TL;DR#
Current LLMs face a critical challenge: the scarcity of high-quality pretraining data. Existing approaches for data augmentation, such as data repetition and upsampling, have limitations. This paper introduces MAGA, a novel method that systematically synthesizes diverse and contextually-rich pretraining data from existing corpora. MAGA addresses this limitation by reformulating existing high-quality text collections into a significantly larger dataset, thereby overcoming the data bottleneck and enabling the training of larger and more powerful LLMs.
MAGA utilizes a two-stage synthesis process involving a large language model and smaller, task-specific tool models. It incorporates a ‘Limited Consistency’ criterion for quality control and investigates the impact of prompt engineering on synthetic training. Experiments demonstrate consistent performance improvements across various model sizes, validating the effectiveness of MAGA in expanding training datasets and maintaining quality. Furthermore, the analysis challenges existing collapse detection metrics, shedding light on the limitations of using validation loss as a sole indicator. This work provides valuable insights and a practical approach for scaling LLMs beyond data limitations.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) and data synthesis. It presents a novel method for expanding training datasets using a lightweight and scalable approach, offering a reliable pathway for scaling models beyond data limitations. The findings highlight the importance of prompt engineering and challenge conventional collapse detection metrics, opening new avenues for future research in synthetic data generation and LLM scaling.
Visual Insights#

🔼 The MAGA framework expands an original corpus using a two-stage synthesis process. First, (genre, audience) pairs are generated for each document. Then, each document is reformulated into 5 new documents based on these pairs. This approach achieves a 3.9x increase in the number of tokens while maintaining diversity in the data.
read the caption
Figure 1: Overview of MAGA framework. Our method expands the original corpus through a two-stage synthesis process. Each document is reformulated to 5 new documents, achieving 3.9× token number expansion while maintaining diversity through massive (genre, audience) pairs.
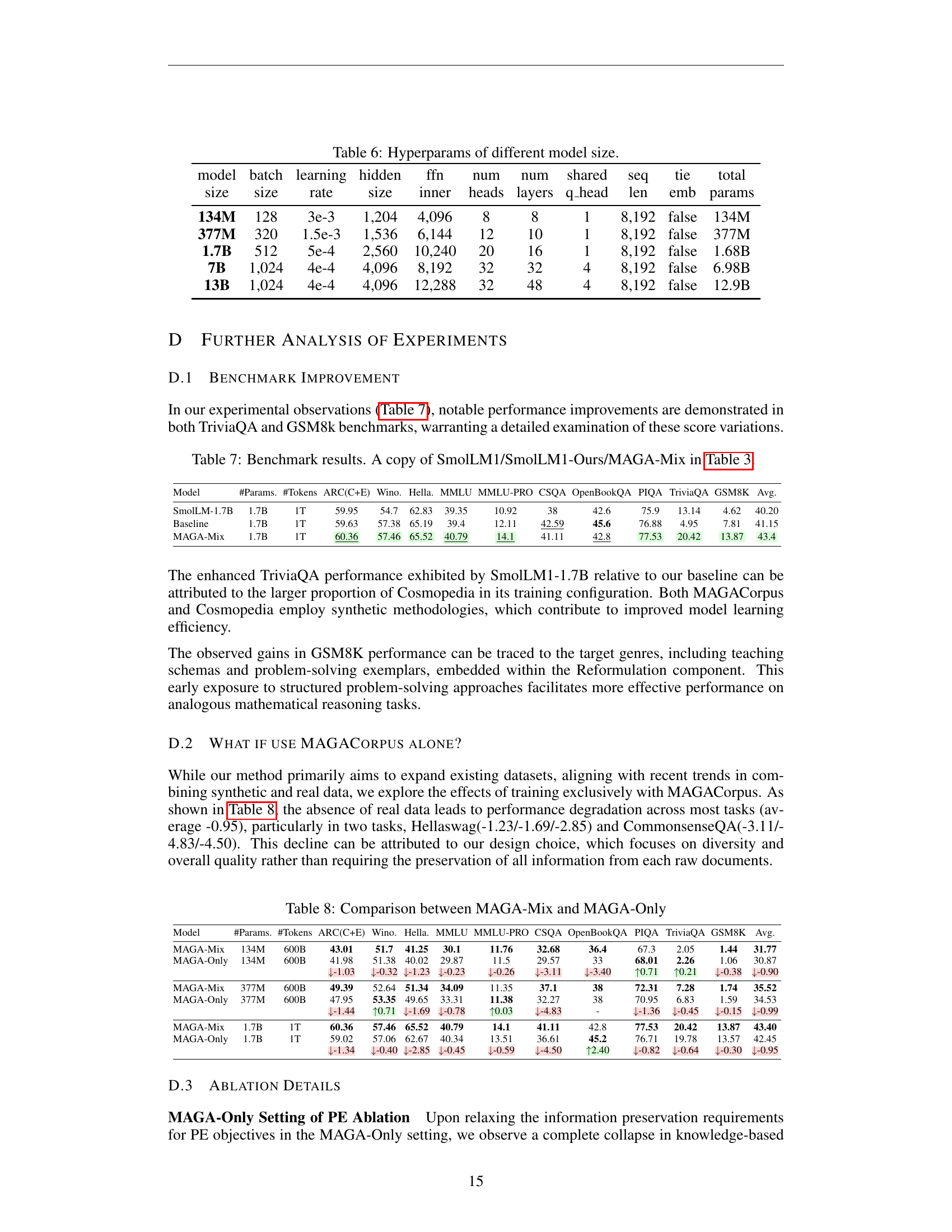
| model | batch | learning | hidden | ffn | num | num | shared | seq | tie | total |
|---|---|---|---|---|---|---|---|---|---|---|
| size | size | rate | size | inner | heads | layers | q_head | len | emb | params |
| 134M | 128 | 3e-3 | 1,204 | 4,096 | 8 | 8 | 1 | 8,192 | false | 134M |
| 377M | 320 | 1.5e-3 | 1,536 | 6,144 | 12 | 10 | 1 | 8,192 | false | 377M |
| 1.7B | 512 | 5e-4 | 2,560 | 10,240 | 20 | 16 | 1 | 8,192 | false | 1.68B |
| 7B | 1,024 | 4e-4 | 4,096 | 8,192 | 32 | 32 | 4 | 8,192 | false | 6.98B |
| 13B | 1,024 | 4e-4 | 4,096 | 12,288 | 32 | 48 | 4 | 8,192 | false | 12.9B |
🔼 This table presents a comparison of the performance of a smaller, more efficient model (SLM) and a larger language model (LLM) on a reformulation quality evaluation task. The evaluation measures the quality of text reformulation, assessing how well each model maintains the original meaning while adapting the text style and focus to different genres and audiences. The table shows the counts of different quality scores (1-5) assigned to the outputs of each model, enabling a direct comparison of their performance in this specific task.
read the caption
Table 1: Performance comparison between SLM and LLM on reformulation quality evaluation.
In-depth insights#
MAGA: Data Synthesis#
