TL;DR#
Large Language Models (LLMs) show promise in complex reasoning but often fail at tasks requiring deductive reasoning and principled planning. A common approach uses the Planning Domain Definition Language (PDDL) to formally describe planning problems, allowing the use of classical search algorithms. However, generating high-quality PDDL domains from natural language or PDDL problems directly using current LLMs is challenging due to data scarcity and ambiguity in natural language. This necessitates human intervention or extensive training data, hindering automation and scalability.
This research introduces a test-time scaling method that effectively addresses these challenges. The method utilizes Best-of-N sampling to generate diverse initial PDDL candidates and then refines them iteratively using Instance Verbalized Machine Learning (iVML). iVML leverages LLMs to verify PDDL domain validity and generate feedback, allowing for iterative refinement without requiring additional training data. This approach substantially improves the success rate of PDDL domain generation across different LLMs, surpassing existing state-of-the-art performance.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to automated PDDL domain synthesis, which is a crucial step in enabling large language models to perform complex planning tasks. The proposed test-time scaling method significantly improves the accuracy and efficiency of PDDL generation, outperforming existing state-of-the-art methods. This work opens avenues for future research in enhancing LLM reasoning capabilities and developing more robust planning systems.
Visual Insights#

🔼 This figure illustrates the two-stage test-time scaling approach for PDDL domain generation. The first stage, Best-of-N sampling, uses parallel LLM calls to generate multiple chain-of-thought responses, each consisting of a PDDL world model (Di) and a natural language explanation (Ti). The top K responses are selected. The second stage, closed-loop iteration with Instance Verbalized Machine Learning (iVML), refines the initial PDDL model. iVML uses two LLMs: an optimizer (fopt) that evaluates the current PDDL model and provides feedback, and a learner (flearner) that uses this feedback to update the PDDL model (Di). This iterative process continues until the best PDDL model is found, which is then used in a systematic search algorithm for planning.
read the caption
Figure 1: An overview of the proposed method. Our test-time compute scaling approach consists of two main steps: (1) Best-of-N Sampling for PDDL Initialization (see Section 3.2): We start by running a parallel sampling process to generate multiple chain-of-thought responses that are composed of the formalized PDDL-based world model representation 𝐃isubscript𝐃𝑖\mathbf{D}_{i}bold_D start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT and the natural language thought 𝐓isubscript𝐓𝑖\mathbf{T}_{i}bold_T start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. (2) Closed-loop Iteration with iVML (see Section 3.3): We use Instance Verbalized Machine Learning (iVML) to iteratively improve the solutions. The iVML incorporates: (1) An optimizer LLM foptsubscript𝑓optf_{\mathrm{opt}}italic_f start_POSTSUBSCRIPT roman_opt end_POSTSUBSCRIPT that evaluates the solutions from the previous iteration, and (2) A learner LLM flearnersubscript𝑓learnerf_{\mathrm{learner}}italic_f start_POSTSUBSCRIPT roman_learner end_POSTSUBSCRIPT that learns from the feedback and updates the PDDL-based world model 𝐃isubscript𝐃𝑖\mathbf{D}_{i}bold_D start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT. The most optimal PDDL-based world model would be sent to the systematic search engine for planning.
| Methods | Synthesis Objective | Benchmarking | Technical Method | |||||
| [13] |
|
| Human experts | |||||
| [46] |
|
| Finetuned on a large dataset | |||||
| Ours |
|
|
|
🔼 This table compares the proposed PDDL (Planning Domain Definition Language) domain generation method with existing state-of-the-art methods. It contrasts the methods’ synthesis objectives (what the LLM is trying to create), the benchmarking datasets used to evaluate them (the test problems used), and the technical methodology used to produce the PDDL domains. This allows readers to understand the relative strengths and weaknesses of the different approaches in terms of data requirements (training data), level of automation (human vs. automated), and performance.
read the caption
Table 1: Comparison between current PDDL synthesis methods and ours.
