TL;DR#
Current state-of-the-art speech synthesis often involves multi-stage models, complicating the decision of whether to scale during training or testing. The research also highlights the lack of a standard framework in TTS, in contrast to the common design philosophy of text LLMs that has spurred rapid progress. This limits exploring broader research questions beyond architecture exploration.
To address these issues, the paper proposes Llasa, a simple single-Transformer TTS framework aligned with standard LLMs. The approach uses a single-layer vector quantizer (VQ) codec and a single Transformer architecture. Experiments show that scaling training-time compute consistently improves the naturalness and prosody of synthesized speech. Furthermore, scaling inference compute by integrating speech understanding models as verifiers improves emotional expressiveness, timbre, and content accuracy. The release of the model and code further promotes community research and development.
Key Takeaways#
Why does it matter?#
This paper is crucial because it systematically investigates the effects of scaling both training-time and inference-time compute on speech synthesis, a significant trend in current research. It bridges the gap between text-based LLMs and TTS, suggesting novel strategies for performance improvement. The provided open-access model and code further enhance its impact, enabling researchers to build on and extend this work, potentially leading to breakthroughs in natural and expressive speech generation.
Visual Insights#

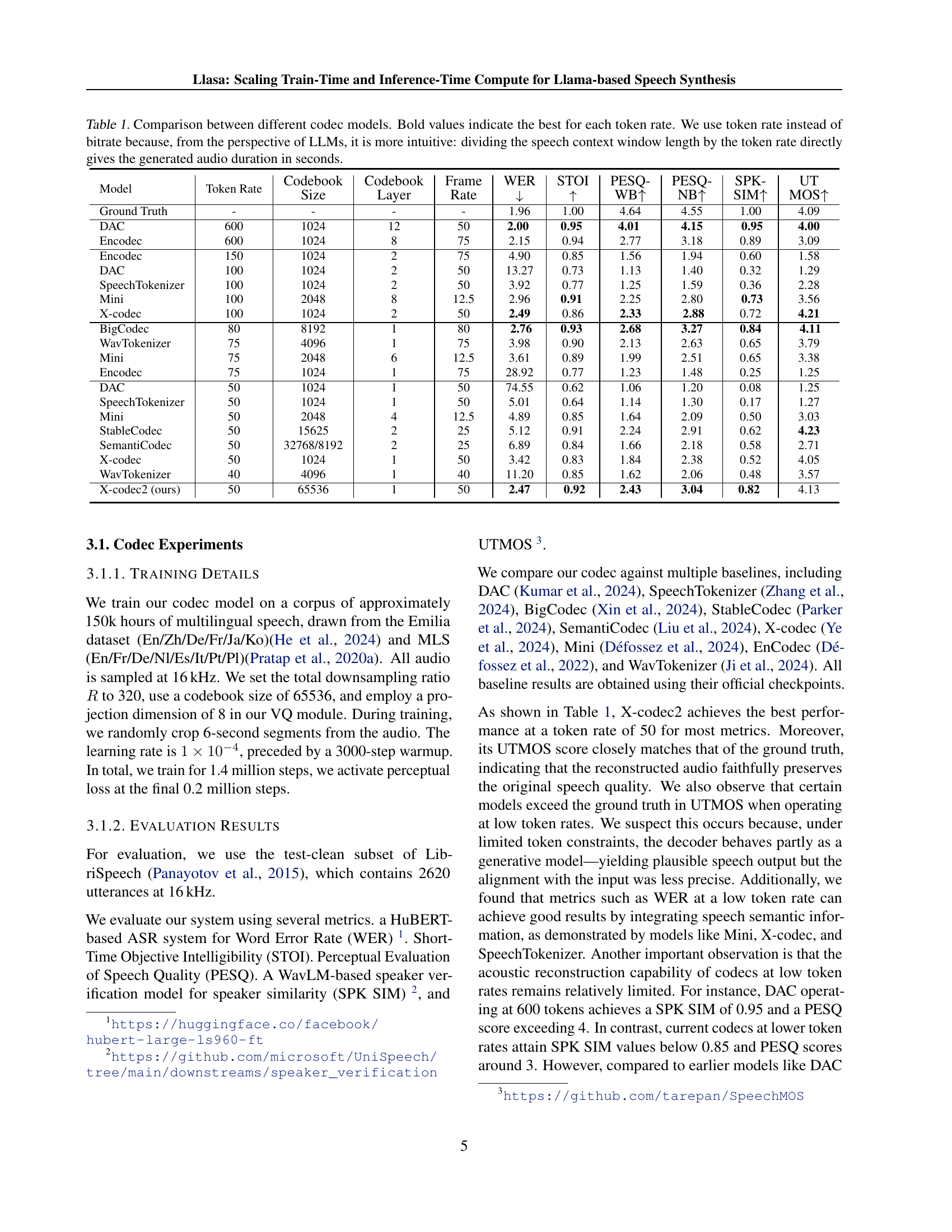
🔼 This figure presents a comparison of average expert scores for text understanding ability in both Chinese and English. The scores are based on evaluations performed using several categories of texts designed to assess different facets of text understanding, such as emotional expressiveness, handling of complex syntax, and nuanced prosody. The evaluations were conducted by expert linguistic annotators who rated the generated speech according to predefined criteria. The figure visually shows how the scores vary across different models (Llasa models with varying parameter counts and training data sizes) to demonstrate the relationship between model capacity and training data and the overall text understanding capabilities of the speech synthesis system.