The heading ‘MAGA: Data Synthesis’ suggests a method for creating synthetic data using the MAGA framework. This likely involves a two-stage process, starting with genre and audience generation to ensure diversity. The generated pairs are then fed into a large language model (LLM) to reformulate existing text, expanding the dataset. The key innovation lies in the efficiency of the system, using lightweight models and scalable techniques, unlike other methods that rely on large and resource intensive models. This approach tackles the data scarcity problem hindering the scaling of Large Language Models (LLMs). The success depends on maintaining high quality while expanding quantity, which is achieved through prompt engineering and quality control. MAGA’s approach likely addresses challenges of synthetic data collapse by optimizing the balance between textual variation and information preservation. Validation loss analysis might show unusual patterns, as discussed in the paper, possibly requiring a shift from relying solely on traditional evaluation metrics.
Genre-Audience Reformulation#
The concept of ‘Genre-Audience Reformulation’ presents a novel approach to data augmentation for language models. It centers on adaptively expanding existing corpora by reformulating documents to target diverse genres and audiences. This methodology goes beyond simple data repetition or paraphrasing, focusing on creating contextually rich and varied training data that mirrors the diverse ways humans use language. The effectiveness of this approach hinges on the ability to preserve the core knowledge of original documents while enhancing their diversity through systematic reformulation, ensuring the model learns both factual information and nuanced expressions. Careful prompt engineering is crucial to balance textual variation with information preservation, avoiding model collapse or generating low-quality synthetic data. The success of this method depends on the ability to efficiently generate high-quality reformulations at scale, using potentially lightweight models to avoid computational constraints. The ultimate goal is to reliably expand training datasets, improving the capabilities of large language models while mitigating the limitations of high-quality data scarcity.
Model Scaling & Data Limits#
Model scaling and data limits represent a critical juncture in large language model (LLM) development. Scaling model size without sufficient high-quality data leads to diminishing returns, or even model collapse. The paper highlights the scarcity of readily available, high-quality training data, a significant constraint on further scaling. Synthetic data generation, a promising solution, faces challenges such as computational cost, and the risk of producing low-quality or repetitive data that hinder performance. The research underscores the importance of effective data curation and synthesis methods capable of generating diverse and high-quality data. Balancing model size and data quantity is crucial for achieving optimal performance, with strategies such as controlled data repetition proving less effective than carefully crafted synthetic data. This highlights the need for innovative data augmentation techniques that address both efficiency and quality concerns.
Prompt Engineering Effects#
Prompt engineering significantly impacts the performance and behavior of large language models (LLMs). Careful prompt design is crucial for maintaining a balance between flexibility and fidelity in text generation. Overly strict prompts can hinder the LLM’s ability to generate diverse and creative outputs, potentially limiting its capabilities. Conversely, overly relaxed prompts can lead to outputs that deviate significantly from the original input, resulting in factual inaccuracies and reduced quality. The optimal approach appears to be finding a middle ground, allowing for creative exploration while maintaining the core meaning of the original text. The paper’s findings emphasize that prompt engineering is not merely a technical detail but a critical factor influencing both the quality and scalability of LLM-based applications. Further research is needed to fully explore the nuanced interplay between prompt design, LLM architecture, and dataset characteristics.
