TL;DR#
Large language models (LLMs) are known for their impressive capabilities, but their ability to generalize and compose knowledge remains a subject of active debate. One major challenge is understanding how LLMs generalize to novel situations and avoid generating incorrect or hallucinatory outputs. Many researchers are working to improve LLMs’ capabilities in these aspects.
This research delves into the nature of LLM knowledge composition by examining the relationship between the ’logits’ (probability scores) of different knowledge prompts. They discovered a surprising phenomenon: a consistent linear relationship exists between the logits of related prompts. This means the model’s predictions for one type of prompt can be approximately derived from the predictions on a related one via a simple linear transformation. Further analysis revealed that this linear correlation is surprisingly stable, even after significant model fine-tuning. Importantly, the strength and accuracy of this linear transformation serve as an indicator of the LLM’s ability to generalize correctly to new knowledge combinations.
Key Takeaways#
Why does it matter?#
This paper is crucial because it uncovers a hidden linearity in language models’ knowledge composition. This finding challenges existing assumptions about how LMs generalize, providing a novel perspective on compositional generalization and hallucination. The identification of linear correlations as a predictor of generalization and hallucination offers a new diagnostic tool and opens new avenues for improving LM capabilities and mitigating unwanted behaviors.
Visual Insights#

🔼 This figure demonstrates two key findings about how language models (LMs) handle knowledge composition. First, it shows that a linear transformation can accurately map the prediction logits (the LM’s internal probabilities for the next word) from one type of knowledge prompt to another. For example, logits predicting the country someone lives in can be approximated linearly from the logits predicting the city they live in. Importantly, this linear relationship remains even after substantial further training of the LM (fine-tuning). Second, the figure illustrates how updating knowledge in one domain (e.g., correcting the LM’s knowledge about a city) propagates through this linear transformation to other related domains (e.g., updating knowledge about the country). This propagation can lead to either accurate generalizations (correctly updated information) or hallucinations (incorrectly inferred information) depending on whether the linear transformation accurately captures the underlying relationship between the knowledge domains.
read the caption
Figure 1: Demonstration of our main discoveries. 1) We can fit a linear transformation between the output of source and target knowledge prompts, which is resilient against fine-tuning. 2) Updating the source knowledge will generalize to the target one via resilient linearity, causing compositional generalization/hallucination.
| Family | Prompt | Domain Examples |
|---|---|---|
| Attribute | “X lives in the city of” | Paris, Vienna |
| “X lives in the country of” | France, Austria | |
| X-Lang. | “X vit dans la ville de” | Paris, Vienne |
| “X lebt in der Stadt von” | Paris, Wien | |
| Simile | “X has the same color as” | Apple, Banana |
| “X’s color is” | Red, Yellow | |
| Math | “X+1=” | 1, 2, 3, 4, 5 |
| “X*2=” | 2, 4, 6, 8, 10 |
🔼 This table presents examples of prompts used to investigate knowledge composition in large language models (LLMs). It showcases four families of knowledge composition: Attribute (e.g., relating city to country), Cross-language (e.g., translating ‘Paris’ to ‘Paris’ in different languages), Simile (e.g., connecting concepts based on shared attributes like color), and Math (e.g., performing arithmetic operations). Each family includes example prompts and the corresponding domains of potential outputs or target concepts. This illustrates the range of tasks explored to understand how LMs generalize across these different types of compositional relations.
read the caption
Table 1: Examples of prompts and domains in different families of knowledge composition.
In-depth insights#
Linear Knowledge#
The concept of “Linear Knowledge” in the context of large language models (LLMs) suggests that some relationships between pieces of knowledge are inherently linear. This linearity manifests as a linear transformation between the prediction logits of related prompts, meaning that the model’s confidence in one piece of knowledge can be directly predicted from its confidence in a related piece. This phenomenon is resilient to fine-tuning and even large-scale model updates, indicating a deep-seated aspect of how LMs structure information. This linearity mirrors human cognition in that we often associate related concepts in a straightforward manner (e.g., Paris-France). However, this linearity is a double-edged sword. While it facilitates compositional generalization in some cases, it can also lead to hallucinations when the linear mapping deviates from real-world relationships, creating inaccurate or fabricated knowledge.
LM Generalization#
The paper investigates the generalization capabilities of Large Language Models (LLMs), specifically focusing on compositional generalization and the phenomenon of hallucination. A core finding is the presence of resilient linear correlations between the output logits of related knowledge prompts, even after extensive fine-tuning. This suggests that LLMs leverage linear transformations to map knowledge from one domain to another, mirroring aspects of human knowledge composition. However, this linearity, while often enabling successful generalization, can also lead to hallucinations when the linear mapping deviates from real-world relationships. The study highlights the importance of both high correlation and precise linear transformations for successful generalization and emphasizes that vocabulary representations play a critical role in establishing these correlations.
Correlation’s Role#
The research paper explores the crucial role of linear correlations in large language models (LLMs), particularly concerning their compositional generalization capabilities. Linear correlations between the prediction logits of related knowledge pairs are identified as a key factor influencing how well LLMs generalize. This means that the LLM’s ability to accurately predict the next token in a sequence related to a given concept significantly depends on the existence and strength of linear relationships between those concepts’ representations within the model. The presence of a high linear correlation combined with a precise linear transformation (W, b) generally leads to successful generalization, allowing LLMs to apply knowledge learned in one context to a related but novel situation. However, when the correlation is high but the transformation matrix (W) is imprecise, the result is often compositional hallucination, where the model incorrectly generalizes knowledge, producing nonsensical or factually incorrect outputs. Thus, the study highlights the importance of analyzing both the strength of correlations and the accuracy of the learned linear transformations for understanding LLM generalization and for mitigating the risk of hallucination.
Vocabulary’s Impact#
The research paper significantly highlights vocabulary’s crucial role in the compositional generalization and hallucination observed in large language models (LLMs). The authors demonstrate that the linear correlations found between logits of related knowledge prompts are heavily influenced by, and strongly linked to, the underlying vocabulary representations. Experiments show that even a simplified model, using only a mean-pooling layer and a feedforward network with pre-trained vocabulary embeddings, can learn to compose knowledge successfully. This finding directly points to the importance of lexical mappings and suggests that the LLM’s ability to generalize or hallucinate is deeply rooted in how it processes and relates vocabulary items. Altering these mappings disrupts the compositional abilities, underlining the critical role of vocabulary representations in the overall functioning of the LLM. Therefore, improvements in LLM generalization and the mitigation of hallucination might require careful attention to enhancing the quality of vocabulary representations and their interrelationships within the model’s architecture.
Future Research#
Future research should focus on developing a formal theory explaining why resilient linear correlations emerge in language models. Investigating how model architecture, optimization dynamics, and linguistic structures contribute to these correlations is crucial. Further work must systematically analyze the influence of training data on correlation formation to better understand which data properties drive their emergence. A key area for investigation is creating a general method for predicting which knowledge pairs will exhibit linear correlations, going beyond specific examples like city-country. Finally, research should explore the implications of linear correlations for various tasks, including knowledge editing and hallucination mitigation, and determine how these correlations can be effectively leveraged for improved generalizable learning.
More visual insights#
More on figures
🔼 This figure illustrates the hypothesis that Language Models (LMs) learn a linear transformation (W, b) to compose knowledge. The core idea is that the model’s output logits for related knowledge prompts (e.g., ‘X lives in the city of’ and ‘X lives in the country of’) are linearly correlated. The figure poses four key questions. 1) Can a linear transformation (W, b) be fit between the logits of these related prompts? 2) Does this linear relationship hold for arbitrary inputs X, not just those that are explicitly paired in the training data? 3) Does fine-tuning the LM significantly alter the learned linear transformation (W, b)? 4) Which LM parameters contribute to the formation of this linear transformation?
read the caption
Figure 2: Our hypothesis and questions about how LMs compose knowledge by learning (W,b)𝑊𝑏(W,b)( italic_W , italic_b ).

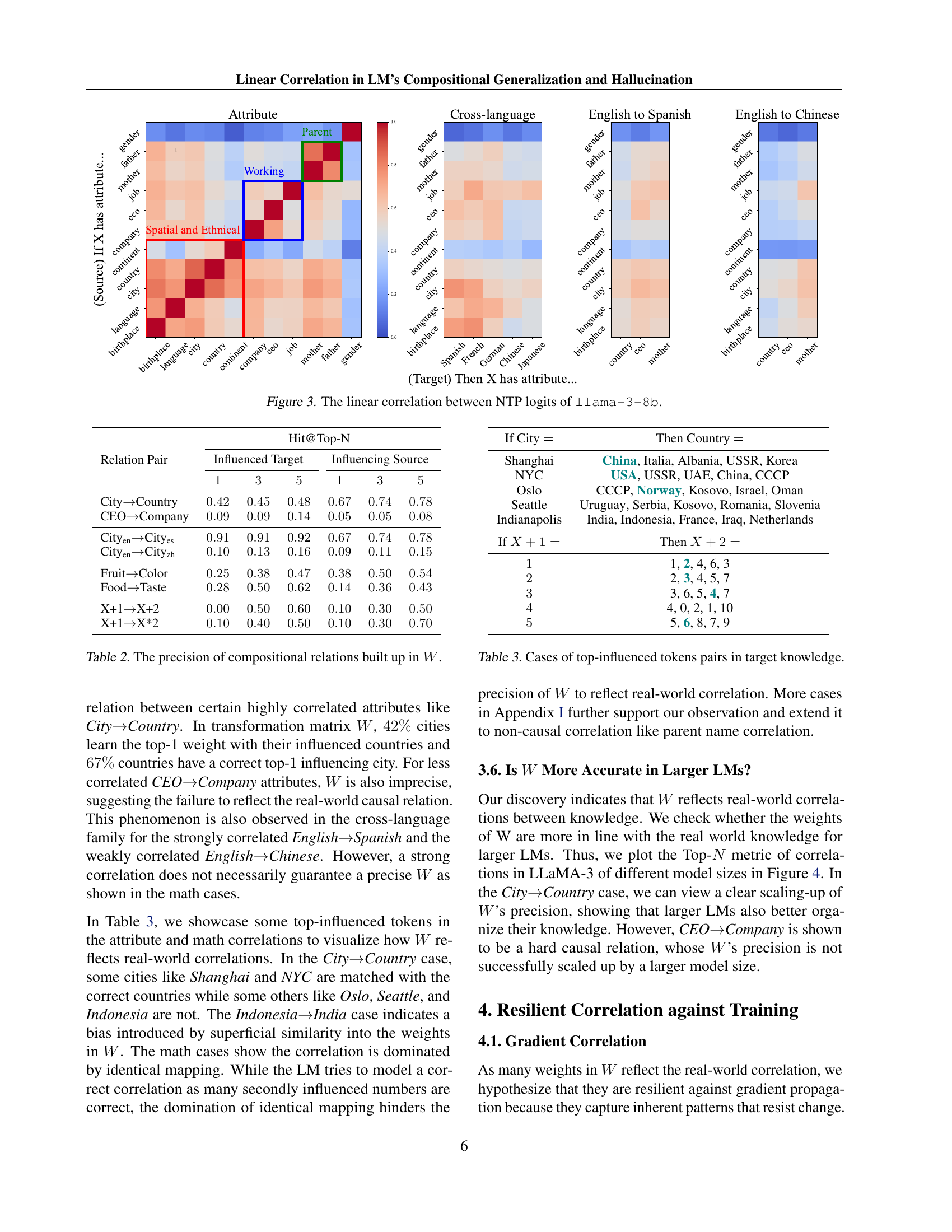
🔼 This figure displays a heatmap visualizing the linear correlation between the next-token prediction (NTP) logits from the LLaMA-3-8B language model. The heatmap shows the correlation between pairs of related knowledge prompts. Warmer colors (red) represent stronger positive correlations, while cooler colors (blue) indicate weaker or negative correlations. The figure helps illustrate the concept of resilient linearity in the model’s knowledge composition, revealing relationships between different knowledge subdomains.
read the caption
Figure 3: The linear correlation between NTP logits of llama-3-8b.

