TL;DR#
Rotary Position Embeddings (RoPE) are widely used in Transformer models for handling long sequences, but extending them to video data, which has a complex spatiotemporal structure, is challenging. Existing methods often flatten video data into a 1D sequence, losing crucial spatial and temporal information, or use suboptimal frequency allocations, leading to poor performance, especially when dealing with distractors.
This paper introduces VideoRoPE, a new 3D RoPE specifically designed for video. VideoRoPE uses a 3D structure, a diagonal layout to maintain spatial symmetry, adjustable temporal spacing, and low-frequency temporal allocation to reduce periodic oscillations. The authors introduce a new challenging benchmark (V-NIAH-D), which demonstrates the superiority of VideoRoPE over existing methods. VideoRoPE achieves state-of-the-art results across diverse video tasks such as long video retrieval, video understanding, and video hallucination.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in adapting rotary position embeddings (RoPE) for video data, which is crucial for the development of advanced video large language models. It proposes a novel method, VideoRoPE, that significantly outperforms existing methods on various benchmarks. This work provides a deeper understanding of the key properties required for effective video RoPE, and opens up new avenues for research into improved positional encoding techniques for other multi-modal applications.
Visual Insights#

🔼 This radar chart displays the performance of VideoRoPE and other RoPE variants across multiple video benchmarks: Long Video Bench, MLVU, VideoMME, V-NIAH, and VideoHalluciner. Each benchmark assesses different aspects of video understanding capabilities. VideoRoPE demonstrates superior performance compared to other methods, showcasing its effectiveness in various video tasks. The chart visually highlights VideoRoPE’s consistent improvements across these diverse benchmarks.
read the caption
Figure 1: VideoRoPE outperforms RoPE variants on benchmarks.
| 2D/3D Structure | Frequency Allocation | Spatial Symmetry | Temporal Index Scaling | |
| Vanilla RoPE (Su et al., 2024) | ✗ | ✗ | ✗ | ✗ |
| TAD-RoPE (Gao et al., 2024) | ✗ | ✗ | ✗ | ✓ |
| RoPE-Tie (Su, 2024a) | ✓ | ✗ | ✓ | ✗ |
| M-RoPE (Wang et al., 2024b) | ✓ | ✗ | ✗ | ✗ |
| VideoRoPE (Ours) | ✓ | ✓ | ✓ | ✓ |
🔼 This table compares several variants of Rotary Position Embedding (RoPE), a technique used in Transformer models to incorporate positional information, specifically focusing on their effectiveness for Video Large Language Models (Video LLMs). It highlights key differences across four aspects: the 2D/3D structure of the model (how it handles the spatial and temporal dimensions of video data), frequency allocation (how frequencies are assigned to different dimensions), spatial symmetry (whether the model maintains symmetry in its handling of spatial information), and temporal index scaling (how the model handles the different granularities of temporal and spatial information). Each RoPE variant is evaluated according to whether it satisfies these characteristics with a checkmark or an ‘X’. This allows for a comparison of different approaches and their suitability for processing video data.
read the caption
Table 1: Comparison between different RoPE variants for Video Large Language Models (Video LLMs).
In-depth insights#
RoPE’s Video Limits#
The heading “RoPE’s Video Limits” suggests an exploration of the challenges in applying Rotary Position Embeddings (RoPE), a successful technique in natural language processing, to the spatiotemporal domain of video data. The core limitation lies in RoPE’s inherent 1D structure, which struggles to directly represent the 2D or 3D nature of video frames and their temporal evolution. Simply flattening video data into a 1D sequence loses crucial spatial and temporal relationships, hindering effective positional encoding. The paper likely delves into how existing attempts to adapt RoPE to video, such as through direct extensions or 3D adaptations, fall short of adequately capturing complex spatiotemporal relationships. This might involve a discussion of frequency allocation strategies, the impact of periodic oscillations, and the challenges of aligning temporal and spatial dimensions. A key insight likely uncovered is the need for a more sophisticated 3D positional encoding scheme that respects the unique characteristics of video. The authors probably propose a novel method that addresses these limitations by explicitly modeling spatiotemporal dependencies with improved frequency allocation or a new architectural approach to positional embedding for video.
VideoRoPE Design#
The VideoRoPE design is a novel approach to rotary position embedding (RoPE) specifically tailored for video data. It addresses the limitations of previous methods by incorporating three key components: Low-frequency Temporal Allocation (LTA), which mitigates periodic oscillations and improves robustness to distractors; a Diagonal Layout (DL), which maintains spatial symmetry and ensures equal contextual influence from surrounding tokens; and Adjustable Temporal Spacing (ATS), allowing for flexible scaling of temporal indices to better align with varying granularities of temporal and spatial information in video. These components are carefully integrated into a 3D structure to preserve spatio-temporal relationships inherent in video, providing an effective and robust representation of positional information within video-language models. The design’s effectiveness is demonstrated through superior performance across various benchmarks, including those involving long video understanding, retrieval, and hallucination tasks, showcasing its adaptability and superior ability to handle long-range dependencies within complex video data.
V-NIAH-D Challenge#
The V-NIAH-D challenge, a novel extension of the V-NIAH benchmark, introduces a crucial test for video understanding models. By adding periodic distractors to the original V-NIAH dataset, V-NIAH-D highlights the susceptibility of models to misleading visual information, especially when temporal relationships are not properly handled. This clever augmentation effectively assesses a model’s robustness in retrieving relevant information amidst noise, pushing beyond simple long-range visual understanding. The challenge reveals weaknesses in existing rotary position embedding (RoPE) variants, demonstrating that inadequate temporal dimension allocation leads to poor performance. Addressing the V-NIAH-D challenge necessitates a more sophisticated approach to spatio-temporal modeling, such as the proposed VideoRoPE architecture, which strategically allocates temporal and spatial dimensions to mitigate the impact of distractors and achieve superior results. Successfully tackling the V-NIAH-D challenge points to significant advancements in the field of video understanding, pushing the development of more robust and reliable models capable of filtering noise and prioritizing relevant information in complex, real-world scenarios.
Empirical Results#
An Empirical Results section in a research paper would ideally present a comprehensive evaluation of the proposed method, demonstrating its effectiveness and comparing it to existing state-of-the-art techniques. This involves presenting key performance metrics across various datasets and experimental settings. A strong Empirical Results section will detail the experimental setup, including datasets, evaluation metrics, and baseline models used for comparison. In-depth analysis of the results should be provided, explaining any trends or unexpected outcomes. The presentation of results should be clear, concise, and visually engaging, often employing tables and figures to facilitate understanding. Ideally, the authors should also acknowledge limitations and potential biases of their experimental methodology. A robust Empirical Results section is critical for establishing the credibility and impact of the research findings; it’s where the theoretical claims of the paper are put to the test and validated through rigorous empirical evidence.
Future Work#
Future work in video rotary position embedding (RoPE) could explore several promising avenues. Extending VideoRoPE to handle even longer video sequences is crucial, potentially involving techniques like hierarchical attention or memory mechanisms to manage the increased computational complexity. Investigating different frequency allocation strategies beyond the low-frequency temporal allocation could yield further improvements, particularly in balancing spatial and temporal information processing. A deeper investigation into the interaction between RoPE and other components of video LLMs, such as attention mechanisms and normalization layers, is warranted to optimize overall model performance. Benchmarking VideoRoPE on a wider range of video understanding tasks is needed to fully assess its generalizability and effectiveness, potentially including tasks beyond those currently considered. Finally, exploring the application of VideoRoPE to other multi-modal tasks, such as video question answering and video generation, would broaden its impact and showcase its potential as a fundamental building block in advanced video AI systems.
