TL;DR#
Large Language Models (LLMs) are powerful but heavily reliant on prompt engineering. While content optimization is widely studied, the impact of prompt formatting remains under-explored. Existing methods often fail to fully leverage the potential of LLMs due to their inability to effectively handle the complex interplay between content and format. This limitation leads to suboptimal performance and hinders real-world applications.
This paper introduces Content-Format Integrated Prompt Optimization (CFPO), a novel method that simultaneously optimizes both prompt content and formatting. CFPO uses natural language mutations to explore content variations and a dynamic format exploration strategy to systematically evaluate different format options. Experiments across multiple open-source LLMs and tasks demonstrate that CFPO achieves significant performance gains compared to methods focusing solely on content optimization, highlighting the importance of an integrated approach.
Key Takeaways#
Why does it matter?#
This paper is important because it highlights the often-overlooked role of prompt formatting in LLM performance. By introducing a novel method for jointly optimizing prompt content and format, it offers a practical, model-agnostic approach to significantly enhance LLM performance. This opens new avenues for research into prompt engineering and has implications for improving the effectiveness of LLMs in real-world applications. Its model-agnostic approach is especially valuable, making it easily adaptable to various LLM models and tasks.
Visual Insights#

🔼 This figure demonstrates the impact of prompt formatting on Large Language Model (LLM) performance. Panel (A) shows how two different LLMs perform differently across various formats on the GSM8K task, revealing significant model-specific biases. Panel (B) illustrates the complex interplay between content and format by showing the performance of seven different prompt contents with 24 different formats, demonstrating that no single format is universally superior.
read the caption
Figure 1: The crucial role of prompt formatting and its interaction with content. (A): Model-specific format biases: Illustrates the performance sensitivity of two LLMs to different format styles on the GSM8K task, showing substantial variability in the effectiveness of 10 randomly selected formats. (B): For seven different prompt contents evaluated across 24 distinct formats, performance variations show the complex, interdependent relationship between prompt content and structure, demonstrating that no single format universally maximizes effectiveness.
| Method | Mistral-7B-v0.1 | LLaMA-3.1-8B | LLaMA-3-8B-Instruct | Phi-3-Mini-Instruct |
| GSM8K | ||||
| Baseline (1-shot cot) | 36.85 | 50.03 | 74.00 | 83.45 |
| Baseline (8-shot cot) | 38.21 | 51.02 | 73.46 | 85.75 |
| GRIPS | 39.04 | 50.27 | 74.53 | 83.47 |
| APE | 40.33 | 52.39 | 75.13 | 83.85 |
| ProTeGi | 45.72 | 54.74 | 75.36 | 84.84 |
| SAMMO | 43.82 | 54.74 | 75.89 | 84.76 |
| CFPO (Ours) | 53.22 | 63.38 | 80.74 | 89.16 |
| MATH-500 | ||||
| Baseline (1-shot cot) | 4.60 | 10.58 | 12.20 | 12.60 |
| Baseline (4-shot cot) | 10.20 | 23.40 | 14.00 | 40.40 |
| GRIPS | 13.40 | 15.80 | 23.60 | 10.80 |
| APE | 11.60 | 12.80 | 22.80 | 30.60 |
| ProTeGi | 10.80 | 17.00 | 18.40 | 28.80 |
| SAMMO | 12.20 | 15.40 | 25.80 | 42.40 |
| CFPO (Ours) | 14.80 | 26.99 | 33.33 | 44.20 |
| ARC-Challenge | ||||
| Baseline | 67.15 | 73.81 | 75.94 | 84.39 |
| GRIPS | 77.05 | 77.90 | 79.61 | 87.46 |
| APE | 75.85 | 77.05 | 78.67 | 87.63 |
| ProTeGi | 76.54 | 77.22 | 79.86 | 87.54 |
| SAMMO | 77.22 | 77.13 | 79.86 | 87.03 |
| CFPO (Ours) | 79.35 | 78.50 | 80.63 | 88.23 |
| Big-Bench Classification | ||||
| Baseline | 56.00 | 64.00 | 70.00 | 54.00 |
| GRIPS | 86.00 | 67.00 | 84.00 | 69.00 |
| APE | 73.00 | 65.00 | 60.00 | 63.00 |
| ProTeGi | 83.00 | 81.00 | 82.00 | 76.00 |
| SAMMO | 86.00 | 80.00 | 86.00 | 78.00 |
| CFPO (Ours) | 94.00 | 90.00 | 91.00 | 87.00 |
🔼 This table presents the main quantitative results of the experiments conducted in the paper. It shows the performance comparison between CFPO (the proposed method) and several baseline methods across four different tasks: GSM8K (math reasoning), MATH500 (math reasoning), ARC-Challenge (multiple-choice commonsense reasoning), and Big-Bench Classification (classification). The results are presented separately for each of the four tasks, indicating the accuracy achieved by each model on each task. Different LLMs were used, including Mistral-7B-v0.1, LLaMA-3.1-8B, LLaMA-3-8B-Instruct, and Phi-3-Mini-Instruct. This allows for an evaluation of the method’s performance under various conditions and LLMs.
