TL;DR#
Current methods for enabling Large Language Models (LLMs) to perform complex reasoning using “Long Chain of Thought” (LongCoT) heavily rely on knowledge distillation from existing, powerful models or expensive human annotations. This creates bottlenecks in the systematic development and scalability of LongCoT abilities. Furthermore, many existing approaches narrowly focus on math or coding tasks, limiting their generalizability.
This paper introduces BOLT (Bootstrap Long Chain-of-Thought), a novel approach that enables LLMs to exhibit LongCoT reasoning without distillation or extensive human annotation. BOLT involves a three-stage process: 1) bootstrapping LongCoT data using in-context learning on a standard instruct model; 2) supervised fine-tuning on the generated data to adapt the model; 3) online training to refine LongCoT capabilities further. The experiments demonstrate the efficiency of this approach with only 10 examples used in the bootstrapping stage and achieves remarkable results across diverse benchmarks, surpassing previous methods and showcasing scalability across model sizes (7B, 8B, 70B).
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel approach to enable LLMs to generate long chain-of-thought reasoning without relying on distillation or expensive human annotations. This addresses a major limitation in current research, which often relies on these methods, opening new avenues for developing LongCoT reasoning capabilities in LLMs more efficiently and systematically. The findings could significantly impact the development of more sophisticated and generalizable reasoning abilities in LLMs.
Visual Insights#

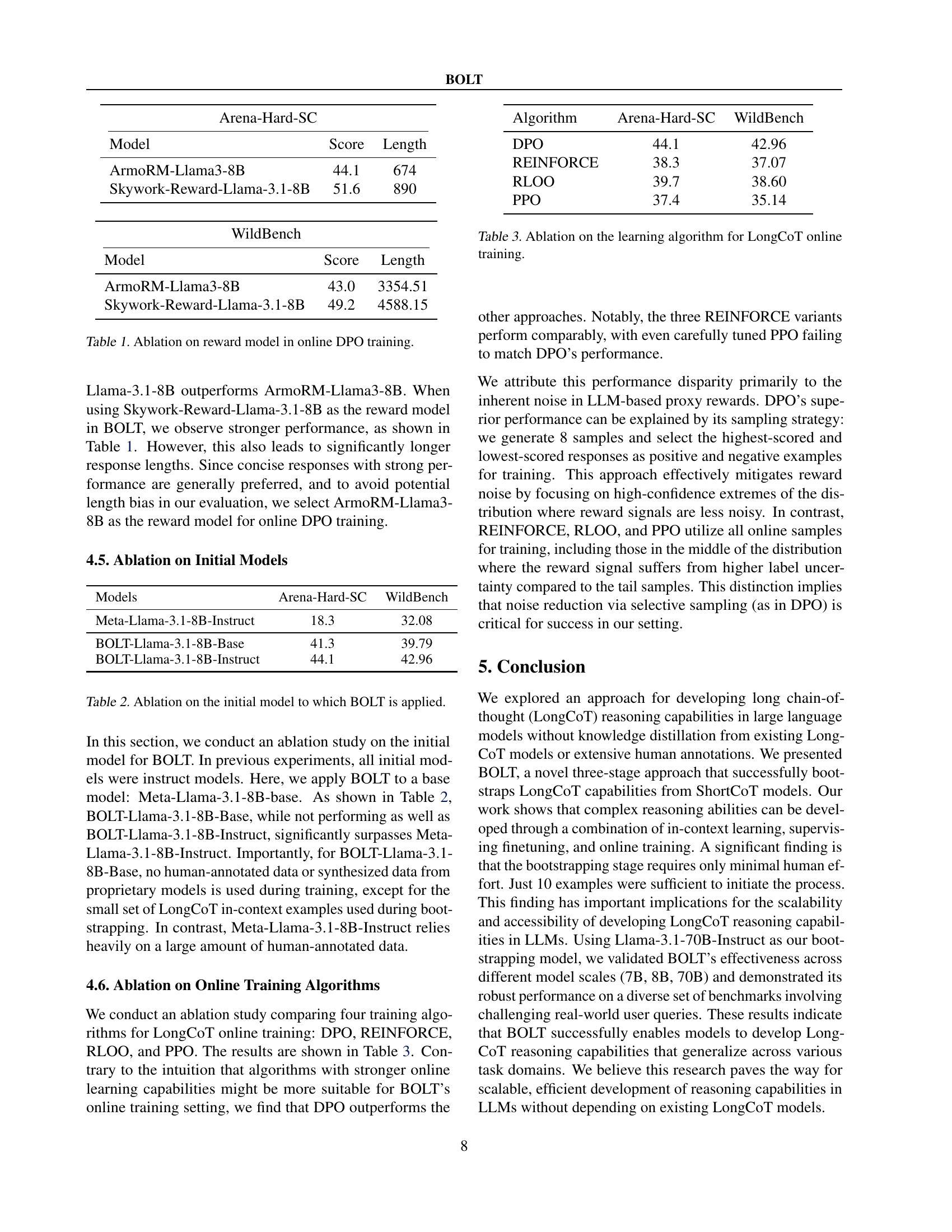
🔼 The figure illustrates the BOLT (Bootstrap Long Chain-of-Thought) framework, a three-stage process for training language models to generate long chains of reasoning. Stage 1, LongCoT Bootstrapping, uses a ShortCoT (short chain-of-thought) language model and a small number of in-context examples to generate LongCoT data. This data is then used in Stage 2, LongCoT Supervised Finetuning, to train a ShortCoT model on the LongCoT format, encouraging it to generate richer reasoning before providing an answer. Finally, Stage 3, LongCoT Online Training, refines the model’s LongCoT capabilities through online learning and feedback using an Outcome Reward Model (ORM) to evaluate the quality of answers. The ORM assesses the quality of the final solution generated by the model.
read the caption
