TL;DR#
Scaling robot learning is hindered by the need for massive high-quality datasets and real-time, high-fidelity evaluation. Current generative models often struggle with computational efficiency or fail to handle the diverse settings of real-world robotics. Furthermore, existing methods for video generation can be computationally expensive, making real-time applications challenging.
The paper introduces Heterogeneous Masked Autoregression (HMA), a new approach that tackles these issues. HMA uses heterogeneous pre-training from diverse robotic embodiments, domains, and tasks to learn a generalizable action-video dynamic model. Masked autoregression enables efficient video prediction, significantly improving speed and visual fidelity. Experiments demonstrate that HMA achieves better visual fidelity and controllability than state-of-the-art models with a 15x speed improvement, making real-time applications in robotics possible. HMA can generate synthetic data and serve as a video simulator for efficient policy evaluation.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical bottleneck in robotics: the need for massive, high-quality datasets and real-time evaluation. The proposed method, Heterogeneous Masked Autoregression (HMA), offers a novel and efficient solution by leveraging masked autoregression and heterogeneous pre-training. This opens new avenues for developing more general and efficient robotic video generation models, which has far-reaching implications for advancing robotics research. The improved efficiency, 15x faster than previous methods, makes real-time applications feasible.
Visual Insights#
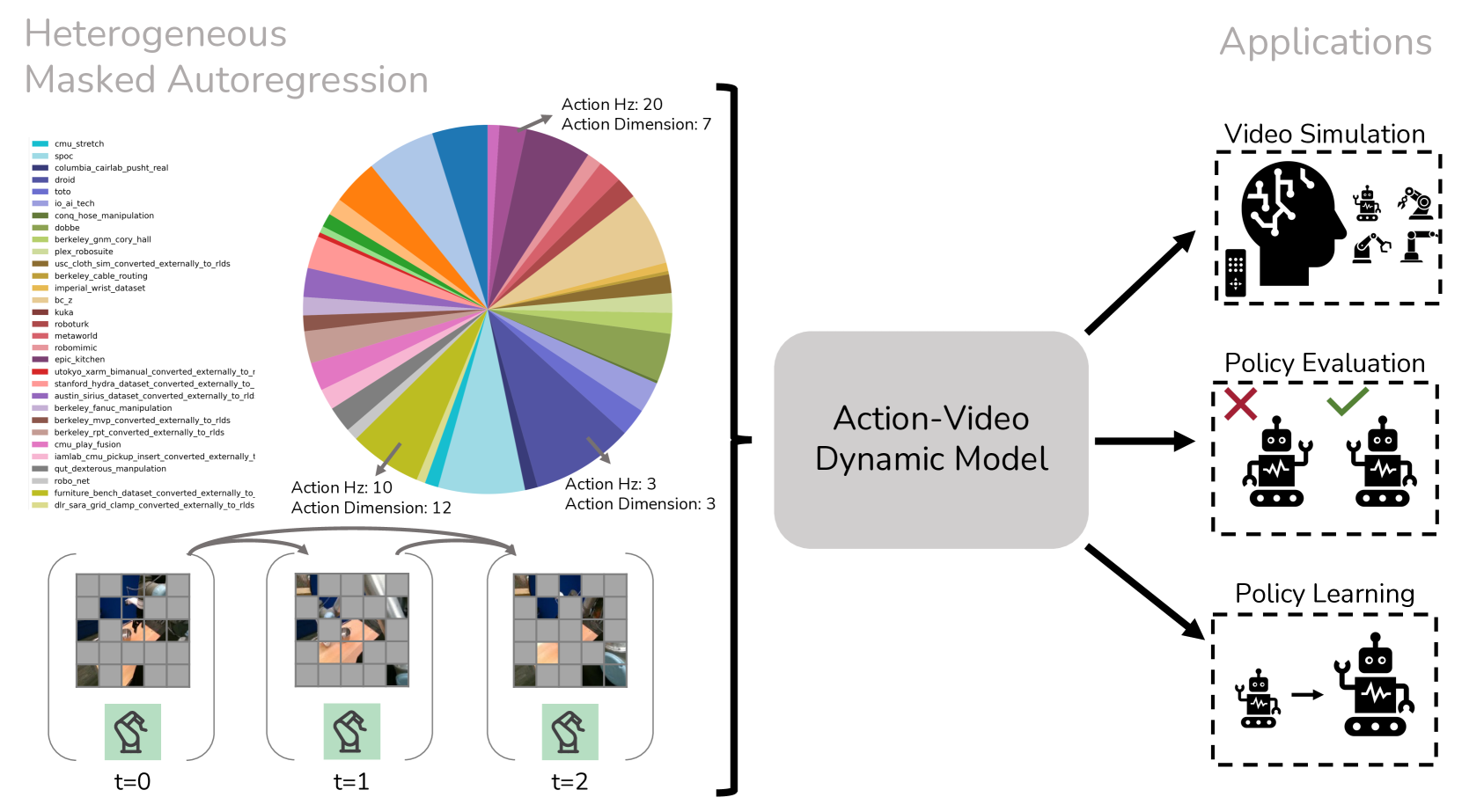
🔼 The figure illustrates the architecture and workflow of the Heterogeneous Masked Autoregression (HMA) model. HMA leverages a diverse dataset of over 3 million video trajectories from 40 different robot embodiments to learn a comprehensive action-video dynamics model. The pre-training phase employs masked autoregression to predict the next set of tokens (visual and action), effectively capturing the complex interactions between robot actions and resulting video observations. Following pre-training, this versatile model finds applications in various robotics tasks: generating realistic video simulations, evaluating robot policies (by simulating the consequences of different actions), creating synthetic training data, and even acting as a direct imitation policy.
