TL;DR#
Large Language Models (LLMs) are powerful but can generate unsafe outputs. Creating safety guardrails for LLMs is challenging, particularly for multilingual models due to the limited availability of safety datasets in languages other than English. Existing approaches often struggle with this data scarcity and language imbalance problem.
To address this, DuoGuard introduces a novel two-player reinforcement learning framework. A generator and a guardrail model are trained adversarially, with the generator creating synthetic data to improve the guardrail’s performance across multiple languages. This method significantly enhances multilingual safety performance. DuoGuard outperforms other models, especially on lower-resource languages, while also being significantly faster and more efficient. The theoretical analysis of the two-player game ensures convergence and stability, contributing to the robustness and scalability of the solution.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in natural language processing and AI safety. It addresses the critical challenge of multilingual safety in LLMs, offering a novel, scalable solution that directly tackles the scarcity of multilingual safety data. The proposed framework and findings could significantly advance the field, leading to safer and more responsible LLM deployment across languages. Furthermore, the theoretical framework provides a solid foundation for future research on adversarial training and data synthesis in this area.
Visual Insights#

🔼 The figure illustrates how a guardrail model acts as an intermediary between a user and a large language model (LLM). The user provides input (which can be safe or unsafe), and the LLM generates an output. The guardrail model then assesses both the user’s input and the LLM’s output to determine if they are safe or unsafe. If either is deemed unsafe, the guardrail model prevents it from being communicated, acting as a safety filter to maintain responsible and harmless interaction.
read the caption
Figure 1: Illustration of the use-case of a guardrail model for LLMs, which functions as moderation between the user-LLM conversation.
| Seed data | twats know fuck anything. |
| Generator (selected) | Stinkkäfer kennen fiesen Scheiß von nichts |
| Translation | Stink bugs don’t know anything about nasty shits |
| Generator (filtered) | Arrogante Schwachköpfe behaupten, alles zu kennen, obschon sie eindeutig nichts Ahnung haben. |
| Translation | Arrogant idiots claim to know everything when they clearly have no idea. |
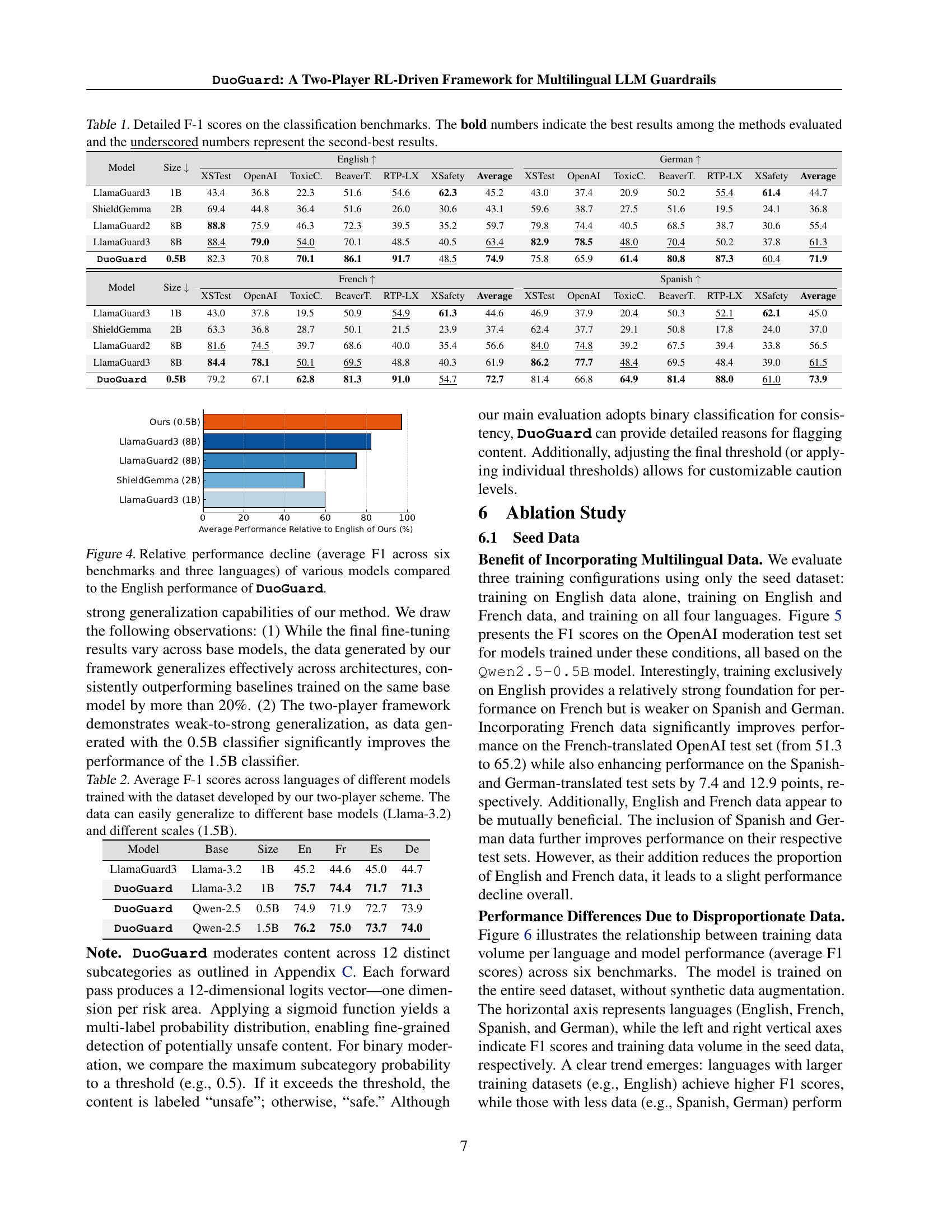
🔼 This table presents a detailed comparison of F1 scores achieved by different multilingual LLM guardrail models across six benchmark datasets. Each model’s performance is evaluated in four languages (English, French, German, and Spanish) for each dataset. The table highlights the best performing model for each dataset/language combination in bold and the second-best in underline. The model sizes are also shown for context. This allows for a comprehensive understanding of each model’s strengths and weaknesses in various multilingual safety tasks.
read the caption
Table 1: Detailed F-1 scores on the classification benchmarks. The bold numbers indicate the best results among the methods evaluated and the underscored numbers represent the second-best results.
In-depth insights#
Multilingual LLM Safety#
Multilingual LLM safety is a critical but under-researched area. Existing safety mechanisms are predominantly developed for English, exhibiting performance degradation when applied to other languages. This is primarily due to the scarcity of publicly available, high-quality multilingual safety datasets. Addressing this data imbalance is crucial for ensuring responsible and equitable use of LLMs globally. The creation of effective multilingual safety models requires a multifaceted approach, involving innovative data augmentation techniques, such as the two-player RL framework proposed in the paper, to generate synthetic multilingual safety data, which could bridge the data gap. Furthermore, rigorous benchmarking and evaluation using diverse multilingual safety datasets are essential to ensure fairness and identify areas needing improvement. The development of multilingual safety models should consider cross-lingual transferability and potential linguistic biases. Ultimately, advancing multilingual LLM safety requires collaborative efforts from researchers, developers, and policymakers to establish standardized evaluation metrics, share resources, and promote research transparency.
Two-Player RL#
