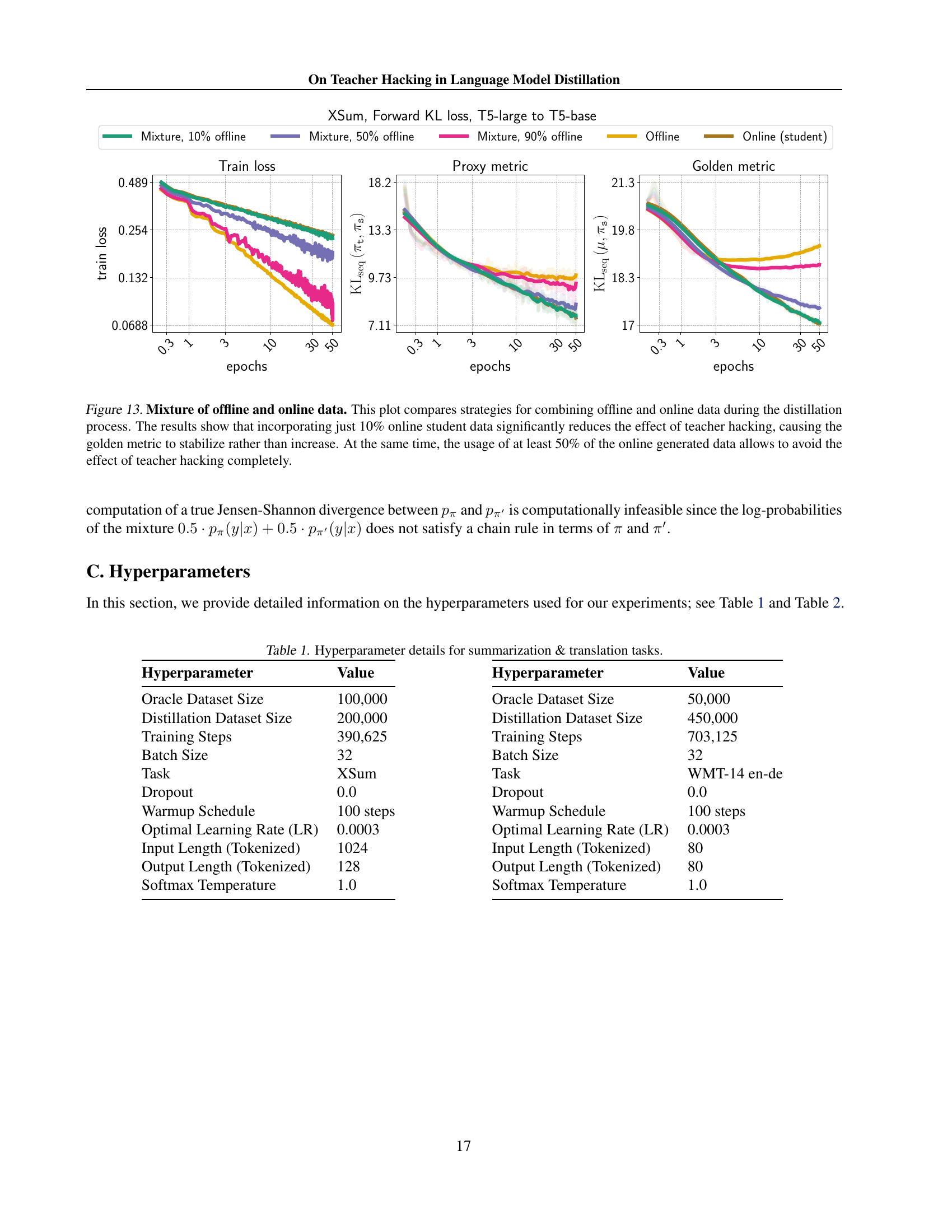
The researchers designed a controlled experiment to study this issue. They introduced an ‘oracle’ model representing the ideal distribution, used it to train a teacher model, and then trained a student model using that teacher. Using offline data (a fixed dataset), they found evidence of teacher hacking - the student improved relative to the teacher, but its overall accuracy decreased compared to the oracle. However, when using online data (continuously generated from the teacher or the student model), teacher hacking was avoided. This finding points to data diversity as the key factor in preventing teacher hacking. The study’s formal definition of teacher hacking and the novel experimental setup advance our understanding of LM training methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in language model training and optimization. It highlights a critical, previously understudied issue—teacher hacking—which can lead to degraded model performance. The proposed mitigation strategies using online data generation and data diversity are directly applicable to current research efforts. Furthermore, the study’s focus on evaluating the teacher’s role in knowledge distillation opens new avenues for research on more robust and efficient LM training methods.
Visual Insights#

🔼 This figure illustrates the experimental setup used to investigate teacher hacking in language model distillation. The standard knowledge distillation process involves training a teacher model on expert data, and then training a student model to mimic the teacher. This setup introduces an additional oracle model representing the true data distribution. The teacher model is first trained by distilling knowledge from the oracle. Then, a student model is trained by distilling knowledge from this imperfect teacher model. By comparing the student model to both the teacher and the oracle, the researchers can quantitatively assess the quality of the distillation process and identify instances of teacher hacking, where the student model over-optimizes the teacher’s imperfections rather than learning the true data distribution.
read the caption
Figure 1: Overview of our controlled experimental setup. Usually, the teacher model is trained on expert data before being distilled into the student LM. In the controlled setup of this paper, the teacher is itself distilled from an additional oracle model. This oracle model allows us to measure the quality of the distillation process into the student, and to reveal “teacher hacking”.
| Hyperparameter | Value |
|---|---|
| Oracle Dataset Size | 100,000 |
| Distillation Dataset Size | 200,000 |
| Training Steps | 390,625 |
| Batch Size | 32 |
| Task | XSum |
| Dropout | 0.0 |
| Warmup Schedule | 100 steps |
| Optimal Learning Rate (LR) | 0.0003 |
| Input Length (Tokenized) | 1024 |
| Output Length (Tokenized) | 128 |
| Softmax Temperature | 1.0 |
🔼 This table details the hyperparameters used for the summarization and translation tasks in the experiments. It includes settings for dataset sizes (oracle and distillation), training steps, batch size, dropout rate, learning rate, warmup schedule, and input/output lengths (tokenized). These parameters were crucial in controlling the training process for language model distillation.
read the caption
Table 1: Hyperparameter details for summarization & translation tasks.