read the caption
Figure 1: Comparison of mean expert score for Chinese and English
| Model | Token Rate | Codebook Size | Codebook Layer | Frame Rate | WER | STOI | PESQ- WB | PESQ- NB | SPK- SIM | UT MOS |
| Ground Truth | - | - | - | - | 1.96 | 1.00 | 4.64 | 4.55 | 1.00 | 4.09 |
| DAC | 600 | 1024 | 12 | 50 | 2.00 | 0.95 | 4.01 | 4.15 | 0.95 | 4.00 |
| Encodec | 600 | 1024 | 8 | 75 | 2.15 | 0.94 | 2.77 | 3.18 | 0.89 | 3.09 |
| Encodec | 150 | 1024 | 2 | 75 | 4.90 | 0.85 | 1.56 | 1.94 | 0.60 | 1.58 |
| DAC | 100 | 1024 | 2 | 50 | 13.27 | 0.73 | 1.13 | 1.40 | 0.32 | 1.29 |
| SpeechTokenizer | 100 | 1024 | 2 | 50 | 3.92 | 0.77 | 1.25 | 1.59 | 0.36 | 2.28 |
| Mimi | 100 | 2048 | 8 | 12.5 | 2.96 | 0.91 | 2.25 | 2.80 | 0.73 | 3.56 |
| X-codec | 100 | 1024 | 2 | 50 | 2.49 | 0.86 | 2.33 | 2.88 | 0.72 | 4.21 |
| BigCodec | 80 | 8192 | 1 | 80 | 2.76 | 0.93 | 2.68 | 3.27 | 0.84 | 4.11 |
| WavTokenizer | 75 | 4096 | 1 | 75 | 3.98 | 0.90 | 2.13 | 2.63 | 0.65 | 3.79 |
| Mimi | 75 | 2048 | 6 | 12.5 | 3.61 | 0.89 | 1.99 | 2.51 | 0.65 | 3.38 |
| Encodec | 75 | 1024 | 1 | 75 | 28.92 | 0.77 | 1.23 | 1.48 | 0.25 | 1.25 |
| DAC | 50 | 1024 | 1 | 50 | 74.55 | 0.62 | 1.06 | 1.20 | 0.08 | 1.25 |
| SpeechTokenizer | 50 | 1024 | 1 | 50 | 5.01 | 0.64 | 1.14 | 1.30 | 0.17 | 1.27 |
| Mimi | 50 | 2048 | 4 | 12.5 | 4.89 | 0.85 | 1.64 | 2.09 | 0.50 | 3.03 |
| StableCodec | 50 | 15625 | 2 | 25 | 5.12 | 0.91 | 2.24 | 2.91 | 0.62 | 4.23 |
| SemantiCodec | 50 | 32768/8192 | 2 | 25 | 6.89 | 0.84 | 1.66 | 2.18 | 0.58 | 2.71 |
| X-codec | 50 | 1024 | 1 | 50 | 3.42 | 0.83 | 1.84 | 2.38 | 0.52 | 4.05 |
| WavTokenizer | 40 | 4096 | 1 | 40 | 11.20 | 0.85 | 1.62 | 2.06 | 0.48 | 3.57 |
| X-codec2 (ours) | 50 | 65536 | 1 | 50 | 2.47 | 0.92 | 2.43 | 3.04 | 0.82 | 4.13 |
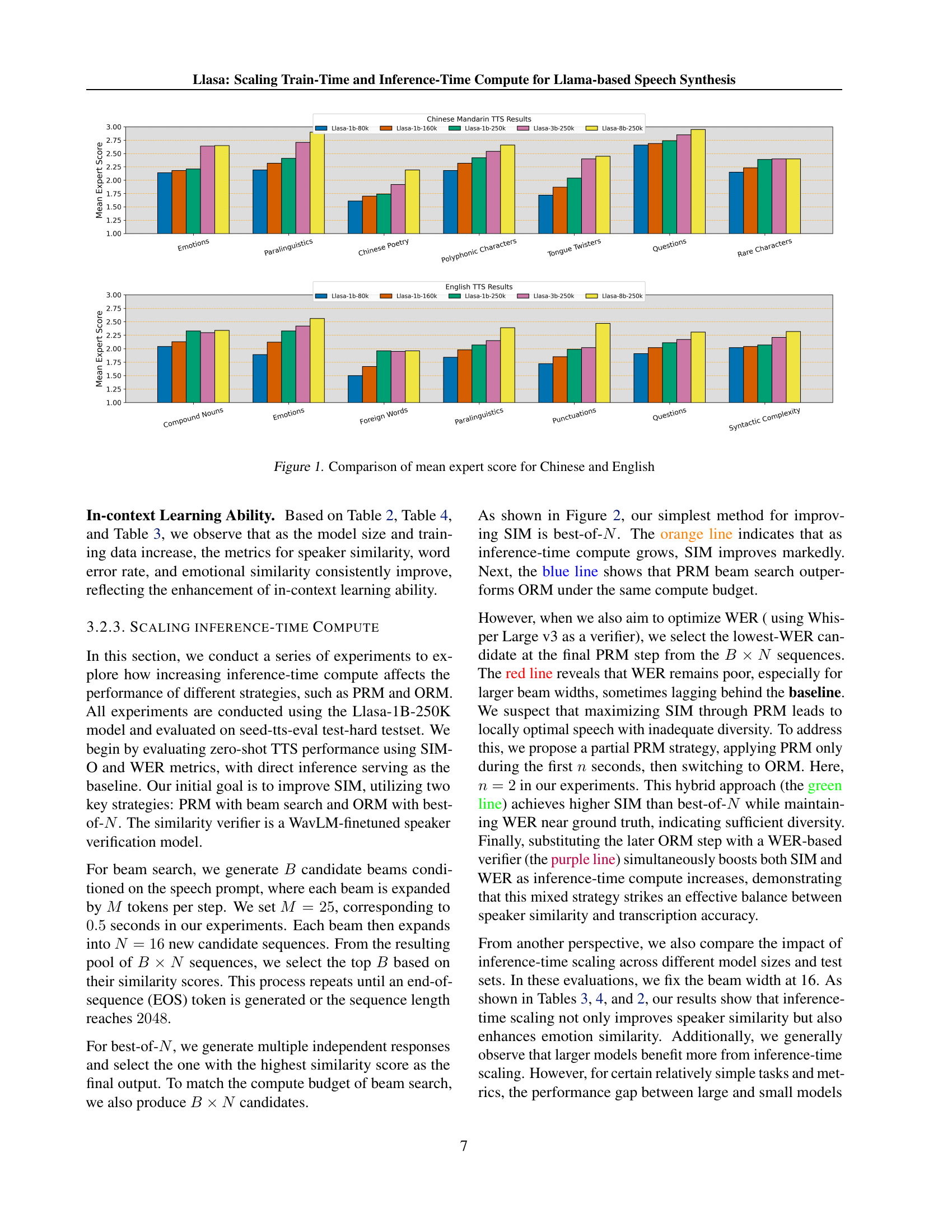
🔼 This table compares the performance of different speech codecs in terms of various metrics, including Word Error Rate (WER), Short-Time Objective Intelligibility (STOI), Perceptual Evaluation of Speech Quality (PESQ), speaker similarity (SPK SIM), and Mean Opinion Score (MOS). The codecs are evaluated across different token rates, which are presented instead of bitrates for better comparison with Large Language Models (LLMs). Lower WER and higher STOI, PESQ, SPK SIM, and MOS scores generally indicate better performance, showing how well the codec reconstructs the original speech signal, preserves its intelligibility and naturalness, and maintains speaker consistency. The bold values highlight the best-performing codec for each token rate.