read the caption
Figure 1: Action-Video Dynamics Model from Heterogeneous Robot Interactions. HMA utilizes heterogeneous datasets comprising over 3 million trajectories (videos) from 40 distinct embodiments to pre-train a full dynamics model with next-set-of-token predictions using masked autoregression. After pre-training, the resulting action-video dynamics model is versatile, supporting applications such as video simulation, policy evaluation, synthetic data generation, and direct adoption as an imitation policy.
| Model | Method | Parameters (M) | FPS |
| IRASim-XL | DiT | 679 | 0.28 |
| IRASim-XL, amortized | DiT | 679 | 0.58 |
| HMA-Base | MaskGIT | 44 | 22.72 |
| HMA-XL | MaskGIT | 679 | 4.38 |
| HMA-Base | MAR | 96 | 4.44 |
| HMA-XL | MAR | 741 | 2.01 |
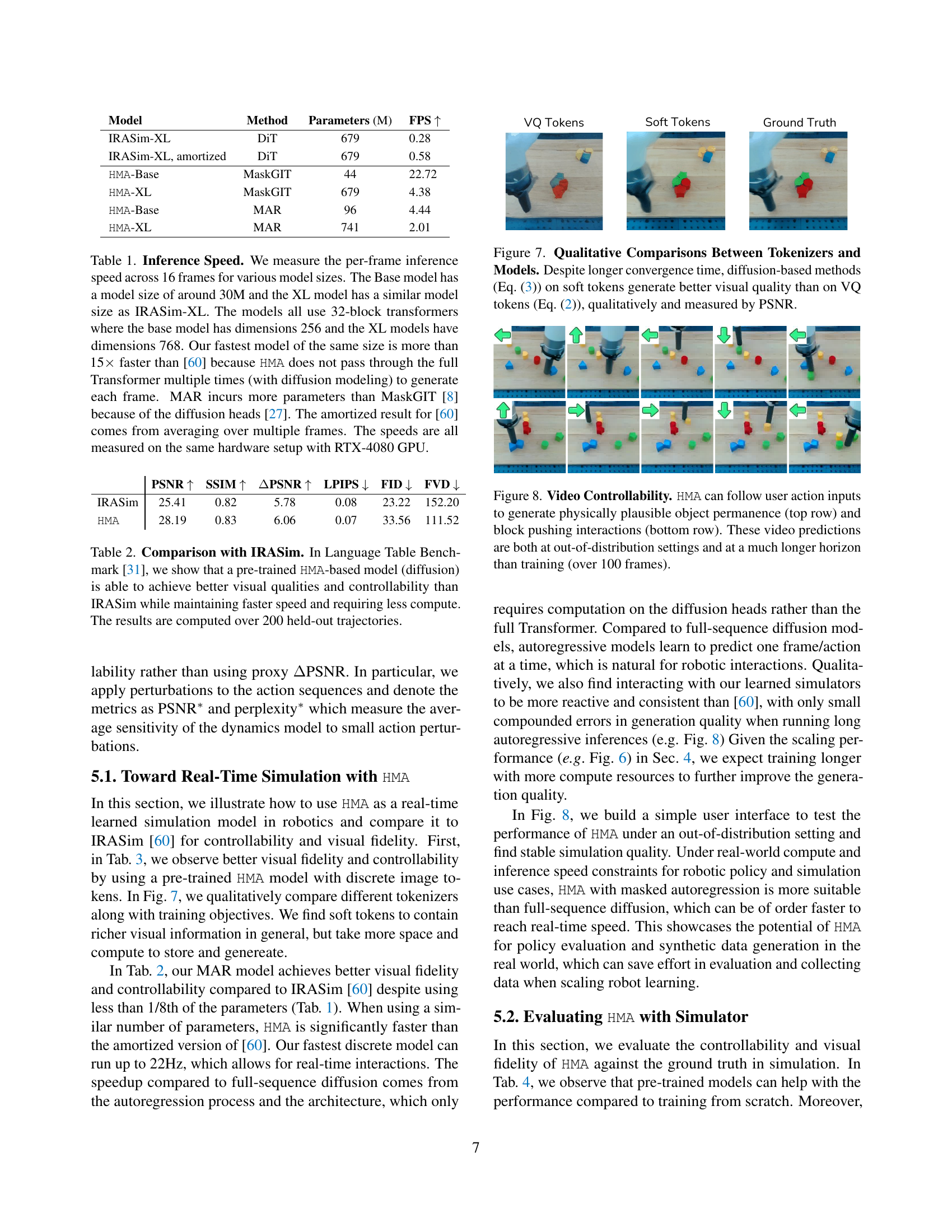
🔼 This table compares the inference speed of different models, highlighting the significant speed advantage of the proposed HMA model. It breaks down the inference speed (frames per second, FPS) for various model sizes (Base and XL) across different methods (MaskGIT and MAR). The table shows that HMA is substantially faster than a comparable model from the literature (IRASim-XL), particularly when using the MaskGIT method. The differences in speed are attributed to HMA’s architecture, which avoids repeated passes through the Transformer during generation, unlike diffusion-based models. The table also notes the parameter counts for each model and that all results were obtained using the same hardware configuration (RTX-4080 GPU).
read the caption
Table 1: Inference Speed. We measure the per-frame inference speed across 16 frames for various model sizes. The Base model has a model size of around 30M and the XL model has a similar model size as IRASim-XL. The models all use 32-block transformers where the base model has dimensions 256 and the XL models have dimensions 768. Our fastest model of the same size is more than 15×\times× faster than [60] because HMA does not pass through the full Transformer multiple times (with diffusion modeling) to generate each frame. MAR incurs more parameters than MaskGIT [8] because of the diffusion heads [27]. The amortized result for [60] comes from averaging over multiple frames. The speeds are all measured on the same hardware setup with RTX-4080 GPU.
