TL;DR#
Large Language Models (LLMs) struggle with complex reasoning in question answering, often providing vague or generic responses. Existing methods like Chain-of-Thought prompting offer limited improvement. This necessitates more effective prompting techniques to enhance LLM reasoning capabilities and accuracy.
The paper introduces ARR, a novel zero-shot prompting method addressing these limitations. ARR explicitly guides LLMs through three steps: analyzing the question’s intent, retrieving relevant information, and reasoning step-by-step. Comprehensive experiments demonstrate ARR’s consistent improvement over baseline and Chain-of-Thought methods across diverse QA datasets. Ablation studies highlight the vital role of intent analysis. The results solidify ARR’s effectiveness and robustness across different LLMs, model sizes, and generation settings, making it a valuable tool for researchers.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs in question answering. It introduces a novel prompting method, ARR, that significantly improves performance. The findings are broadly applicable and inspire further research into effective prompting strategies and LLM reasoning abilities.
Visual Insights#

🔼 This figure illustrates the three key steps involved in the ARR (Analyzing, Retrieving, and Reasoning) method for question answering. The process begins with analyzing the question’s intent to understand what information is needed. Then, relevant information is retrieved. Finally, step-by-step reasoning is applied to arrive at an answer. This figure visually represents the core idea behind ARR, which is to guide large language models (LLMs) through these explicit stages to enhance their reasoning capabilities during question answering, as opposed to more generic approaches.
read the caption
Figure 1: ARR motivation. To answer a question, we often need to analyze the question’s intent, retrieve relevant information, and reason step by step.
| QA Dataset | Split | # Item | # Class | |
| BoolQ | Valid | 3,270 | 145 | 2 |
| LogiQA | Test | 651 | 192 | 4 |
| CSQA | Valid | 1221 | 43 | 5 |
| SIQA | Valid | 1,954 | 51 | 3 |
| SciQ | Test | 1,000 | 132 | 4 |
| OBQA | Test | 500 | 55 | 4 |
| ARC | Test | 3,548 | 59 | 4 |
| BBH | Test | 5,281 | 112 | 2–18 |
| MMLU | Test | 13,842 | 108 | 4 |
| MMLU-Pro | Test | 12,032 | 186 | 10 |
🔼 This table presents the statistics of ten multiple-choice question answering datasets used in the paper’s experiments. For each dataset, it lists the number of options per question (’# Class’), the total number of questions for evaluation (’# Item’), and the average number of tokens per question-answer pair (’# Token’). The tokenization was performed using the LLaMA tokenizer.
read the caption
Table 1: QA dataset statistics. “# Class” is the number of options m𝑚mitalic_m, “# Item” is the total number of data items for evaluation, and “# Token¯¯# Token\overline{\text{\# Token}}over¯ start_ARG # Token end_ARG” is the average number of tokens per instance (zero-shot prompt), tokenized by the LLaMA Dubey et al. (2024) tokenizer.
In-depth insights#
ARR Prompting#
The proposed “ARR Prompting” method offers a structured approach to enhance Large Language Model (LLM) performance in question answering. It moves beyond generic instructions by explicitly incorporating three key steps: analyzing the question’s intent, retrieving relevant information, and reasoning step-by-step. This structured approach contrasts with previous methods like Chain-of-Thought (CoT) prompting, which provides less specific guidance. Experimental results show that ARR consistently outperforms baselines and CoT across diverse datasets, highlighting its effectiveness and generalizability. The emphasis on intent analysis is particularly noteworthy, showing a significant impact on overall accuracy. The method’s effectiveness is demonstrated across varying model sizes and LLM architectures, suggesting its robustness and potential for wide application. However, further exploration of prompt variations and potential redundancy in generated responses could further refine the method’s efficacy and efficiency.
LLM Reasoning#
LLM reasoning is a crucial area of research focusing on enhancing the ability of large language models (LLMs) to perform complex reasoning tasks. Chain-of-Thought (CoT) prompting has emerged as a key technique, guiding LLMs to generate intermediate reasoning steps and improve accuracy. However, zero-shot CoT provides only generic guidance. Therefore, research is exploring more structured and effective prompting methods that explicitly incorporate steps like analyzing question intent, retrieving relevant information, and reasoning step-by-step, showing improved performance over baseline and CoT methods. This highlights the importance of contextual understanding and knowledge retrieval within the reasoning process. Further investigation involves exploring various reasoning techniques such as self-consistency, self-correction, and reinforcement learning to optimize LLM reasoning capabilities. The generalizability and robustness of these methods across different model sizes and datasets is a significant focus to ensure practical application.
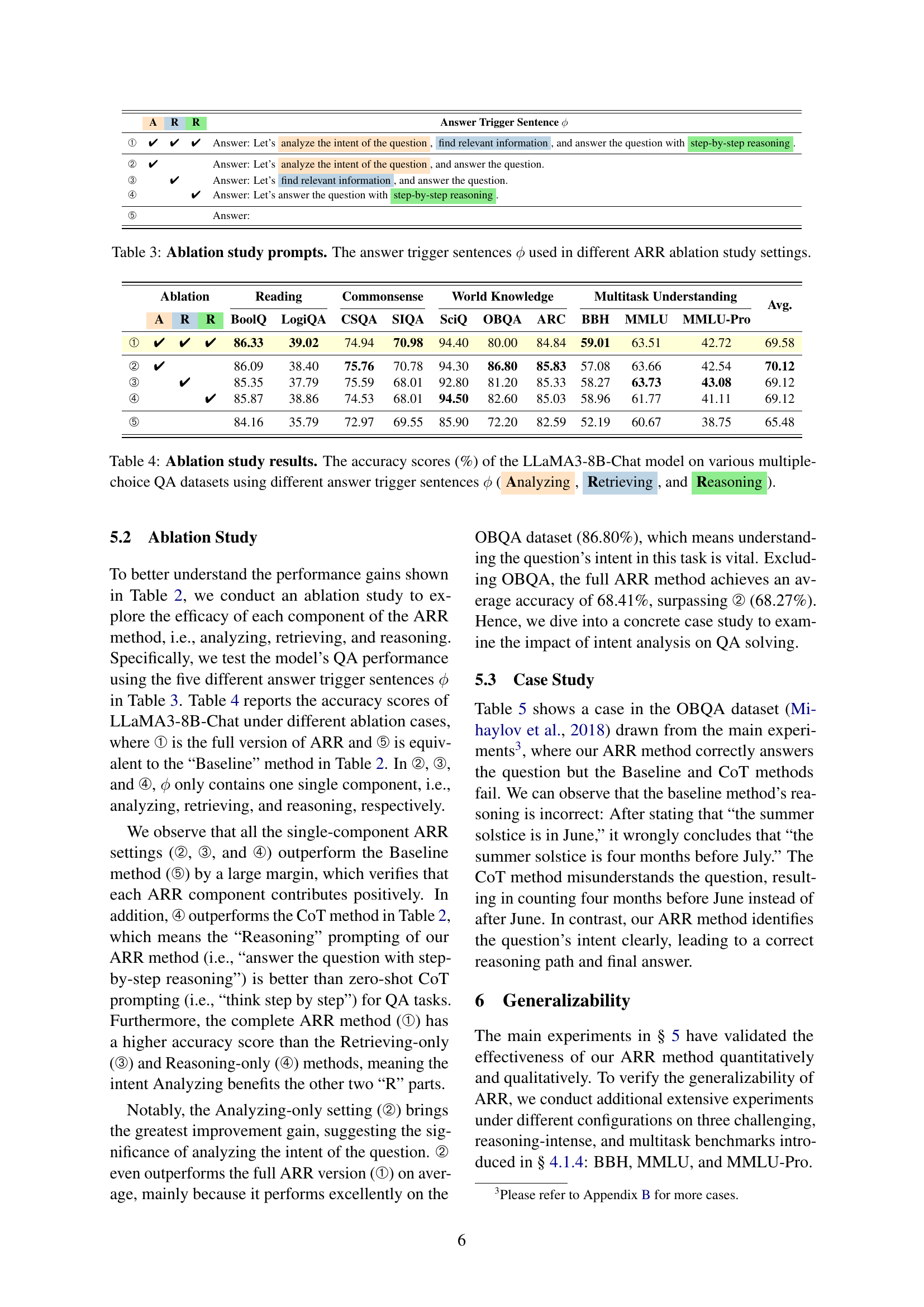
Ablation Study#
An ablation study systematically removes components of a model or system to assess their individual contributions. In this context, it would likely involve testing variations of the proposed ARR (Analyzing, Retrieving, Reasoning) prompting method. Removing the ‘Analyzing’ step would isolate the impact of intent analysis on performance, while removing ‘Retrieving’ assesses the role of information retrieval in improving accuracy. Finally, removing ‘Reasoning’ would gauge the importance of structured step-by-step reasoning. By comparing the performance of the full ARR model to these ablated versions, researchers can quantify the contribution of each component and demonstrate whether they work synergistically or independently. The results might reveal that ‘Analyzing’ is crucial, providing the most significant performance boost, while others offer smaller but still meaningful gains. This detailed analysis offers valuable insights into the functionality of the ARR method and guides future improvements.