More visual insights#
More on figures

🔼 Figure 2 demonstrates the effect of frequency allocation on video retrieval performance. The left side shows two examples, (a) V-NIAH (Visual Needle-in-a-Haystack) and (b) V-NIAH-D (Visual Needle-in-a-Haystack with Distractors). V-NIAH-D is a more challenging variant that introduces visually similar distractor images around the relevant ‘needle’ image. The right side presents a comparison of retrieval accuracy between M-ROPE and VideoRoPE on both tasks. This comparison highlights VideoRoPE’s improved robustness to distractors, suggesting the effectiveness of its frequency allocation strategy.
read the caption
Figure 2: Left: To demonstrate the importance of frequential allocation, based on VIAH (a) we present a more challenging V-NIAH-D task (b) that similar images are inserted as distractors. Right: Compared to M-RoPE, our VideoRoPE is more robust in retrieval and is less affected by distractors.

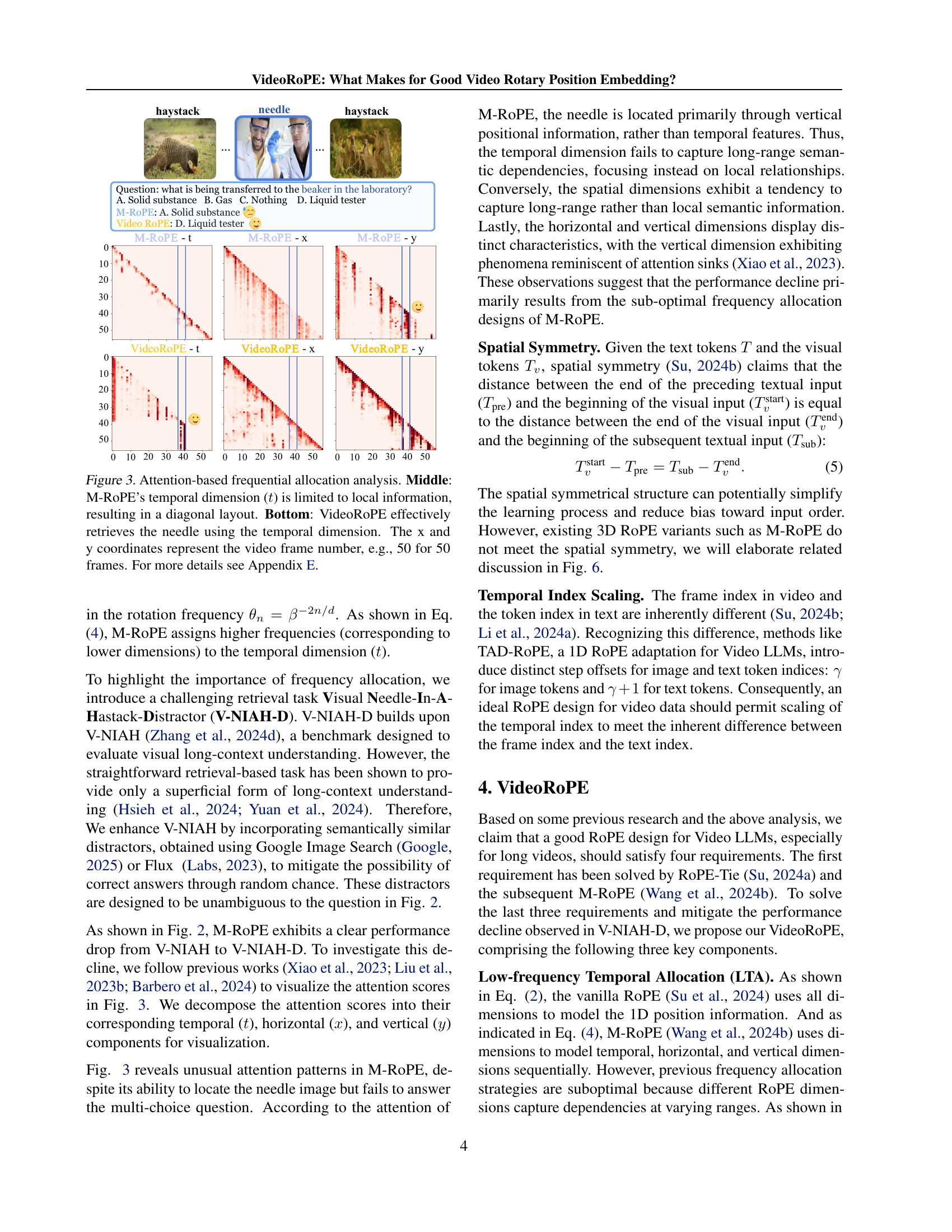
🔼 Figure 3 visualizes the attention weights of different RoPE methods for a video retrieval task. The top row shows the attention weights for M-ROPE, highlighting how its temporal dimension focuses on short-term relationships, resulting in a diagonal pattern. This limitation hinders the model’s ability to capture long-range temporal dependencies, which are crucial for accurately identifying the target ’needle’ in a long video sequence. The bottom row displays the attention weights for VideoRoPE, demonstrating its improved ability to capture long-range temporal dependencies. The VideoRoPE’s temporal dimension effectively focuses on the relevant temporal segments, allowing it to successfully retrieve the ’needle’. The x and y axes represent the spatial coordinates (horizontal and vertical frame indices) in the video, and the color intensity of each cell represents the magnitude of the attention weight.
read the caption
Figure 3: Attention-based frequential allocation analysis. Middle: M-RoPE’s temporal dimension (t𝑡titalic_t) is limited to local information, resulting in a diagonal layout. Bottom: VideoRoPE effectively retrieves the needle using the temporal dimension. The x and y coordinates represent the video frame number, e.g., 50 for 50 frames. For more details see Appendix E.