In-depth insights#
HMA: A Novel Approach#
HMA, as a novel approach, presents a significant advancement in robotic video modeling. Its core innovation lies in heterogeneous masked autoregression, enabling the model to learn from diverse robotic datasets despite differences in action spaces and frequencies. This addresses a major bottleneck in scaling robot learning by generating high-fidelity, real-time video simulations from heterogeneous data. The use of masked autoregression offers a significant speed advantage over diffusion-based methods, making real-time interaction feasible. Post-training applications are particularly noteworthy, demonstrating HMA’s versatility in policy evaluation, data generation, and direct policy implementation. While challenges remain in perfect controllability and handling extreme complexities, HMA’s scalability and efficiency showcase its potential to transform robot learning and simulation.
Action Heterogeneity#
The concept of ‘Action Heterogeneity’ in robotics highlights the diverse nature of actions across different robots. Robots vary significantly in their physical capabilities, control mechanisms, and operational domains. This diversity translates into heterogeneous action spaces, meaning robots may have different numbers of degrees of freedom, varying action frequencies, and use different control signals. Addressing this heterogeneity is crucial for building general-purpose world models and policies. A unified framework is needed to represent and handle the diverse action spaces, enabling the learning of models capable of simulating and generating actions for various robotic platforms. This involves integrating action information into a shared latent space, allowing for effective transfer learning and seamless interaction across embodiments. Modularized architectures are key, such as using separate encoder and decoder modules per robot while sharing a central processing unit that generalizes the dynamics. This approach maximizes adaptability while minimizing training data and computational overhead for each new robot.
