TL;DR#
Large Language Models (LLMs) like Transformers struggle with long-context reasoning and complex multi-step inference. Existing solutions often sacrifice generalization or introduce significant computational overhead. This paper presents LM2, a novel Transformer architecture integrating an auxiliary memory module.
LM2 enhances the standard Transformer architecture by adding a complementary memory pathway. This memory module interacts with input tokens via cross-attention and updates dynamically via gating mechanisms. LM2 outperforms existing models on the BABILong benchmark (designed for memory-intensive tasks), showing significant improvements in multi-hop reasoning, numerical reasoning, and long-context question answering. Importantly, LM2 also achieves performance gains on the MMLU dataset, demonstrating that its memory enhancements do not come at the cost of general performance.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to enhance the capabilities of Transformer models, addressing limitations in handling long contexts and complex reasoning. The LM2 architecture, with its auxiliary memory module, offers a significant improvement in performance on memory-intensive tasks while maintaining generalizability. This work could significantly impact research in natural language processing, impacting advancements in various applications, and opening up avenues for further exploration into memory-augmented Transformer architectures.
Visual Insights#

🔼 The figure illustrates the architecture of the Large Memory Model (LM2). It shows how a memory bank interacts with the standard Transformer decoder blocks. The memory bank receives input and is updated using input, output, and forget gates, influencing the main information flow through cross-attention. A gray curve depicts the standard Transformer’s attention flow, while a pink curve represents the additional memory flow that augments the original pathway.
read the caption
Figure 1: Illustration of LM2 overall architecture. It consists of a separate memory bank, which updates the main information flow through cross attention, and is updated using the input (ℐℐ\mathcal{I}caligraphic_I), output (𝒪𝒪\mathcal{O}caligraphic_O), and forget (ℱℱ\mathcal{F}caligraphic_F) gates. For the information flow from one block to another, the gray curve shows the normal attention flow and the pink curve shows the extra memory flow.
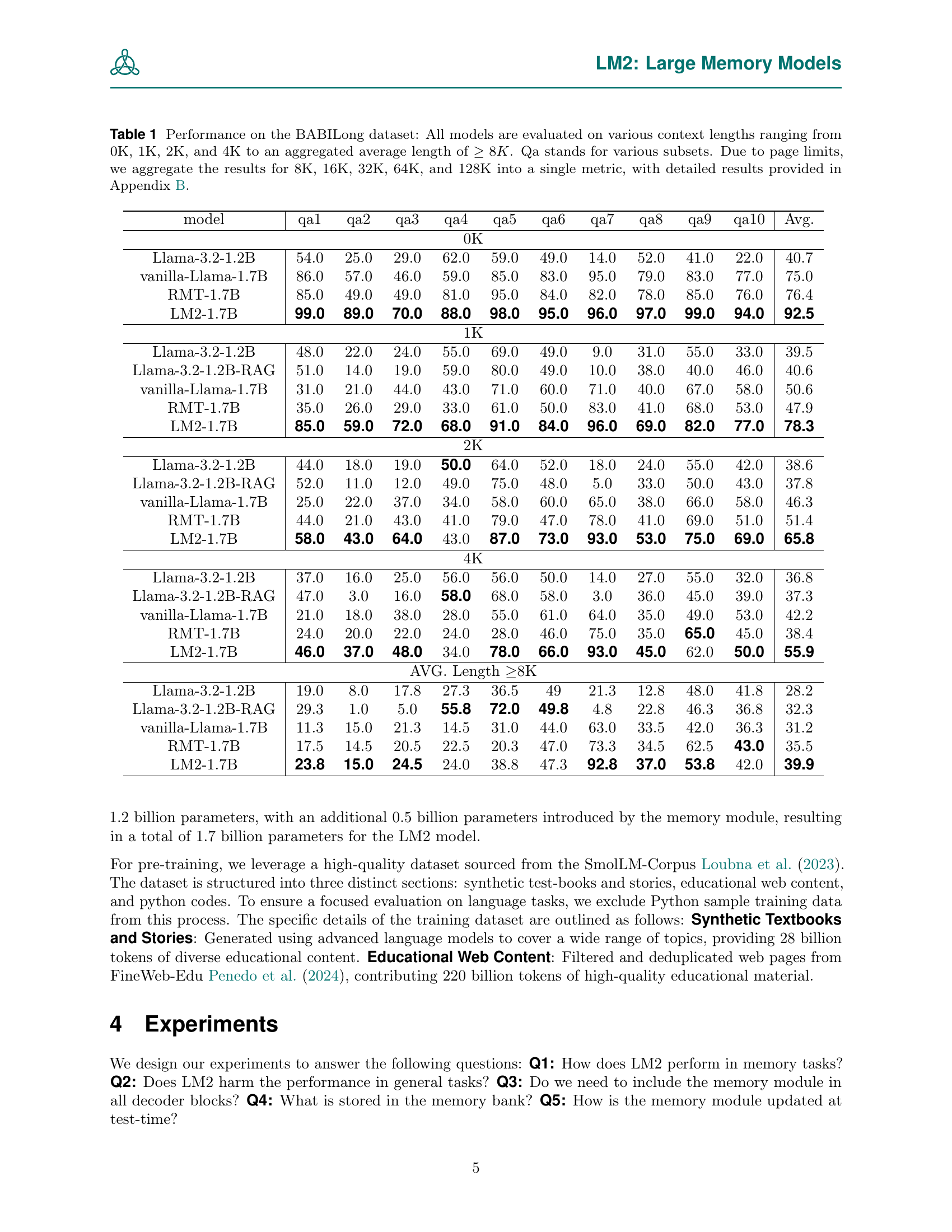
| model | qa1 | qa2 | qa3 | qa4 | qa5 | qa6 | qa7 | qa8 | qa9 | qa10 | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0K | |||||||||||
| Llama-3.2-1.2B | 54.0 | 25.0 | 29.0 | 62.0 | 59.0 | 49.0 | 14.0 | 52.0 | 41.0 | 22.0 | 40.7 |
| vanilla-Llama-1.7B | 86.0 | 57.0 | 46.0 | 59.0 | 85.0 | 83.0 | 95.0 | 79.0 | 83.0 | 77.0 | 75.0 |