Synthetic Data Collapse#
Synthetic data, while offering a seemingly limitless source of training data for large language models (LLMs), presents a significant challenge: synthetic data collapse. This phenomenon occurs when the model’s performance on synthetic data improves dramatically, but its ability to generalize to real-world data significantly deteriorates. The root cause is often attributed to the model overfitting the specific patterns and biases present in the synthetic dataset, failing to learn robust and generalizable representations. Preventing collapse requires careful consideration of several factors, including the quality and diversity of the synthetic data generation process, the methods used to detect and mitigate overfitting, and the choice of evaluation metrics. A nuanced approach is crucial, balancing the advantages of scalability offered by synthetic data with the need for maintaining a model’s generalizability to real-world data. Prompt engineering and data augmentation techniques are proving useful in mitigating some aspects of the collapse problem, but further research is needed to fully understand and address this critical limitation in LLM training.
More visual insights#
More on figures

🔼 This figure illustrates the MAGA framework’s implementation details. It begins with a high-quality corpus from which a subset is sampled to serve as input for an LLM that acts as both labeler and judger. This LLM evaluates the quality of data generated by tool models (SLMs). The SLMs are trained iteratively through a two-stage filtering process and then quantized to improve efficiency. The output of this process is the reformulated corpus, created by the improved, quantized SLMs.
read the caption
Figure 2: Implementation details. From a high-quality corpus, we sample a subset to serve as input for the LLM labeler and judger. Through iterative filtering, we train and quantize SLM tool models for each stage to improve inference efficiency, which are used to generate the reformulated corpus.

🔼 This figure displays the training dynamics observed during experiments using different data recipes: EntireSet and Subset. The EntireSet recipe involves training with a full dataset, while the Subset recipe uses a smaller subset. The graphs likely show training curves, plotting metrics like validation loss or accuracy against the number of training tokens processed. The trends revealed in these curves illustrate how the different data strategies impact model performance across various model sizes. Detailed results and analysis of these benchmarks are provided in Appendix D of the paper.
read the caption
Figure 3: The first and last two figures illustrate the training dynamics of EntireSet and SubSet data recipes, respectively. Benchmark details are provided in Appendix D.

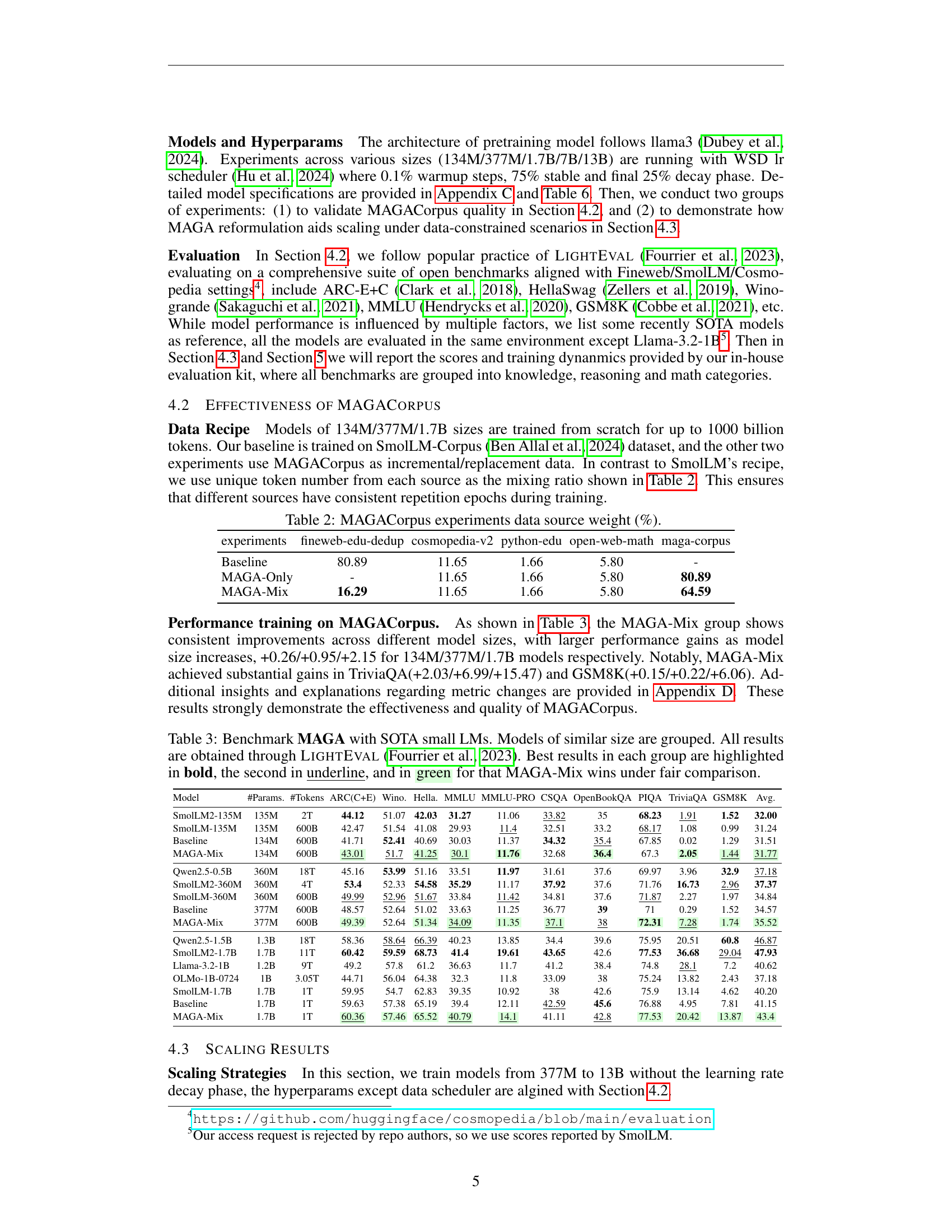
🔼 Figure 4 presents the results of experiments using the MAGA-Mix approach, which combines real and synthetic data for model training. The figure shows training dynamics (scores and validation losses) across different model sizes (377M, 1.7B and 13B parameters) for multiple domains (knowledge, reasoning, math). The key observation is the varying sensitivity of different domains to data repetition. The knowledge domain exhibits greater resilience to data repetition than the reasoning and math domains, where the negative effects of repetition become more pronounced. Different prompt engineering strategies (SLM-Base, SLM-Strict, and SLM-Relaxed) are compared. This comparison helps illustrate how the method’s sensitivity to data repetition changes depending on the prompt engineering strategy used.