read the caption
Table 1: Comparison between different codec models. Bold values indicate the best for each token rate. We use token rate instead of bitrate because, from the perspective of LLMs, it is more intuitive: dividing the speech context window length by the token rate directly gives the generated audio duration in seconds.
In-depth insights#
LLM-TTS Scaling Laws#
Exploring scaling laws in LLM-based text-to-speech (TTS) systems reveals crucial insights into efficiency and quality improvements. Model size and training data exhibit a complex interplay; simply increasing model size without sufficient data may yield diminishing returns. Conversely, massive datasets might not fully leverage larger models’ potential, highlighting the need for balanced scaling. Inference-time scaling, involving sophisticated search strategies and verifier models, offers exciting possibilities for enhancing quality and expressiveness post-training. Understanding the interaction between these factors will guide future research towards developing more efficient and high-quality LLM-TTS systems, paving the way for personalized and emotionally expressive speech synthesis.
X-Codec2 Tokenizer#
The X-Codec2 tokenizer represents a significant advancement in speech tokenization for text-to-speech (TTS) systems. It directly addresses the challenge of aligning TTS with the minimalist yet powerful paradigm of text LLMs by fusing semantic and acoustic features into a unified codebook. Unlike previous methods requiring separate semantic and acoustic models, X-Codec2 uses a single vector quantizer, streamlining the process and improving efficiency. This design choice, coupled with the 1D causal dependency, fully aligns the tokenizer with the autoregressive mechanism of LLMs, leveraging their inherent ability to model sequential data effectively. The resulting unified representation allows the LLM to capture all facets of the speech signal, including content, prosody, and timbre, within a single framework. This approach not only simplifies the TTS architecture, making it more flexible and scalable, but also enhances the quality and naturalness of the generated speech by facilitating a deeper understanding of the input text and enabling finer control over various acoustic characteristics. Moreover, the training process, which leverages adversarial training and perceptual loss, further improves the performance and robustness of the tokenizer.
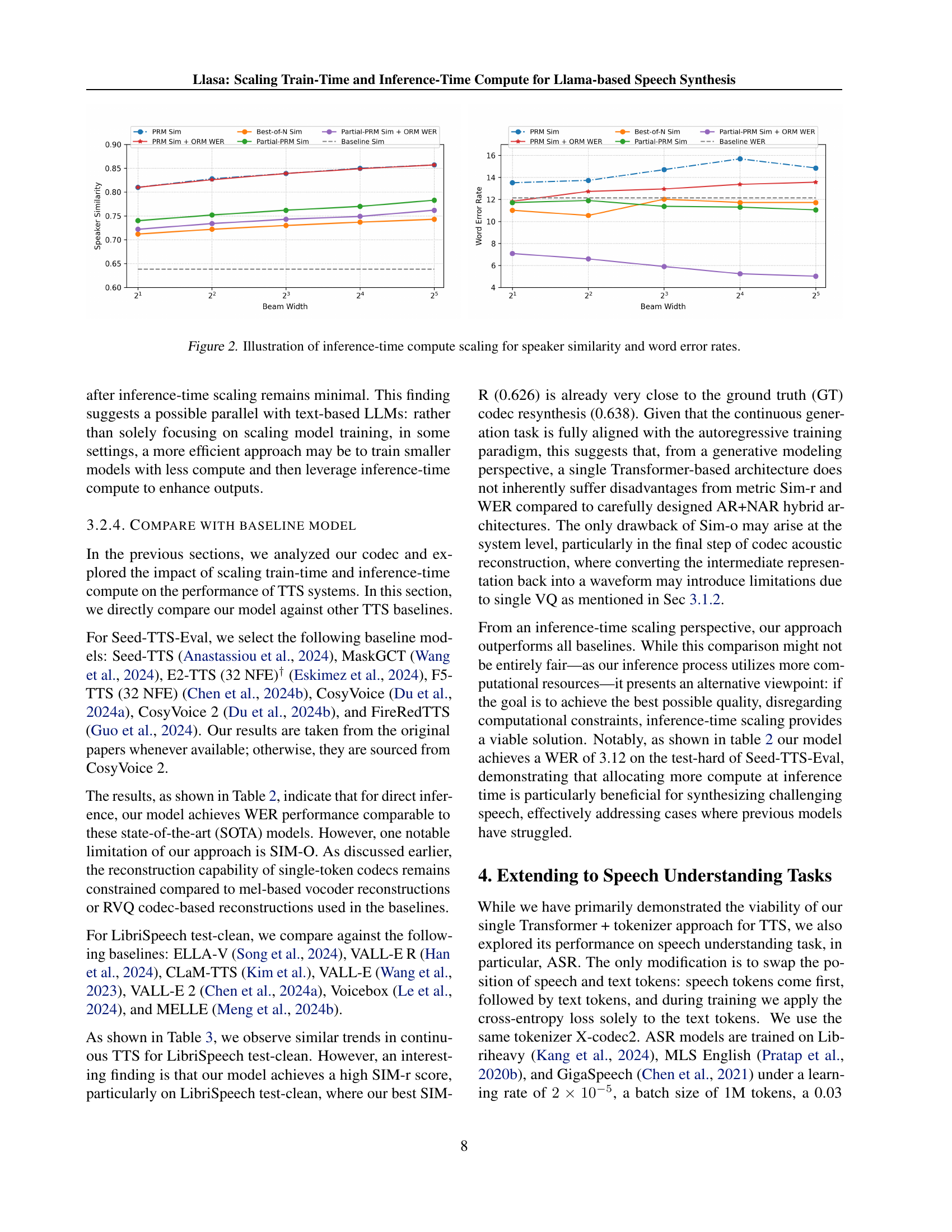
Inference-Time Search#
Inference-time search in LLMs involves augmenting model outputs with post-hoc refinement. Instead of solely relying on the initial model generation, this technique explores multiple candidate outputs and uses a verification or scoring mechanism to select the best one. This approach is particularly relevant in speech synthesis where achieving high quality often requires substantial computational resources. The core idea is to invest more computational effort during the inference phase to compensate for limitations in training data and model