TL;DR#
Large Language Models (LLMs) are becoming increasingly complex, and training them requires significant computational resources. Recent studies have observed that many of the layers in these models are less effective than expected, leading to wasted resources. This phenomenon is often referred to as the ‘Curse of Depth’. This research paper delves into this problem, investigating the reason behind the ineffectiveness of deep layers. The researchers find that this is largely due to a common technique called Pre-Layer Normalization (Pre-LN), which causes the output variance of the deeper layers to grow exponentially during training, ultimately hindering their contribution.
To address this issue, the authors propose a novel technique called LayerNorm Scaling. This simple method scales the output variance of each layer inversely proportional to the square root of its depth. By doing so, it effectively prevents the exponential variance growth and improves the performance of deeper layers. The researchers conducted extensive experiments, demonstrating that LayerNorm Scaling not only improves the training efficiency of LLMs but also enhances their performance on various downstream tasks. This shows that the method is not just a theoretical improvement but a practical solution for improving large language model training.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses a critical inefficiency in large language models (LLMs). By identifying the root cause of the underperformance of deep layers and proposing a simple yet effective solution (LayerNorm Scaling), this research directly impacts the cost-effectiveness and efficiency of LLM training. It also opens new avenues for research into LLM architecture and optimization techniques, paving the way for more powerful and resource-efficient LLMs.
Visual Insights#

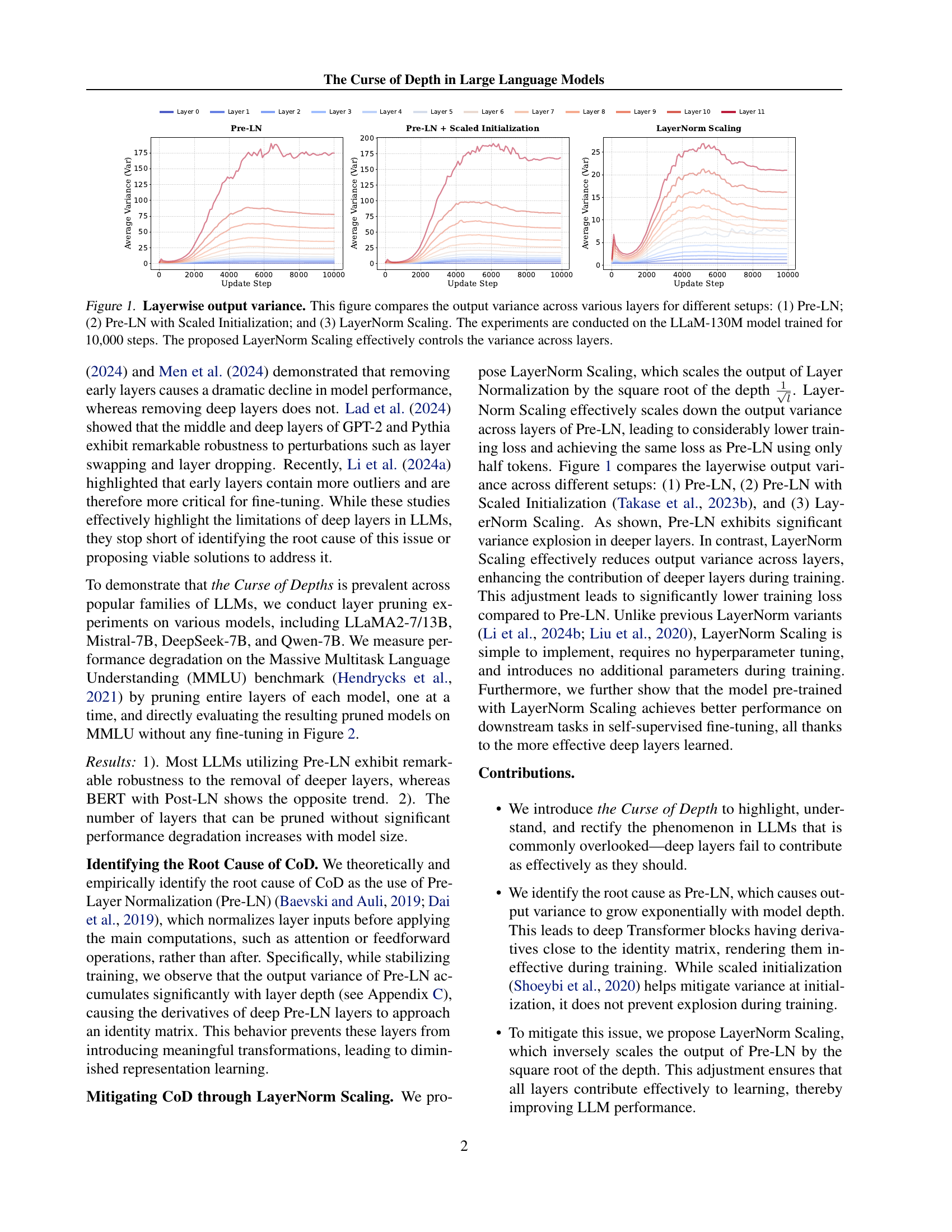
