TL;DR#
Current text-to-3D generation models struggle to produce outputs that fully align with human preferences. Existing methods often rely heavily on reward models to estimate the quality of generated 3D models, which is computationally expensive and may not fully capture the nuances of human perception. Furthermore, these methods often lack the flexibility to incorporate various aspects of human preference.
DreamDPO tackles these challenges with a novel optimization-based framework that directly incorporates human preferences. By constructing pairwise examples and using a preference-driven loss function, DreamDPO effectively guides the 3D generation process to better align with human preferences. The results demonstrate that DreamDPO generates higher-quality 3D models that are more aligned with human expectations and offers improved flexibility for controlling the generation process.
Key Takeaways#
Why does it matter?#
This paper is important because it presents DreamDPO, a novel framework for text-to-3D generation that directly incorporates human preferences, addressing a critical limitation of existing methods. It introduces a new optimization-based approach that leverages pairwise comparisons, reducing reliance on absolute quality evaluations and enabling fine-grained control. This work is highly relevant to current trends in AI-driven 3D content creation and opens up new avenues for research in preference-guided optimization and multimodal learning.
Visual Insights#

🔼 DreamDPO is an optimization-based framework. It consists of three steps: (1) Pairwise Example Construction: constructing pairs of 3D model examples by adding different Gaussian noise to the initial model; (2) Pairwise Comparison: comparing the alignment of the pairs with human preferences using reward models or large multimodal models; (3) Preference-Guided Optimization: optimizing the 3D representation using a preference-driven loss function that pulls the preferred example closer and pushes away the less preferred example only when their preference scores differ significantly. This prevents chaotic gradients and allows for more fine-grained control.
read the caption
Figure 1: Overview of our method. DreamDPO first constructs pairwise examples, then compares their alignment with human preferences using reward or large multimodal models, and lastly optimizes the 3D presentation with a preference-driven loss function. The loss function pulls the win example 𝐱twinsuperscriptsubscript𝐱𝑡win\mathbf{x}_{t}^{\text{win}}bold_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT win end_POSTSUPERSCRIPT closer and pushes the lose example 𝐱tlosesuperscriptsubscript𝐱𝑡lose\mathbf{x}_{t}^{\text{lose}}bold_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT lose end_POSTSUPERSCRIPT away. As a piecewise objective, it selectively pushes 𝐱tlosesuperscriptsubscript𝐱𝑡lose\mathbf{x}_{t}^{\text{lose}}bold_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT lose end_POSTSUPERSCRIPT only when the preference score gap sgapsubscript𝑠gaps_{\text{gap}}italic_s start_POSTSUBSCRIPT gap end_POSTSUBSCRIPT exceeds a threshold τ𝜏\tauitalic_τ, preventing chaotic gradients from overly similar 𝐱tlosesuperscriptsubscript𝐱𝑡lose\mathbf{x}_{t}^{\text{lose}}bold_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT start_POSTSUPERSCRIPT lose end_POSTSUPERSCRIPT.
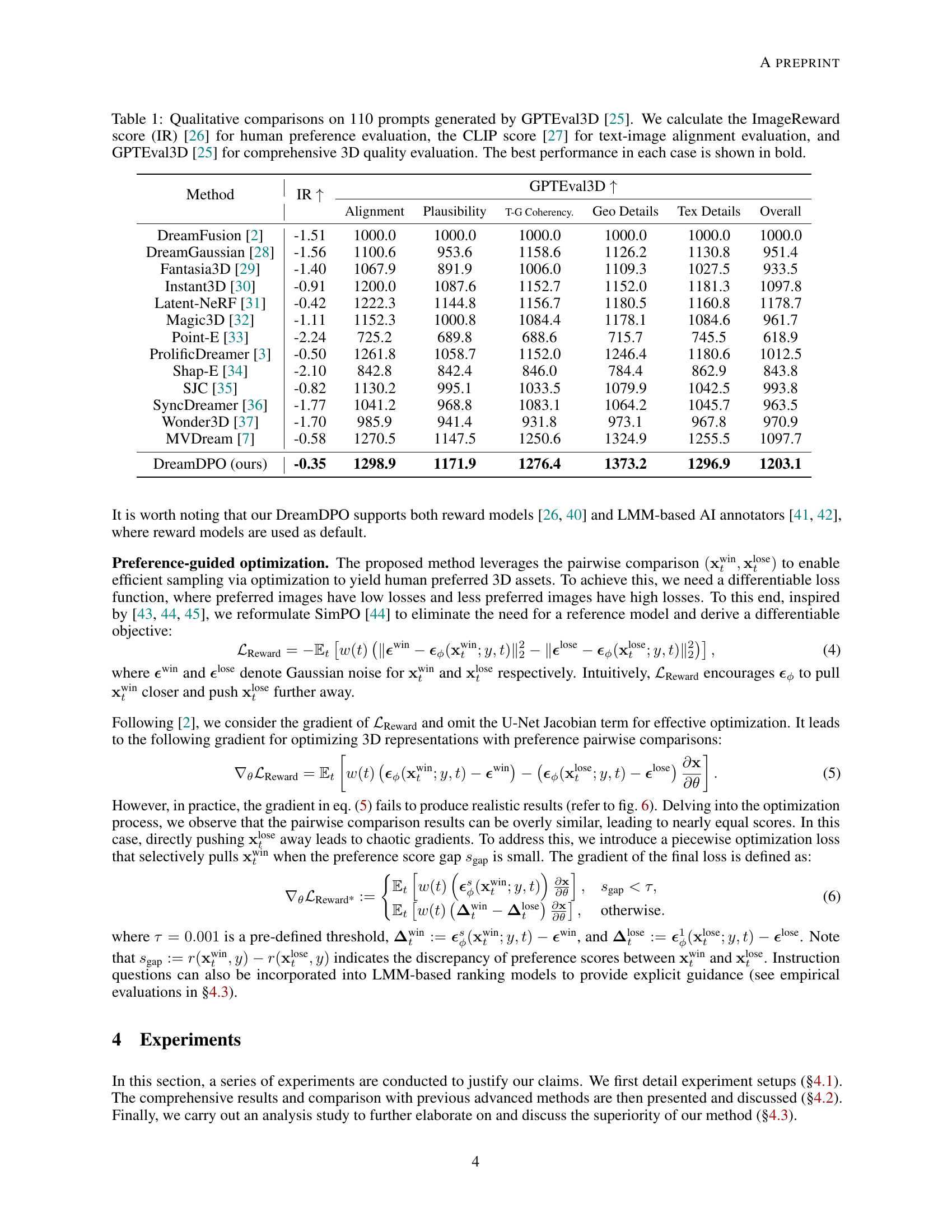
| Method | IR | GPTEval3D | |||||
| Alignment | Plausibility | T-G Coherency. | Geo Details | Tex Details | Overall | ||
| DreamFusion [2] | -1.51 | 1000.0 | 1000.0 | 1000.0 | 1000.0 | 1000.0 | 1000.0 |
| DreamGaussian [28] | -1.56 | 1100.6 | 953.6 | 1158.6 | 1126.2 | 1130.8 | 951.4 |
| Fantasia3D [29] | -1.40 | 1067.9 | 891.9 | 1006.0 | 1109.3 | 1027.5 | 933.5 |