Masked Autoregression#
Masked autoregression, as applied in this research, is a powerful technique for modeling action-video dynamics. Its core strength lies in efficiently handling the complexities of sequential data, such as those found in robotics videos where actions and observations are interlinked. By masking parts of the input sequence during training and predicting the masked portions, the model learns to capture temporal dependencies and generate high-quality predictions. This approach is particularly well-suited for real-time applications, where computational efficiency is paramount. Furthermore, the use of masked autoregression allows for the integration of heterogeneous data, handling variations in action spaces and frequencies from different robots. This leads to more robust and generalizable models. The combination of masked autoregression with heterogeneous data greatly enhances the ability to build efficient and versatile robotic video simulators, supporting a wide range of applications like policy evaluation and synthetic data generation.
Scaling Behaviors#
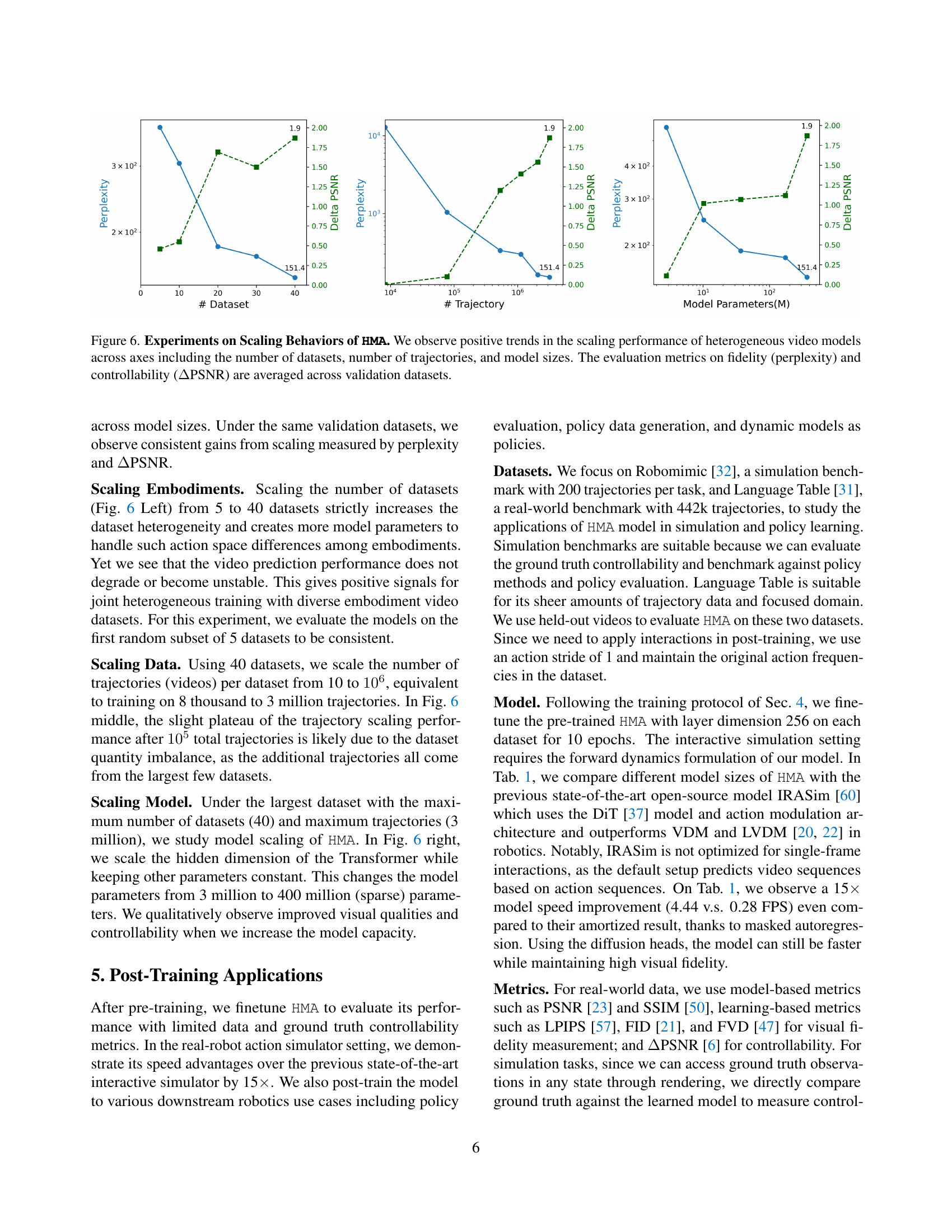
The section on “Scaling Behaviors” in the research paper is crucial for assessing the generalizability and practical applicability of the proposed Heterogeneous Masked Autoregression (HMA) model. It investigates how the model’s performance changes across various dimensions: the number of datasets (embodiments), the size of the datasets (number of trajectories), and the model’s complexity (number of parameters). Positive scaling trends across these dimensions indicate that HMA is robust and capable of handling increasingly diverse and large-scale data. The consistent performance gains as the number of datasets and trajectories increase highlight the model’s ability to learn generalizable representations from heterogeneous data. Furthermore, the improvements with increased model size suggest that scaling up the model’s capacity can further enhance its performance, potentially achieving even higher fidelity and controllability. These scaling experiments demonstrate not just the performance of HMA on a particular dataset, but also its potential for real-world applications where data diversity and scale are significant factors. The results provide strong evidence that the HMA model is not overfitting to specific datasets, but rather learning robust and transferable representations of action-video dynamics.