In-depth insights#
LLM Test-Time Scaling#
LLM test-time scaling represents a paradigm shift in leveraging large language models (LLMs) for complex tasks like planning. Instead of relying on extensive pre-training or fine-tuning, test-time scaling enhances an LLM’s reasoning abilities during inference. This is particularly crucial for tasks where training data is scarce, such as symbolic planning using PDDL. By employing techniques like best-of-N sampling and instance verbalized machine learning (iVML), LLMs can generate high-quality PDDL domains directly from natural language or PDDL problems. Best-of-N sampling explores diverse solutions, while iVML iteratively refines initial results, creating an effective balance between exploration and exploitation. This approach significantly improves the success rate in generating correct and complete PDDL models, achieving state-of-the-art results without requiring additional model training. The method demonstrates robustness and scalability across different LLMs and problem domains, highlighting the potential for broader applications of test-time scaling in various AI domains requiring sophisticated reasoning and symbolic manipulation.
PDDL Symbolic Models#
Utilizing Planning Domain Definition Language (PDDL) to create symbolic models offers a structured approach to address the inherent ambiguity of natural language in complex planning tasks. PDDL’s formal nature, based on first-order logic, allows for unambiguous representation of states, actions, and their effects. This precision is crucial for tasks requiring optimality and constraint satisfaction. By translating the problem into PDDL, classic search algorithms like A* can be effectively applied, finding optimal plans without the uncertainties introduced by directly interpreting natural language instructions. However, generating accurate PDDL models from natural language descriptions or problem codes is a challenge, requiring sophisticated deductive reasoning capabilities and an ability to maintain logical consistency. The paper explores test-time scaling of large language models (LLMs) to overcome this, demonstrating an improvement over current state-of-the-art methods by combining techniques like Best-of-N sampling to find a strong initial solution followed by refinement using iterative machine learning. This hybrid method addresses limitations of both purely exploration and exploitation-based approaches, leading to a balance and improved accuracy. The successful use of PDDL highlights its potential as a key component of an effective LLM-based planning framework.
iVML Refinement#
The core idea behind ‘iVML Refinement’ is an iterative process to improve initial PDDL domain generation. It leverages a closed-loop system using two LLMs: an optimizer and a learner. The optimizer evaluates the current PDDL domain, offering critiques which are then used by the learner to refine the domain. This iterative feedback mechanism is crucial because it enables the system to correct errors, resolve inconsistencies, and enhance the domain’s accuracy. The process is data-efficient as it doesn’t rely on extensive training data, making it particularly appealing for tasks with limited PDDL datasets. Furthermore, the incorporation of Best-of-N sampling to initialize the process allows for a balance between exploration (finding diverse initial candidates) and exploitation (iteratively refining the best solutions). This hybrid approach proves effective in overcoming the limitations of using LLMs for symbolic reasoning directly, leading to the generation of high-quality PDDL domains suitable for classical planning algorithms. However, this approach’s dependence on the initial solutions means that poor quality initialization can impact the refinement’s success. The effectiveness of iVML refinement is therefore intricately linked to the robust initialization strategies employed.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a systematic comparison of the proposed method against existing state-of-the-art techniques. This would involve clearly defined metrics (e.g., accuracy, success rate, computational efficiency) and a diverse set of benchmark datasets, reflecting the complexity and variety of real-world planning problems. Key aspects to include are performance comparisons across different model sizes, showing scalability, and a breakdown of results across various planning domains, to demonstrate generalization capabilities. Furthermore, ablation studies examining the impact of individual components (e.g., best-of-N sampling, instance verbalized machine learning) would be crucial. The discussion should analyze the strengths and weaknesses of the proposed method in comparison to baselines, offering a nuanced perspective. Statistical significance testing would provide strong evidence for any observed performance gains. Finally, it is essential that the benchmark results are presented clearly, using visualizations such as tables and charts to facilitate understanding and interpretation. Visualizations showing the relative performance of different methods on various benchmark datasets would offer the best insight and provide a strong foundation for drawing conclusions about the proposed approach’s effectiveness.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending the iVML framework to handle more complex reasoning tasks, such as those involving temporal logic or uncertainty, would significantly enhance its capabilities. This might involve integrating advanced planning techniques or incorporating probabilistic models within the iVML loop. Another key area for future work is improving the robustness and efficiency of the BoN sampling method. While BoN significantly improves initial PDDL generation, its computational cost could be reduced through more sophisticated sampling strategies. Furthermore, exploring different LLM architectures and training paradigms is crucial for further improving performance. This includes investigating the efficacy of LLMs specifically trained on PDDL data or those employing more advanced reasoning mechanisms. Finally, a comprehensive evaluation across a wider range of PDDL benchmarks is essential to solidify the generality and effectiveness of the proposed approach. This broader evaluation would include more complex scenarios and potentially diverse language styles used to describe the tasks, offering a more robust assessment of the method’s true potential.
