TL;DR#
Current neural audio codecs face challenges such as high bitrates, loss of information, and complex multi-codebook designs. These limitations hinder efficient speech processing for various applications. The high computational cost and difficulty in capturing long-term dependencies are also significant concerns.
To overcome these issues, the researchers propose FocalCodec. FocalCodec uses focal modulation networks and a single binary codebook to efficiently compress speech, achieving competitive performance at bitrates as low as 0.16 kbps. The single codebook design simplifies downstream tasks, while focal modulation captures both semantic and acoustic information effectively. Evaluations across various benchmarks demonstrate its superior performance over existing codecs in reconstruction quality, multilingual capabilities, and robustness to noisy environments.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces FocalCodec, a novel low-bitrate speech codec that significantly improves speech reconstruction quality and efficiency. This offers significant advancements for various speech processing applications and opens avenues for research in low-bitrate speech coding and downstream tasks. The use of focal modulation is a novel approach with potential applications beyond speech processing.
Visual Insights#

🔼 The FocalCodec architecture diagram shows the flow of information processing. The encoder processes the input audio to extract features rich in both acoustic and semantic information. These features are compressed into a low-dimensional representation by the compressor module. This compressed representation is then quantized using a binary codebook. A decompressor module reconstructs the compressed features from this quantized representation. Finally, the decoder uses the reconstructed features to generate the output waveform, completing the speech coding process.
read the caption
Figure 1: FocalCodec architecture. The encoder extracts features containing both acoustic and semantic information. These features are then mapped to a low-dimensional space by the compressor, binary quantized, and projected back by the decompressor. The decoder resynthesizes the waveform from these features.
| Codec | Bitrate (kbps) | Sample Rate (kHz) | Token Rate (Hz) | Codebooks | Code Size | Params (M) | MACs (G) |
| EnCodec | 1.50 | 24 | 75.0 | 2 1024 | 128 | 15 | 2 |
| DAC | 1.00 | 16 | 50.0 | 2 1024 | 8 | 74 | 56 |
| WavLM6-KM | 0.45 | 16 | 50.0 | 1 512 | 1024 | 127 | 28 |
| SpeechTokenizer | 1.00 | 16 | 50.0 | 2 1024 | 1024 | 108 | 17 |
| SemantiCodec | 0.65 | 16 | 25.0 | 2 8192 | 1536 | 1033 | 1599 |
| Mimi | 0.69 | 24 | 12.5 | 5 2048 | 256 | 82 | 11 |
| WavTokenizer | 0.48 | 24 | 40.0 | 1 4096 | 512 | 85 | 3 |
| BigCodec | 1.04 | 16 | 80.0 | 1 8192 | 8 | 160 | 61 |
| Stable Codec | 0.70 | 16 | 25.0 | 2 15625 | 6 | 95 | 37 |
| FocalCodec@50 | 0.65 | 16 | 50.0 | 1 8192 | 13 | 142 | 9 |
| FocalCodec@25 | 0.33 | 16 | 25.0 | 1 8192 | 13 | 144 | 9 |
| FocalCodec@12.5 | 0.16 | 16 | 12.5 | 1 8192 | 13 | 145 | 8 |
🔼 This table compares various low-bitrate speech codecs used in the paper, providing key characteristics for each codec to facilitate comparison. It includes the bitrate (kbps), sample rate (kHz), token rate (Hz), the number of codebooks used, the number of parameters (millions), the number of multiply-accumulate operations per second (MACs; in billions), and the size of the model checkpoint (in MB). The codecs are categorized as acoustic, semantic, or hybrid, reflecting their design and training approach.
read the caption
Table 1: Compared codecs.
In-depth insights#
Focal Modulation’s Role#
Focal modulation plays a crucial role in FocalCodec by enabling efficient and scalable speech compression. Unlike traditional self-attention mechanisms, it introduces inductive biases, allowing the model to learn more effectively from speech data. The hierarchical structure of focal modulation, processing features at multiple granularities, is key to preserving both acoustic detail and semantic information. This is achieved through efficient context aggregation and modulation of local interactions, resulting in granular quantization that maintains high reconstruction quality even at ultra-low bitrates. Focal modulation’s capacity for handling long-range dependencies in linear time is a significant advantage, making FocalCodec well-suited for handling longer speech sequences effectively. The use of focal modulation, in combination with a single binary codebook, fundamentally differentiates FocalCodec from other hybrid codecs, significantly simplifying the architecture and improving its efficiency for downstream tasks.
Low-bitrate Speech#
Low-bitrate speech coding is a crucial area of research focusing on compressing speech signals into smaller sizes for efficient transmission and storage. The challenge lies in achieving this compression without significant degradation of speech quality or loss of semantic information. FocalCodec, presented in this paper, addresses this challenge using a novel approach based on focal modulation networks and a single binary codebook. This method is shown to outperform existing state-of-the-art codecs in terms of speech quality and downstream task performance, even at extremely low bitrates (0.16 to 0.65 kbps). The use of a single codebook simplifies architecture, making the design more efficient and less complex for integration into downstream applications. The effectiveness of FocalCodec’s approach across various tasks and noisy conditions highlights its potential for broad application, making it a significant advancement in low-bitrate speech technology.
Single Codebook Design#
The single codebook design in FocalCodec represents a significant departure from conventional hybrid speech codecs, which often employ multiple codebooks to disentangle acoustic and semantic information. This simplification is a major contribution, as it reduces model complexity and improves efficiency for downstream tasks. By leveraging focal modulation, a single binary codebook effectively captures both acoustic detail and semantic content, achieving competitive performance at ultra-low bitrates. The success of this approach highlights the potential of inductive biases in neural audio codecs, showing that carefully designed architectures can achieve high-quality speech reconstruction and effective semantic representations without relying on complex multi-codebook designs or computationally expensive training procedures. The single codebook paradigm further facilitates easier integration with downstream models, as it avoids the need for handling multiple codebook outputs, making FocalCodec a more versatile and practical solution for various speech processing applications.