architecture. This may involve sophisticated search algorithms (e.g., beam search) that explore the solution space and refine generated outputs incrementally. The choice of verifier models significantly impacts the performance, with models like speech understanding models, measuring timbre, emotion, naturalness, and content accuracy often being used. While computationally expensive, this approach offers flexibility for improving the final output, especially in challenging scenarios. A crucial aspect is balancing computational cost with quality gains; strategies like partial inference-time search (combining different search methods) aim to optimize the tradeoff. This technique offers a promising avenue for advancing speech synthesis capabilities, especially when combined with training-time scaling methods.
Zero-Shot TTS#
Zero-shot Text-to-Speech (TTS) represents a significant advancement in speech synthesis, aiming to generate high-quality speech for unseen speakers or languages without requiring any explicit training data for those specific cases. This capability is particularly valuable because it drastically reduces the need for extensive data collection and model retraining for every new voice or language, making the technology significantly more scalable and efficient. The success of zero-shot TTS hinges on the model’s ability to generalize from its training data. Effective generalization requires robust model architectures capable of extracting and applying underlying acoustic and linguistic patterns present across diverse speech datasets. Key challenges in zero-shot TTS include maintaining high fidelity and naturalness while avoiding artifacts or distortions associated with generalization. Careful selection of both training data and model design is crucial for achieving high performance. Further research should focus on improving generalization capabilities, exploring novel model architectures, and investigating strategies to handle variability in speech characteristics.
TTS Codec Analysis#
A thorough TTS codec analysis would involve a multifaceted investigation. It would start with a detailed comparison of different codecs, examining their performance across standard metrics like WER, STOI, PESQ, and MOS. The analysis should explore how codec choices impact the overall quality and naturalness of synthesized speech. Furthermore, it’s essential to evaluate the computational efficiency of each codec. This assessment should consider both encoding and decoding times to determine their suitability for real-time or near real-time applications. Finally, the analysis should investigate the trade-off between codec complexity and speech quality. A high-quality codec might necessitate significant computational resources, whereas a simpler codec may compromise speech naturalness. The results of the analysis should not only report quantitative metrics but also offer qualitative insights into the perceptual differences between codecs, aiding in the selection of the optimal codec for specific TTS applications.
More visual insights#
