TL;DR#
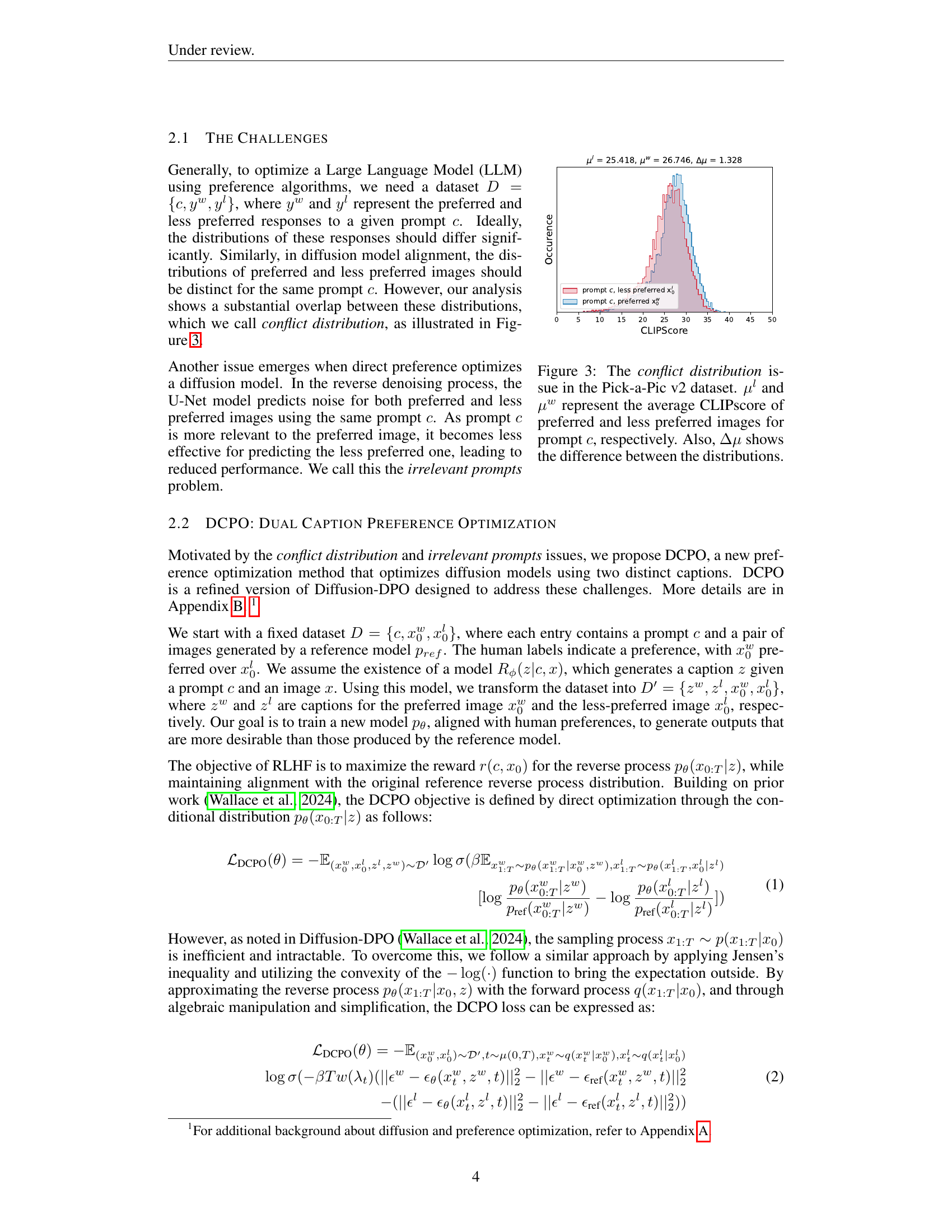
Current preference optimization methods for diffusion models suffer from issues like conflict distribution (overlap between preferred and less-preferred image distributions) and irrelevant prompts (prompts containing information unrelated to less-preferred images). These issues hinder the model’s ability to accurately learn preferences.
To address these limitations, the researchers propose a novel method called Dual Caption Preference Optimization (DCPO). DCPO utilizes two distinct captions for each image pair, mitigating the effects of irrelevant prompts. It also introduces a modified dataset, Pick-Double Caption, with separate captions for preferred and less-preferred images to combat the conflict distribution. Experiments show DCPO significantly outperforms existing techniques across various metrics, demonstrating improved image quality and relevance to prompts.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles key challenges in preference optimization for diffusion models, improving image quality and relevance. It introduces a novel approach, DCPO, addressing issues like conflict distribution and irrelevant prompts, leading to significant performance gains over existing methods. This opens new avenues for research in aligning generative models with human preferences, particularly in multi-modal contexts.
Visual Insights#

🔼 Figure 1 showcases a comparison of image generation results from various methods, including Stable Diffusion 2.1 (SD 2.1), SFTChosen, Diffusion-DPO, MaPO, and the novel DCPO method. The models were fine-tuned using the Pick-a-Pic v2 and Pick-Double Caption datasets. Each model was given the same text prompts, and the resulting images are displayed, demonstrating the relative quality and adherence to the prompt. The figure highlights that DCPO generates images with superior preference and visual appeal compared to the other techniques. More examples are available in Appendix H.
read the caption
Figure 1: Sample images generated by different methods on the HPSv2, Geneval, and Pickscore benchmarks. After fine-tuning SD 2.1 with SFTChosensubscriptSFTChosen\text{SFT}_{\text{Chosen}}SFT start_POSTSUBSCRIPT Chosen end_POSTSUBSCRIPT, Diffusion-DPO, MaPO, and DCPO on Pick-a-Picv2 and Pick-Double Caption datasets, DCPO produces images with notably higher preference and visual appeal (See more examples in Appendix H).
| \stackanchorPickScore () | HPSv2.1 () | \stackanchorImageReward () | \stackanchorCLIPScore () | |
|---|---|---|---|---|
| Results from other methods | ||||
| SD 2.1 | 20.30 | 25.17 | 55.8 | 26.84 |
| 20.35 | 25.09 | 56.4 | 26.98 | |
| Diffusion-DPO | 20.36 | 25.10 | 56.4 | 26.98 |
| MaPO | 19.41 | 24.47 | 50.4 | 24.82 |
| Results from our methods | ||||
| DCPO-c (LLaVA) | 20.46 | 25.10 | 56.5 | 27.00 |
| DCPO-c (Emu2) | 20.46 | 25.06 | 56.6 | 26.97 |
| DCPO-p | 20.28 | 25.42 | 54.2 | 26.98 |
| DCPO-h (LLaVA) | 20.57 | 25.62 | 58.2 | 27.13 |
🔼 This table presents a quantitative comparison of different image generation methods, evaluating their performance on four key metrics: PickScore, HSPv2.1, normalized ImageReward, and CLIPScore. The results demonstrate that the Dual Caption Preference Optimization (DCPO) approach significantly outperforms existing methods such as Stable Diffusion 2.1 (SD 2.1), SFTChosen, Diffusion-DPO, and MaPO, particularly in terms of Pickscore, HSPv2.1, and ImageReward. This highlights the effectiveness of DCPO in generating images that better align with human preferences.
read the caption
Table 1: Results on PickScore, HSPv2.1, ImageReward (normalized), and CLIPScore. We show that DCPO significantly improves on Pickscore, HSP2.1, and ImageReward.