Future of HMA#
The future of Heterogeneous Masked Autoregression (HMA) appears bright, given its demonstrated success in handling action-video dynamics. Real-time performance is a significant achievement, opening doors for direct use in robotics, eliminating the bottleneck of slow simulation. Further research should focus on improving the model’s controllability, particularly addressing limitations observed with limited training data and complex tasks. Scaling to even larger datasets and exploring diverse robotic applications remains key. Addressing limitations in modeling deformable objects and complex physics interactions would broaden the system’s applicability. Integrating HMA with advanced planning algorithms and exploring its potential for generating high-fidelity synthetic data for training complex robotic policies are also promising directions. Finally, investigating the use of soft tokens beyond visual generation could significantly enhance the system’s overall capabilities and efficiency. Addressing these research opportunities would solidify HMA’s position as a leading technology in robotics simulation and learning.
More visual insights#
More on figures

🔼 Figure 2 illustrates the versatility of masked autoregression in modeling robot dynamics. It shows how a single framework can address various robotics problems, such as policy learning (predicting future actions given past observations and actions), forward dynamics (predicting future observations given past observations and actions), passive dynamics (predicting future observations given only past observations), and full dynamics (jointly predicting future observations and actions). This unified approach allows the model to handle different tasks and scenarios in robotics through a common architecture.
read the caption
Figure 2: Dynamics Model. Masked autoregression in the dynamics model generalizes multiple problem settings including policy learning, forward and passive dynamics, and full dynamics.

🔼 The figure illustrates the architecture of the Heterogeneous Masked Autoregression (HMA) model. The model processes both video and action sequences from various robotic embodiments. Each embodiment has a dedicated ‘stem’ (action encoder) and ‘head’ (action decoder), which map the embodiment-specific action data into a shared latent space. The core of the model is a spatial-temporal transformer (’trunk’) that processes the shared latent representations to predict both future video frames and actions. The spatial attention mechanism operates bi-directionally on masked and unmasked tokens for both video and action, while the temporal attention mechanism is causal (only considering past information). The modular design allows for easy adaptation to new embodiments by simply training new stem and head components without modifying the trunk.
read the caption
Figure 3: Network Architecture. The HMA model architecture maps low-level video and action sequences across different embodiments into a shared latent space. For actions, embodiment projectors are activated based on the training sample. The spatial-temporal Transformer produces the output video and action tokens for future frames.