🔼 This figure shows the output variance of different layers in a 130M parameter LLaMA model under three different normalization methods: Pre-Layer Normalization (Pre-LN), Pre-LN with Scaled Initialization, and LayerNorm Scaling. The x-axis represents the update steps during training (up to 10,000 steps), and the y-axis represents the average output variance across layers. The plot visually demonstrates that Pre-LN leads to a significant increase in output variance as the layer depth increases, while LayerNorm Scaling effectively mitigates this issue, maintaining relatively stable variance across all layers.
read the caption
Figure 1: Layerwise output variance. This figure compares the output variance across various layers for different setups: (1) Pre-LN; (2) Pre-LN with Scaled Initialization; and (3) LayerNorm Scaling. The experiments are conducted on the LLaM-130M model trained for 10,000 steps. The proposed LayerNorm Scaling effectively controls the variance across layers.
| LLaMA-130M | LLaMA-250M | LLaMA-350M | LLaMA-1B | |
|---|---|---|---|---|
| Training Tokens | 2.2B | 3.9B | 6.0B | 8.9B |
| Post-LN (Ba, 2016) | 26.95 | 1409.79 | 1368.33 | 1390.75 |
| DeepNorm (Wang et al., 2024) | 27.17 | 22.77 | 1362.59 | 1409.08 |
| Mix-LN (Li et al., 2024b) | 26.07 | 21.39 | 1363.21 | 1414.78 |
| Pre-LN (Baevski and Auli, 2019) | 26.73 | 21.92 | 19.58 | 17.02 |
| Pre-LN + LayerNorm Scaling | 25.76 | 20.35 | 18.20 | 15.71 |
🔼 This table presents a comparison of perplexity scores achieved by different layer normalization methods across various sizes of LLaMA language models. Perplexity is a metric indicating how well a model predicts a sample, with lower scores signifying better performance. The table allows for a quantitative assessment of the effectiveness of different normalization techniques (Post-LN, DeepNorm, Mix-LN, Pre-LN, and Pre-LN with LayerNorm Scaling) in training LLMs of varying scale (130M, 250M, 350M, and 1B parameters). The results highlight the impact of the chosen normalization method on the overall model performance and training efficiency.
read the caption
Table 1: Perplexity (↓) comparison of various layer normalization methods across various LLaMA sizes.
