TL;DR#
Existing methods for three-dimensional scene inpainting struggle with maintaining view consistency and geometric accuracy, especially in 360° unbounded scenes. This is a significant challenge for applications like virtual and augmented reality, where realistic scene manipulation is crucial. These issues stem from the difficulties in accurately identifying and filling unseen regions in 3D scenes represented by multiple views. Inconsistent depth estimation and difficulties in handling large viewpoint changes also hinder performance.
The paper introduces AuraFusion360, a novel reference-based method that leverages Gaussian Splatting for efficient 3D scene representation. Key innovations include depth-aware unseen mask generation for accurate occlusion identification, Adaptive Guided Depth Diffusion (AGDD) for structured initial point placement, and SDEdit-based detail enhancement for multi-view coherence. The proposed method significantly outperforms existing techniques in both perceptual quality and geometric accuracy, even with dramatic viewpoint changes. Furthermore, it introduces 360-USID, a new dataset for 360° unbounded scene inpainting, providing a valuable benchmark for future research.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the challenging problem of 360° unbounded scene inpainting, a crucial task in various applications like VR/AR and robotics. It introduces a novel method (AuraFusion360) that significantly outperforms existing techniques, achieving higher perceptual quality and geometric accuracy. Further, the introduction of the 360-USID dataset provides a valuable benchmark for future research in this area, opening avenues for improved algorithms and evaluation metrics. This research directly contributes to the advancement of 3D scene manipulation techniques.
Visual Insights#