read the caption
Table 1: Main results on math reasoning tasks and commonsense reasoning tasks.
In-depth insights#
Prompt Format Bias#
Prompt format bias, a critical yet often overlooked aspect of large language model (LLM) interaction, refers to the disproportionate impact of prompt formatting choices on model performance. Different formats, even those conveying the same information, can lead to vastly different outcomes. This bias arises from the internal mechanisms of LLMs, which process textual input and structure in specific ways. Understanding and mitigating prompt format bias is crucial for building robust and reliable LLM applications. Failing to consider it can lead to inconsistent results and hinder the generalizability of LLM-based systems. Research should focus on developing techniques to identify, quantify, and address format bias. This might involve developing standardized formatting guidelines, creating model-agnostic prompt optimization strategies, or exploring methods to make LLMs less sensitive to variations in prompt structure. Addressing prompt format bias is essential for unlocking the full potential of LLMs and ensuring their reliable performance in diverse real-world applications.
CFPO Framework#
The CFPO framework, as conceived in the research paper, presents a novel approach to prompt optimization for Large Language Models (LLMs). Its core innovation lies in the integrated and iterative optimization of both prompt content and format, a departure from existing methods that primarily focus on content alone. This integrated strategy acknowledges the interdependence of content and format, recognizing that optimal content may vary depending on the formatting style. The framework employs distinct yet coordinated strategies for optimizing these two dimensions. Content optimization leverages case-diagnosis and Monte Carlo sampling, refining the prompt content using feedback and variations, while format optimization uses a dynamic exploration strategy and LLM-assisted generation of novel formats to identify the most effective presentation style. This iterative process of refinement allows CFPO to achieve superior performance compared to methods focusing solely on content or employing a less sophisticated format exploration.
Format Optimization#
The research paper section on ‘Format Optimization’ likely details methods for improving large language model (LLM) performance by enhancing prompt formatting. This goes beyond optimizing just the textual content of prompts and delves into the structural aspects. The authors probably explore various formatting strategies, such as using different delimiters, structural templates (e.g., markdown, JSON), or visual layouts (e.g., bullet points, tables). A key aspect is the interaction between content and format, meaning that the optimal format might be highly dependent on the specific content of the prompt. The methodology might involve an iterative refinement process, where the system dynamically evaluates different formats and selects those that yield better performance, potentially using reinforcement learning or other optimization techniques. A significant contribution may be the development of a structured prompt template, designed to systematically organize and categorize prompt components for optimal format and content interaction. This framework likely facilitates targeted optimization by allowing for adjustments across different formatting dimensions. The results section might show that a content-format integrated approach leads to substantial performance improvements in LLMs compared to methods focused solely on content optimization, highlighting the often-overlooked role of prompt formatting in achieving optimal LLM outputs.