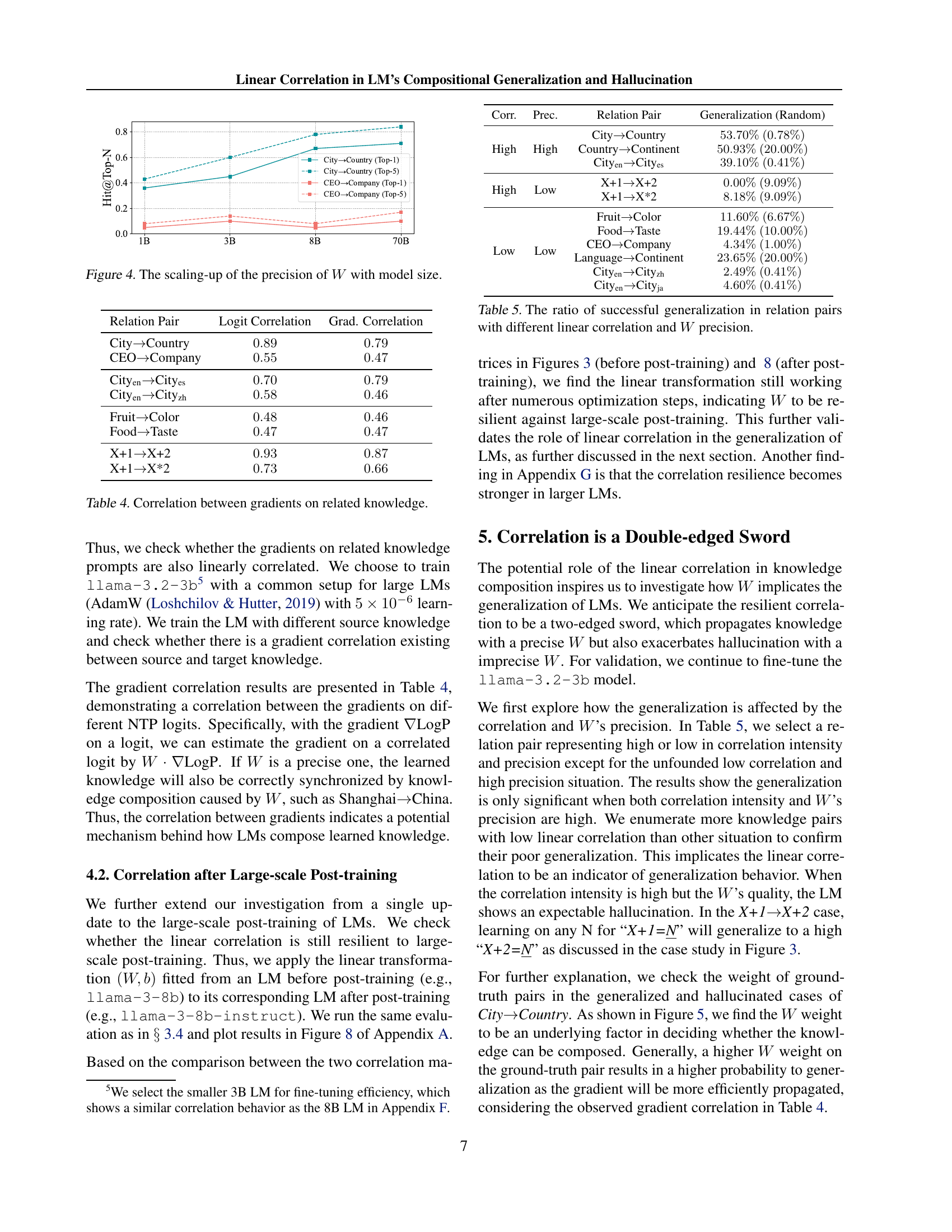
🔼 This figure shows how the precision of the linear transformation matrix W increases with the size of the language model. The precision is measured by the Hit@Top-N metric (where N=1 and 5 are shown), which indicates how frequently the model correctly identifies the most influential (or influenced) token pairs when composing knowledge. The figure uses the City-Country and CEO-Company knowledge pairs as examples, illustrating that larger models achieve higher precision in inferring relationships, particularly for the City-Country task.
read the caption
Figure 4: The scaling-up of the precision of W𝑊Witalic_W with model size.

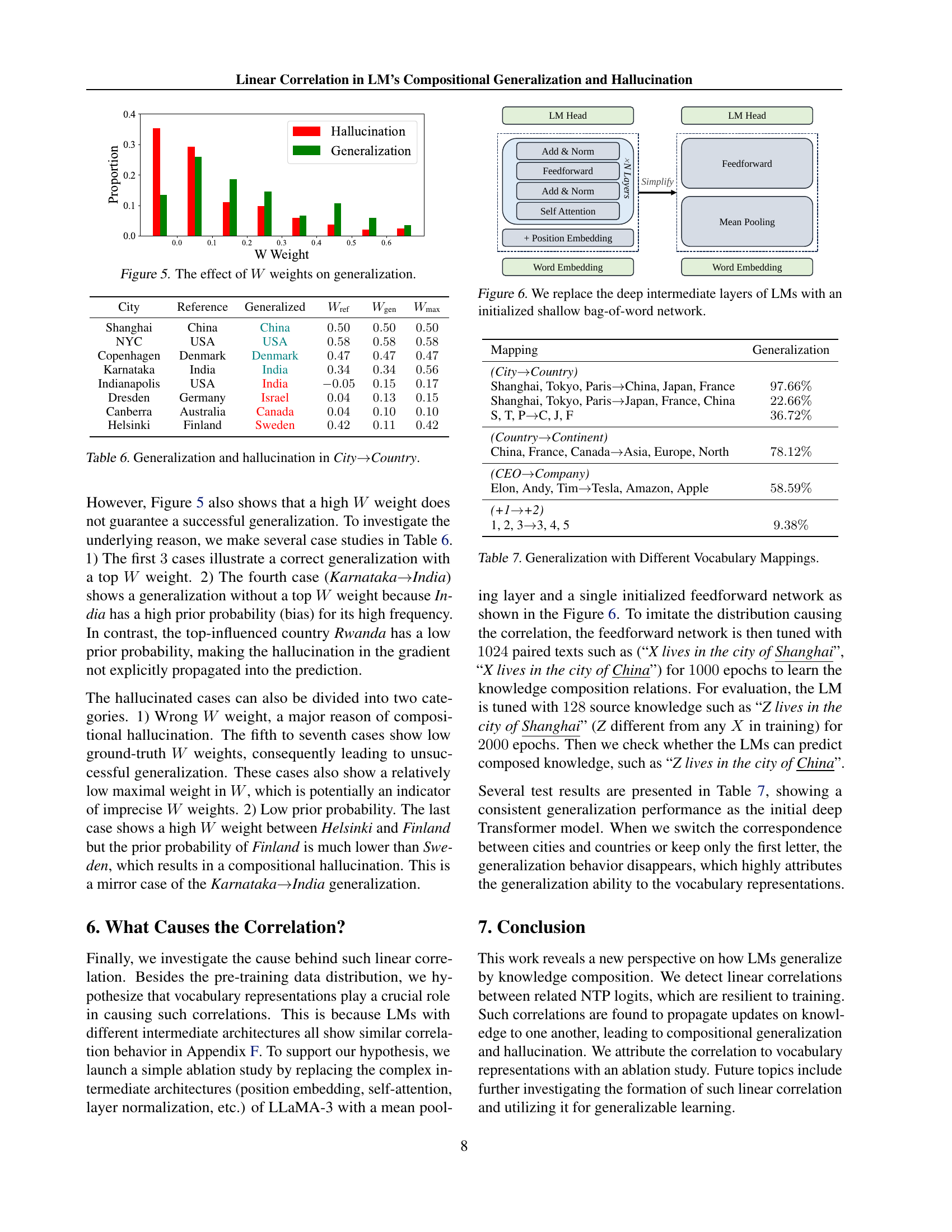
🔼 This figure illustrates the relationship between the weights of the linear transformation matrix W and the success of compositional generalization. The x-axis represents the weight assigned to a specific (City, Country) pair in matrix W. The y-axis represents the proportion of times this pair correctly generalizes (successful generalization) or results in a hallucination (hallucination). The bars show that high weights generally lead to successful generalization, while low weights are more likely to result in hallucinations. This indicates that the precision of W is critical for successful compositional generalization.
read the caption
Figure 5: The effect of W𝑊Witalic_W weights on generalization.

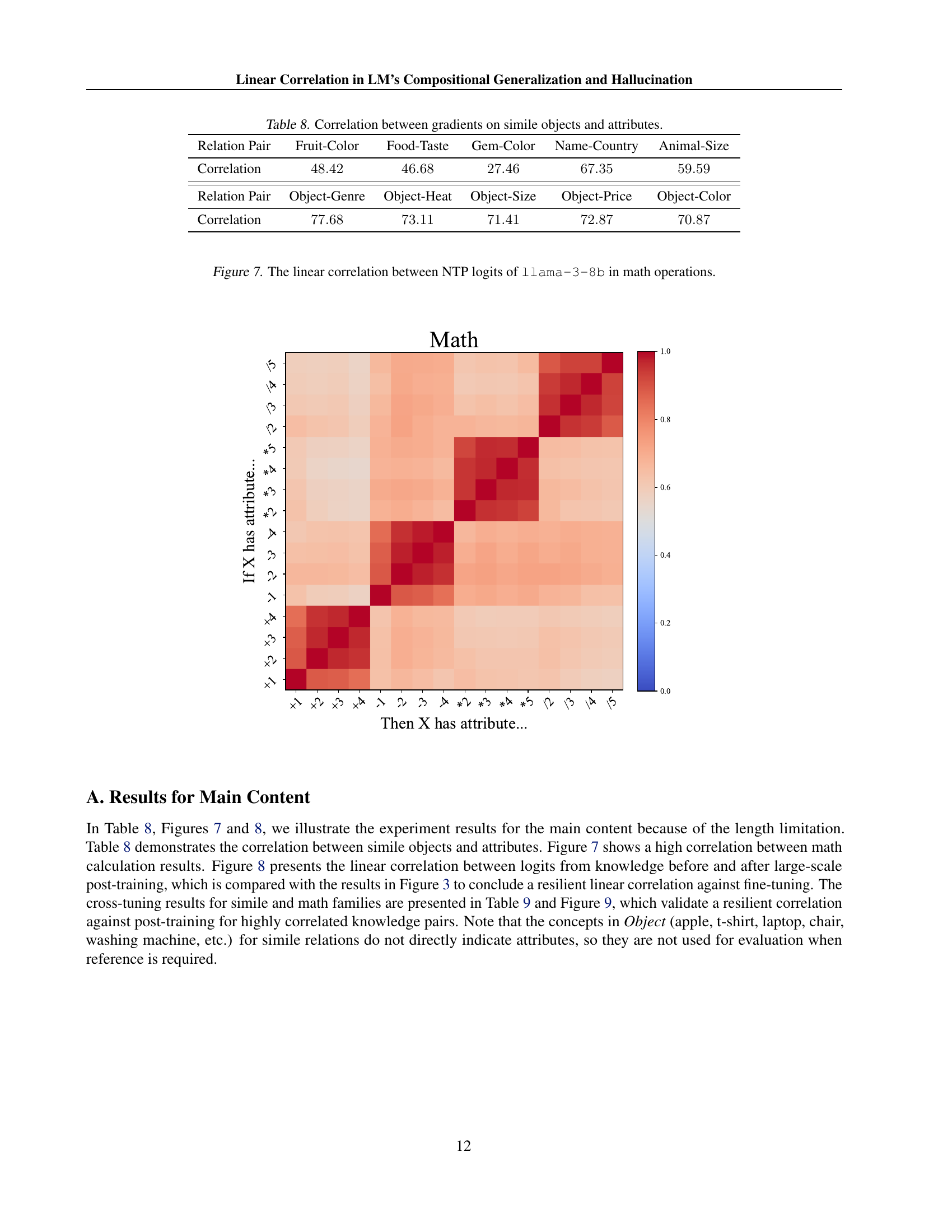
🔼 This figure illustrates an experiment to investigate the origin of linear correlations in Language Models (LMs). The researchers simplified the LM architecture by replacing its complex internal layers (e.g., self-attention, positional embeddings, etc.) with a simpler structure consisting only of a mean-pooling layer and a single feedforward network. This simplified model was trained on a small set of paired texts exhibiting the knowledge composition relations studied in the paper. The goal was to determine whether the simplified model could still learn and generalize the compositional knowledge relationships observed in larger, more complex LMs, thereby helping to isolate the factors responsible for the linear correlations found in those LMs. The simplified structure helps to show that the linear correlation is not caused by the complex inner workings of the transformer models.
read the caption
Figure 6: We replace the deep intermediate layers of LMs with an initialized shallow bag-of-word network.