Downstream Tasks#
The ‘Downstream Tasks’ section of the research paper is crucial for evaluating the effectiveness of the proposed FocalCodec. It assesses the quality of the learned discrete speech representations by applying them to various tasks. The choice of tasks—automatic speech recognition (ASR), speaker identification (SI), and speech emotion recognition (SER)—is insightful, as they probe different aspects of speech understanding: semantic content (ASR), acoustic properties (SI), and higher-level emotional nuances (SER). The use of shallow downstream models is a methodological strength, minimizing the risk of confounding factors and emphasizing the inherent quality of FocalCodec’s representations. The results show that FocalCodec achieves competitive performance across all three tasks, demonstrating its ability to preserve both semantic and acoustic information, even at low bitrates. This underscores the success of its single-codebook design and the effectiveness of its focal modulation architecture. The section highlights a practical strength of the codec, demonstrating that these efficient representations are not only useful for resynthesis but can also effectively empower various downstream applications.
Future Work#
Future work for FocalCodec should prioritize addressing its non-causal nature, exploring architectural modifications or training strategies to enable real-time applications. Expanding the dataset to encompass multilingual speech, diverse acoustic conditions (noisy environments), and higher sampling rates (24 kHz) is crucial for enhancing robustness and generalization. Investigating the application of FocalCodec to other audio modalities beyond speech (music, environmental sounds) would broaden its utility. Finally, a deeper exploration into the trade-offs between compression ratio and downstream task performance is warranted, possibly involving novel quantization techniques or loss functions. These improvements would significantly enhance FocalCodec’s versatility and practical applicability.
More visual insights#
More on tables
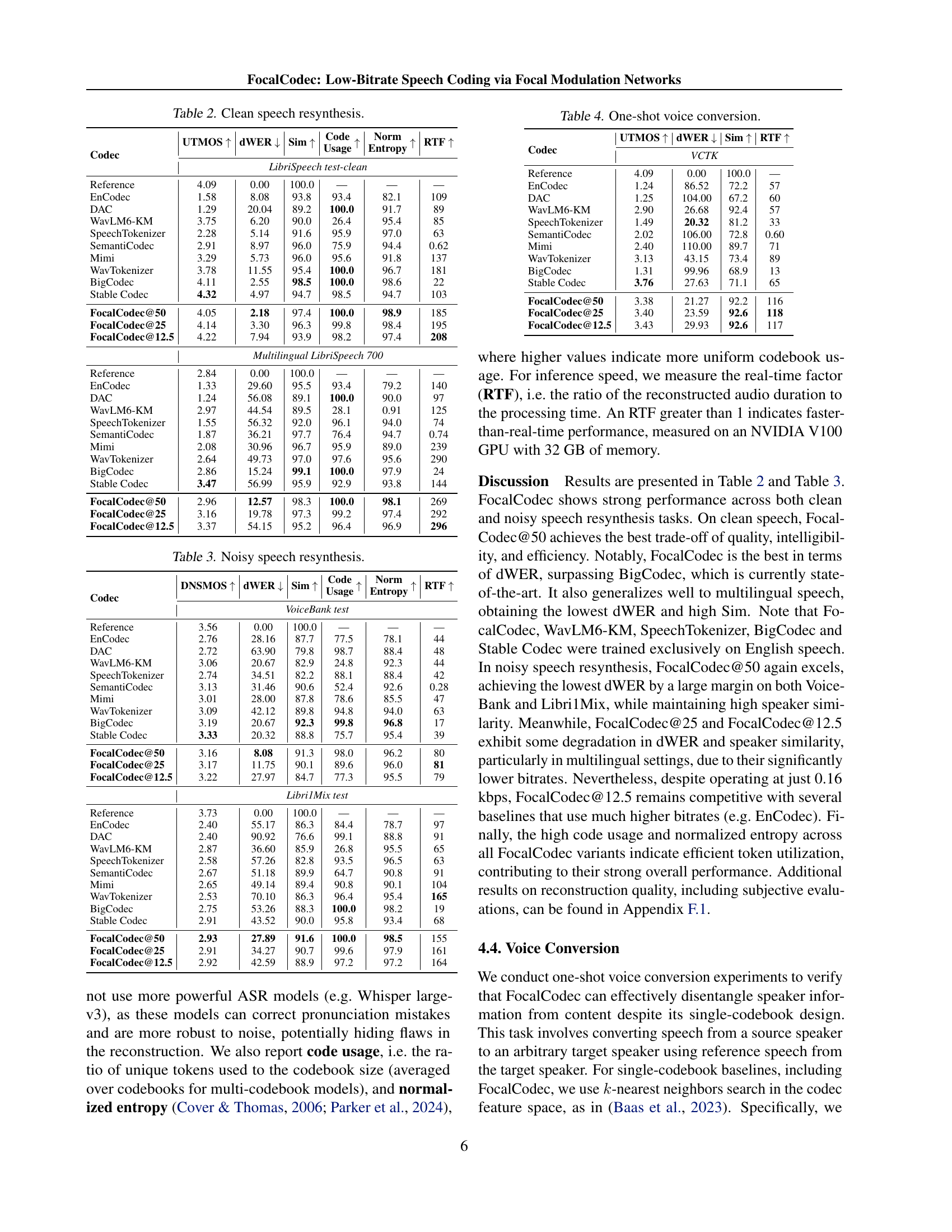
| Codec | UTMOS | dWER | Sim | Code Usage | Norm Entropy | RTF |
| LibriSpeech test-clean | ||||||
| Reference | 4.09 | 0.00 | 100.0 | — | — | — |
| EnCodec | 1.58 | 8.08 | 93.8 | 93.4 | 82.1 | 109 |
| DAC | 1.29 | 20.04 | 89.2 | 100.0 | 91.7 | 89 |
| WavLM6-KM | 3.75 | 6.20 | 90.0 | 26.4 | 95.4 | 85 |
| SpeechTokenizer | 2.28 | 5.14 | 91.6 | 95.9 | 97.0 | 63 |
| SemantiCodec | 2.91 | 8.97 | 96.0 | 75.9 | 94.4 | 0.62 |
| Mimi | 3.29 | 5.73 | 96.0 | 95.6 | 91.8 | 137 |
| WavTokenizer | 3.78 | 11.55 | 95.4 | 100.0 | 96.7 | 181 |
| BigCodec | 4.11 | 2.55 | 98.5 | 100.0 | 98.6 | 22 |
| Stable Codec | 4.32 | 4.97 | 94.7 | 98.5 | 94.7 | 103 |
| FocalCodec@50 | 4.05 | 2.18 | 97.4 | 100.0 | 98.9 | 185 |
| FocalCodec@25 | 4.14 | 3.30 | 96.3 | 99.8 | 98.4 | 195 |
| FocalCodec@12.5 | 4.22 | 7.94 | 93.9 | 98.2 | 97.4 | 208 |
| Multilingual LibriSpeech 700 | ||||||
| Reference | 2.84 | 0.00 | 100.0 | — | — | — |
| EnCodec | 1.33 | 29.60 | 95.5 | 93.4 | 79.2 | 140 |
| DAC | 1.24 | 56.08 | 89.1 | 100.0 | 90.0 | 97 |
| WavLM6-KM | 2.97 | 44.54 | 89.5 | 28.1 | 0.91 | 125 |
| SpeechTokenizer | 1.55 | 56.32 | 92.0 | 96.1 | 94.0 | 74 |
| SemantiCodec | 1.87 | 36.21 | 97.7 | 76.4 | 94.7 | 0.74 |
| Mimi | 2.08 | 30.96 | 96.7 | 95.9 | 89.0 | 239 |