Figure 1: Illustration of bootstrapping long chain-of-thought in large language models (BOLT). BOLT comprises three stages: 1) LongCoT Bootstrapping which involves synthesizing LongCoT data, 2) LongCoT Supervised Finetuning where we train a ShortCoT model to adapt to the LongCoT format, incorporating reasoning elements and practicing extended chains of thought before arriving at an external solution, 3) LongCoT Online Training where the LongCoT SFT model is further improved through online exploration and refinement. Bootstrapping LLM is a ShortCoT LLM that is used to generate LongCoT data via in-context learning. ORM is an outcome reward model which scores the external solution in the model response.
| Arena-Hard-SC | ||
| Model | Score | Length |
| ArmoRM-Llama3-8B | 44.1 | 674 |
| Skywork-Reward-Llama-3.1-8B | 51.6 | 890 |
🔼 This table presents an ablation study on the impact of different reward models used in the online Direct Preference Optimization (DPO) training phase of the BOLT method. It compares the performance of the method when using different reward models (ArmoRM-Llama3-8B and Skywork-Reward-Llama-3.1-8B), evaluating their influence on the final model’s performance across different metrics (Arena-Hard-SC, Wildbench). The table displays the scores and lengths of responses generated by the models, demonstrating the effect of different reward mechanisms on the length and accuracy of the generated text.
read the caption
Table 1: Ablation on reward model in online DPO training.
In-depth insights#
LongCoT Reasoning#
Long chain-of-thought (LongCoT) reasoning, as demonstrated by models like OpenAI’s o1, signifies a significant advancement in large language models (LLMs). LongCoT empowers LLMs to solve complex problems by generating an extended chain of reasoning steps before arriving at a final answer. This process mirrors human problem-solving, involving planning, reflection, and error correction. However, replicating LongCoT capabilities has proven challenging. Existing methods primarily rely on knowledge distillation, using data from already-capable models, limiting the understanding of how to systematically develop such reasoning abilities from scratch. The reliance on distillation creates a black box; researchers lack a clear picture of how LongCoT emerges without direct transfer learning from pre-trained models. This paper, therefore, proposes a novel, bootstrap approach to overcome this limitation, offering a white-box alternative to the knowledge distillation approach and paving the way for future research to more completely understand and develop this critical capability in LLMs.