| Instant3D [30] | -0.91 | 1200.0 | 1087.6 | 1152.7 | 1152.0 | 1181.3 | 1097.8 |
| Latent-NeRF [31] | -0.42 | 1222.3 | 1144.8 | 1156.7 | 1180.5 | 1160.8 | 1178.7 |
| Magic3D [32] | -1.11 | 1152.3 | 1000.8 | 1084.4 | 1178.1 | 1084.6 | 961.7 |
| Point-E [33] | -2.24 | 725.2 | 689.8 | 688.6 | 715.7 | 745.5 | 618.9 |
| ProlificDreamer [3] | -0.50 | 1261.8 | 1058.7 | 1152.0 | 1246.4 | 1180.6 | 1012.5 |
| Shap-E [34] | -2.10 | 842.8 | 842.4 | 846.0 | 784.4 | 862.9 | 843.8 |
| SJC [35] | -0.82 | 1130.2 | 995.1 | 1033.5 | 1079.9 | 1042.5 | 993.8 |
| SyncDreamer [36] | -1.77 | 1041.2 | 968.8 | 1083.1 | 1064.2 | 1045.7 | 963.5 |
| Wonder3D [37] | -1.70 | 985.9 | 941.4 | 931.8 | 973.1 | 967.8 | 970.9 |
| MVDream [7] | -0.58 | 1270.5 | 1147.5 | 1250.6 | 1324.9 | 1255.5 | 1097.7 |
| DreamDPO (ours) | -0.35 | 1298.9 | 1171.9 | 1276.4 | 1373.2 | 1296.9 | 1203.1 |
🔼 This table presents a qualitative comparison of different text-to-3D generation methods. Eleven methods are evaluated across 110 prompts, using three metrics: ImageReward score (measuring human preference), CLIP score (measuring text-image alignment), and the GPTEval3D score (measuring overall 3D quality). The best performing method for each metric is highlighted in bold.
read the caption
Table 1: Qualitative comparisons on 110 prompts generated by GPTEval3D [25]. We calculate the ImageReward score (IR) [26] for human preference evaluation, the CLIP score [27] for text-image alignment evaluation, and GPTEval3D [25] for comprehensive 3D quality evaluation. The best performance in each case is shown in bold.
In-depth insights#
Pref-Based 3D Gen#
Pref-Based 3D generation represents a significant advancement in 3D modeling, moving beyond traditional techniques that solely focus on objective quality metrics. The core idea is to directly incorporate human preferences into the generation process, resulting in models that produce 3D assets more aligned with user expectations and aesthetic sensibilities. This approach acknowledges that the concept of “quality” is subjective and highly context-dependent. Instead of relying solely on automated evaluation methods, pref-based systems leverage techniques like pairwise comparisons, ranking models, or even direct user feedback to guide the generation process. This allows for a greater degree of control and customization, enabling users to specify desired stylistic elements, structural properties, or even emotional impact. The success of pref-based 3D generation hinges on the effectiveness of the preference acquisition and integration methods. While offering significant potential for creative applications, challenges remain in scalability, computational cost, and the robustness of preference models to diverse user preferences and ambiguous prompts. Future work in this area should focus on developing more efficient preference acquisition methods, creating more robust and adaptable preference models, and further exploring the interaction between preference-based generation and other advanced 3D modeling techniques.
DreamDPO Framework#
The hypothetical “DreamDPO Framework” likely centers on direct preference optimization for text-to-3D generation. It would likely involve a three-step process: pairwise example construction (generating subtly different 3D models from the same text prompt), pairwise comparison (using a reward model or large language model to rank the generated pairs based on user preference), and preference-guided optimization (adjusting the 3D model parameters using a loss function that maximizes the preference score). This framework aims to directly incorporate human preferences, reducing reliance on absolute quality metrics and potentially improving controllability over the generated 3D output. A key innovation is likely the use of pairwise comparisons, which is more robust than direct pointwise scoring and can handle less precise ranking signals. This approach is particularly useful because getting accurate quality scores for 3D assets is inherently difficult.