In-depth insights#
Depth’s Curse Unveiled#
The heading “Depth’s Curse Unveiled” aptly captures a critical finding regarding the underperformance of deeper layers in large language models (LLMs). The core issue is the unexpected ineffectiveness of many layers despite the substantial computational cost of training them. This phenomenon, often overlooked, represents a significant inefficiency. The research likely explores the reasons behind this, potentially linking it to specific architectural choices or training dynamics. Unveiling this “curse” likely involves identifying the root cause, whether it is a limitation in the model architecture or a consequence of the optimization process itself. Addressing this would involve proposing and evaluating solutions that mitigate the problem, potentially leading to more efficient and effective LLMs with similar performance but using fewer layers and less computational resources. Practical implications include optimizing training processes and designing novel architectures to fully harness the potential of all model layers, making the training process more resource-efficient. The research’s contribution would thus be to highlight this overlooked problem, explain its origin, and offer solutions that improve LLM efficiency and performance, potentially changing the way LLMs are developed in the future.
Pre-LN’s Variance#
The analysis of Pre-LN’s variance is crucial to understanding the paper’s core argument. The authors demonstrate that the use of Pre-Layer Normalization (Pre-LN) in large language models (LLMs) leads to an exponential growth in output variance as depth increases. This is a key component of what the authors call the “Curse of Depth.” This variance explosion causes the derivatives of deeper layers to approach an identity matrix, rendering them ineffective for learning and contributing minimally to model performance. The theoretical analysis is supported by empirical evidence, showing that deeper layers are more robust to pruning and less influential on overall performance, indicating that they are not actively learning. The identification of this variance problem is essential for understanding why many deep layers in LLMs become ineffective. It directly motivates the need for the proposed LayerNorm Scaling solution, which directly addresses this variance growth and improves LLM efficiency.
LayerNorm Scaling#
The proposed LayerNorm Scaling method directly addresses the “Curse of Depth” in large language models (LLMs) by mitigating the issue of exponentially growing output variance in deeper layers when using pre-Layer Normalization (Pre-LN). Pre-LN, while stabilizing training, leads to derivatives approaching an identity matrix in deeper layers, hindering their contribution to learning. LayerNorm Scaling cleverly scales the output variance inversely proportional to the square root of the layer’s depth, thus preventing the variance explosion and enabling deeper layers to participate more effectively in the training process. This simple yet elegant solution doesn’t introduce additional parameters or require hyperparameter tuning, making it easily implementable in existing LLM architectures. Empirical results demonstrate significant improvements in pre-training and fine-tuning performance across various model sizes, showcasing the effectiveness of LayerNorm Scaling in enhancing LLM training efficiency and overall performance. The theoretical analysis provides a solid foundation for understanding why the method works and its limitations. By effectively utilizing deeper layers, LayerNorm Scaling promises more efficient resource usage during LLM training.
Empirical Evidence#
The section ‘Empirical Evidence’ would present concrete data demonstrating the phenomenon of the Curse of Depth. This would likely involve experiments showing that deeper layers in various LLMs are surprisingly robust to pruning or other perturbations, suggesting they aren’t contributing significantly to model learning. The data might include performance metrics on tasks like MMLU or SQUAD after systematically removing layers, revealing minimal performance degradation when removing deeper layers but significant drops when shallower ones are removed. This would strongly support the claim that deeper layers are less effective, providing compelling visual evidence (like graphs showing performance drop per layer) to back up the theoretical arguments of the paper. The evidence should also exhibit consistency across different LLM families (Llama, Mistral, etc.) to establish the generality of the phenomenon and rule out architecture-specific quirks.
Future of LLMs#
The future of LLMs hinges on addressing current limitations like the Curse of Depth, where deeper layers underperform. Solutions like LayerNorm Scaling offer promising avenues for improvement by mitigating variance explosion and enhancing the contribution of all layers. Further research into alternative normalization techniques and a deeper understanding of the interactions between layers are crucial. Efficient training methods are paramount given the resource intensity of LLM training, suggesting a move towards more efficient architectures and training paradigms. Additionally, the future of LLMs will involve exploring novel model architectures beyond the current Transformer-based dominance, potentially leveraging advancements in other fields such as graph neural networks or hybrid approaches. Successfully navigating these challenges will unlock the true potential of LLMs, enabling more powerful and resource-efficient models that serve a wider range of applications.