More on tables
| Model | test-zh | test-en | test-hard | |||
| CER ↓ | sim-o ↑ | WER ↓ | sim-o ↑ | WER ↓ | sim-o ↑ | |
| Human | 1.26 | 0.755 | 2.14 | 0.734 | - | - |
| Our Codec Resyn. | 1.92 | 0.677 | 2.91 | 0.619 | - | - |
| Seed-TTS † | 1.12 | 0.796 | 2.25 | 0.762 | 7.59 | 0.776 |
| FireRedTTS | 1.51 | 0.635 | 3.82 | 0.460 | 17.45 | 0.621 |
| MaskGCT | 2.27 | 0.774 | 2.62 | 0.714 | 10.27 | 0.748 |
| E2 TTS (32 NFE)† | 1.97 | 0.730 | 2.19 | 0.710 | - | - |
| F5-TTS (32 NFE) | 1.56 | 0.741 | 1.83 | 0.647 | 8.67 | 0.713 |
| CosyVoice | 3.63 | 0.723 | 4.29 | 0.609 | 11.75 | 0.709 |
| CosyVoice 2 | 1.45 | 0.748 | 2.57 | 0.652 | 6.83 | 0.724 |
| Train-time Scaling | ||||||
| llasa 1b 80k | 2.69 | 0.648 (0.779) | 3.71 | 0.541 (0.685) | 17.11 | 0.618 (0.765) |
| llasa 1b 160k | 2.22 | 0.658 (0.783) | 3.60 | 0.563 (0.701) | 16.73 | 0.627 (0.770) |
| llasa 1b 250k | 1.89 | 0.669 (0.794) | 3.22 | 0.572 (0.708) | 12.13 | 0.638 (0.779) |
| llasa 3b 250k | 1.60 | 0.675 (0.792) | 3.14 | 0.579 (0.708) | 13.37 | 0.652 (0.782) |
| llasa 8b 250k | 1.59 | 0.684 (0.798) | 2.97 | 0.574 (0.706) | 11.09 | 0.660 (0.787) |
| Partial PRM (spk sim) | ||||||
| llasa 1b 80k | 1.52 | 0.811 (0.849) | 2.30 | 0.761 (0.798) | 16.09 | 0.759 (0.824) |
| llasa 1b 160k | 1.29 | 0.815 (0.851) | 2.29 | 0.774 (0.804) | 14.10 | 0.768 (0.830) |
| llasa 1b 250k | 1.11 | 0.818 (0.855) | 2.03 | 0.781 (0.809) | 11.30 | 0.773 (0.833) |
| llasa 3b 250k | 1.06 | 0.824 (0.856) | 1.89 | 0.784 (0.812) | 11.22 | 0.780 (0.836) |
| llasa 8b 250k | 1.04 | 0.827 (0.856) | 1.84 | 0.783 (0.806) | 10.59 | 0.785 (0.839) |
| Partial PRM (spk sim)+ORM (WER) | ||||||
| llasa 1b 80k | 0.53 | 0.809 (0.840) | 1.43 | 0.761 (0.792) | 7.22 | 0.732 (0.789) |
| llasa 1b 160k | 0.53 | 0.812 (0.841) | 1.49 | 0.775 (0.798) | 6.35 | 0.745 (0.799) |
| llasa 1b 250k | 0.45 | 0.818 (0.845) | 1.46 | 0.782 (0.801) | 5.24 | 0.750 (0.803) |
| llasa 3b 250k | 0.50 | 0.823 (0.848) | 1.31 | 0.783 (0.803) | 5.39 | 0.759 (0.808) |
| llasa 8b 250k | 0.47 | 0.825 (0.848) | 1.39 | 0.783 (0.799) | 4.38 | 0.767 (0.812) |
| llasa 8b 250k | Chunking: if chunks, chunks, | 3.12 | 0.770 (0.791) | |||
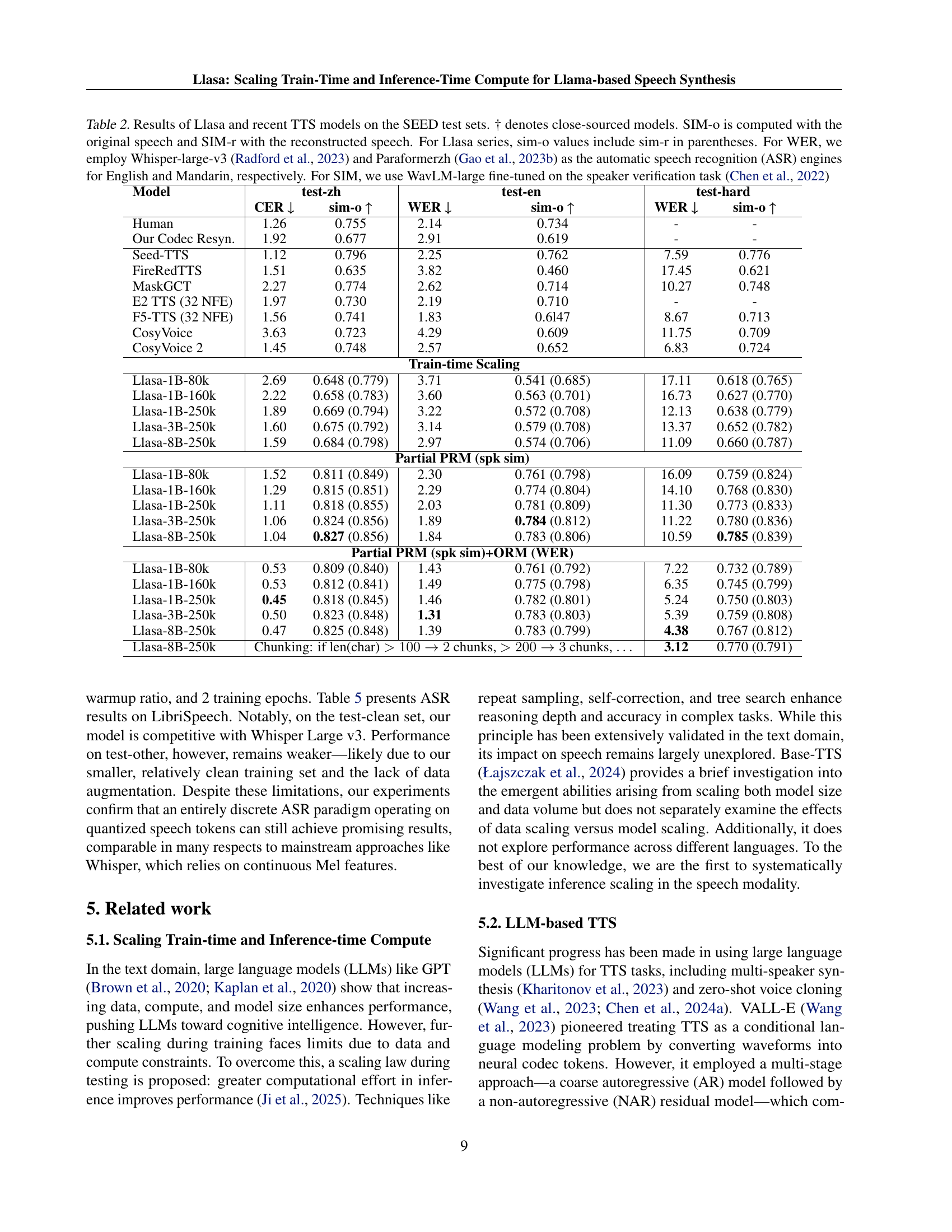
🔼 Table 2 presents a comparison of the performance of the Llasa model and several other state-of-the-art Text-to-Speech (TTS) models on the SEED-TTS-Eval benchmark dataset. The table includes results for three subsets of SEED-TTS-Eval: test-zh, test-en, and test-hard. For each model, the table shows the Character Error Rate (CER), Speaker Similarity (SIM-o), and Word Error Rate (WER). The SIM-o values for the Llasa models include the reconstructed speech similarity (SIM-r) values in parentheses. Models marked with † indicate that their source code is not publicly available. The table highlights the performance improvements achieved by scaling the Llasa model in terms of training time and data.
read the caption
Table 2: Results of llasa and recent TTS models on the SEED test sets. † denotes close-sourced models. For llasa series, sim-o values include sim-r in parentheses.