read the caption
Figure 4: Benchmark results and validation losses in the MAGA-Mix setting. The sensitivity to data repetition varies across capability domains, with knowledge dimension showing greater resilience.

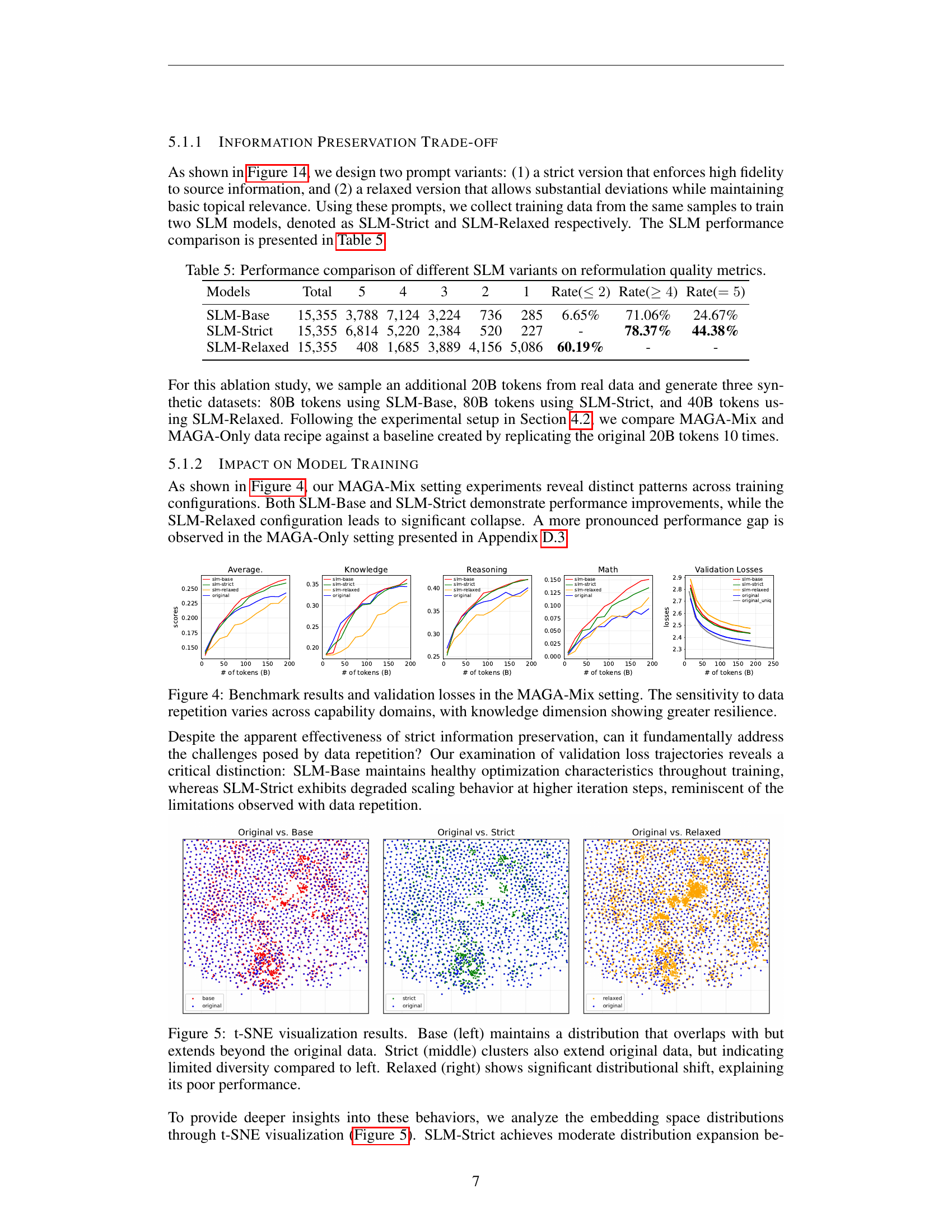
🔼 This figure displays t-SNE visualizations illustrating the distribution of data embeddings generated under three different prompt engineering strategies: Base, Strict, and Relaxed. The Base model shows a distribution that shares some overlap with the original data but also extends beyond it, indicating successful expansion while maintaining data quality. The Strict method produces a distribution that also expands beyond the original but exhibits less diversity than the Base model, suggesting more constrained data generation. The Relaxed approach, however, shows a significantly different distribution compared to both the Base model and the original data, hinting at a substantial shift in data characteristics that is correlated with poor model performance.