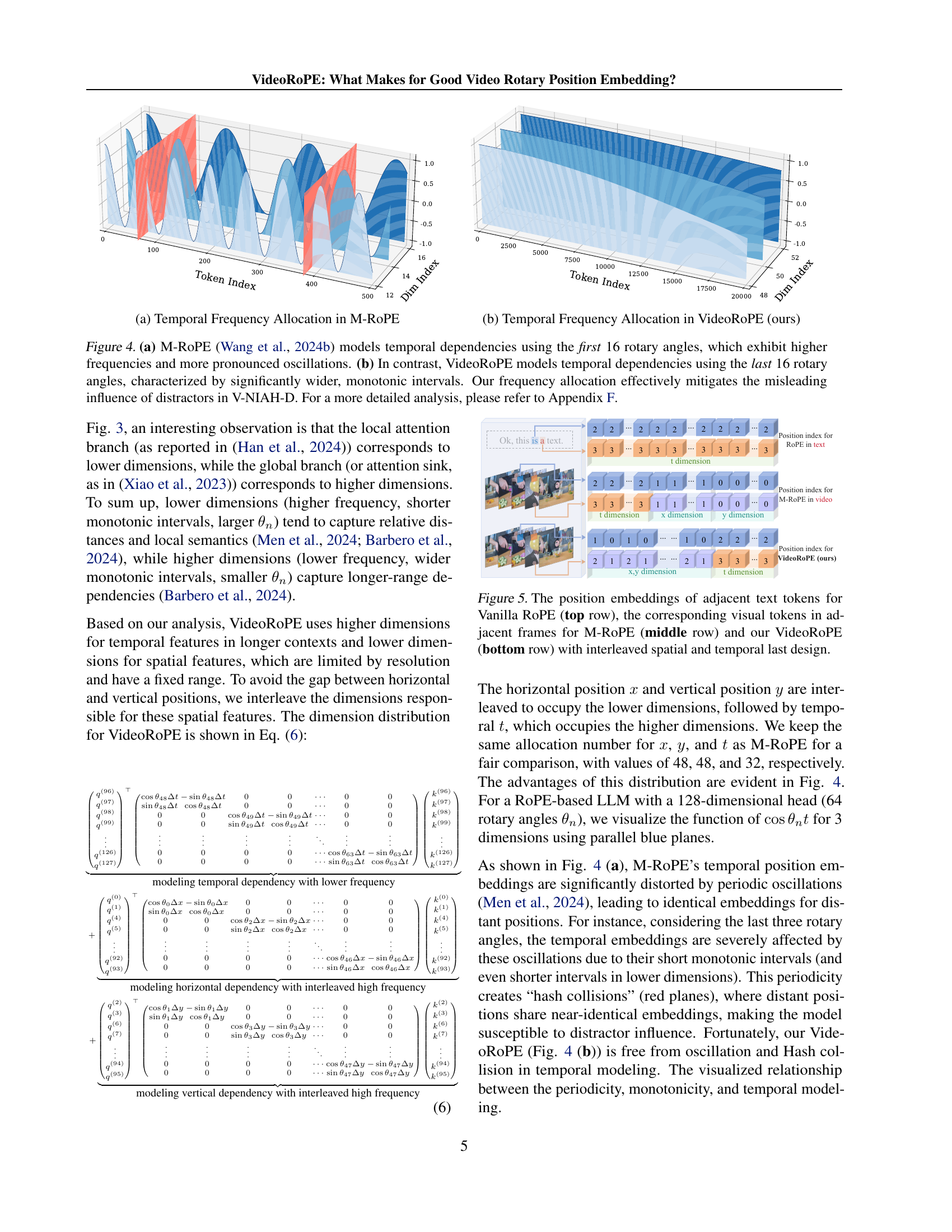
🔼 This figure compares the temporal frequency allocation strategies of M-ROPE and VideoRoPE. M-ROPE allocates higher frequencies (shorter monotonic intervals) to the temporal dimension, while VideoRoPE uses lower frequencies (wider monotonic intervals). This difference is visually represented using graphs that show how quickly the frequency changes across different dimensions. The y-axis shows the index of the dimension, and the x-axis shows the token index (or time). The difference in frequency allocation significantly impacts the robustness of the models to periodic oscillations and distractors, as discussed in the paper.
read the caption
(a) Temporal Frequency Allocation in M-RoPE

🔼 This figure compares the frequency allocation strategies between M-ROPE and VideoRoPE for modeling temporal dependencies. M-ROPE uses higher frequencies for the temporal dimension resulting in pronounced oscillations and a diagonal layout in the attention patterns. In contrast, VideoRoPE allocates lower frequencies to the temporal dimension, resulting in wider, more monotonic intervals, mitigating the periodic oscillations and resulting in improved robustness against distractors in long video retrieval. The x-axis represents the token index, indicating the position within the sequence, while the y-axis represents the dimension index, showing the different frequency bands used for temporal encoding.
read the caption
(b) Temporal Frequency Allocation in VideoRoPE (ours)

🔼 Figure 4 illustrates the difference in temporal frequency allocation between M-ROPE and VideoRoPE. M-ROPE allocates higher frequencies (and thus, more pronounced oscillations) to the early dimensions, making it susceptible to interference from periodic distractors. In contrast, VideoRoPE uses lower frequencies for the temporal dimension, resulting in wider, monotonic intervals that are more robust against periodic distractions in the V-NIAH-D task. This is because the higher frequency of the temporal dimension in M-ROPE makes it more sensitive to noise and periodic patterns, whereas the lower frequency in VideoRoPE makes it more resilient to noise.
read the caption
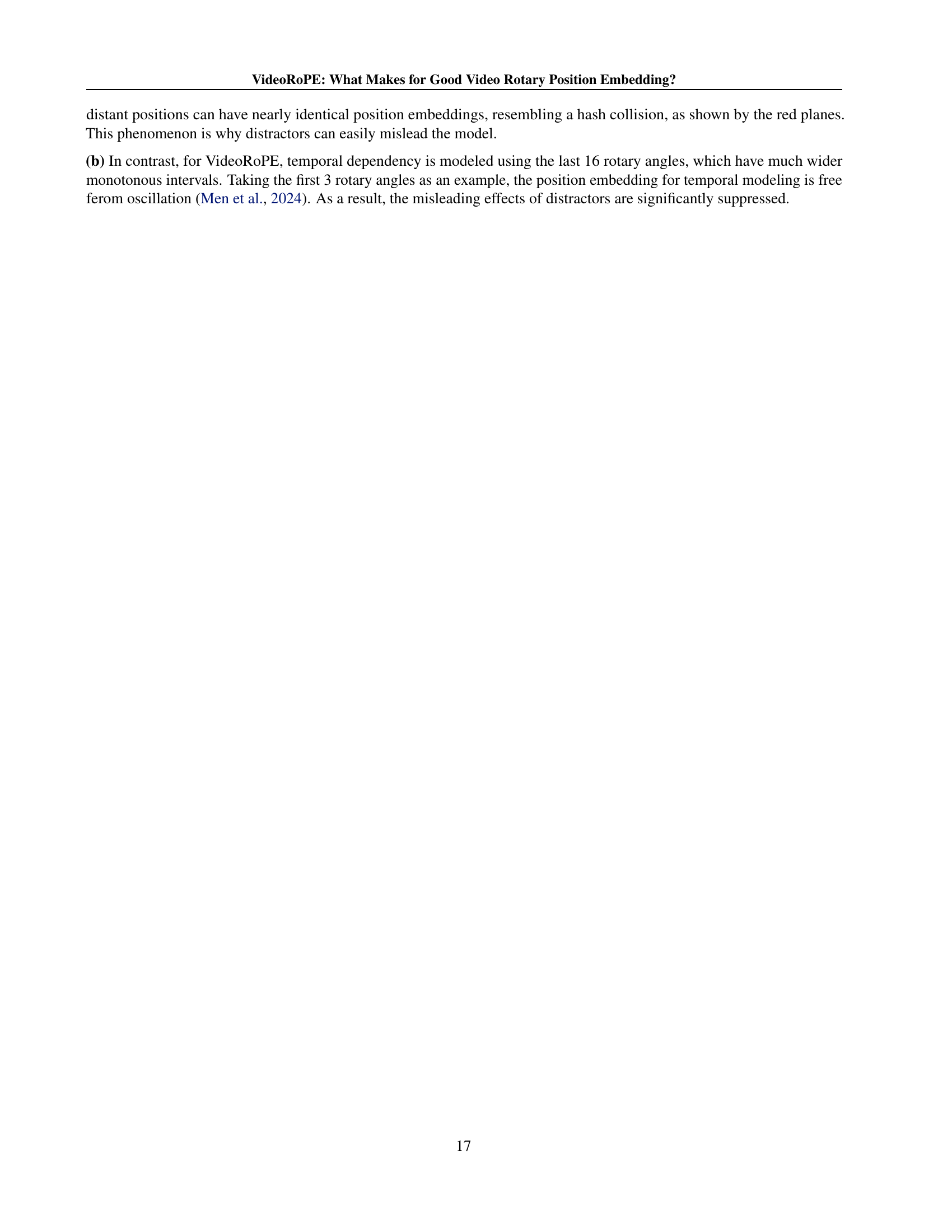
Figure 4: (a) M-RoPE (Wang et al., 2024b) models temporal dependencies using the first 16 rotary angles, which exhibit higher frequencies and more pronounced oscillations. (b) In contrast, VideoRoPE models temporal dependencies using the last 16 rotary angles, characterized by significantly wider, monotonic intervals. Our frequency allocation effectively mitigates the misleading influence of distractors in V-NIAH-D. For a more detailed analysis, please refer to Appendix F.