| Model | Test Clean | Test Other |
| whisper large v3 | 1.8 | 3.6 |
| whisper large v2 | 2.7 | 5.2 |
| llasa asr 1b | 2.3 | 7.2 |
| llasa asr 3b | 1.9 | 5.9 |
🔼 This table presents the performance of different Automatic Speech Recognition (ASR) models on the LibriSpeech dataset’s test sets. It compares the Word Error Rate (WER) achieved by various models, specifically highlighting the performance of the proposed Llasa model (in multiple configurations) against Whisper Large v2 and Whisper Large v3.
read the caption
Table 3: ASR Performance on LibriSpeech Test Sets
| Model | en | zh |
| GT | 0.94 | 0.94 |
| Train-time scaling | ||
| llasa 1b (80k) | 0.753 | 0.815 |
| llasa 1b (160k) | 0.762 | 0.822 |
| llasa 1b (250k) | 0.768 | 0.836 |
| llasa 3b (250k) | 0.769 | 0.852 |
| llasa 8b (250k) | 0.778 | 0.861 |
| Process Reward Models (emotion sim) | ||
| llasa 1b (80k) | 0.933 | 0.970 |
| llasa 1b (160k) | 0.936 | 0.971 |
| llasa 1b (250k) | 0.937 | 0.974 |
| llasa 3b (250k) | 0.949 | 0.975 |
| llasa 8b (250k) | 0.951 | 0.974 |
🔼 Table 4 presents the results of evaluating emotion similarity using Emotion2Vec-Plus-Large for English (’en’) and Chinese (‘zh’) speech synthesis. It shows the emotion similarity scores (SIM-o and SIM-r) achieved by different models, including various configurations of the Llasa model with different training data sizes and model parameters, alongside baselines such as ground truth (GT) and other existing systems. SIM-o represents similarity calculated using the original speech, while SIM-r represents similarity computed using the reconstructed speech from the TTS system. The table allows for comparison of the effect of training-time scaling (different model sizes and training data amounts) on emotion generation accuracy.
read the caption
Table 4: en, zh Emotion Similarity
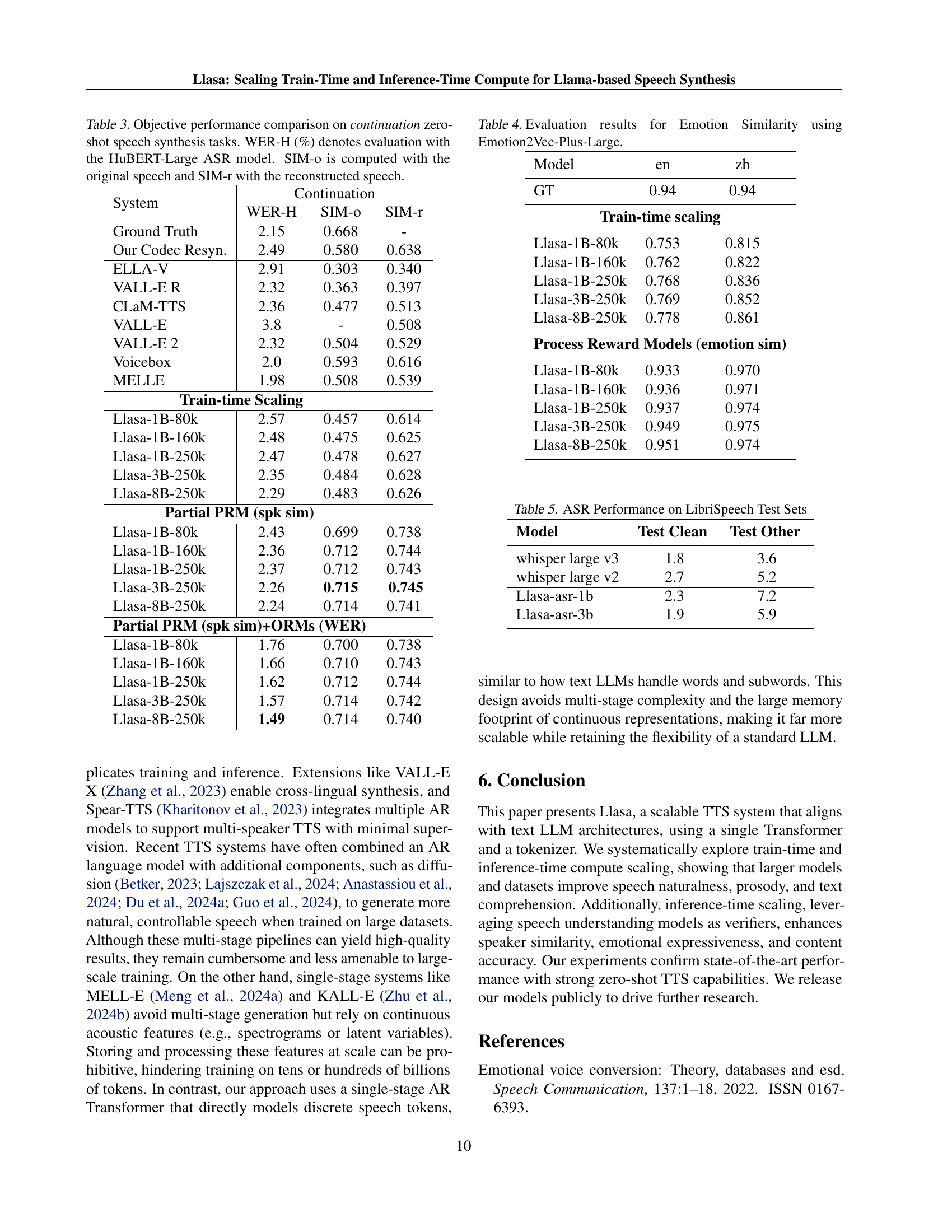
| System | Continuation | ||
| WER-H | SIM-o | SIM-r | |
| Ground Truth | 2.15 | 0.668 | - |
| Our Codec Resyn. | 2.49 | 0.580 | 0.638 |
| ELLA-V * | 2.91 | 0.303 | 0.340 |
| VALL-E R † | 2.32 | 0.363 | 0.397 |
| CLaM-TTS | 2.36 | 0.477 | 0.513 |
| VALL-E | 3.8 | - | 0.508 |
| VALL-E 2 † | 2.32 | 0.504 | 0.529 |
| Voicebox | 2.0 | 0.593 | 0.616 |
| MELLE | 1.98 | 0.508 | 0.539 |
| Train-time Scaling | |||
| LLaSA-TTS 1b 80k | 2.57 | 0.457 | 0.614 |
| LLaSA-TTS 1b 160k | 2.48 | 0.475 | 0.625 |
| LLaSA-TTS 1b 250k | 2.47 | 0.478 | 0.627 |
| LLaSA-TTS 3b 250k | 2.35 | 0.484 | 0.628 |
| LLaSA-TTS 8b 250k | 2.29 | 0.483 | 0.626 |
| PRM (spk sim) | |||
| LLaSA-TTS-80k 1b | 2.43 | 0.699 | 0.738 |
| LLaSA-TTS-160k 1b | 2.36 | 0.712 | 0.744 |
| LLaSA-TTS 1b 250k | 2.37 | 0.712 | 0.743 |
| LLaSA-TTS 3b 250k | 2.26 | 0.715 | 0.745 |
| LLaSA-TTS 8b 250k | 2.24 | 0.714 | 0.741 |
| PRM (spk sim)+ORMs (WER) | |||
| LLaSA-TTS-80k 1b | 1.76 | 0.700 | 0.738 |
| LLaSA-TTS-160k 1b | 1.66 | 0.710 | 0.743 |
| LLaSA-TTS 1b 250k | 1.62 | 0.712 | 0.744 |
| LLaSA-TTS 3b 250k | 1.57 | 0.714 | 0.742 |
| LLaSA-TTS 8b 250k | 1.49 | 0.714 | 0.740 |
