TL;DR#
Current omni-modal large language models (LLMs) lag behind specialized single-modality models in performance, and suffer from issues like data inefficiency and inadequate modality alignment. Existing solutions often require massive datasets, leading to high training costs and delayed user interaction. This paper introduces Ola, a novel approach aimed at resolving these challenges.
Ola employs a progressive modality alignment strategy. The training begins with text and image data, gradually integrating video and audio. This approach enables efficient knowledge transfer and avoids the need for huge datasets. Further, Ola adopts a sentence-wise decoding solution, enabling real-time streaming for speech generation. Experiments demonstrate that Ola outperforms existing omni-modal LLMs and achieves highly competitive results, exceeding those of some specialized models of similar size, while being a highly efficient and open-sourced model.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multimodal learning and large language models. It presents a novel progressive modality alignment strategy, offering a highly efficient and competitive method for developing advanced omni-modal models. The open-sourcing of the model, code and data further accelerates future research in this exciting emerging field, particularly on handling various modalities (image, video, audio) simultaneously and efficiently. The work also pushes the boundaries of what’s possible with relatively smaller models.
Visual Insights#

🔼 Figure 1 compares the performance of the Ola omni-modal language model against other state-of-the-art open-source multimodal models and GPT-4 on various image, video, and audio benchmarks. To ensure a fair comparison, models with approximately 7 billion parameters were selected. The results demonstrate that Ola significantly outperforms other models across all modalities, attributed to its progressive modality alignment training strategy. The ‘×’ symbol indicates a model’s inability to perform a specific task, while ‘-’ signifies missing results. Note that the LibriSpeech benchmark uses a reversed scoring system where lower values represent better performance (lower Word Error Rate).
read the caption
Figure 1: Ola pushes the frontiers of the omni-modal language model across image, video and audio understanding benchmarks. We compare Ola with existing state-of-the-art open-sourced multimodal models and GPT-4o on their abilities in mainstream image, video, and audio benchmarks. For fair comparisons, we select around 7B versions of existing MLLMs. Ola can achieve outperforming performance against omni-modal and specialized MLLMs in all modalities thanks to our progressive alignment strategy. “×\times×” indicates that the model is not capable of the task and “−--” indicates the result is lacking. The score for LibriSpeech is inverted as lower is better for the WER metric.
In-depth insights#
Progressive Alignment#
The concept of “Progressive Alignment” in the context of multimodal learning is a powerful approach. It suggests a phased training strategy, starting with simpler, more distinct modalities (like text and images) before gradually incorporating more complex and related ones (video and audio). This phased approach offers several key advantages. Firstly, it simplifies the training process, making it more manageable and reducing the computational cost associated with large datasets. Secondly, it allows for the development of strong foundational understanding in the simpler modalities before building upon that knowledge to integrate additional ones. This incremental learning process helps to avoid the pitfalls of directly combining diverse and potentially conflicting data, which can hinder the overall performance of the model. Thirdly, it optimizes resource utilization, requiring smaller and more manageable datasets at each stage, reducing the massive data requirements commonly seen in multimodal learning. By carefully designing the alignment strategy and data preparation at each step, progressive alignment promotes efficiency, reduces complexity, and improves the overall performance and robustness of the resulting multimodal model.
Omni-Modal Benchmarks#
Developing truly effective omni-modal models necessitates robust benchmarks that comprehensively evaluate performance across various modalities. Omni-modal benchmarks should move beyond simple aggregation of single-modality scores and instead focus on tasks requiring genuine cross-modal understanding. This might involve evaluating performance on tasks where understanding one modality is crucial for inferring information in another (e.g., using audio cues to improve image captioning accuracy or using visual context to improve speech recognition). Furthermore, the benchmarks must account for different data types and complexities within each modality, considering the diverse nature of image, video, audio, and textual data. A well-designed benchmark will also consider the relative difficulty of tasks and avoid bias toward specific modalities. Finally, open-source benchmarks are essential to facilitate community participation and transparent evaluation of omni-modal models, promoting faster progress in this rapidly evolving field. Diverse and challenging tasks within the benchmark are crucial for measuring a model’s true capabilities and highlighting areas where further research is needed.