More visual insights#
More on figures

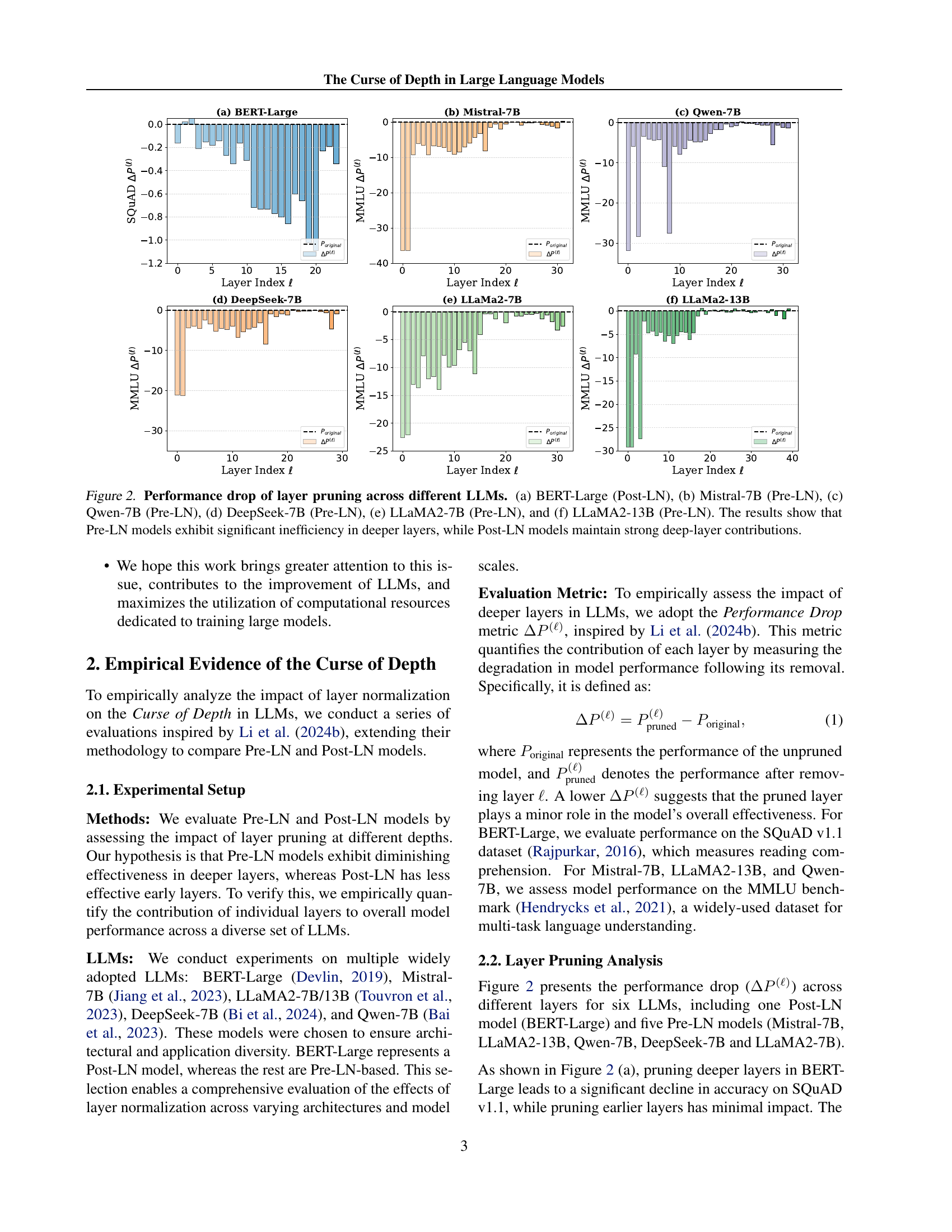
🔼 This figure displays the performance drop when layers are pruned from various large language models (LLMs). It compares six different LLMs: BERT-Large, which uses Post-Layer Normalization (Post-LN), and five others (Mistral-7B, Qwen-7B, DeepSeek-7B, LLaMA2-7B, and LLaMA2-13B) that use Pre-Layer Normalization (Pre-LN). The x-axis represents the layer index, and the y-axis shows the performance drop (ΔP(l)) in the MMLU or SQUAD benchmark when a layer is removed. The results illustrate that in Pre-LN models, removing deeper layers has minimal impact on overall performance, highlighting their inefficiency; whereas Post-LN models show a greater performance drop when deeper layers are removed.
