TL;DR#
Current video generation models face challenges in producing high-quality, coherent outputs across various applications, especially at scale. Existing methods often struggle with efficiency and the joint modeling of image and video data, limiting their potential. This research addresses these issues by introducing a novel framework and highlighting the importance of careful data curation and efficient training strategies.
The paper introduces Goku, a family of models that leverage rectified flow Transformers and a comprehensive data processing pipeline to achieve high-quality image and video generation. Goku demonstrates superior performance on various benchmarks, outperforming existing state-of-the-art models. Its innovative architecture, combined with the developed training infrastructure, provides valuable insights and practical advancements for the research community.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video and image generation because it presents Goku, a novel model achieving state-of-the-art results. Goku’s innovative rectified flow Transformer architecture and data processing pipeline offer valuable insights into efficient, high-quality multi-modal generation. The work also details a robust training infrastructure optimized for large-scale model training, providing practical guidance for researchers facing similar challenges. This opens up new avenues for research in improving both the quality and efficiency of multi-modal generative models.
Visual Insights#

🔼 This figure displays a collection of images generated from text prompts using the Goku model. The samples highlight the model’s ability to generate diverse and detailed images from a wide range of text descriptions. These examples showcase its capacity for generating high-quality and visually appealing images.
read the caption
(a) Text-to-Image Samples
| Model | Layer | Model Dimension | FFN Dimension | Attention Heads |
| Goku-1B | 28 | 1152 | 4608 | 16 |
| Goku-2B | 28 | 1792 | 7168 | 28 |
| Goku-8B | 40 | 3072 | 12288 | 48 |
🔼 This table details the architectural configurations of the various Goku models. It shows the model’s layer count, model dimension (embedding size), feed-forward network (FFN) dimension, and number of attention heads. The sizes of these parameters influence the model’s capacity and computational requirements. The Goku-1B model, with relatively smaller parameters, served primarily as a testbed for pilot experiments in Section 2.3 of the paper.
read the caption
Table 1: Architecture configurations for Goku Models. Goku-1B model is only used for pilot experiments in Section 2.3
In-depth insights#
Goku’s Flow-Based Design#
Goku’s architecture centers on a novel flow-based approach, specifically rectified flow, integrated with transformer networks. This design is noteworthy for its ability to handle both images and videos within a unified framework, using a 3D joint image-video variational autoencoder (VAE) to compress inputs into a shared latent space. This shared latent space is crucial as it allows for seamless joint training of image and video data, leading to highly coherent and high-quality outputs across both modalities. The rectified flow formulation is key, streamlining the generation process and leading to faster convergence during training. This contrasts with more computationally intensive diffusion-based methods. The use of full attention, despite the computational demands, is also a pivotal design choice. This approach, optimized with techniques like FlashAttention and sequence parallelism, allows the model to capture complex temporal and spatial relationships crucial for generating high-quality videos. In short, Goku’s design elegantly merges advanced architectural components, including rectified flows and transformers, resulting in an efficient and high-performing system for multi-modal visual generation. The unified framework and careful optimization are crucial factors contributing to its success in achieving state-of-the-art performance.
Data Curation Pipeline#
The ‘Data Curation Pipeline’ section in this research paper is crucial for understanding the foundation of the Goku model’s success. It highlights the meticulous approach to data collection and processing, emphasizing the need for high-quality, large-scale datasets for robust video generation. The pipeline’s multi-stage approach involving advanced techniques like video and image filtering based on aesthetic scores, OCR-driven content analysis, and subjective evaluations shows a commitment to high quality and contextually relevant data. The use of multimodal large language models to generate and refine captions demonstrates an understanding of the need for accurate and descriptive textual data. The resulting robust dataset, comprising approximately 36 million video-text and 160 million image-text pairs, is a testament to the scale and quality achieved. This section underscores the significance of data curation in achieving state-of-the-art results in video generation. The detailed description of each step, including data collection sources, balancing strategies and filtering criteria, highlights the importance of a carefully designed pipeline to support training of high-performing models.
Multi-Stage Training#
The proposed multi-stage training strategy for joint image-and-video generation models is a pragmatic approach to address the complexity of learning both spatial and temporal dynamics simultaneously. The initial stage focuses on establishing a solid understanding of text-to-image relationships, allowing the model to ground itself in basic visual semantics before tackling the complexities of video. This sequential approach avoids overwhelming the model with multi-modal data early on, improving stability. By first pre-training on image data, a strong foundation is built before introducing video. Subsequent stages progressively integrate video data, building upon this initial understanding, allowing the model to effectively learn temporal dependencies. The final stage is dedicated to modality-specific finetuning, optimizing each modality separately, further enhancing quality. This carefully staged approach of learning is designed to address the resource-intensive nature of video data while leveraging the benefits of both image and video data. This staged approach contrasts with single-stage methods, likely yielding more efficient and robust models. The strategy is crucial for large-scale model training, enhancing performance and stability.