🔼 This heatmap visualizes the linear correlation between next-token prediction (NTP) logits in the LLaMA-3-8B language model when performing mathematical operations. Each cell represents the correlation between logits from two different prompts involving math problems. The intensity of color corresponds to the strength of the correlation; darker red signifies stronger positive correlation, while darker blue represents stronger negative correlation. The diagonal represents perfect correlation (1.0). This figure helps to illustrate the extent to which the model uses linear relationships in solving mathematical problems and generating sequential tokens.
read the caption
Figure 7: The linear correlation between NTP logits of llama-3-8b in math operations.

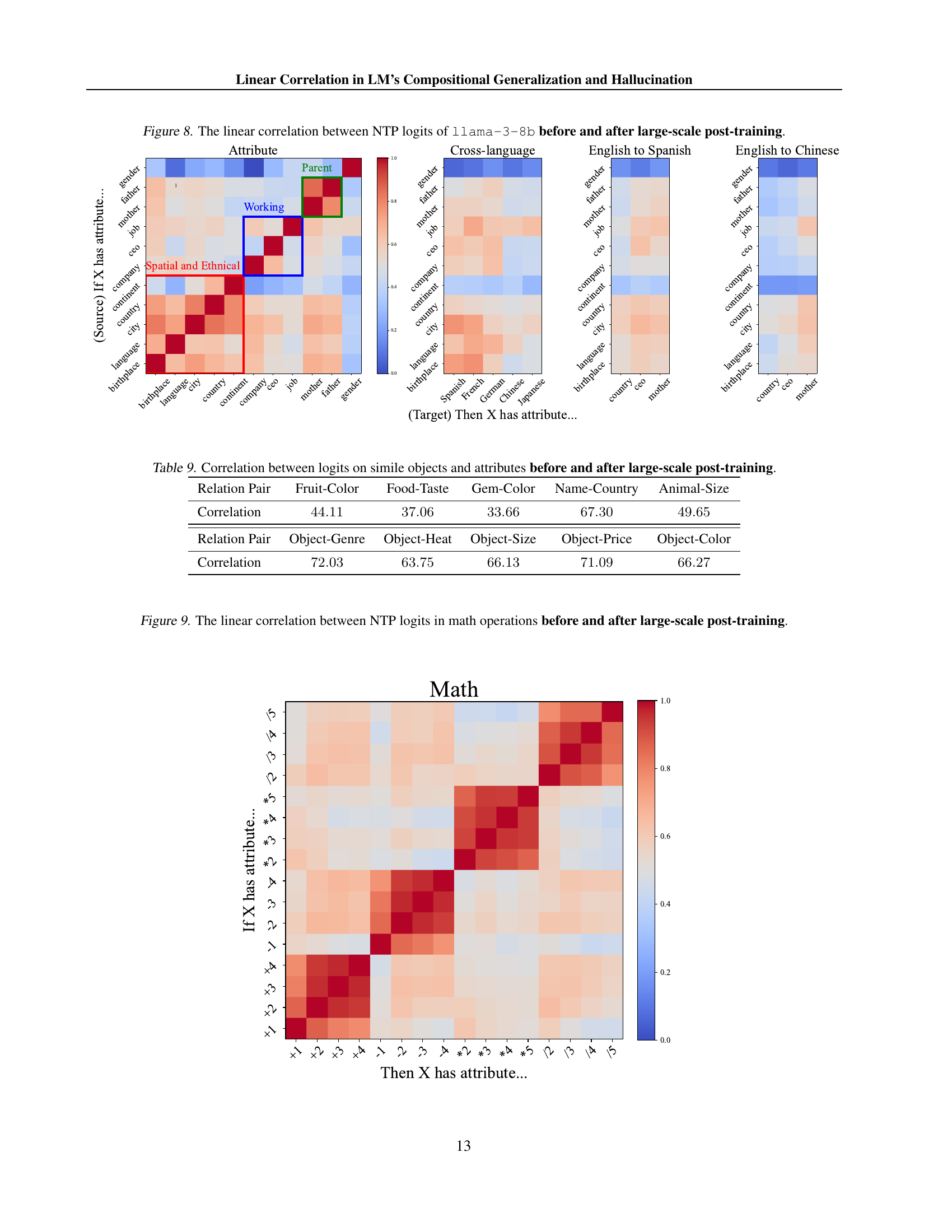
🔼 This figure visualizes the correlation matrices of next token prediction (NTP) logits from the LLaMA-3-8B language model. It compares the correlations before and after large-scale post-training. The color intensity in the matrix represents the strength of the correlation between logits; warmer colors indicate stronger correlations, while cooler colors represent weaker correlations. Comparing the two matrices allows for an assessment of how the model’s understanding of relationships between concepts changes after extensive fine-tuning, highlighting the resilience (or lack thereof) of the learned correlations to further training.
read the caption
Figure 8: The linear correlation between NTP logits of llama-3-8b before and after large-scale post-training.

🔼 This figure visualizes the correlation matrices of next token prediction (NTP) logits for mathematical operations before and after large-scale post-training. It shows the correlation coefficients between the logits generated by the language model for different mathematical expressions, both before any post-training fine-tuning and after a large-scale fine-tuning process. This allows for assessment of how robust the linear relationships between these logits are to significant model adjustments, and how the model’s understanding of mathematical composition changes.
read the caption
Figure 9: The linear correlation between NTP logits in math operations before and after large-scale post-training.

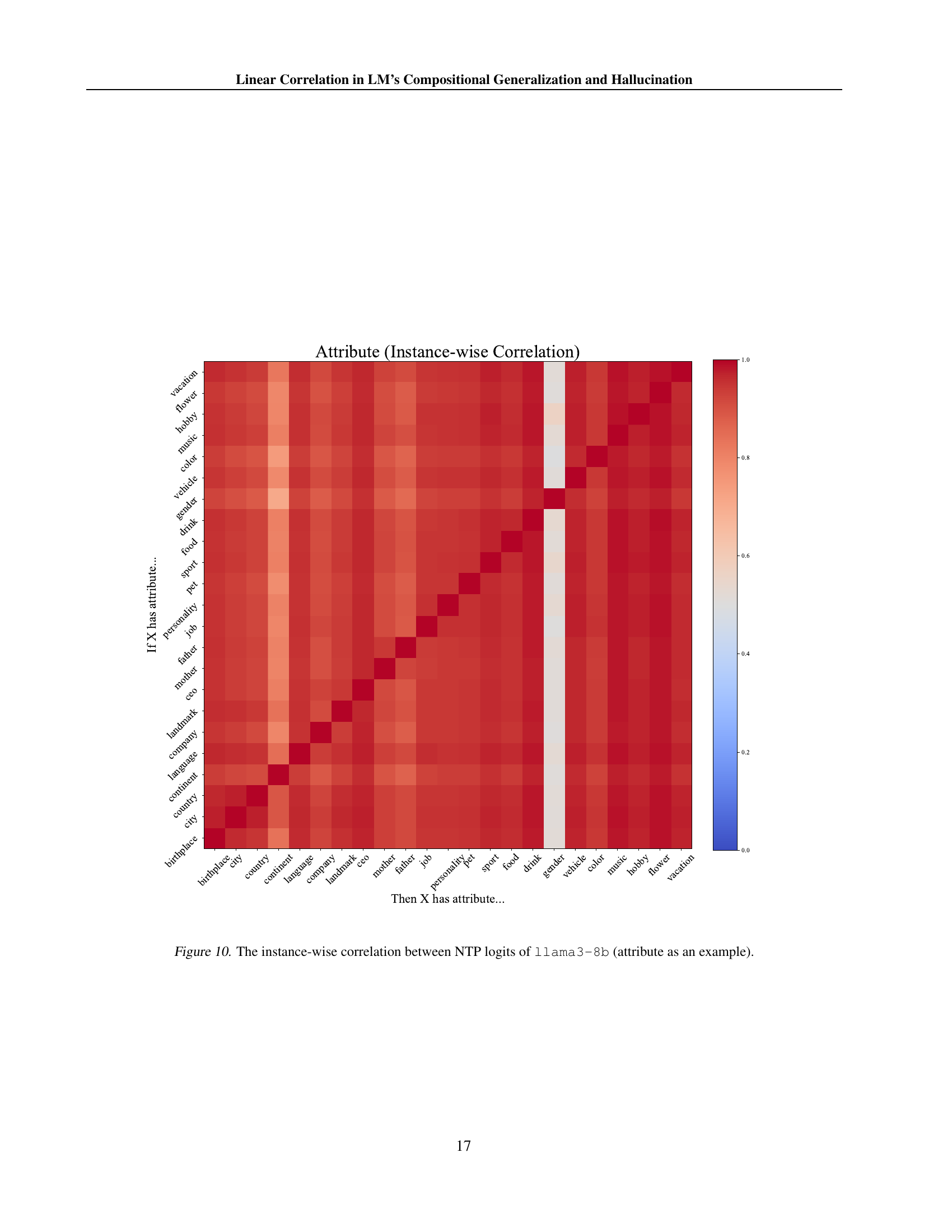
🔼 This figure displays the instance-wise correlation matrix for the next token prediction (NTP) logits of the LLaMA3-8b model, focusing on the ‘attribute’ knowledge family as an example. The matrix visualizes the Pearson correlation coefficients between the logits of different input-output word pairs within the attribute family. Higher correlation (redder colors) indicates a stronger linear relationship between the corresponding logits, suggesting that the model is more likely to generalize knowledge composition for those pairs. Conversely, lower correlation (bluer colors) indicates a weaker linear relationship and a higher likelihood of compositional generalization failures or hallucinations.
read the caption
Figure 10: The instance-wise correlation between NTP logits of llama3-8b (attribute as an example).