BOLT Framework#
The BOLT framework presents a novel approach to bootstrap Long Chain-of-Thought (LongCoT) reasoning in Language Models (LLMs) without relying on distillation from existing LongCoT models or extensive human annotations. It leverages a three-stage process: 1) LongCoT data bootstrapping via in-context learning from a standard instruct model, requiring minimal example creation; 2) LongCoT supervised fine-tuning to adapt a ShortCoT model to the LongCoT format; and 3) online training to further refine LongCoT capabilities. The framework’s strength lies in its efficiency and scalability, demonstrated by impressive performance improvements across various model sizes and diverse benchmarks. Its white-box nature, unlike black-box distillation methods, offers greater transparency and understanding of how LongCoT reasoning is developed. The open-sourcing of training data and models further promotes future research and wider adoption, offering a cost-effective pathway for cultivating advanced reasoning skills in LLMs.
Empirical Results#
An Empirical Results section in a research paper would typically present quantitative or qualitative findings that support or refute the study’s hypotheses. A thoughtful analysis would delve into the specific metrics used, examining their appropriateness and limitations. Statistical significance of results should be highlighted, along with consideration of effect sizes. Furthermore, a critical review would explore potential confounding variables or biases that could affect the interpretation of findings. It’s crucial to assess the robustness of the results by examining whether they hold across various subgroups or under different conditions. Finally, a comprehensive summary would connect the empirical findings back to the research questions and theoretical framework, discussing their implications and limitations in advancing knowledge within the field.
Ablation Studies#
Ablation studies systematically remove or alter components of a model to understand their individual contributions and effects on overall performance. In this context, they would likely involve removing or modifying specific stages of the BOLT (Bootstrap Long Chain-of-Thought) process—LongCoT bootstrapping, LongCoT supervised finetuning, or LongCoT online training—to assess their individual importance. Removing the bootstrapping stage would test the feasibility of generating LongCoT data from scratch. Modifying or removing finetuning would isolate the impact of supervised learning on adapting a short-chain model to long-chain reasoning. Finally, removing online training would assess the role of reinforcement learning in refinement. By analyzing performance differences across these variations, researchers gain crucial insight into the relative contribution of each component and identify critical factors driving the model’s success. Results would reveal which parts are most essential for generating high-quality LongCoT responses, guiding future model improvements and potentially simplifying the model architecture by eliminating less important elements.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending BOLT to other LLMs beyond the ones tested is crucial to assess its generalizability and effectiveness across different architectures and scales. Investigating the minimal number of in-context examples needed for successful bootstrapping, and how that number scales with model size or task complexity, warrants further research. Improving the efficiency of the online training phase is also important. Exploring different reward model designs and reinforcement learning algorithms could lead to faster convergence and better LongCoT capabilities. Finally, this work could be extended to understand the theoretical underpinnings of the effectiveness of the BOLT approach in fostering long-chain reasoning. A deeper theoretical understanding can offer valuable insights into how to systematically design and train more capable reasoning LLMs.
More visual insights#
More on figures

🔼 This figure illustrates the three stages of the BOLT method. The first stage is LongCoT bootstrapping, which uses in-context learning on a standard instruct model to generate LongCoT data. The second stage is LongCoT supervised finetuning, where a ShortCoT model is fine-tuned on the bootstrapped data. The third stage is LongCoT online training, which further refines the model’s LongCoT capabilities using online learning. The figure visually represents this process, showing how the model generates internal thoughts and external solutions.
read the caption
Figure 2: An illustration of long chain-of-thought as internal thoughts. Portions of the external solution are omitted for brevity.

🔼 Figure 3 is a bar chart that visualizes the distribution of topics within the query data used in the LongCoT Bootstrapping stage of the BOLT method. The x-axis represents various topic categories, such as ‘Mathematics,’ ‘Computer Science and Coding,’ ‘Creative Writing,’ etc., and the y-axis represents the percentage of queries falling under each topic. The chart shows the relative frequency of different query types in the dataset, indicating the diversity of tasks the model is trained on. This is useful in understanding the breadth of reasoning capabilities the model is expected to handle.
read the caption
Figure 3: Topic distribution of query data in LongCoT Bootstrapping, 𝒟b-querysubscript𝒟b-query\mathcal{D}_{\text{b-query}}caligraphic_D start_POSTSUBSCRIPT b-query end_POSTSUBSCRIPT.