Cross-Modal Video#
The concept of “Cross-Modal Video” in the context of multimodal learning suggests a powerful approach to bridge the gap between visual and auditory information within video data. It moves beyond treating video as a mere sequence of images. The key insight is leveraging the inherent connection between the visual stream (images/frames) and the audio stream (sound) within the video. By jointly modeling these two modalities, the model can gain a richer, more comprehensive understanding of the video content than by analyzing the visual and auditory data separately. This joint processing might involve techniques such as multi-modal attention mechanisms or fusion strategies that combine visual and audio features to create a unified representation. The benefits include improved performance on tasks requiring both visual and auditory comprehension, like video question answering where the answer might be implied by a combination of visual and audible cues. This approach is particularly beneficial when dealing with noisy or ambiguous visual data, where audio cues can help disambiguate the visual content or vice versa. Training data would require careful alignment of audio and video; techniques like subtitle generation or synchronised audio-visual datasets would prove valuable. The challenges lie in efficiently handling high-dimensional data from both modalities and designing network architectures able to effectively combine and process this information in a way that maximises its relevance to the overall understanding.
Architecture Design#
The architecture of a multimodal large language model (MLLM) is crucial for its ability to effectively process and integrate information from diverse modalities. A modular design, where different encoders are used for each modality (text, image, audio, video), allows for specialization and optimized processing for each input type. A joint alignment module then becomes critical, responsible for harmonizing these disparate representations into a unified embedding space suitable for the core LLM. This requires careful consideration of how different modalities interact, potentially utilizing attention mechanisms or other techniques to capture cross-modal relationships. The design of the core LLM itself is significant, impacting the model’s capacity for reasoning and knowledge integration across modalities. Choosing a transformer-based architecture is common for its scalability and proven performance. Finally, efficient decoding mechanisms for generating outputs are essential, particularly when dealing with streaming modalities like audio and video. Implementing a sentence-wise decoding strategy can significantly enhance the user experience by providing faster, more interactive responses. An effective architecture must balance modularity, integration, efficiency, and user-friendliness to create a seamless multimodal experience.
Future of Omni-Modal#
The future of omni-modal AI hinges on solving the challenges of data scarcity and computational cost associated with training models capable of seamlessly integrating diverse data modalities. Progressive modality alignment, as demonstrated in the paper, offers a promising approach, starting with simpler modalities (text and image) before gradually incorporating others. However, developing robust methods for aligning data from disparate sources and handling the inherent noise and variability will be crucial. Moreover, the field needs to move beyond simple benchmark tasks towards real-world applications, requiring more sophisticated evaluation metrics that reflect nuanced performance across various scenarios. Improving the efficiency of streaming decoding is also vital to deliver a user-friendly, real-time experience. The combination of advanced alignment techniques, efficient architectures, and real-world benchmarks promises a future where omni-modal AI can truly revolutionize how humans interact with and understand information.
More visual insights#
More on figures

🔼 The Ola architecture diagram shows its ability to process text, image, video, and audio inputs simultaneously. Each modality’s input is fed through its respective encoder (visual encoder, audio encoder, etc.). These encodings are then combined and processed by the Ola Omni-Modal Language Model, which generates tokens. These tokens are then decoded into text output via a text detokenizer and converted to speech output using a speech decoder. This enables real-time streaming decoding for text and speech, providing a user-friendly experience.
read the caption
Figure 2: Ola Architecture. Ola supports omni-modal inputs including text, image, video, and audio, capable of processing the inputs simultaneously with competitive performance on understanding tasks for all these modalities. Meanwhile, Ola supports user-friendly real-time streaming decoding for texts and speeches thanks to the text detokenizer and the speech decoder.

🔼 This figure compares three different training strategies for an omni-modal language model: progressive modality alignment (the proposed method), direct mixing of data, and balanced sampling of data. The results are shown on three tasks: Image QA (using the MMBench benchmark), Video QA (using the VideoMME benchmark), and Automatic Speech Recognition (ASR) (using the LibriSpeech benchmark). The progressive alignment strategy shows consistent improvements across all three tasks compared to the baselines. The direct mixing approach merges all data types and trains at once, while the balanced sampling approach oversamples smaller datasets to balance the dataset size across all modalities. The figure highlights the benefits of the progressive approach, which incrementally adds modalities to improve performance by maintaining relatively small cross-modal alignment data.
read the caption
Figure 3: Progressive modality alignment helps to learn better omni-modal models. We compare our progressive alignment strategy with two baseline training pipelines on Image QA(MMBench [40]), Video QA(VideoMME [21]), and ASR(LibriSpeech [54]): 1) direct mixing where all instruction tuning data is merged and trained in a single stage, and 2) balanced sampling where we upsample certain sources to make the training data more balanced among modalities. The experiment is conducted on a subsampled training set for efficiency and we train models for the same number of steps for fair comparisons. The score is normalized based on the score of progressive alignment to calculate the relative score and the ASR score is inverted as lower is better for the WER metric.