Generalizability#
The section on ‘Generalizability’ in a research paper would explore the extent to which the study’s findings can be applied to other contexts beyond the specific settings of the research. A robust exploration would investigate the impact of various factors, such as different model sizes, LLM architectures, and generation settings, on the performance of the proposed method (e.g., ARR). It would likely present results showing consistent outperformance across these varied conditions, thus supporting the claim of broad applicability. Furthermore, it might discuss limitations and potential areas for future work to further enhance the generalization capability of the model, demonstrating a thorough and critical evaluation of the model’s robustness and reliability in diverse situations.
Future Work#
Future work could explore improving the robustness of ARR across various domains and languages by testing on a wider range of datasets. Further investigation into the impact of different prompting strategies in combination with ARR is warranted. A deeper analysis of the internal mechanisms of LLMs used with ARR is needed, to understand why and how ARR improves performance. Incorporating external knowledge sources directly within the ARR framework would enhance retrieval and reasoning accuracy. Quantitative studies are needed to demonstrate the scalability and efficiency of ARR at larger scales. Finally, exploring alternative methods for analyzing intent beyond keyword analysis is important, such as leveraging sentiment analysis or contextual embeddings.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage question answering process using Large Language Models (LLMs). In the first stage (Reasoning Generation), the LLM generates a rationale (ri) based on the input passage (pi), question (qi), answer trigger sentence (&), and option list (oi). The second stage (Option Selection) involves evaluating the language modeling losses of different context-option combinations, which include the input passage, question, answer trigger sentence, rationale and each option from the list, to finally select the optimal option (oi*).
read the caption
Figure 2: Question answering with LLMs. We first obtain rationale risubscript𝑟𝑖r_{i}italic_r start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT by reasoning generation and then select the optimal option via evaluating the language modeling losses of different context-option combinations.

🔼 This figure shows the relationship between the size of the language model and its performance on question answering tasks. As the model size increases (measured in the number of parameters), the accuracy on various question-answering datasets generally improves. The graph visually represents this trend, showing the performance gains obtained by using larger models. This demonstrates the scaling law phenomenon, where larger models tend to exhibit improved performance in many NLP tasks.
read the caption
Figure 3: Model size experiments. The trend of QA performance changes as the model becomes larger.
More on tables
| Method | Reading | Commonsense | World Knowledge | Multitask Understanding | Avg. | ||||||
| BoolQ | LogiQA | CSQA | SIQA | SciQ | OBQA | ARC | BBH | MMLU | MMLU-Pro | ||
| Baseline | 84.16 | 35.79 | 72.97 | 69.55 | 85.90 | 72.20 | 82.59 | 52.19 | 60.67 | 38.75 | 65.48 |
| CoT | 84.65 | 38.10 | 73.71 | 68.12 | 93.70 | 78.20 | 84.31 | 58.40 | 62.08 | 40.10 | 68.14 |
| ARR | 86.33 | 39.02 | 74.94 | 70.98 | 94.40 | 80.00 | 84.84 | 59.01 | 63.51 | 42.72 | 69.58 |
🔼 This table presents the zero-shot performance of the LLaMA3-8B-Chat large language model on ten different multiple-choice question answering datasets. Three prompting methods are compared: a simple ‘Answer:’ baseline, the Chain-of-Thought (CoT) method, and the proposed ARR method. The ARR method explicitly incorporates three steps: analyzing the question’s intent, retrieving relevant information, and reasoning step-by-step. Accuracy is reported as a percentage for each dataset and averaged across all datasets.
read the caption
Table 2: Main experiments. The zero-shot performance (Accuracy %) of the LLaMA3-8B-Chat model on various multiple-choice QA datasets using different answer trigger sentences ϕitalic-ϕ\phiitalic_ϕ. (1) Baseline: ϕitalic-ϕ\phiitalic_ϕ is “Answer:”; (2) CoT Kojima et al. (2022): ϕitalic-ϕ\phiitalic_ϕ is “Answer: Let’s think step by step.”; (3) ARR: our method that elicits intent analyzing, information retrieving, and step-by-step reasoning.
| A | R | R | Answer Trigger Sentence | |
| ➀ | ✔ | ✔ | ✔ | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| ➁ | ✔ | Answer: Let’s analyze the intent of the question, and answer the question. | ||
| ➂ | ✔ | Answer: Let’s find relevant information, and answer the question. | ||
| ➃ | ✔ | Answer: Let’s answer the question with step-by-step reasoning. | ||
| ➄ | Answer: |
🔼 This table presents the different answer trigger sentences used in the ablation study to evaluate the contribution of each component (Analyzing, Retrieving, and Reasoning) of the proposed ARR method. Each row represents a different setting, where a checkmark indicates the inclusion of a particular component in the prompt. The baseline setting includes no specific trigger sentence, while others incorporate only one or two of the three components to isolate their effects on the model’s performance.
read the caption
Table 3: Ablation study prompts. The answer trigger sentences ϕitalic-ϕ\phiitalic_ϕ used in different ARR ablation study settings.