read the caption
Figure 2: Performance drop of layer pruning across different LLMs. (a) BERT-Large (Post-LN), (b) Mistral-7B (Pre-LN), (c) Qwen-7B (Pre-LN), (d) DeepSeek-7B (Pre-LN), (e) LLaMA2-7B (Pre-LN), and (f) LLaMA2-13B (Pre-LN). The results show that Pre-LN models exhibit significant inefficiency in deeper layers, while Post-LN models maintain strong deep-layer contributions.

🔼 This figure illustrates the core difference between the Pre-Layer Normalization (Pre-LN) and the proposed LayerNorm Scaling methods. Panel (a) shows the architecture of a standard Transformer block using Pre-LN, where layer normalization is applied before the attention and feed-forward network operations. This can lead to an exponential increase in the output variance as the depth (layer index, ’l’) increases. Panel (b) depicts the LayerNorm Scaling method, which addresses this issue by introducing a scaling factor inversely proportional to the square root of the layer index (1/√l). This scaling effectively controls the variance, ensuring that deeper layers contribute more effectively to training and preventing the variance explosion problem associated with Pre-LN.
read the caption
Figure 3: Comparison between Pre-LN (a) and LayerNorm Scaling (b). LayerNorm Scaling applies a scaling factor inversely proportional to the square root of the layer index l𝑙litalic_l, preventing excessive variance growth and stabilizing training dynamics across layers.

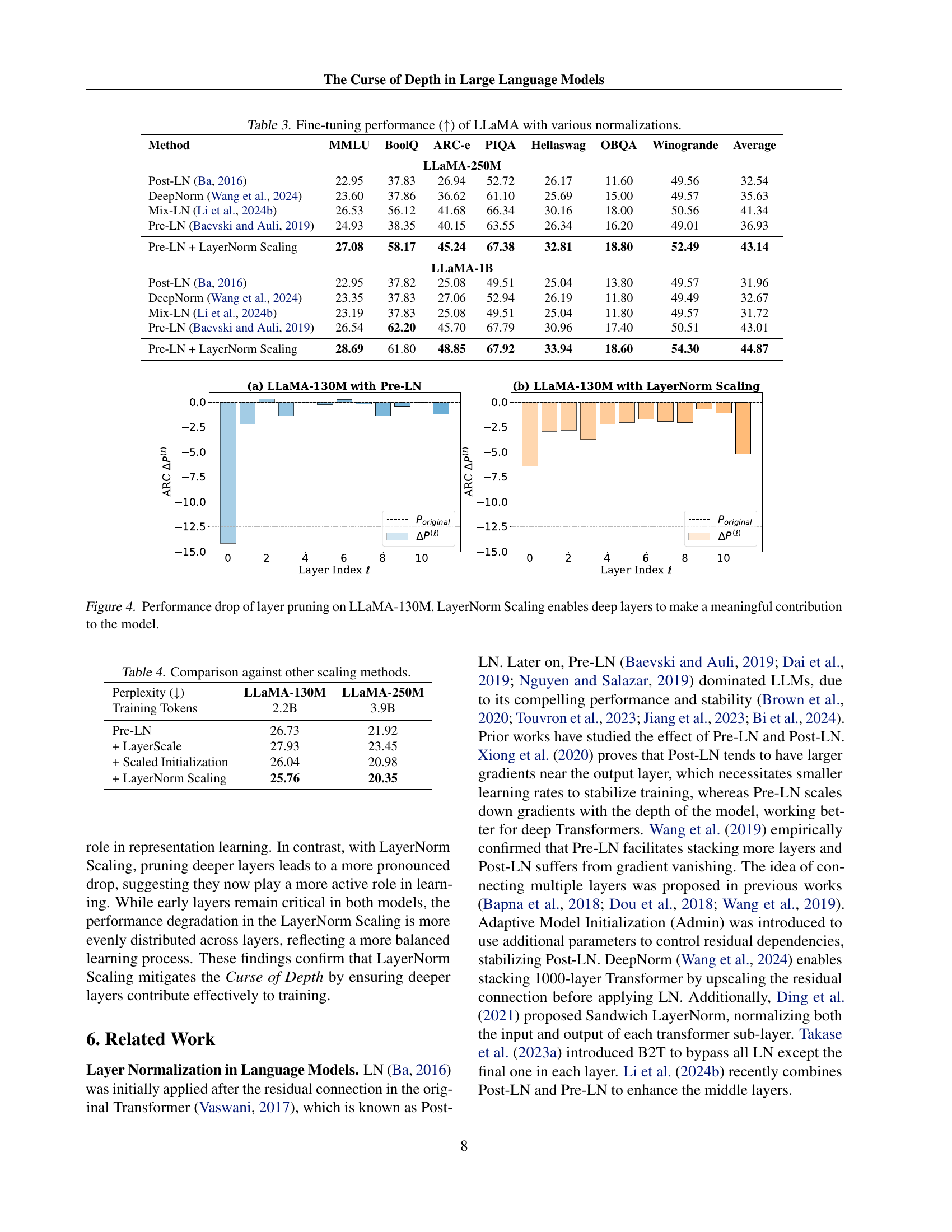
🔼 This figure shows the performance drop when pruning layers in the LLaMA-130M model, comparing the standard Pre-Layer Normalization (Pre-LN) with the proposed LayerNorm Scaling method. The Pre-LN model shows minimal performance degradation when deeper layers are pruned, indicating their limited contribution. In contrast, the LayerNorm Scaling model exhibits significant performance decrease upon pruning of deeper layers, suggesting their crucial role in learning and improved model performance. This demonstrates LayerNorm Scaling successfully mitigates the Curse of Depth and enables deeper layers to participate in the overall performance of the model.