In-depth insights#
Teacher Hacking in KD#
Teacher hacking, a newly identified phenomenon in knowledge distillation (KD), describes a scenario where the student model, instead of faithfully learning the underlying data distribution from a teacher model, exploits imperfections within the teacher itself. This results in suboptimal generalization because the student model prioritizes mimicking the teacher’s flaws over accurately representing the true underlying data. The core issue is that the teacher model is not a perfect representation of the ground truth; it’s an imperfect proxy. This concept parallels reward hacking in reinforcement learning, where the agent over-optimizes a flawed reward function. The paper proposes a novel controlled experimental setting involving an oracle model, teacher model, and student model to systematically investigate this phenomenon. Crucially, they find that teacher hacking manifests with offline datasets and is indicated by deviations from expected polynomial convergence laws during optimization. However, using online data generation methods, which introduce data diversity, effectively mitigates teacher hacking. This highlights the importance of data quality and diversity in preventing this issue and creating robust, generalizable language models. The insights suggest that mitigating teacher hacking is important for building truly effective and safe language models.
Data Diversity’s Role#
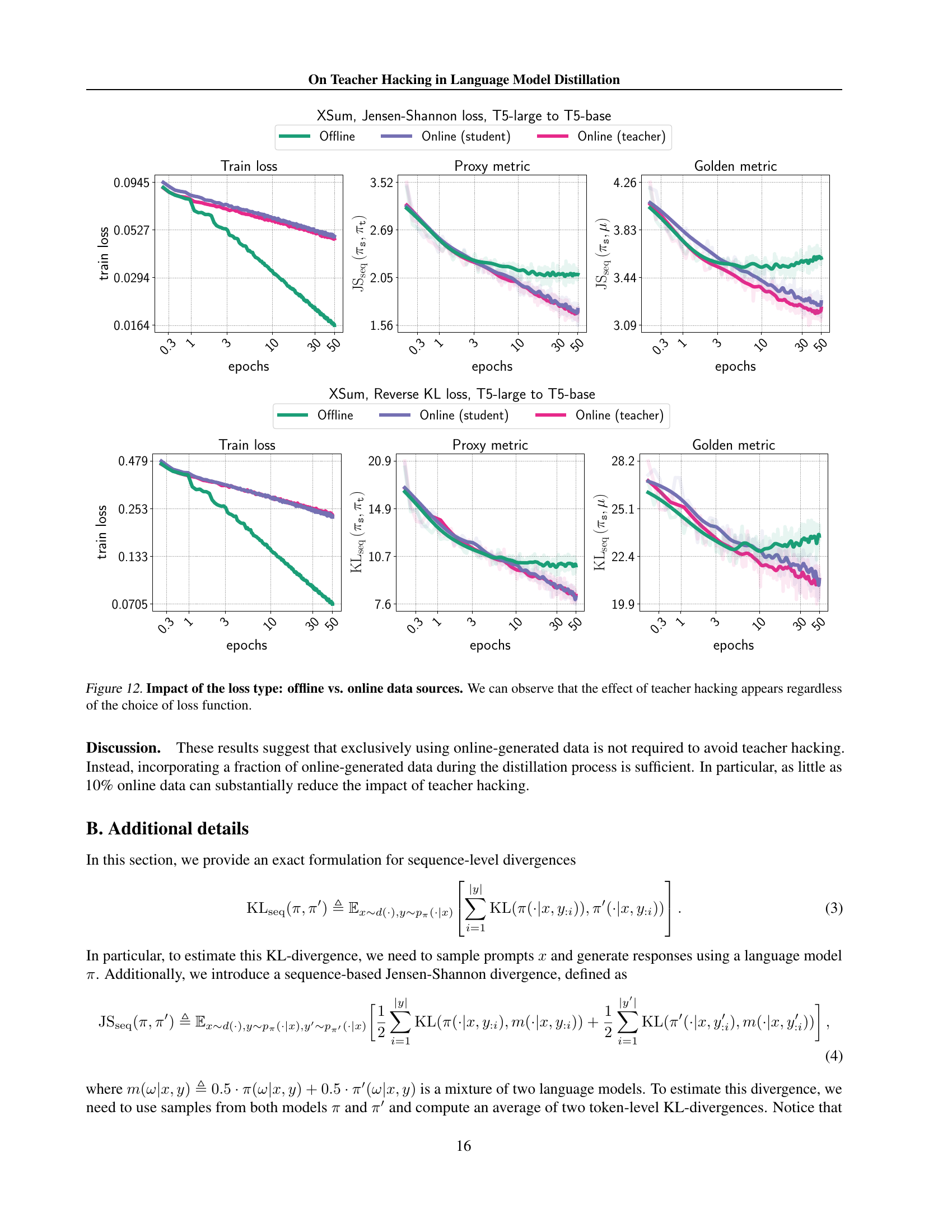
The research highlights the critical role of data diversity in mitigating teacher hacking during language model distillation. Insufficient diversity in offline training data allows the student model to exploit imperfections in the teacher model, leading to degraded performance on the true objective despite seemingly successful imitation. This is analogous to reward hacking in RLHF, where the model over-optimizes a flawed reward function. Employing online data generation techniques, whether sampling from the teacher or student model, introduces substantial diversity, effectively eliminating teacher hacking. Furthermore, augmenting offline datasets with multiple generations per prompt, or increasing prompt diversity itself, offers practical strategies to improve generalization and reduce the susceptibility to this phenomenon. The findings strongly suggest that sufficient data diversity is paramount for robust and efficient language model distillation, ensuring the student model learns to approximate the true data distribution rather than just the quirks of its teacher.