In-depth insights#
Dual Caption Optimization#
The core idea of “Dual Caption Optimization” centers on improving the alignment of diffusion models with human preferences by using two distinct captions for each image in a preference dataset. This approach directly addresses two key limitations of existing methods: conflict distribution, where preferred and less-preferred images share similar characteristics, and irrelevant prompts, where the prompt provides unhelpful information for distinguishing between preferred and less-preferred images. By generating separate captions tailored to highlight the aspects that make each image preferred or less preferred, this technique enhances the model’s ability to learn the nuanced differences in human preferences, leading to a significant improvement in the quality and relevance of generated images. The use of dual captions provides more discriminative training signals, improving the model’s ability to generalize and produce higher-quality results. The method proposes distinct strategies for generating these captions (captioning, perturbation, and hybrid approaches), suggesting a flexible and adaptable framework for preference optimization in diffusion models.
Irrelevant Prompt Issue#
The “Irrelevant Prompt Issue”, as discussed in the research paper, highlights a significant challenge in preference optimization for diffusion models. The issue stems from the presence of irrelevant information within prompts, particularly those associated with less preferred images. This irrelevant information can confuse the denoising network during training. The network struggles to discern and appropriately weight the relevant noise patterns in the images, hindering its ability to distinguish between preferred and less preferred samples effectively. Consequently, the optimization process becomes less efficient and effective, impacting the model’s ability to generate highly preferred images. The solution proposed in the paper focuses on mitigating this issue by introducing a dual-caption approach, employing two separate and informative captions for preferred and less preferred images respectively. This strategy ensures the network receives only relevant information for each image, thus refining the noise prediction and overall preference optimization process. The paper’s findings demonstrate that this approach successfully addresses the “Irrelevant Prompt Issue”, leading to substantial improvements in image quality and alignment with user preferences.
Pick-Double Dataset#
The creation of a new dataset, the “Pick-Double Dataset,” is a pivotal contribution of this research. It directly addresses limitations found in existing preference datasets, specifically the conflict distribution problem where preferred and less-preferred images show significant overlap in feature space. By pairing each image with two distinct captions – one for the preferred and one for the less-preferred instance – the Pick-Double Dataset provides more discriminative information for training diffusion models. This approach is crucial for improving the effectiveness of preference optimization techniques which aim to align model outputs with human preferences. The dual captions, rather than relying solely on the prompt, enable the model to learn finer distinctions between the images, reducing ambiguity and potentially mitigating issues like reward hacking. The use of a modified version of Pick-a-Pic v2 as a base further suggests a methodological rigor that prioritizes data quality and relevance. Improved dataset quality directly translates to a model’s ability to learn nuanced preferences more effectively, resulting in higher-quality and more relevant image generation based on user input. Therefore, the Pick-Double Dataset represents a substantial advance in the field of image generation, providing a critical resource for future research in preference optimization.
Ablation Studies#
Ablation studies systematically remove components of a model or process to understand their individual contributions. In the context of this research paper, ablation studies would likely have investigated the impact of each component of the Dual Caption Preference Optimization (DCPO) framework. This would involve experiments where caption generation methods (captioning, perturbation, hybrid), different perturbation strengths (weak, medium, strong), and the choice of large language models (LLMs) for caption generation were selectively disabled or altered. The results of these experiments would reveal the relative importance of each component in improving the quality and alignment of generated images. For example, comparing the performance of DCPO with and without caption perturbation would show the effectiveness of this strategy in mitigating the conflict distribution problem. Similarly, comparing different LLMs would indicate which model best suited the task. By carefully dissecting the model, the authors could isolate the specific features responsible for performance gains, providing valuable insights for future improvements and potentially offering a more refined and efficient optimization approach. The ultimate goal of these studies is to demonstrate a robust and effective methodology for improving the training of diffusion models by establishing the importance of the novel dual caption approach and each of its components.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of caption generation is crucial, as current methods are computationally intensive. Investigating alternative approaches, such as leveraging smaller, more efficient language models or incorporating pre-trained image captioning models, could significantly reduce computational costs. Extending DCPO to other diffusion model architectures beyond Stable Diffusion 2.1 and exploring its effectiveness on other tasks (e.g., video generation, 3D modeling) are important next steps. A deeper analysis of the hyperparameter β in the DCPO loss function could reveal ways to optimize its performance across different datasets and tasks. Further investigation into the impact of different perturbation methods and their effect on the quality of generated captions would also be valuable. Finally, conducting more extensive user studies and applying more sophisticated evaluation metrics could provide a more complete understanding of DCPO’s performance and limitations. Addressing the out-of-distribution issue in caption generation remains a challenge; innovative methods for generating high-quality, in-distribution captions are needed.
More visual insights#
More on figures
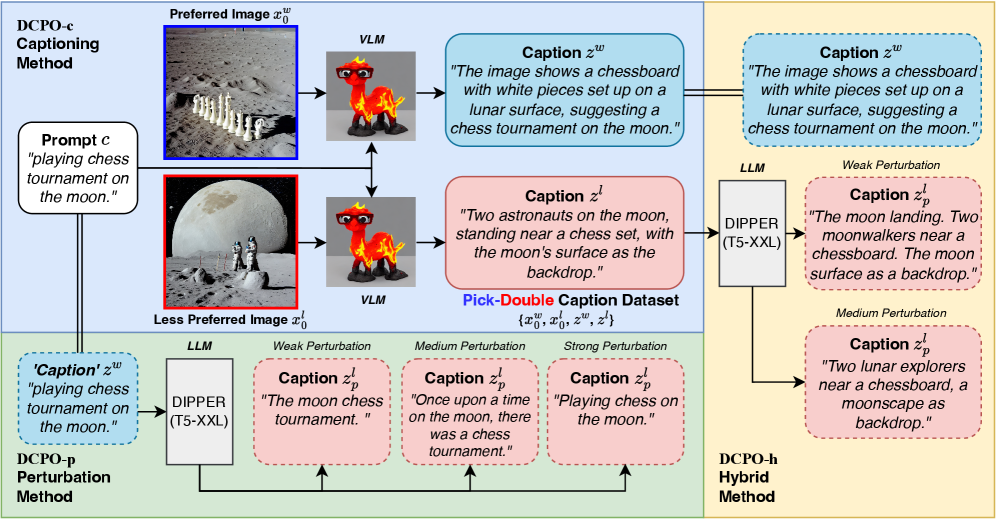
🔼 Figure 2 illustrates the three Dual Caption Preference Optimization (DCPO) pipelines: DCPO-c, DCPO-p, and DCPO-h. Each pipeline uses a pair of images: a preferred image with its caption and a less preferred image with its caption. DCPO-c uses a captioning model to generate distinct captions for the preferred and less-preferred images, given a shared prompt. DCPO-p uses the shared prompt as the caption for the preferred image, and employs a Large Language Model (LLM) to create a semantically perturbed caption for the less-preferred image. DCPO-h combines both strategies, starting with a generated caption for the less preferred image which is then further perturbed. The Pick-Double Caption Dataset (discussed in Section 3.1) is created using the DCPO-c pipeline.