| Ablation | Reading | Commonsense | World Knowledge | Multitask Understanding | Avg. | |||||||||
| A | R | R | BoolQ | LogiQA | CSQA | SIQA | SciQ | OBQA | ARC | BBH | MMLU | MMLU-Pro | ||
| ➀ | ✔ | ✔ | ✔ | 86.33 | 39.02 | 74.94 | 70.98 | 94.40 | 80.00 | 84.84 | 59.01 | 63.51 | 42.72 | 69.58 |
| ➁ | ✔ | 86.09 | 38.40 | 75.76 | 70.78 | 94.30 | 86.80 | 85.83 | 57.08 | 63.66 | 42.54 | 70.12 | ||
| ➂ | ✔ | 85.35 | 37.79 | 75.59 | 68.01 | 92.80 | 81.20 | 85.33 | 58.27 | 63.73 | 43.08 | 69.12 | ||
| ➃ | ✔ | 85.87 | 38.86 | 74.53 | 68.01 | 94.50 | 82.60 | 85.03 | 58.96 | 61.77 | 41.11 | 69.12 | ||
| ➄ | 84.16 | 35.79 | 72.97 | 69.55 | 85.90 | 72.20 | 82.59 | 52.19 | 60.67 | 38.75 | 65.48 | |||
🔼 This table presents the results of an ablation study on the effectiveness of different components of the ARR prompting method. It shows the accuracy scores achieved by the LLaMA3-8B-Chat language model on ten multiple-choice question-answering (QA) datasets. Five different variations of the ARR prompt are tested, each removing one or more of the key components (Analyzing, Retrieving, and Reasoning). The results allow for a comparison of the individual contributions of each component to the overall performance of the ARR method against a baseline and a Chain-of-Thought (CoT) prompting method.
read the caption
Table 4: Ablation study results. The accuracy scores (%) of the LLaMA3-8B-Chat model on various multiple-choice QA datasets using different answer trigger sentences ϕitalic-ϕ\phiitalic_ϕ (Analyzing, Retrieving, and Reasoning).
| Task Input | Fact: the summer solstice is on June 21st in the northern hemisphere. Question: The summer solstice in the northern hemisphere is four months before (A) May (B) July (C) April (D) October |
| Baseline | Answer: |
| Reasoning | (B) July. Explanation: The summer solstice is the longest day of the year and marks the beginning of summer. It is four months before the beginning of winter. The beginning of winter is in December, so the summer solstice is in June. Therefore, the summer solstice is four months before July. |
| CoT | Answer: Let’s think step by step. |
| Reasoning | The summer solstice is on June 21st. If we count four months before that, we get March 21st. March is the third month of the year, so the answer is (C). April is the fourth month, May is the fifth month, and October is the tenth month. None of these months is four months before June. July is the seventh month, which is five months after June, so it is not the correct answer either. The correct answer is (C). |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | The question asks for the month that is four months after the summer solstice. The summer solstice is on June 21st. Four months after June 21st is October 21st. Therefore, the correct answer is (D) October. |
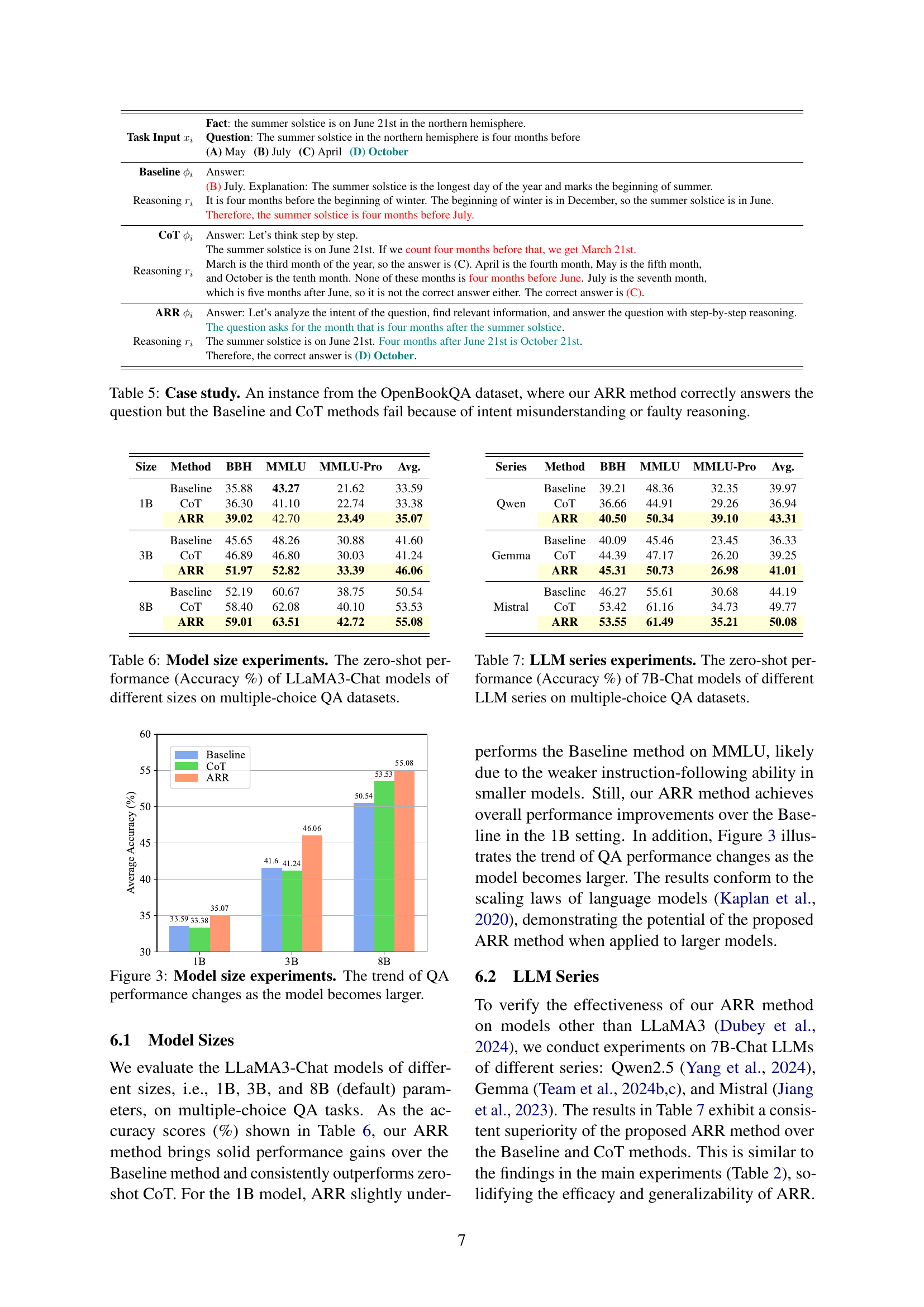
🔼 This table presents a case study from the OpenBookQA dataset to illustrate how the proposed ARR method effectively addresses a question where both the Baseline and Chain-of-Thought (CoT) methods fail. It highlights the strengths of ARR by showcasing how it correctly identifies the question’s intent and uses relevant information for accurate reasoning, while the Baseline and CoT methods suffer from either intent misunderstanding or flawed reasoning process. The case study demonstrates the superior performance of the ARR method in complex question answering scenarios.
read the caption
Table 5: Case study. An instance from the OpenBookQA dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail because of intent misunderstanding or faulty reasoning.
| Size | Method | BBH | MMLU | MMLU-Pro | Avg. |
| 1B | Baseline | 35.88 | 43.27 | 21.62 | 33.59 |
| CoT | 36.30 | 41.10 | 22.74 | 33.38 | |
| ARR | 39.02 | 42.70 | 23.49 | 35.07 | |
| 3B | Baseline | 45.65 | 48.26 | 30.88 | 41.60 |
| CoT | 46.89 | 46.80 | 30.03 | 41.24 | |
| ARR | 51.97 | 52.82 | 33.39 | 46.06 | |
| 8B | Baseline | 52.19 | 60.67 | 38.75 | 50.54 |
| CoT | 58.40 | 62.08 | 40.10 | 53.53 | |
| ARR | 59.01 | 63.51 | 42.72 | 55.08 |
🔼 This table presents the results of experiments evaluating the impact of model size on the performance of different LLMs. Specifically, it shows the zero-shot accuracy achieved by LLaMA3-Chat models of varying sizes (1B, 3B, and 8B parameters) across multiple multiple-choice question answering datasets. The purpose is to demonstrate how the model’s performance scales with its size.