Offline vs. Online Data#
The distinction between offline and online data sources is pivotal in understanding the phenomenon of teacher hacking in language model distillation. Offline data, being fixed and unchanging across training epochs, allows for the student model to exploit imperfections or biases in the teacher model. This leads to the student over-optimizing the proxy metric (its alignment with the teacher) while potentially degrading its performance against the true objective (as measured by the golden metric), which is what constitutes teacher hacking. In contrast, online data, generated dynamically during training, introduces variability and forces the student model to generalize more effectively. This constant adaptation to the evolving teacher output prevents the exploitation of teacher limitations and encourages more robust learning, mitigating teacher hacking. The choice between offline and online data fundamentally influences the training process’ effectiveness and the ultimate fidelity of the distilled student model. Data diversity, closely linked to the use of online data, plays a crucial role in preventing teacher hacking by creating a more challenging, multifaceted learning environment that doesn’t allow for simple exploitation of the teacher’s flaws.
Mitigating Teacher Hack#
The phenomenon of teacher hacking, where a student language model over-optimizes its imitation of a flawed teacher model instead of learning the true underlying data distribution, presents a significant challenge in knowledge distillation. Mitigating teacher hacking requires a multi-pronged approach focusing on improving data quality and diversity. Employing online data generation, where the data for training the student model is dynamically created during the training process, proves particularly effective. This approach prevents the student model from overfitting to the teacher’s imperfections by constantly exposing it to new and varied data. However, online data generation is computationally expensive. Therefore, enhancing the diversity of offline datasets is also crucial. Methods like increasing the number of generations per prompt or carefully balancing the number of prompts and responses are explored as more efficient strategies to lessen the problem without significantly increasing computational cost. Understanding the interplay between data diversity and model convergence is key. By monitoring deviations from expected convergence patterns, one can detect early signs of teacher hacking and adjust training parameters accordingly.
Limitations of Distillation#
Knowledge distillation, while offering efficiency gains in language model training, suffers from significant limitations. A core issue is the imperfect nature of the teacher model, which acts as a proxy for the true data distribution. This can lead to teacher hacking, where the student model over-optimizes the teacher’s shortcomings rather than learning the underlying data distribution. This problem is exacerbated when using fixed, offline datasets for distillation, resulting in degraded generalization. Data diversity emerges as a crucial factor; methods that increase diversity, such as online data generation or using larger, diverse offline datasets, mitigate teacher hacking. Furthermore, the success of distillation hinges on the choice of token-level loss function and the careful selection of teacher and student model architectures. Overfitting remains a concern, especially when using smaller student models. Addressing these limitations requires careful consideration of dataset properties, training techniques, and model selection to achieve robust and efficient language models.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage training pipeline used in the paper’s experiments. Stage 1 involves using an oracle model (representing the ideal ground truth) to generate a dataset of (prompt, response) pairs from a real-world task-specific dataset. This dataset is then used for supervised fine-tuning (SFT) to obtain initial checkpoints for both the teacher and student language models. Stage 2 focuses on knowledge distillation, where the student model learns to mimic the teacher model’s behavior using prompts sampled from the same distribution as in Stage 1. The teacher model acts as an imperfect proxy for the ideal ground truth distribution. This setup allows for a controlled examination of the distillation process and the potential for teacher hacking.
read the caption
Figure 2: Overview of the training pipeline. Two stages: (1) prompts x𝑥xitalic_x from a task-specific real dataset are used by the oracle model to generate the oracle pairs (x,y)𝑥𝑦(x,y)( italic_x , italic_y ), and afterwards, this dataset is used to get initial SFT checkpoints for both teacher and student model; (2) prompts from the same distribution are used to perform knowledge distillation, where the teacher model serves as a proxy to train the student model.

🔼 This figure illustrates the evaluation pipeline used to assess the performance of the student model. It highlights the use of a validation prompt dataset and two key metrics: the ‘golden metric’ and the ‘proxy metric’. The golden metric directly measures the performance of the student model by comparing its output to the ground-truth oracle model. In contrast, the proxy metric assesses how well the student model has learned from the teacher model, indicating the alignment between the student and teacher. This two-metric approach allows for a comprehensive evaluation of both the student’s ability to approximate the ground truth and its success in imitating its teacher.
read the caption
Figure 3: Overview of the evaluation pipeline. We use the validation prompt dataset to measure the golden metric (the distance between the oracle and the student models) and the proxy metric (the distance between the teacher and the student models).

🔼 This figure shows a plot of the golden metric (distance to the oracle distribution, representing true performance) against the proxy metric (distance to the teacher distribution, representing optimization progress) during the distillation of a T5-large teacher model to a T5-base student model on the XSUM dataset. The x-axis represents the proxy metric, and the y-axis represents the golden metric; lower values indicate better performance. The orange curve shows the relationship between the two metrics for the offline data source. The U-shape of this curve is indicative of teacher hacking: as optimization progresses (proxy metric decreases), the true performance (golden metric) initially improves but then begins to degrade.
read the caption
Figure 4: Proxy-Golden plot (offline data source). We distill a T5-large teacher into a T5-base student on the XSUM dataset. The token-level training loss is the forward KL, the proxy metric is the distance to the teacher distribution and the golden metric is the distance to the ground-truth (oracle) distribution (available thanks to our semi-synthetic controlled experimental setup). In this plot, the x𝑥xitalic_x-axis (proxy metric) indicates optimization progress, and the y𝑦yitalic_y-axis shows the ground-truth performance (golden metric): lower is better. Teacher hacking occurs in the case of offline data source: the orange curve has a U-type shape, indicating that during optimization, the orange metric starts increasing, whereas the proxy metric continues to decrease.