🔼 Table 5 presents an objective comparison of various models’ performance on continuation zero-shot speech synthesis tasks. The evaluation metrics include Word Error Rate (WER) calculated using the HuBERT-Large ASR model, and Speaker Similarity (SIM) scores (both SIM-o, computed with the original speech, and SIM-r, using reconstructed speech). The table highlights the best and second-best performing models for each metric. Note that some results are based on reproductions from other papers, and certain results include additional metrics not originally reported by those papers.
read the caption
Table 5: Objective performance comparison on continuation zero-shot speech synthesis tasks. WER-H (%) denotes evaluation with the HuBERT-Large ASR model. The boldface indicates the best result, and the underline denotes the second best. *We quote Han et al. [2024]’s reproduction results, which demonstrate better performance. †We evaluate metrics not reported in the original paper, using the audios provided by the authors.
| Category | 1 | 2 | 3 |
| Emotion | No detectable emotion / 无可检测的情感 | Emotion present but not convincingly rendered / 存在情感但表达不够令人信服 | Correct emotion recognition and appropriate rendering / 正确识别情感并恰当表达 |
| Paralinguistic | No recognition of paralinguistic cues like interjections / 未识别出语调学关键词,如“哎呀”或“嘘” | Attempts to render paralinguistic cues but unnatural / 明确意图表达关键词,但表达不自然 | Natural rendering of paralinguistic cues with appropriate emphasis / 自然表达语调学关键词,恰当强调 |
| Chinese Poetry | Fails to capture the poetic structure and imagery / 未能捕捉诗歌的结构和意象 | Captures some poetic elements but lacks depth / 捕捉了一些诗歌元素但缺乏深度 | Accurately captures the poetic structure, imagery, and emotional depth / 准确捕捉诗歌的结构、意象和情感深度 |
| Polyphonic Characters | Incorrect pronunciation and meaning of polyphonic characters / 多音字发音错误,意义不正确 | Attempts correct pronunciation but with minor errors / 尝试正确发音但有小错误 | Correct pronunciation and meaning of polyphonic characters / 多音字发音和意义正确 |
| Questions | Intonation pattern incorrect, failing to convey questioning tone / 语调模式不正确,未能传达问句的语气 | Intonation pattern largely correct but with minor flaws / 语调模式大体正确,但有细微瑕疵 | Correct intonation patterns that clearly convey the questioning nature / 语调模式正确,清晰传达问句的性质 |
| Tongue Twisters | Inability to articulate the tongue twister, resulting in errors / 无法清晰表达绕口令,导致错误 | Attempts articulation with some errors / 尝试表达绕口令但有部分错误 | Clear and accurate articulation of the tongue twister without errors / 清晰准确地表达绕口令,无错误 |
| Rare Characters | Mispronunciation or incorrect interpretation of rare characters / 生僻字发音错误或解释不正确 | Attempts correct pronunciation and interpretation with minor mistakes / 尝试正确发音和解释但有小错误 | Accurate pronunciation and insightful interpretation of rare characters / 生僻字发音和解释准确 |
🔼 This table details the evaluation criteria used to assess the performance of text-to-speech (TTS) systems on Chinese language tests. Each row represents a category of text (e.g., Emotion, Paralinguistic cues, etc.) and lists three scoring levels reflecting the naturalness and accuracy of the TTS system’s output in capturing the nuances of the language, The three levels of scores 1, 2, and 3 describe the performance from poor to excellent, respectively. Specifically, score 1 indicates the system fails to capture the intended aspects, score 2 shows attempts to do so but with some flaws, and score 3 indicates accurate and natural rendering.