read the caption
Table 6: Model size experiments. The zero-shot performance (Accuracy %) of LLaMA3-Chat models of different sizes on multiple-choice QA datasets.
| Series | Method | BBH | MMLU | MMLU-Pro | Avg. |
| Qwen | Baseline | 39.21 | 48.36 | 32.35 | 39.97 |
| CoT | 36.66 | 44.91 | 29.26 | 36.94 | |
| ARR | 40.50 | 50.34 | 39.10 | 43.31 | |
| Gemma | Baseline | 40.09 | 45.46 | 23.45 | 36.33 |
| CoT | 44.39 | 47.17 | 26.20 | 39.25 | |
| ARR | 45.31 | 50.73 | 26.98 | 41.01 | |
| Mistral | Baseline | 46.27 | 55.61 | 30.68 | 44.19 |
| CoT | 53.42 | 61.16 | 34.73 | 49.77 | |
| ARR | 53.55 | 61.49 | 35.21 | 50.08 |
🔼 This table presents the zero-shot accuracy results achieved by different large language models (LLMs) on multiple-choice question answering (QA) tasks. Each LLM used is a 7B parameter Chat model, but from different LLM series. The goal is to show the generalizability of the proposed ARR method across various LLM architectures. The results are reported as percentages, representing the accuracy of each model on several QA datasets.
read the caption
Table 7: LLM series experiments. The zero-shot performance (Accuracy %) of 7B-Chat models of different LLM series on multiple-choice QA datasets.
| Temp. | Method | BBH | MMLU | MMLU-Pro | Avg. |
| 0.0 | Baseline | 52.19 | 60.67 | 38.75 | 50.54 |
| CoT | 58.40 | 62.08 | 40.10 | 53.53 | |
| ARR | 59.01 | 63.51 | 42.72 | 55.08 | |
| 0.5 | Baseline | 50.19 | 59.35 | 36.88 | 48.81 |
| CoT | 56.58 | 60.82 | 37.82 | 51.74 | |
| ARR | 58.87 | 62.87 | 42.64 | 54.79 | |
| 1.0 | Baseline | 46.33 | 54.80 | 33.10 | 44.74 |
| CoT | 51.46 | 55.57 | 33.00 | 46.68 | |
| ARR | 52.90 | 56.58 | 36.73 | 48.74 | |
| 1.5 | Baseline | 40.84 | 45.03 | 26.85 | 37.57 |
| CoT | 42.53 | 44.85 | 25.61 | 37.66 | |
| ARR | 42.65 | 45.16 | 27.44 | 38.42 |
🔼 This table presents the results of experiments evaluating the impact of different generation temperatures on the performance of the LLaMA3-8B-Chat large language model. The experiments used a zero-shot prompting approach on multiple-choice question answering (QA) datasets. The table shows the accuracy (in percentage) achieved by the model across various datasets for different generation temperatures, including the default temperature of 0.0. It helps to understand the model’s robustness and sensitivity to the generation temperature setting.
read the caption
Table 8: Generation temperature experiments. The zero-shot performance (Accuracy %) of the LLaMA3-8B-Chat model on multiple-choice QA datasets using different generation temperatures (default: 0.0).
| Shot | Method | BBH | MMLU | MMLU-Pro | Avg. |
| 0 | Baseline | 52.19 | 60.67 | 38.75 | 50.54 |
| CoT | 58.40 | 62.08 | 40.10 | 53.53 | |
| ARR | 59.01 | 63.51 | 42.72 | 55.08 | |
| 1 | Baseline | 35.68 | 44.80 | 28.62 | 36.37 |
| CoT | 47.39 | 48.36 | 31.07 | 42.27 | |
| ARR | 47.22 | 49.29 | 34.33 | 43.61 | |
| 3 | Baseline | 34.39 | 42.08 | 25.92 | 34.13 |
| CoT | 42.84 | 48.21 | 26.69 | 39.25 | |
| ARR | 40.19 | 49.68 | 37.04 | 42.30 | |
| 5 | Baseline | 34.11 | 41.14 | 25.76 | 33.67 |
| CoT | 39.92 | 47.48 | 26.12 | 37.84 | |
| ARR | 40.68 | 49.19 | 36.62 | 42.16 |
🔼 This table presents the few-shot learning results using the LLaMA3-8B-Chat model on multiple-choice question answering datasets. It shows the accuracy achieved when providing the model with 1, 3, and 5 few-shot examples, each including the question, the answer, and the reasoning steps that led to that answer. This illustrates how the model’s performance improves with more examples and the effectiveness of few-shot learning with rationales.
read the caption
Table 9: Few-shot experiments. The few-shot performance (Accuracy %) of the LLaMA3-8B-Chat model on multiple-choice QA datasets using 1, 3, and 5 few-show examples with rationales.
| QA Datasets | URL |
| BoolQ Clark et al. (2019) | Link |
| LogiQA Liu et al. (2020) | Link |
| CSQA Talmor et al. (2019) | Link |
| SIQA Sap et al. (2019) | Link |
| SciQ Welbl et al. (2017) | Link |
| OBQA Mihaylov et al. (2018) | Link |
| ARC Clark et al. (2018) | Link |
| BBH Suzgun et al. (2023) | Link |
| MMLU Hendrycks et al. (2021) | Link |
| MMLU-Pro Wang et al. (2024b) | Link |
🔼 This table lists the names of ten multiple-choice question answering datasets used in the paper’s experiments, along with a URL link to access each dataset. These datasets cover a variety of question types and difficulty levels, testing various aspects of language model capabilities like reading comprehension, commonsense reasoning, and world knowledge.
read the caption
Table 10: The URL links of adopted QA datasets.
| LLM Series | Size | Type | URL |
| LLaMA3 Dubey et al. (2024) | 8B | Chat | Link |
| 3B | Chat | Link | |
| 1B | Chat | Link | |
| Qwen2.5 Yang et al. (2024) | 7B | Chat | Link |
| Gemma Team et al. (2024b, c) | 7B | Chat | Link |
| Mistral Jiang et al. (2023) | 7B | Chat | Link |
🔼 This table lists the URLs for the large language models (LLMs) and their corresponding tokenizers used in the experiments. The LLMs include different sizes and series of LLaMA, as well as Qwen, Gemma, and Mistral models, enabling the assessment of the ARR method’s generalizability across various model architectures and sizes.
read the caption
Table 11: The URL links of models and tokenizers.