read the caption
Figure 2: The overview of our 3 Dual Preference Optimization (DCPO) pipelines: DCPO-c, DCPO-p, and DCPO-h, all of which require a duo of a captioned preferred image (x0w,zw)subscriptsuperscript𝑥𝑤0superscript𝑧𝑤(x^{w}_{0},z^{w})( italic_x start_POSTSUPERSCRIPT italic_w end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , italic_z start_POSTSUPERSCRIPT italic_w end_POSTSUPERSCRIPT ) and a captioned less-preferred image (x0l,zl)subscriptsuperscript𝑥𝑙0superscript𝑧𝑙(x^{l}_{0},z^{l})( italic_x start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , italic_z start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT ). DCPO-c (Top Left): We use a captioning model to generate distinctive captions respectively for images x0wsubscriptsuperscript𝑥𝑤0x^{w}_{0}italic_x start_POSTSUPERSCRIPT italic_w end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT and x0lsubscriptsuperscript𝑥𝑙0x^{l}_{0}italic_x start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT given the shared prompt c𝑐citalic_c. DCPO-p (Bottom Left): We take prompt c𝑐citalic_c as the caption for image x0wsubscriptsuperscript𝑥𝑤0x^{w}_{0}italic_x start_POSTSUPERSCRIPT italic_w end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT, then we use a Large Language Model (LLM) to generate a semantically perturbed prompt zplsuperscriptsubscript𝑧𝑝𝑙z_{p}^{l}italic_z start_POSTSUBSCRIPT italic_p end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT given prompt c𝑐citalic_c as the caption for image x0lsubscriptsuperscript𝑥𝑙0x^{l}_{0}italic_x start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT. DCPO-h (Right): A hybrid method where the generated caption zlsuperscript𝑧𝑙z^{l}italic_z start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT is now perturbed into zplsuperscriptsubscript𝑧𝑝𝑙z_{p}^{l}italic_z start_POSTSUBSCRIPT italic_p end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT for image x0lsubscriptsuperscript𝑥𝑙0x^{l}_{0}italic_x start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT. Our Pick-Double Caption Dataset discussed in Section 3.1 is constructed with the DCPO-c pipeline.

🔼 Figure 3 illustrates the issue of overlapping distributions in the Pick-a-Pic v2 dataset, which is a key challenge in preference optimization for diffusion models. The figure displays the distribution of CLIP scores for both preferred and less preferred images generated from the same prompt. The average CLIP score for preferred images is represented by μw (mu-w), and the average CLIP score for less preferred images is represented by μl (mu-l). The difference between these two averages, Δμ (delta-mu), highlights the extent of the overlap. A smaller difference indicates a greater overlap, making it more challenging to distinguish between preferred and less preferred images using only the prompt as input for the optimization process.
read the caption
Figure 3: The conflict distribution issue in the Pick-a-Pic v2 dataset. μlsuperscript𝜇𝑙\mu^{l}italic_μ start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT and μwsuperscript𝜇𝑤\mu^{w}italic_μ start_POSTSUPERSCRIPT italic_w end_POSTSUPERSCRIPT represent the average CLIPscore of preferred and less preferred images for prompt c𝑐citalic_c, respectively. Also, ΔμΔ𝜇\Delta\muroman_Δ italic_μ shows the difference between the distributions.

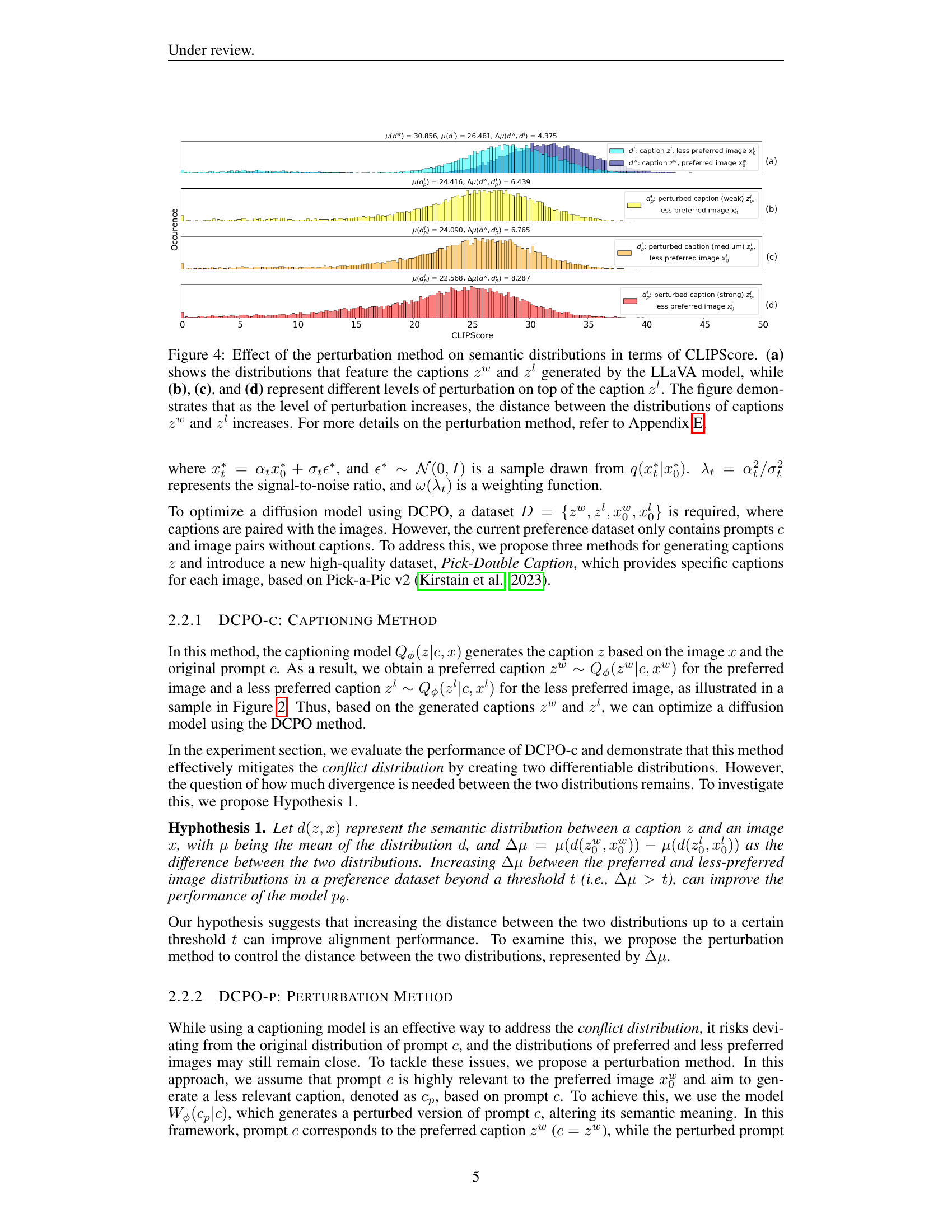
🔼 Figure 4 illustrates the impact of different perturbation levels on the semantic similarity between captions associated with preferred and less preferred images, as measured by CLIPScore. Panel (a) displays the CLIPScore distributions for captions generated by the LLaVA model without perturbation. Subsequent panels (b), (c), and (d) show how these distributions change with increasing levels of perturbation applied to the caption of the less preferred image. The key observation is that greater perturbation leads to a larger separation between the CLIPScore distributions of the preferred and less preferred image captions, indicating that the perturbation method effectively increases the semantic difference between the two types of captions.