🔼 AuraFusion360 takes input images, camera parameters, object masks, and a reference image. It uses these to create an object-masked Gaussian Splatting representation of the scene. This representation allows the system to generate novel views of the scene with the masked objects removed, while maintaining consistency with the reference image. The figure visually depicts this process, showing the input data, the intermediate Gaussian splatting representation, and the final inpainted novel views.
read the caption
Figure 1: Overview of our reference-based 360° unbounded scene inpainting method. Given input images with camera parameters, object masks, and a reference image, our AuraFusion360 approach generates an object-masked Gaussian Splatting representation. This representation can then render novel views of the inpainted scene, effectively removing the masked objects while maintaining consistency with the reference image.
| PSNR / LPIPS | Carton | Cone | Cookie | Newcone | Plant | Skateboard | Sunflower | Average |
|---|---|---|---|---|---|---|---|---|
| SPIn-NeRF [34] | 16.659 / 0.539 | 15.438 / 0.389 | 11.879 / 0.521 | 17.131 / 0.519 | 16.850 / 0.401 | 15.645 / 0.675 | 23.538 / 0.206 | 16.734 / 0.464 |
| 2DGS [18] + LaMa [53] | 16.433 / 0.499 | 15.591 / 0.351 | 11.711 / 0.538 | 16.598 / 0.670 | 14.491 / 0.564 | 15.520 / 0.639 | 23.024 / 0.194 | 16.195 / 0.494 |
| 2DGS [18] + LeftRefill [6] | 15.157 / 0.567 | 16.143 / 0.372 | 12.458 / 0.526 | 16.717 / 0.677 | 12.856 / 0.666 | 16.429 / 0.634 | 24.216 / 0.181 | 16.282 / 0.518 |
| LeftRefill [6] | 14.667 / 0.560 | 14.933 / 0.380 | 11.148 / 0.519 | 16.264 / 0.448 | 16.183 / 0.463 | 14.912 / 0.572 | 18.851 / 0.331 | 15.280 / 0.468 |
| Gaussian Grouping [65] | 16.695 / 0.502 | 14.549 / 0.366 | 11.564 / 0.731 | 16.745 / 0.533 | 16.175 / 0.440 | 16.002 / 0.577 | 20.787 / 0.209 | 16.074 / 0.480 |
| GScream [60] | 14.609 / 0.587 | 14.655 / 0.476 | 12.733 / 0.429 | 13.662 / 0.605 | 16.238 / 0.437 | 12.941 / 0.626 | 18.470 / 0.436 | 14.758 / 0.514 |
| Infusion [27] | 14.191 / 0.555 | 14.163 / 0.439 | 12.051 / 0.486 | 9.562 / 0.624 | 16.127 / 0.406 | 13.624 / 0.638 | 21.195 / 0.238 | 14.416 / 0.484 |
| AuraFusion360 (Ours) w/o SDEdit | 13.731 / 0.477 | 14.260 / 0.390 | 12.332 / 0.445 | 16.646 / 0.460 | 17.609 / 0.319 | 15.107 / 0.580 | 24.884 / 0.170 | 16.367 / 0.406 |
| AuraFusion360 (Ours) | 17.675 / 0.473 | 15.626 / 0.332 | 12.841 / 0.434 | 17.536 / 0.426 | 18.001 / 0.322 | 17.007 / 0.559 | 24.943 / 0.173 | 17.661 / 0.388 |
🔼 This table presents a quantitative comparison of different 360° inpainting methods using the 360-USID dataset. The comparison is based on two metrics: PSNR (Peak Signal-to-Noise Ratio), measuring the accuracy of the reconstruction, and LPIPS (Learned Perceptual Image Patch Similarity), evaluating the perceptual quality of the results. The table shows the scores for each method across seven different scenes within the dataset. The best-performing method for each scene and metric is highlighted in red, while the second-best is shown in blue. This allows for a direct comparison of the performance of various methods under similar conditions.
read the caption
Table 1: Quantitative comparison of 360° inpainting methods on the 360-USID dataset. Red text indicates the best, and blue text indicates the second-best performing method.
In-depth insights#
360° Inpainting#
360° inpainting presents unique challenges compared to traditional image inpainting due to its inherent complexity. View consistency is paramount; any inpainting solution must seamlessly blend across multiple perspectives, avoiding jarring discontinuities. Geometric accuracy is another key factor, as the inpainted regions must maintain consistent spatial relationships with the surrounding scene to preserve realism. Handling unseen regions, areas occluded in all input views, requires sophisticated techniques capable of plausible reconstruction. Existing methods often struggle with these aspects, especially in unbounded scenes, highlighting a need for innovative approaches that leverage multi-view information effectively. Reference-based methods show promise, but often suffer from limitations in viewpoint variation and overall consistency. Data scarcity also poses a major hurdle, emphasizing the importance of creating high-quality 360° datasets with ground truth for rigorous evaluation. Successful 360° inpainting solutions will likely involve robust depth estimation and geometry-aware generative models that integrate semantic information effectively to maintain consistent 3D structure across multiple viewpoints.
Depth-Aware Masks#
The concept of ‘Depth-Aware Masks’ in the context of 360° unbounded scene inpainting is crucial for accurately identifying regions requiring inpainting. A naive approach might simply use existing object masks; however, depth information adds a critical layer of understanding. By analyzing depth disparities, a depth-aware method can distinguish between areas genuinely occluded (unseen regions) and those merely hidden behind objects in specific views. This is vital for maintaining consistency across multiple viewpoints, avoiding the hallucination of content where it’s impossible to infer visually from the available data. Such depth-aware techniques are essential for avoiding artifacts and producing visually plausible results that successfully integrate the newly generated information with the existing scene’s geometry, especially in challenging 360° scenes where viewpoint changes dramatically impact what’s visible. The success of the approach relies heavily on accurate and reliable depth maps, which could be improved with advanced algorithms or further refined by incorporating additional sensory inputs.
AGDD Diffusion#
The Adaptive Guided Depth Diffusion (AGDD) method is a novel approach for aligning depth maps in 360° unbounded scenes, a crucial step for high-quality 3D inpainting. Traditional depth estimation methods struggle with scale ambiguity and inconsistencies in 360° views. AGDD addresses this by iteratively refining depth estimates, using a VAE decoder and an adaptive loss function that compares the estimated depth to the existing incomplete depth. This ensures that the final depth map aligns well with the existing structure, providing a robust foundation for subsequent Gaussian splatting initialization. The use of a bounding box and thresholding in the loss function further improves efficiency and accuracy, enabling zero-shot application without requiring additional training. The method’s effectiveness is demonstrated by its superior performance compared to other depth completion techniques in aligning depth across viewpoints, leading to improved consistency and accuracy in the final inpainted scene.
SDEdit Enhancement#
The section on “SDEdit Enhancement” within the research paper likely details how the authors leverage Stable Diffusion’s editing capabilities (SDEdit) to refine the quality of their 360° scene inpainting. This likely involves using SDEdit’s denoising process, possibly conditioned on the reference image or other relevant contextual information, to iteratively improve the generated details and ensure visual consistency across multiple viewpoints. The technique might address potential artifacts or inconsistencies introduced during the initial inpainting stage, achieving a higher level of realism and coherence in the final output. A key aspect might involve intelligently managing the noise injection process within SDEdit, perhaps by using a depth-aware mechanism or other techniques to selectively guide the refinement process. This would focus the enhancements to critical areas requiring attention and prevent unwanted alterations in well-rendered parts. The effectiveness of this enhancement is likely evaluated through perceptual metrics, comparing its impact on visual fidelity, geometric accuracy and multi-view consistency relative to baselines and other competing methods. The authors probably discuss its crucial role in seamlessly merging newly generated regions with the pre-existing scene elements, resulting in a highly cohesive and visually appealing 360° inpainted scene.
Future of 360°#
The future of 360° imaging and processing hinges on addressing current limitations. Real-time performance remains a challenge, especially for high-resolution scenes and complex manipulations. Further advancements in depth estimation are crucial for accurate and robust unseen region identification, particularly in dynamic environments. Integrating AI-driven techniques, such as improved object tracking and semantic understanding, will enhance scene consistency and enable more precise object removal and inpainting. The development of larger, more diverse datasets is vital for training robust and generalizable models. Finally, exploring novel representations beyond Gaussian Splatting could lead to improved efficiency and accuracy, potentially unlocking the creation of truly interactive and immersive 360° experiences. Research into more computationally efficient algorithms and hardware acceleration is essential for achieving real-time capabilities.
More visual insights#
More on figures