| RMT-1.7B | 85.0 | 49.0 | 49.0 | 81.0 | 95.0 | 84.0 | 82.0 | 78.0 | 85.0 | 76.0 | 76.4 |
| LM2-1.7B | 99.0 | 89.0 | 70.0 | 88.0 | 98.0 | 95.0 | 96.0 | 97.0 | 99.0 | 94.0 | 92.5 |
| 1K | |||||||||||
| Llama-3.2-1.2B | 48.0 | 22.0 | 24.0 | 55.0 | 69.0 | 49.0 | 9.0 | 31.0 | 55.0 | 33.0 | 39.5 |
| Llama-3.2-1.2B-RAG | 51.0 | 14.0 | 19.0 | 59.0 | 80.0 | 49.0 | 10.0 | 38.0 | 40.0 | 46.0 | 40.6 |
| vanilla-Llama-1.7B | 31.0 | 21.0 | 44.0 | 43.0 | 71.0 | 60.0 | 71.0 | 40.0 | 67.0 | 58.0 | 50.6 |
| RMT-1.7B | 35.0 | 26.0 | 29.0 | 33.0 | 61.0 | 50.0 | 83.0 | 41.0 | 68.0 | 53.0 | 47.9 |
| LM2-1.7B | 85.0 | 59.0 | 72.0 | 68.0 | 91.0 | 84.0 | 96.0 | 69.0 | 82.0 | 77.0 | 78.3 |
| 2K | |||||||||||
| Llama-3.2-1.2B | 44.0 | 18.0 | 19.0 | 50.0 | 64.0 | 52.0 | 18.0 | 24.0 | 55.0 | 42.0 | 38.6 |
| Llama-3.2-1.2B-RAG | 52.0 | 11.0 | 12.0 | 49.0 | 75.0 | 48.0 | 5.0 | 33.0 | 50.0 | 43.0 | 37.8 |
| vanilla-Llama-1.7B | 25.0 | 22.0 | 37.0 | 34.0 | 58.0 | 60.0 | 65.0 | 38.0 | 66.0 | 58.0 | 46.3 |
| RMT-1.7B | 44.0 | 21.0 | 43.0 | 41.0 | 79.0 | 47.0 | 78.0 | 41.0 | 69.0 | 51.0 | 51.4 |
| LM2-1.7B | 58.0 | 43.0 | 64.0 | 43.0 | 87.0 | 73.0 | 93.0 | 53.0 | 75.0 | 69.0 | 65.8 |
| 4K | |||||||||||
| Llama-3.2-1.2B | 37.0 | 16.0 | 25.0 | 56.0 | 56.0 | 50.0 | 14.0 | 27.0 | 55.0 | 32.0 | 36.8 |
| Llama-3.2-1.2B-RAG | 47.0 | 3.0 | 16.0 | 58.0 | 68.0 | 58.0 | 3.0 | 36.0 | 45.0 | 39.0 | 37.3 |
| vanilla-Llama-1.7B | 21.0 | 18.0 | 38.0 | 28.0 | 55.0 | 61.0 | 64.0 | 35.0 | 49.0 | 53.0 | 42.2 |
| RMT-1.7B | 24.0 | 20.0 | 22.0 | 24.0 | 28.0 | 46.0 | 75.0 | 35.0 | 65.0 | 45.0 | 38.4 |
| LM2-1.7B | 46.0 | 37.0 | 48.0 | 34.0 | 78.0 | 66.0 | 93.0 | 45.0 | 62.0 | 50.0 | 55.9 |
| AVG. Length 8K | |||||||||||
| Llama-3.2-1.2B | 19.0 | 8.0 | 17.8 | 27.3 | 36.5 | 49 | 21.3 | 12.8 | 48.0 | 41.8 | 28.2 |
| Llama-3.2-1.2B-RAG | 29.3 | 1.0 | 5.0 | 55.8 | 72.0 | 49.8 | 4.8 | 22.8 | 46.3 | 36.8 | 32.3 |
| vanilla-Llama-1.7B | 11.3 | 15.0 | 21.3 | 14.5 | 31.0 | 44.0 | 63.0 | 33.5 | 42.0 | 36.3 | 31.2 |
| RMT-1.7B | 17.5 | 14.5 | 20.5 | 22.5 | 20.3 | 47.0 | 73.3 | 34.5 | 62.5 | 43.0 | 35.5 |
| LM2-1.7B | 23.8 | 15.0 | 24.5 | 24.0 | 38.8 | 47.3 | 92.8 | 37.0 | 53.8 | 42.0 | 39.9 |
🔼 Table 1 presents a comprehensive evaluation of different large language models (LLMs) on the BABILong dataset, a benchmark designed to assess reasoning capabilities with long contexts. The table shows the performance of various models across different context lengths, ranging from short contexts (0K tokens, equivalent to the original bAbI dataset) to extremely long contexts (up to 128K tokens). Multiple model variations are compared, including a baseline Llama model, a memory-augmented version (RMT), and the proposed LM2 model. The results are broken down by individual questions (qa1-qa10), and an average performance score is also shown. Due to space limitations, results for very long contexts (8K, 16K, 32K, 64K, and 128K tokens) are aggregated into a single average metric, with the full details available in Appendix B.