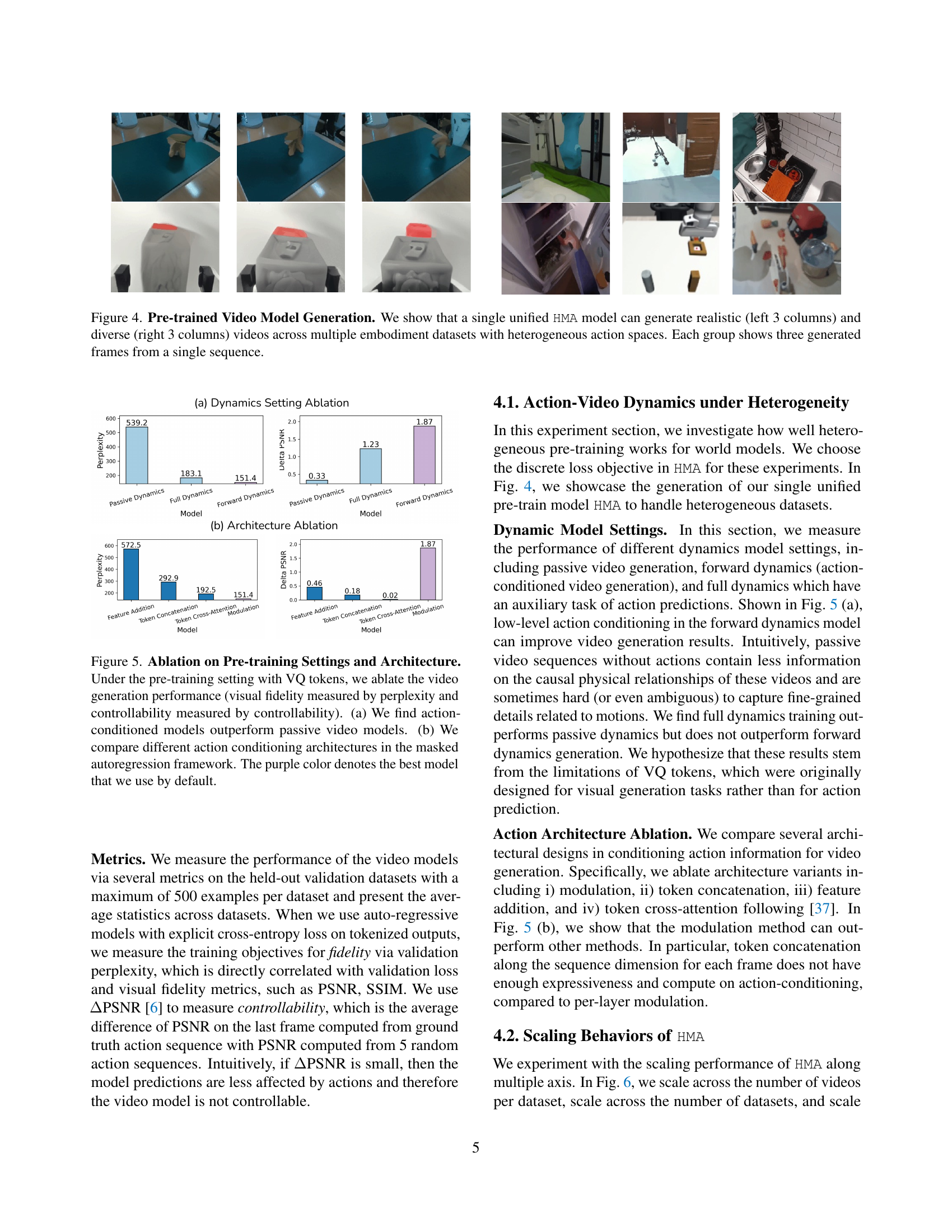
🔼 This figure demonstrates the capability of the Heterogeneous Masked Autoregression (HMA) model to generate high-quality and diverse videos. The model is trained on a dataset containing videos from various robotic embodiments and heterogeneous action spaces. The left three columns showcase videos that are visually realistic and consistent with typical real-world interactions. In contrast, the right three columns display videos with more unexpected or creative actions, reflecting the model’s capacity to produce diverse results. Each group of three images represents consecutive frames from a single video sequence generated by the model.
read the caption
Figure 4: Pre-trained Video Model Generation. We show that a single unified HMA model can generate realistic (left 3 columns) and diverse (right 3 columns) videos across multiple embodiment datasets with heterogeneous action spaces. Each group shows three generated frames from a single sequence.

🔼 Figure 5 presents ablation studies on the Heterogeneous Masked Autoregression (HMA) model, specifically examining the effects of different pre-training settings and architectures on video generation performance. Part (a) compares the performance of action-conditioned models (forward and full dynamics) against passive video models, showing that incorporating action information significantly improves both visual fidelity (measured by perplexity) and controllability (measured by APSNR). Part (b) analyzes various action-conditioning architectures within the HMA framework, including modulation, token concatenation, feature addition, and token cross-attention, to determine the optimal design for balancing performance and efficiency. The best performing model configuration is highlighted in purple.
read the caption
Figure 5: Ablation on Pre-training Settings and Architecture. Under the pre-training setting with VQ tokens, we ablate the video generation performance (visual fidelity measured by perplexity and controllability measured by controllability). (a) We find action-conditioned models outperform passive video models. (b) We compare different action conditioning architectures in the masked autoregression framework. The purple color denotes the best model that we use by default.