read the caption
Figure 4: Performance drop of layer pruning on LLaMA-130M. LayerNorm Scaling enables deep layers to make a meaningful contribution to the model.

🔼 This figure displays the training loss curves for a 1B parameter LLaMA model using two different layer normalization techniques: Pre-Layer Normalization (Pre-LN) and the proposed LayerNorm Scaling. It visually compares the convergence speed and overall loss achieved by each method during the model’s training process. The graph allows for a direct comparison of the effectiveness of the two normalization strategies.
read the caption
Figure 5: Training loss of LLaMA-1B with Pre-LN and LayerNorm Scaling.

🔼 This figure visualizes the variance of layer outputs in a LLaMA-130M model trained with Pre-Layer Normalization (Pre-LN). Three subplots display the variance at different training epochs (1000, 3000, and 6000). The key observation is that variance remains low in the initial layers but increases exponentially as the layer depth increases, regardless of the training stage. This exponential growth suggests that deeper layers suffer from uncontrolled variance amplification during training, even with Pre-LN, highlighting the need for variance control mechanisms like LayerNorm Scaling.
read the caption
Figure 6: Variance growth across layers in LLaMA-130M with Pre-LN. Each subplot shows the variance at different training stages (1000, 3000, and 6000 epochs). In all cases, the variance follows an exponential growth pattern as depth increases, indicating that deeper layers experience uncontrolled variance amplification regardless of training progress.