Ablation Study Insights#
Ablation studies in the context of a video generation model like Goku would systematically assess the contribution of individual components to the overall performance. Model scaling, for instance, would compare variations with differing numbers of parameters (e.g., 2B vs. 8B). Insights would reveal whether increased model size translates to improved visual quality and generation fidelity, or if there are diminishing returns. Investigating joint image-and-video training helps determine if this approach, compared to separate training pipelines, enhances temporal coherence, scene consistency, and overall video quality. The results could indicate whether joint training yields superior performance across multiple evaluation metrics. Analyzing the impact of specific architectural components such as the Rectified Flow formulation can provide insights into its efficacy in modeling temporal dependencies and generating high-quality videos. By removing or modifying elements of the data processing pipeline (e.g., filtering steps, caption generation techniques), researchers can uncover the influence of data quality and textual descriptions on the model’s performance. Such studies can reveal how the data curation pipeline improves various attributes like semantic consistency and realism. Ultimately, a thorough ablation study would provide critical understanding of the model’s strengths, weaknesses, and design choices, facilitating future improvements and development of even more advanced video generation models.
Joint Image-Video VAE#
The concept of a ‘Joint Image-Video VAE’ presents a powerful approach to visual data representation, particularly for tasks involving both images and videos. By encoding both image and video data into a shared latent space, this method enables the model to learn unified representations, capturing commonalities and differences between the two modalities. This shared latent space is crucial for efficient and effective joint training, allowing the model to leverage information from both images and videos to improve overall performance. The effectiveness hinges on the VAE’s ability to compress high-dimensional visual data into a lower-dimensional latent space while preserving essential information. Successfully implementing this requires a robust VAE architecture capable of handling the unique challenges of temporal and spatial dependencies inherent in video data. The advantages are considerable; joint training can lead to more robust and generalized models, capable of handling diverse visual inputs and generating high-quality outputs for both image and video generation tasks. However, the complexity of designing and training such a model is non-trivial, demanding careful consideration of both architectural design and training strategies to address computational costs and potential overfitting.
More visual insights#
More on figures

🔼 The figure displays several video clips generated by the Goku model in response to text prompts. Each video showcases the model’s ability to generate coherent and visually appealing videos based on the given text descriptions. The videos demonstrate a wide range of scenarios and visual styles.
read the caption
(b) Text-to-Video Samples

🔼 Figure 1 showcases examples of images and videos generated by the Goku model. The text-to-image samples demonstrate Goku’s ability to generate diverse and high-quality images based on textual descriptions. Similarly, the text-to-video samples highlight Goku’s capability to create coherent and detailed videos from textual prompts. Key components of the pipeline responsible for generating these outputs are highlighted in red for emphasis.
read the caption
Figure 1: Generated samples from Goku. Key components are highlighted in RED.