🔼 This figure displays the results of experiments evaluating the scalability of the Heterogeneous Masked Autoregression (HMA) model. Three separate experiments are shown, each exploring a different aspect of scalability: 1. Scaling the Number of Datasets: This shows how HMA performs as the number of different robotic datasets used for training increases. More datasets mean more diverse robot embodiments, actions, and environments are included in the training, representing a greater degree of heterogeneity. 2. Scaling the Number of Trajectories: This assesses HMA’s performance as the total number of training video trajectories increases. More trajectories offer more data to train the model and potentially lead to better performance. 3. Scaling Model Size: This experiment examines how HMA behaves as the size and complexity of the model itself increase (number of parameters). For each experiment, two key metrics are shown. Perplexity measures the fidelity of the generated videos (lower perplexity indicates higher fidelity), and ΔΔ PSNR (Delta PSNR) measures the controllability of the generated videos (lower ΔΔ PSNR suggests better controllability, indicating that the model’s output is more consistent and less affected by random noise). The results in the plots demonstrate that the performance of the HMA model improves with increased dataset diversity, more training data, and larger model size, thus showcasing its strong scaling properties.
read the caption
Figure 6: Experiments on Scaling Behaviors of HMA. We observe positive trends in the scaling performance of heterogeneous video models across axes including the number of datasets, number of trajectories, and model sizes. The evaluation metrics on fidelity (perplexity) and controllability (ΔΔ\Deltaroman_ΔPSNR) are averaged across validation datasets.

🔼 This figure compares the visual quality of videos generated using different methods: VQ tokens (vector-quantized tokens, a discrete representation) and soft tokens (continuous representation), both within a masked autoregressive framework. The comparison highlights that while diffusion-based models using soft tokens take longer to train (slower convergence), they produce significantly better visual results. This superior quality is evident both qualitatively (by visual inspection) and quantitatively (as measured by the Peak Signal-to-Noise Ratio, or PSNR). The improved visual fidelity from using soft tokens comes at the cost of increased training time.
read the caption
Figure 7: Qualitative Comparisons Between Tokenizers and Models. Despite longer convergence time, diffusion-based methods (Eq. 3) on soft tokens generate better visual quality than on VQ tokens (Eq. 2), qualitatively and measured by PSNR.

🔼 Figure 8 showcases the model’s capacity for generating physically realistic video sequences based on user-provided actions. The top row demonstrates the model’s handling of object permanence, a scenario where objects continue to exist even when not directly visible. The bottom row depicts a block-pushing interaction, a more complex task requiring understanding of physics and object manipulation. Importantly, both scenarios extend significantly beyond the model’s training horizon (over 100 frames), and involve actions unseen during training, highlighting the model’s generalization capabilities.
read the caption
Figure 8: Video Controllability. HMA can follow user action inputs to generate physically plausible object permanence (top row) and block pushing interactions (bottom row). These video predictions are both at out-of-distribution settings and at a much longer horizon than training (over 100 frames).

🔼 Figure 9 demonstrates the application of the Heterogeneous Masked Autoregression (HMA) model for policy evaluation. Unlike traditional simulators which primarily focus on successful policy executions, HMA learns from both successful and failed examples of robot actions and their corresponding video sequences. This allows HMA to provide more realistic and comprehensive evaluations of policies, assessing their performance across a wider range of scenarios. The figure highlights that HMA’s autoregressive prediction extends far beyond its training timeframe; at inference, it can predict 10 times longer sequences than those seen during training, further enhancing its utility for evaluating policy performance in complex, long-horizon robotic tasks.
read the caption
Figure 9: Policy Evaluation with HMA. By learning the action-video dynamics over both successful and failed examples, HMA can be used to evaluate policies, similar to a traditional simulator [46]. The autoregressive horizon at inference time is 10 times more than the training time horizon.