More visual insights#
More on figures

🔼 Figure 2 illustrates the shortcomings of directly using Large Language Models (LLMs) for complex planning tasks. It shows a specific example using the Termes planning domain, where the OpenAI-o1 model produces a plan that contains several critical errors. These errors include rule violations (the model takes actions that break predefined rules in steps three and four), and a hallucinated goal achievement (incorrectly stating that the goal has been reached in step four). The hallucination leads to incorrect outcomes, and even when the OpenAI-o1 model is used to evaluate its own plan, it incorrectly identifies it as valid, highlighting the unreliability of relying on LLMs alone for such complex tasks.
read the caption
Figure 2: OpenAI-o1 plans for Termes: o1 frequently exhibits hallucination during the planning process. Specifically, in steps three and four, the LLM violates predefined rules when selecting and leveraging actions. Additionally, step four hallucinates the achievement of the goal, leading to incorrect or unrealistic outcomes. Even when using o1 itself to evaluate the hallucinated plan, it incorrectly identifies the plan as valid.
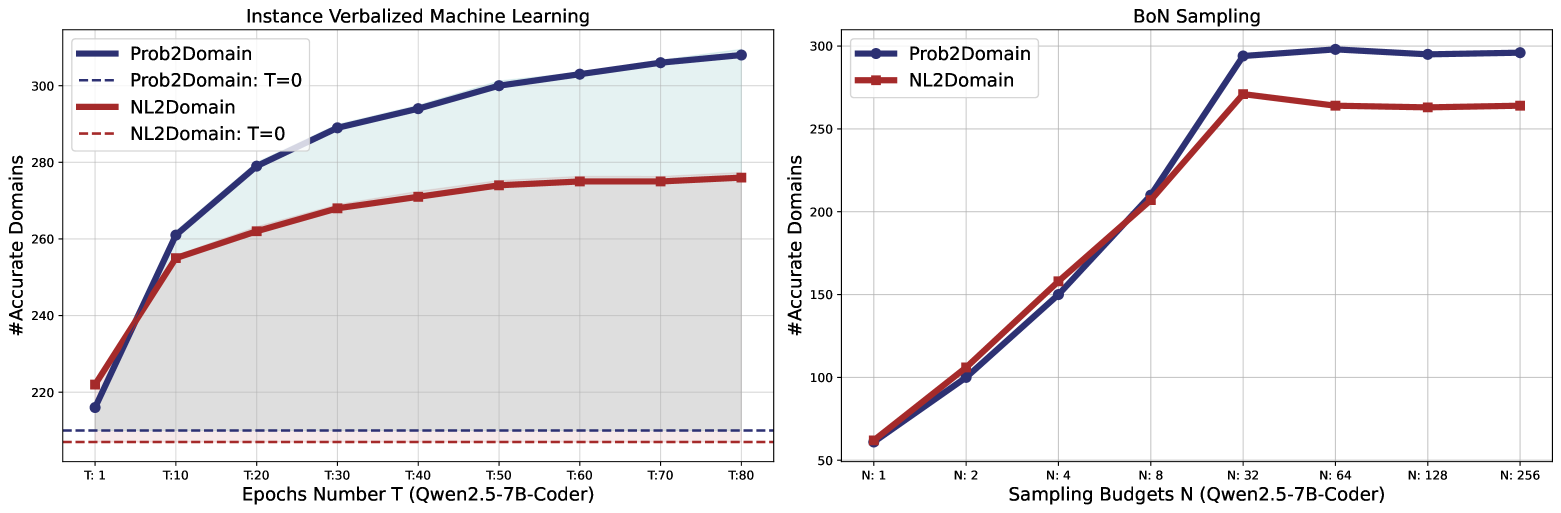
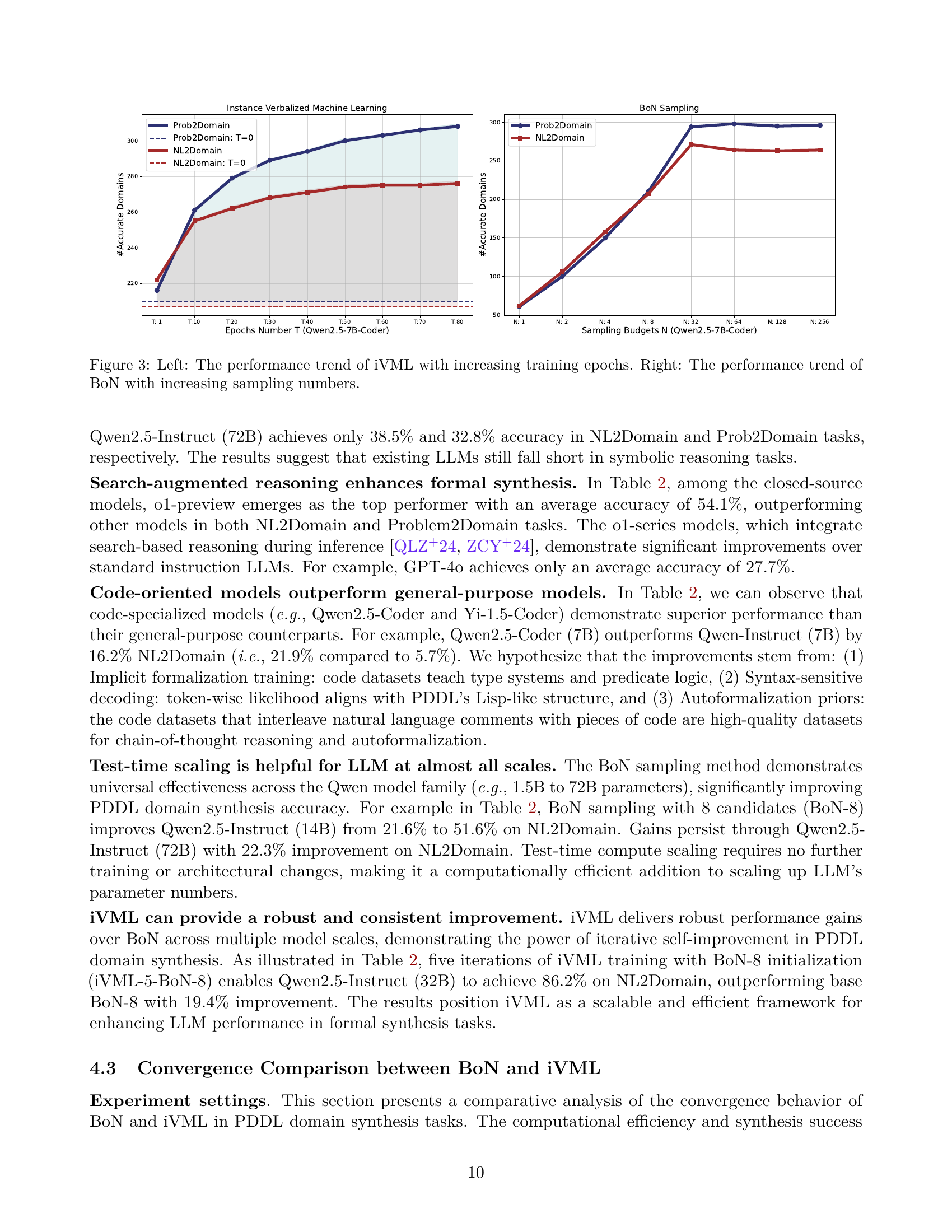
🔼 Figure 3 presents two graphs illustrating the convergence behavior of the proposed test-time scaling approach. The left graph shows how the accuracy of the Instance Verbalized Machine Learning (iVML) method improves as the number of training epochs increases. The right graph displays the accuracy of the Best-of-N (BoN) sampling method as the sampling budget (number of candidates) grows. Both graphs demonstrate the effectiveness of the methods in PDDL domain synthesis tasks. The plots show the number of accurately generated PDDL domains for both NL2Domain and Prob2Domain tasks. This figure highlights the balance between exploration and exploitation achieved by combining BoN and iVML.
read the caption
Figure 3: Left: The performance trend of iVML with increasing training epochs. Right: The performance trend of BoN with increasing sampling numbers.