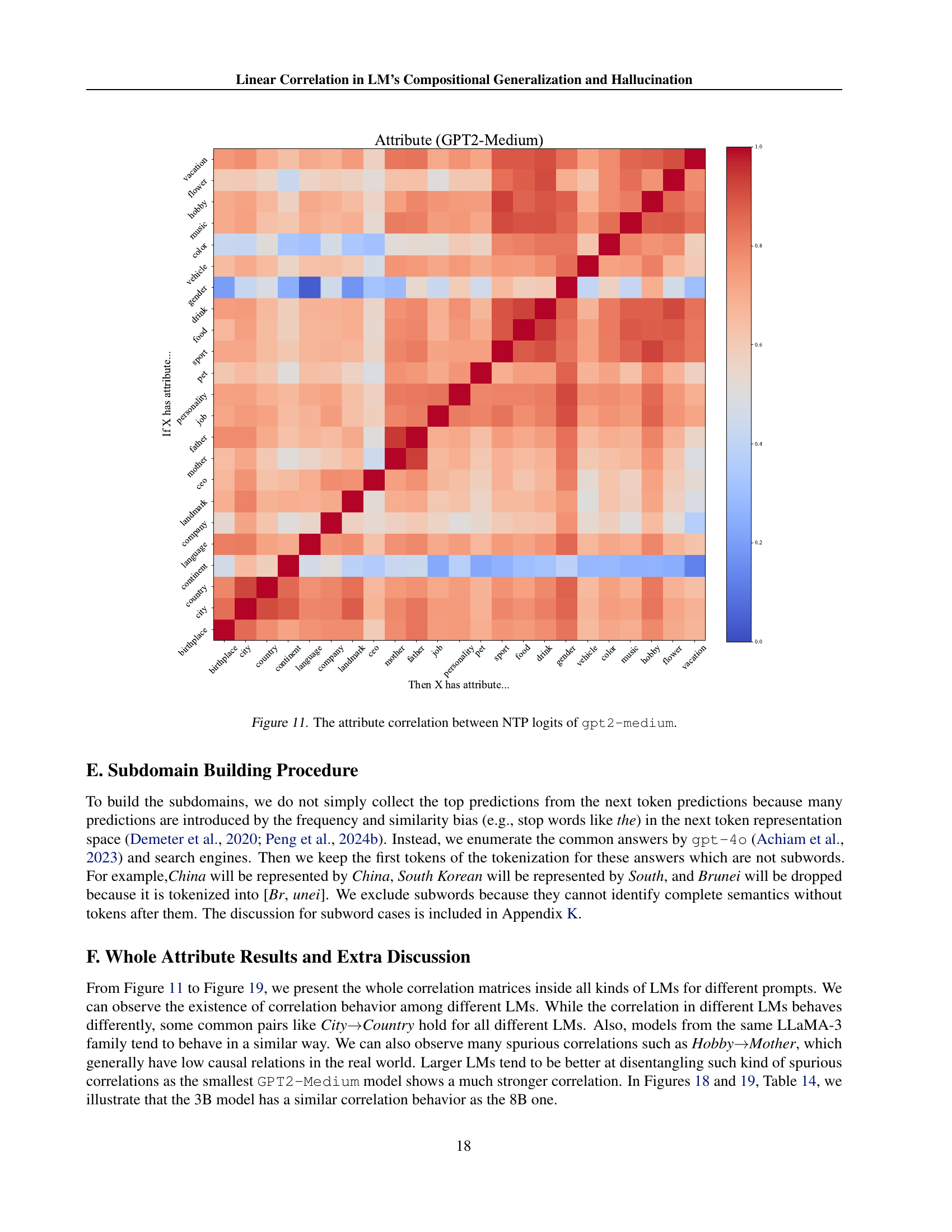
🔼 This figure displays a heatmap visualizing the correlation between next-token prediction (NTP) logits in the GPT-2-medium language model. The heatmap shows the correlation strength between different attributes, such as the correlation between ‘city’ and ‘country’ or ‘job’ and ‘company’. Warmer colors (red) indicate a stronger positive correlation, while cooler colors (blue) indicate a weaker or negative correlation. The diagonal line represents perfect correlation (1.0) between identical attributes. This visualization helps understand how the model associates different attributes in its internal representation of knowledge.
read the caption
Figure 11: The attribute correlation between NTP logits of gpt2-medium.

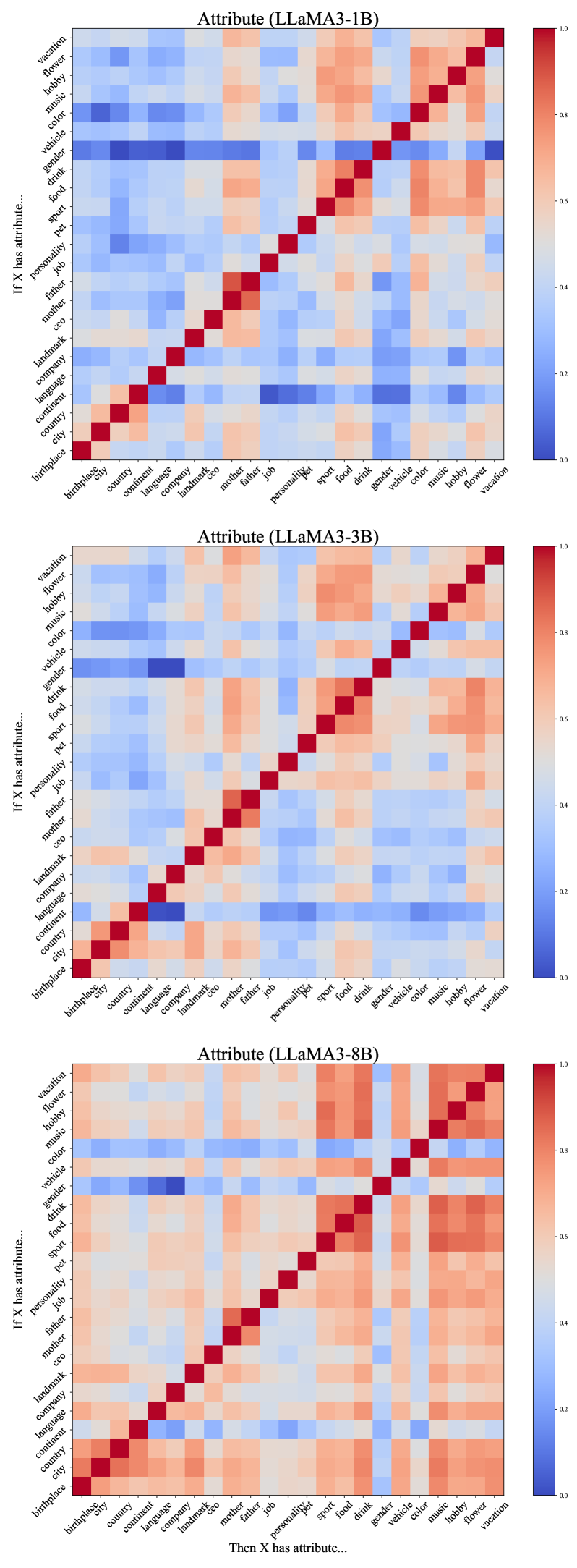
🔼 This figure shows a heatmap representing the correlation between the next-token prediction (NTP) logits of the LLaMA-3-1B language model for different attribute pairs. Each cell’s color intensity indicates the strength of the linear correlation between the logits of two attributes. Darker red indicates a strong positive correlation, while dark blue indicates a strong negative correlation. The diagonal shows perfect correlation, and the off-diagonal elements reveal the relationships between various attributes (e.g., city, country, job, personality, etc.). The figure helps visualize how the model associates and generalizes knowledge between related attributes.
read the caption
Figure 12: The attribute correlation between NTP logits of llama-3.2-1b.

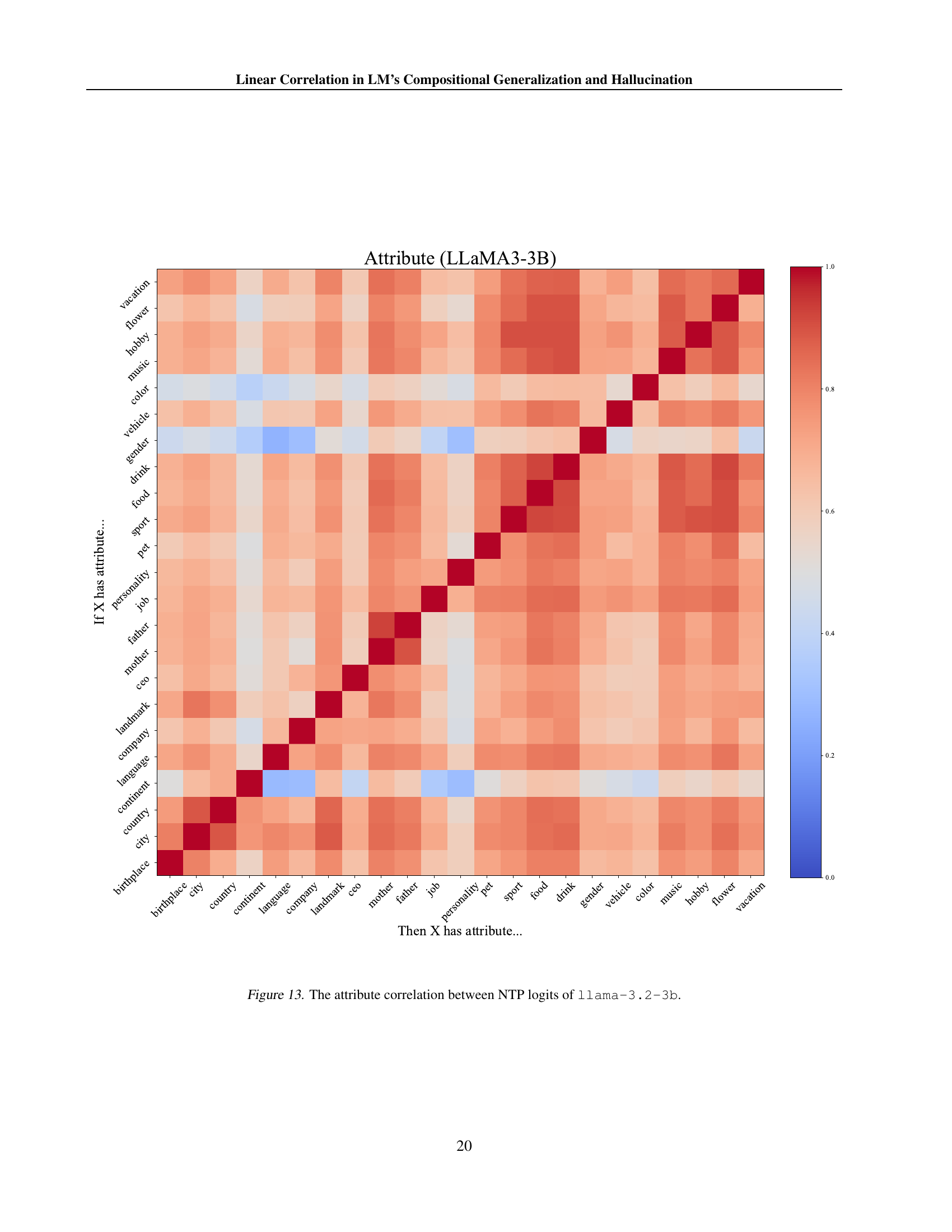
🔼 This heatmap visualizes the correlation between next-token prediction (NTP) logits from different attribute-related prompts in the LLaMA-3-3B language model. Each cell’s color intensity represents the correlation coefficient between the logits of two prompts, indicating the strength of their semantic relationship. Warmer colors suggest a stronger positive correlation, while cooler colors represent a negative or weaker correlation. The diagonal shows perfect correlation (1.0) as it compares a prompt’s logits to itself. This figure helps understand how the model relates different attributes in its knowledge representation.
read the caption
Figure 13: The attribute correlation between NTP logits of llama-3.2-3b.