Human Pref Alig#
The heading ‘Human Pref Alig,’ likely short for ‘Human Preference Alignment,’ points to a crucial aspect of text-to-3D generation: bridging the gap between what a model generates and what humans find desirable. Aligning generated 3D models with human preferences is challenging because it requires understanding and incorporating subjective aesthetic judgments. This involves moving beyond simple quantitative metrics, which might only assess technical aspects like resolution or geometry, and delving into the more nuanced realm of human perception and taste. Effective human preference alignment demands robust methods for evaluating the quality and appeal of generated 3D content. This could involve user studies, comparing different generation outputs, or employing sophisticated reward models trained on human feedback. The research likely explores novel algorithms and frameworks to optimize the generation process, steering it toward outputs that consistently resonate with human preferences. This could include techniques like direct preference optimization, where user feedback directly guides the model’s learning, or indirect approaches using reward signals derived from large multimodal models.
3D Gen Limitations#
Current text-to-3D generation methods face significant limitations. Accuracy in representing textual descriptions is often lacking, leading to mismatches between the generated 3D model and the user’s intent. Controllability over the generated 3D assets remains a major challenge, with many methods struggling to consistently produce models that meet specific requirements regarding shape, texture, and detail. Furthermore, reliance on large, pre-trained models is a significant hurdle, demanding substantial computational resources and potentially limiting the accessibility and reproducibility of research findings. Evaluating the quality of 3D-generated content objectively is complex, as human perception plays a crucial role, and existing metrics often fail to capture the nuances of 3D model quality. Finally, the scalability and efficiency of existing methods present limitations, as many processes are computationally intensive and slow, hindering their practical applicability in real-world scenarios. Addressing these shortcomings requires further research into improved model architectures, more robust optimization techniques, and novel evaluation metrics better aligned with human expectations.
Future Work#
The paper’s ‘Future Work’ section hints at several crucial areas for improvement. Addressing the limitations of AI feedback, especially its reliance on generative model capabilities and the inherent instability of open APIs, is paramount. The authors suggest exploring prompt-free methods such as object detection or grounding models to enhance robustness and reduce reliance on prompt engineering. Improving the model’s robustness in pairwise comparisons is also highlighted, proposing the use of the diffusion model itself for comparisons to enhance consistency. Further research should investigate leveraging stronger reward models and exploring new methods such as incorporating image prompts to provide more context for generation. Expanding the applicability of the method to other generation tasks like 4D generation and scene generation is another promising avenue. Overall, future work focuses on enhancing model robustness, reducing reliance on specific AI components, and expanding the model’s versatility to a broader range of applications.
More visual insights#
More on figures