read the caption
Figure 5: t-SNE visualization results. Base (left) maintains a distribution that overlaps with but extends beyond the original data. Strict (middle) clusters also extend original data, but indicating limited diversity compared to left. Relaxed (right) shows significant distributional shift, explaining its poor performance.
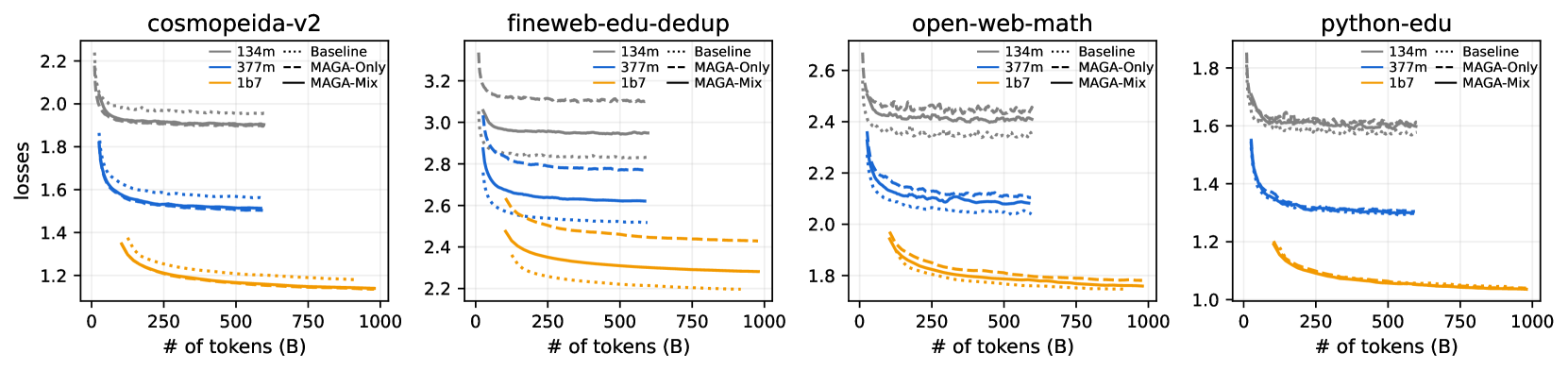
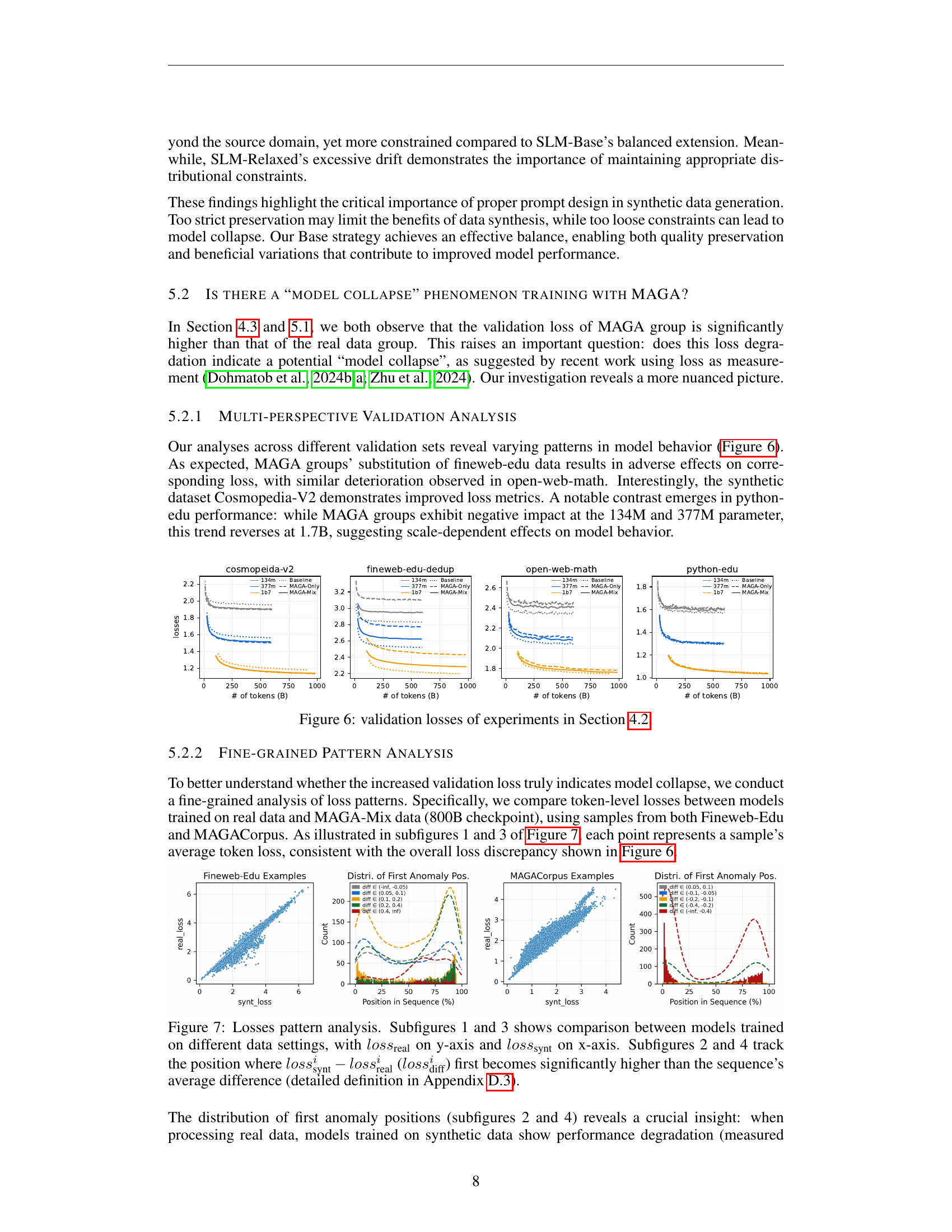
🔼 Figure 6 presents a detailed analysis of validation losses observed during the experiments described in Section 4.2. The plots illustrate the trends of validation loss across different datasets (Fineweb-Edu, Cosmopedia-V2, Open-web-math, and Python-edu) for various model sizes (134M, 377M, and 1.7B parameters). This visualization helps to understand the impact of using the MAGA-Corpus in comparison to baseline models trained solely on the original