| WavTokenizer | 2.64 | 49.73 | 97.0 | 97.6 | 95.6 | 290 |
| BigCodec | 2.86 | 15.24 | 99.1 | 100.0 | 97.9 | 24 |
| Stable Codec | 3.47 | 56.99 | 95.9 | 92.9 | 93.8 | 144 |
| FocalCodec@50 | 2.96 | 12.57 | 98.3 | 100.0 | 98.1 | 269 |
| FocalCodec@25 | 3.16 | 19.78 | 97.3 | 99.2 | 97.4 | 292 |
| FocalCodec@12.5 | 3.37 | 54.15 | 95.2 | 96.4 | 96.9 | 296 |
🔼 This table presents the results of clean speech resynthesis experiments. It compares various speech coding methods (FocalCodec at different bitrates, EnCodec, DAC, WavLM6-KM, SpeechTokenizer, SemantiCodec, Mimi, WavTokenizer, BigCodec, and Stable Codec) across multiple metrics. The metrics evaluated include the utterance-level MOS (UTMOS) score, which measures perceived naturalness; the differential word error rate (dWER), indicating speech intelligibility; the cosine similarity (Sim), reflecting speaker fidelity; and the real-time factor (RTF), representing inference speed. The table is organized to show the performance of each codec, allowing a comparison of their strengths and weaknesses in reconstructing clean speech.
read the caption
Table 2: Clean speech resynthesis.
| Codec | DNSMOS | dWER | Sim | Code Usage | Norm Entropy | RTF |
| VoiceBank test | ||||||
| Reference | 3.56 | 0.00 | 100.0 | — | — | — |
| EnCodec | 2.76 | 28.16 | 87.7 | 77.5 | 78.1 | 44 |
| DAC | 2.72 | 63.90 | 79.8 | 98.7 | 88.4 | 48 |
| WavLM6-KM | 3.06 | 20.67 | 82.9 | 24.8 | 92.3 | 44 |
| SpeechTokenizer | 2.74 | 34.51 | 82.2 | 88.1 | 88.4 | 42 |
| SemantiCodec | 3.13 | 31.46 | 90.6 | 52.4 | 92.6 | 0.28 |
| Mimi | 3.01 | 28.00 | 87.8 | 78.6 | 85.5 | 47 |
| WavTokenizer | 3.09 | 42.12 | 89.8 | 94.8 | 94.0 | 63 |
| BigCodec | 3.19 | 20.67 | 92.3 | 99.8 | 96.8 | 17 |
| Stable Codec | 3.33 | 20.32 | 88.8 | 75.7 | 95.4 | 39 |
| FocalCodec@50 | 3.16 | 8.08 | 91.3 | 98.0 | 96.2 | 80 |
| FocalCodec@25 | 3.17 | 11.75 | 90.1 | 89.6 | 96.0 | 81 |
| FocalCodec@12.5 | 3.22 | 27.97 | 84.7 | 77.3 | 95.5 | 79 |
| Libri1Mix test | ||||||
| Reference | 3.73 | 0.00 | 100.0 | — | — | — |
| EnCodec | 2.40 | 55.17 | 86.3 | 84.4 | 78.7 | 97 |
| DAC | 2.40 | 90.92 | 76.6 | 99.1 | 88.8 | 91 |
| WavLM6-KM | 2.87 | 36.60 | 85.9 | 26.8 | 95.5 | 65 |
| SpeechTokenizer | 2.58 | 57.26 | 82.8 | 93.5 | 96.5 | 63 |
| SemantiCodec | 2.67 | 51.18 | 89.9 | 64.7 | 90.8 | 91 |
| Mimi | 2.65 | 49.14 | 89.4 | 90.8 | 90.1 | 104 |
| WavTokenizer | 2.53 | 70.10 | 86.3 | 96.4 | 95.4 | 165 |
| BigCodec | 2.75 | 53.26 | 88.3 | 100.0 | 98.2 | 19 |
| Stable Codec | 2.91 | 43.52 | 90.0 | 95.8 | 93.4 | 68 |
| FocalCodec@50 | 2.93 | 27.89 | 91.6 | 100.0 | 98.5 | 155 |
| FocalCodec@25 | 2.91 | 34.27 | 90.7 | 99.6 | 97.9 | 161 |
| FocalCodec@12.5 | 2.92 | 42.59 | 88.9 | 97.2 | 97.2 | 164 |
🔼 This table presents the results of speech resynthesis experiments conducted on noisy speech datasets. It compares the performance of various speech coding models in terms of their ability to reconstruct high-quality speech from noisy inputs. The metrics used to evaluate the models include DNSMOS (for naturalness), dWER (for intelligibility), and speaker similarity (Sim). Additionally, code usage, entropy, and real-time factor (RTF) are provided to showcase the efficiency and speed of each model. Two noisy speech datasets were used for evaluation: VoiceBank and Librimix.
read the caption
Table 3: Noisy speech resynthesis.