read the caption
Figure 4: Effect of the perturbation method on semantic distributions in terms of CLIPScore. (a) shows the distributions that feature the captions zwsuperscript𝑧𝑤z^{w}italic_z start_POSTSUPERSCRIPT italic_w end_POSTSUPERSCRIPT and zlsuperscript𝑧𝑙z^{l}italic_z start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT generated by the LLaVA model, while (b), (c), and (d) represent different levels of perturbation on top of the caption zlsuperscript𝑧𝑙z^{l}italic_z start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT. The figure demonstrates that as the level of perturbation increases, the distance between the distributions of captions zwsuperscript𝑧𝑤z^{w}italic_z start_POSTSUPERSCRIPT italic_w end_POSTSUPERSCRIPT and zlsuperscript𝑧𝑙z^{l}italic_z start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT increases. For more details on the perturbation method, refer to Appendix E.

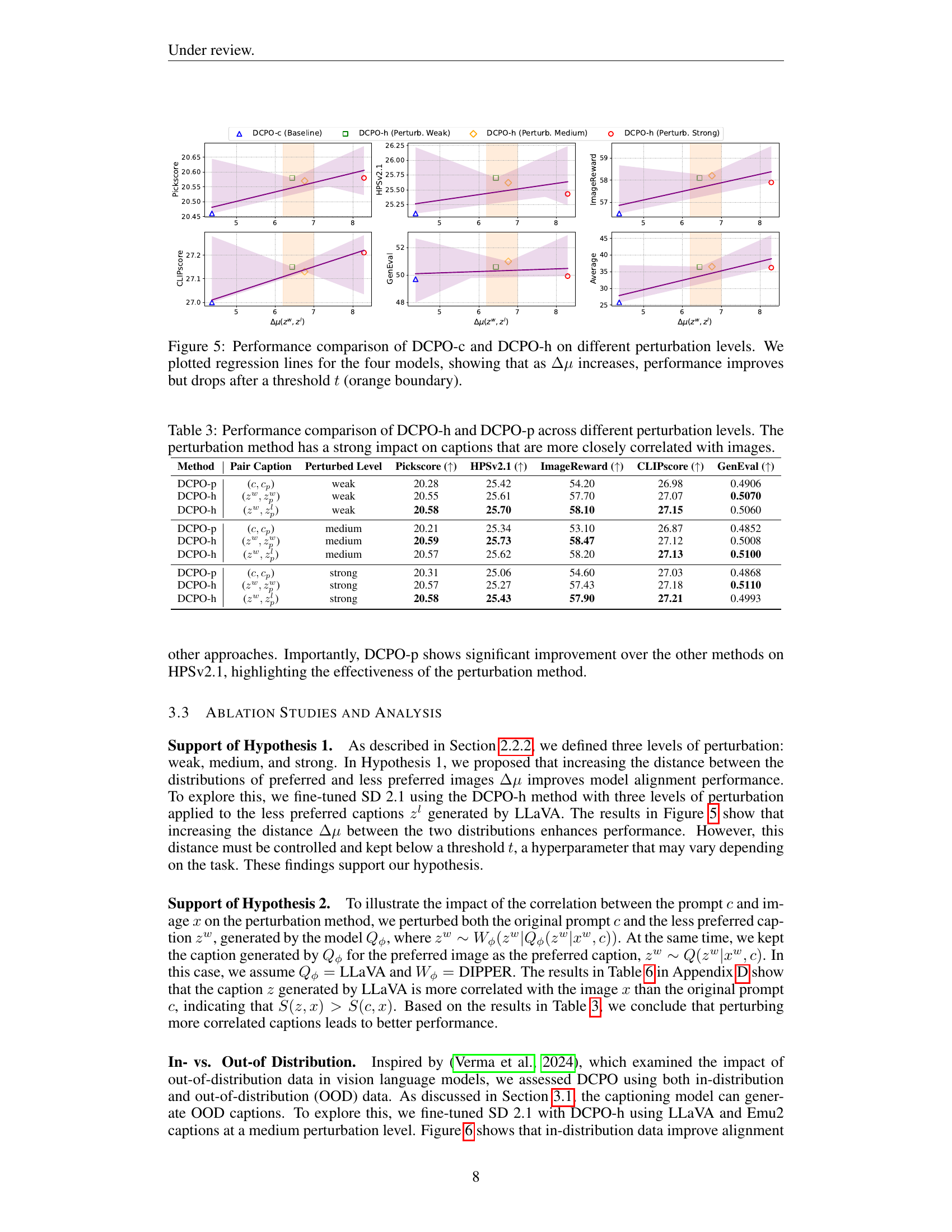
🔼 This figure shows the performance comparison between DCPO-c (baseline) and three variants of DCPO-h with different levels of perturbation. The x-axis represents the difference in CLIPScore (Δμ) between preferred and less preferred image captions. The y-axis shows the performance metrics (Pickscore, HPSv2.1, ImageReward, CLIPscore, and GenEval). Regression lines are plotted for each model to illustrate the trend. The results indicate that increasing Δμ improves performance up to a certain threshold (represented by the orange vertical line), after which performance begins to decrease. This suggests that an optimal level of perturbation exists for maximizing the effectiveness of dual caption preference optimization.
read the caption
Figure 5: Performance comparison of DCPO-c and DCPO-h on different perturbation levels. We plotted regression lines for the four models, showing that as ΔμΔ𝜇\Delta\muroman_Δ italic_μ increases, performance improves but drops after a threshold t𝑡titalic_t (orange boundary).