🔼 This figure illustrates the data processing pipeline used to create the dataset for training the Goku model. The process begins with collecting large volumes of video and image data from the internet. Subsequently, these raw data undergo several filtering stages to ensure high quality. This involves video and image filtering to remove low-quality or inappropriate content (e.g., NSFW content), using techniques such as aesthetic score filtering, OCR to eliminate images with excessive text, and motion analysis. Following this, the pipeline generates captions for both images and videos utilizing a combination of Multimodal Large Language Models (MLLMs) and Large Language Models (LLMs). These captions ensure that the text descriptions are both accurate and descriptive. The final step involves balancing the distribution of the data to correct any biases.
read the caption
Figure 2: The data curation pipeline in Goku. Given a large volume of video/image data collected from Internet, we generate high-quality video/image-text pairs through a series of data filtering, captioning and balancing steps.

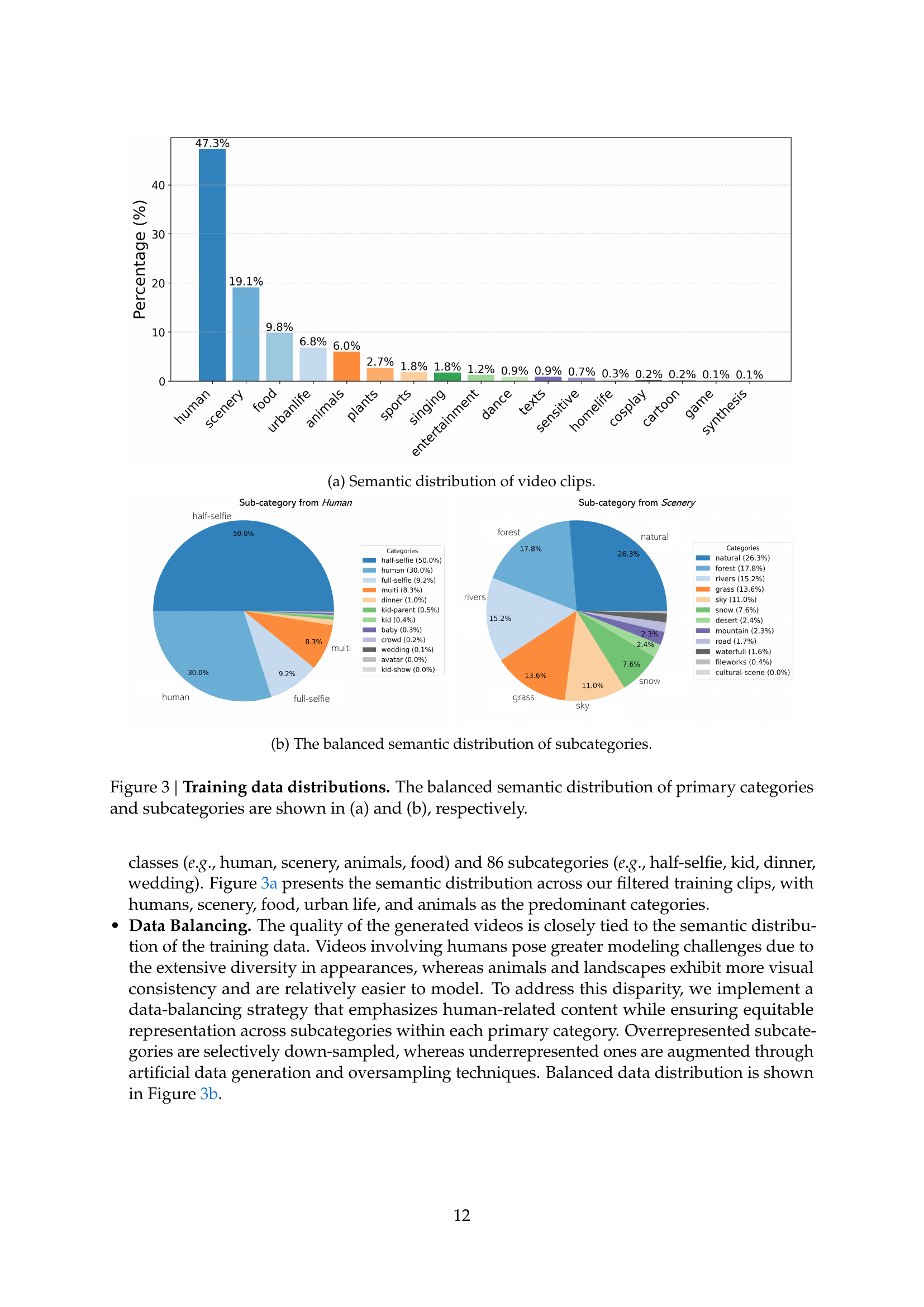
🔼 The figure shows the distribution of video clips across different semantic categories in the training dataset. The primary categories are displayed with their respective percentages, illustrating the relative abundance of each category in the dataset. This visualization helps in understanding the dataset’s composition and the balance of various themes represented.
read the caption
(a) Semantic distribution of video clips.

🔼 This figure is a pie chart that visualizes the balanced distribution of subcategories within the video dataset used for training the Goku model. The dataset was initially imbalanced, with some categories over-represented and others under-represented. To address this, the authors implemented data balancing techniques. This chart shows the resulting balanced distribution after applying these techniques, indicating a more even representation of diverse video content across various subcategories. Each slice of the pie chart represents a subcategory, and the size of the slice corresponds to the proportion of videos belonging to that subcategory in the balanced dataset.
read the caption
(b) The balanced semantic distribution of subcategories.

🔼 Figure 3 presents the balanced distribution of video clips across different semantic categories. Subfigure (a) shows the distribution of primary categories (e.g., human, scenery, animals, food), revealing the relative frequency of each category in the training dataset. Subfigure (b) breaks down the data further, illustrating the distribution of subcategories within each primary category (e.g., different types of human activities, specific animal breeds, various food items). This balanced distribution is achieved through data curation techniques such as downsampling overrepresented categories and upsampling underrepresented ones.
read the caption
Figure 3: Training data distributions. The balanced semantic distribution of primary categories and subcategories are shown in (a) and (b), respectively.

🔼 Figure 4 showcases examples of Goku-I2V (Goku Image-to-Video), a model that generates videos conditioned on a given image and text prompt. The figure’s leftmost column displays the reference images used as input. Each row presents the corresponding text prompt (with key words highlighted in red) and the resulting video frames. The prompts have been shortened from their original lengths to highlight only essential details, illustrating how Goku-I2V generates videos based on a combination of image and text. The videos effectively combine the reference image with the visual elements described in the text prompt.
read the caption
Figure 4: Samples of Goku-I2V. Reference images are presented in the leftmost columns. We omitted redundant information from the long prompts, displaying only the key details in each one. Key words are highlighted in RED.

🔼 This figure presents ablation study results on the impact of model scaling on Goku-T2V. The left-hand side shows video results from the Goku-T2V(2B) model, which has 2 billion parameters. The right-hand side shows video results from the Goku-T2V(8B) model, which has 8 billion parameters. The goal is to demonstrate that increasing model size (and thus increasing parameters) improves the quality of the generated videos, specifically reducing the occurrence of artifacts such as distorted objects.