read the caption
Table 1: Performance on the BABILong dataset: All models are evaluated on various context lengths ranging from 0K, 1K, 2K, and 4K to an aggregated average length of ≥8Kabsent8𝐾\geq 8K≥ 8 italic_K. Qa stands for various subsets. Due to page limits, we aggregate the results for 8K, 16K, 32K, 64K, and 128K into a single metric, with detailed results provided in Appendix B.
In-depth insights#
LM2’s Memory Flow#
LM2’s memory flow is a crucial aspect of its design, dynamically interacting with the Transformer’s original information flow rather than replacing it. This design choice allows LM2 to leverage the strengths of the Transformer architecture while adding the benefits of explicit memory. The memory information is carefully integrated using cross-attention, allowing the model to retrieve and utilize relevant past information. Learnable gates (input, forget, and output) control the flow of information, ensuring that the memory is updated efficiently and relevantly, while also preventing the model from overwriting or forgetting essential information. The interaction is carefully managed via skip connections, ensuring that the standard attention mechanisms are not disrupted, maintaining the model’s general-purpose capabilities and enhancing performance in demanding tasks. The system’s efficiency comes from its ability to focus on the most salient past information and avoids the inherent problems of simply feeding previous answers as prompts, which leads to degraded performance.
Memory Updates#
The section on “Memory Updates” would detail the mechanisms by which the memory module in the LM2 model is dynamically updated. This is crucial because it addresses a key limitation of previous memory-augmented models: the inability to efficiently manage and update long-term context over extended sequences. The authors likely describe a gated mechanism, similar to those found in LSTMs, involving input, forget, and output gates. The input gate determines how much new information is added, filtering out noise or redundant details. The forget gate controls which information is discarded, preventing the overwriting of crucial long-term facts. Finally, the output gate regulates the flow of memory information into the main Transformer network. This carefully controlled update process is key to LM2’s success, balancing the incorporation of new information with the preservation of relevant context, a significant improvement over simply appending or summarizing previous responses.