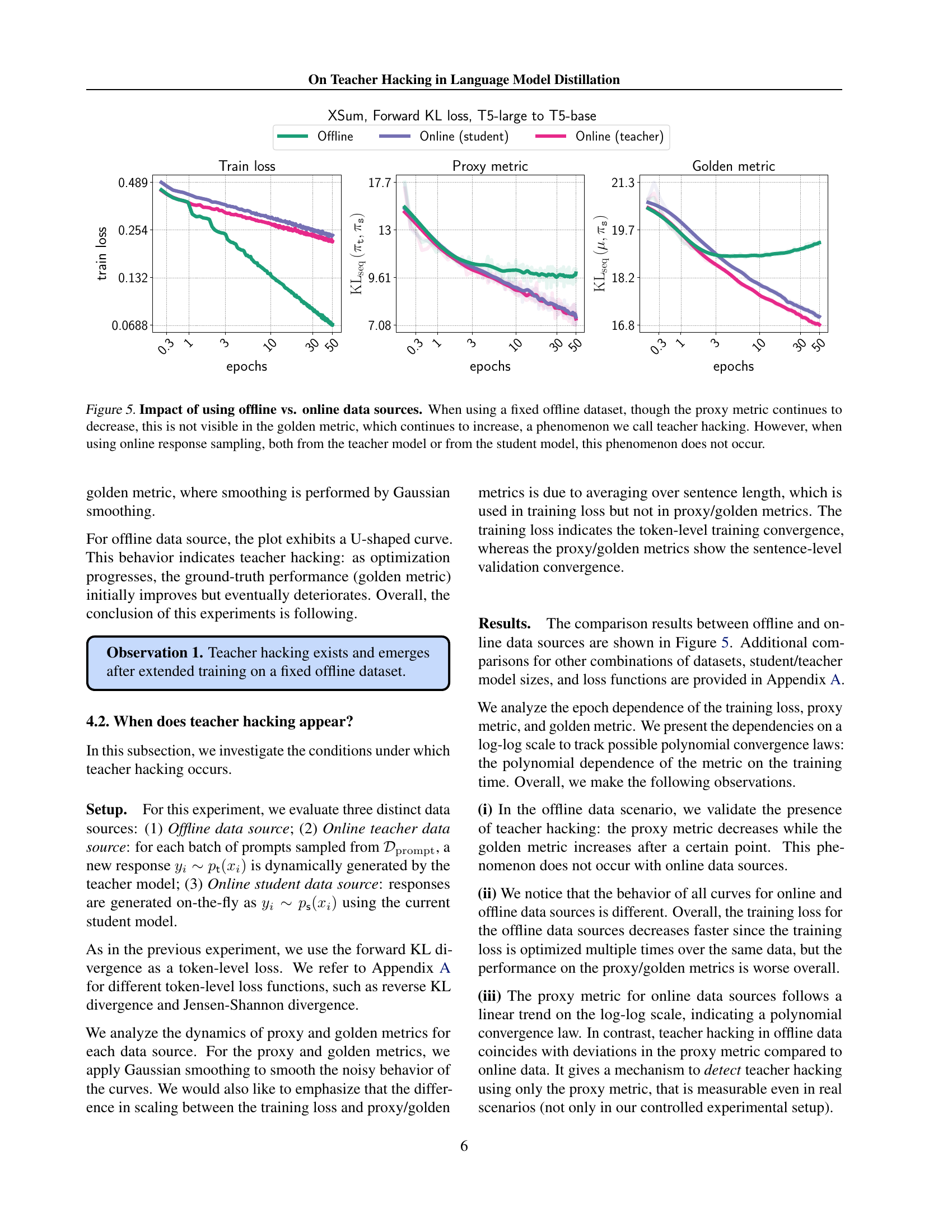
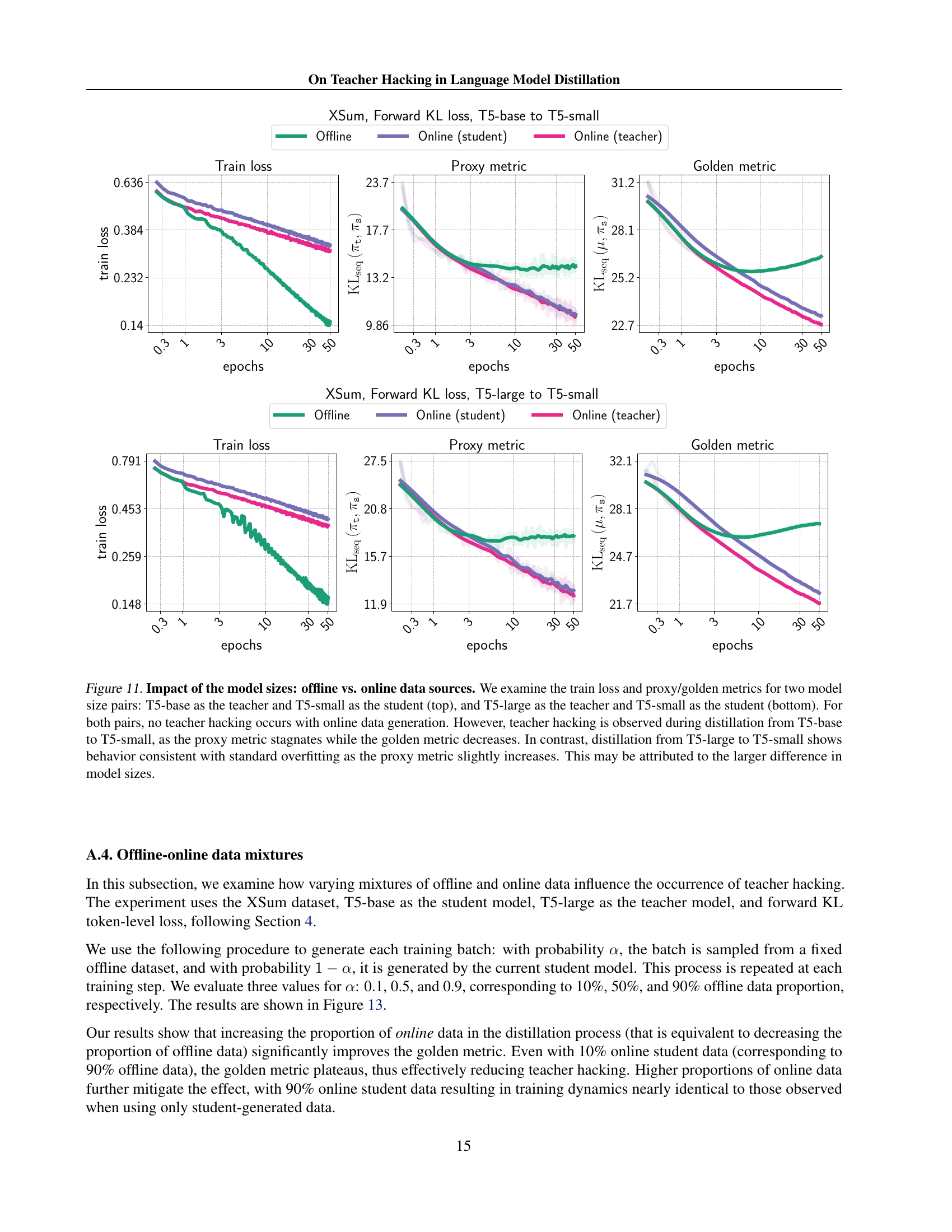
🔼 This figure compares the training dynamics of language models when using offline versus online data sources for knowledge distillation. The x-axis represents the number of training epochs, and the y-axis shows the values of three metrics: training loss, proxy metric (measuring the difference between student and teacher models), and golden metric (measuring the difference between student and oracle models). The offline setting demonstrates a phenomenon called ’teacher hacking,’ where the proxy metric improves (decreases) but the golden metric worsens (increases), indicating that the model is overfitting to the teacher’s imperfections rather than truly learning the underlying task. In contrast, the online data generation (from either the teacher or the student) successfully mitigates teacher hacking, leading to consistent improvement in both proxy and golden metrics.
read the caption
