TL;DR#
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs in finance. It introduces FailSafeQA, a novel benchmark for evaluating LLM robustness and context awareness in real-world scenarios, addressing critical limitations of existing benchmarks. Its findings highlight the need for improved LLM dependability in finance, paving the way for future research in LLM resilience and safety.
Visual Insights#

🔼 Figure 1 illustrates the FailSafeQA benchmark, designed to assess the robustness and context grounding of LLMs in a financial QA setting. It focuses on two scenarios: Query Failure and Context Failure. Query Failure tests the LLM’s ability to handle variations in the input query, such as spelling errors (Misspelled Query), incomplete queries (Incomplete Query), and queries phrased in non-domain-specific language (Out-of-Domain Query). Context Failure simulates real-world challenges where users may provide incomplete (Missing Context), low-quality (OCRed Context), or irrelevant (Irrelevant Context) documents. The figure shows how these perturbations affect LLM responses. Robustness is measured by consistent performance across Query Failure scenarios (A-C and E), while Context Grounding evaluates the ability to avoid hallucinations when facing Context Failure (D and F).
read the caption
Figure 1: FailSafeQA: Robustness and Context Grounding Evaluation We evaluate the resilience of an LLM-based QA system in two case studies: Query Failure and Context Failure. In the Query Failure scenario, we perturb the original query into three variants: containing spelling errors (Misspelled Query), query-term form (Incomplete Query), rephrased to exclude in-domain terminology (Out-of-Domain Query). In the Context Failure case, we assume users can either fail to upload the document (Missing Context) , use degraged quality documents due to OCR (OCRed Context) or upload a document irrelevant to the query (Irrelevant Context). Robustness involves maintaining consistent model performance across perturbations (A)-(C) and (E), which preserve the intended meaning, while Context Grounding involves preventing hallucinations in scenarios (D) and (F).