BABILong Results#
The BABILong results section would be crucial in evaluating the Large Memory Model (LM2)’s performance. It would likely present quantitative results comparing LM2 against various baselines (e.g., standard Transformers, other memory-augmented models) across multiple metrics relevant to long-context reasoning tasks. Key aspects to analyze would include performance trends across different context lengths, highlighting how LM2’s performance changes as the amount of input text increases. This is important because the primary goal of LM2 is to overcome limitations in handling long contexts. Furthermore, a breakdown of performance by task type within BABILong would be vital. BABILong likely includes diverse tasks requiring various levels of reasoning and memory access. Analyzing LM2’s strengths and weaknesses across these tasks would provide a nuanced understanding of its capabilities and limitations. Finally, statistical significance testing should accompany any reported performance differences, ensuring the results are robust and not simply due to random variation. The discussion of these findings would likely highlight the impact of the memory module on enabling LM2 to effectively utilize long-term information, drawing connections to the model’s architecture and design choices.
MMLU Performance#
The MMLU (Massive Multitask Language Understanding) performance section of the research paper is crucial for evaluating the robustness and generalization capabilities of the proposed LM2 model beyond specialized memory tasks. A key insight would be the comparison of LM2’s performance against a vanilla Transformer model and a memory-augmented model (e.g., RMT) on MMLU. This comparison would reveal whether incorporating the memory module enhances general language understanding or hinders performance in diverse tasks. A significant finding would be if LM2 demonstrates superior or comparable performance on MMLU compared to the vanilla Transformer, showing that the memory module doesn’t compromise its ability to handle general tasks. Conversely, if performance is significantly lower on MMLU than the vanilla model, it suggests that the added memory mechanism interferes with generalization abilities. The detailed breakdown of results across various MMLU subjects and difficulty levels will offer valuable insights into the model’s strengths and weaknesses. Analyzing the results could reveal subject-specific impacts of the memory module, possibly revealing which types of reasoning benefit the most or are negatively affected. Overall, the MMLU results section should offer a complete assessment of the LM2 model’s practical applicability and general language understanding beyond its targeted strengths in memory-intensive tasks.
Memory Analysis#
A dedicated memory analysis section in a research paper would ideally delve into several key aspects. It should begin by describing the memory architecture itself, detailing its design choices and how it integrates with the core model architecture. A crucial element would be the methodology used to analyze the memory’s contents and behavior. This may involve techniques like probing the memory representations with specifically designed prompts or leveraging visualization methods to understand internal activations. The analysis should present concrete results, showing quantitative metrics like accuracy improvements or efficiency gains attributable to the memory module. Qualitative insights are equally important; this section should discuss what types of information the memory effectively stores and how the memory’s contents evolve during the processing of complex tasks. Finally, the analysis must interpret the findings, explaining how the observed results relate to the overarching goals of the research and contribute to a deeper understanding of memory augmentation in models.
More visual insights#
More on figures

🔼 This figure illustrates the memory module’s operation within a single decoding block of the LM2 model. The memory module is composed of three phases: the input phase (green), forget phase (blue), and output phase (red). The input phase determines how much new information is added to the memory bank. The forget phase decides which parts of the existing memory are discarded. Finally, the output phase regulates how much memory information is passed to the next decoder layer. The figure visually represents these three phases as separate components interacting with the input and output embeddings of the decoder block.
read the caption
Figure 2: Illustration of how memory module works inside of each decoding block, where blue, green, and red box corresponds to forget, input, and output phase.

🔼 This radar chart visualizes the performance of different models on the BABILong benchmark, categorized by various reasoning capabilities. Each axis represents a specific reasoning task: Single-step Reasoning, Multi-step Reasoning, Relation Tracking, Basic Queries, and Negation & Uncertainty. The length of each spoke indicates the model’s performance on that task. The chart allows for a direct comparison of the relative strengths and weaknesses of each model across different reasoning skills.
read the caption
Figure 3: Performance on BABILong benchmark with different capabilities.

🔼 Figure 4 shows an example of a question from the MMLU benchmark used to evaluate the LM2 model. The question is presented in a few-shot learning setting, meaning a few examples are given before the actual question. Critically, useful information relevant to answering the target question is deliberately included within one of the example questions. This experimental setup allows the researchers to analyze how the memory module within the LM2 model focuses on and retrieves relevant information when answering the question. By strategically placing relevant information within the examples, the researchers can better understand how the memory module functions during the question-answering process.
read the caption
Figure 4: We sample a question from MMLU to test the LM2 in a few-shot fashion. To study how the memory module focuses on relevant information, we place useful information inside one of the few-shot examples.