| Codec | UTMOS | dWER | Sim | RTF |
| VCTK | ||||
| Reference | 4.09 | 0.00 | 100.0 | — |
| EnCodec | 1.24 | 86.52 | 72.2 | 57 |
| DAC | 1.25 | 104.00 | 67.2 | 60 |
| WavLM6-KM | 2.90 | 26.68 | 92.4 | 57 |
| SpeechTokenizer | 1.49 | 20.32 | 81.2 | 33 |
| SemantiCodec | 2.02 | 106.00 | 72.8 | 0.60 |
| Mimi | 2.40 | 110.00 | 89.7 | 71 |
| WavTokenizer | 3.13 | 43.15 | 73.4 | 89 |
| BigCodec | 1.31 | 99.96 | 68.9 | 13 |
| Stable Codec | 3.76 | 27.63 | 71.1 | 65 |
| FocalCodec@50 | 3.38 | 21.27 | 92.2 | 116 |
| FocalCodec@25 | 3.40 | 23.59 | 92.6 | 118 |
| FocalCodec@12.5 | 3.43 | 29.93 | 92.6 | 117 |
🔼 This table presents the results of a one-shot voice conversion experiment, where the goal is to convert speech from a source speaker to a target speaker using only a short reference audio sample from the target speaker. The table compares FocalCodec with several other state-of-the-art speech codecs across various metrics, including UTMOS (a measure of speech naturalness), dWER (a measure of intelligibility), Sim (a measure of speaker similarity), and RTF (real-time factor). The results are shown separately for both clean and multilingual speech to evaluate generalization capabilities. Higher values for UTMOS and Sim are better, while lower values for dWER are better.
read the caption
Table 4: One-shot voice conversion.
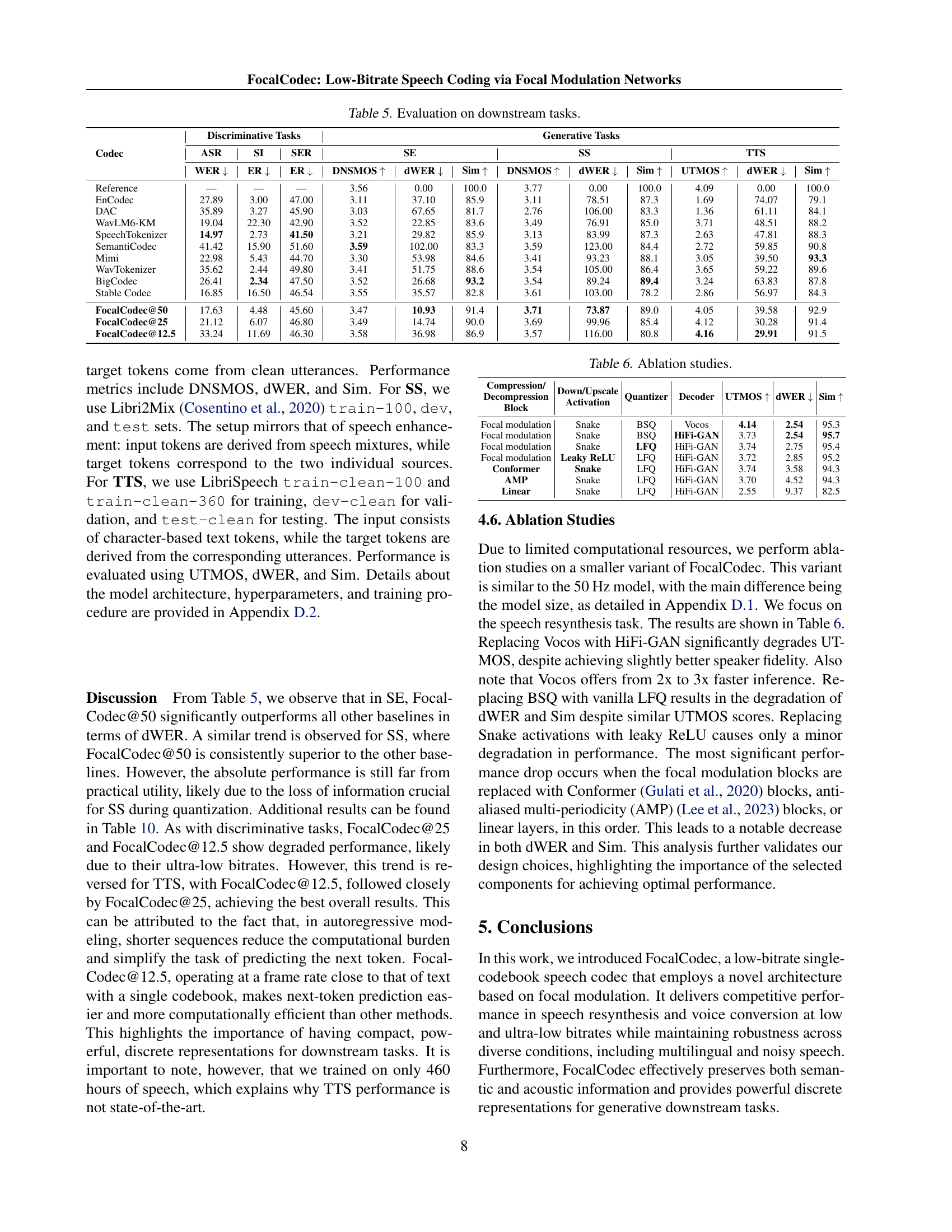
| Codec | Discriminative Tasks | Generative Tasks | ||||||||||
| ASR | SI | SER | SE | SS | TTS | |||||||
| WER | ER | ER | DNSMOS | dWER | Sim | DNSMOS | dWER | Sim | UTMOS | dWER | Sim | |
| Reference | — | — | — | 3.56 | 0.00 | 100.0 | 3.77 | 0.00 | 100.0 | 4.09 | 0.00 | 100.0 |
| EnCodec | 27.89 | 3.00 | 47.00 | 3.11 | 37.10 | 85.9 | 3.11 | 78.51 | 87.3 | 1.69 | 74.07 | 79.1 |
| DAC | 35.89 | 3.27 | 45.90 | 3.03 | 67.65 | 81.7 | 2.76 | 106.00 | 83.3 | 1.36 | 61.11 | 84.1 |
| WavLM6-KM | 19.04 | 22.30 | 42.90 | 3.52 | 22.85 | 83.6 | 3.49 | 76.91 | 85.0 | 3.71 | 48.51 | 88.2 |
| SpeechTokenizer | 14.97 | 2.73 | 41.50 | 3.21 | 29.82 | 85.9 | 3.13 | 83.99 | 87.3 | 2.63 | 47.81 | 88.3 |
| SemantiCodec | 41.42 | 15.90 | 51.60 | 3.59 | 102.00 | 83.3 | 3.59 | 123.00 | 84.4 | 2.72 | 59.85 | 90.8 |