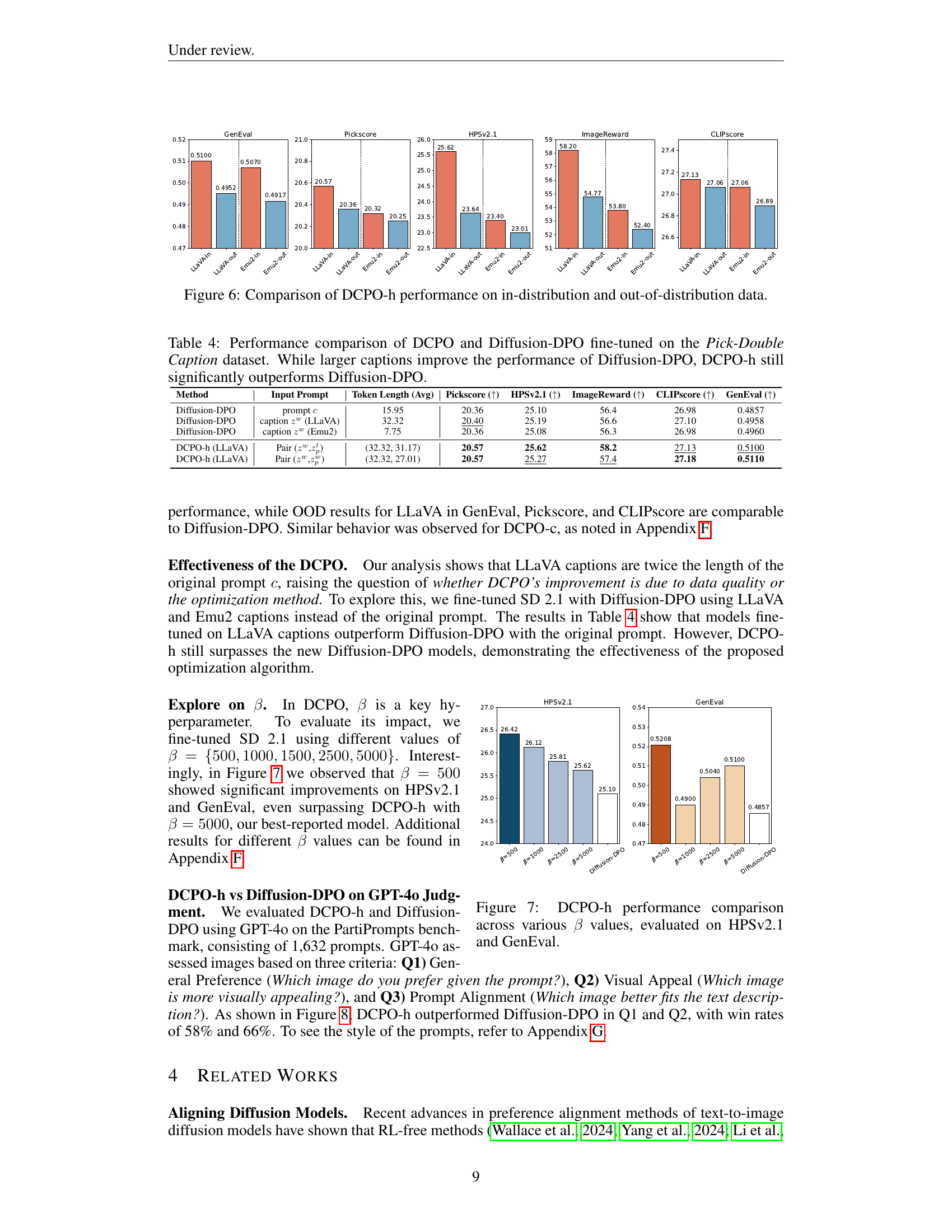
🔼 Figure 6 presents a comparative analysis of the Dual Caption Preference Optimization (DCPO-h) model’s performance when trained on both in-distribution and out-of-distribution data. The figure displays bar charts showing the performance metrics (Pickscore, HPSv2.1, ImageReward, CLIPscore, and GenEval) achieved by the DCPO-h model trained on in-distribution data (LLaVA-in, Emu2-in) versus the model trained on out-of-distribution data (LLaVA-out, Emu2-out). The results visually demonstrate the impact of data distribution on the model’s ability to generate high-quality images. This comparison highlights the robustness and generalizability of DCPO-h.
read the caption
Figure 6: Comparison of DCPO-h performance on in-distribution and out-of-distribution data.

🔼 Figure 7 displays the performance of the DCPO-h model across various values of the hyperparameter (\beta). The results are shown for two key evaluation benchmarks: HPSv2.1 and GenEval. The graph likely shows how the model’s performance (e.g., measured by a specific score) changes as (\beta) is varied. This helps to illustrate the impact of this hyperparameter on the effectiveness of the DCPO-h method.
read the caption
Figure 7: DCPO-h performance comparison across various β𝛽\betaitalic_β values, evaluated on HPSv2.1 and GenEval.

🔼 Figure 8 presents a comparative analysis of the performance of DCPO-h and Diffusion-DPO, both fine-tuned on the Stable Diffusion 2.1 model. The left panel displays the quantitative results of the PartiPrompts benchmark evaluation using GPT-4 as the evaluator. Three specific questions were posed to GPT-4: General Preference (which image is preferred?), Visual Appeal (which image is more visually appealing?), and Prompt Alignment (which image better matches the text prompt?). The bar chart shows the win rates for DCPO-h versus Diffusion-DPO for each question. The right panel provides a qualitative comparison of images generated by both methods in response to three sample prompts. The images generated by DCPO-h exhibit higher visual fidelity, richer detail, more vibrant colors, superior contrast, and better compositional focus, indicating enhanced realism and overall quality that more closely aligns with human preference compared to images produced by Diffusion-DPO.
read the caption
Figure 8: (Left) PartiPrompts benchmark results for three evaluation questions, as voted by GPT-4o. (Right) Qualitative comparison between DCPO-h and Diffusion-DPO fine-tuned on SD 2.1. DCPO-h shows better prompt adherence and realism, with outputs that align more closely with human preferences, emphasizing high contrast, vivid colors, fine detail, and well-focused composition.