Ablation Experiments#
Ablation experiments are crucial for understanding the contribution of individual components within a complex system. In the context of a research paper, ablation studies systematically remove or disable parts of the proposed model or method to observe the impact on overall performance. This helps isolate the effects of specific features and determine their relative importance. For instance, if a paper proposes a novel prompt optimization technique, ablation experiments might involve removing certain modules (e.g., format optimization) to measure the performance drop. By comparing the full model’s performance to the ablated versions, researchers can quantify the contribution of each removed component. This provides strong evidence for the effectiveness and necessity of each part, bolstering the claims made by the authors. Furthermore, well-designed ablation studies can reveal unexpected interactions between different parts of the system, highlighting areas where improvements could be made or alternative designs explored. Ultimately, ablation experiments are a powerful tool for rigorous evaluation and build confidence in the claims made by the research.
Future of Prompt Eng.#
The future of prompt engineering is likely to be characterized by a shift from manual, expert-driven approaches to more automated and intelligent methods. This will involve leveraging advanced machine learning techniques, such as reinforcement learning and evolutionary algorithms, to optimize prompt design and generation at scale. We can also expect further research into prompt decomposition and standardization, creating reusable modules and templates for different tasks and domains. The development of model-agnostic prompt optimization techniques will be crucial, enabling adaptation across various LLMs without model-specific tuning. Furthermore, the field will likely focus on incorporating user feedback and preferences directly into the optimization process for personalized and more effective prompts. This user-centric approach will be key to creating truly interactive and intuitive interfaces for LLMs. Explainability and interpretability of optimized prompts will also be a major focus, facilitating debugging and understanding the reasoning behind LLM outputs. Lastly, research into prompt security and safety will become increasingly important, mitigating potential vulnerabilities and biases in prompts and ensuring the responsible development and deployment of LLMs.
More visual insights#
More on figures

🔼 This figure illustrates the iterative process of Content-Format Integrated Prompt Optimization (CFPO). The pipeline starts with Component-wise Content Optimization, which uses case-diagnosis and Monte Carlo sampling to generate variations of the prompt content. These content variations are then passed to the Format Optimization stage where the best-performing format is selected for each content variation using a scoring system and an LLM-assisted method. The yellow dashed line highlights the use of an LLM optimizer to guide the optimization process. This figure shows a single iteration of this cycle.
read the caption
Figure 2: Illustration of the CFPO pipeline within a single iteration round. In the initial Component-wise Content Optimization stage, case-diagnosis and Monte-Carlo sampling are employed for content mutation. Subsequently, the Format Optimization stage identifies the most suitable format for each content candidate. The yellow dashed line indicates where the LLM optimizer is employed to guide the optimization process.

🔼 Figure 3 illustrates the structured prompt template used in the Content-Format Integrated Prompt Optimization (CFPO) framework. The template breaks down a prompt into distinct, functional components: Task Instruction, Task Detail, Output Format, and Examples. These components are then organized using a Query Format (which dictates how examples and queries are presented) and a Prompt Renderer (which combines all the components into a single, coherent prompt string). This structured approach enables targeted optimization of both content and format, enhancing LLM performance. The figure provides a visual example showcasing how the template organizes these components and the resulting rendered prompt.
read the caption
Figure 3: An illustrative example of our Structured Prompt Template. This template systematically organizes the prompt into distinct components, each serving a specific functional role. When formulating a prompt, the template first employs a Query format to present examples and queries, and then integrates all content components via the Prompt Renderer to construct the comprehensive prompt string.

🔼 Figure 4 illustrates the building blocks for creating various prompt formats used in the Content-Format Integrated Prompt Optimization (CFPO) framework. It shows the initial set of ‘Prompt Renderer’ formats (e.g., plain text, markdown, HTML, LaTeX, XML, JSON) that define the overall prompt structure. It also displays the ‘Query Format’ options (e.g., Markdown-Ins-Res, Role-Mapping-Format, COT-Question-Answer, Multi-choice) which dictate the arrangement of in-context examples and queries. The final prompt format is a combination of one Prompt Renderer and one Query Format. This modular approach allows for systematic exploration of diverse prompt structures.
read the caption
Figure 4: Built-in formats and rendering effects in our initial format pool. The final format configuration is achieved by selecting and combining elements from both the Prompt Renderer and the Query Format categories.