🔼 This figure compares the positional embeddings of adjacent text and visual tokens for three different methods: Vanilla RoPE, M-ROPE, and VideoRoPE. Vanilla RoPE, designed for 1D sequential data, flattens the video frames into a 1D sequence. M-ROPE uses a 3D structure but divides the dimensions into distinct groups for temporal and spatial features. VideoRoPE, in contrast, employs a 3D structure with an interleaved spatial and temporal layout, aiming to better represent the spatio-temporal relationships in video data. The visualization helps show how each method handles the positional encoding, highlighting differences in how they capture spatial and temporal context.
read the caption
Figure 5: The position embeddings of adjacent text tokens for Vanilla RoPE (top row), the corresponding visual tokens in adjacent frames for M-RoPE (middle row) and our VideoRoPE (bottom row) with interleaved spatial and temporal last design.
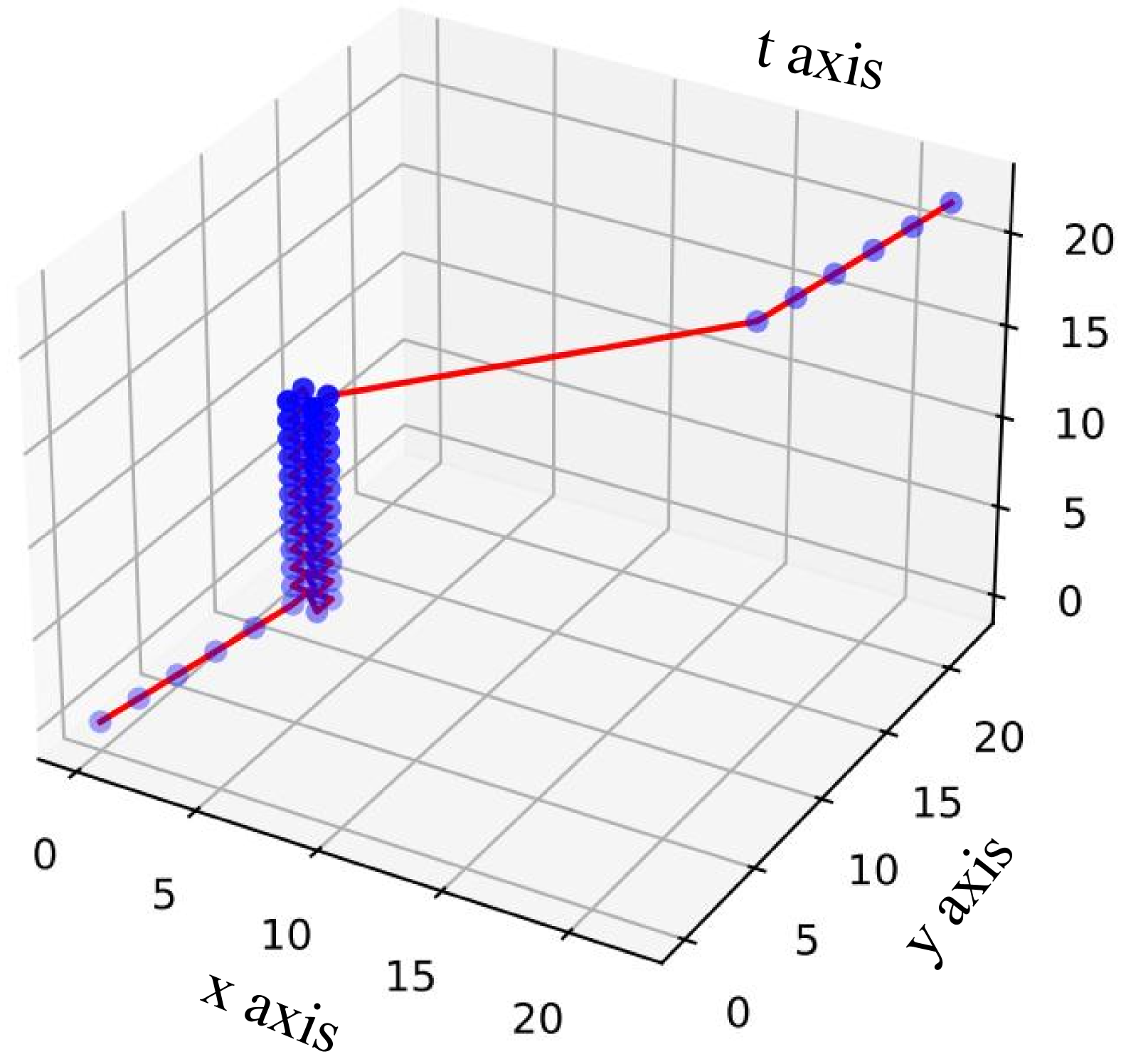
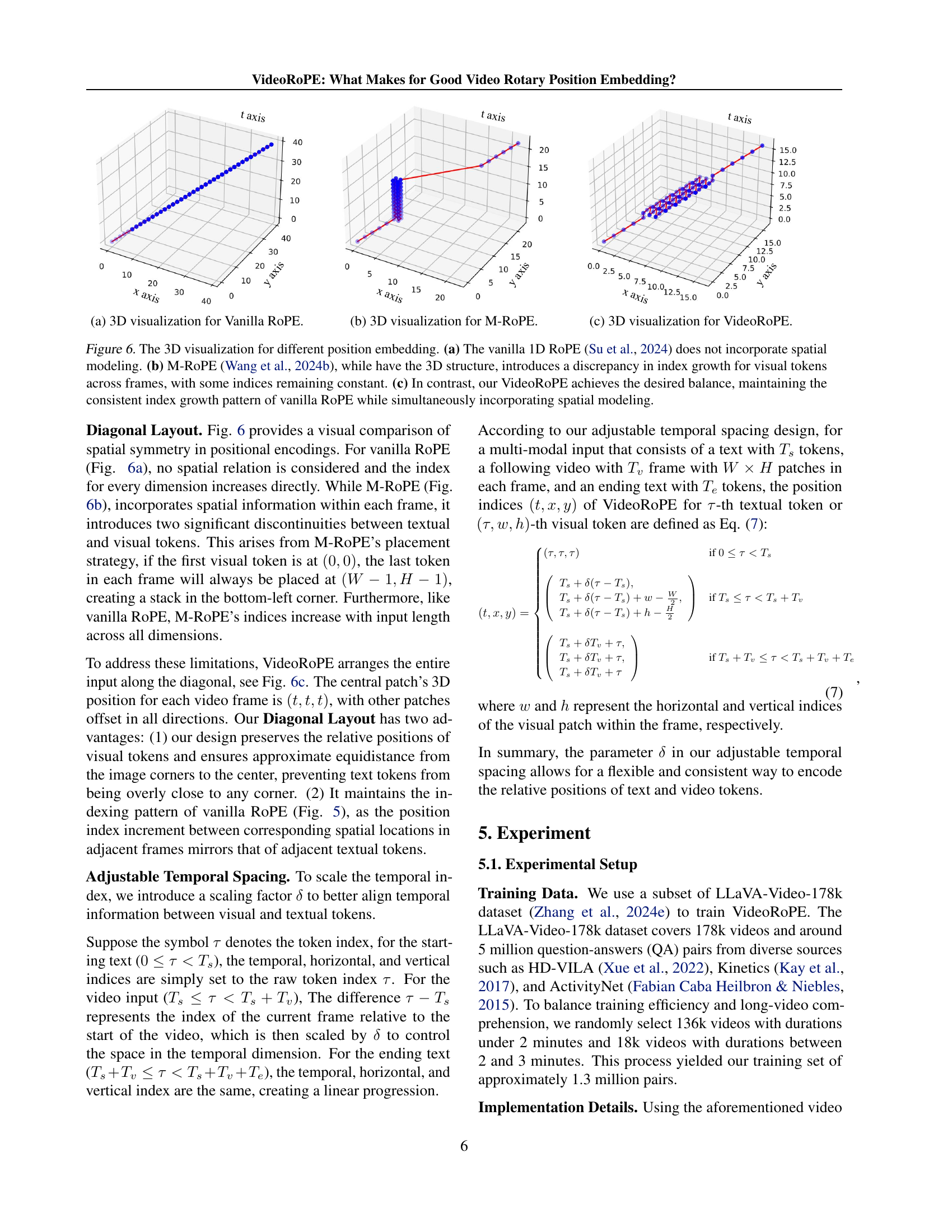
🔼 This 3D visualization illustrates the relative positional encoding scheme of Vanilla RoPE. It shows how the vanilla RoPE, designed for 1D sequential data, handles higher dimensional data by flattening it into a single dimension. The plot lacks the explicit representation of spatiotemporal relationships inherent in 3D data. This visualization helps to illustrate the limitations of applying a 1D positional encoding method to video data, which possesses an inherent 3D structure (temporal, height, width).