| Model Name | Baseline | Mispelled () | Incomplete () | Out-of-Domain () | OCR Context () | Robustness () |
|---|---|---|---|---|---|---|
| Gemini 2.0 Flash Exp | 0.95 | 0.95 (0.0) | 0.95 (0.0) | 0.88 (0.07) | 0.91 (0.04) | 0.83 (0.12) |
| Gemini 1.5 Pro 002 | 0.96 | 0.96 (0.0) | 0.94 (0.02) | 0.92 (0.04) | 0.92 (0.04) | 0.84 (0.12) |
| OpenAI GPT-4o | 0.95 | 0.94 (0.01) | 0.94 (0.01) | 0.92 (0.03) | 0.95 (0.0) | 0.85 (0.1) |
| OpenAI o1 | 0.97 | 0.95 (0.02) | 0.94 (0.03) | 0.89 (0.08) | 0.94 (0.03) | 0.81 (0.16) |
| OpenAI o3-mini | 0.98 | 0.96 (0.02) | 0.96 (0.02) | 0.95 (0.03) | 0.90 (0.08) | 0.90 (0.08) |
| DeepSeek-R1-Distill-Llama-8B | 0.83 | 0.85 (0.02) | 0.82 (0.01) | 0.87 (0.04) | 0.72 (0.11) | 0.64 (0.19) |
| DeepSeek-R1-Distill-Qwen-14B | 0.95 | 0.90 (0.05) | 0.92 (0.03) | 0.93 (0.02) | 0.86 (0.09) | 0.82 (0.13) |
| DeepSeek-R1-Distill-Qwen-32B | 0.95 | 0.97 (0.02) | 0.95 (0.0) | 0.92 (0.03) | 0.89 (0.06) | 0.86 (0.09) |
| DeepSeek-R1-Distill-Llama-70B | 0.96 | 0.97 (0.01) | 0.95 (0.01) | 0.94 (0.02) | 0.93 (0.03) | 0.89 (0.07) |
| DeepSeek-R1 | 0.94 | 0.94 (0.0) | 0.93 (0.01) | 0.91 (0.03) | 0.88 (0.06) | 0.80 (0.14) |
| Meta-Llama-3.1-8B-Instruct | 0.91 | 0.90 (0.01) | 0.86 (0.05) | 0.82 (0.09) | 0.80 (0.11) | 0.70 (0.21) |
| Meta-Llama-3.1-70B-Instruct | 0.94 | 0.92 (0.02) | 0.94 (0.0) | 0.87 (0.07) | 0.88 (0.06) | 0.80 (0.14) |
| Meta-Llama-3.3-70B-Instruct | 0.95 | 0.92 (0.03) | 0.93 (0.02) | 0.90 (0.05) | 0.89 (0.06) | 0.82 (0.13) |
| Qwen2.5-7B-Instruct | 0.92 | 0.91 (0.01) | 0.90 (0.02) | 0.85 (0.07) | 0.80 (0.12) | 0.75 (0.17) |
| Qwen2.5-14B-Instruct | 0.95 | 0.94 (0.01) | 0.94 (0.01) | 0.94 (0.01) | 0.88 (0.07) | 0.86 (0.09) |
| Qwen2.5-32B-Instruct | 0.95 | 0.94 (0.01) | 0.93 (0.02) | 0.92 (0.03) | 0.92 (0.03) | 0.85 (0.1) |
| Qwen2.5-72B-Instruct | 0.94 | 0.94 (0.0) | 0.94 (0.0) | 0.92 (0.02) | 0.91 (0.03) | 0.84 (0.1) |
| Qwen2.5-7B-Instruct-1M | 0.91 | 0.91 (0.0) | 0.91 (0.0) | 0.86 (0.05) | 0.77 (0.14) | 0.74 (0.17) |
| Qwen2.5-14B-Instruct-1M | 0.95 | 0.92 (0.03) | 0.91 (0.04) | 0.91 (0.04) | 0.89 (0.06) | 0.80 (0.15) |
| Nemotron-70B-Instruct-HF | 0.94 | 0.94 (0.0) | 0.93 (0.01) | 0.90 (0.04) | 0.91 (0.03) | 0.82 (0.12) |