🔼 Figure 2 compares AuraFusion360 to other 3D inpainting methods on 360° unbounded scenes. It shows that previous methods like SPIn-NeRF and GScream, designed for forward-facing scenes, perform poorly on 360° scenes. Reference-based methods like Infusion struggle with accurate reference view projection, leading to artifacts. Gaussian Grouping often misidentifies unseen regions, impacting quality. AuraFusion360, however, achieves better unseen mask generation and depth alignment using Adaptive Guided Depth Diffusion and SDEdit, resulting in improved multi-view consistency.
read the caption
Figure 2: Comparison with different 3D inpainting approaches. Previous methods, such as SPin-NeRF [34] and GScream [60], are tailored for forward-facing scenes and tend to underperform in 360° unbounded scenarios. Reference-based methods, such as Infusion [27], whose depth completion model struggles to accurately project the reference view back into the 3D scene, leading to fine-tuning artifacts. Gaussian Grouping [65] often misidentifies the unseen region during mask generation, which can degrade inpainting quality. Our method, AuraFusion360, achieves a more accurate unseen mask and enhanced depth alignment through Adaptive Guided Depth Diffusion, with SDEdit [30] applied to the initial points to leverage diffusion prior while also maintaining multi-view consistency in RGB guidance.

🔼 This figure illustrates the AuraFusion360 method for 360° unbounded scene inpainting. The process begins with multi-view RGB images and their corresponding object masks. These inputs are processed through three main stages: 1. Depth-Aware Unseen Mask Generation: Identifies areas completely hidden from all viewpoints (the ‘unseen region’). 2. Depth-Aligned Gaussian Initialization on Reference View: Fills the unseen regions using a reference image. Depth information from the reference view is projected into the 3D scene to guide the generation of new Gaussian splatting points. These points inherit RGB values from the reference image ensuring consistency. 3. SDEdit-Based RGB Guidance for Detail Enhancement: Refines the generated image details using a diffusion model (SDEdit). Instead of random noise, DDIM inversion is used to retain the reference image’s structure, thereby enhancing visual quality and maintaining consistency across all views. The output is a Gaussian splatting representation where the masked objects have been seamlessly removed and replaced with realistic inpainting.
read the caption
Figure 3: Overview of our method. Our approach takes multi-view RGB images and corresponding object masks as input and outputs a Gaussian representation with the masked objects removed. The pipeline consists of three main stages: (a) Depth-Aware Unseen Masks Generation to identify truly occluded areas, referred to as the “unseen region”, (b) Depth-Aligned Gaussian Initialization on Reference View to fill unseen regions with initialized Gaussian containing reference RGB information after object removal, and (c) SDEdit-Based RGB Guidance for Detail Enhancement, which enhances fine details using an inpainting model while preserving reference view information. Instead of applying SDEdit with random noise, we use DDIM Inversion on the rendered initial Gaussians to generate noise that retains the structure of the reference view, ensuring multi-view consistency across all RGB Guidance.