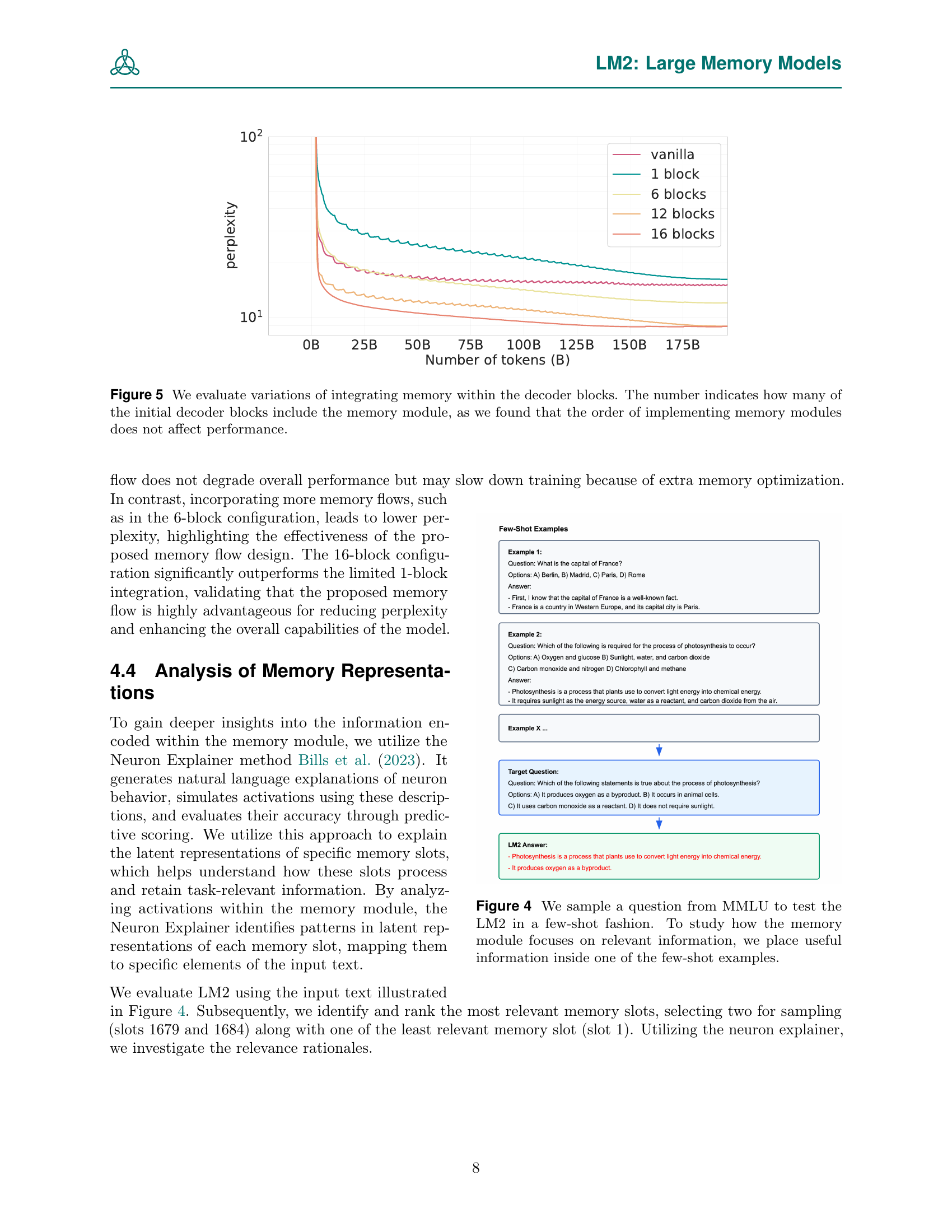
🔼 This figure displays the results of an experiment evaluating the impact of integrating a memory module into different numbers of decoder blocks within a transformer-based language model. The x-axis represents the number of training tokens (in billions), and the y-axis shows the perplexity scores. Multiple lines are plotted, each representing a different configuration where the memory module is included in varying numbers of initial decoder blocks (1, 6, 12, or all 16). The purpose is to analyze how incorporating the memory mechanism in different layers of the architecture affects model performance and training efficiency. The results show that including the memory module in more blocks leads to lower perplexity, but that including it in only one block significantly slows training.
read the caption
Figure 5: We evaluate variations of integrating memory within the decoder blocks. The number indicates how many of the initial decoder blocks include the memory module, as we found that the order of implementing memory modules does not affect performance.