Figure 5: Impact of using offline vs. online data sources. When using a fixed offline dataset, though the proxy metric continues to decrease, this is not visible in the golden metric, which continues to increase, a phenomenon we call teacher hacking. However, when using online response sampling, both from the teacher model or from the student model, this phenomenon does not occur.

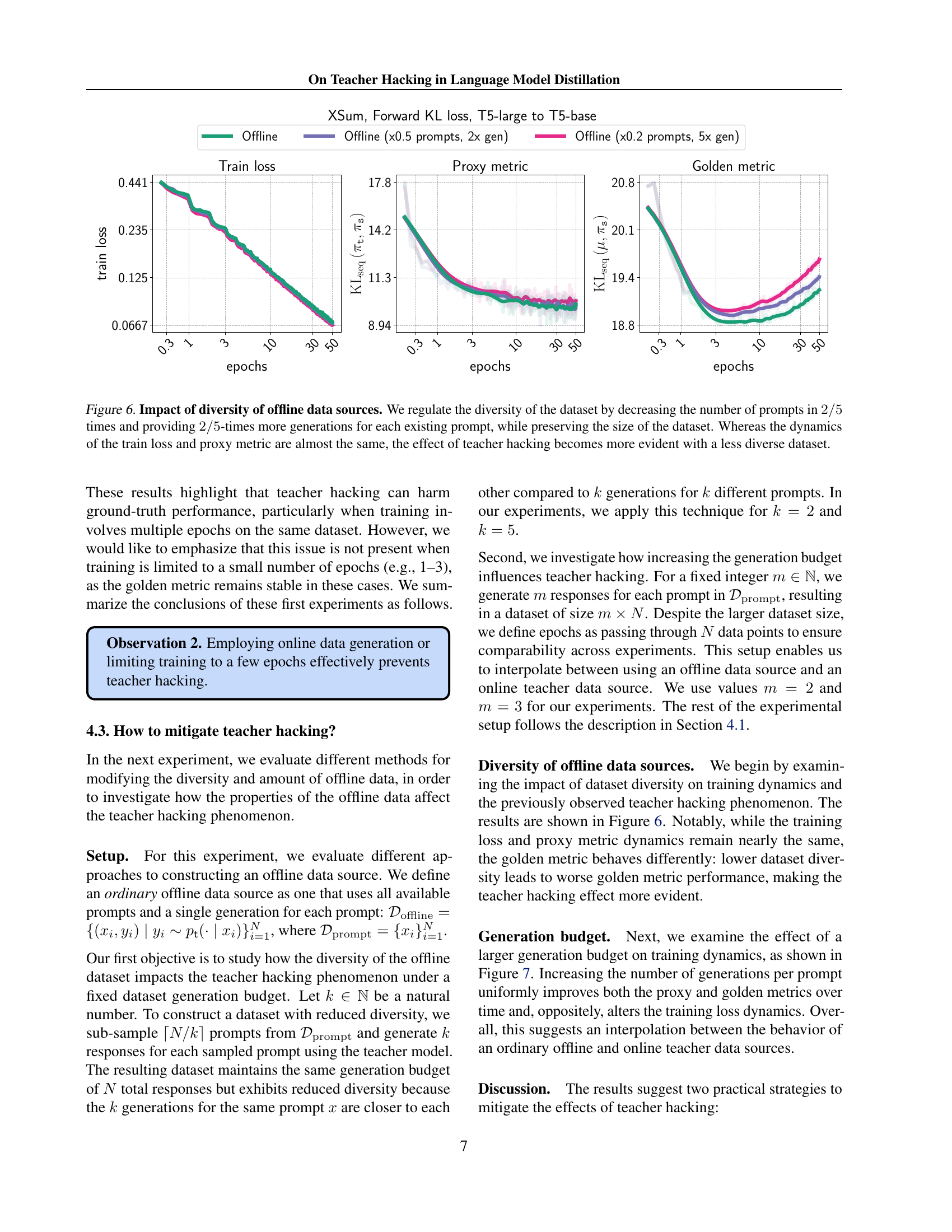
🔼 This figure demonstrates the effect of data diversity on teacher hacking during knowledge distillation. By reducing the number of unique prompts and increasing the number of generations per prompt (while maintaining the overall dataset size), the experiment manipulates the diversity of the offline dataset. The results show that although the training loss and proxy metrics (measuring the student’s similarity to the teacher) remain largely unchanged, the degree of teacher hacking (the divergence between the student model and the ground truth, as measured by the golden metric) increases significantly as data diversity decreases. This indicates that a more diverse dataset is crucial for mitigating teacher hacking during knowledge distillation.