🔼 This heatmap visualizes the correlation between the next-token prediction (NTP) logits of the LLaMA-3-8B language model for different attribute pairs. Each cell’s color intensity represents the correlation coefficient between the logits of two related attributes, indicating how strongly the model associates them. Darker red indicates a strong positive correlation, while dark blue represents a strong negative correlation. The attributes considered are likely related to various semantic fields like geography, occupation, family, etc. The figure aids in understanding the model’s implicit knowledge structures by highlighting strongly correlated attributes.
read the caption
Figure 14: The attribute correlation between NTP logits of llama-3-8b.

🔼 This heatmap visualizes the correlation between the next-token prediction logits of the LLaMA-3-70B language model for different attribute pairs. Each cell represents the correlation coefficient between the logits of two attributes (e.g., city and country). Warmer colors (red) indicate a higher positive correlation, while cooler colors (blue) show a negative correlation. The diagonal line represents the perfect correlation of an attribute with itself. The figure provides insights into how the model relates different attributes in its internal knowledge representation, revealing potential linear relationships between certain attributes which might explain compositional generalization or hallucination.
read the caption
Figure 15: The attribute correlation between NTP logits of llama-3-70b.

🔼 This heatmap visualizes the correlation between the next-token prediction (NTP) logits from different attribute prompts in the Deepseek-r1-distll-qwen-7B language model. Each row and column represents a specific attribute prompt (e.g., ‘X lives in the city of’, ‘X works for the company’). The color intensity at the intersection of a row and column indicates the strength of the correlation between the corresponding attribute pairs. Darker red shades signify high positive correlation, while darker blue shades indicate high negative correlation. The diagonal line shows perfect correlation because an attribute is perfectly correlated with itself. This visualization helps to understand how different attributes are related and interconnected within the language model’s knowledge representation.
read the caption
Figure 16: The attribute correlation between NTP logits of deepseek-r1-distll-qwen-7B.

🔼 This heatmap visualizes the correlation between the next-token prediction (NTP) logits of the Mistral-7b-v0.3 language model for various attribute pairs. Each cell represents the correlation between the logits of two attributes. Strong positive correlations (red) indicate that the model strongly associates the two attributes, suggesting a strong learned relationship in the model. Negative correlations (blue) mean the model associates the attributes inversely. The diagonal line shows perfect correlation between an attribute and itself. This figure helps understand the nature of knowledge composition within the model.
read the caption
Figure 17: The attribute correlation between NTP logits of mistral-7b-v0.3.

🔼 This heatmap visualizes the linear correlation between next-token prediction (NTP) logits from different knowledge prompts in the LLaMA-3-8B language model. The rows and columns represent source and target knowledge prompts, respectively, and the color intensity of each cell reflects the strength of the linear correlation between the logits of the corresponding prompts. Darker red indicates a strong positive correlation, while darker blue indicates a strong negative correlation. The figure is used to illustrate the existence of linear correlations between related knowledge pairs and the resilience of these correlations to large-scale fine-tuning. The specific knowledge categories are indicated within the heatmap.
read the caption
Figure 18: The linear correlation between NTP logits of llama-3.2-3b.

🔼 This figure visualizes the correlation matrices of next token prediction (NTP) logits from the LLaMA-3 3B parameter model. The left panel shows the correlation before large-scale post-training, while the right panel shows the correlation after the post-training. Comparing these two matrices reveals the resilience of linear correlations in the model’s parameters to significant fine-tuning. The color intensity in each matrix represents the strength of the correlation between different logits. Darker reds indicate strong positive correlations, while darker blues indicate strong negative correlations. The figure provides visual evidence that relationships between logits captured before fine-tuning are largely maintained after the model undergoes substantial post-training.
read the caption
Figure 19: The linear correlation between NTP logits of llama-3.2-3b before and after large-scale post-training.
🔼 This figure displays the correlation matrices for three different sizes of LLAMA language models (1B, 3B, and 8B parameters) before and after large-scale post-training. It visually demonstrates how the linear correlation between next-token prediction (NTP) logits of related knowledge pairs, as established prior to fine-tuning, remains consistent even after extensive post-training. The increased robustness of the correlation in larger models suggests that the effect is more prominent and resilient in models with greater scale and capacity.
read the caption
Figure 20: The correlation becomes more resilient in larger LMs.

🔼 This figure displays heatmaps visualizing the correlation between next-token prediction (NTP) logits from the Mistral-7b-v0.3 language model. It compares the correlation matrices before and after large-scale post-training. The heatmaps allow for a visual comparison of how the relationships between different word tokens change before and after the model undergoes further training. A strong correlation between logits suggests a stronger relationship between corresponding words, highlighting the impact of post-training on the model’s understanding of word relationships.
read the caption
Figure 21: The correlation between logits from mistral-7b-v0.3 before and after post-training.

🔼 This figure compares the cross-lingual correlation of language models between Aya and LLaMA. Specifically, it visualizes the correlation between language pairs’ output logits. The heatmaps illustrate the strength of linear correlation discovered in the study. Higher correlation indicates a stronger association between the logits of related concepts in different languages. The comparison highlights how the multilingual nature of Aya impacts its ability to correlate concepts in diverse languages, particularly when compared to the primarily English-centric training of LLaMA. Note that this comparison focuses on the consistency of correlated concepts, not the accuracy or completeness of the concepts themselves.
read the caption
Figure 22: The comparison between Aya and LLaMA in cross-lingual correlation.

🔼 This figure visualizes the standard deviation (std) of the label-wise correlation distribution between next token prediction (NTP) logits. It provides insight into how consistent the linear correlations are across different knowledge pairs and addresses the concern that the correlation might primarily reflect the majority property of labels or be biased by highly correlated pairs. The heatmap shows the standard deviations, with lower values indicating more consistent correlations.
read the caption
Figure 23: The std of correlation distribution between logits.