| Phi-3-mini-128k-Instruct | 0.86 | 0.85 (0.01) | 0.78 (0.08) | 0.79 (0.07) | 0.69 (0.17) | 0.58 (0.28) |
| Phi-3-small-128k-Instruct | 0.88 | 0.84 (0.04) | 0.88 (0.0) | 0.83 (0.05) | 0.78 (0.1) | 0.70 (0.18) |
| Phi-3-medium-128k-Instruct | 0.89 | 0.84 (0.05) | 0.84 (0.05) | 0.81 (0.08) | 0.72 (0.17) | 0.63 (0.26) |
| Palmyra-Fin-128k-Instruct | 0.96 | 0.93 (0.03) | 0.92 (0.04) | 0.90 (0.06) | 0.89 (0.07) | 0.83 (0.13) |
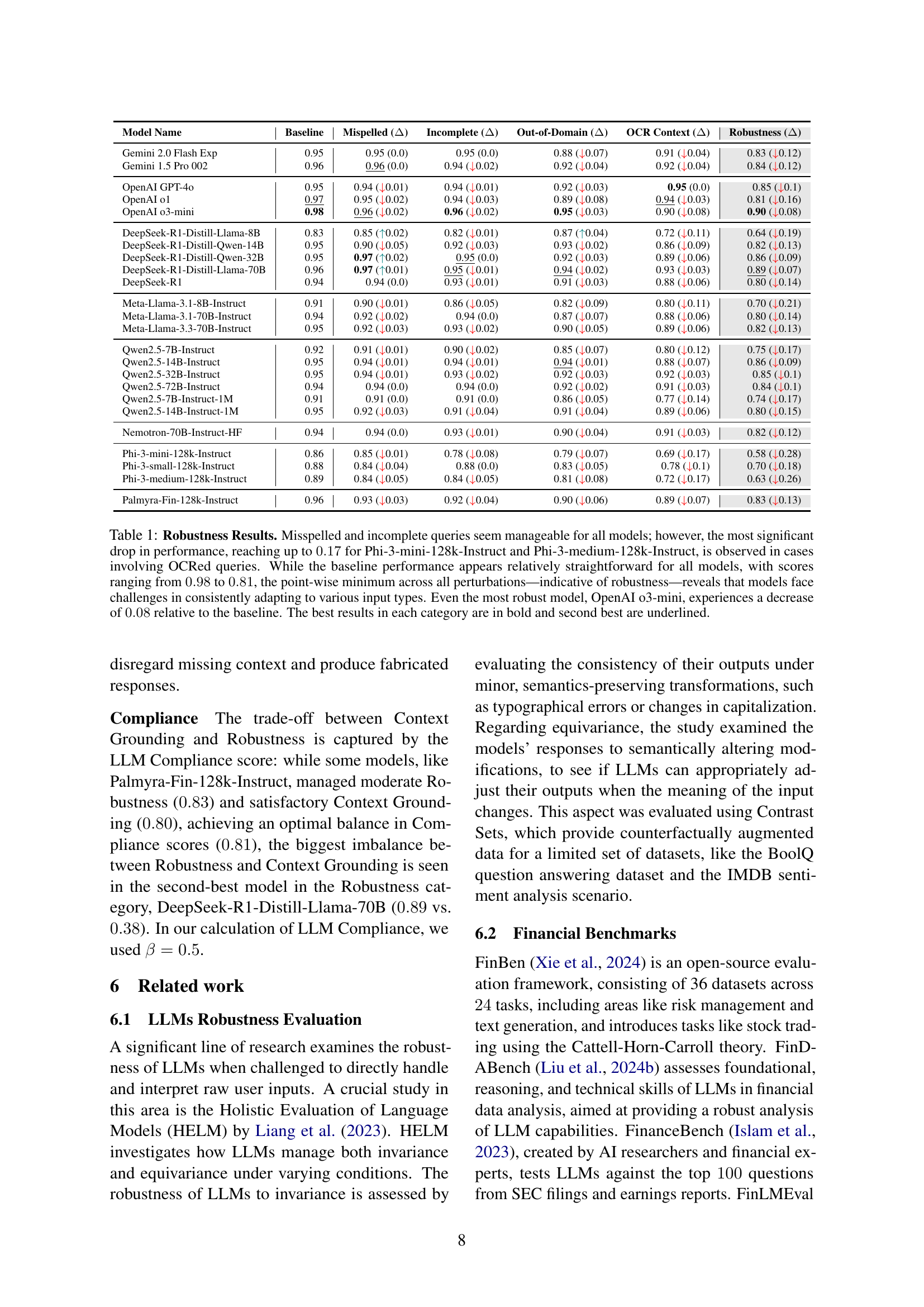
🔼 This table presents the robustness results of various LLMs evaluated on the FailSafeQA benchmark. The benchmark tests the models’ ability to handle different types of input perturbations, specifically misspelled queries, incomplete queries, out-of-domain queries, and OCR-corrupted contexts. The table shows that while minor query variations (misspelled or incomplete) pose minimal challenges, OCR-corrupted contexts lead to the most significant performance drops, highlighting the models’ vulnerability to noisy inputs. Even high-performing models experience noticeable decreases in accuracy compared to their baseline performance under ideal conditions. The results illustrate the difficulties that LLMs face in consistently adapting to diverse input variations and emphasize the importance of robustness in real-world applications.
read the caption
Table 1: Robustness Results. Misspelled and incomplete queries seem manageable for all models; however, the most significant drop in performance, reaching up to 0.170.170.170.17 for Phi-3-mini-128k-Instruct and Phi-3-medium-128k-Instruct, is observed in cases involving OCRed queries. While the baseline performance appears relatively straightforward for all models, with scores ranging from 0.980.980.980.98 to 0.810.810.810.81, the point-wise minimum across all perturbations—indicative of robustness—reveals that models face challenges in consistently adapting to various input types. Even the most robust model, OpenAI o3-mini, experiences a decrease of 0.080.080.080.08 relative to the baseline. The best results in each category are in bold and second best are underlined.