read the caption
(a) 3D visualization for Vanilla RoPE.

🔼 This 3D visualization shows how M-RoPE (Multi-dimensional Rotary Position Embedding) allocates dimensions for representing temporal, horizontal, and vertical information in video data. It highlights that M-RoPE, while employing a 3D structure, introduces inconsistencies in the index growth pattern for visual tokens across frames. Some indices remain constant, leading to an imbalance in representing spatial and temporal relationships.
read the caption
(b) 3D visualization for M-RoPE.

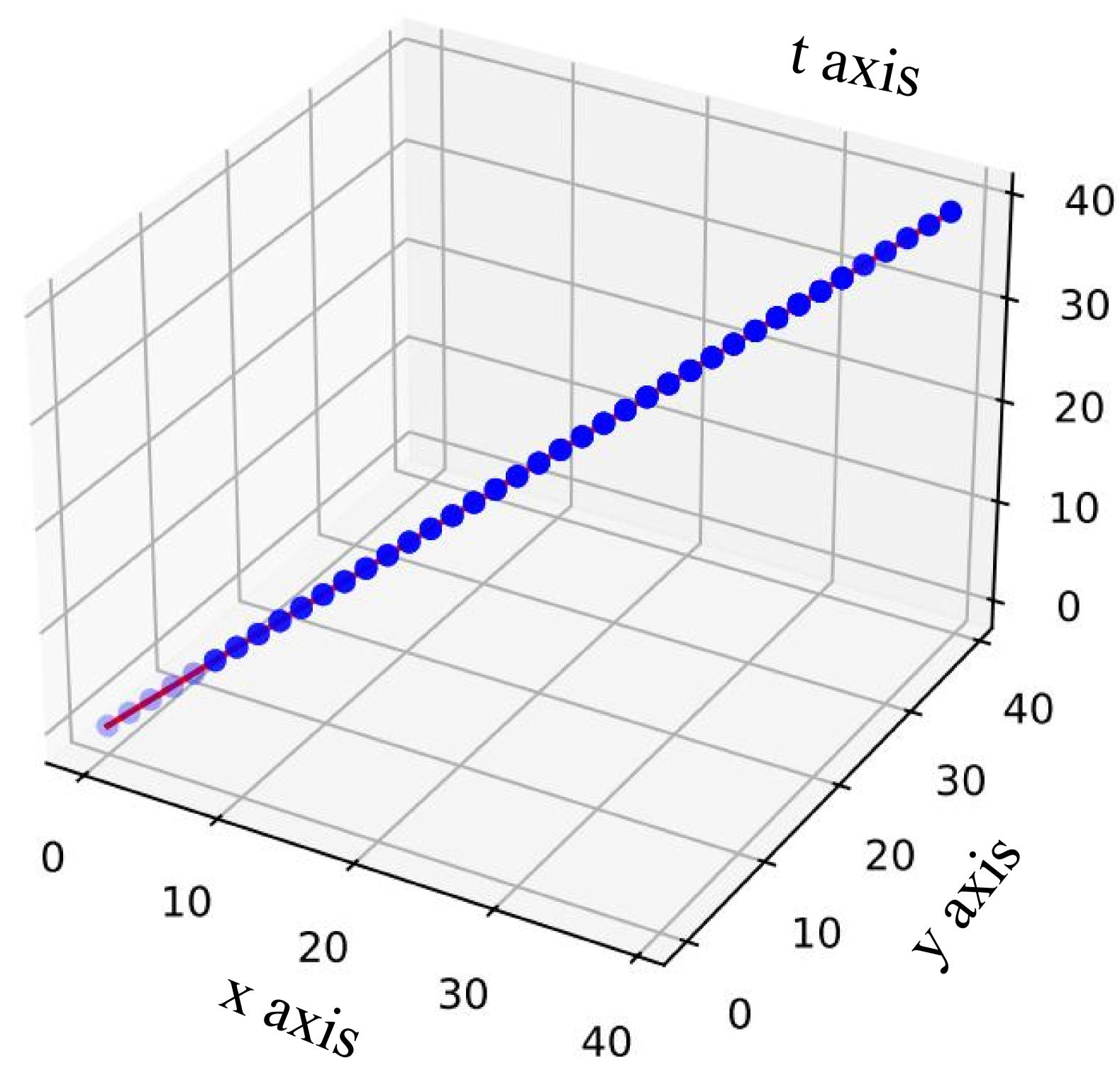
🔼 This 3D visualization showcases VideoRoPE’s unique approach to positional encoding in video data. Unlike previous methods that flatten video frames into a 1D sequence or exhibit inconsistencies in index growth across dimensions, VideoRoPE maintains a consistent index growth pattern while simultaneously incorporating spatial modeling. The visualization clearly illustrates the consistent progression of indices across the temporal (t), horizontal (x), and vertical (y) axes, highlighting the balance achieved between spatial and temporal information.
read the caption
(c) 3D visualization for VideoRoPE.

🔼 Figure 6 visualizes the positional encoding of three different methods: Vanilla RoPE, M-ROPE, and VideoRoPE. Vanilla RoPE, being a 1D method, lacks spatial information, resulting in a linear progression along the time axis (t). M-ROPE attempts 3D modeling, but introduces inconsistencies in the index growth for visual tokens across frames; some indices remain static, breaking the consistent progression. In contrast, VideoRoPE maintains a consistent index growth across all dimensions (t, x, y) while effectively incorporating spatial relationships within its 3D structure. This balanced approach is visualized as a smooth, consistent progression in the figure.
read the caption
Figure 6: The 3D visualization for different position embedding. (a) The vanilla 1D RoPE (Su et al., 2024) does not incorporate spatial modeling. (b) M-RoPE (Wang et al., 2024b), while have the 3D structure, introduces a discrepancy in index growth for visual tokens across frames, with some indices remaining constant. (c) In contrast, our VideoRoPE achieves the desired balance, maintaining the consistent index growth pattern of vanilla RoPE while simultaneously incorporating spatial modeling.