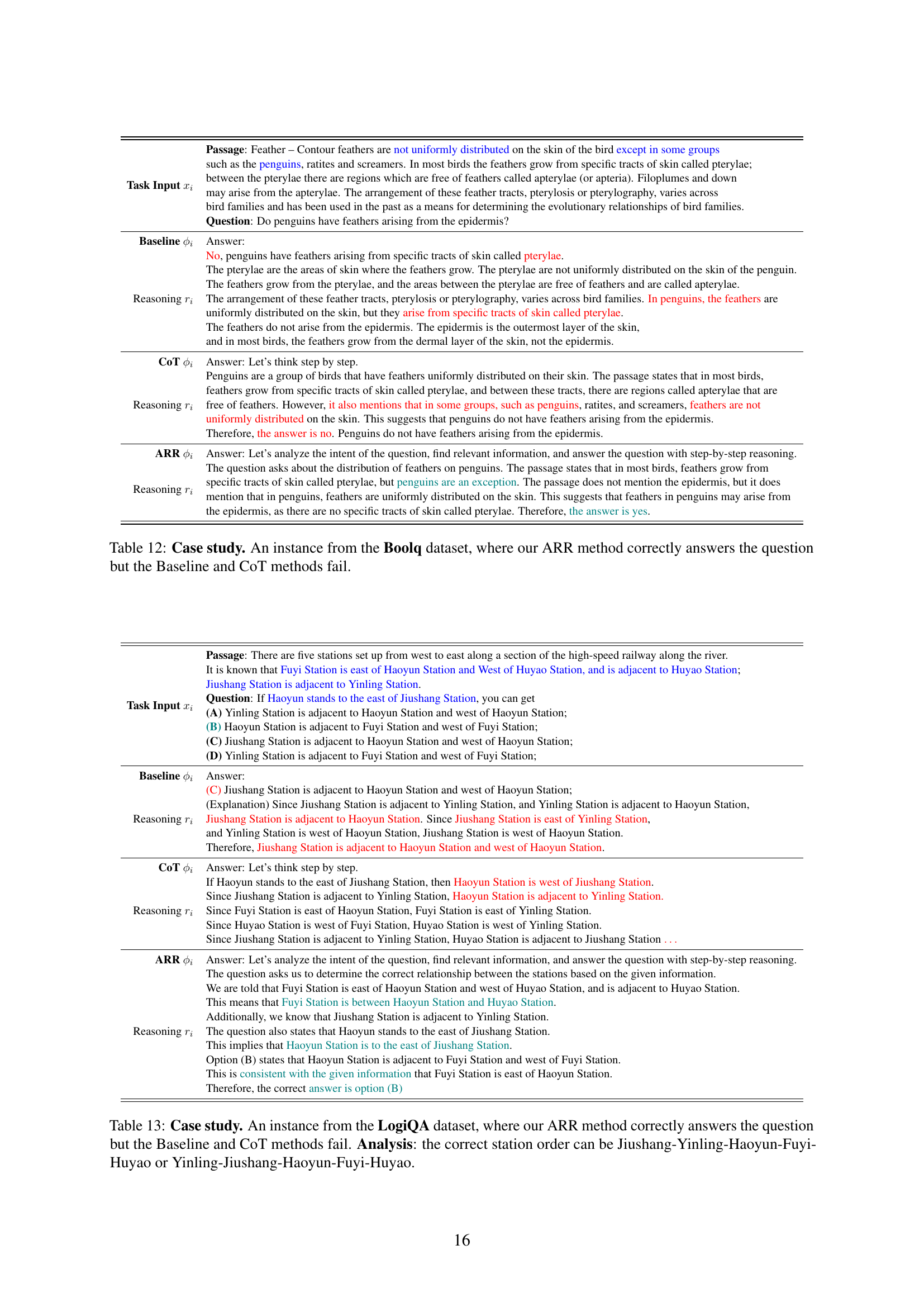
| Task Input | Passage: Feather – Contour feathers are not uniformly distributed on the skin of the bird except in some groups such as the penguins, ratites and screamers. In most birds the feathers grow from specific tracts of skin called pterylae; between the pterylae there are regions which are free of feathers called apterylae (or apteria). Filoplumes and down may arise from the apterylae. The arrangement of these feather tracts, pterylosis or pterylography, varies across bird families and has been used in the past as a means for determining the evolutionary relationships of bird families. Question: Do penguins have feathers arising from the epidermis? |
| Baseline | Answer: |
| Reasoning | No, penguins have feathers arising from specific tracts of skin called pterylae. The pterylae are the areas of skin where the feathers grow. The pterylae are not uniformly distributed on the skin of the penguin. The feathers grow from the pterylae, and the areas between the pterylae are free of feathers and are called apterylae. The arrangement of these feather tracts, pterylosis or pterylography, varies across bird families. In penguins, the feathers are uniformly distributed on the skin, but they arise from specific tracts of skin called pterylae. The feathers do not arise from the epidermis. The epidermis is the outermost layer of the skin, and in most birds, the feathers grow from the dermal layer of the skin, not the epidermis. |
| CoT | Answer: Let’s think step by step. |
| Reasoning | Penguins are a group of birds that have feathers uniformly distributed on their skin. The passage states that in most birds, feathers grow from specific tracts of skin called pterylae, and between these tracts, there are regions called apterylae that are free of feathers. However, it also mentions that in some groups, such as penguins, ratites, and screamers, feathers are not uniformly distributed on the skin. This suggests that penguins do not have feathers arising from the epidermis. Therefore, the answer is no. Penguins do not have feathers arising from the epidermis. |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | The question asks about the distribution of feathers on penguins. The passage states that in most birds, feathers grow from specific tracts of skin called pterylae, but penguins are an exception. The passage does not mention the epidermis, but it does mention that in penguins, feathers are uniformly distributed on the skin. This suggests that feathers in penguins may arise from the epidermis, as there are no specific tracts of skin called pterylae. Therefore, the answer is yes. |
🔼 This case study demonstrates a BoolQ question where the ARR method correctly identifies the answer, while both the baseline and Chain-of-Thought (CoT) methods fail. The table presents the question, the passage providing context, and the reasoning and answers generated by each method (Baseline, CoT, and ARR). This highlights the superior ability of the ARR method to understand the question’s intent and extract relevant information for accurate answering.
read the caption
Table 12: Case study. An instance from the Boolq dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail.
| Task Input | Passage: There are five stations set up from west to east along a section of the high-speed railway along the river. It is known that Fuyi Station is east of Haoyun Station and West of Huyao Station, and is adjacent to Huyao Station; Jiushang Station is adjacent to Yinling Station. Question: If Haoyun stands to the east of Jiushang Station, you can get (A) Yinling Station is adjacent to Haoyun Station and west of Haoyun Station; (B) Haoyun Station is adjacent to Fuyi Station and west of Fuyi Station; (C) Jiushang Station is adjacent to Haoyun Station and west of Haoyun Station; (D) Yinling Station is adjacent to Fuyi Station and west of Fuyi Station; |
| Baseline | Answer: |
| Reasoning | (C) Jiushang Station is adjacent to Haoyun Station and west of Haoyun Station; (Explanation) Since Jiushang Station is adjacent to Yinling Station, and Yinling Station is adjacent to Haoyun Station, Jiushang Station is adjacent to Haoyun Station. Since Jiushang Station is east of Yinling Station, and Yinling Station is west of Haoyun Station, Jiushang Station is west of Haoyun Station. Therefore, Jiushang Station is adjacent to Haoyun Station and west of Haoyun Station. |
| CoT | Answer: Let’s think step by step. |
| Reasoning | If Haoyun stands to the east of Jiushang Station, then Haoyun Station is west of Jiushang Station. Since Jiushang Station is adjacent to Yinling Station, Haoyun Station is adjacent to Yinling Station. Since Fuyi Station is east of Haoyun Station, Fuyi Station is east of Yinling Station. Since Huyao Station is west of Fuyi Station, Huyao Station is west of Yinling Station. Since Jiushang Station is adjacent to Yinling Station, Huyao Station is adjacent to Jiushang Station |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | The question asks us to determine the correct relationship between the stations based on the given information. We are told that Fuyi Station is east of Haoyun Station and west of Huyao Station, and is adjacent to Huyao Station. This means that Fuyi Station is between Haoyun Station and Huyao Station. Additionally, we know that Jiushang Station is adjacent to Yinling Station. The question also states that Haoyun stands to the east of Jiushang Station. This implies that Haoyun Station is to the east of Jiushang Station. Option (B) states that Haoyun Station is adjacent to Fuyi Station and west of Fuyi Station. This is consistent with the given information that Fuyi Station is east of Haoyun Station. Therefore, the correct answer is option (B) |
🔼 This case study from the LogiQA dataset shows a scenario where the ARR method successfully determines the correct order of train stations (either Jiushang-Yinling-Haoyun-Fuyi-Huyao or Yinling-Jiushang-Haoyun-Fuyi-Huyao), while both the baseline and Chain-of-Thought (CoT) methods fail to provide the correct answer. The analysis highlights that the ambiguity in the possible station order does not hinder the ARR method’s accuracy, unlike the baseline and CoT methods.