🔼 This figure shows the prompt template used in the LongCoT bootstrapping stage of the BOLT method. The prompt presents several in-context examples of Long chain-of-thought reasoning. Each example consists of a query, followed by the model’s internal thought process (reasoning steps), and finally, the model’s external solution. This carefully constructed prompt guides the ShortCoT model to generate similar LongCoT responses during the bootstrapping phase.
read the caption
Figure 4: An illustration of the prompt used in LongCoT Bootstrapping.

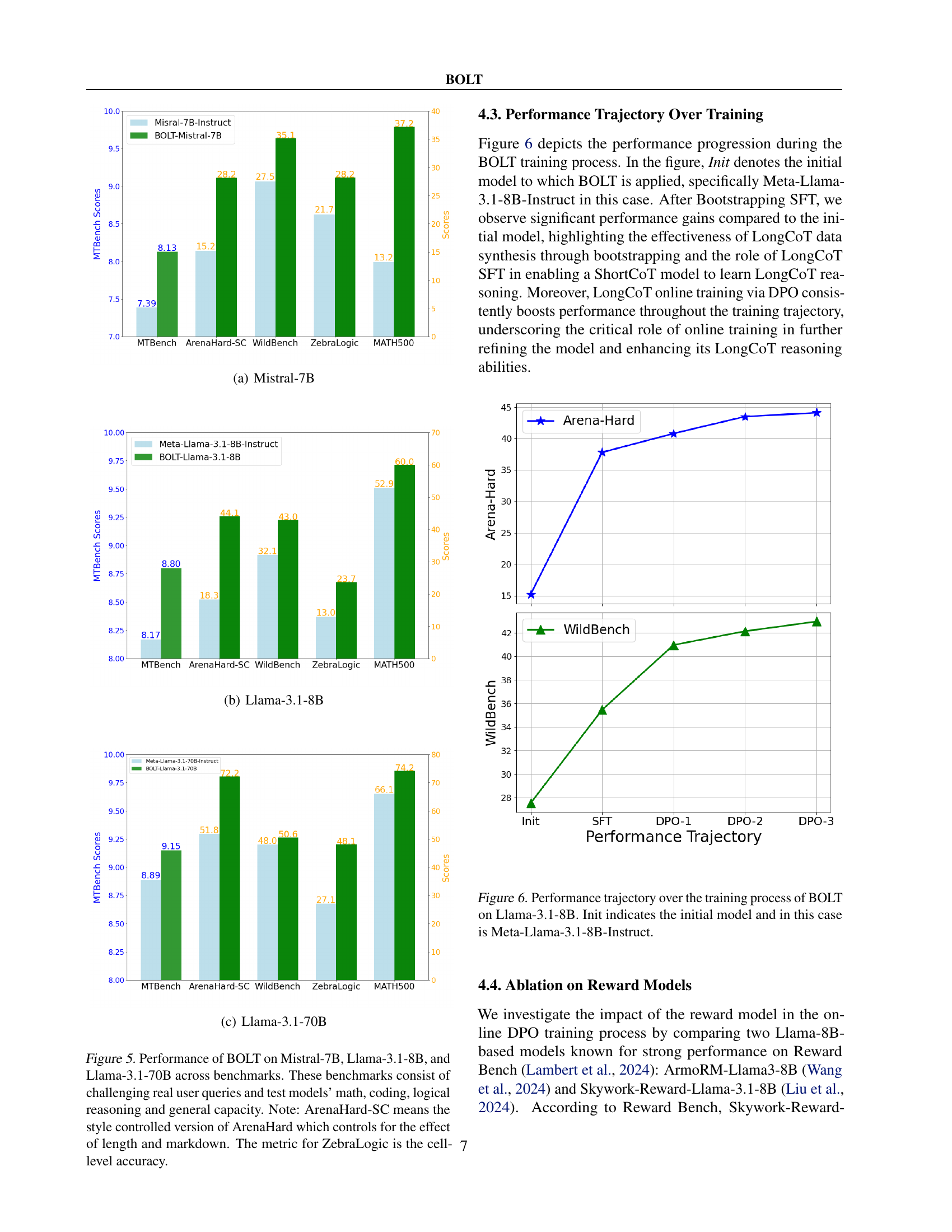
🔼 Figure 5 presents a performance comparison of three different language models across five distinct benchmarks. The models are Mistral-7B, Llama-3.1-8B, and Llama-3.1-70B. The benchmarks are MT-Bench, Arena-Hard (style-controlled version), WildBench, ZebraLogic, and MATH500. The figure visualizes the performance scores, allowing for a direct comparison of each model’s capabilities across diverse tasks that evaluate reasoning, problem-solving, and general language understanding abilities. Each bar graph section corresponds to a specific benchmark.