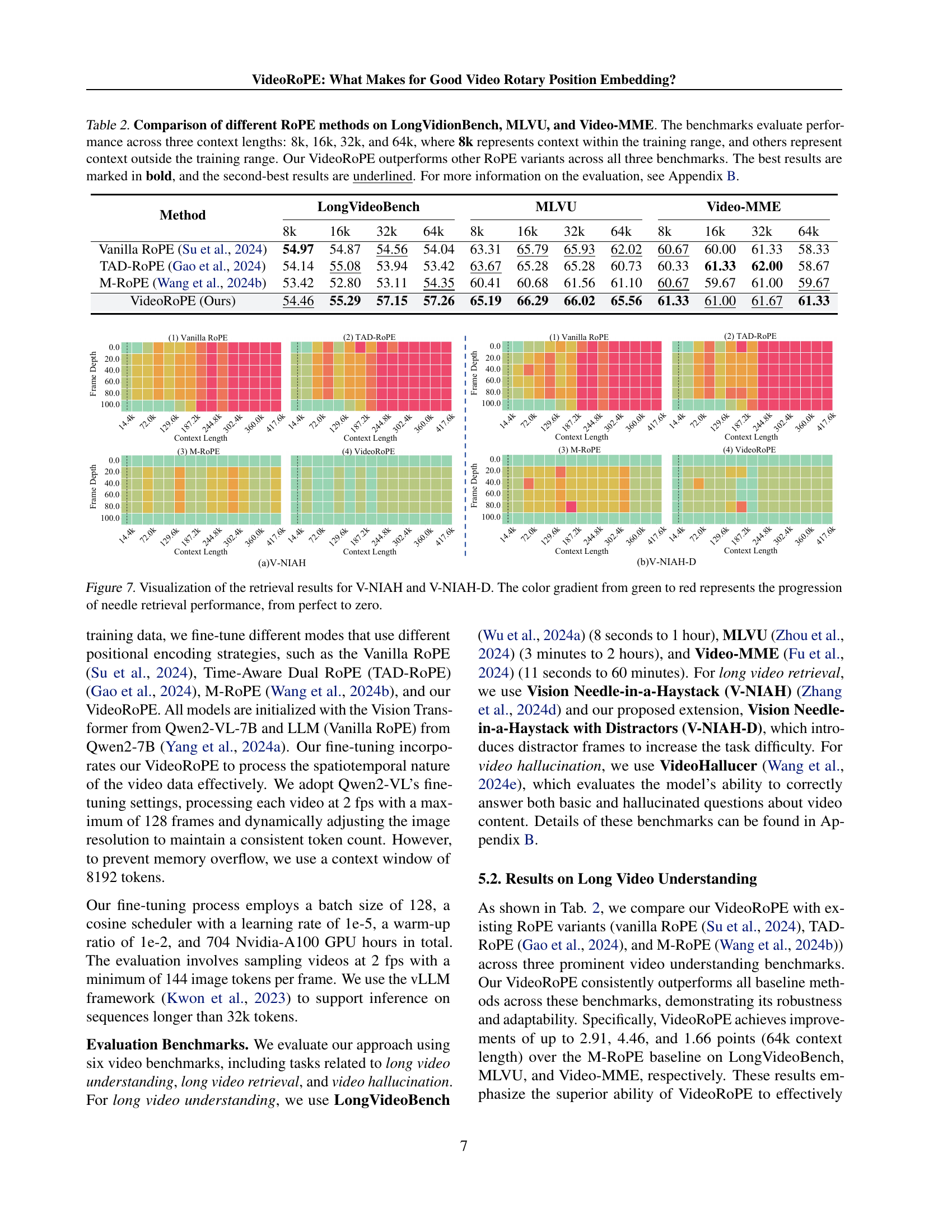
🔼 Figure 7 visualizes the performance of different RoPE methods on the V-NIAH and V-NIAH-D datasets. The plots show how well each method can locate the ’needle’ (target frame) within the ‘haystack’ (video sequence), particularly in the presence of distractors (V-NIAH-D). The color gradient shifting from green to red signifies the performance, ranging from perfect retrieval (green) to complete failure (red). The x-axis shows the length of the haystack, demonstrating the models’ ability to perform long-range retrieval. The y-axis represents the number of frames examined. The four subplots show the results for Vanilla RoPE, TAD-ROPE, M-ROPE, and VideoRoPE, respectively. The figure highlights how VideoRoPE significantly outperforms the others in accurately locating the target frame even with increasing haystack length and distractors.
read the caption
Figure 7: Visualization of the retrieval results for V-NIAH and V-NIAH-D. The color gradient from green to red represents the progression of needle retrieval performance, from perfect to zero.
More on tables
| Method | LongVideoBench | MLVU | Video-MME | |||||||||
| 8k | 16k | 32k | 64k | 8k | 16k | 32k | 64k | 8k | 16k | 32k | 64k | |
| Vanilla RoPE (Su et al., 2024) | 54.97 | 54.87 | 54.56 | 54.04 | 63.31 | 65.79 | 65.93 | 62.02 | 60.67 | 60.00 | 61.33 | 58.33 |
| TAD-RoPE (Gao et al., 2024) | 54.14 | 55.08 | 53.94 | 53.42 | 63.67 | 65.28 | 65.28 | 60.73 | 60.33 | 61.33 | 62.00 | 58.67 |
| M-RoPE (Wang et al., 2024b) | 53.42 | 52.80 | 53.11 | 54.35 | 60.41 | 60.68 | 61.56 | 61.10 | 60.67 | 59.67 | 61.00 | 59.67 |
| VideoRoPE (Ours) | 54.46 | 55.29 | 57.15 | 57.26 | 65.19 | 66.29 | 66.02 | 65.56 | 61.33 | 61.00 | 61.67 | 61.33 |
🔼 This table compares the performance of different rotary position embedding (RoPE) methods on three video understanding benchmarks: LongVideoBench, MLVU, and Video-MME. The benchmarks test performance with varying context lengths (8k, 16k, 32k, and 64k tokens), where 8k represents the context length used during training, and the others represent longer contexts unseen during training. The results show that VideoRoPE consistently outperforms other RoPE variants across all three benchmarks and context lengths. Bold values indicate the best performance, while underlined values indicate second-best performance.
read the caption
Table 2: Comparison of different RoPE methods on LongVidionBench, MLVU, and Video-MME. The benchmarks evaluate performance across three context lengths: 8k, 16k, 32k, and 64k, where 8k represents context within the training range, and others represent context outside the training range. Our VideoRoPE outperforms other RoPE variants across all three benchmarks. The best results are marked in bold, and the second-best results are underlined. For more information on the evaluation, see Appendix B.