read the caption
Table 13: Case study. An instance from the LogiQA dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail. Analysis: the correct station order can be Jiushang-Yinling-Haoyun-Fuyi-Huyao or Yinling-Jiushang-Haoyun-Fuyi-Huyao.
| Task Input | Question: What do people aim to do at work? (A) complete job (B) learn from each other (C) kill animals (D) wear hats (E) talk to each other |
| Baseline | Answer: |
| Reasoning | (B) learn from each other. The best answer is B. Step 1: Understand the context of the question: The question is asking about the purpose or goal of people at work. Step 2: Analyze the options given Option (A) "complete job" is a task-oriented answer, but it doesn’t necessarily imply learning or personal growth. Option (C) "kill animals" is unrelated to the typical goals of work in most industries. Option (D) "wear hats" is a superficial aspect of work attire and not a goal. Option (E) "talk to each other" is a common aspect of work but doesn’t necessarily imply learning. Step 3: Identify the most appropriate answer: Option (B) "learn from each other" is a goal that aligns with personal and professional development, which is a common aim in many workplaces. It suggests a focus on growth, improvement, and collaboration, which are key aspects of many work environments. The final answer is: B |
| CoT | Answer: Let’s think step by step. |
| Reasoning | (B) People go to work to earn a living, but they also go to learn from each other and to be part of a community. Choice (A) is incorrect because people do not go to work to complete a job. They go to work to do a job. Choice (C) is incorrect because people do not go to work to kill animals. Choice (D) is incorrect because people do not go to work to wear hats. Choice (E) is incorrect because people do not go to work to talk to each other. They go to work to do a job. The best answer is B. |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | The question asks what people aim to do at work. The relevant information is that people go to work to earn a living. The answer is that people aim to complete their jobs at work. Choice (B) is incorrect because people may learn from each other at work, but that is not the main purpose of going to work. Choice (C) is incorrect because people do not go to work to kill animals. Choice (D) is incorrect because people do not go to work to wear hats. Choice (E) is incorrect because people do not go to work to talk to each other. The best answer is A. |
🔼 This case study from the CommonsenseQA dataset shows a question where the ARR method correctly identifies the answer, while both the Baseline and Chain-of-Thought (CoT) methods fail. It highlights the differences in reasoning and how ARR’s structured approach of analyzing the question’s intent, retrieving relevant information, and reasoning step-by-step leads to a more accurate and effective answer compared to the less structured approaches.
read the caption
Table 14: Case study. An instance from the Commonsense QA dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail.
| Task Input | Context: Alex grew closer to their significant other after they vacationed together. Question: How would Alex feel afterwards? (A) in love (B) happy (C) back from vacation |
| Baseline | Answer: |
| Reasoning | (B) happy Reasoning Skill: Empathy And Perspective Taking This question requires the test-taker to put themselves in Alex’s shoes and understand how they would feel after a positive experience like vacationing with their significant other. The correct answer, "happy", is a natural emotional response to a pleasant experience. The other options are not directly related to the emotional state of Alex after the vacation. "In love" is a more intense and long-term feeling, "back from vacation" is a factual statement rather than an emotional response, and "happy" is the most appropriate answer given the context. |
| CoT | Answer: Let’s think step by step. |
| Reasoning | Alex grew closer to their significant other after they vacationed together. This implies that the vacation strengthened their relationship. Therefore, Alex would likely feel happy after the vacation. Reasoning skill: Empathy And Perspective Taking. This question requires the reader to put themselves in Alex’s shoes and understand how they would feel after a positive experience. It also requires the reader to consider the context of the situation and how it would impact Alex’s emotions. The best answer is (B) |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | Step 1: Identify the context of the question. The context is about Alex growing closer to their significant other after a vacation. Step 2: Determine the emotional state of Alex after the vacation. The question asks how Alex would feel afterwards. Step 3: Analyze the relationship between Alex and their significant other. The question implies that the vacation strengthened their bond. Step 4: Determine the emotional state of Alex based on the context. Given that the vacation brought them closer together, it is likely that Alex would feel happy or in love. Step 5: Choose the most appropriate answer. Between "happy" and "in love," "in love" is a more intense emotion that aligns with the context of growing closer to someone. The final answer is: (A) in love. |
🔼 This case study demonstrates a question from the SocialIQA dataset where the ARR method correctly identifies the answer, while both the baseline and Chain-of-Thought (CoT) methods fail. The question asks about a person’s emotional state after a positive experience (spending time with a significant other). The ARR method excels by analyzing the question’s nuance, understanding the relational context of ‘significant other,’ and inferring a more appropriate answer (in love) over a more general answer (happy).
read the caption
Table 15: Case study. An instance from the SocialIQA dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail. Analysis: Option B is not wrong, but Option A is more appropriate as they are in a romantic relationship (“significant other”).
| Task Input | Question: Rupture can cause fragments of what to travel via the bloodstream and become lodged in other arteries? (A) red blood cells (B) white blood cells (C) plaque (D) enamel |
| Baseline | Answer: |
| Reasoning | Rupture of an atherosclerotic plaque can cause fragments of the plaque to travel via the bloodstream and become lodged in other arteries. This is known as an embolus. Choice (B) is incorrect because white blood cells are not typically associated with atherosclerosis. Choice (C) is incorrect because plaque is the substance that ruptures. Choice (D) is incorrect because enamel is the hard, outer layer of the teeth. The best answer is (A). |
| CoT | Answer: Let’s think step by step. |
| Reasoning | The question is asking about the consequences of a rupture, which implies a physical injury or damage to a structure. The correct answer should be related to the physical structure that can be damaged and cause fragments to travel through the bloodstream. Option (A) red blood cells are a type of cell that carries oxygen throughout the body via the bloodstream, and they can be damaged or ruptured in the event of a physical injury or damage to a blood vessel. Option (B) white blood cells are part of the immune system and help fight infections, but they are not a physical structure that can rupture and cause fragments to travel through the bloodstream. Option (C) plaque is a sticky film of bacteria that can cause dental problems, but it’s not a physical structure that can rupture and cause fragments to travel through the bloodstream. Option (D) enamel is a hard, outer layer of teeth, which is not directly related to the bloodstream or arteries. Therefore, the correct answer is (A) red blood cells. |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | The question is asking about the consequences of a rupture, which is likely referring to a rupture of an aneurysm or an atherosclerotic plaque. In the context of aneurysms or atherosclerosis, a rupture can lead to the release of fragments into the bloodstream. These fragments can then travel to other parts of the body and become lodged in other arteries, potentially causing blockages or other complications. Considering the options provided, the most relevant choice is (C) plaque, as atherosclerotic plaque is a common cause of arterial blockages and can rupture, releasing fragments into the bloodstream. The other options are not directly related to the consequences of a rupture in the context of aneurysms or atherosclerosis. |
🔼 This case study demonstrates a scenario from the SciQ dataset where the ARR method successfully answers the question, unlike the Baseline and Chain-of-Thought (CoT) methods. It highlights ARR’s superior performance by showcasing the reasoning processes of each method. The table provides the question, the different answers from each method, and the reasoning steps behind those answers.