🔼 This figure shows the standard deviation (std) of the label-wise Pearson correlation coefficients before and after large-scale post-training. It visualizes the dispersion or spread of the correlation values across different pairs of next-token prediction (NTP) logits. A low standard deviation indicates that the correlations are clustered around a central value, implying a more consistent relationship between the logits, whereas a higher standard deviation indicates more variability in the strength of the linear relationships. This analysis helps assess the robustness of the linear correlation against the large-scale fine-tuning process, demonstrating its resilience in capturing consistent patterns in the data.
read the caption
Figure 24: The std of correlation distribution between logits before and after large-scale post-training.
More on tables
| Relation Pair | Hit@Top-N | |||||
|---|---|---|---|---|---|---|
| Influenced Target | Influencing Source | |||||
| CityCountry | ||||||
| CEOCompany | ||||||
| CityCity | ||||||
| CityCity | ||||||
| FruitColor | ||||||
| FoodTaste | ||||||
| X+1X+2 | ||||||
| X+1X*2 | ||||||
🔼 This table presents the precision of compositional relationships learned by the language model and captured in the weight matrix W. It shows how accurately the model’s learned associations between source and target knowledge reflect real-world relationships for various knowledge pairs. Higher precision indicates a stronger alignment between the model’s knowledge and human understanding of those relationships. The table includes metrics like Hit@Top-N (for N=1, 3, 5) to evaluate the accuracy of the top-ranked predictions made by the model.
read the caption
Table 2: The precision of compositional relations built up in W𝑊Witalic_W.
| If City | Then Country |
|---|---|
| Shanghai | China, Italia, Albania, USSR, Korea |
| NYC | USA, USSR, UAE, China, CCCP |
| Oslo | CCCP, Norway, Kosovo, Israel, Oman |
| Seattle | Uruguay, Serbia, Kosovo, Romania, Slovenia |
| Indianapolis | India, Indonesia, France, Iraq, Netherlands |
| If | Then |
| 1, 2, 4, 6, 3 | |
| 2, 3, 4, 5, 7 | |
| 3, 6, 5, 4, 7 | |
| 4, 0, 2, 1, 10 | |
| 5, 6, 8, 7, 9 |
🔼 This table presents examples of top-influenced tokens in target knowledge after applying a linear transformation (W,b) to source knowledge logits. It demonstrates the precision of the learned transformation (W,b) in predicting correct target knowledge tokens and showcases instances where the transformation yields either accurate generalization or hallucinations. For each knowledge pair (e.g., City-Country), the table shows the top-influenced tokens in the target knowledge for various source knowledge tokens and compares them to ground truth values. The purpose is to illustrate the connection between the linear transformation, its precision, and the outcome of compositional generalization (accurate or hallucinatory).
read the caption
Table 3: Cases of top-influenced tokens pairs in target knowledge.
| Relation Pair | Logit Correlation | Grad. Correlation |
|---|---|---|
| CityCountry | ||
| CEOCompany | ||
| CityCity | ||
| CityCity | ||
| FruitColor | ||
| FoodTaste | ||
| X+1X+2 | ||
| X+1X*2 |
🔼 This table presents the correlation coefficients between gradients of related knowledge pairs before fine-tuning. For each pair of related knowledge prompts (e.g., City-Country, CEO-Company), it shows the Pearson correlation between the gradients calculated during the training process. This helps illustrate the relationship between gradients on different next-token-prediction (NTP) logits, providing insight into how the language model (LM) generalizes and updates knowledge during training. High correlation suggests a stronger linear relationship in the gradient space between the two prompts, indicating that updating one prompt’s knowledge is likely to simultaneously update the other due to the inherent correlation.
read the caption
Table 4: Correlation between gradients on related knowledge.
| Corr. | Prec. | Relation Pair | Generalization (Random) |
|---|---|---|---|
| High | High | CityCountry | |
| CountryContinent | |||
| CityCity | |||
| High | Low | X+1X+2 | |
| X+1X*2 | |||
| Low | Low | FruitColor | |
| FoodTaste | |||
| CEOCompany | |||
| LanguageContinent | |||
| CityCity | |||
| CityCity |
🔼 This table presents the results of an experiment evaluating the impact of linear correlation and the precision of a learned linear transformation (W) on the generalization performance of language models (LMs). Specifically, it shows the percentage of successful generalization across various relation pairs (e.g., City-Country, CEO-Company) categorized by levels of linear correlation (high/low) and W precision (high/low). The results demonstrate the importance of both factors for successful compositional generalization in LMs.
read the caption
Table 5: The ratio of successful generalization in relation pairs with different linear correlation and W𝑊Witalic_W precision.
| City | Reference | Generalized | |||
|---|---|---|---|---|---|
| Shanghai | China | China | |||
| NYC | USA | USA | |||
| Copenhagen | Denmark | Denmark | |||
| Karnataka | India | India | |||
| Indianapolis | USA | India | |||
| Dresden | Germany | Israel | |||
| Canberra | Australia | Canada | |||
| Helsinki | Finland | Sweden |
🔼 This table presents a case study demonstrating the effects of the linear transformation (W, b) on compositional generalization and hallucination in the City→Country knowledge domain. It shows example pairs of cities and their corresponding countries where the model correctly generalizes (high W weight and correct association) and where it hallucinates (low or incorrect W weight, resulting in incorrect country assignments). The table illustrates the interplay between the strength of linear correlation, precision of W, and the accuracy of the model’s compositional generalization.
read the caption
Table 6: Generalization and hallucination in City→→\rightarrow→Country.
| Mapping | Generalization |
|---|---|
| (CityCountry) | |
| Shanghai, Tokyo, ParisChina, Japan, France | |
| Shanghai, Tokyo, ParisJapan, France, China | |
| S, T, PC, J, F | |
| (CountryContinent) | |
| China, France, CanadaAsia, Europe, North | |
| (CEOCompany) | |
| Elon, Andy, TimTesla, Amazon, Apple | |
| (+1+2) | |
| 1, 2, 33, 4, 5 |
🔼 This table presents the results of an experiment evaluating the impact of vocabulary mappings on the model’s ability to generalize. The experiment replaced the deep internal layers of a language model with a simplified feedforward network. The model was trained on paired knowledge examples (e.g., Paris-France) to learn knowledge composition. The table shows the generalization performance of the simplified model under different vocabulary mappings, demonstrating how different mappings affect generalization.
read the caption
Table 7: Generalization with Different Vocabulary Mappings.
| Relation Pair | Fruit-Color | Food-Taste | Gem-Color | Name-Country | Animal-Size |
|---|---|---|---|---|---|
| Correlation | |||||
| Relation Pair | Object-Genre | Object-Heat | Object-Size | Object-Price | Object-Color |
| Correlation |
🔼 This table presents the correlation coefficients between gradients of related simile objects and attributes in a language model. It shows how strongly the gradients of different but semantically related parts of the model are correlated during the training process. This is relevant to understanding how the model generalizes compositional knowledge and is particularly useful in evaluating the precision of the linear transformation (W,b) learned by the model. A high correlation indicates that the model is efficiently transferring updates during training.
read the caption
Table 8: Correlation between gradients on simile objects and attributes.
| Relation Pair | Fruit-Color | Food-Taste | Gem-Color | Name-Country | Animal-Size |
|---|---|---|---|---|---|
| Correlation | |||||
| Relation Pair | Object-Genre | Object-Heat | Object-Size | Object-Price | Object-Color |
| Correlation |
🔼 This table presents the Pearson correlation coefficients between the logits of next-token prediction (NTP) tasks related to simile objects and their attributes. It shows correlations before and after large-scale fine-tuning (post-training) of the language model. This allows for an assessment of how well the model maintains its ability to generalize knowledge composition regarding similes after undergoing significant parameter updates. Higher correlation suggests better compositional generalization.
read the caption
Table 9: Correlation between logits on simile objects and attributes before and after large-scale post-training.
| Template | Domain Size |
|---|---|
| Attribute | |
| Cross-language | |
| Simile | |
| Math | |
| Total |
🔼 This table presents a summary of the number of prompts used in the experiments, categorized by four different families of knowledge composition: Attribute, Cross-language, Simile, and Math. It shows the total number of prompts used across all families, highlighting the distribution of prompts among the four types. This breakdown is essential for understanding the scope and balance of the experimental design.
read the caption
Table 10: The statistics of prompts in different families.
| Knowledge | Template | Domain Size | |
|---|---|---|---|
| Attribute | birthplace | “{} was born in the city of” | 242 |
| city | “{} lives in the city of” | 242 | |
| country | “{} lives in the country of” | 128 | |
| continent | “{} lives in the continent of” | 6 | |
| language | “{} speaks the language of” | 217 | |
| company | “{} works for the company of” | 100 | |
| landmark | “{} lives near the landmark of” | 100 | |
| ceo | “{} works for the CEO called” | 101 | |
| mother | “{}’s mother’s name is” | 100 | |
| father | “{}’s father’s name is” | 100 | |
| job | “{}’s job is” | 105 | |
| personality | “{}’s personality is” | 100 | |
| pet | “{}’s pet is” | 100 | |
| sport | “{}’s favorite sport is” | 102 | |
| food | “{}’s favorite food is” | 104 | |
| drink | “{}’s favorite drink is” | 102 | |
| gender | “{}’s gender is” | 3 | |
| vehicle | “{}’s preferred mode of transportation is” | 51 | |
| color | “{}’s favorite color is” | 15 | |
| music | “{}’s favorite music genre is” | 100 | |
| hobby | “{}’s favorite hobby is” | 101 | |
| flower | “{}’s favorite flower is” | 97 | |
| vacation | “{}’s favorite vacation spot is” | 101 | |
🔼 This table lists the various prompts used in the experiments in the Attribute family. Each row shows a knowledge template, the associated prompt used to elicit responses from language models, and the size of the domain for which that template was applied (i.e., number of distinct entities considered). The goal is to investigate how language models compose knowledge by learning a linear transformation between different knowledge domains. For example, a prompt such as ‘X lives in the city of’ relates to the source knowledge domain of cities, and it is paired with a target knowledge domain, such as countries, using prompts like ‘X lives in the country of.’
read the caption
Table 11: Templates used in our experiments (Part 1: Attribute).
| Knowledge | Template | Domain Size | |
|---|---|---|---|
| Spanish | birthplace | “{} nació en la ciudad de” | 242 |
| city | “{} vive en la ciudad de” | 242 | |
| country | “{} vive en el país de” | 128 | |
| continent | “{} vive en el continente de” | 6 | |
| language | “{} habla el idioma de” | 217 | |