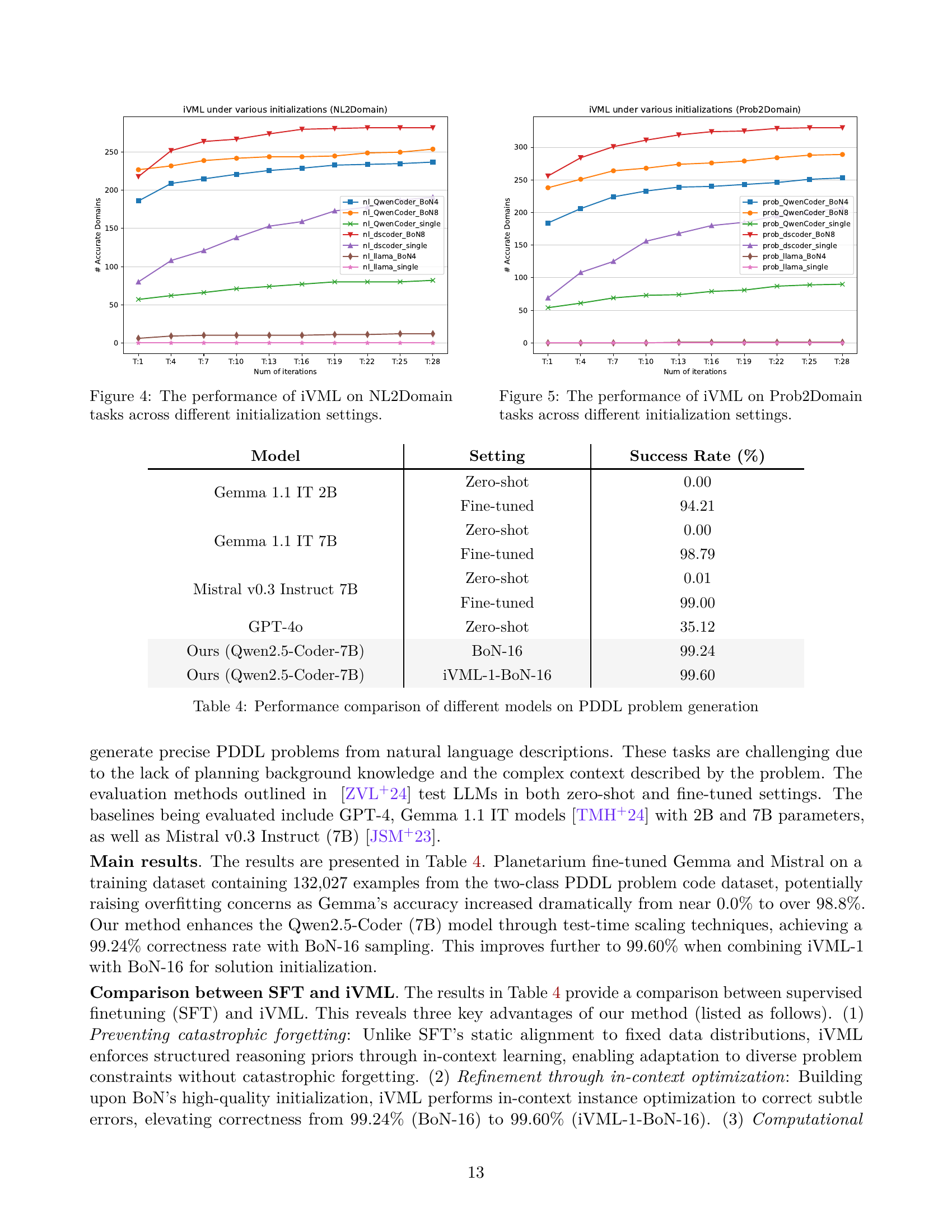
🔼 Figure 4 illustrates the performance comparison of the Instance Verbalized Machine Learning (iVML) algorithm under different initialization strategies for the NL2Domain task (Natural Language to PDDL Domain translation). It shows the number of accurately generated PDDL domains across various iterations (epochs) of iVML. Different lines represent different initialization methods (e.g., BoN with different sampling budgets, or single-pass initialization) for different LLMs (QwenCoder, dscoder, llama). This visualization helps understand how different initialization strategies affect the convergence and accuracy of the iVML algorithm in generating high-quality PDDL domains from natural language descriptions. The x-axis represents the number of iVML iterations, and the y-axis represents the number of correctly generated PDDL domains.
read the caption
Figure 4: The performance of iVML on NL2Domain tasks across different initialization settings.