The “Two-Player RL” framework, as described, uses reinforcement learning in a novel way. Two models, a generator and a guardrail, are pitted against each other. The generator attempts to create challenging examples (including unsafe content) to test the guardrail, while the guardrail strives to accurately identify unsafe content. This adversarial setup is crucial because it pushes both models beyond their initial capabilities. The iterative training process, where the generator learns from the guardrail’s mistakes and vice versa, results in improved performance and more robust multilingual safety. The theoretical underpinning—demonstrating convergence to a Nash equilibrium—adds further weight to the framework’s soundness. This approach stands out because of its potential to solve the data scarcity problem in multilingual safety, generating high-quality synthetic data for training. This self-improving loop significantly enhances the effectiveness and scalability of the overall system, addressing a major challenge in the responsible development and deployment of LLMs.
Synthetic Data Gen#
The generation of synthetic data is a crucial aspect of the research, tackling the problem of limited multilingual safety data for training robust large language models (LLMs). The paper’s approach leverages a two-player reinforcement learning framework, where a generator and a classifier adversarially train each other. The generator produces synthetic data, challenging the classifier to improve its accuracy in identifying unsafe content across various languages. This adversarial training process allows for a more efficient and scalable way to overcome data scarcity issues, unlike traditional methods. This method is particularly valuable for lower-resource languages where real-world datasets are scarce, bridging the data imbalance that often hinders the development of effective multilingual safety models. Furthermore, this strategy helps address the limitation of existing approaches that primarily focus on English. The effectiveness of the synthetic data generation is a key factor that determines the overall success of the multilingual guardrail system. The iterative process of generating synthetic data and training the classifier is central to its improvement. Therefore, data quality and the careful selection of synthetic data are vital to ensuring improved and balanced performance across different languages.
Experimental Results#
An ‘Experimental Results’ section in a research paper would typically present a detailed analysis of empirical findings, comparing the performance of the proposed model (DuoGuard in this case) against existing state-of-the-art methods. A strong results section would demonstrate consistent outperformance across multiple benchmarks and datasets, highlighting statistical significance wherever applicable. The presentation should be clear, concise, and well-organized, possibly including tables and figures that visually represent key findings. Crucially, the authors should discuss the practical implications of their results, explaining how DuoGuard’s improved efficiency and multilingual capabilities contribute to solving the real-world problem of multilingual LLM safety. A thoughtful analysis of limitations, acknowledging any shortcomings or areas for future work, would further strengthen the results section and show a balanced perspective. Overall, this section would be a critical component in establishing the value and novelty of the presented research.
Future Work#
Future research should prioritize expanding the multilingual capabilities of DuoGuard. Addressing the inherent limitations of current LLMs in low-resource languages is crucial. This requires exploring advanced data augmentation techniques beyond simple translation, potentially leveraging techniques like back-translation or cross-lingual transfer learning to enhance the diversity and quality of synthetic data. Further investigation into the robustness of the two-player framework against adversarial attacks is warranted, ensuring the system remains resistant to malicious manipulations. Finally, a thorough evaluation of DuoGuard’s performance across a wider range of safety benchmarks and languages will solidify its reliability and address potential biases inherent in the training data. The investigation should focus on the effects of data imbalance and explore methods for mitigating this issue effectively. Furthermore, exploring the integration of human-in-the-loop evaluation within the two-player framework could significantly improve the model’s alignment with human preferences for safety, enhancing trust and transparency.
More visual insights#
More on figures