🔼 This figure details the process of generating an unseen mask for a given view (n) in a 360° scene. It leverages depth warping to accurately identify occluded regions. First, pixel correspondences are computed between view n and all other views (i) using the incomplete depth map of view n. Then, removal regions from each view i are warped back to view n to align occlusions. These warped regions are aggregated, and a threshold is applied to produce a contour representing the unseen mask in view n. Finally, this contour is converted into a bounding box prompt for the SAM2 model which further refines the unseen mask.
read the caption
Figure 4: Overview of the Unseen Mask Generation Process using Depth Warping. To obtain the unseen mask for view n𝑛nitalic_n, we calculate the pixel correspondences between the view n𝑛nitalic_n and all other views i𝑖iitalic_i by using the rendered incomplete depth Dnincompletesuperscriptsubscript𝐷𝑛incompleteD_{n}^{\text{incomplete}}italic_D start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT start_POSTSUPERSCRIPT incomplete end_POSTSUPERSCRIPT. For each view i𝑖iitalic_i, the removal region Risubscript𝑅𝑖R_{i}italic_R start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT is backward traversal to view n𝑛nitalic_n to align occlusions. We then aggregate the results from multiple views, averaging and applying a threshold to produce the initial contour of the unseen mask. This contour is subsequently converted into a bounding box prompt for SAM2 [44], which refines the unseen mask to its final version for view n𝑛nitalic_n.

🔼 Adaptive Guided Depth Diffusion (AGDD) is an algorithm used to align estimated depth with existing depth, especially challenging in 360° unbounded scenes due to scale ambiguity and coordinate system differences. AGDD uses a latent representation perturbed by full-strength Gaussian noise. It iteratively updates the noise via an adaptive loss function comparing the pre-decoded estimated depth to the incomplete depth, ensuring alignment. A guided region (determined by dilating and subtracting the unseen mask) focuses the alignment process. This iterative refinement generates aligned depth that matches the incomplete depth distribution within the guided region, improving depth estimation in 360° unbounded scene inpainting.
read the caption
Figure 5: Overview of Adaptive Guided Depth Diffusion (AGDD). The framework takes image latent, incomplete depth, and unseen mask as inputs to generate aligned depth estimates. (a) The guided region is identified by dilating the unseen mask and subtracting the original mask. (b) At each denoising timestep t𝑡titalic_t, an adaptive loss ℒadaptivesubscriptℒadaptive\mathcal{L}_{\text{adaptive}}caligraphic_L start_POSTSUBSCRIPT adaptive end_POSTSUBSCRIPT is computed between the pre-decoded and incomplete depth to update the noise input ϵ^tsubscript^italic-ϵ𝑡\hat{\epsilon}_{t}over^ start_ARG italic_ϵ end_ARG start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT. This process repeats N𝑁Nitalic_N times before advancing to the next denoising step, ensuring the estimated depth aligns with the incomplete depth distribution in the guided region.
🔼 Figure 6 presents the 360-USID dataset, a collection of seven diverse 360° scenes designed for evaluating 3D inpainting methods. The dataset includes both indoor (Cookie, Sunflower) and outdoor (Carton, Cone, Newcone, Skateboard, Plant) environments. The figure shows example images from each scene. The table to the bottom right provides detailed statistics, including the number of training views used to create each scene and the number of ground truth novel views that were captured for testing purposes.
read the caption
Figure 6: Overview of the 360-USID dataset. Sample images from each scene, including five outdoor scenes (Carton, Cone, Newcone, Skateboard, Plant) and two indoor scenes (Cookie, Sunflower). (Bottom right) The table shows statistics for each scene, including the number of training views and ground truth (GT) novel views. The dataset provides a diverse range of environments for evaluating 3D inpainting methods in both indoor and outdoor settings.