🔼 Figure 4 illustrates the Ola model’s progressive modality alignment training strategy. The left side depicts the relationships between modalities: text connects to image directly, while speech acts as a bridge between text and audio, and video connects text, image, and audio. The training process starts with aligning text and image (Stage 1), then adds video data (Stage 2) and finally incorporates audio and video data (Stage 3) to fully integrate all modalities. This progressive approach is chosen because it leverages existing strong text-image models and incrementally adds more complex modalities. Specifically, cross-modal video-audio data was created to enhance learning of the relationships between audio and visual information. The figure visually represents this step-wise training process.
read the caption
Figure 4: Illustrations of the Ola Progressive Modality Alignment. We visualize the relationships among modalities in the left part. Speech acts as the connection between language and audio knowledge, while video constructs the bridge with highly relevant visual and audio information. Therefore, we design the progressive alignment training strategy from primary to periphery. Furthermore, we design the cross-modality video-audio data to better capture the relationships among modalities.

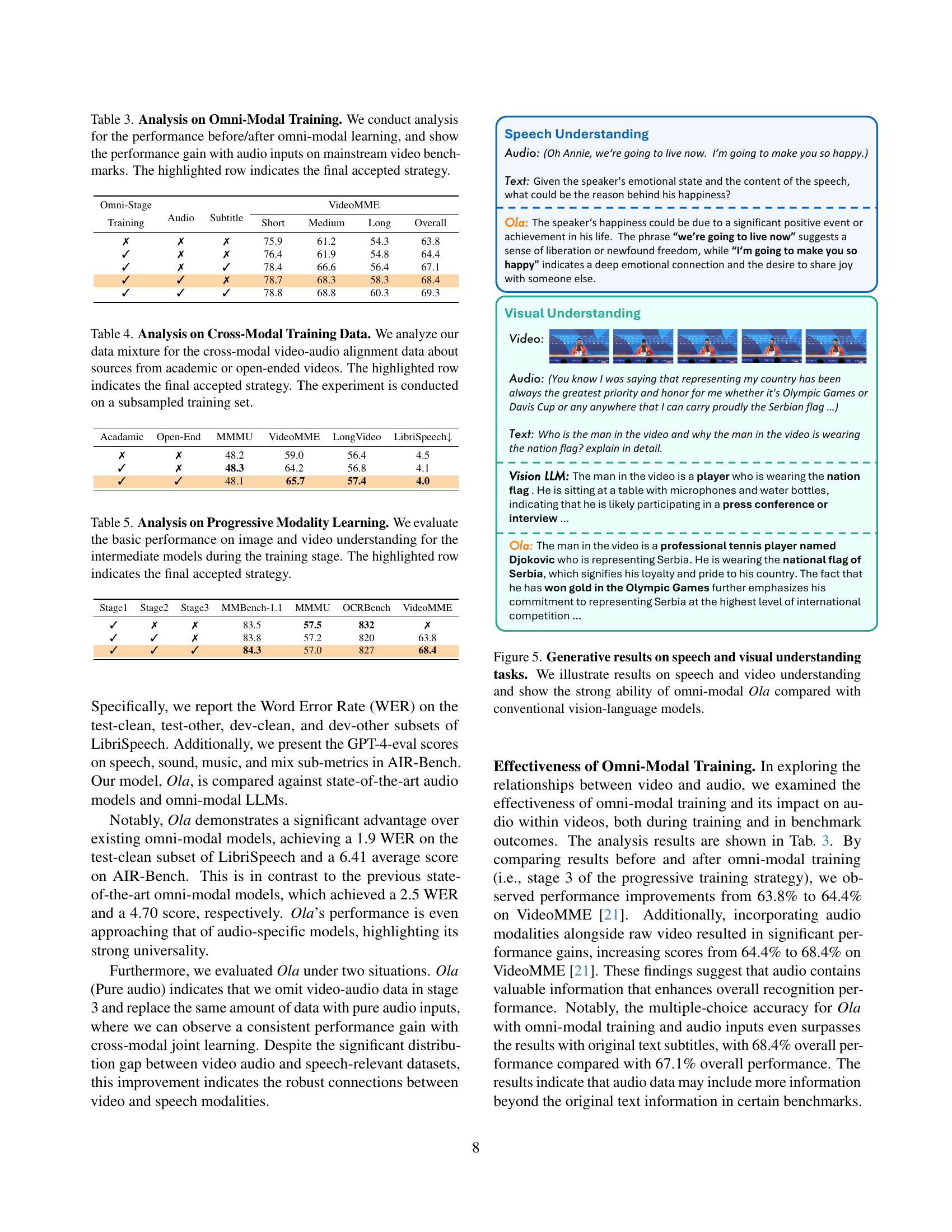
🔼 Figure 5 presents a comparison of Ola’s performance on speech and video understanding tasks against conventional vision-language models. The figure showcases examples where Ola leverages its omni-modal capabilities (processing text, audio, and visual data simultaneously) to generate more comprehensive and accurate responses compared to models limited to vision and language only. Specifically, it highlights Ola’s superior ability to understand nuanced details and contexts from audio inputs within a video, resulting in superior responses.
read the caption
Figure 5: Generative results on speech and visual understanding tasks. We illustrate results on speech and video understanding and show the strong ability of omni-modal Ola compared with conventional vision-language models.