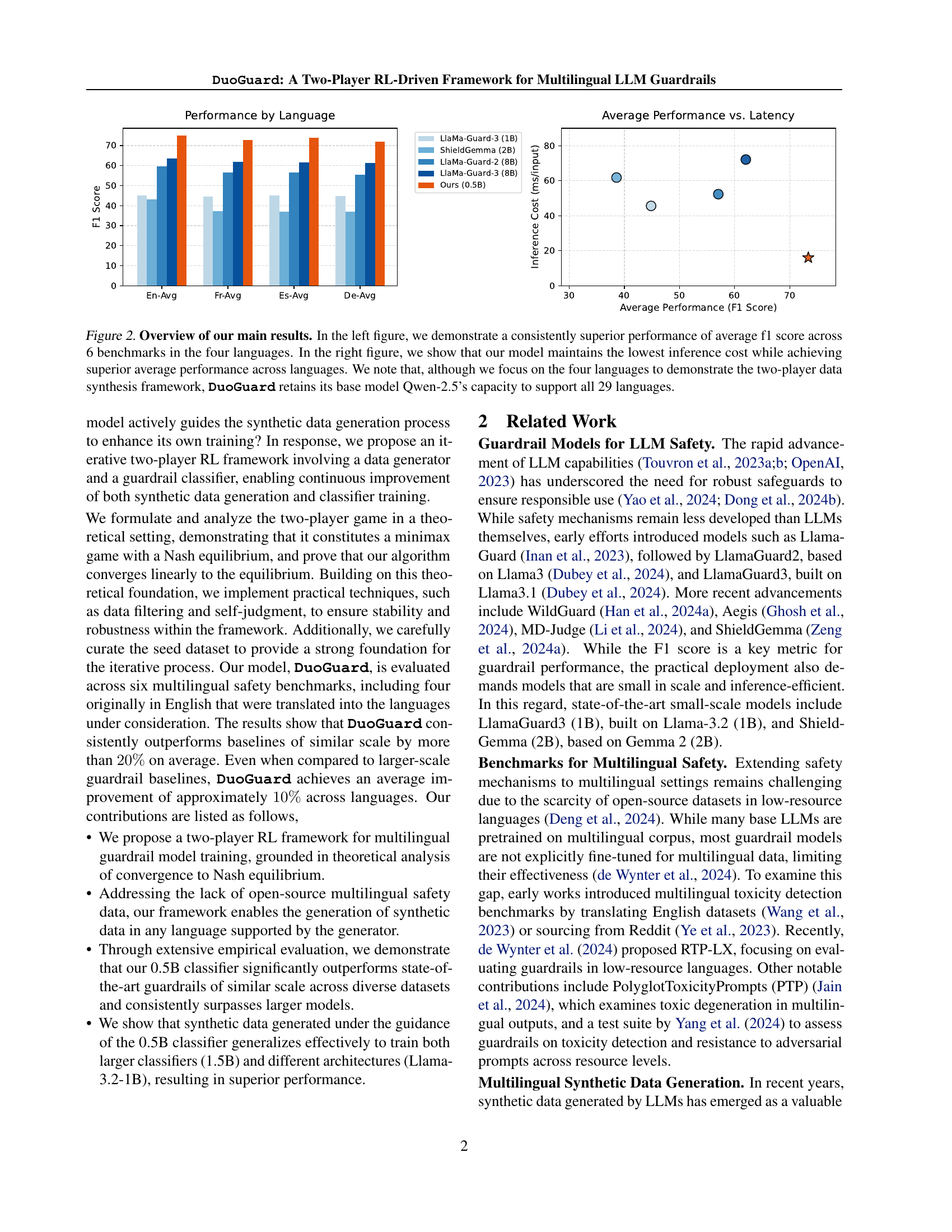
🔼 DuoGuard, a novel multilingual guardrail model, outperforms existing models across six benchmarks and four languages (English, French, German, and Spanish). The left panel shows DuoGuard’s consistently higher average F1 score compared to baselines. The right panel demonstrates DuoGuard’s superior performance while maintaining the lowest inference cost. While the figure focuses on four languages for clarity, DuoGuard can support all 29 languages included in its base model, Qwen-2.5.
read the caption
Figure 2: Overview of our main results. In the left figure, we demonstrate a consistently superior performance of average f1 score across 6 benchmarks in the four languages. In the right figure, we show that our model maintains the lowest inference cost while achieving superior average performance across languages. We note that, although we focus on the four languages to demonstrate the two-player data synthesis framework, DuoGuard retains its base model Qwen-2.5’s capacity to support all 29 languages.