read the caption
Table 6: Evaluation Criteria for Chinese Test Set
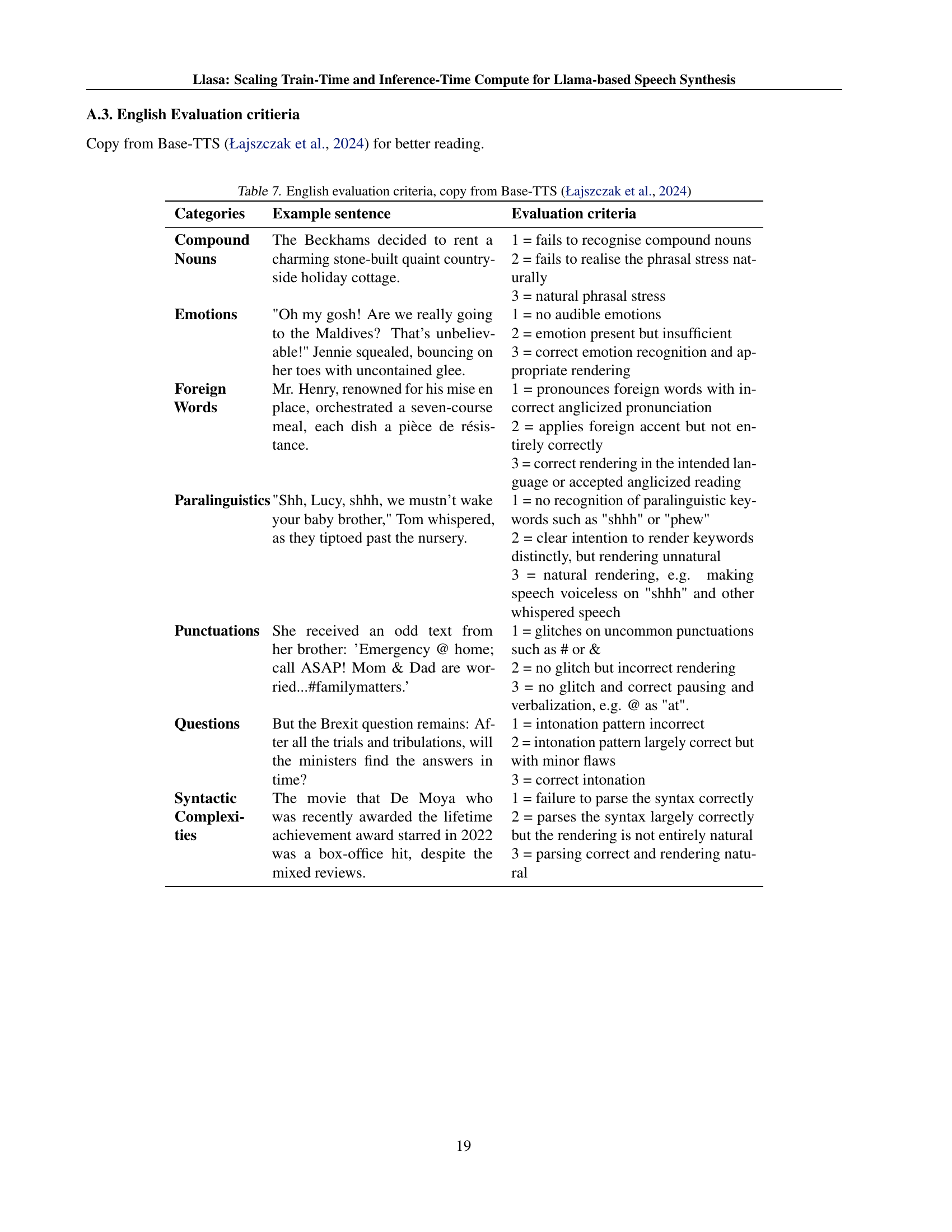
| Categories | Example sentence | Evaluation criteria |
| Compound Nouns | The Beckhams decided to rent a charming stone-built quaint countryside holiday cottage. | 1 = fails to recognise compound nouns 2 = fails to realise the phrasal stress naturally 3 = natural phrasal stress |
| Emotions | ”Oh my gosh! Are we really going to the Maldives? That’s unbelievable!” Jennie squealed, bouncing on her toes with uncontained glee. | 1 = no audible emotions 2 = emotion present but insufficient 3 = correct emotion recognition and appropriate rendering |
| Foreign Words | Mr. Henry, renowned for his mise en place, orchestrated a seven-course meal, each dish a pièce de résistance. | 1 = pronounces foreign words with incorrect anglicized pronunciation 2 = applies foreign accent but not entirely correctly 3 = correct rendering in the intended language or accepted anglicized reading |
| Paralinguistics | ”Shh, Lucy, shhh, we mustn’t wake your baby brother,” Tom whispered, as they tiptoed past the nursery. | 1 = no recognition of paralinguistic keywords such as ”shhh” or ”phew” 2 = clear intention to render keywords distinctly, but rendering unnatural 3 = natural rendering, e.g. making speech voiceless on ”shhh” and other whispered speech |
| Punctuations | She received an odd text from her brother: ’Emergency @ home; call ASAP! Mom & Dad are worried…#familymatters.’ | 1 = glitches on uncommon punctuations such as # or & 2 = no glitch but incorrect rendering 3 = no glitch and correct pausing and verbalization, e.g. @ as ”at”. |
| Questions | But the Brexit question remains: After all the trials and tribulations, will the ministers find the answers in time? | 1 = intonation pattern incorrect 2 = intonation pattern largely correct but with minor flaws 3 = correct intonation |
| Syntactic Complexities | The movie that De Moya who was recently awarded the lifetime achievement award starred in 2022 was a box-office hit, despite the mixed reviews. | 1 = failure to parse the syntax correctly 2 = parses the syntax largely correctly but the rendering is not entirely natural 3 = parsing correct and rendering natural |
🔼 This table presents the evaluation criteria and example sentences used to assess the emergent abilities of the tested Text-to-Speech (TTS) models across seven different categories: Compound Nouns, Emotions, Foreign Words, Paralinguistics, Punctuations, Questions, and Syntactic Complexities. For each category, three score levels (1, 2, and 3) are defined, representing different levels of success in capturing nuanced aspects of the text, such as appropriate stress and intonation, accurate emotion conveyance, correct pronunciation of foreign words, proper rendering of paralinguistic cues, handling of punctuation, comprehension of questions, and accurate parsing and rendering of complex sentences. Example sentences are provided for each category to illustrate the evaluation criteria.
read the caption
Table 7: Emergent abilities testset by category and evaluation criteria.
Full paper#