🔼 Figure 5 presents a detailed analysis of the Instance Verbalized Machine Learning (iVML) algorithm’s performance on Prob2Domain tasks. It showcases how different initialization strategies impact iVML’s ability to successfully generate PDDL domains from problem descriptions. The figure illustrates the convergence behavior of iVML across multiple runs, each employing a unique initialization method. This allows for a comparative assessment of the effectiveness and efficiency of various initialization strategies in achieving successful PDDL domain synthesis within the context of the Prob2Domain task.
read the caption
Figure 5: The performance of iVML on Prob2Domain tasks across different initialization settings.

🔼 This figure shows a planning graph for the Termes task, which visualizes the sequence of states and actions involved in solving the planning problem. Each node represents a state, and each edge represents an action that transitions between states. The graph illustrates the explicit state transition during the planning process for the Termes task.
read the caption
Figure 6: The planning graph for Termes
More on tables
| Each action separately |
| within PDDL domains |
🔼 Table 2 presents a performance comparison of various methods for generating Planning Domain Definition Language (PDDL) models. The methods are evaluated on two tasks: converting natural language descriptions to PDDL (NL2Domain) and generating PDDL domains from PDDL problems (Prob2Domain). The table shows the success rate (percentage) achieved by each method on these two tasks. Results are shown for various open-source large language models (LLMs), as well as closed-source models from OpenAI for comparison. The table also includes results for the proposed methods: Best-of-N (BoN) sampling and Iterative Verbalized Machine Learning (iVML). BoN is used to generate multiple initial PDDL models, and iVML iteratively refines these models to improve accuracy. The table clearly indicates the model size (in parameters), method employed, and the corresponding success rates on both NL2Domain and Prob2Domain tasks. This allows direct comparison across different LLMs and different model sizes as well as the effects of the proposed methods.
read the caption
Table 2: A comparison of performance in PDDL domain synthesis. BoN-8 refers to BoN sampling with 8 candidates, while iVML-5-BoN-8 denotes five iterations of iVML training initialized with BoN-8.
| 3 domains: |
| Household, Logistics, Tyreworld |
🔼 Table 3 presents a detailed comparison of the PDDL (Planning Domain Definition Language) code generated by two different methods: Best-of-N sampling (BoN) and Instance Verbalized Machine Learning (iVML). The table focuses specifically on action-level PDDL code synthesis. For each example, the table shows the natural language description of the task, the PDDL code generated by BoN, and the refined PDDL code generated by iVML. Logically incorrect code generated by BoN is highlighted in red, while the corrections made by iVML are shown in blue. This illustrates the iterative refinement process of iVML and how it addresses errors made by the initial BoN approach.
read the caption
Table 3: The comparison highlights the differences between Best-of-N sampling (BoN) and iVML in synthesizing action-level PDDL code. The red text marks where BoN@8 produces logically incorrect code, while the blue text shows how iVML detects these inaccuracies and applies the necessary corrections.
| Whole PDDL problems |
| (initial state and goal) |
🔼 This table compares the performance of various large language models (LLMs) on the task of generating PDDL (Planning Domain Definition Language) problems. It includes both zero-shot and fine-tuned results, showing the success rates achieved by different models on the Planetarium benchmark, which is specifically designed for evaluating the ability of LLMs to translate natural language descriptions into structured planning languages.