🔼 Figure 2 presents a qualitative comparison of different text-to-3D generation models on the GPTEval3D benchmark. The figure visually demonstrates the strengths and weaknesses of various methods in aligning generated 3D models with the input text prompt. Models that struggled to accurately capture elements described in the prompt are highlighted in red, illustrating the challenges that existing methods face in correctly interpreting and representing textual descriptions in a 3D space. In contrast, DreamDPO, the method proposed in the paper, shows significantly improved text matching, which is reflected in improved alignment with human preferences, as the generated 3D models more closely resemble the textual descriptions.
read the caption
Figure 2: Qualitative comparisons on the benchmark of GPTEval3D [25]. Existing methods struggle with text matching, as marked in red. DreamDPO improves text matching, which provides better human preference results. (Zoom in to see the details.)

🔼 Figure 3 presents a qualitative comparison of 3D models generated by DreamDPO and MVDream for various text prompts ranging in length and complexity. The figure showcases DreamDPO’s improved ability to generate 3D models that align more closely with human preferences as indicated by the red markings highlighting superior results in text matching, detail, and overall quality. Zooming in reveals finer details of the 3D models and their respective text prompts.
read the caption
Figure 3: Qualitative comparisons with MVDream [7]. DreamDPO performs well across short to long prompts, offering better human preference results, marked in red. (Zoom in to see the details.)

🔼 Figure 4 showcases an ablation study analyzing the impact of the backbone diffusion model used in DreamDPO. The results compare DreamDPO’s performance when using the Stable Diffusion v2.1 model (SD2.1) against other backbones, demonstrating that DreamDPO achieves effective results even with this model. This highlights the model’s adaptability and its potential for improvement when utilizing more advanced diffusion models.
read the caption
Figure 4: The analysis of backbone. We present the results of DreamDPO using Stable Diffusion v2.1 (SD2.1) [17]. DreamDPO demonstrates effective performance with SD2.1, highlighting its potential to leverage more advanced backbone diffusion models for further improvements.

🔼 This figure showcases the results of experiments conducted using DreamDPO with the ImageReward model for human preference evaluation. The results demonstrate that DreamDPO consistently performs well when integrated with ImageReward, suggesting that using more robust reward models could further improve the quality of 3D asset generation.
read the caption
Figure 5: The analysis of reward models. We present the results of DreamDPO using ImageReward [26]. DreamDPO demonstrates effective performance with ImageReward, highlighting its potential to leverage stronger reward models to further enhance generation quality.