dataset, providing insights into the effectiveness and potential limitations of MAGA’s synthetic data expansion strategy. The differing trends across datasets showcase dataset-specific characteristics and highlight the complexity of evaluating model performance using solely validation loss.
read the caption
Figure 6: validation losses of experiments in Section 4.2.

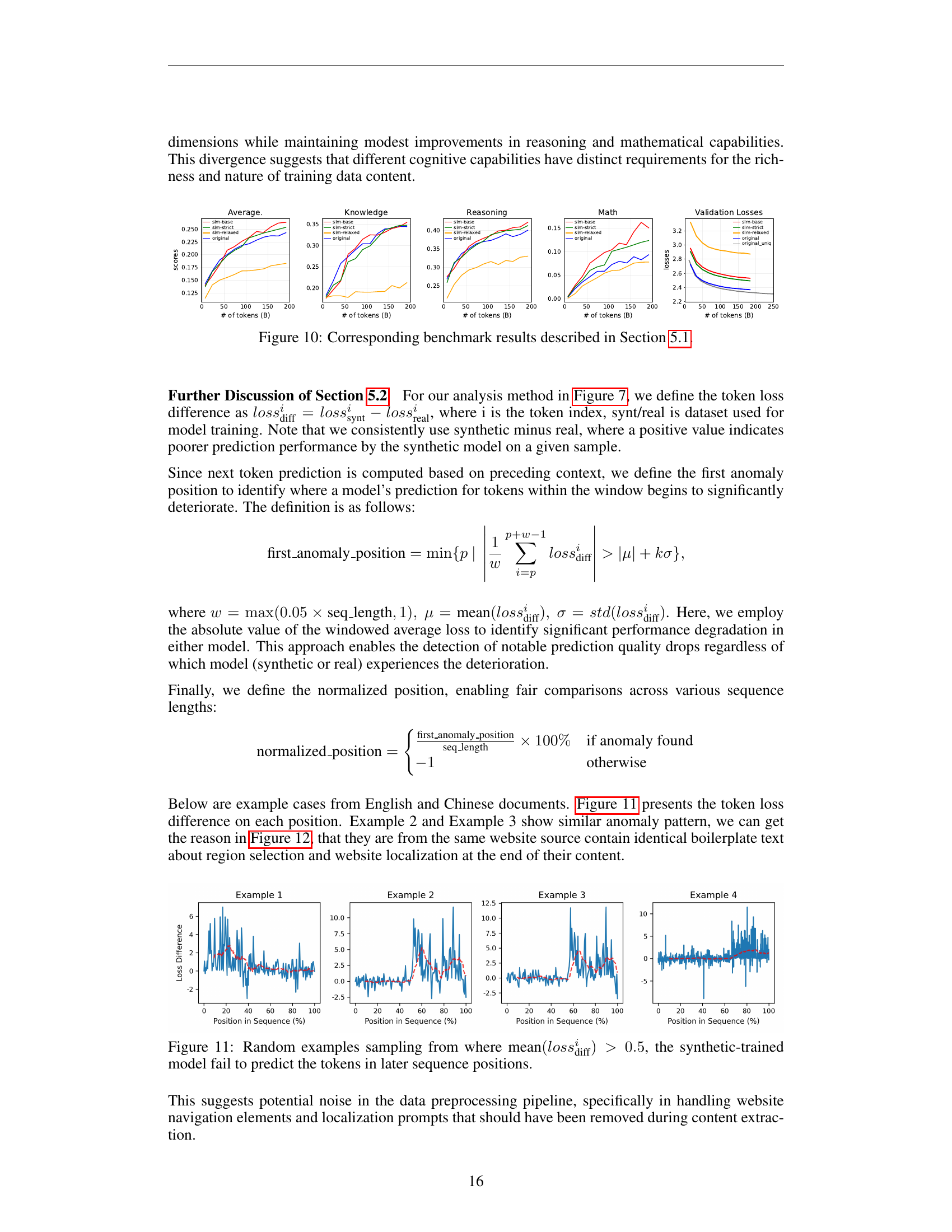
🔼 Figure 7 presents a detailed analysis of token-level loss patterns in models trained on real and synthetic data. Subfigures 1 and 3 compare the loss for each token in the real and synthetic datasets. Subfigures 2 and 4 analyze where the difference between the synthetic and real token loss first surpasses the average difference across a sequence. This analysis helps to understand the model’s behavior and potential issues, such as model collapse, during training on synthetic data.