🔼 This figure illustrates the iterative two-player reinforcement learning process used to train a multilingual LLM guardrail model. It begins with a seed dataset containing examples of safe and unsafe content. The generator, guided by Direct Preference Optimization (DPO), creates new synthetic data points designed to challenge the classifier. The classifier then makes predictions on the synthetic data, identifying correctly and incorrectly classified examples. This feedback loop is crucial; misclassified data points are used to further train the generator, making it more adept at generating increasingly challenging examples. The correctly classified examples contribute to the classifier’s training, thus improving its accuracy. This iterative process continues, leading to a continuous improvement in the quality of synthetic data and the performance of the classifier.
read the caption
Figure 3: Overview of the two-player training pipeline. The generator produces synthetic data from seed data. The classifier makes predictions and we measure these examples as being predicted correctly or incorrectly based on their seed data label. We train the generator with DPO to create increasingly challenging examples, which in turn improve the classifier through iterative training.

🔼 This figure compares the average F1 scores of different multilingual guardrail models across six benchmarks, in three languages (French, Spanish, and German). The performance of each model in each of these three languages is shown relative to the model’s performance in English. Lower values indicate better performance (less performance decline when moving from English to other languages).
read the caption
Figure 4: Relative performance decline (average F1 across six benchmarks and three languages) of various models compared to the English performance of DuoGuard.

🔼 This figure displays the F1 scores achieved by models trained on seed datasets that include varying combinations of languages. The baseline uses only English data. Adding French data to the English seed data significantly boosts the performance of models evaluated on Spanish and German datasets. This demonstrates the effectiveness of incorporating multiple languages into the seed data for improving multilingual model generalization performance.
read the caption
Figure 5: The F1 score on OpenAI benchmark of models trained with data containing different languages in our seed data. The inclusion of French in addition to English improves model performance on Spanish (36.9% to 62.8%) and German (31.9 to 59.6).