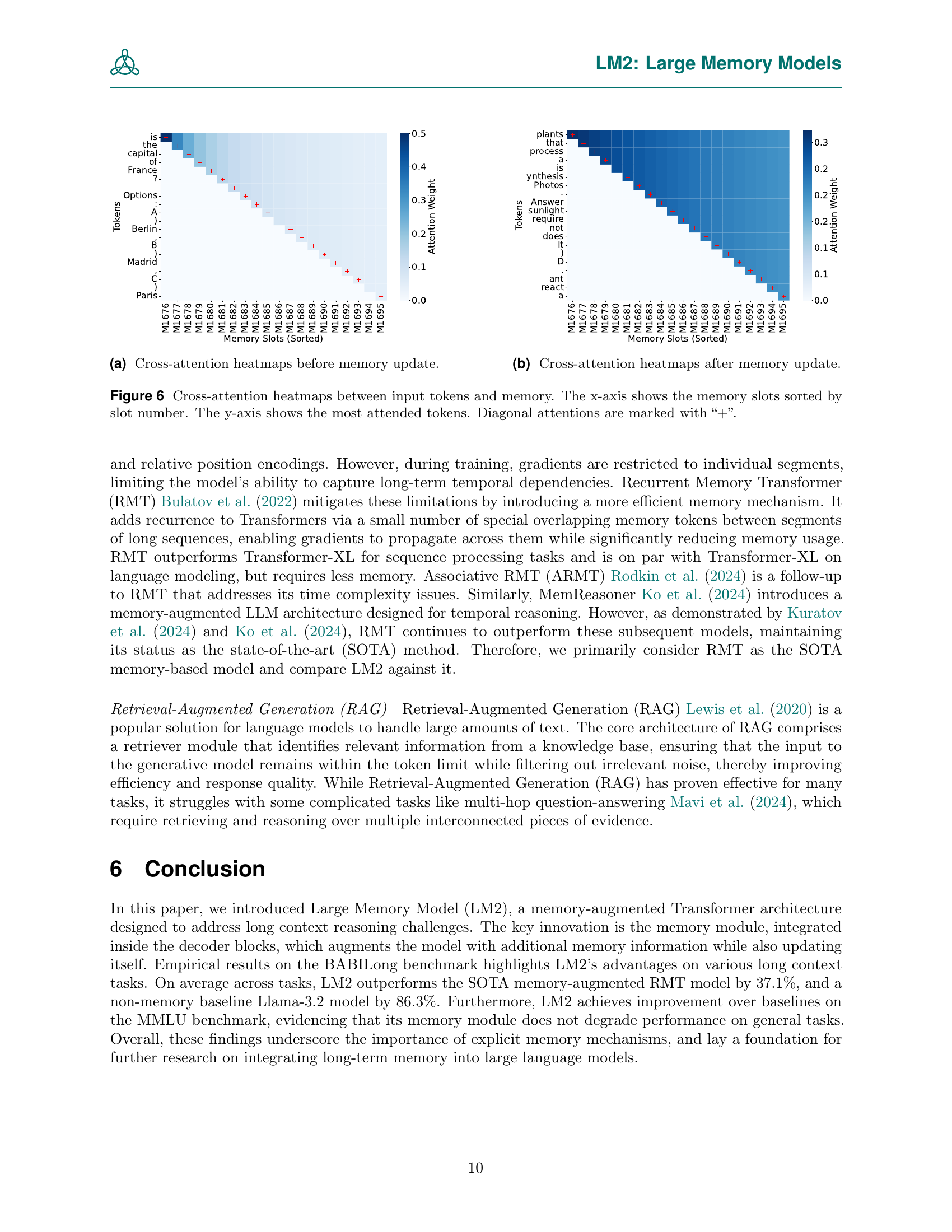
🔼 This figure shows cross-attention heatmaps between input tokens and memory slots. Panel (a) displays the heatmap before any memory updates have been applied during the model’s inference process. This visualization helps to understand which parts of the input text are initially most strongly associated with different memory locations. The heatmap uses color intensity to represent the strength of the cross-attention weights, with darker colors indicating stronger associations.
read the caption
(a) Cross-attention heatmaps before memory update.

🔼 This figure shows a heatmap visualization of cross-attention weights between input tokens and memory slots in the LM2 model after the memory has been updated. The heatmap displays the attention weights, indicating the strength of the relationships between different input tokens and memory slots. The x-axis represents the memory slots, ordered numerically, while the y-axis represents the input tokens. Warmer colors (e.g., red) represent stronger attention weights, signifying a greater influence of the memory slot on the corresponding input token, while cooler colors (e.g., blue) represent weaker attention weights. Comparing this figure with Figure 6a (before memory update) helps illustrate the dynamic nature of the memory’s interaction with the input during the generation process. This change demonstrates the model’s ability to adapt memory focus based on context.
read the caption
(b) Cross-attention heatmaps after memory update.