| company | “{} trabaja para la empresa de” | 100 | |
| ceo | “{} trabaja para el CEO llamado” | 101 | |
| job | “El trabajo de {} es” | 105 | |
| mother | “El nombre de la madre de {} es” | 100 | |
| father | “{} el nombre del padre es” | 100 | |
| gender | “El género de {} es” | 3 | |
| French | birthplace | “{} est né dans la ville de” | 242 |
| city | “{} vit dans la ville de” | 242 | |
| country | “{} vit dans le pays de” | 128 | |
| continent | “{} vit sur le continent de” | 6 | |
| language | “{} parle la langue de” | 217 | |
| company | “{} travaille pour l’entreprise de” | 100 | |
| ceo | “{} travaille pour le PDG appelé” | 101 | |
| job | “{} travaille comme” | 105 | |
| mother | “Le nom de la mère de {} est” | 100 | |
| father | “Le nom du père de {} est” | 100 | |
| gender | “{} est de sexe” | 3 | |
| German | birthplace | “{} wurde in der Stadt geboren” | 242 |
| city | “{} lebt in der Stadt” | 242 | |
| country | “{} lebt im Land” | 128 | |
| continent | “{} lebt auf dem Kontinent” | 6 | |
| language | “{} spricht die Sprache von” | 217 | |
| company | “{} arbeitet für das Unternehmen von” | 100 | |
| ceo | “{} arbeitet für den CEO namens” | 101 | |
| job | “Der Beruf von {} ist” | 105 | |
| mother | “Der Name von {}’s Mutter ist” | 100 | |
| father | “Der Name von {}’s Vater ist” | 100 | |
| gender | “Das Geschlecht von {} ist” | 3 | |
| Chinese | birthplace | {CJK}UTF8gbsn“{}所出生的城市是” | 242 |
| city | {CJK}UTF8gbsn“{}所居住的城市是” | 242 | |
| country | {CJK}UTF8gbsn“{}所居住的国家是” | 128 | |
| continent | {CJK}UTF8gbsn“{}所居住的大陆是” | 6 | |
| language | {CJK}UTF8gbsn“{}说的语言是” | 217 | |
| company | {CJK}UTF8gbsn“{}工作的公司是” | 100 | |
| ceo | {CJK}UTF8gbsn“{}工作的公司的CEO是” | 101 | |
| job | {CJK}UTF8gbsn“{}的工作是” | 105 | |
| mother | {CJK}UTF8gbsn“{}的母亲的名字是” | 100 | |
| father | {CJK}UTF8gbsn“{}的父亲的名字是” | 100 | |
| gender | {CJK}UTF8gbsn“{}的性别是” | 3 | |
| Japanese | birthplace | {CJK}UTF8min“{}が生まれた都市は” | 242 |
| city | {CJK}UTF8min“{}が住んでいる都市は” | 242 | |
| country | {CJK}UTF8min“{}が住んでいる国は” | 128 | |
| continent | {CJK}UTF8min“{}が住んでいる大陸は” | 6 | |
| language | {CJK}UTF8min“{}が話している言語は” | 217 | |
| company | {CJK}UTF8min“{}が働いている会社は” | 100 | |
| ceo | {CJK}UTF8min“{}が働いている会社のCEOは” | 101 | |
| job | {CJK}UTF8min“{}の仕事は” | 105 | |
| mother | {CJK}UTF8min“{}の母の名前は” | 100 | |
| father | {CJK}UTF8min“{}の父の名前は” | 100 | |
| gender | {CJK}UTF8min“{}の性別は” | 3 | |
🔼 This table lists the various sentence templates used in the cross-language experiments of the research paper. Each template is designed to test the model’s ability to generalize knowledge across different languages. The table provides the knowledge type being tested (e.g., birthplace, city, country), the template in each target language (English, Spanish, French, German, Chinese, Japanese), and the number of distinct entities used for evaluation within each language for that template. The purpose is to systematically explore how the linear correlation between source and target language logits varies across different language pairs and knowledge types.
read the caption
Table 12: Templates used in our experiments (Part 2: Cross Language).
| Knowledge | Template | Domain Size | |
| Simile | object_color | “The color of {} is the same as” | 85 |
| object_price | “The size of {} is the same as” | 85 | |
| object_heat | “The heat of {} is the same as” | 85 | |
| object_genre | “The genre of {} is the same as” | 85 | |
| object_size | “The size of {} is the same as” | 85 | |
| simile_color | “The color of {} is” | 15 | |
| simile_price | “The size of {} is” | 2 | |
| simile_heat | “The heat of {} is” | 4 | |
| simile_genre | “The genre of {} is” | 22 | |
| simile_size | “The size of {} is” | 3 | |
| simile_taste | “The taste of {} is” | 3 | |
| name_country | “{} lives in the same country as” | 128 | |
| gem_color | “The color of {} is the same as the gem called” | ||
| animal_size | “The size of {} is the same as the animal called” | ||
| food_taste | “{} has the same taste as the food:” | ||
| fruit_color | “{} X has the same color as the fruit:” | ||
| Math | X+N | “{}+N=” | 11 |
| X-N | “{}-N=” | 11 | |
| X*N | “{}*N=” | 11 | |
| X/N | “{}/N=” | 11 | |
🔼 This table lists the prompts used in the Simile and Math sections of the experiments. For Simile, it shows various prompts comparing attributes of different objects (color, price, heat, genre, size) using phrases like “The color of {} is the same as”. For Math, it displays prompts involving basic arithmetic operations (+, -, *, /) applied to an unknown variable represented by {}. Each prompt is categorized by the knowledge type it tests (object color, object price, etc.) and indicates the size of the domain of possible responses for each prompt.
read the caption
Table 13: Templates used in our experiments (Part 3: Simile and Math).
| Relation Pair | Fruit-Color | Food-Taste | Gem-Color | Name-Country | Animal-Size |
|---|---|---|---|---|---|
| Correlation | |||||
| Relation Pair | Object-Genre | Object-Heat | Object-Size | Object-Price | Object-Color |
| Correlation |
🔼 This table presents the Pearson correlation coefficients between the logits of the LLaMA-3-2-3B language model for pairs of simile objects and their attributes. It shows the strength of linear relationships between the model’s predictions for different simile attributes (like color, size, taste) given a simile object. Higher values indicate stronger correlations, suggesting a closer semantic relationship between the attributes within the model’s representation.
read the caption
Table 14: Correlation between logits of llama-3.2-3b on simile objects and attributes.
| Country | Influencing Cities |
|---|---|
| Sweden | Stockholm, Brisbane, Johannesburg, Cardiff, Chicago, Hyderabad, Aleppo, Lima, Rochester, Salem |
| Cuba | Havana, Chicago, Columbus, stockholm, Rochester, Hyderabad, Scarborough, Johannesburg, singapore, Hamburg |
| Switzerland | Columbus, Stuttgart, Cardiff, Leicester, Chicago, Brisbane, Saras, stockholm, vegas, Bethlehem |
| Ghana | Winnipeg, Nairobi, Johannesburg, Leicester, Atlanta, Tulsa, Maharashtra, Greenville, Brisbane, Lima |
| Poland | Warsaw, Cardiff, Liverpool, Maharashtra, stockholm, Amsterdam, Atlanta, Kashmir, Perth, Aleppo |
| Turkey | Istanbul, Chicago, Toronto, Maharashtra, stockholm, Johannesburg, Cardiff, Lima, Columbus, Ankara |
| Sudan | Nairobi, stockholm, Lima, Tulsa, Johannesburg, Maharashtra, Winnipeg, Hyderabad, Wilmington, Kashmir |
| Romania | Cardiff, Rochester, Johannesburg, Budapest, Seattle, Rajasthan, Hyderabad, Chicago, Kyoto, Lima |
| Samoa | Maharashtra, Leicester, Winnipeg, Chicago, Honolulu, Brisbane, Nairobi, Hyderabad, Lima, Cardiff |
| Iceland | Cardiff, Leicester, Chicago, Amsterdam, Wilmington, Islamabad, Winnipeg, Kyoto, Hyderabad, stockholm |
| Nigeria | Winnipeg, Nairobi, Maharashtra, Lagos, Johannesburg, Stuttgart, Leicester, Abu, Chicago, Tulsa |
| Iraq | Chicago, Hyderabad, Wilmington, Lima, Baghdad, stockholm, Kashmir, Tulsa, Belfast, singapore |
| Laos | Bangkok, Leicester, Chicago, Kashmir, Tulsa, stockholm, Winnipeg, Lima, Rajasthan, Johannesburg |
| USSR | Moscow, NYC, Midlands, stockholm, Chicago, Cardiff, Maharashtra, Pyongyang, Boulder, Columbus |
| Kosovo | Kashmir, Seattle, Leicester, stockholm, Tulsa, Belfast, Mosul, vegas, Rochester, Buenos |
| China | Beijing, Shanghai, Hyderabad, Brisbane, Columbus, stockholm, Maharashtra, Amsterdam, Leicester, Hamburg |
| Guatemala | Greenville, Tulsa, Leicester, Buenos, Johannesburg, Kashmir, Wilmington, Lima, Chicago, Rochester |
| Tunisia | Johannesburg, stockholm, Hamburg, Columbus, Leicester, Tulsa, Stuttgart, Winnipeg, Cardiff, Maharashtra |
| Denmark | Copenhagen, Cardiff, Leicester, Brisbane, Hyderabad, Atlanta, Saras, Chicago, Hamburg, Salem |
| Nicaragua | Nairobi, Bangkok, Rochester, Leicester, Amsterdam, Kerala, Maharashtra, Belfast, Winnipeg, Chicago |
| Türkiye | Maharashtra, München, Seattle, İstanbul, stockholm, Jakarta, Istanbul, Toronto, Milwaukee, Kyoto |
| Bosnia | Hyderabad, Islamabad, Belfast, Johannesburg, Jakarta, Cardiff, Rochester, Kashmir, Leicester, Lima |
| Netherlands | Amsterdam, Cardiff, Midlands, Columbus, Karachi, stockholm, Nottingham, Maharashtra, Saras, Wilmington |
| Malaysia | Leicester, Kuala, Cardiff, Hamburg, Maharashtra, Baltimore, Chicago, Columbus, Johannesburg, Hyderabad |
| Venezuela | Wilmington, vegas, Cardiff, Maharashtra, Rochester, Brisbane, stockholm, Buenos, Lima, Tulsa |
| Sri | Leicester, Atlanta, Kashmir, Rajasthan, Nairobi, Cardiff, stockholm, Lima, Maharashtra, Islamabad |
| Ireland | Dublin, Cardiff, Belfast, Leicester, Tehran, Johannesburg, Stuttgart, Aleppo, Bethlehem, Hyderabad |
| Liberia | Leicester, Winnipeg, Nairobi, Johannesburg, Chicago, Kerala, Rochester, Maharashtra, Atlanta, Greenville |
| Afghanistan | Kabul, Cardiff, Islamabad, stockholm, Tulsa, Chicago, Maharashtra, Kashmir, Rajasthan, Leicester |
| America | Columbus, Chicago, Belfast, Sofia, Hyderabad, Seattle, Cardiff, Johannesburg, Maharashtra, Moscow |
| Austria | Cardiff, Vienna, Hamburg, Hyderabad, Leicester, Bethlehem, Stuttgart, stockholm, Columbus, Rajasthan |
| Scotland | Cardiff, Glasgow, Edinburgh, Stuttgart, stockholm, Belfast, Leicester, Columbus, Maharashtra, Lima |
| Libya | Chicago, stockholm, Columbus, Leicester, Aleppo, Cardiff, Mosul, Lima, Wilmington, Johannesburg |
| Uruguay | Buenos, Seattle, Hyderabad, Maharashtra, Hamburg, Johannesburg, Wilmington, Leicester, Columbus, Cardiff |
| Bangladesh | Winnipeg, Cardiff, Leicester, Maharashtra, Tulsa, Atlanta, Chicago, Bangalore, Islamabad, Kashmir |
| Bahrain | Leicester, Chicago, Brisbane, Kashmir, Lima, Riyadh, Dubai, Wilmington, Atlanta, Saras |
| Pakistan | Islamabad, Cardiff, Jakarta, Karachi, Tulsa, Leicester, Winnipeg, Atlanta, Maharashtra, Wilmington |
| Fiji | Lima, Leicester, Fargo, Kashmir, Brisbane, Winnipeg, Johannesburg, Cardiff, Tulsa, Edinburgh |
| Cambodia | Bangkok, Tulsa, Leicester, Cardiff, stockholm, Kashmir, Johannesburg, Wilmington, Kabul, Lima |
| Singapore | singapore, Chicago, Leicester, Brisbane, Hamburg, Columbus, Atlanta, Kashmir, Johannesburg, Cardiff |
| Macedonia | Leicester, Stuttgart, Winnipeg, Rochester, Kashmir, Johannesburg, Jakarta, Maharashtra, Budapest, Lima |
| Mongolia | Winnipeg, Chattanooga, Leicester, Lima, Cardiff, Kyoto, Maharashtra, Johannesburg, Rajasthan, Hamburg |
| Peru | Lima, Perth, Maharashtra, Winnipeg, Leicester, Chattanooga, Seattle, Hyderabad, Nairobi, Chicago |
| Myanmar | Bangkok, Cardiff, Tulsa, Leicester, Winnipeg, Kashmir, Maharashtra, Kyoto, Lima, Chicago |
| Trinidad | Leicester, Cardiff, Maharashtra, Brisbane, Rochester, Tulsa, Winnipeg, Abu, vegas, Johannesburg |
| Colombia | Maharashtra, Columbus, Lima, Seattle, Rochester, Wilmington, Johannesburg, Stuttgart, Amsterdam, Hyderabad |
| Maurit | Winnipeg, Leicester, Johannesburg, Edinburgh, Cardiff, Chicago, Stuttgart, stockholm, Moscow, Wilmington |
| Iran | Tehran, Cardiff, Lima, Kashmir, Hyderabad, Leicester, Aleppo, Chicago, Stuttgart, Hamburg |
| India | Indianapolis, Cardiff, Maharashtra, Chicago, Hyderabad, Leicester, Lima, Columbus, Winnipeg, stockholm |
| Spain | Madrid, Hyderabad, stockholm, Spokane, Cardiff, Amsterdam, Rome, Barcelona, Dallas, Johannesburg |
| Honduras | Wilmington, Winnipeg, Buenos, Hamburg, Nairobi, stockholm, Johannesburg, Amsterdam, Columbus, Lima |
| USA | NYC, Moscow, Columbus, Midlands, Chicago, Sofia, Karnataka, Karachi, Cardiff, Sevilla |