read the caption
Table 16: Case study. An instance from the SciQ dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail.
| Task Input | Fact: force causes the speed of an object to decrease. Question: The amount of friction and the speed of an object have what kind of relationship? (A) inverse (B) reverse (C) direct (D) equal |
| Baseline | Answer: |
| Reasoning | (C) Direct Explanation: The more friction an object has, the slower it will move. The less friction an object has, the faster it will move. This is a direct relationship. The amount of friction and the speed of an object are directly related. |
| CoT | Answer: Let’s think step by step. |
| Reasoning | Step 1: Understand the relationship between friction and speed The relationship between friction and speed is that as friction increases, the speed of an object decreases. Step 2: Determine the type of relationship Since an increase in friction leads to a decrease in speed, this is a direct relationship. A direct relationship means that as one variable increases, the other variable also increases. Step 3: Choose the correct answer Based on the understanding of the relationship between friction and speed, the correct answer is (C) direct. |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | The question asks about the relationship between the amount of friction and the speed of an object. The relevant information is that force causes the speed of an object to decrease. The intent of the question is to determine the relationship between the amount of friction and the speed of an object. The correct answer is (A) inverse. The amount of friction and the speed of an object have an inverse relationship. The more friction, the slower the object moves. The less friction, the faster the object moves. |
🔼 This case study from the OpenBookQA dataset demonstrates how the ARR method outperforms the baseline and Chain-of-Thought (CoT) methods in a multiple-choice question-answering task. The baseline and CoT methods both make incorrect inferences due to flawed reasoning processes. The baseline incorrectly concludes a direct relationship exists based on a correlation presented out of context. Similarly, CoT uses correct information but draws the wrong conclusion, likely because of the autoregressive generation process failing to condition on subsequent information. In contrast, ARR’s structured approach allows it to analyze the question’s intent, retrieve relevant information, and perform accurate reasoning before selecting the correct answer.
read the caption
Table 17: Case study. An instance from the OpenBookQA dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail. Analysis: The CoT method provides a correct fact about the direct relationship (“A direct relationship means that ……\dots…”), but wrongly infers that “this is a direct relationship” from “an increase in friction leads to a decrease in speed.” This is because the wrong statement is made without conditioning on the correct fact that is presented after the statement (due to the autoregressive generation). In contrast, the ARR method performs reasoning based on sufficient context after analyzing the intent and finding relevant information.
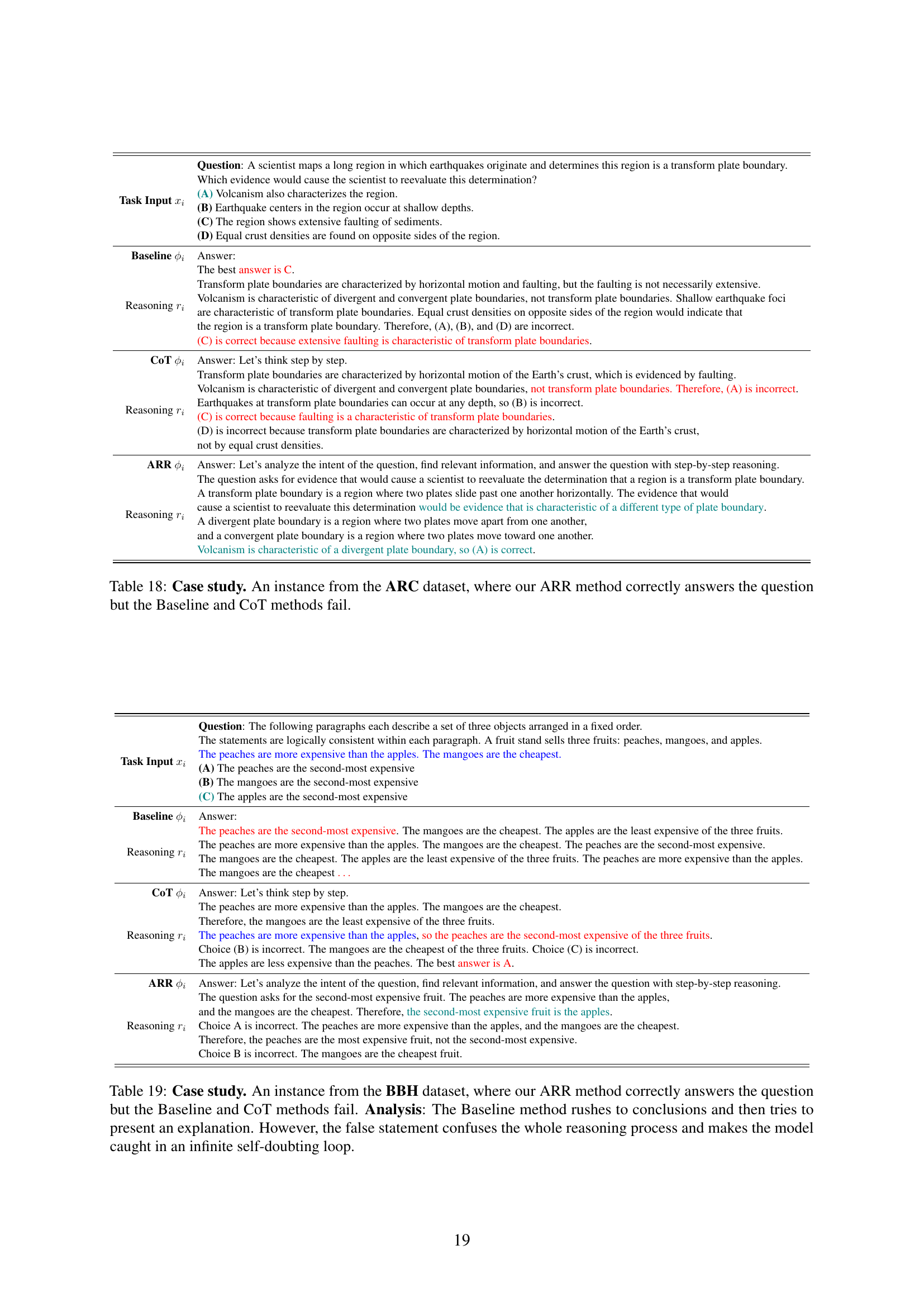
| Task Input | Question: A scientist maps a long region in which earthquakes originate and determines this region is a transform plate boundary. Which evidence would cause the scientist to reevaluate this determination? (A) Volcanism also characterizes the region. (B) Earthquake centers in the region occur at shallow depths. (C) The region shows extensive faulting of sediments. (D) Equal crust densities are found on opposite sides of the region. |
| Baseline | Answer: |
| Reasoning | The best answer is C. Transform plate boundaries are characterized by horizontal motion and faulting, but the faulting is not necessarily extensive. Volcanism is characteristic of divergent and convergent plate boundaries, not transform plate boundaries. Shallow earthquake foci are characteristic of transform plate boundaries. Equal crust densities on opposite sides of the region would indicate that the region is a transform plate boundary. Therefore, (A), (B), and (D) are incorrect. (C) is correct because extensive faulting is characteristic of transform plate boundaries. |
| CoT | Answer: Let’s think step by step. |
| Reasoning | Transform plate boundaries are characterized by horizontal motion of the Earth’s crust, which is evidenced by faulting. Volcanism is characteristic of divergent and convergent plate boundaries, not transform plate boundaries. Therefore, (A) is incorrect. Earthquakes at transform plate boundaries can occur at any depth, so (B) is incorrect. (C) is correct because faulting is a characteristic of transform plate boundaries. (D) is incorrect because transform plate boundaries are characterized by horizontal motion of the Earth’s crust, not by equal crust densities. |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | The question asks for evidence that would cause a scientist to reevaluate the determination that a region is a transform plate boundary. A transform plate boundary is a region where two plates slide past one another horizontally. The evidence that would cause a scientist to reevaluate this determination would be evidence that is characteristic of a different type of plate boundary. A divergent plate boundary is a region where two plates move apart from one another, and a convergent plate boundary is a region where two plates move toward one another. Volcanism is characteristic of a divergent plate boundary, so (A) is correct. |
🔼 This case study demonstrates a scenario from the AI2 Reasoning Challenge (ARC) dataset where the ARR method successfully answers a question, while both the Baseline and Chain-of-Thought (CoT) methods fail. It highlights the superior reasoning capabilities of the ARR method by showcasing how it analyzes the question’s intent, identifies relevant information, and uses step-by-step reasoning to reach the correct conclusion, unlike the other two methods.