| Mimi | 22.98 | 5.43 | 44.70 | 3.30 | 53.98 | 84.6 | 3.41 | 93.23 | 88.1 | 3.05 | 39.50 | 93.3 |
| WavTokenizer | 35.62 | 2.44 | 49.80 | 3.41 | 51.75 | 88.6 | 3.54 | 105.00 | 86.4 | 3.65 | 59.22 | 89.6 |
| BigCodec | 26.41 | 2.34 | 47.50 | 3.52 | 26.68 | 93.2 | 3.54 | 89.24 | 89.4 | 3.24 | 63.83 | 87.8 |
| Stable Codec | 16.85 | 16.50 | 46.54 | 3.55 | 35.57 | 82.8 | 3.61 | 103.00 | 78.2 | 2.86 | 56.97 | 84.3 |
| FocalCodec@50 | 17.63 | 4.48 | 45.60 | 3.47 | 10.93 | 91.4 | 3.71 | 73.87 | 89.0 | 4.05 | 39.58 | 92.9 |
| FocalCodec@25 | 21.12 | 6.07 | 46.80 | 3.49 | 14.74 | 90.0 | 3.69 | 99.96 | 85.4 | 4.12 | 30.28 | 91.4 |
| FocalCodec@12.5 | 33.24 | 11.69 | 46.30 | 3.58 | 36.98 | 86.9 | 3.57 | 116.00 | 80.8 | 4.16 | 29.91 | 91.5 |
🔼 This table presents the results of evaluating different speech codecs on a variety of downstream tasks, including speech recognition (ASR), speaker identification (SI), speech emotion recognition (SER), speech enhancement (SE), speech separation (SS), and text-to-speech (TTS). For each task, the table shows the performance of each codec using relevant metrics such as Word Error Rate (WER), Error Rate (ER), DNSMOS (for quality), and others depending on the task. It allows for a comparison of how well different codecs preserve semantic and acoustic information for various applications.
read the caption
Table 5: Evaluation on downstream tasks.
| Compression/ Decompression Block | Down/Upscale Activation | Quantizer | Decoder | UTMOS | dWER | Sim |
| Focal modulation | Snake | BSQ | Vocos | 4.14 | 2.54 | 95.3 |
| Focal modulation | Snake | BSQ | HiFi-GAN | 3.73 | 2.54 | 95.7 |
| Focal modulation | Snake | LFQ | HiFi-GAN | 3.74 | 2.75 | 95.4 |
| Focal modulation | Leaky ReLU | LFQ | HiFi-GAN | 3.72 | 2.85 | 95.2 |
| Conformer | Snake | LFQ | HiFi-GAN | 3.74 | 3.58 | 94.3 |
| AMP | Snake | LFQ | HiFi-GAN | 3.70 | 4.52 | 94.3 |
| Linear | Snake | LFQ | HiFi-GAN | 2.55 | 9.37 | 82.5 |
🔼 This table presents the results of ablation studies performed on a smaller variant of the FocalCodec model. It investigates the impact of different components and design choices on the model’s performance in speech resynthesis. Specifically, it examines the effects of altering the quantizer, decoder, compression/decompression method, activation function, and downscaling/upscaling block.