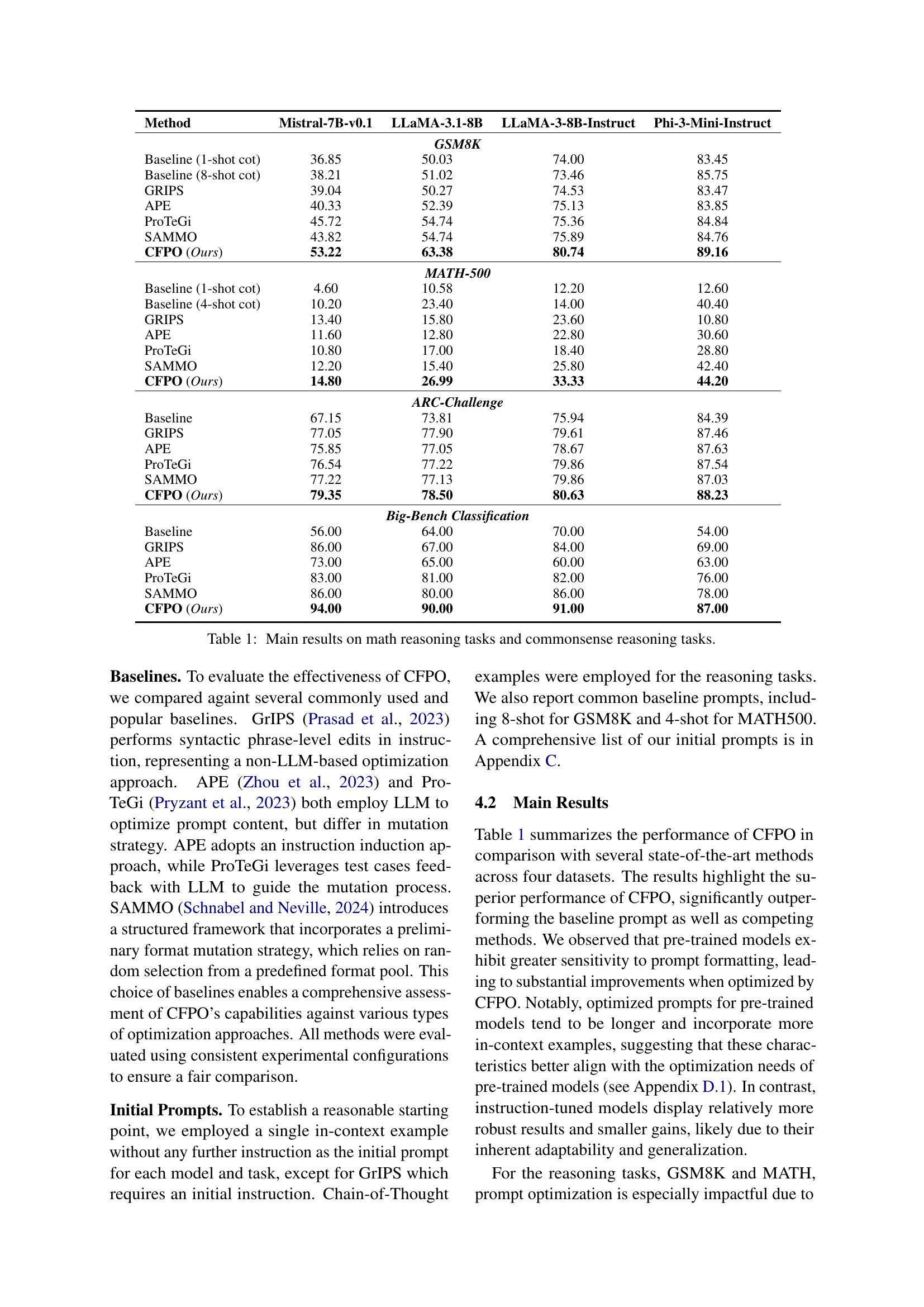
🔼 Figure 5 provides a detailed analysis of the relationship between the number of in-context examples and the length of prompts used in different tasks and models. The chart visually compares four datasets (GSM8K, MATH500, ARC-Challenge, and Big-Bench Classification) across four different LLMs (Mistral-7B-v0.1, LLaMA-3.1-8B, LLaMA-3-8B-Instruct, and Phi-3-Mini-Instruct). It reveals that pre-trained models (like LLaMA-3.1-8B) tend to perform better with longer prompts and more in-context examples, unlike instruction-tuned models (like Phi-3-Mini-Instruct) which show less dependence on these factors.