🔼 This figure shows the impact of the score gap threshold (τ) on the quality of generated images in 2D toy experiments. The experiments varied τ from 0.01 down to 0. The results demonstrate that a small, non-zero value of τ effectively removes very similar ’lose’ examples from the optimization process. This results in more detailed and refined final image outputs because the optimization isn’t distracted by near-identical samples.
read the caption
Figure 6: The analysis of the score gap threshold τ𝜏\tauitalic_τ. We conduct 2D toy experiments with τ𝜏\tauitalic_τ ranging from 0.010.010.010.01 to 00. The results indicate that a small but non-zero τ𝜏\tauitalic_τ effectively filters out overly similar lose examples, leading to more detailed outputs.

🔼 Figure 7 presents a qualitative comparison of 3D model generation results between DreamReward and the proposed DreamDPO method. Each row shows a text prompt and the 3D models generated by each method. Elements where DreamDPO shows improvement over DreamReward in terms of accurately representing details described in the text prompt are highlighted in red. This demonstrates DreamDPO’s improved ability to align generated 3D models with textual descriptions and produce superior geometric and textural details.
read the caption
Figure 7: Qualitative comparisons with DreamReward [12]. DreamDPO improves both text matching (marked in red) and geometric/texture details.

🔼 Figure 8 showcases DreamDPO’s ability to integrate Large Multimodal Models (LMMs) like QwenVL for enhanced 3D asset generation. The experiment demonstrates how carefully crafted questions posed to the LMM can provide pairwise comparisons, guiding the optimization process by indicating preferred (‘win’) and less preferred (’lose’) 3D renderings. This allows DreamDPO to refine the generated 3D models, correcting issues like incorrect object counts or attributes. The left corner of the figure details the question-answer process and win/lose labels used in the LMM evaluation. Zooming in reveals more detail.
read the caption
Figure 8: The generation results of DreamDPO with large multi-modal models (LMMs). We explore the potential of our method to leverage LMMs, such as QwenVL [41] for explicit guidance in correcting the number and attribute of 3D assets. The left corner shows the details of pairwise comparisons using the LMM, including the question and win/lose criteria. By carefully designing the question, DreamDPO can leverage both win and lose examples to guide optimization. (Zoom in to see the details.)

🔼 Figure 9 investigates the impact of the pairwise example construction method on the model’s performance. The figure compares two approaches: (1) using different Gaussian noise at the same timestep to generate the pairs and (2) using the same Gaussian noise but different timesteps. This comparison helps understand how different methods of introducing variation in the input affect the model’s ability to learn and generate high-quality 3D assets guided by preferences.
read the caption
Figure 9: The analysis of pairwise example construction. We compare (1) different noises: adding different Gaussian noises with the same timesteps, and (2) difference timesteps: adding the same Gaussian noise with different timesteps.

🔼 This figure demonstrates an application of the DreamDPO method to text-to-avatar generation. It shows a comparison between avatars generated by a prior method (MVDream) and DreamDPO. The results indicate that DreamDPO, when combined with a Gaussian-based avatar generation framework [48], produces improved results. More details of this experiment and implementation are provided in Appendix B.3.
read the caption
Figure 10: The further application of DreamDPO. We conduct toy experiments on text-to-avatar generation by combining DreamDPO with Gaussian-based avatar generation framework [48]. More details can be checked in Appendix B.3.

🔼 This figure displays qualitative results obtained using the DreamDPO method. It presents several 3D model renderings generated by DreamDPO, compared to models created by the MVDream method. The comparison highlights DreamDPO’s superior ability to generate models that more closely align with textual descriptions. For each prompt, the two resulting images are displayed side by side to visually showcase the differences.
read the caption
Figure 11: More qualitative results using DreamDPO.

🔼 This figure displays additional qualitative results generated by DreamDPO, showcasing its ability to produce high-fidelity 3D models that accurately reflect the given text prompts. Each row presents a text prompt along with comparative 3D renderings from both DreamDPO and a baseline method (MVDream). The comparisons demonstrate that DreamDPO generates more realistic 3D models with enhanced alignment to the input text, improved text matching, and better geometric and texture details compared to the baseline method. Specific examples include an improved rendering of a cat magician with a white dove, a more accurate depiction of a beagle in a detective outfit, and a more realistic rendition of plants in a workshop. This visual comparison provides further evidence of DreamDPO’s superior performance.
read the caption
Figure 12: More qualitative results using DreamDPO.
Full paper#