More on tables
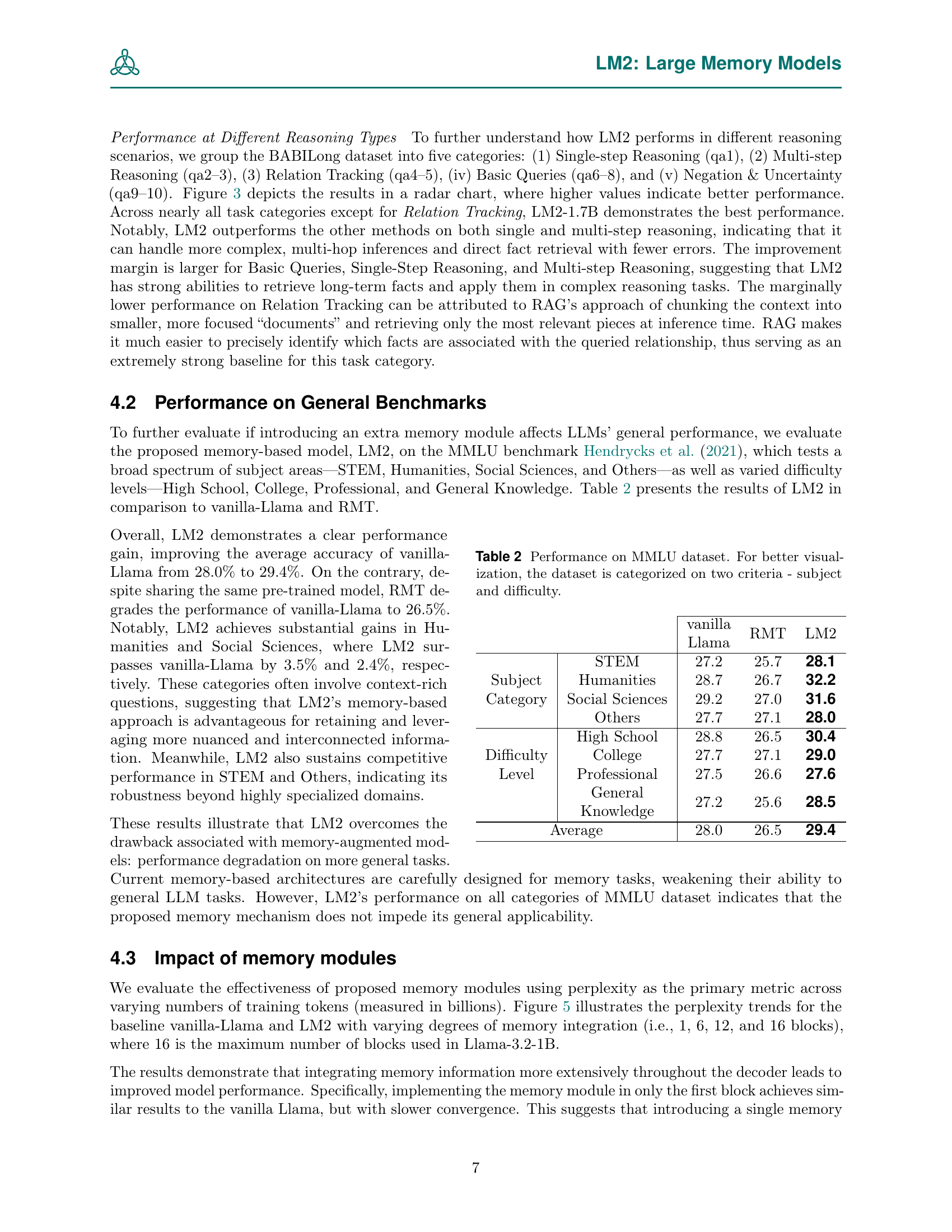
| RMT | LM2 | ||||
| Subject Category | STEM | 27.2 | 25.7 | 28.1 | ||
| Humanities | 28.7 | 26.7 | 32.2 | |||
| Social Sciences | 29.2 | 27.0 | 31.6 | |||
| Others | 27.7 | 27.1 | 28.0 | |||
| Difficulty Level | High School | 28.8 | 26.5 | 30.4 | ||
| College | 27.7 | 27.1 | 29.0 | |||
| Professional | 27.5 | 26.6 | 27.6 | |||
| 27.2 | 25.6 | 28.5 | |||
| Average | 28.0 | 26.5 | 29.4 | |||
🔼 This table presents the results of the Large Memory Model (LM2) and baseline models on the Massive Multitask Language Understanding (MMLU) benchmark. MMLU tests a wide range of subjects (STEM, Humanities, Social Sciences, and Others) and difficulty levels (High School, College, Professional, and General Knowledge). The table categorizes the MMLU dataset by subject and difficulty level to provide a more detailed performance comparison, highlighting how the models perform across different domains and challenge levels. This allows for a nuanced evaluation of the LM2’s ability to generalize across various tasks and difficulty levels compared to the baseline models.