read the caption
Figure 7: Losses pattern analysis. Subfigures 1 and 3 shows comparison between models trained on different data settings, with lossreal𝑙𝑜𝑠subscript𝑠realloss_{\text{real}}italic_l italic_o italic_s italic_s start_POSTSUBSCRIPT real end_POSTSUBSCRIPT on y-axis and losssynt𝑙𝑜𝑠subscript𝑠syntloss_{\text{synt}}italic_l italic_o italic_s italic_s start_POSTSUBSCRIPT synt end_POSTSUBSCRIPT on x-axis. Subfigures 2 and 4 track the position where losssynti−lossreali𝑙𝑜𝑠subscriptsuperscript𝑠𝑖synt𝑙𝑜𝑠subscriptsuperscript𝑠𝑖realloss^{i}_{\text{synt}}-loss^{i}_{\text{real}}italic_l italic_o italic_s italic_s start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT synt end_POSTSUBSCRIPT - italic_l italic_o italic_s italic_s start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT real end_POSTSUBSCRIPT (lossdiffi𝑙𝑜𝑠subscriptsuperscript𝑠𝑖diffloss^{i}_{\text{diff}}italic_l italic_o italic_s italic_s start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT diff end_POSTSUBSCRIPT) first becomes significantly higher than the sequence’s average difference (detailed definition in Appendix D.3).

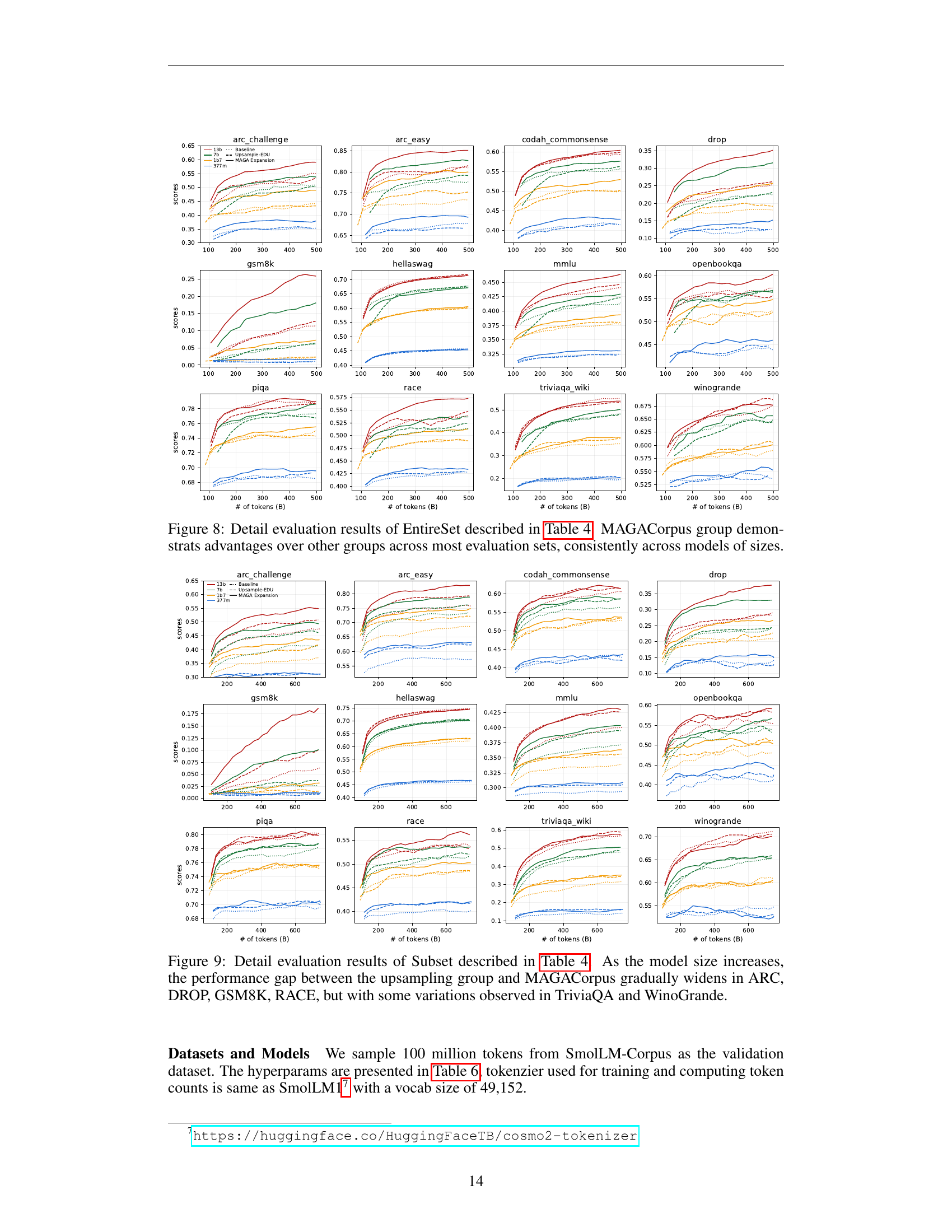
🔼 Figure 8 presents a detailed performance comparison across multiple benchmark datasets. It shows the results of using different training data configurations (EntireSet) as described in Table 4. Notably, it highlights the consistent superior performance of the MAGACorpus across various model sizes (134M, 377M, 1.7B, 7B, and 13B parameters), demonstrating its effectiveness as a training dataset in improving the overall performance of language models.