read the caption
Figure 5: Overview of in-context examples and text lengths for various tasks and models.
More on tables
| Task | Method | LLaMA-3.1-8B | LLaMA-3-8B-Instruct |
| GSM8K | ProTeGi | 54.74 | 75.36 |
| CFPOc | 58.07 | 77.71 | |
| CFPOc+Format | 61.94 | 79.30 | |
| CFPO | 63.38 | 80.74 | |
| BBC | ProTeGi | 81.00 | 82.00 |
| CFPOc | 85.00 | 85.00 | |
| CFPOc+Format | 88.00 | 89.00 | |
| CFPO | 90.00 | 91.00 |
🔼 This ablation study analyzes the contributions of the format and content optimizers within the CFPO framework. Three variations are compared: the full CFPO model (which optimizes both content and format iteratively), CFPOc (which only optimizes content with a fixed, initial format), and CFPO+Format (which optimizes content first, then performs a separate format optimization step). The results illustrate the relative importance of each component to CFPO’s overall performance, demonstrating the synergistic effect of optimizing content and format together.
read the caption
Table 2: Ablation study of the format optimizer and content optimizer. CFPOc𝑐{c}italic_c performs content optimization with a fixed format. CFPOc𝑐{c}italic_c+Format performs format optimization after content optimization.
| Task | Method | LLaMA-3.1-8B | LLaMA-3-8B-Instruct |
| GSM8K | w/o Format Gen | 62.70 | 78.85 |
| with Format Gen | 63.38 | 80.74 | |
| BBC | w/o Format Gen | 88.00 | 87.00 |
| with Format Gen | 90.00 | 91.00 |
🔼 This table presents the results of an ablation study investigating the impact of using an LLM-assisted format generation process within the CFPO framework. It compares the performance of CFPO with and without the LLM-based format generation on two tasks: GSM8K and Big-Bench Classification (BBC). The comparison shows the improvement achieved by dynamically generating new formats during the optimization process versus using only pre-defined formats. The performance metric is likely accuracy or a similar metric reflecting the effectiveness of the prompt. This table demonstrates the importance of the LLM-assisted format generation component in CFPO.
read the caption
Table 3: Impact of format generation during prompt optimization.
| Task | Method | LLaMA-3.1-8B | LLaMA-3-8B-Instruct |
| Random | 62.40 | 78.82 | |
| GSM8K | UCT() | 63.23 | 79.08 |
| UCT(ours) | 63.38 | 80.74 | |
| Random | 85.00 | 87.00 | |
| BBH | UCT() | 86.00 | 88.00 |
| UCT(ours) | 90.00 | 91.00 |
🔼 This table presents the results of an ablation study comparing different format selection strategies used in the Content-Format Integrated Prompt Optimization (CFPO) framework. Specifically, it contrasts the performance of CFPO using its proposed Upper Confidence Bound (UCT) algorithm for format selection against two alternative approaches: a random selection of formats and a greedy selection strategy (using UCT with α = 0). The results are shown for two different tasks, GSM8K (a reasoning task) and Big-Bench (a classification task). The comparison highlights the effectiveness of the UCT-based approach in balancing exploration and exploitation during the search for optimal prompt formats.
read the caption
Table 4: Impact of different format selection strategies during optimization.
Full paper#