read the caption
Table 6: Ablation studies.
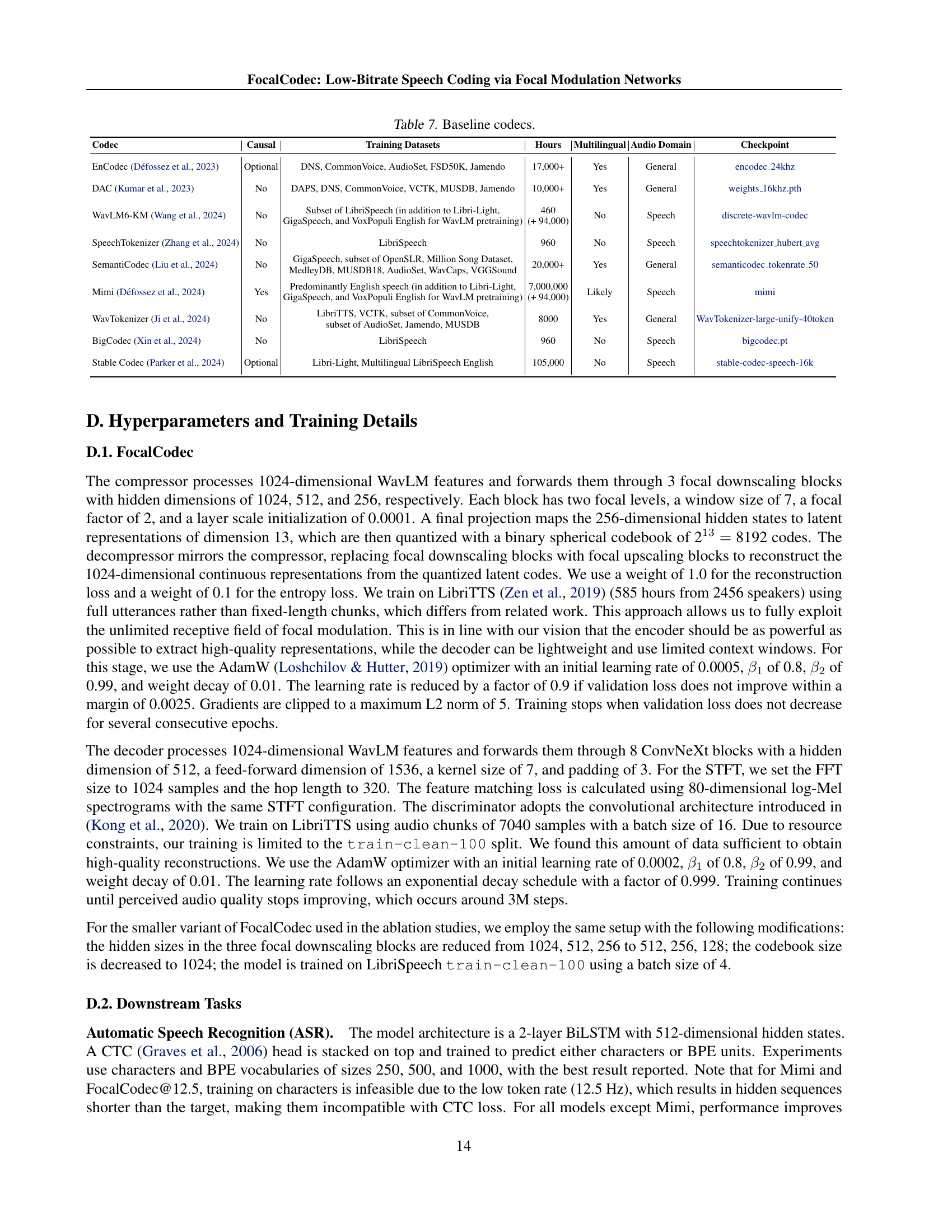
| Codec | Causal | Training Datasets | Hours | Multilingual | Audio Domain | Checkpoint |
| EnCodec (Défossez et al., 2023) | Optional | DNS, CommonVoice, AudioSet, FSD50K, Jamendo | 17,000+ | Yes | General | encodec_24khz |
| DAC (Kumar et al., 2023) | No | DAPS, DNS, CommonVoice, VCTK, MUSDB, Jamendo | 10,000+ | Yes | General | weights_16khz.pth |
| WavLM6-KM (Wang et al., 2024) | No | Subset of LibriSpeech (in addition to Libri-Light, GigaSpeech, and VoxPopuli English for WavLM pretraining) | 460 (+ 94,000) | No | Speech | discrete-wavlm-codec |
| SpeechTokenizer (Zhang et al., 2024) | No | LibriSpeech | 960 | No | Speech | speechtokenizer_hubert_avg |
| SemantiCodec (Liu et al., 2024) | No | GigaSpeech, subset of OpenSLR, Million Song Dataset, MedleyDB, MUSDB18, AudioSet, WavCaps, VGGSound | 20,000+ | Yes | General | semanticodec_tokenrate_50 |
| Mimi (Défossez et al., 2024) | Yes | Predominantly English speech (in addition to Libri-Light, GigaSpeech, and VoxPopuli English for WavLM pretraining) | 7,000,000 (+ 94,000) | Likely | Speech | mimi |
| WavTokenizer (Ji et al., 2024) | No | LibriTTS, VCTK, subset of CommonVoice, subset of AudioSet, Jamendo, MUSDB | 8000 | Yes | General | WavTokenizer-large-unify-40token |
| BigCodec (Xin et al., 2024) | No | LibriSpeech | 960 | No | Speech | bigcodec.pt |
| Stable Codec (Parker et al., 2024) | Optional | Libri-Light, Multilingual LibriSpeech English | 105,000 | No | Speech | stable-codec-speech-16k |
🔼 This table compares FocalCodec to several state-of-the-art low-bitrate speech codecs. It lists each codec’s name, whether it is causal (meaning the output can be generated in real-time without needing future input), the datasets used for training, the total training hours, whether the codec supports multiple languages, the type of audio data it was trained on, and the location of the model checkpoints. This information helps to understand the different approaches and resources used to train these baseline models.
read the caption