read the caption
(a) Model Scaling
More on tables
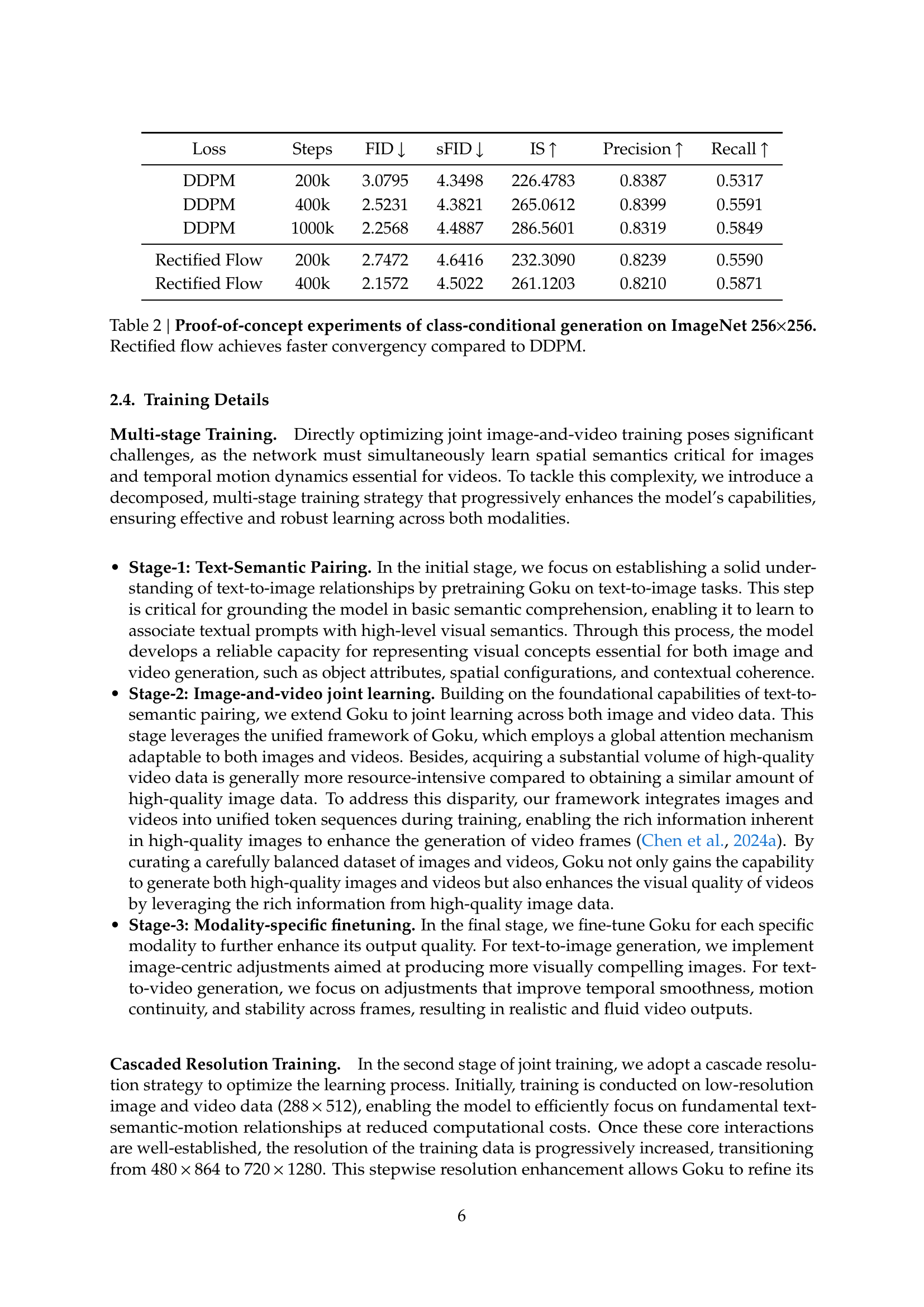
| Loss | Steps | FID | sFID | IS | Precision | Recall |
| DDPM | 200k | 3.0795 | 4.3498 | 226.4783 | 0.8387 | 0.5317 |
| DDPM | 400k | 2.5231 | 4.3821 | 265.0612 | 0.8399 | 0.5591 |
| DDPM | 1000k | 2.2568 | 4.4887 | 286.5601 | 0.8319 | 0.5849 |
| Rectified Flow | 200k | 2.7472 | 4.6416 | 232.3090 | 0.8239 | 0.5590 |
| Rectified Flow | 400k | 2.1572 | 4.5022 | 261.1203 | 0.8210 | 0.5871 |
🔼 This table presents a comparison of the performance of two training methods, Rectified Flow and Denoising Diffusion Probabilistic Model (DDPM), on the task of class-conditional image generation using the ImageNet dataset with 256x256 resolution images. The metrics used to evaluate performance include FID (Fréchet Inception Distance), SFID (modified FID), IS (Inception Score), precision, and recall. The table shows the values of these metrics for both methods at different training steps (200k, 400k, and 1000k). The key takeaway is that Rectified Flow demonstrates significantly faster convergence towards better performance (lower FID and SFID, higher IS) than DDPM.
read the caption
Table 2: Proof-of-concept experiments of class-conditional generation on ImageNet 256×\times×256. Rectified flow achieves faster convergency compared to DDPM.
| Parameter | Description | Threshold |
| Duration | Raw video length | 4 seconds |
| Resolution | Width and height of the video | { height, width} 480 |
| Bitrate | Amount of data processed per second during playback, which impacts the video’s quality, clarity, and file size | 500 kbps |
| Frame Rate | Frames displayed per second | 24 FPS (Film Standard) / 23.976 FPS (NTSC Standard) |
🔼 Table 3 details the criteria for filtering and standardizing raw video data to ensure data quality and consistency for training the Goku model. It outlines specific thresholds for several key video parameters: Duration (minimum video length), Resolution (minimum dimensions), Bitrate (data processed per second impacting video quality), and Frame Rate (frames per second). These thresholds help filter out low-quality, inconsistent, or unsuitable videos before model training.
read the caption
Table 3: Summary of video quality parameters and their thresholds for preprocessing. The table outlines the criteria used to filter and standardize raw videos based on essential attributes, ensuring uniformity and compatibility in the dataset.