read the caption
(a) Mistral-7B

🔼 The figure shows the performance of BOLT on the Llama-3.1-8B model across five benchmarks: MT-Bench, Arena-Hard-SC, WildBench, ZebraLogic, and MATH500. It compares the initial performance of the Llama-3.1-8B Instruct model against its performance after undergoing the three stages of BOLT (Bootstrapping, SFT, and Online Training). The bar chart illustrates the improvement in scores achieved by applying BOLT for each benchmark.
read the caption
(b) Llama-3.1-8B

🔼 Figure 5(c) presents the performance comparison results for the Llama-3.1-70B model across various benchmarks. These benchmarks cover a wide range of tasks, testing mathematical problem-solving abilities, coding skills, logical reasoning, and general reasoning capabilities. The figure visually compares the performance of the original Llama-3.1-70B model (the ‘Init’ or initial model) to the performance of the model after undergoing the three stages of the BOLT method (‘BOLT-Llama-3.1-70B’). The improvement in performance after applying the BOLT method is clearly shown.
read the caption
(c) Llama-3.1-70B

🔼 This figure displays the performance comparison of three different language models (Mistral-7B, Llama-3.1-8B, and Llama-3.1-70B) after applying the BOLT method. The models are evaluated on five benchmarks: MT-Bench, Arena-Hard-SC (a style-controlled version of Arena-Hard focusing on content rather than formatting), WildBench, ZebraLogic, and MATH500. Each benchmark tests a different aspect of the models’ capabilities, ranging from multi-turn question answering and creative writing to logical reasoning and mathematical problem-solving. The results illustrate the improvements achieved in each benchmark after applying the BOLT method across different model sizes. The style-controlled version of Arena-Hard was used to isolate the impact of reasoning quality from stylistic differences in response formatting. For ZebraLogic, cell-level accuracy is reported.
read the caption
Figure 5: Performance of BOLT on Mistral-7B, Llama-3.1-8B, and Llama-3.1-70B across benchmarks. These benchmarks consist of challenging real user queries and test models’ math, coding, logical reasoning and general capacity. Note: ArenaHard-SC means the style controlled version of ArenaHard which controls for the effect of length and markdown. The metric for ZebraLogic is the cell-level accuracy.
More on tables
| WildBench | ||
| Model | Score | Length |
| ArmoRM-Llama3-8B | 43.0 | 3354.51 |
| Skywork-Reward-Llama-3.1-8B | 49.2 | 4588.15 |
🔼 This table presents the results of an ablation study on the initial model used in the BOLT method. It compares the performance of BOLT when applied to different initial models, showing the impact of the model’s starting capabilities on the final LongCoT performance. Specifically, it shows the performance (scores on Arena-Hard and Wildbench benchmarks) for BOLT when initialized with a standard instruct model and when initialized with a base model without instruction tuning.
read the caption
Table 2: Ablation on the initial model to which BOLT is applied.
| Models | Arena-Hard-SC | WildBench |
| Meta-Llama-3.1-8B-Instruct | 18.3 | 32.08 |
| BOLT-Llama-3.1-8B-Base | 41.3 | 39.79 |
| BOLT-Llama-3.1-8B-Instruct | 44.1 | 42.96 |
🔼 This table presents the results of an ablation study comparing four different online training algorithms used in the Long Chain-of-Thought (LongCoT) online training stage of the BOLT model. The algorithms compared are Direct Preference Optimization (DPO), REINFORCE, Reverse Reinforcement Learning with Online Optimization (RLOO), and Proximal Policy Optimization (PPO). The table shows the performance of each algorithm on two benchmarks: Arena-Hard-SC and WildBench, reporting the score and sequence length for each. This ablation study aims to determine which algorithm is most effective for enhancing LongCoT reasoning capabilities in the BOLT framework.
read the caption
Table 3: Ablation on the learning algorithm for LongCoT online training.
Full paper#