Table 7: Baseline codecs.
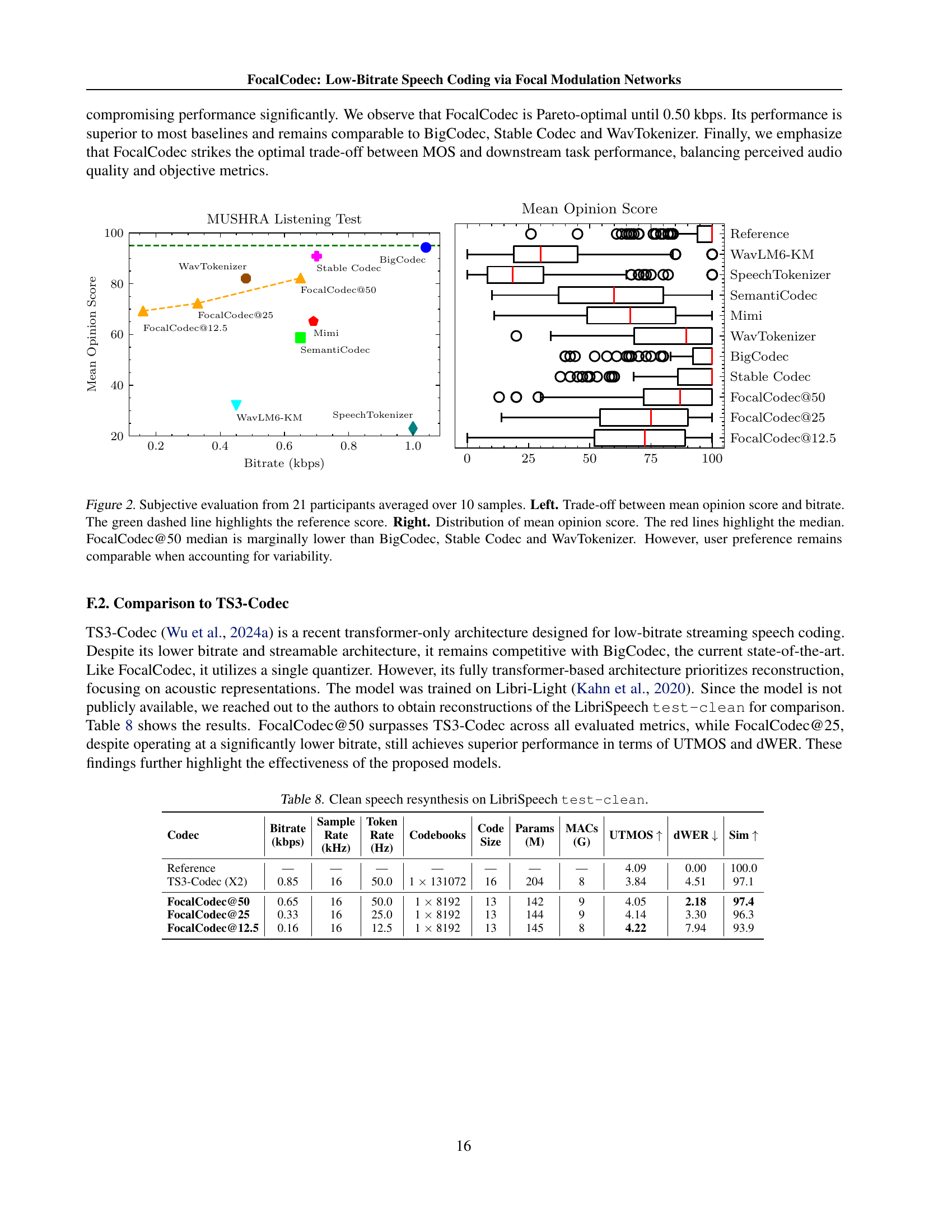
| Codec | Bitrate (kbps) | Sample Rate (kHz) | Token Rate (Hz) | Codebooks | Code Size | Params (M) | MACs (G) | UTMOS | dWER | Sim |
| Reference | — | — | — | — | — | — | — | 4.09 | 0.00 | 100.0 |
| TS3-Codec (X2) | 0.85 | 16 | 50.0 | 1 131072 | 16 | 204 | 8 | 3.84 | 4.51 | 97.1 |
| FocalCodec@50 | 0.65 | 16 | 50.0 | 1 8192 | 13 | 142 | 9 | 4.05 | 2.18 | 97.4 |
| FocalCodec@25 | 0.33 | 16 | 25.0 | 1 8192 | 13 | 144 | 9 | 4.14 | 3.30 | 96.3 |
| FocalCodec@12.5 | 0.16 | 16 | 12.5 | 1 8192 | 13 | 145 | 8 | 4.22 | 7.94 | 93.9 |
🔼 This table presents a comparison of the speech resynthesis performance on the LibriSpeech test-clean dataset for various codecs, including FocalCodec and several state-of-the-art baselines. Metrics shown include bitrate, sample rate, token rate, codebook size, number of parameters, multiply-accumulate operations per second (MACs), and objective quality measures such as UTMOS, dWER, and speaker similarity (Sim). This allows for a detailed comparison of both the efficiency and quality of the different codecs at achieving low-bitrate speech reconstruction.
read the caption
Table 8: Clean speech resynthesis on LibriSpeech test-clean.
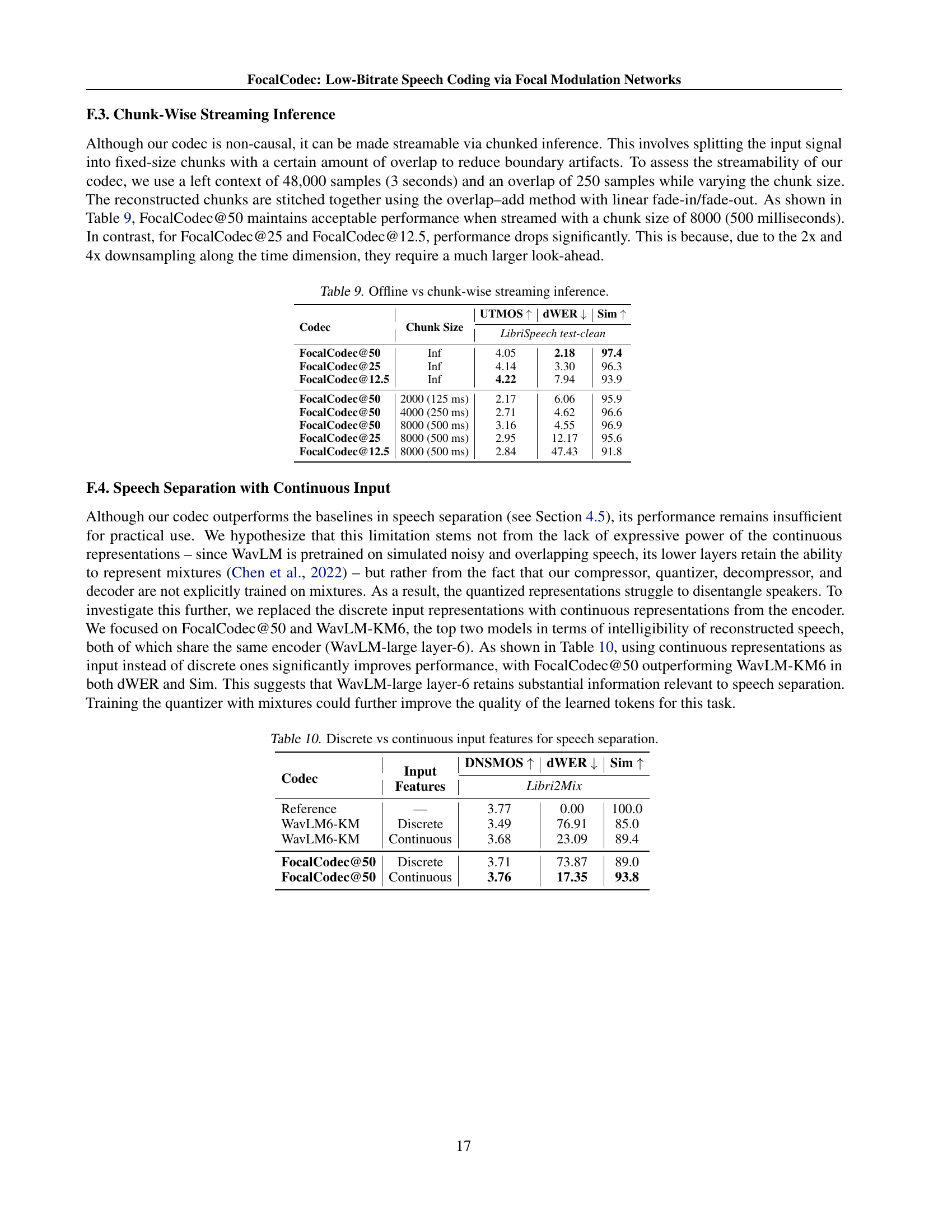
| Codec | Chunk Size | UTMOS | dWER | Sim |
| LibriSpeech test-clean | ||||
| FocalCodec@50 | Inf | 4.05 | 2.18 | 97.4 |
| FocalCodec@25 | Inf | 4.14 | 3.30 | 96.3 |
| FocalCodec@12.5 | Inf | 4.22 | 7.94 | 93.9 |
| FocalCodec@50 | 2000 (125 ms) | 2.17 | 6.06 | 95.9 |
| FocalCodec@50 | 4000 (250 ms) | 2.71 | 4.62 | 96.6 |
| FocalCodec@50 | 8000 (500 ms) | 3.16 | 4.55 | 96.9 |
| FocalCodec@25 | 8000 (500 ms) | 2.95 | 12.17 | 95.6 |
| FocalCodec@12.5 | 8000 (500 ms) | 2.84 | 47.43 | 91.8 |
🔼 This table compares the performance of FocalCodec at different bitrates (50Hz, 25Hz, and 12.5Hz) under offline and chunk-wise streaming inference conditions. It shows the effect of varying chunk sizes (in milliseconds) on the objective metrics UTMOS (quality), dWER (intelligibility), and Sim (speaker similarity) for the LibriSpeech test-clean dataset. This helps determine the feasibility of streaming for each bitrate.