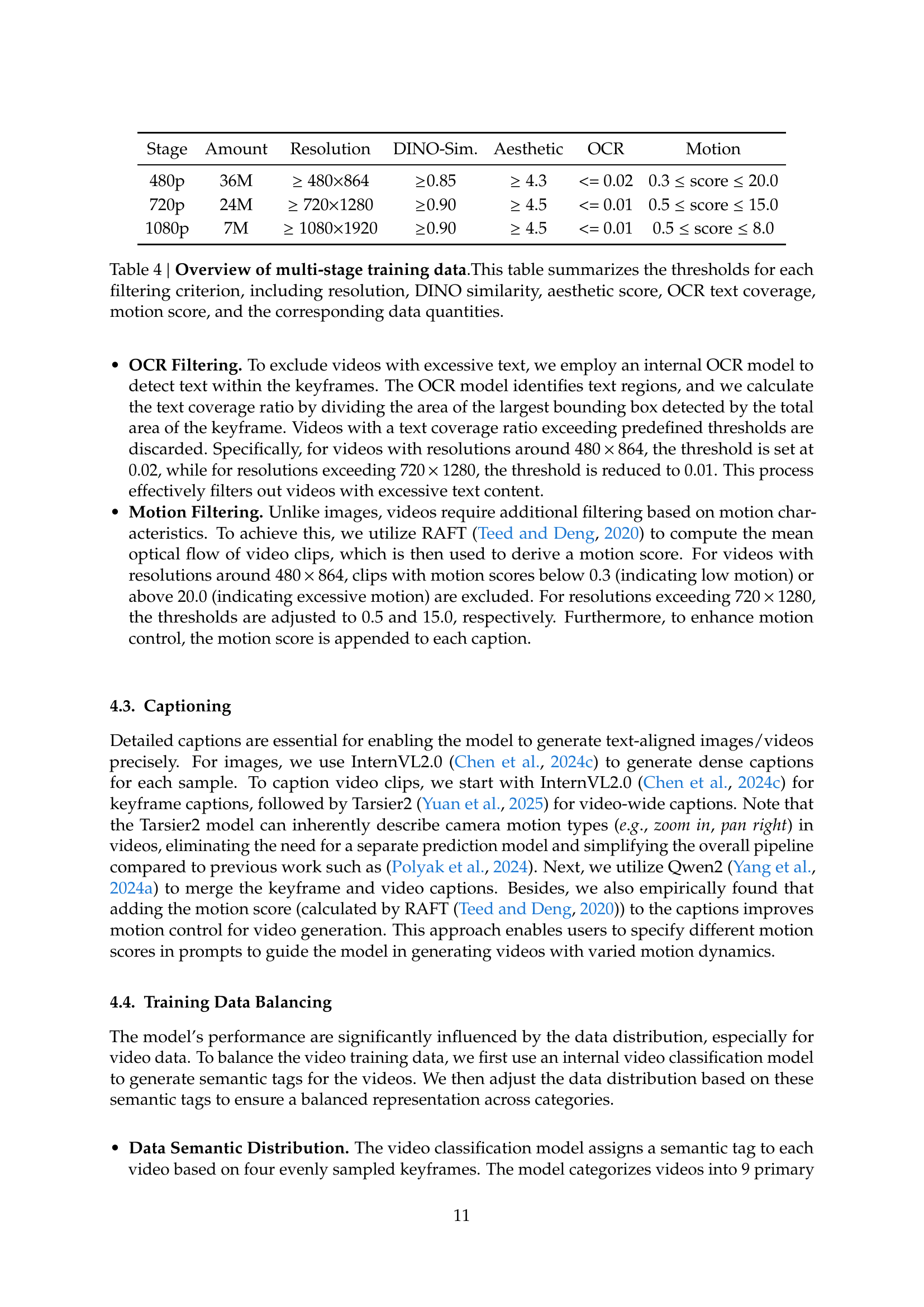
| Stage | Amount | Resolution | DINO-Sim. | Aesthetic | OCR | Motion |
| 480p | 36M | 480864 | 0.85 | 4.3 | <= 0.02 | 0.3 score 20.0 |
| 720p | 24M | 7201280 | 0.90 | 4.5 | <= 0.01 | 0.5 score 15.0 |
| 1080p | 7M | 10801920 | 0.90 | 4.5 | <= 0.01 | 0.5 score 8.0 |
🔼 Table 4 details the dataset filtering process for a multi-stage video and image training pipeline. It outlines the thresholds applied at each stage for various quality metrics, including resolution, DINO similarity score (a measure of visual similarity), aesthetic score (subjective assessment of visual appeal), OCR text coverage (proportion of text detected), and motion score (degree of motion in video clips). The table shows how these thresholds were used to filter the data and the amount of data remaining after each filtering step for different resolution categories (480p, 720p, 1080p). This provides a quantitative understanding of data selection criteria and resulting dataset characteristics.
read the caption
Table 4: Overview of multi-stage training data.This table summarizes the thresholds for each filtering criterion, including resolution, DINO similarity, aesthetic score, OCR text coverage, motion score, and the corresponding data quantities.