In-depth insights#
FailSafeQA Benchmark#
The FailSafeQA benchmark emerges as a critical evaluation tool designed to assess the robustness and reliability of Large Language Models (LLMs) specifically within the financial domain. Unlike traditional benchmarks focusing on ideal conditions, FailSafeQA simulates real-world scenarios by introducing variations in human-computer interactions and data quality. Its focus on query and context failures, along with a fine-grained scoring system encompassing robustness, grounding, and compliance, offers a holistic perspective on LLM performance. This approach allows researchers to understand the trade-offs inherent in building dependable models, highlighting the strengths and limitations of various LLMs. FailSafeQA’s emphasis on real-world problems, particularly the potential for hallucination and the handling of imperfect information, makes it a valuable contribution to the field, pushing LLM development toward higher levels of trustworthiness and dependability in high-stakes financial applications. The publicly available dataset further enhances the benchmark’s impact, facilitating broader participation and collaboration in improving the safety and efficacy of LLMs.
LLM Robustness Tests#
LLM robustness tests in research papers are crucial for evaluating the reliability and dependability of large language models (LLMs) across diverse conditions. These tests often involve perturbing inputs (queries, contexts) in various ways to assess the model’s resilience and consistency. For example, researchers might introduce spelling errors, incomplete queries, or out-of-domain prompts to gauge the models’ ability to maintain accuracy. Robustness is essential in real-world applications where unexpected inputs are common. The results of such testing illuminate the strengths and weaknesses of specific LLMs, highlighting areas needing further development. A comprehensive evaluation should include a wide range of perturbation techniques and consider both quantitative (accuracy scores) and qualitative (hallucination analysis) metrics to paint a complete picture of LLM robustness.
Context Grounding#
The concept of ‘Context Grounding’ in the research paper focuses on the ability of large language models (LLMs) to reliably discern between scenarios where a response is appropriate and those where it isn’t, particularly when presented with incomplete or irrelevant contextual information. The paper highlights a crucial trade-off between robustness (maintaining performance under various input perturbations) and context grounding (avoiding hallucinations when context is missing or insufficient). It emphasizes that an ideal model would not only provide accurate answers when given proper context, but also explicitly acknowledge its limitations and refuse to respond when the provided context is inadequate or irrelevant to the question. This aspect is vital for building trustworthy and reliable LLMs, particularly within safety-critical domains like finance, where inaccurate or fabricated information can have severe consequences. The evaluation of context grounding, therefore, is a key factor in assessing the overall dependability of LLMs for real-world applications.
Trade-off Analysis#
A trade-off analysis in the context of a research paper, especially one involving large language models (LLMs), would likely explore the interplay between competing performance metrics. For example, an LLM might excel at generating fluent, grammatically correct text but struggle with factual accuracy, exhibiting a trade-off between fluency and factuality. The analysis would delve into the nature of this compromise: does improved fluency invariably reduce accuracy? Are there specific LLM architectures or training methodologies that better balance these aspects? The paper may quantify these trade-offs using metrics such as precision and recall, or introduce a novel metric designed to capture the balance. A sophisticated trade-off analysis would move beyond simple comparisons, potentially examining different weighting schemes for these metrics, reflecting how the relative importance of fluency and factuality may shift depending on the application or user needs. Contextual factors might also be considered, showing whether these trade-offs vary with different tasks or input data. Overall, a comprehensive trade-off analysis provides valuable insights into the inherent limitations and strengths of LLMs, guiding development efforts towards more robust and versatile systems.
Future of LLMs#
The future of LLMs is multifaceted and brimming with potential. Improved robustness and safety are paramount, requiring advancements in addressing biases, hallucinations, and adversarial attacks. We can anticipate enhanced contextual understanding, enabling LLMs to navigate nuanced situations and complex queries more effectively. Interoperability and integration with other AI systems will be crucial, leading to hybrid models capable of performing diverse tasks beyond the limitations of individual LLMs. Further research into explainability and interpretability will foster trust and transparency. The development of specialized LLMs for specific domains, like finance, will continue to flourish, driving further innovation. Efficient training methodologies are needed to reduce computational costs and environmental impact, pushing the boundaries of scalability. Ultimately, the future of LLMs lies in responsibly harnessing their power to solve real-world problems ethically and effectively.