read the caption
Figure 8: Detail evaluation results of EntireSet described in Table 4. MAGACorpus group demonstrats advantages over other groups across most evaluation sets, consistently across models of sizes.

🔼 Figure 9 presents a detailed performance comparison of different data strategies for training language models, focusing on a subset of data as described in Table 4 of the paper. The graph shows how the performance gap between upsampling and MAGACorpus (the proposed method) changes as model size increases. Specifically, it highlights that the advantage of MAGACorpus over upsampling becomes more pronounced for larger models on certain benchmarks (ARC, DROP, GSM8K, RACE), while the difference is less consistent or even reversed on others (TriviaQA, Winogrande). This suggests that MAGACorpus is a more effective scaling method for language models, particularly when dealing with larger sizes.
read the caption
Figure 9: Detail evaluation results of Subset described in Table 4. As the model size increases, the performance gap between the upsampling group and MAGACorpus gradually widens in ARC, DROP, GSM8K, RACE, but with some variations observed in TriviaQA and WinoGrande.

🔼 Figure 10 presents a detailed comparison of benchmark results across different model variations, specifically focusing on the impact of prompt engineering strategies on model performance. Each subplot likely represents a specific benchmark task (e.g., knowledge, reasoning, or math-related). The x-axis likely represents the amount of training data or another relevant metric, while the y-axis likely represents the model’s performance on the task. By comparing the performance of different model variants (SLM-Base, SLM-Strict, SLM-Relaxed), the figure illustrates the trade-offs involved in balancing flexibility and information preservation during prompt engineering. Differences in the trends across various tasks likely showcase the different sensitivities of model behavior to strict versus relaxed prompt strategies.
read the caption
Figure 10: Corresponding benchmark results described in Section 5.1.

🔼 This figure showcases examples where the mean difference between the loss of the synthetically trained model and the real model exceeds 0.5. The analysis focuses on the token-level loss, revealing that the synthetic model struggles to predict tokens accurately, particularly in later sequence positions. This suggests a potential limitation of the synthetic training data or a model behavior difference when handling noisy data.
read the caption
Figure 11: Random examples sampling from where mean(lossdiffi)>0.5mean𝑙𝑜𝑠subscriptsuperscript𝑠𝑖diff0.5\text{mean}(loss^{i}_{\text{diff}})>0.5mean ( italic_l italic_o italic_s italic_s start_POSTSUPERSCRIPT italic_i end_POSTSUPERSCRIPT start_POSTSUBSCRIPT diff end_POSTSUBSCRIPT ) > 0.5, the synthetic-trained model fail to predict the tokens in later sequence positions.

🔼 Figure 12 presents example text excerpts from the Fineweb-Edu dataset that exhibit loss patterns similar to those illustrated in Figure 11. Specifically, it highlights instances where the synthetically trained model demonstrates significantly higher loss compared to the model trained on real data. These examples are visually presented, with the higher-loss segments of text marked in red, thereby providing a visual correlation between the model’s performance and the characteristics of specific text samples within the Fineweb-Edu dataset.
read the caption
Figure 12: Corresponding cases sampled from Fineweb-Edu, which align with the loss patterns shown in Figure 11, with higher loss by synthetic-trained model highlighted in red.

🔼 Figure 13 shows examples of Chinese text samples where a synthetically trained language model exhibits higher prediction loss compared to a model trained on real data. The red highlighting indicates segments with the elevated loss. This visualization helps illustrate the challenges in achieving perfect parity between synthetic and real data in model training. It suggests that even with well-designed synthetic data generation methods, there can still be disparities that lead to varying performance on different text samples. These discrepancies are further analyzed in Section 5.2 of the paper to explore potential causes such as differences in data distributions and model learning strategies.
read the caption
Figure 13: Chinese corpus samples with higher loss by synthetic-trained model in red.
Full paper#