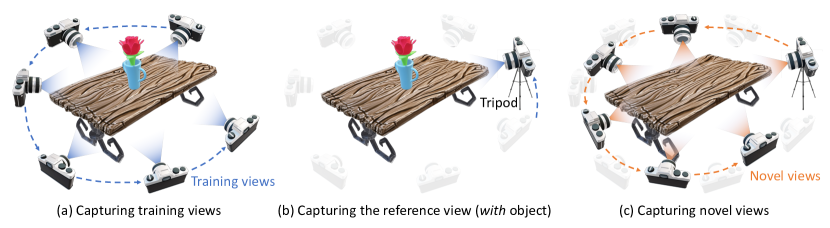
🔼 This figure illustrates the three steps involved in creating the 360-USID dataset. First, multiple images of the scene are taken with an object present, capturing the object from various angles (a). Next, a fixed reference image is taken from a single viewpoint using a tripod (b). This reference image includes the object. Finally, the object is removed, and more images are captured from various positions, including one from the same tripod position used for the reference image, to create the ’novel views’ used for testing (c).
read the caption
Figure 7: Illustration of the data capture process for the 360-USID dataset. (a) Capturing training views: Multiple images are taken around the object in the scene. (b) Capturing the reference view: A camera is mounted on a tripod to capture a fixed reference view (with an object). (c) Capturing novel views: After removing the object, additional images are taken from various viewpoints, including one from the same tripod position as the reference image.

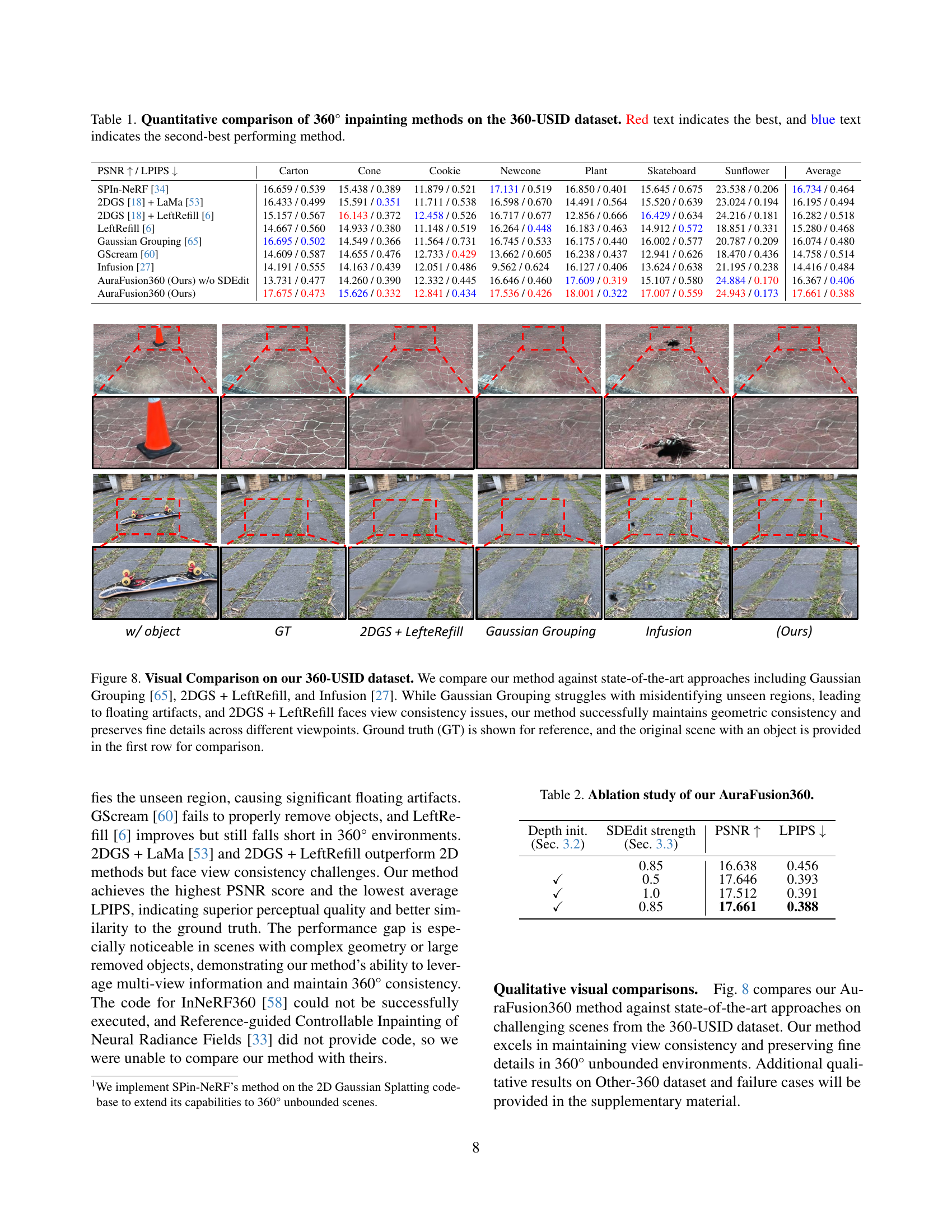
🔼 Figure 8 presents a visual comparison of different 3D scene inpainting methods on the 360-USID dataset. The figure highlights the performance of AuraFusion360 against three state-of-the-art techniques: Gaussian Grouping, 2DGS + LeftRefill, and Infusion. Each column represents a different method, showing results across several viewpoints of a scene. The top row displays the original scene with the object present. The second row shows the ground truth after object removal. Subsequent rows illustrate the results of each inpainting method, revealing differences in how well they handle unseen region identification, view consistency, geometric accuracy, and detail preservation. Gaussian Grouping struggles with identifying unseen regions correctly, leading to artifacts and inconsistencies. 2DGS + LeftRefill exhibits inconsistencies across viewpoints. In contrast, AuraFusion360 demonstrates superior performance in maintaining geometric accuracy, preserving fine details, and ensuring consistent results across multiple viewpoints.
read the caption
Figure 8: Visual Comparison on our 360-USID dataset. We compare our method against state-of-the-art approaches including Gaussian Grouping [65], 2DGS + LeftRefill, and Infusion [27]. While Gaussian Grouping struggles with misidentifying unseen regions, leading to floating artifacts, and 2DGS + LeftRefill faces view consistency issues, our method successfully maintains geometric consistency and preserves fine details across different viewpoints. Ground truth (GT) is shown for reference, and the original scene with an object is provided in the first row for comparison.