More visual insights#
More on figures

🔼 Figure 2 presents an analysis of the dataset’s query diversity. It examines the root verbs and their direct objects from the first sentence of each normalized query in the FailSafeQA dataset. The figure highlights the top 20 most frequent verbs and their five most common direct objects, offering insight into the types of tasks represented. Specifically, it reveals that 83% of the tasks fall under question answering (QA), while 17% involve text generation (TG), demonstrating a substantial bias toward QA tasks within the dataset.
read the caption
Figure 2: The Dataset Analysis of root verbs and their direct objects from the first sentence of each normalized query shows the top 20 verbs and their top five direct objects22footnotemark: 2. This distribution can be used as a proxy measure for the diversity of tasks in the dataset, with 83.0% related to question answering (QA) and 17.0% involving text generation (TG).

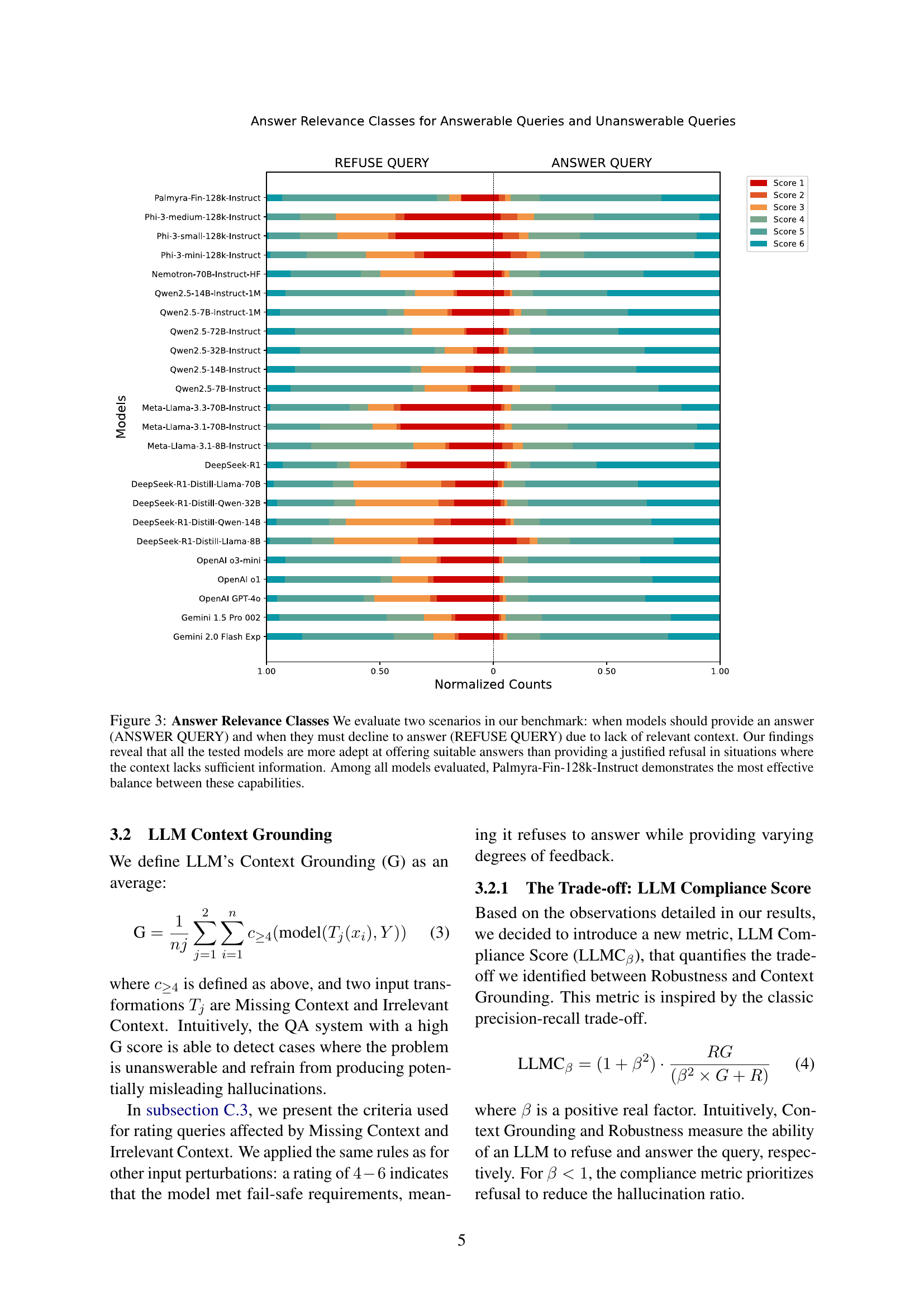
🔼 Figure 3 is a heatmap visualizing the performance of 24 different LLMs on two tasks: answering a question when sufficient context is available (ANSWER QUERY), and appropriately refusing to answer when context is lacking (REFUSE QUERY). The heatmap shows that most LLMs perform better at answering questions than at correctly declining to answer due to insufficient context. The model Palmyra-Fin-128k-Instruct demonstrates the best balance between these two capabilities.