🔼 This histogram displays the distribution of prompt lengths (measured in tokens) from the original Pick-a-Pic v2 dataset. The x-axis represents the number of tokens in a prompt, and the y-axis shows the frequency or count of prompts with that length. The distribution appears to be somewhat right-skewed, indicating that many prompts are relatively short but some are quite long, with a peak around 15 tokens.
read the caption
Figure 9: Token distribution of original prompt.

🔼 Figure 10 shows examples from the Pick-Double Caption dataset, which is a modified version of the Pick-a-Pic v2 dataset. The dataset includes pairs of images, one preferred and one less preferred, for the same prompt. Critically, each image is accompanied by two distinct captions: one generated using a conditional prompt (that is, a caption that explicitly uses the original prompt for guidance) and one generated using an unconditional prompt (a caption that describes the image without any mention of the original prompt). This dual-caption approach addresses the ‘conflict distribution’ problem observed in previous datasets where preferred and less-preferred images share similar visual characteristics for the same prompt. The figure highlights this by illustrating paired images with their corresponding conditional and unconditional captions. This approach provides more information to the model during training, enabling it to more effectively differentiate between preferred and less-preferred images.
read the caption
Figure 10: Examples of Pick-Double Caption dataset.

🔼 This figure compares the performance of the DCPO-c method (Dual Caption Preference Optimization using the captioning method) on two types of data: in-distribution and out-of-distribution. In-distribution data refers to data that closely resembles the data used to train the model, while out-of-distribution data is significantly different. The figure likely shows a bar chart or similar visualization, displaying metrics like Pickscore, HPSv2.1, ImageReward, CLIPscore, and GenEval for both in-distribution and out-of-distribution data sets, allowing for a direct comparison of the model’s performance under different data conditions. The comparison aims to demonstrate how well the model generalizes to unseen data. The results will likely show that the model performs better on in-distribution data than on out-of-distribution data.
read the caption
Figure 11: Comparison of DCPO-c performance on in-distribution and out-of-distribution data.

🔼 Figure 12 presents a qualitative comparison of image generation results across five different methods: Stable Diffusion 2.1 (baseline), SFTChosen, Diffusion-DPO, MaPO, and the proposed DCPO-h. Each method was used to generate images from three prompts sourced from the HPSv2 benchmark. The figure visually demonstrates the differences in image quality, style, and adherence to the prompt between the methods. This comparison highlights the improvements achieved by DCPO-h in terms of image coherence, visual appeal, and relevance to the given prompts.
read the caption
Figure 12: Additional generated outcomes using prompts from HPSv2 benchmark.

🔼 Figure 13 presents a qualitative comparison of image generation results from several different methods: SD 2.1 Base, SFTChosen, Diffusion-DPO, MaPO, and DCPO-h (the authors’ method). Each method was used to generate images based on prompts from the Pickscore benchmark. The figure displays the generated images for four different prompts. By visually comparing the outputs, one can assess the relative strengths and weaknesses of each approach in terms of image quality, adherence to the prompt, and stylistic consistency. The DCPO-h method, in particular, appears to produce high-quality images that align well with the intended prompt, compared to the other methods.
read the caption
Figure 13: Additional generated outcomes using prompts from Pickscore benchmark.

🔼 Figure 14 presents several images generated using different models (SD 2.1 Base, SFTChosen, Diffusion-DPO, MaPO, and DCPO-h) based on prompts from the GenEval benchmark. The prompts focus on everyday objects and scenes and the resulting images show variations in quality and adherence to the prompt across the different models. This figure is a qualitative comparison to demonstrate the visual improvements achieved by the proposed DCPO-h model in comparison to the baseline and other existing methods.
read the caption
Figure 14: Additional generated outcomes using prompts from GenEval benchmark.
More on tables
| Method | Overall | \stackanchorSingleobject | \stackanchorTwoobjects | Counting | Colors | Position | \stackanchorAttributebinding | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Results from other methods | |||||||||||||
