TL;DR#
Many existing methods for training AI agents to communicate naturally in multi-agent settings are limited because they rely on large amounts of human-demonstration data or fail to generate natural and useful communication strategies. This research paper addresses these limitations by training language models to engage in productive discussions within an embodied social deduction game. The core issue is that traditional methods struggle with sparse reward signals, making it difficult for agents to learn effective communication skills.
The researchers introduce a novel method that decomposes the communication problem into ’listening’ and ‘speaking’. They utilize the agents’ goals to predict useful world information, generating a dense reward signal to guide communication. This improves ’listening’ by training models to predict environmental information from discussions. Simultaneously, multi-agent reinforcement learning improves ‘speaking’ by rewarding messages based on their influence on other agents. The results demonstrate significant improvement in discussion quality and a substantial increase in the win rate for the agents, highlighting the effectiveness of this novel training approach.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to training language models for effective communication in complex social settings. It addresses the challenge of sparse reward signals in multi-agent reinforcement learning by introducing auxiliary reward signals. The work also demonstrates the effectiveness of using large language models as agents, opening up new avenues for research in emergent communication and human-AI interaction. The findings have implications for building more natural and effective AI agents that can collaborate with humans.
Visual Insights#
| Our Base Model | Original RWKV | |||||
|---|---|---|---|---|---|---|
| Model Size | Accuracy | PPL | PPL | Accuracy | PPLWorld | PPLLam |
| 169 M | 0.60 | 0.34 | 45.1 | 0.15 | 4.4 | 27.5 |
| 430 M | 0.61 | 0.30 | 19.6 | 0.18 | 2.9 | 11.2 |
| 1.5 B | 0.62 | 0.28 | 7.3 | 0.20 | 2.4 | 6.2 |
| 3 B | 0.64 | 0.23 | 6.2 | 0.14 | 2.0 | 4.8 |
| 7 B | 0.65 | 0.22 | 5.2 | 0.22 | 2.0 | 4.1 |
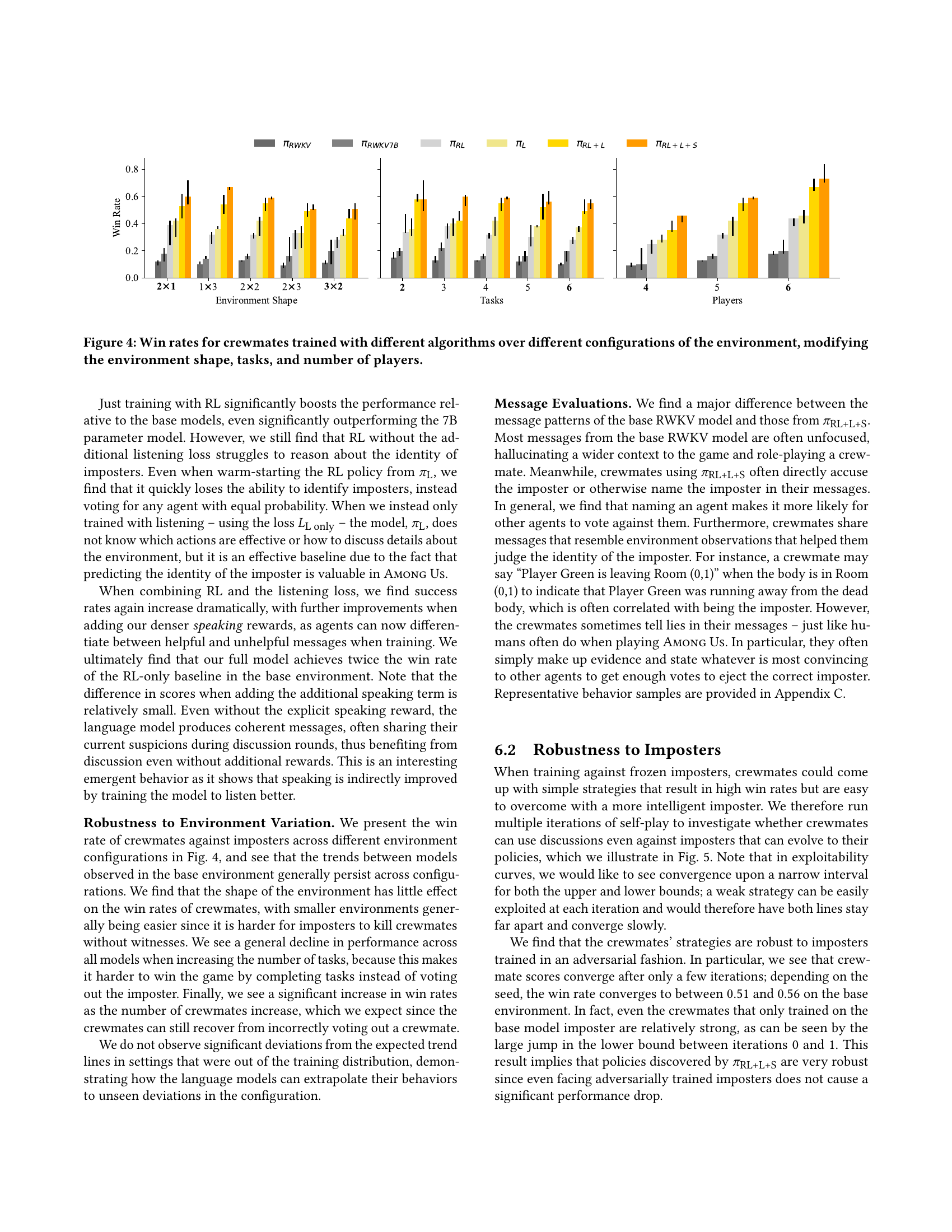
🔼 This table presents the results of scaling experiments conducted on RWKV language models of varying sizes (169M, 430M, 1.5B, 3B, and 7B parameters). The goal was to assess how model size affects performance in a custom Among Us environment. The table shows the accuracy of each model in the environment, along with its perplexity scores for predicting environmental observations (PPLWorld) and for the standard LAMBADA language modeling benchmark (PPLLAM). Lower perplexity values indicate better performance. The results highlight the diminishing returns in performance gains as model size increases beyond a certain point, providing insights into the optimal model size for this specific task.
read the caption
Table 1. Scaling performance for the RWKV base model. PPLWorldWorld{}_{\text{World}}start_FLOATSUBSCRIPT World end_FLOATSUBSCRIPT refers to the perplexity of predicting observation tokens in the environment, which correlates with a model’s ability to understand its environment. PPLLAMLAM{}_{\text{LAM}}start_FLOATSUBSCRIPT LAM end_FLOATSUBSCRIPT refers to the lambada evaluation perplexity.
Full paper#