read the caption
Figure 3: Answer Relevance Classes We evaluate two scenarios in our benchmark: when models should provide an answer (ANSWER QUERY) and when they must decline to answer (REFUSE QUERY) due to lack of relevant context. Our findings reveal that all the tested models are more adept at offering suitable answers than providing a justified refusal in situations where the context lacks sufficient information. Among all models evaluated, Palmyra-Fin-128k-Instruct demonstrates the most effective balance between these capabilities.

🔼 Figure 4 presents a comparative analysis of 24 large language models (LLMs) across two key metrics: Robustness and Context Grounding. The left panel illustrates the Robustness of each model, showing a decline in performance compared to a baseline when various input perturbations (misspellings, incomplete queries, out-of-domain queries, OCR errors) are introduced. The figure highlights that the OpenAI 03-mini model exhibits the highest robustness despite this performance drop. The right panel showcases the Context Grounding capabilities of the models. Reasoning models like OpenAI 01/03-mini and the DeepSeek-R1 series achieve scores up to 0.59, while Qwen models consistently outperform them with scores above 0.60. Palmyra-Fin-128k-Instruct demonstrates exceptional Context Grounding, achieving the highest score of 0.80.
read the caption
Figure 4: Robustness and Compliance (Left) All models lose with respect to the baseline when input perturbations are applied. The biggest drop is observed for Out-Of-Domain and OCR context perturbations. Among the 24242424 tested models, OpenAI o3-mini is the most robust. (Right) Reasoning models like OpenAI-o1/o3-mini and the DeepSeek-R1 series reach scores up to 0.590.590.590.59, while Qwen models consistently surpass 0.600.600.600.60. Palmyra-Fin-128k-Instruct excels with the highest Context Grounding score of 0.800.800.800.80.

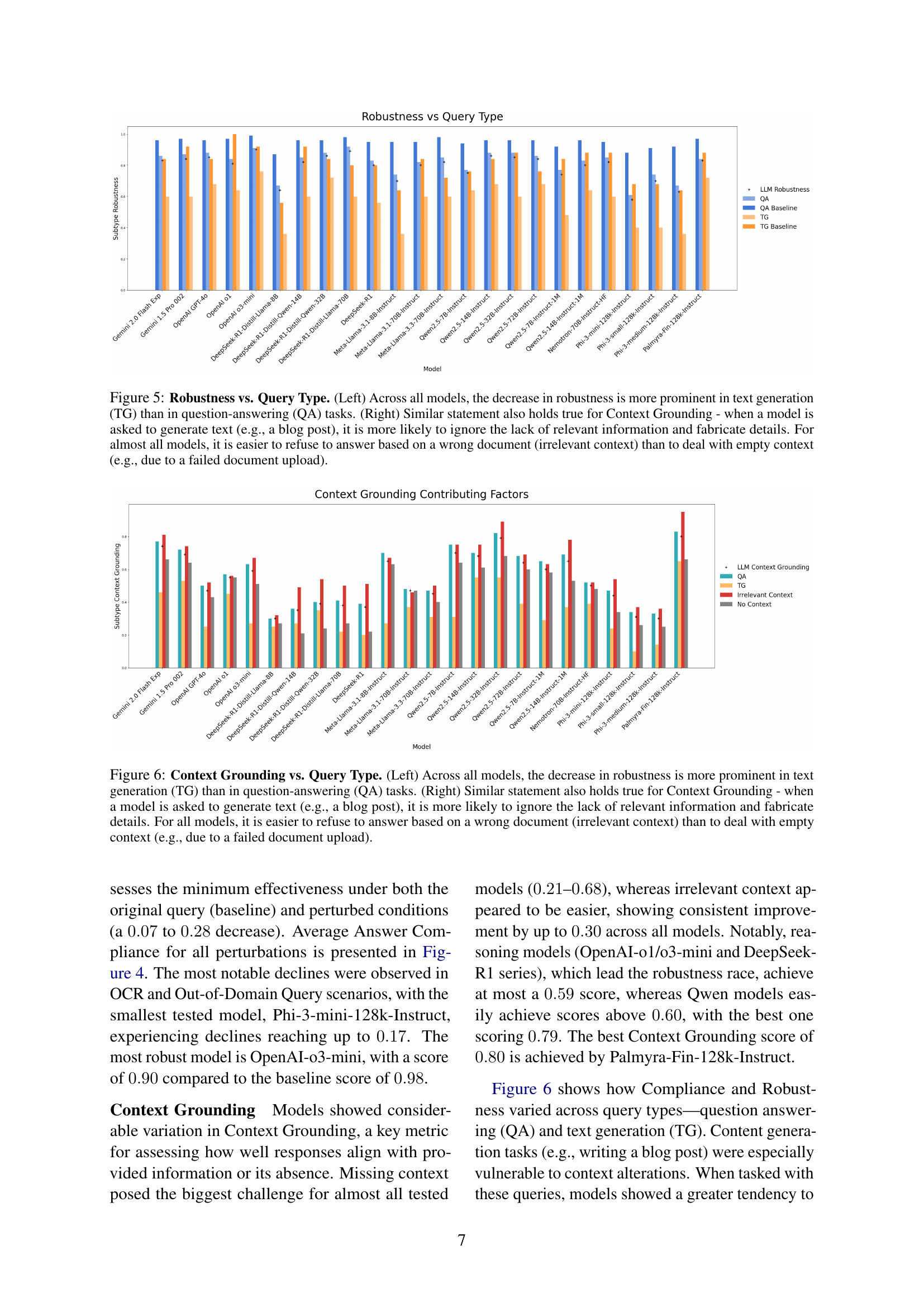
🔼 Figure 5 presents a comparison of model performance across different query types (question answering vs. text generation) and input conditions (presence or absence of context). The left panel illustrates that the drop in robustness is more significant for text generation tasks than for question answering tasks, indicating that models struggle more to provide