More on tables
| PSNR | SSIM | PSNR | LPIPS | FID | FVD | |
| IRASim | 25.41 | 0.82 | 5.78 | 0.08 | 23.22 | 152.20 |
| HMA | 28.19 | 0.83 | 6.06 | 0.07 | 33.56 | 111.52 |
🔼 This table compares the performance of the proposed Heterogeneous Masked Autoregression (HMA) model with IRASim, a state-of-the-art model for interactive robot simulation. The comparison focuses on the Language Table benchmark [31], evaluating visual fidelity (PSNR, SSIM, LPIPS, FID, FVD), controllability (ΔPSNR), inference speed (FPS), and model size (Parameters). It demonstrates that the HMA model achieves superior visual quality and controllability while being significantly faster and requiring fewer parameters than IRASim. The results are based on 200 held-out trajectories.
read the caption
Table 2: Comparison with IRASim. In Language Table Benchmark [31], we show that a pre-trained HMA-based model (diffusion) is able to achieve better visual qualities and controllability than IRASim while maintaining faster speed and requiring less compute. The results are computed over 200 held-out trajectories.
| PSNR | Perplexity | PSNR | LPIPS | |
| HMA | 21.01 | 305.87 | 0.01 | 0.19 |
| HMA + | 22.04 | 189.83 | 0.06 | 0.17 |
🔼 This table presents the results of fine-tuning the Heterogeneous Masked Autoregression (HMA) model on real-world data. It compares the performance of two approaches: one where the model is fine-tuned using pre-trained weights (HMA+) and another where it’s trained from scratch (HMA). The experiment uses a discrete loss function as the baseline for evaluation. The metrics presented likely show improvements in visual fidelity (PSNR, Perplexity), and controllability (ΔPSNR, LPIPS) achieved by fine-tuning versus training from scratch.
read the caption
Table 3: Real World Finetuning. HMA + denotes finetuned model based on pre-trained checkpoints while HMA trains from scratch on the finetuning data. This experiment uses the discrete loss baseline.
| PSNR | Perplexity | PSNR∗ | Perplexity∗ | |
| HMA | 24.17 | 20.69 | 19.19 | 1193.70 |
| HMA + | 25.11 | 11.82 | 20.20 | 103.01 |
🔼 This table presents a comparison of the performance of two models in a simulation transfer learning scenario. The first model, referred to as ‘HMA’, is trained from scratch using a combination of cross-entropy and diffusion loss functions. The second model, denoted as ‘HMA+’, leverages pre-trained weights as a starting point before further fine-tuning with the same loss functions. The results highlight the impact of transfer learning, showing how using pre-trained weights (HMA+) can improve performance, particularly in terms of PSNR (Peak Signal-to-Noise Ratio), a measure of image quality, and perplexity, which reflects how well the model predicts data. Lower perplexity values indicate better predictive performance. The metrics PSNR* and Perplexity*, which reflect sensitivity to small changes in actions, also demonstrates the effect of using pre-trained weights.
read the caption
Table 4: Simulation Transfer Learning. We show that pre-trained HMA can help with fine-tuning using cross-entropy losses and diffusion losses jointly. where HMA + denotes the finetuned model based on pre-trained checkpoints.
| Policy Evaluator | 1 | 2 | 3 | 4 |
| Ground Truth Simulator | 0.38 | 0.52 | 0.70 | 1.00 |
| HMA Simulator | 0.43 | 0.56 | 0.66 | 0.73 |
🔼 This table presents the results of evaluating four different robot control policies using both a ground truth simulator and a learned simulator (HMA). The policies were trained with varying numbers of iterations, allowing for an assessment of how performance correlates across simulators. The high Pearson correlation of 0.95 indicates a strong positive relationship between policy performance as measured by both simulators, suggesting that the learned simulator accurately reflects performance in the real world.
read the caption
Table 5: Policy Evaluation Results Across 4 Different Policies. We observed positive correlations of the evaluation results for 4 different policies bewteen the ground truth and learned simulators. The Pearson ratio between evaluations is 0.95.
🔼 This table investigates the impact of synthetic data generated by the HMA model on policy learning. It evaluates how adding varying amounts of synthetic data (from 10% to 90% ) to a small subset of real-world data (10 out of 100 real trajectories) affects policy performance. The experiment uses two benchmarks: Robomimic (success rates are reported) and Language Table (validation losses are reported). The results show how well the HMA-generated data supplements the real data for training effective policies.
read the caption
Table 6: Synthetic Data for Policy Learning. We evaluate the quality of generated synthetic data by adding different numbers of generated video trajectories in [32] and [31], from 10 to 100, to a fixed subset (10 trajectories) of the original data (100 trajectories). We then conduct policy training and evaluation and report the Robomimic success rates (top row) and Language Table validation losses (bottom row).
Full paper#