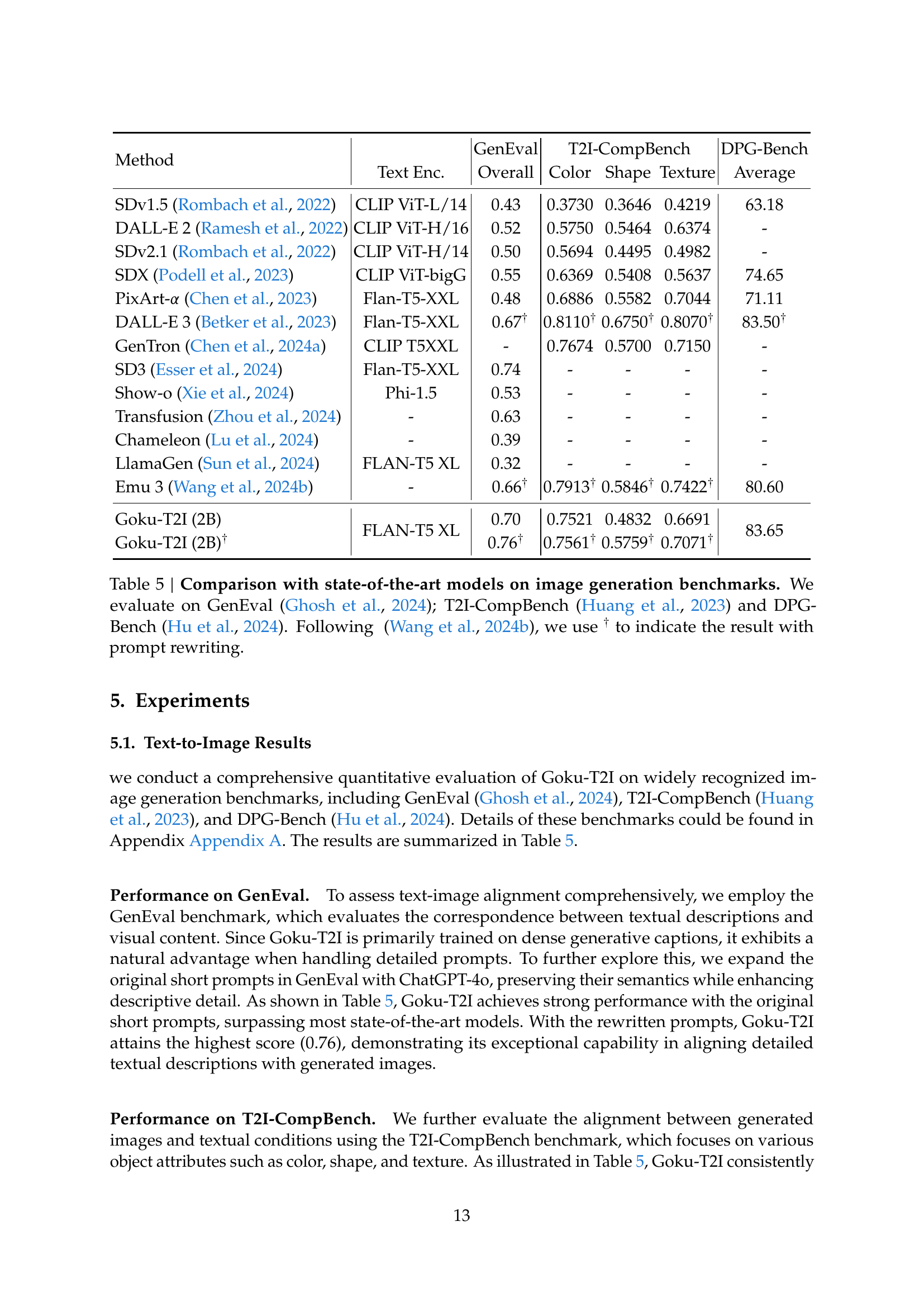
| Method | GenEval | T2I-CompBench | DPG-Bench | |||
| Text Enc. | Overall | Color | Shape | Texture | Average | |
| SDv1.5 (Rombach et al.,, 2022) | CLIP ViT-L/14 | 0.43 | 0.3730 | 0.3646 | 0.4219 | 63.18 |
| DALL-E 2 (Ramesh et al.,, 2022) | CLIP ViT-H/16 | 0.52 | 0.5750 | 0.5464 | 0.6374 | - |
| SDv2.1 (Rombach et al.,, 2022) | CLIP ViT-H/14 | 0.50 | 0.5694 | 0.4495 | 0.4982 | - |
| SDX (Podell et al.,, 2023) | CLIP ViT-bigG | 0.55 | 0.6369 | 0.5408 | 0.5637 | 74.65 |
| PixArt- (Chen et al.,, 2023) | Flan-T5-XXL | 0.48 | 0.6886 | 0.5582 | 0.7044 | 71.11 |
| DALL-E 3 (Betker et al.,, 2023) | Flan-T5-XXL | 0.67† | 0.8110† | 0.6750† | 0.8070† | 83.50† |
| GenTron (Chen et al., 2024a, ) | CLIP T5XXL | - | 0.7674 | 0.5700 | 0.7150 | - |
| SD3 (Esser et al.,, 2024) | Flan-T5-XXL | 0.74 | - | - | - | - |
| Show-o (Xie et al.,, 2024) | Phi-1.5 | 0.53 | - | - | - | - |
| Transfusion (Zhou et al.,, 2024) | - | 0.63 | - | - | - | - |
| Chameleon (Lu et al.,, 2024) | - | 0.39 | - | - | - | - |
| LlamaGen (Sun et al.,, 2024) | FLAN-T5 XL | 0.32 | - | - | - | - |
| Emu 3 (Wang et al., 2024b, ) | - | 0.66† | 0.7913† | 0.5846† | 0.7422† | 80.60 |
| Goku-T2I (2B) | FLAN-T5 XL | 0.70 | 0.7521 | 0.4832 | 0.6691 | 83.65 |
| Goku-T2I (2B)† | 0.76† | 0.7561† | 0.5759† | 0.7071† | ||
🔼 Table 5 presents a comparative analysis of Goku-T2I’s performance against other state-of-the-art image generation models across three widely recognized benchmarks: GenEval, T2I-CompBench, and DPG-Bench. GenEval assesses overall image quality and alignment with the text prompt. T2I-CompBench evaluates the model’s ability to generate images with accurate color, shape, and texture, as specified in the prompts. DPG-Bench tests the model’s performance on complex, detailed prompts. The table indicates results obtained using both original prompts and, where applicable (marked with †), prompts that have been rewritten to enhance clarity and detail. The comparison highlights Goku-T2I’s strengths in achieving high-quality image generation and alignment with the given text prompts.