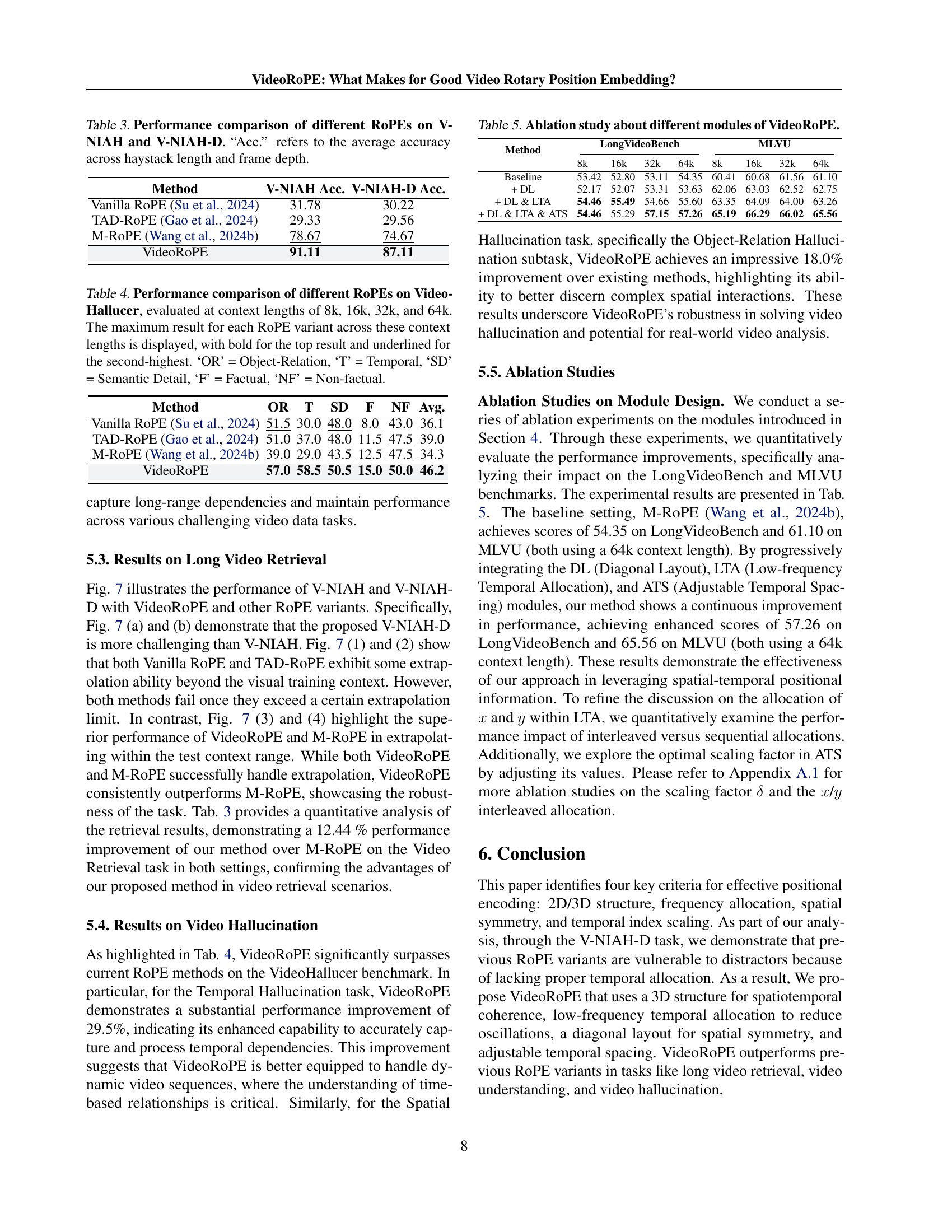
| Method | V-NIAH Acc. | V-NIAH-D Acc. |
| Vanilla RoPE (Su et al., 2024) | 31.78 | 30.22 |
| TAD-RoPE (Gao et al., 2024) | 29.33 | 29.56 |
| M-RoPE (Wang et al., 2024b) | 78.67 | 74.67 |
| VideoRoPE | 91.11 | 87.11 |
🔼 This table presents a performance comparison of various Rotary Position Embedding (RoPE) methods on two video retrieval tasks: V-NIAH (Visual Needle-In-A-Haystack) and V-NIAH-D (V-NIAH with Distractors). V-NIAH-D is a more challenging version of V-NIAH that includes distractor images to test the robustness of the RoPE methods. The table shows the average accuracy (‘Acc.’) achieved by each RoPE method across different haystack lengths (number of frames in the video) and frame depths. Higher accuracy indicates better performance in retrieving the target ’needle’ image from the haystack, even in the presence of distractors.
read the caption
Table 3: Performance comparison of different RoPEs on V-NIAH and V-NIAH-D. “Acc.” refers to the average accuracy across haystack length and frame depth.
| Method | OR | T | SD | F | NF | Avg. |
| Vanilla RoPE (Su et al., 2024) | 51.5 | 30.0 | 48.0 | 8.0 | 43.0 | 36.1 |
| TAD-RoPE (Gao et al., 2024) | 51.0 | 37.0 | 48.0 | 11.5 | 47.5 | 39.0 |
| M-RoPE (Wang et al., 2024b) | 39.0 | 29.0 | 43.5 | 12.5 | 47.5 | 34.3 |
| VideoRoPE | 57.0 | 58.5 | 50.5 | 15.0 | 50.0 | 46.2 |
🔼 This table presents a performance comparison of four different Rotary Position Embedding (RoPE) methods on the VideoHallucer benchmark. VideoHallucer is a video hallucination benchmark that evaluates the model’s ability to correctly answer questions about video content, including both basic and hallucinated questions. The comparison is done across four different context lengths (8k, 16k, 32k, and 64k tokens) to assess the models’ performance with varying amounts of contextual information. For each RoPE method, the table displays the maximum performance achieved across the four context lengths. The best performance is indicated in bold, and the second-best is underlined. The table also breaks down the results by five sub-categories of the VideoHallucer benchmark: Object-Relation (OR), Temporal (T), Semantic Detail (SD), Factual (F), and Non-Factual (NF), giving a more granular view of each method’s strengths and weaknesses.
read the caption
Table 4: Performance comparison of different RoPEs on VideoHallucer, evaluated at context lengths of 8k, 16k, 32k, and 64k. The maximum result for each RoPE variant across these context lengths is displayed, with bold for the top result and underlined for the second-highest. ‘OR’ = Object-Relation, ‘T’ = Temporal, ‘SD’ = Semantic Detail, ‘F’ = Factual, ‘NF’ = Non-factual.
| Method | LongVideoBench | MLVU | ||||||
| 8k | 16k | 32k | 64k | 8k | 16k | 32k | 64k | |
| Baseline | 53.42 | 52.80 | 53.11 | 54.35 | 60.41 | 60.68 | 61.56 | 61.10 |
| + DL | 52.17 | 52.07 | 53.31 | 53.63 | 62.06 | 63.03 | 62.52 | 62.75 |
| + DL & LTA | 54.46 | 55.49 | 54.66 | 55.60 | 63.35 | 64.09 | 64.00 | 63.26 |
| + DL & LTA & ATS | 54.46 | 55.29 | 57.15 | 57.26 | 65.19 | 66.29 | 66.02 | 65.56 |
🔼 This table presents the results of an ablation study that investigates the impact of different components of the proposed VideoRoPE model on its performance. It systematically evaluates the contribution of the Diagonal Layout (DL), Low-frequency Temporal Allocation (LTA), and Adjustable Temporal Spacing (ATS) modules. The study assesses performance on two key benchmarks: Long VideoBench and MLVU, using various context lengths (8k, 16k, 32k, and 64k) to understand the impact of context window size.
read the caption
Table 5: Ablation study about different modules of VideoRoPE.