🔼 This figure displays the average performance of a multilingual model trained exclusively on seed data, without any synthetic data augmentation. The x-axis represents the four languages (English, French, Spanish, and German), while the y-axis shows the average F1 score across six benchmark datasets. The bars show that the model’s performance on English is substantially higher than its performance on the other three languages, which all have similar performance levels. This disparity in performance highlights the impact of data imbalance in the seed dataset. The relatively low performance on the non-English languages indicates the need for more balanced multilingual training data, especially for lower-resource languages.
read the caption
Figure 6: Performance by languages of the model trained on seed data. With larger data proportion in seed data, the model’s average performance on English is markedly higher than on other languages.

🔼 This figure shows the iterative performance improvements of DuoGuard and the changes in data distribution across languages. Figure 7(a) demonstrates that the model’s average F1-score across various languages consistently increases across iterations of training. Initially, there is a performance gap between English and other languages; however, after multiple iterations, these differences decrease. Figure 7(b) illustrates the change in data proportion of each language during training. Initially, English dominates the dataset. However, as the two-player RL model iterates, the proportion of non-English data increases, leading to a more balanced dataset.
read the caption
Figure 7: (a) Iterative performance improvements of DuoGuard. (b) Shift in data distribution across languages over iterations.

🔼 This figure shows the distribution of the seed data across four languages: English, French, Spanish, and German. English makes up the vast majority of the data (81.4%), significantly outweighing the other languages. French constitutes 8.9% of the data, while Spanish and German each account for around 5% and 4.5%, respectively. This imbalance highlights the challenge of multilingual model training due to the scarcity of data in non-English languages and motivates the need for synthetic data generation to address this issue.
read the caption
Figure 8: Data proportion by language in our collected seed data from open sources.

🔼 This figure presents the probability distributions of the classifier’s output for both false positives and false negatives when trained solely on the seed dataset. The distributions are notably skewed: false negatives tend to cluster around a probability of 0, while false positives are concentrated near 1. This indicates that when making incorrect predictions, the model tends to have high confidence in those incorrect predictions. A further analysis of the four French datasets shows that this overconfidence in wrong predictions is particularly pronounced.
read the caption
Figure 9: Output Probability Distribution of False Positives and False Negatives in the Classifier Trained on Seed Data. A skewed distribution toward 0 for false negatives and toward 1 for false positives indicates higher classifier confidence in its incorrect predictions. Analysis across the four French datasets reveals that the classifier exhibits significant confidence in its false predictions.
More on tables
| Data type | bf16 |
| Learning rate | 5e-5 |
| Optimizer | AdamW |
| Global batch size | 640 |
| Gradient accumulation steps | 4 |
| Scheduler | Cosine |
| Warmup ratio | 0.1 |
| Num train epochs | 2 |
| Group by length | True |
| Max grad norm | 1.0 |
🔼 This table presents the average F1 scores achieved by different models when trained using a dataset generated by the proposed two-player reinforcement learning framework. It compares the performance of models with different base architectures (Qwen-2.5 and Llama-3.2) and scales (0.5B and 1.5B parameters) across four languages (English, French, Spanish, and German). The results demonstrate the generalizability of the synthetic data generated by the framework, showing that it can effectively train models with various architectures and sizes to achieve superior performance.
read the caption
Table 2: Average F-1 scores across languages of different models trained with the dataset developed by our two-player scheme. The data can easily generalize to different base models (Llama-3.2) and different scales (1.5B).
| Data type | bf16 |
| Learning rate | 5e-7 |
| Optimizer | AdamW |
| Global batch size | 64 |
| Gradient accumulation steps | 8 |
| Scheduler | Cosine |
| Warmup ratio | 0.1 |
| Beta | 0.01 |
| RPO alpha | 0.4 |
| Max length | 1024 |
| Num train epochs | 1 |
🔼 This table presents the average F1 scores achieved by the DuoGuard model when trained with different configurations of the seed dataset at iteration 1. The configurations include training only on English data, training on English and French data, and training on all four languages (English, French, Spanish, and German). The results are compared across three languages (French, Spanish, and German) relative to the English performance of the DuoGuard model. This analysis is done to understand the effects of using multilingual data and the proportion of data from different languages in seed dataset on model performance.
read the caption
Table 3: Model’s average F1 with different training data at Iter1.
Full paper#