read the caption
Table 5: Comparison with state-of-the-art models on image generation benchmarks. We evaluate on GenEval (Ghosh et al.,, 2024); T2I-CompBench (Huang et al.,, 2023) and DPG-Bench (Hu et al.,, 2024). Following (Wang et al., 2024b, ), we use † to indicate the result with prompt rewriting.
| Method | Resolution | FVD () | IS ( ) |
| CogVideo (Chinese) (Hong et al.,, 2022) | 480480 | 751.34 | 23.55 |
| CogVideo (English) (Hong et al.,, 2022) | 480480 | 701.59 | 25.27 |
| Make-A-Video (Singer et al.,, 2023) | 256256 | 367.23 | 33.00 |
| VideoLDM (Blattmann et al., 2023b, ) | - | 550.61 | 33.45 |
| LVDM (He et al.,, 2022) | 256256 | 372.00 | - |
| MagicVideo (Zhou et al.,, 2022) | - | 655.00 | - |
| PixelDance (Zeng et al.,, 2024) | - | 242.82 | 42.10 |
| PYOCO (Ge et al.,, 2023) | - | 355.19 | 47.76 |
| Emu-Video (Girdhar et al.,, 2023) | 256256 | 317.10 | 42.7 |
| SVD (Blattmann et al., 2023a, ) | 240360 | 242.02 | - |
| Goku-2B (ours) | 256256 | 246.17 | 45.77 1.10 |
| Goku-2B (ours) | 240360 | 254.47 | 46.64 1.08 |
| Goku-2B (ours) | 128128 | 217.24 | 42.30 1.03 |
🔼 Table 6 presents a comparison of zero-shot text-to-video generation performance on the UCF-101 dataset. The table contrasts different models, showing their Frechet Video Distance (FVD) and Inception Score (IS) for videos generated at three different resolutions (256x256, 240x360, 128x128). Lower FVD values and higher IS values indicate better video quality. This allows for evaluation of model performance at various resolutions and a more comprehensive assessment of video generation capabilities.
read the caption
Table 6: Zero-shot text-to-video performance on UCF-101. We generate videos of different resolutions, including 256×\times×256, 240×\times×360, 128×\times×128, for comprehensive comparisons.