| SD 2.1222Note that we rerun all the models on same seeds to have a fair comparison. | 0.4775 | 0.96 | 0.52 | 0.35 | 0.80 | 0.09 | 0.15 | ||||||
| 0.4797 | 1.00 | 0.42 | 0.42 | 0.81 | 0.07 | 0.14 | |||||||
| Diffusion-DPO | 0.4857 | 0.99 | 0.48 | 0.46 | 0.83 | 0.04 | 0.11 | ||||||
| MaPO | 0.4106 | 0.98 | 0.40 | 0.28 | 0.66 | 0.06 | 0.09 | ||||||
| Results from our methods | |||||||||||||
| DCPO-c (LLaVA) | 0.4971 | 1.00 | 0.43 | 0.53 | 0.85 | 0.02 | 0.14 | ||||||
| DCPO-c (Emu2) | 0.4925 | 1.00 | 0.41 | 0.50 | 0.85 | 0.04 | 0.15 | ||||||
| DCPO-p | 0.4906 | 1.00 | 0.41 | 0.50 | 0.83 | 0.03 | 0.17 | ||||||
| DCPO-h (LLaVA) | 0.5100 | 0.99 | 0.51 | 0.54 | 0.84 | 0.05 | 0.14 | ||||||
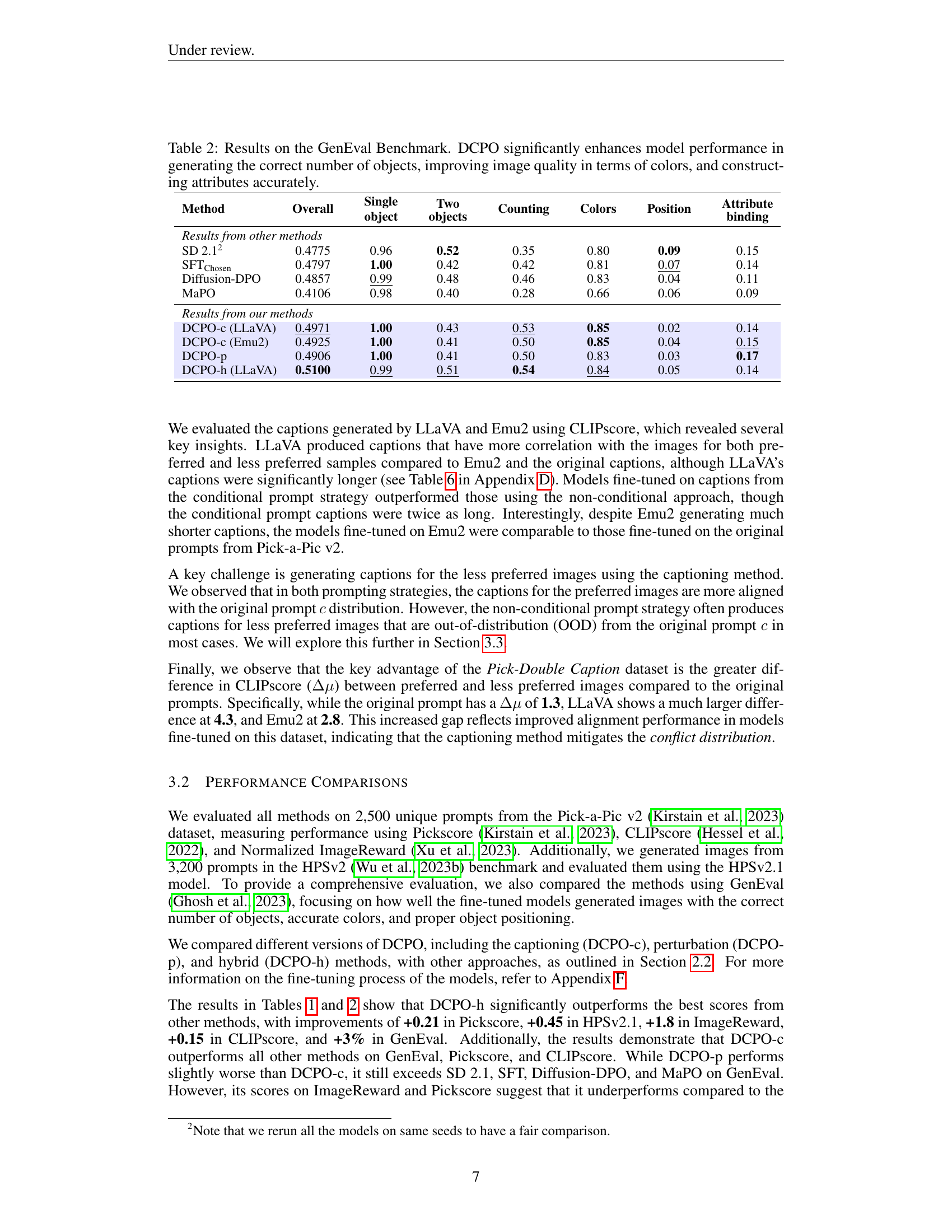
🔼 Table 2 presents a comprehensive evaluation of the DCPO model’s performance on the GenEval benchmark, a widely used metric for assessing the overall quality of generated images. The benchmark considers various aspects of image generation, specifically focusing on the accuracy of object counts (detecting the correct number of objects in the image), the quality of colors used (evaluating the vibrancy and appropriateness of colors), the precision of object placement (measuring the accuracy of the position of generated objects), and the accuracy of attributes (assessing how well the generated images reflect the specified attributes). The results in Table 2 demonstrate that DCPO consistently outperforms existing methods (SD 2.1, SFTChosen, Diffusion-DPO, and MaPO) in all these aspects, thereby highlighting its ability to generate images with higher fidelity, visual appeal, and alignment with user prompts.
read the caption
Table 2: Results on the GenEval Benchmark. DCPO significantly enhances model performance in generating the correct number of objects, improving image quality in terms of colors, and constructing attributes accurately.
| Method | Pair Caption | Perturbed Level | Pickscore () | HPSv2.1 () | ImageReward () | CLIPscore () | GenEval () |
|---|---|---|---|---|---|---|---|
| DCPO-p | () | weak | 20.28 | 25.42 | 54.20 | 26.98 | 0.4906 |
| DCPO-h | () | weak | 20.55 | 25.61 | 57.70 | 27.07 | 0.5070 |
| DCPO-h | () | weak | 20.58 | 25.70 | 58.10 | 27.15 | 0.5060 |
| DCPO-p | () | medium | 20.21 | 25.34 | 53.10 | 26.87 | 0.4852 |
| DCPO-h | () | medium | 20.59 | 25.73 | 58.47 | 27.12 | 0.5008 |
| DCPO-h | () | medium | 20.57 | 25.62 | 58.20 | 27.13 | 0.5100 |
| DCPO-p | () | strong | 20.31 | 25.06 | 54.60 | 27.03 | 0.4868 |
| DCPO-h | () | strong | 20.57 | 25.27 | 57.43 | 27.18 | 0.5110 |
| DCPO-h | () | strong | 20.58 | 25.43 | 57.90 | 27.21 | 0.4993 |
🔼 This table presents a comparison of the performance of two Dual Caption Preference Optimization (DCPO) methods, DCPO-h (hybrid) and DCPO-p (perturbation), across three levels of perturbation (weak, medium, strong). The performance metrics include Pickscore, HPSv2.1, ImageReward, CLIPscore, and GenEval. The results highlight how the choice of perturbation method and the level of perturbation affect the quality of the generated images. The hybrid method generally outperforms the perturbation method, demonstrating the efficacy of integrating captioning and perturbation techniques for better alignment of generated images with their captions. A key observation is that stronger perturbation, while sometimes effective, doesn’t always lead to the best results, suggesting a balance is needed between caption distinctiveness and the original prompt’s relevance to the images.
read the caption
Table 3: Performance comparison of DCPO-h and DCPO-p across different perturbation levels. The perturbation method has a strong impact on captions that are more closely correlated with images.
| Method | Input Prompt | Token Length (Avg) | Pickscore () | HPSv2.1 () | ImageReward () | CLIPscore () | GenEval () |
| Diffusion-DPO | prompt | 15.95 | 20.36 | 25.10 | 56.4 | 26.98 | 0.4857 |
| Diffusion-DPO | caption (LLaVA) | 32.32 | 20.40 | 25.19 | 56.6 | 27.10 | 0.4958 |
| Diffusion-DPO | caption (Emu2) | 7.75 | 20.36 | 25.08 | 56.3 | 26.98 | 0.4960 |
| DCPO-h (LLaVA) | Pair (,) | (32.32, 31.17) | 20.57 | 25.62 | 58.2 | 27.13 | 0.5100 |
| DCPO-h (LLaVA) | Pair (,) | (32.32, 27.01) | 20.57 | 25.27 | 57.4 | 27.18 | 0.5110 |
🔼 This table compares the performance of DCPO-h and Diffusion-DPO after fine-tuning on the Pick-Double Caption dataset. It shows that while using longer captions generally improves Diffusion-DPO’s results, DCPO-h consistently achieves superior performance across multiple metrics (Pickscore, HPSv2.1, ImageReward, CLIPscore, and GenEval). This highlights the effectiveness of the DCPO method even compared to a Diffusion-DPO model that benefits from longer captions.