read the caption
Table 2: Performance on MMLU dataset. For better visualization, the dataset is categorized on two criteria - subject and difficulty.
| vanilla |
| Llama |
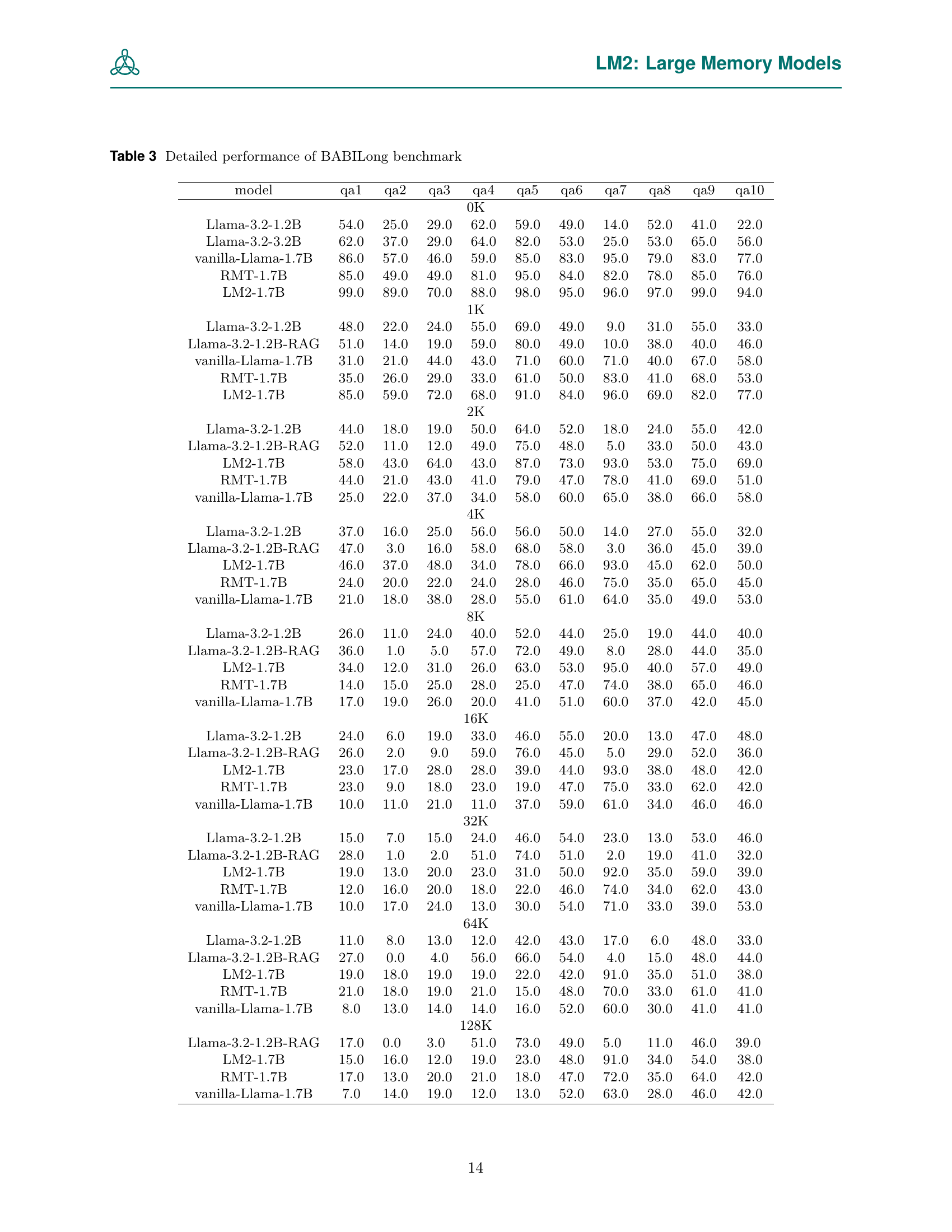
🔼 Table 3 presents a detailed breakdown of the BABILong benchmark results. It shows the performance of several models across various tasks within the BABILong dataset, categorized by context length. The models evaluated include Llama-3.2-1.2B, Llama-3.2-1.2B-RAG (Retrieval Augmented Generation), vanilla-Llama-1.7B, RMT-1.7B (Recurrent Memory Transformer), and LM2-1.7B. The context lengths range from 0K (equivalent to the original bAbI dataset) to 128K tokens. The table allows for a granular comparison of model performance across different task types and context lengths, revealing trends in performance for both memory-intensive and non-memory-intensive models.
read the caption
Table 3: Detailed performance of BABILong benchmark
Full paper#