🔼 This table presents the top cities that most strongly influence the prediction of a given country in a language model’s next-token prediction. For each country, the listed cities represent those with the highest weights in the model’s internal linear transformation, reflecting the strongest learned associations between city and country.
read the caption
Table 15: The most influencing cities of counties in the City→→\rightarrow→Country correlation.
| Father | Influencing Mothers |
|---|---|
| Omar | Olivia, Nora, Sara, Sofia, Naomi, Diana, Uma, Rosa, Eden, Jade |
| Victor | Victoria, Sofia, Maria, Savannah, Sophie, Uma, Sonia, Angela, Grace, Ivy |
| Andre | Angela, Sofia, Sophie, Savannah, Maria, Rebecca, Ivy, Clara, Chloe, Nina |
| Julio | Sofia, Chloe, Maria, Carmen, Rebecca, Ivy, Rosa, Olivia, Sonia, Savannah |
| Enrique | Carmen, Chloe, Rosa, Clara, Sofia, Emma, Maria, Rebecca, Fiona, Olivia |
| Amir | Sara, Sofia, Amelia, Eden, Mei, Nora, Uma, Bella, Victoria, Diana |
| Xavier | Sophie, Maria, Sonia, Olivia, Emma, Leah, Clara, Uma, Jasmine, Carmen |
| Javier | Carmen, Chloe, Sofia, Ivy, Maria, Jasmine, Olivia, Rosa, Fiona, Jennifer |
| Vlad | Elena, Sofia, Chloe, Mia, Nina, Angela, Diana, Naomi, Savannah, Clara |
| Roberto | Chloe, Sofia, Rosa, Carmen, Lucia, Olivia, Clara, Mei, Maria, Elena |
| Lars | Sophie, Clara, Maria, Nina, Ella, Sara, Harper, Savannah, Rebecca, Fiona |
| Min | Sonia, Mei, Angela, Eden, Clara, Chloe, Grace, Maria, Harper, Savannah |
| James | Grace, Fiona, Ella, Savannah, Emma, Angela, Chloe, Harper, Leah, Maria |
| Giovanni | Lucia, Fiona, Sofia, Savannah, Rosa, Diana, Bella, Chloe, Carmen, Mei |
| Ivan | Ivy, Elena, Sofia, Nina, Maria, Ada, Emma, Sophie, Savannah, Sakura |
| Diego | Chloe, Sofia, Maria, Rosa, Angela, Carmen, Savannah, Diana, Clara, Mei |
| Fernando | Maria, Rosa, Fiona, Savannah, Carmen, Angela, Sofia, Luna, Clara, Ada |
| Ethan | Elena, Leah, Jennifer, Emma, Jasmine, Chloe, Clara, Mei, Ada, Serena |
| Chen | Mei, Chloe, Grace, Nina, Eden, Harper, Sofia, Rebecca, Sakura, Sonia |
| Gabriel | Maria, Sophie, Eden, Leah, Sara, Grace, Chloe, Rebecca, Elena, Luna |
| Boris | Bella, Elena, Angela, Fiona, Nina, Ada, Sofia, Sophie, Nora, Leah |
| Jean | Sophie, Angela, Chloe, Maria, Naomi, Carmen, Savannah, Nina, Rebecca, Lucia |
| Dmitry | Sofia, Elena, Chloe, Diana, Nina, Savannah, Mia, Clara, Sakura, Ivy |
| Ahmed | Sara, Sofia, Sophie, Nora, Uma, Victoria, Eden, Sonia, Jennifer, Mei |
| Wei | Mei, Chloe, Grace, Rebecca, Mia, Sofia, Ada, Nina, Angela, Harper |
| Ibrahim | Sofia, Sara, Eden, Uma, Victoria, Nora, Bella, Ada, Sophie, Elena |
| Liam | Fiona, Emma, Mia, Chloe, Nora, Leah, Grace, Jasmine, Jade, Angela |
| Mustafa | Sara, Sofia, Nora, Victoria, Ada, Uma, Eden, Jade, Rosa, Elena |
| Jorge | Maria, Carmen, Rosa, Chloe, Sofia, Diana, Elena, Fiona, Angela, Nora |
| Leonardo | Clara, Sofia, Jennifer, Olivia, Chloe, Jasmine, Fiona, Rosa, Lucia, Diana |
| Luca | Fiona, Lucia, Sofia, Angela, Maria, Savannah, Emma, Clara, Sakura, Leah |
| Carlos | Carmen, Maria, Rosa, Olivia, Chloe, Sofia, Clara, Sakura, Savannah, Fiona |
| Pedro | Maria, Rosa, Carmen, Chloe, Olivia, Clara, Sakura, Sofia, Ivy, Ada |
| Michel | Sophie, Lucia, Nina, Maria, Leah, Eden, Elena, Sara, Sonia, Carmen |
| Kai | Mei, Maria, Nina, Angela, Chloe, Eden, Jade, Uma, Sakura, Ada |
| Benjamin | Leah, Eden, Bella, Rebecca, Sophie, Grace, Nina, Harper, Lucia, Victoria |
| Noah | Rebecca, Chloe, Nina, Nora, Eden, Naomi, Sara, Grace, Leah, Ada |
| Ali | Sara, Nora, Eden, Victoria, Uma, Sofia, Mei, Jade, Bella, Sonia |
| Levi | Chloe, Leah, Eden, Sara, Nina, Elena, Harper, Bella, Rosa, Rebecca |
| Antonio | Rosa, Maria, Angela, Lucia, Sofia, Chloe, Savannah, Olivia, Carmen, Fiona |
| Rafael | Sofia, Rosa, Carmen, Maria, Clara, Leah, Ivy, Chloe, Naomi, Lucia |
| Marco | Maria, Sofia, Jasmine, Lucia, Clara, Angela, Chloe, Mei, Rebecca, Carmen |
| Stefan | Elena, Fiona, Angela, Savannah, Clara, Sophie, Mei, Maria, Eden, Rebecca |
| Chung | Mei, Chloe, Grace, Maria, Angela, Sonia, Harper, Clara, Savannah, Mia |
| Abdul | Uma, Sara, Sofia, Nora, Jennifer, Ada, Rosa, Victoria, Eden, Bella |
| Muhammad | Sofia, Sara, Victoria, Mei, Emily, Jennifer, Nora, Uma, Eden, Naomi |
| Hugo | Maria, Sophie, Chloe, Clara, Fiona, Emma, Savannah, Angela, Carmen, Ivy |
| Axel | Sophie, Angela, Rebecca, Nina, Ada, Emma, Fiona, Ivy, Eden, Savannah |
| Lucas | Lucia, Maria, Clara, Fiona, Uma, Chloe, Harper, Savannah, Sophie, Jasmine |
| Mason | Harper, Leah, Jasmine, Chloe, Angela, Nina, Ada, Sofia, Ella, Emma |
| Hassan | Sara, Eden, Nora, Victoria, Bella, Sofia, Naomi, Savannah, Mei, Diana |
| Pablo | Maria, Chloe, Sofia, Rosa, Savannah, Rebecca, Carmen, Elena, Fiona, Luna |
| Raphael | Rebecca, Sophie, Elena, Leah, Rosa, Grace, Eden, Fiona, Clara, Sonia |
| Elijah | Elena, Eden, Rebecca, Chloe, Savannah, Ella, Leah, Emily, Grace, Uma |
| Louis | Sophie, Nina, Savannah, Grace, Rosa, Maria, Rebecca, Fiona, Leah, Sonia |
| Ricardo | Chloe, Carmen, Sofia, Rosa, Jennifer, Clara, Rebecca, Sakura, Mei, Olivia |
| Samuel | Sonia, Savannah, Leah, Eden, Rebecca, Sophie, Grace, Ada, Emma, Clara |
| William | Grace, Emma, Emily, Leah, Ada, Harper, Angela, Victoria, Fiona, Diana |
| Salman | Sonia, Sofia, Nora, Uma, Sara, Bella, Eden, Jennifer, Victoria, Leah |
| Oliver | Olivia, Sophie, Harper, Elena, Nina, Maria, Grace, Diana, Emma, Nora |
| Angelo | Angela, Sofia, Fiona, Clara, Chloe, Rosa, Carmen, Savannah, Lucia, Nina |
| Hans | Sophie, Rebecca, Angela, Savannah, Eden, Ella, Clara, Maria, Uma, Mei |
| Jamal | Sofia, Jasmine, Uma, Sara, Mei, Eden, Naomi, Victoria, Bella, Diana |
| Santiago | Sofia, Maria, Rosa, Carmen, Chloe, Savannah, Mei, Olivia, Ivy, Luna |
🔼 This table displays the top influencing fathers associated with each mother’s name in the context of a linear correlation analysis between the ‘mother’ and ‘father’ knowledge domains within a language model. The analysis investigates how the prediction of a father’s name is influenced by different mothers’ names, revealing potential biases or patterns in the model’s learned associations between parental names.
read the caption
Table 16: The most influencing fathers of mothers in the Mother→→\rightarrow→Father correlation.
| Attribute | Influencing Objects | |
| Genre | toys | toy, puzzle, drum, shoes, sweater, electric, fridge, gloves, chair, jeans |
| transport | headphones, pen, plate, drum, electric, car, couch, smartphone, rug, suitcase | |
| kitchen | drum, jeans, pen, plate, toy, backpack, rug, fridge, chair, grill | |
| furniture | drum, chair, fridge, electric, rug, camera, puzzle, shoes, sweater, plate | |
| decor | drum, rug, vase, pen, sweater, jeans, smartphone, backpack, washing, speaker | |
| accessories | drum, shoes, plate, laptop, electric, oven, gloves, curtains, jeans, chair | |
| sports | basketball, pen, drum, jeans, plate, skateboard, tennis, rug, charger, puzzle | |
| travel | pen, drum, water, yoga, suitcase, sunglasses, watch, plate, jeans, fridge | |
| art | drum, puzzle, pen, scarf, water, camera, couch, toy, chair, jeans | |
| fitness | yoga, puzzle, drum, pen, couch, electric, sweater, scarf, rug, camera | |
| outdoors | drum, plate, pen, fishing, electric, water, couch, camera, toy, puzzle | |
| bags | drum, fridge, sweater, gloves, jeans, backpack, pen, rug, electric, umbrella | |
| electronics | electric, drum, headphones, plate, toy, pen, laptop, jeans, sweater, couch | |
| clothing | drum, sweater, electric, shoes, skateboard, pen, jeans, camera, rug, fridge | |
| food | fridge, drum, pen, water, scarf, couch, plate, smartphone, sweater, speaker | |
| photography | camera, water, drum, puzzle, scarf, skateboard, yoga, headphones, rug, couch | |
| literature | book, iron, pen, drum, yoga, couch, water, speaker, scarf, fan | |
| appliances | electric, sweater, jeans, plate, shoes, fridge, drum, chair, oven, laptop | |
| home | electric, oven, drum, smartphone, pen, backpack, rug, jeans, fridge, puzzle | |
| music | guitar, drum, headphones, scarf, basketball, pen, toy, puzzle, suitcase, water | |
| Heat | warm | hoodie, sweater, clock, lamp, drum, earrings, yoga, apple, tennis, oven |
| hot | hoodie, puzzle, tennis, drum, oven, jeans, car, lamp, earrings, fan | |
| neutral | jeans, speaker, blanket, sofa, car, puzzle, earrings, hoodie, tennis, rug | |
| cold | hoodie, car, earrings, fan, lamp, curtains, couch, clock, puzzle, sweater | |
| Size | large | smartphone, jeans, drum, puzzle, hoodie, umbrella, pencil, clock, car, backpack |
| medium | hoodie, tripod, car, keyboard, drum, suitcase, smartphone, basketball, curtains, bottle | |
| small | smartphone, hoodie, car, drum, pencil, jeans, backpack, keyboard, puzzle, toy | |
| Color | black | jeans, iron, fan, umbrella, hoodie, suitcase, puzzle, bowl, printer, electric |
| green | backpack, plate, puzzle, jeans, couch, umbrella, drum, soap, car, sweater | |
| blue | jeans, electric, puzzle, plate, backpack, fishing, bottle, chair, car, umbrella | |
| beige | jeans, soap, hoodie, drum, puzzle, bottle, suitcase, oven, bed, speaker | |
| gold | puzzle, backpack, car, earrings, iron, bottle, drum, jeans, plate, fan | |
| natural | jeans, bottle, puzzle, earrings, car, plate, oven, yoga, suitcase, drum | |
| silver | bottle, jeans, puzzle, iron, drum, mirror, soap, electric, backpack, earrings | |
| orange | puzzle, car, drum, backpack, jeans, umbrella, bottle, electric, oven, plate | |
| red | car, drum, earrings, puzzle, microwave, pen, umbrella, bowl, electric, backpack | |
| gray | jeans, soap, mouse, puzzle, plate, sweater, umbrella, printer, bed, backpack | |
| brown | soap, iron, puzzle, sweater, umbrella, backpack, speaker, drum, hoodie, couch | |
| yellow | plate, yoga, car, backpack, umbrella, soap, drum, puzzle, sweater, fan | |
| purple | puzzle, drum, electric, hoodie, backpack, jeans, microwave, mouse, bottle, bowl | |
| white | plate, suitcase, fan, jeans, puzzle, backpack, soap, umbrella, sweater, drum | |
| Price | high | smartphone, drum, air, car, hoodie, jeans, backpack, umbrella, puzzle, electric |
| low | drum, jeans, backpack, smartphone, car, hoodie, air, umbrella, puzzle, electric |
🔼 This table shows the top influencing objects for various attributes within the simile correlation analysis. For each attribute (e.g., color, size, heat, genre), the table lists the objects that most strongly influence the prediction of that attribute in the language model. This helps illustrate how the model connects similar concepts, such as linking the color of an apple to the color of a banana. The strength of these connections is a key aspect of the model’s compositional generalization ability.
read the caption
Table 17: The most influencing objects of attributes in the simile correlation.
| Completeness | Correlation | Precision (Hit@Top-) | Generalization |
|---|---|---|---|
| Whole Semantics | |||
| Word in a Phrase | |||
| Subword |
🔼 This table presents the correlation, precision (Hit@Top-5), and generalization performance for tokens categorized by their semantic completeness. Three levels of semantic completeness are considered: ‘Whole Semantics’ (tokens with complete meaning), ‘Word in a Phrase’ (tokens forming part of a phrase), and ‘Subword’ (sub-word units). The results show that tokens with higher semantic completeness exhibit stronger correlations and higher precision, leading to better generalization.
read the caption
Table 18: The correlation and W𝑊Witalic_W precision of tokens with different levels of semantic completeness.
Full paper#