read the caption
Table 18: Case study. An instance from the ARC dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail.
| Task Input | Question: The following paragraphs each describe a set of three objects arranged in a fixed order. The statements are logically consistent within each paragraph. A fruit stand sells three fruits: peaches, mangoes, and apples. The peaches are more expensive than the apples. The mangoes are the cheapest. (A) The peaches are the second-most expensive (B) The mangoes are the second-most expensive (C) The apples are the second-most expensive |
| Baseline | Answer: |
| Reasoning | The peaches are the second-most expensive. The mangoes are the cheapest. The apples are the least expensive of the three fruits. The peaches are more expensive than the apples. The mangoes are the cheapest. The peaches are the second-most expensive. The mangoes are the cheapest. The apples are the least expensive of the three fruits. The peaches are more expensive than the apples. The mangoes are the cheapest |
| CoT | Answer: Let’s think step by step. |
| Reasoning | The peaches are more expensive than the apples. The mangoes are the cheapest. Therefore, the mangoes are the least expensive of the three fruits. The peaches are more expensive than the apples, so the peaches are the second-most expensive of the three fruits. Choice (B) is incorrect. The mangoes are the cheapest of the three fruits. Choice (C) is incorrect. The apples are less expensive than the peaches. The best answer is A. |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | The question asks for the second-most expensive fruit. The peaches are more expensive than the apples, and the mangoes are the cheapest. Therefore, the second-most expensive fruit is the apples. Choice A is incorrect. The peaches are more expensive than the apples, and the mangoes are the cheapest. Therefore, the peaches are the most expensive fruit, not the second-most expensive. Choice B is incorrect. The mangoes are the cheapest fruit. |
🔼 This case study demonstrates a scenario from the BIG-Bench Hard (BBH) dataset where the ARR method successfully answers a question, while both the Baseline and Chain-of-Thought (CoT) methods fail. The Baseline method makes a hasty conclusion and attempts to justify it, but its initial false statement disrupts the entire reasoning process, leading the model into a cycle of self-doubt. This highlights ARR’s superior ability to systematically analyze, retrieve, and reason.
read the caption
Table 19: Case study. An instance from the BBH dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail. Analysis: The Baseline method rushes to conclusions and then tries to present an explanation. However, the false statement confuses the whole reasoning process and makes the model caught in an infinite self-doubting loop.
| Task Input | Question: Select the best translation into predicate logic. David teaches Chris. (c: Chris; d: David; Txy: x teaches y) (A) Tdc (B) Tcd (C) Tcc (D) dTc |
| Baseline | Answer: |
| Reasoning | (B) The translation of the sentence into predicate logic is Tcd, where Txy means x teaches y. The subject of the sentence is David, the object is Chris, and the predicate is teaches. The correct translation is Tcd, not Tdc, because the subject comes before the predicate in a predicate logic statement. Choice (C) is incorrect because it reverses the subject and object. Choice (D) is incorrect because it reverses the subject and predicate. |
| CoT | Answer: Let’s think step by step. |
| Reasoning | (B) The predicate logic translation of the sentence is Tcd, where Txy means x teaches y. The best answer is B. |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | The question asks for the best translation into predicate logic. The relevant information is the statement "David teaches Chris." The statement is in the active voice, so the subject is the teacher, and the object is the student. The predicate logic translation is Tdc, where Txy means x teaches y, c is Chris, and d is David. Choice (B) is incorrect. This is the translation of "Chris teaches David." Choice (C) is incorrect. This is the translation of "Chris teaches Chris." Choice (D) is incorrect. This is the translation of "David is taught by Chris." The best answer is A. |
🔼 This case study contrasts three different methods (Baseline, Chain-of-Thought prompting, and the proposed ARR method) for answering a multiple-choice question from the MMLU dataset. The Baseline and Chain-of-Thought methods demonstrate overconfidence, arriving at incorrect answers without a thorough analysis of the question or the options. In contrast, the ARR method showcases a more meticulous approach, prioritizing a careful understanding of the question before assessing each option, ultimately leading to the correct answer. This highlights ARR’s superior ability to perform logical reasoning and avoid hasty conclusions.
read the caption
Table 20: Case study. An instance from the MMLU dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail. Analysis: The Baseline and CoT methods jump to the wrong conclusions confidently, while the ARR method understands the question first and analyzes each option correctly.
| Task Input | Question: Which type of research methods are designed to elicit responses to predetermined, standardized questions from many respondents? (A) Non-probability. (B) Cross-sectional. (C) Qualitative. (D) Ethnographic. (E) Longitudinal. (F) Experimental. (G) Probability. (H) Observational. (I) Case Study. (J) Quantitative. |
| Baseline | Answer: |
| Reasoning | The best answer is G. Probability sampling is a type of research method that is designed to elicit responses to predetermined, standardized questions from many respondents. Probability sampling is a type of sampling method that is used to select a sample of participants from a larger population. Probability sampling methods include simple random sampling, stratified sampling, and cluster sampling. |
| CoT | Answer: Let’s think step by step. |
| Reasoning | (G) Probability sampling is a method of selecting a sample from a population in which every member of the population has an equal chance of being selected. Probability sampling is used in research to ensure that the sample is representative of the population. |
| ARR | Answer: Let’s analyze the intent of the question, find relevant information, and answer the question with step-by-step reasoning. |
| Reasoning | The question asks about research methods that are designed to elicit responses to predetermined, standardized questions from many respondents. This is a clue that the research method is quantitative. Quantitative research methods are designed to elicit responses to predetermined, standardized questions from many respondents. The correct answer is (J). The other choices are incorrect because they are not quantitative research methods. |
🔼 This case study demonstrates a scenario from the MMLU-Pro dataset where the ARR method successfully answers a question about research methodology, while both the baseline and Chain-of-Thought (CoT) methods fail. The analysis highlights ARR’s superior ability to understand the question’s underlying meaning and implications before attempting to answer. This showcases ARR’s strength in accurately interpreting the question’s intent, a crucial aspect not fully addressed by the other methods.
read the caption
Table 21: Case study. An instance from the MMLU-Pro dataset, where our ARR method correctly answers the question but the Baseline and CoT methods fail. Analysis: The ARR method grasps the question’s intent and implications before answering.
Full paper#