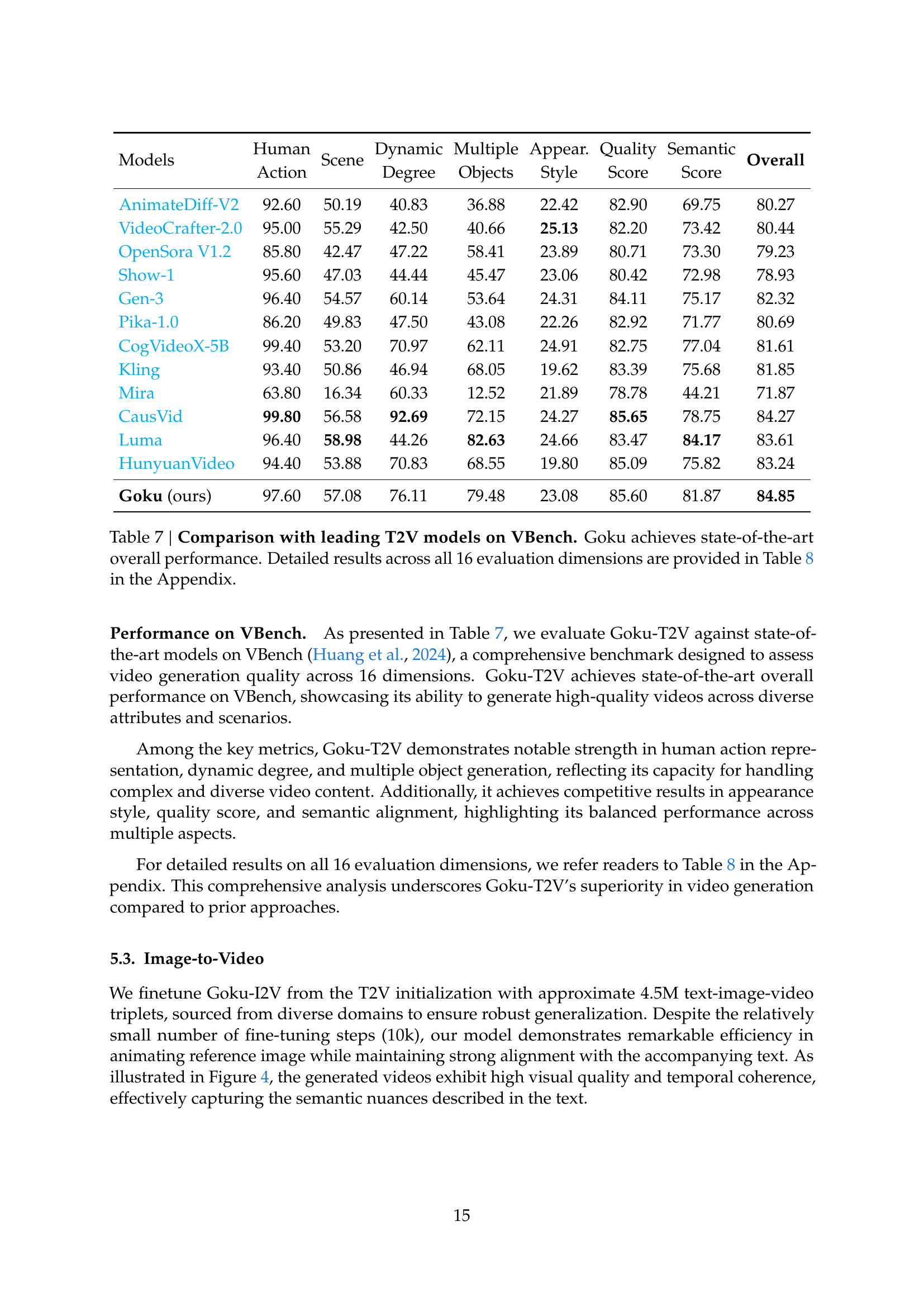
| Models | Human | Scene | Dynamic | Multiple | Appear. | Quality | Semantic | Overall |
| Action | Degree | Objects | Style | Score | Score | |||
| AnimateDiff-V2 | 92.60 | 50.19 | 40.83 | 36.88 | 22.42 | 82.90 | 69.75 | 80.27 |
| VideoCrafter-2.0 | 95.00 | 55.29 | 42.50 | 40.66 | 25.13 | 82.20 | 73.42 | 80.44 |
| OpenSora V1.2 | 85.80 | 42.47 | 47.22 | 58.41 | 23.89 | 80.71 | 73.30 | 79.23 |
| Show-1 | 95.60 | 47.03 | 44.44 | 45.47 | 23.06 | 80.42 | 72.98 | 78.93 |
| Gen-3 | 96.40 | 54.57 | 60.14 | 53.64 | 24.31 | 84.11 | 75.17 | 82.32 |
| Pika-1.0 | 86.20 | 49.83 | 47.50 | 43.08 | 22.26 | 82.92 | 71.77 | 80.69 |
| CogVideoX-5B | 99.40 | 53.20 | 70.97 | 62.11 | 24.91 | 82.75 | 77.04 | 81.61 |
| Kling | 93.40 | 50.86 | 46.94 | 68.05 | 19.62 | 83.39 | 75.68 | 81.85 |
| Mira | 63.80 | 16.34 | 60.33 | 12.52 | 21.89 | 78.78 | 44.21 | 71.87 |
| CausVid | 99.80 | 56.58 | 92.69 | 72.15 | 24.27 | 85.65 | 78.75 | 84.27 |
| Luma | 96.40 | 58.98 | 44.26 | 82.63 | 24.66 | 83.47 | 84.17 | 83.61 |
| HunyuanVideo | 94.40 | 53.88 | 70.83 | 68.55 | 19.80 | 85.09 | 75.82 | 83.24 |
| Goku (ours) | 97.60 | 57.08 | 76.11 | 79.48 | 23.08 | 85.60 | 81.87 | 84.85 |
🔼 Table 7 presents a comprehensive comparison of Goku’s text-to-video (T2V) performance against leading models on the VBench benchmark. VBench is a rigorous evaluation framework assessing video generation quality across 16 different dimensions, covering aspects like human action representation, dynamic scene elements, multiple object generation, aesthetic quality, and semantic alignment. Goku demonstrates state-of-the-art overall performance, excelling particularly in areas such as dynamic object generation and human action representation. For a detailed breakdown of performance across each of the 16 individual evaluation dimensions, refer to Table 8 in the appendix.
read the caption
Table 7: Comparison with leading T2V models on VBench. Goku achieves state-of-the-art overall performance. Detailed results across all 16 evaluation dimensions are provided in Table 8 in the Appendix.
Full paper#