🔼 Figure 9 compares the performance of different unseen mask generation methods. The standard SAM2 method often requires manual prompts to accurately identify the unseen regions, which is time-consuming and prone to errors. In contrast, the proposed depth-aware method automatically generates bounding box prompts by utilizing depth information across multiple views. This automated approach significantly improves the accuracy of unseen mask generation, leading to more precise and consistent inpainting results, as demonstrated by the visual comparison in the figure.
read the caption
Figure 9: Visual comparison of unseen mask generation method. Our method enables SAM2 [44] to generate more accurate predictions for each view without the need for manually provided prompts, as the bounding box prompts are automatically generated through depth warping.

🔼 Figure 10 compares the unseen mask generation methods of the proposed AuraFusion360 approach and the Gaussian Grouping method [65]. Gaussian Grouping relies on a video tracker [9] and a textual prompt (‘black blurry hole’) to identify the unseen regions needing inpainting. This method is prone to tracking errors that can negatively impact the inpainting results. Conversely, AuraFusion360 utilizes a geometry-based approach with depth warping to more accurately estimate the unseen region’s contour, thereby reducing segmentation errors and leading to improved inpainting accuracy.
read the caption
Figure 10: Compared Unseen Mask w/ Gaussian Grouping. Gaussian Grouping [65] uses a video tracker [9] and the “black blurry hole” prompt for the DEVA [9] method to track the unseen region. However, this can result in tracking errors, affecting inpainting. In contrast, our geometry-based approach uses depth warping to estimate the unseen region’s contour, reducing segmentation errors.