read the caption
Table 9: Offline vs chunk-wise streaming inference.
| Codec | Input Features | DNSMOS | dWER | Sim |
| Libri2Mix | ||||
| Reference | — | 3.77 | 0.00 | 100.0 |
| WavLM6-KM | Discrete | 3.49 | 76.91 | 85.0 |
| WavLM6-KM | Continuous | 3.68 | 23.09 | 89.4 |
| FocalCodec@50 | Discrete | 3.71 | 73.87 | 89.0 |
| FocalCodec@50 | Continuous | 3.76 | 17.35 | 93.8 |
🔼 This table presents a comparison of speech separation performance using discrete versus continuous input features for two models: WavLM-KM6 and FocalCodec@50. It highlights the impact of using raw continuous speech representations as input to the downstream task instead of the quantized discrete representations generated by the codec. The metrics reported are DNSMOS (perceptual objective speech quality), dWER (differential word error rate indicating intelligibility), and Sim (speaker similarity). This comparison underscores the effect of the codec’s quantization process on the ability of the downstream model to effectively separate speech sources.
read the caption
Table 10: Discrete vs continuous input features for speech separation.
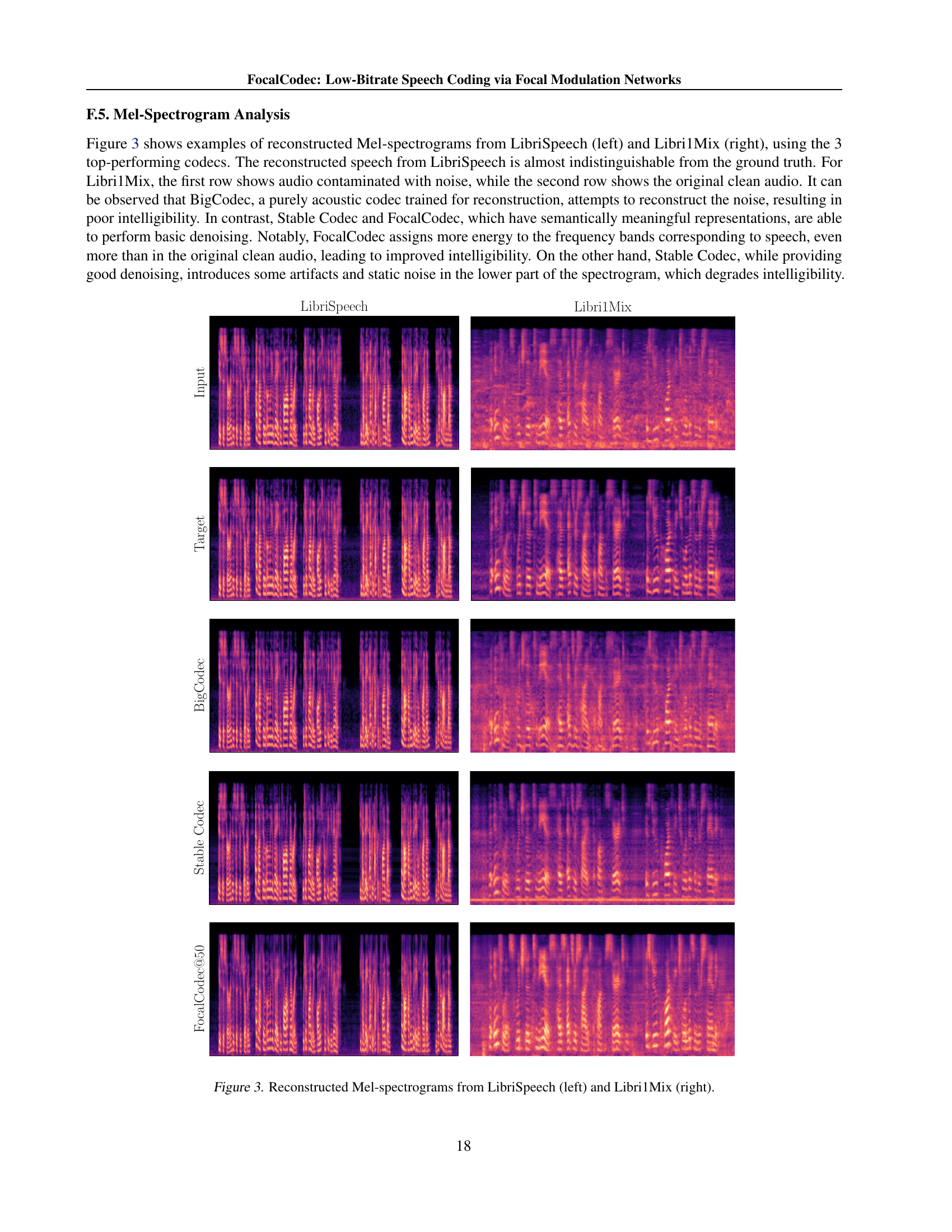
Full paper#