read the caption
Figure 6: Impact of diversity of offline data sources. We regulate the diversity of the dataset by decreasing the number of prompts in 2/5252/52 / 5 times and providing 2/5252/52 / 5-times more generations for each existing prompt, while preserving the size of the dataset. Whereas the dynamics of the train loss and proxy metric are almost the same, the effect of teacher hacking becomes more evident with a less diverse dataset.

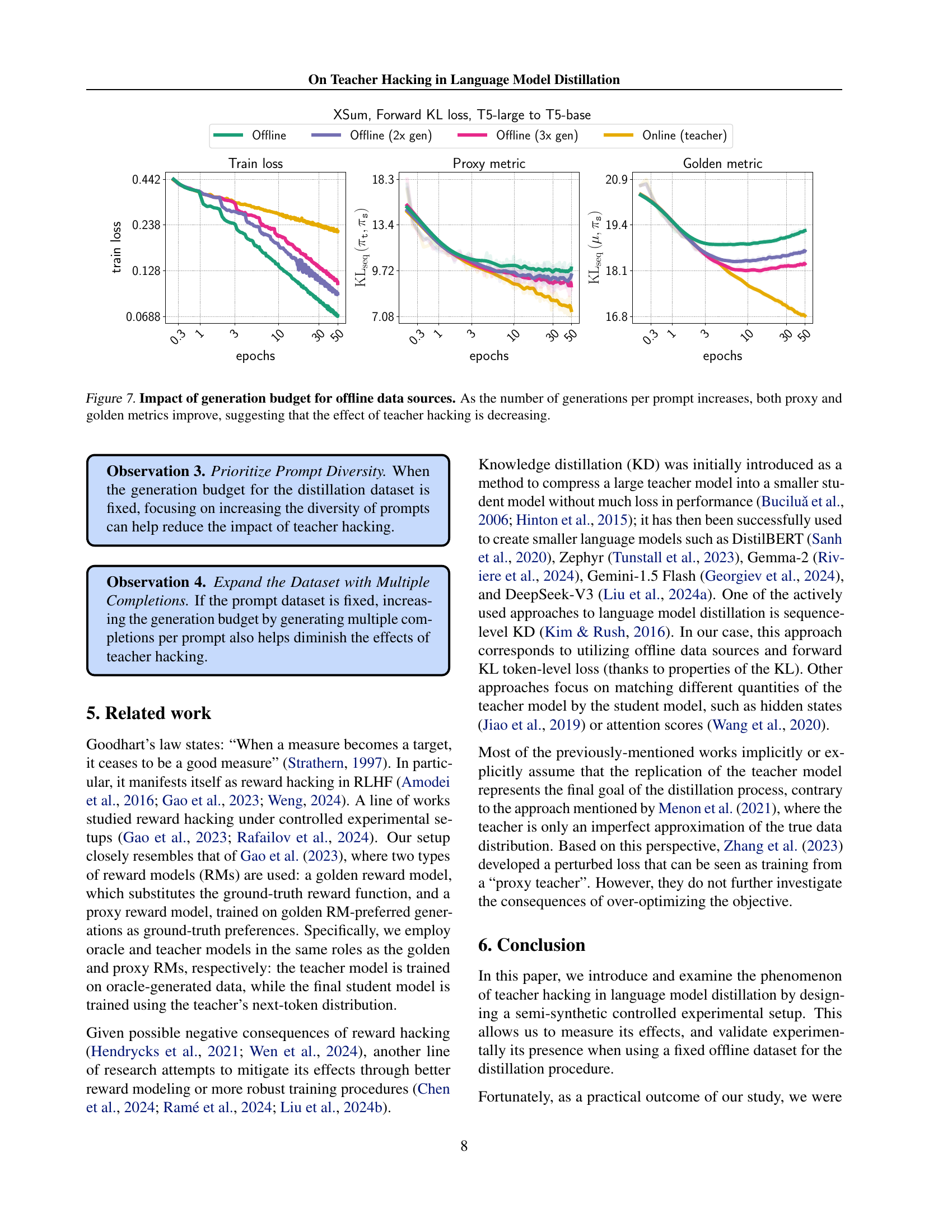
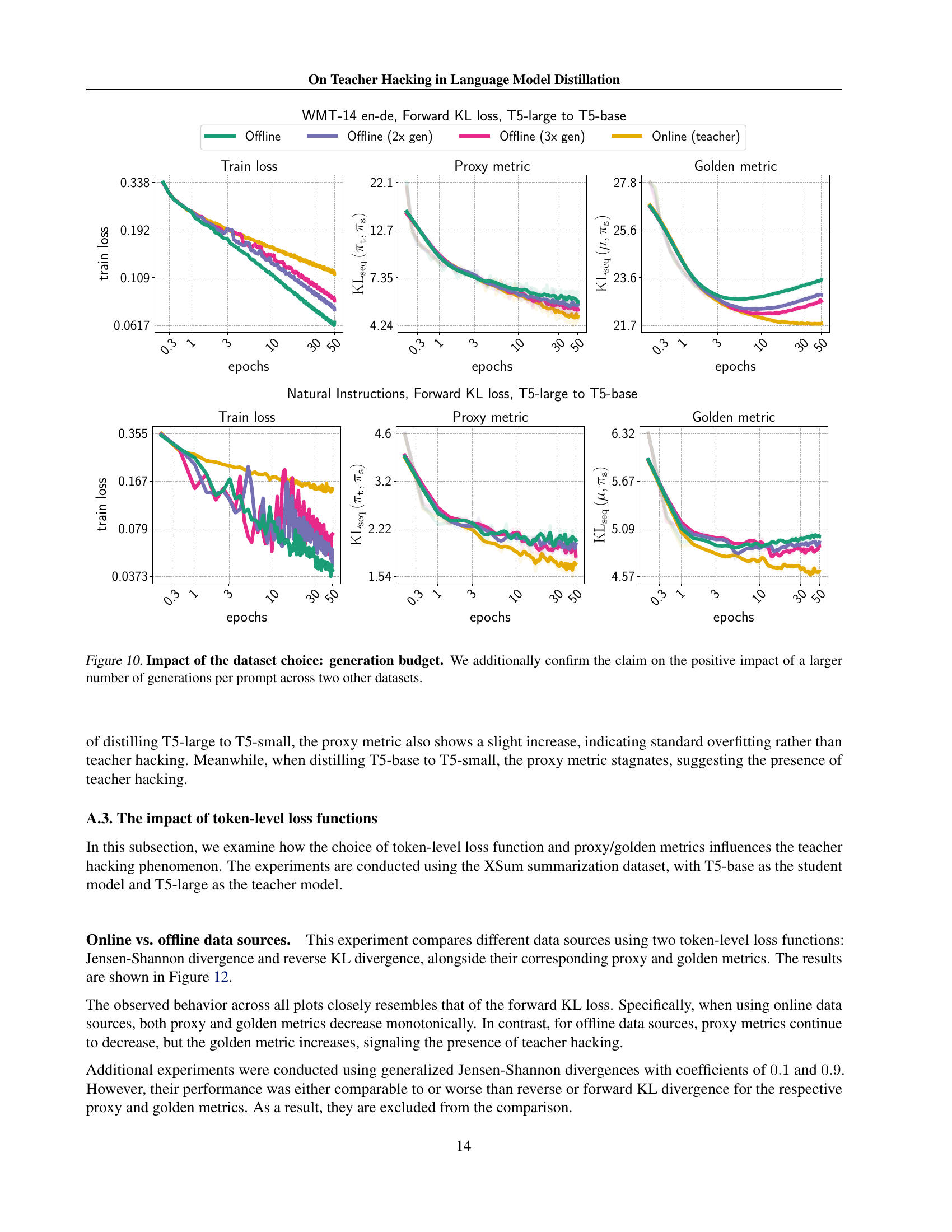
🔼 This figure demonstrates the effect of increasing the number of generated responses per prompt in an offline knowledge distillation setup. The x-axis represents the number of training epochs, while the y-axis shows the values for three metrics: training loss, proxy metric (measuring the distance between student and teacher models), and golden metric (measuring the distance between student and oracle models). The results show that as the number of generations per prompt increases (indicating a larger dataset