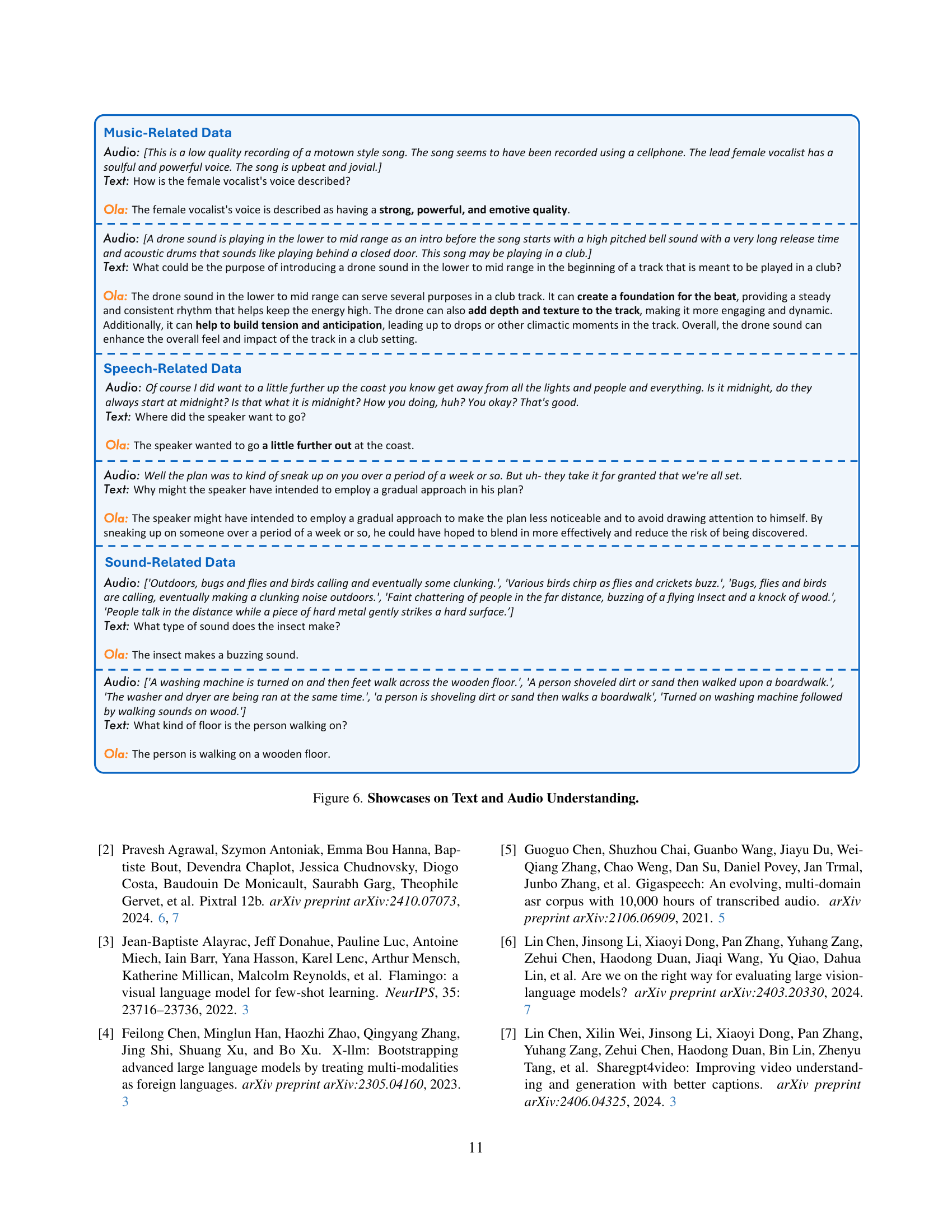
🔼 Figure 6 presents examples showcasing Ola’s capabilities in understanding and generating text based on various audio inputs. It demonstrates Ola’s ability to accurately interpret and respond to diverse audio types, including music, speech, and environmental sounds. The figure highlights Ola’s comprehension of both the semantic content and the emotional context within the audio, and its ability to generate relevant and coherent textual descriptions or responses. This showcases Ola’s capacity for robust cross-modal understanding and generation.
read the caption
Figure 6: Showcases on Text and Audio Understanding.
Full paper#