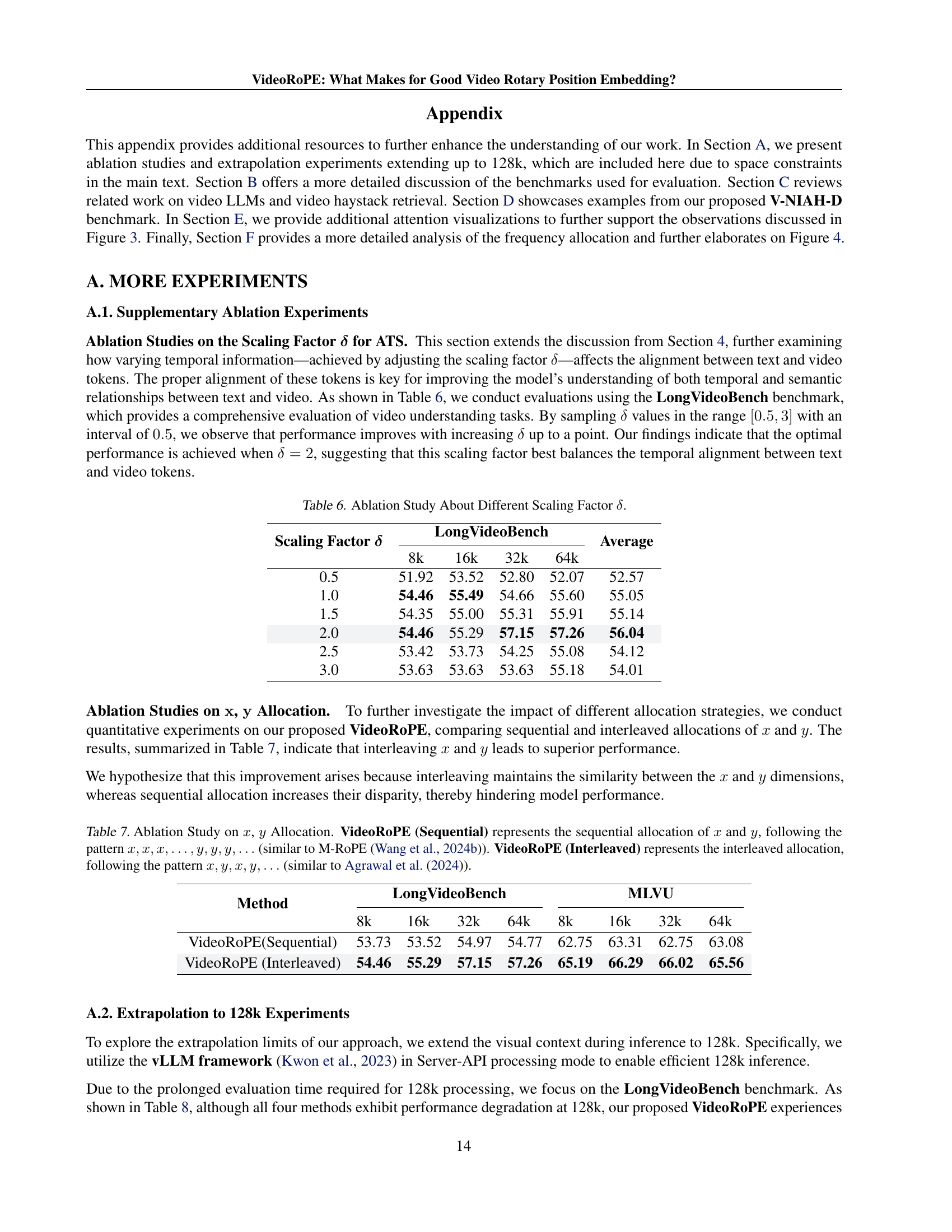
| Scaling Factor | LongVideoBench | Average | |||
| 8k | 16k | 32k | 64k | ||
| 0.5 | 51.92 | 53.52 | 52.80 | 52.07 | 52.57 |
| 1.0 | 54.46 | 55.49 | 54.66 | 55.60 | 55.05 |
| 1.5 | 54.35 | 55.00 | 55.31 | 55.91 | 55.14 |
| 2.0 | 54.46 | 55.29 | 57.15 | 57.26 | 56.04 |
| 2.5 | 53.42 | 53.73 | 54.25 | 55.08 | 54.12 |
| 3.0 | 53.63 | 53.63 | 53.63 | 55.18 | 54.01 |
🔼 This table presents the results of an ablation study investigating the impact of different scaling factors (δ) on the performance of the VideoRoPE model. The study focuses on the LongVideoBench benchmark, evaluating performance across four different context lengths (8k, 16k, 32k, 64k) for each scaling factor tested. The average performance across all context lengths is also reported. The purpose is to determine the optimal scaling factor that best balances the temporal alignment between text and video tokens, thereby maximizing the model’s ability to understand long videos.
read the caption
Table 6: Ablation Study About Different Scaling Factor δ𝛿\deltaitalic_δ.
| Method | LongVideoBench | MLVU | ||||||
| 8k | 16k | 32k | 64k | 8k | 16k | 32k | 64k | |
| VideoRoPE(Sequential) | 53.73 | 53.52 | 54.97 | 54.77 | 62.75 | 63.31 | 62.75 | 63.08 |
| VideoRoPE (Interleaved) | 54.46 | 55.29 | 57.15 | 57.26 | 65.19 | 66.29 | 66.02 | 65.56 |
🔼 This table presents an ablation study comparing two different strategies for allocating the horizontal (x) and vertical (y) dimensions in the VideoRoPE positional encoding scheme. The ‘Sequential’ allocation method assigns all x dimensions consecutively followed by all y dimensions, mirroring the approach used in M-ROPE (Wang et al., 2024b). In contrast, the ‘Interleaved’ method alternates between x and y dimensions, which is similar to the approach used in Agrawal et al. (2024). The table shows the performance of both methods on the Long VideoBench and MLVU benchmarks using 8k, 16k, 32k, and 64k context lengths to evaluate the impact of the different allocation strategies on model performance.
read the caption
Table 7: Ablation Study on x𝑥xitalic_x, y𝑦yitalic_y Allocation. VideoRoPE (Sequential) represents the sequential allocation of x𝑥xitalic_x and y𝑦yitalic_y, following the pattern x,x,x,…,y,y,y,…𝑥𝑥𝑥…𝑦𝑦𝑦…x,x,x,\dots,y,y,y,\dotsitalic_x , italic_x , italic_x , … , italic_y , italic_y , italic_y , … (similar to M-RoPE (Wang et al., 2024b)). VideoRoPE (Interleaved) represents the interleaved allocation, following the pattern x,y,x,y,…𝑥𝑦𝑥𝑦…x,y,x,y,\dotsitalic_x , italic_y , italic_x , italic_y , … (similar to Agrawal et al. (2024)).
| Method | LongVideoBench | |
| 64k | 128k | |
| Vanilla RoPE (Su et al., 2024) | 54.04 | 48.01 |
| TAD-RoPE (Gao et al., 2024) | 53.42 | 45.77 |
| M-RoPE (Wang et al., 2024b) | 54.35 | 51.45 |
| VideoRoPE | 57.26 | 55.64 |
🔼 This table presents a comparison of the performance of four different video rotary position embedding (RoPE) methods—Vanilla RoPE, TAD-ROPE, M-ROPE, and VideoRoPE—when evaluated on the LongVideoBench benchmark dataset. The comparison is made using two different context lengths: 64k and 128k tokens, allowing for an assessment of how each method scales to extremely long sequences. The results showcase the accuracy (as measured by the LongVideoBench metric) obtained by each method at both context lengths, enabling an analysis of their relative performance and robustness when processing very long video sequences.
read the caption
Table 8: Comparison of model performance at 64k and 128k context lengths for different methods.
Full paper#