consistent, accurate responses when generating text rather than answering factual questions. The right panel focuses on context grounding, showing that models are more likely to hallucinate details when generating text, ignoring the absence of relevant information. In contrast, when faced with an empty or irrelevant context, models tend to correctly refuse to answer.
read the caption
Figure 5: Robustness vs. Query Type. (Left) Across all models, the decrease in robustness is more prominent in text generation (TG) than in question-answering (QA) tasks. (Right) Similar statement also holds true for Context Grounding - when a model is asked to generate text (e.g., a blog post), it is more likely to ignore the lack of relevant information and fabricate details. For almost all models, it is easier to refuse to answer based on a wrong document (irrelevant context) than to deal with empty context (e.g., due to a failed document upload).

🔼 Figure 6 presents a comparative analysis of how different Large Language Models (LLMs) perform on two tasks: question answering (QA) and text generation (TG), under varying conditions of context relevance. The left panel shows that the drop in model performance (robustness) is generally more pronounced for text generation when compared to question answering. The right panel demonstrates that the ability of LLMs to effectively recognize and handle irrelevant or missing contextual information is also significantly impacted by the task type, with text generation exhibiting a greater tendency to ignore the lack of relevant information and generate fabricated content. Models find it easier to decline answering a question when provided with an irrelevant document than when dealing with a missing document.
read the caption
Figure 6: Context Grounding vs. Query Type. (Left) Across all models, the decrease in robustness is more prominent in text generation (TG) than in question-answering (QA) tasks. (Right) Similar statement also holds true for Context Grounding - when a model is asked to generate text (e.g., a blog post), it is more likely to ignore the lack of relevant information and fabricate details. For all models, it is easier to refuse to answer based on a wrong document (irrelevant context) than to deal with empty context (e.g., due to a failed document upload).
Full paper#