More on tables
| Pre-LN | Admin | Group-LN | Sandwich-LN | Mix-LN | LayerNorm Scaling |
|---|---|---|---|---|---|
| 26.73 | 27.91 | 28.01 | 26.51 | 26.07 | 25.76 |
🔼 This table presents a comparison of the perplexity scores achieved by different layer normalization methods when training the LLaMA-130M language model. Lower perplexity indicates better performance. The methods compared include Pre-LN (Pre-Layer Normalization), Admin, Group-LN (Group Layer Normalization), Sandwich-LN, Mix-LN, and LayerNorm Scaling. This allows for a direct assessment of how these different normalization techniques impact the model’s ability to learn and generate text, offering insights into their relative effectiveness.
read the caption
Table 2: Comparison against other normalization methods on LLaMA-130M. Perplexity (↓) is reported.
| Method | MMLU | BoolQ | ARC-e | PIQA | Hellaswag | OBQA | Winogrande | Average |
|---|---|---|---|---|---|---|---|---|
| LLaMA-250M | ||||||||
| Post-LN (Ba, 2016) | 22.95 | 37.83 | 26.94 | 52.72 | 26.17 | 11.60 | 49.56 | 32.54 |
| DeepNorm (Wang et al., 2024) | 23.60 | 37.86 | 36.62 | 61.10 | 25.69 | 15.00 | 49.57 | 35.63 |
| Mix-LN (Li et al., 2024b) | 26.53 | 56.12 | 41.68 | 66.34 | 30.16 | 18.00 | 50.56 | 41.34 |
| Pre-LN (Baevski and Auli, 2019) | 24.93 | 38.35 | 40.15 | 63.55 | 26.34 | 16.20 | 49.01 | 36.93 |
| Pre-LN + LayerNorm Scaling | 27.08 | 58.17 | 45.24 | 67.38 | 32.81 | 18.80 | 52.49 | 43.14 |
| LLaMA-1B | ||||||||
| Post-LN (Ba, 2016) | 22.95 | 37.82 | 25.08 | 49.51 | 25.04 | 13.80 | 49.57 | 31.96 |
| DeepNorm (Wang et al., 2024) | 23.35 | 37.83 | 27.06 | 52.94 | 26.19 | 11.80 | 49.49 | 32.67 |
| Mix-LN (Li et al., 2024b) | 23.19 | 37.83 | 25.08 | 49.51 | 25.04 | 11.80 | 49.57 | 31.72 |
| Pre-LN (Baevski and Auli, 2019) | 26.54 | 62.20 | 45.70 | 67.79 | 30.96 | 17.40 | 50.51 | 43.01 |
| Pre-LN + LayerNorm Scaling | 28.69 | 61.80 | 48.85 | 67.92 | 33.94 | 18.60 | 54.30 | 44.87 |
🔼 This table presents the results of fine-tuning various LLaMA models (LLaMA-250M and LLaMA-1B) on eight downstream tasks using different layer normalization techniques. The table shows the performance improvement (measured as a percentage increase) achieved by using LayerNorm Scaling compared to standard Pre-LN (Pre-Layer Normalization), Post-LN (Post-Layer Normalization), DeepNorm, and Mix-LN. The results demonstrate the effectiveness of LayerNorm Scaling in enhancing fine-tuning performance across different model sizes and tasks.
read the caption
Table 3: Fine-tuning performance (↑↑\uparrow↑) of LLaMA with various normalizations.
| Perplexity () | LLaMA-130M | LLaMA-250M |
|---|---|---|
| Training Tokens | 2.2B | 3.9B |
| Pre-LN | 26.73 | 21.92 |
| + LayerScale | 27.93 | 23.45 |
| + Scaled Initialization | 26.04 | 20.98 |
| + LayerNorm Scaling | 25.76 | 20.35 |
🔼 This table compares the performance of LayerNorm Scaling against other scaling methods (LayerScale and Scaled Initialization) in terms of perplexity on the LLaMA-130M and LLaMA-250M models. It highlights the impact of different scaling techniques on model performance during pre-training, showing how LayerNorm Scaling achieves lower perplexity compared to the baselines.
read the caption
Table 4: Comparison against other scaling methods.
Full paper#