🔼 Figure 11 compares the performance of different depth completion methods, including traditional methods and Guided Depth Diffusion [68], with the proposed Adaptive Guided Depth Diffusion (AGDD). The results show that while Infusion [27] offers better depth alignment than traditional methods, it struggles with generalization to unseen data. Similarly, Guided Depth Diffusion suffers from imprecise alignment due to background noise affecting loss calculations. AGDD overcomes these limitations, achieving superior depth alignment.
read the caption
Figure 11: Compared to other depth completion methods. The depth completion model in Infusion [27] (a) performs better at depth alignment compared to traditional methods (b) and (c), but it lacks generalization. Similarly, (d) Guided Depth Diffusion [68] struggles to achieve precise alignment, as the background regions amplify the loss, leading to misalignment. In contrast, (e) Our AGDD effectively addresses these issues.

🔼 Figure 12 illustrates the intermediate steps of depth warping used to identify unseen regions for 360° scene inpainting. It starts with an RGB image (a) and its corresponding removal region (b) at a specific view (n). Then, it shows removal regions (c) from other views (i) which are warped back to view n (d), highlighting intersections that indicate unseen regions. Areas with zero values within the unseen regions are due to missing Gaussians, preventing depth calculation and correspondence establishment. All warped unseen regions are aggregated (e), thresholded, and intersected with the original removal region at view n (f), resulting in the final unseen region mask.
read the caption
Figure 12: Intermediate Results of Depth Warping for Unseen Region Detection. This figure illustrates the intermediate results generated during the depth warping process. (a) and (b) show the RGB image and the corresponding removal region at view n𝑛nitalic_n, respectively. (c) displays the removal regions obtained from view i𝑖iitalic_i (i≠n𝑖𝑛i\neq nitalic_i ≠ italic_n). (d) shows the unseen region obtained from view i𝑖iitalic_i through backward traversal. The intersections are concentrated near the unseen region. Note that the pixels within the unseen region, but with a value of zero, are due to the absence of Gaussians in that area, preventing depth rendering and thus making it impossible to establish pixel correspondences between view n𝑛nitalic_n and view i𝑖iitalic_i. (e) presents the aggregation of all unseen regions obtained from view i𝑖iitalic_i at view n𝑛nitalic_n. A threshold is applied to this result, and it is then intersected with the removal region at view n𝑛nitalic_n to obtain the final result in (f).

🔼 This ablation study compares two methods for defining removal regions in 360° scene inpainting: using object masks and using depth differences. The results show that object masks, while simple, fail to accurately capture geometric changes in the scene, leading to inaccurate identification of unseen regions. Consequently, the subsequent inpainting step, using SAM2, is less effective. In contrast, using depth differences to define removal regions better preserves the scene’s overall structure. This leads to more accurate prompts for SAM2 and, ultimately, improved unseen region segmentation and overall better inpainting results.
read the caption
Figure 13: Ablation Study on Removal Region Definition. Comparison of (a) object masks vs. (b) depth difference for defining removal regions. Object masks fail to capture geometric changes, leading to less accurate unseen masks. Depth difference better preserves scene structure, improving SAM2 prompts and unseen region segmentation.

🔼 This figure showcases examples where several state-of-the-art 3D inpainting methods fail to produce satisfactory results. The failures stem from significant occlusions near the inpainting regions, leading to difficulties in achieving good inpainted RGB images (b, c) and errors from incorrect pixel unprojections (d, e). This demonstrates a common challenge in 3D inpainting not yet fully solved by existing techniques, indicating a need for further research in this area.
read the caption
Figure 14: Failure Cases. The figure illustrates failure cases of inpainting results. These examples highlight the challenges of 3D inpainting when significant occlusions are present near the regions requiring inpainting. For instance, (b) and (c) demonstrate difficulties in achieving satisfactory guided inpainted RGB images in the training views, while (d) and (e) show errors resulting from incorrect pixel unprojections. These observations indicate that this issue is not effectively addressed by any of the compared methods, suggesting a potential avenue for further exploration and improvement.

🔼 This figure shows a qualitative comparison of different 360° unbounded scene inpainting methods on the 360-USID dataset. It compares the ground truth results with the results produced by several state-of-the-art methods such as 2DGS+LeftRefill, Gaussian Grouping, Infusion, and the proposed AuraFusion360 method. Each row represents a different scene, showing the original scene with the object, the ground truth after object removal, and the results from each inpainting method. This visual comparison highlights the strengths and weaknesses of each approach in terms of view consistency, geometric accuracy, and overall perceptual quality.
read the caption
Figure 15: Visual Comparison on our 360-USID dataset.
Full paper#