read the caption
Table 4: Performance comparison of different models on PDDL problem generation
| 2 domains: |
| Gripper, Blockworld |
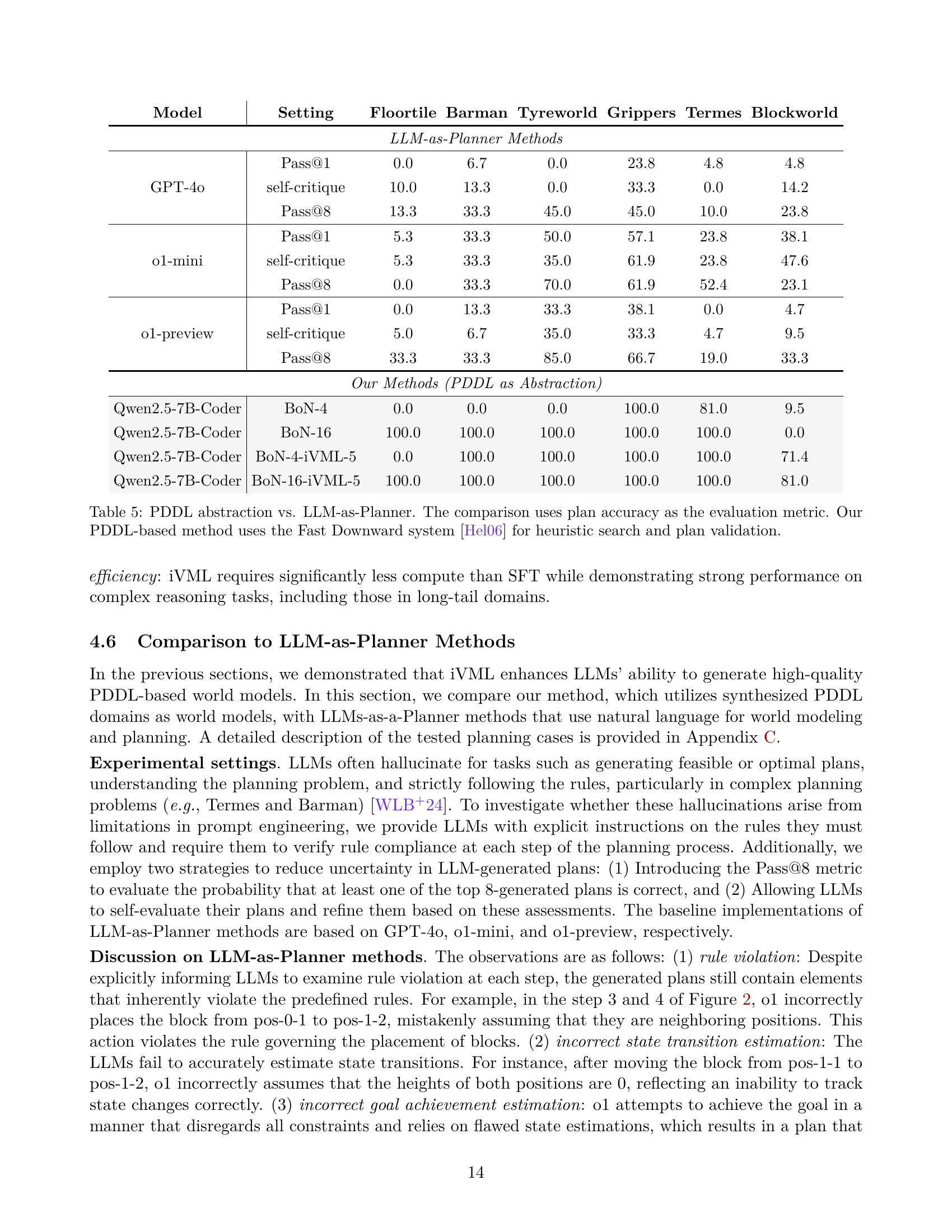
🔼 This table compares the performance of using PDDL (Planning Domain Definition Language) as an abstraction layer for planning versus directly using LLMs (Large Language Models) as planners. The ‘LLM-as-Planner’ methods directly generate plans using natural language, while the PDDL-based method uses LLMs to generate PDDL code, which is then used by the Fast Downward planning system to find optimal plans. Plan accuracy is used as the evaluation metric across several benchmark planning tasks (Floortile, Barman, Tyreworld, Grippers, Termes, Blocksworld). The PDDL approach demonstrates significantly higher accuracy, highlighting the advantages of using structured representations for planning.
read the caption
Table 5: PDDL abstraction vs. LLM-as-Planner. The comparison uses plan accuracy as the evaluation metric. Our PDDL-based method uses the Fast Downward system [14] for heuristic search and plan validation.
Full paper#