read the caption
Table 4: Performance comparison of DCPO and Diffusion-DPO fine-tuned on the Pick-Double Caption dataset. While larger captions improve the performance of Diffusion-DPO, DCPO-h still significantly outperforms Diffusion-DPO.
| Method | GenEval () | Pickscore () | HPSv2.1 () | ImageReward () | CLIPscore () |
|---|---|---|---|---|---|
| Diffusion-KTO | 0.5008 | 20.41 | 24.80 | 55.5 | 26.95 |
| DCPO-h | 0.5100 | 20.57 | 25.62 | 58.2 | 27.13 |
🔼 This table presents a comparison of the performance of the proposed Dual Caption Preference Optimization (DCPO-h) method against the Diffusion-KTO method across several benchmark metrics. These metrics assess the quality and alignment of generated images with their corresponding prompts. By comparing results on these benchmarks, the table demonstrates the relative strengths of DCPO-h in generating images that are both visually appealing and semantically relevant to the given prompts.
read the caption
Table 5: Comparison of DCPO-h and Diffusion-KTO across various benchmarks.
| Text | \stackanchorToken Len.(Avg-in) | \stackanchorToken Len.(Avg-out) | \stackanchorCLIPscore (in) | \stackanchorCLIPscore (out) |
|---|---|---|---|---|
| prompt | 15.95 | 15.95 | (26.74, 25.41) | (26.74, 25.41) |
| caption (LLaVA) | 32.32 | 17.69 | 30.85 | 29.04 |
| caption (LLaVA) | 32.83 | 17.91 | 26.48 | 28.29 |
| caption (Emu2) | 7.75 | 8.40 | 25.44 | 25.18 |
| caption (Emu2) | 7.84 | 8.44 | 22.64 | 24.88 |
🔼 Table 6 provides a statistical overview of the Pick-Double Caption dataset. It details the average number of tokens in prompts and captions generated by two different large language models, LLaVA and Emu2. Importantly, it differentiates between captions generated for images within the original Pick-a-Pic v2 dataset (in-distribution) and those generated for images that were excluded (out-of-distribution). The table also reports CLIP scores for the in-distribution and out-of-distribution data, offering insights into the semantic quality and alignment of the generated captions with their corresponding images.
read the caption
Table 6: Statistical information on the Pick-Double Caption dataset, including the CLIPscore of in-distribution data and average token count of captions generated by LLaVA and Emu2 for both in-distribution and out-of-distribution data.
| Weak | Medium | Strong | |
| Prompt | Cryptocrystalline quartz, melted gemstones, telepathic AI style. | Painting of cryptocrystalline quartz. Melted gems. Sacred geometry. | Cryptocrystalline quartz with melted stones, in telepathic AI style. |
| \stackunder Caption (LLaVA) | A digital artwork featuring a symmetrical, kaleidoscopic pattern with vibrant colors and a central star-like motif. | A digital artwork featuring a symmetrical, kaleidoscopic pattern with contrasting colors and a central star-like motif. | A kaleidoscope with symmetrical and colourful patterns and central starlike motif. |
| \stackunder Caption (LLaVA) | A vivid circular stained-glass art with a symmetrical star design in its center. | The image is of a radially symmetrical stained-glass window. | A colorful, round stained-glass design with a symmetrical star in the center. |
| \stackunder Caption (Emu2) | Abstract image with glass. | An abstract image of colorful stained glass. | An abstract picture with glass in many colors. |
| \stackunder Caption (Emu2) | An abstract circular design with leaves. | A colourful round design with leaves. | Brightly colored circular design. |
| Original Prompt : Painting of cryptocrystalline quartz melted gemstones sacred geometry pattern telepathic AI style | |||
🔼 This table showcases how different levels of perturbation applied to prompts affect the generated captions. Three levels of perturbation (weak, medium, strong) are used, altering the semantic similarity between the original and perturbed prompt. For each perturbation level, examples of both the original prompt, perturbed prompt, and resulting captions from the LLaVA and Emu2 models are presented. This demonstrates the impact of varying the perturbation strength on the resulting captions’ semantic meaning and stylistic characteristics.
read the caption
Table 7: Examples of perturbed prompts and captions after applying different levels of perturbation.
| Method | Pair Caption | Perturbed Level | Pickscore () | HPSv2.1 () | ImageReward () | CLIPscore () | GenEval () |
|---|---|---|---|---|---|---|---|
| DCPO-h | () | weak | 20.10 | 21.23 | 49.7 | 26.87 | 0.5003 |
| DCPO-h | () | weak | 20.32 | 23.4 | 53.8 | 27.06 | 0.5070 |
| DCPO-h | () | medium | 20.31 | 23.08 | 53.2 | 27.01 | 0.4895 |
| DCPO-h | () | medium | 20.33 | 23.22 | 53.8 | 27.09 | 0.5009 |
| DCPO-h | () | strong | 20.31 | 22.95 | 53.1 | 27.11 | 0.4878 |
| DCPO-h | () | strong | 20.35 | 23.24 | 53.63 | 27.08 | 0.5050 |
🔼 This table presents the results of applying different perturbation levels (weak, medium, strong) to the captions generated by the Emu2 model in the Dual Caption Preference Optimization (DCPO) pipeline. It shows how the performance metrics (Pickscore, HPSv2.1, ImageReward, CLIPscore, and GenEval) change when using weakly, moderately, and strongly perturbed captions for both preferred and less preferred images. This helps analyze the impact of perturbation strength on the overall performance of the DCPO method.
read the caption
Table 8: Results of the perturbation method applied to Emu2 captions across different levels.
| Method | Pickscore () | HPSv2.1 () | ImageReward () | CLIPscore () | GenEval () | |
|---|---|---|---|---|---|---|
| DCPO-h | 500 | 20.43 | 26.42 | 58.1 | 27.02 | 0.5208 |
| DCPO-h | 1000 | 20.51 | 26.12 | 58.2 | 27.10 | 0.4900 |
| DCPO-h | 2500 | 20.53 | 25.81 | 58.0 | 27.02 | 0.5036 |
| DCPO-h | 5000 | 20.57 | 25.62 | 58.2 | 27.13 | 0.5100 |
🔼 This table presents the performance of the Dual Caption Preference Optimization (DCPO-h) method across various values of the hyperparameter β (beta). It shows the impact of different β values on several metrics, including Pickscore, HPSv2.1, ImageReward, CLIPscore, and GenEval, to assess the model’s performance in generating high-quality images that align well with user preferences. The results help determine the optimal β value that balances model alignment and performance.
read the caption
Table 9: Results of DCPO-h across different β𝛽\betaitalic_β.
Full paper#