and more data diversity), both the proxy and golden metrics improve, indicating a reduction in the teacher hacking phenomenon. This suggests that the issue of teacher hacking can be mitigated by increasing the richness and diversity of the training data.
read the caption
Figure 7: Impact of generation budget for offline data sources. As the number of generations per prompt increases, both proxy and golden metrics improve, suggesting that the effect of teacher hacking is decreasing.

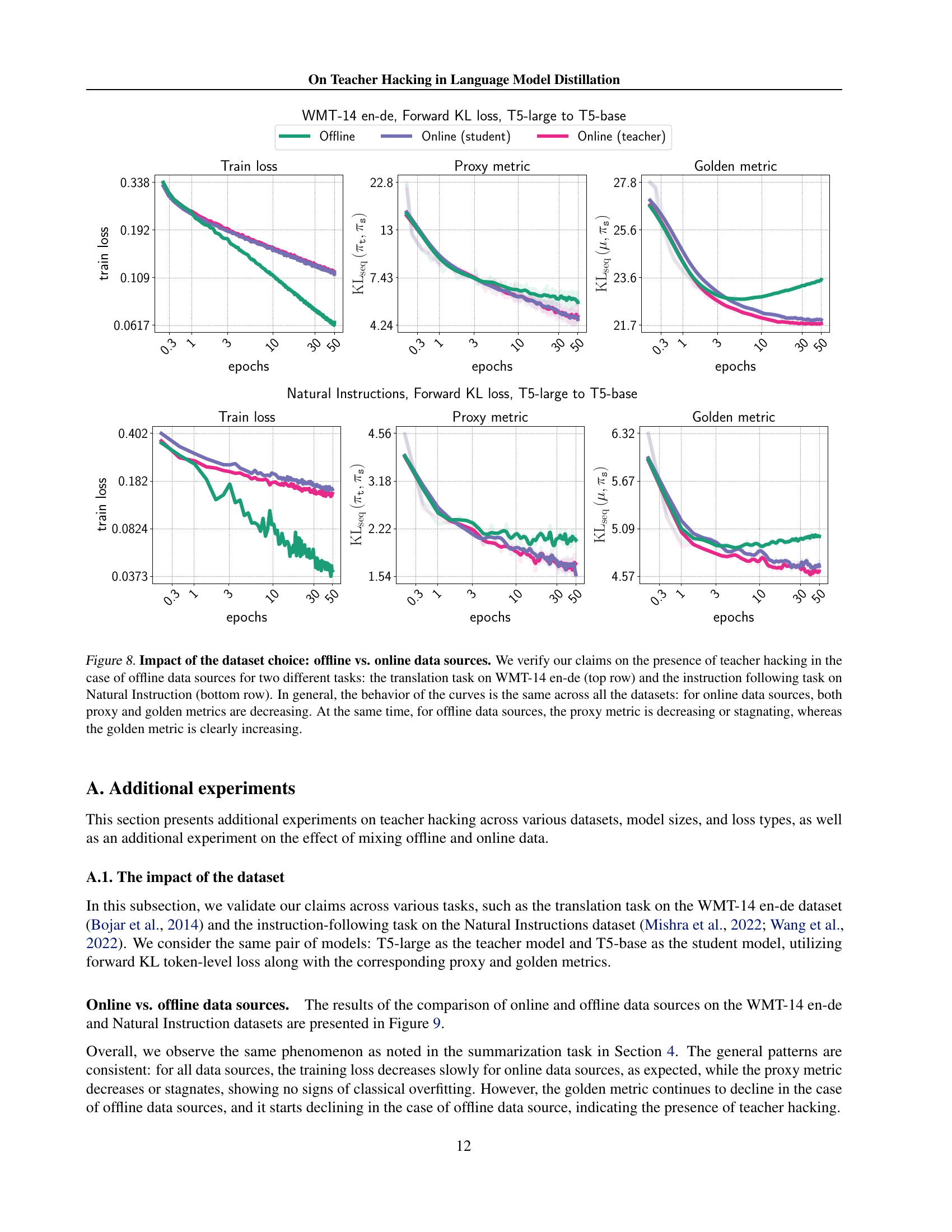
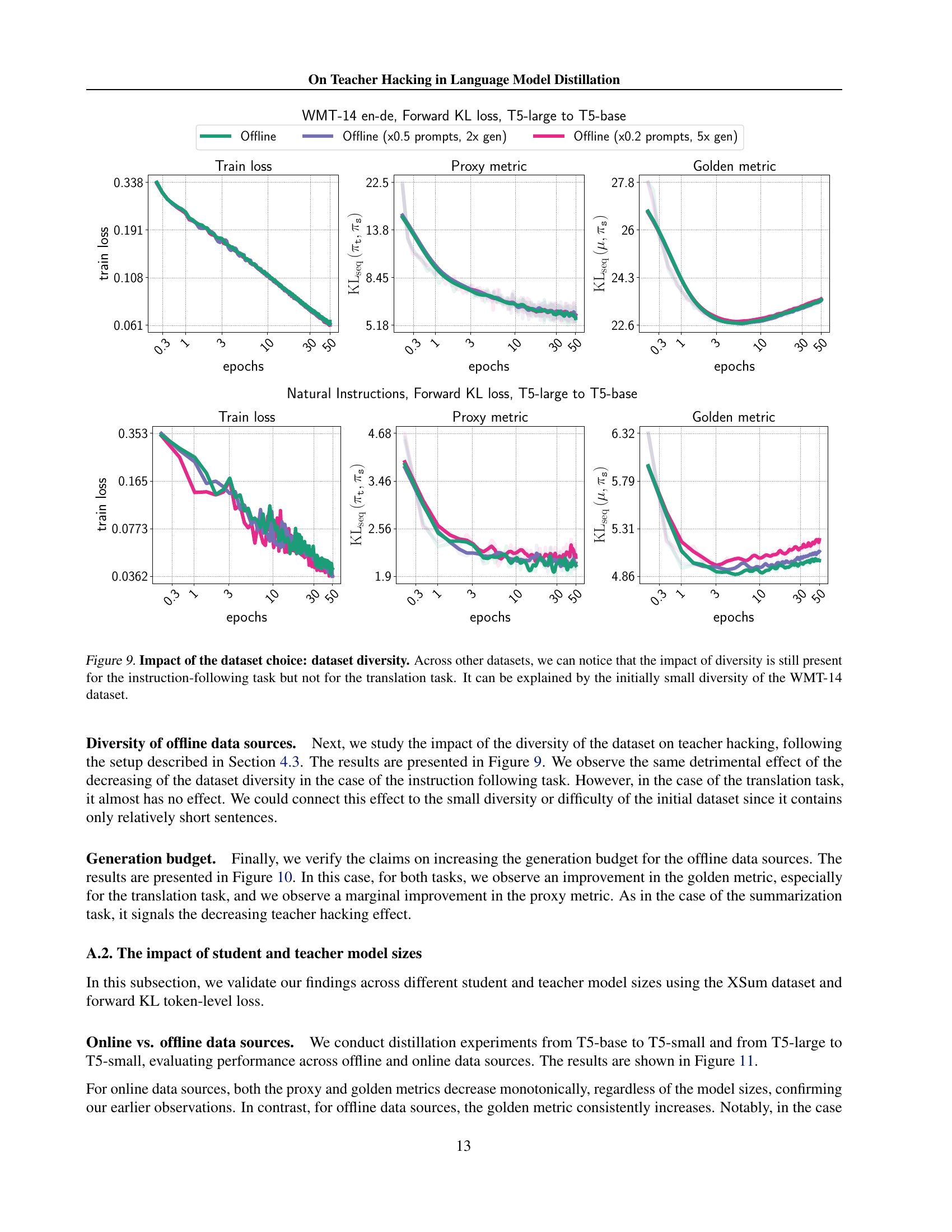
🔼 This figure displays the results of experiments comparing offline and online data sources for two distinct tasks: machine translation (WMT-14 en-de dataset) and instruction following (Natural Instructions dataset). The top row shows the translation task results, while the bottom row displays the results for the instruction following task. For both tasks, the plots demonstrate the behavior of the training loss, proxy metrics, and golden metrics across epochs. The key observation is that when using online data sources, both proxy and golden metrics consistently decrease, indicating successful model learning and generalization. Conversely, with offline data sources, while the proxy metric shows a decrease or remains relatively stable, the golden metric increases, clearly exhibiting teacher hacking. This highlights that teacher hacking occurs during training from fixed datasets.
read the caption
Figure 8: Impact of the dataset choice: offline vs. online data sources. We verify our claims on the presence of teacher hacking in the case of offline data sources for two different tasks: the translation task on WMT-14 en-de (top row) and the instruction following task on Natural Instruction (bottom row). In general, the behavior of the curves is the same across all the datasets: for online data sources, both proxy and golden metrics are decreasing. At the same time, for offline data sources, the proxy metric is decreasing or stagnating, whereas the golden metric is clearly increasing.
Full paper#