TL;DR#
Multilingual text detoxification is hampered by limited parallel datasets. Existing methods struggle with cross-lingual transfer and data scarcity, hindering the development of robust multilingual models that effectively mitigate online toxicity across languages. This is a critical issue given the global reach of online hate speech and the need for effective countermeasures.
This research addresses this data scarcity by introducing SynthDetoxM, a novel, large-scale multilingual parallel text detoxification dataset generated using modern large language models (LLMs) and a few-shot prompting technique. The dataset significantly outperforms existing resources, demonstrating the effectiveness of this approach for data augmentation. This framework and dataset represent a substantial contribution, enabling further development and evaluation of multilingual text detoxification models and advancing research in ethical AI.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the scarcity of multilingual parallel data for text detoxification, a major hurdle in the field. By introducing SynthDetoxM, a large-scale synthetic dataset, and a novel generation framework, it significantly advances research and opens doors for more effective multilingual models. This is highly relevant to current trends in cross-lingual NLP and ethical AI.
Visual Insights#

🔼 This figure illustrates the process of creating the SynthDetoxM multilingual text detoxification dataset. It starts with collecting multilingual toxic data from various sources. This data is then processed using several modern large language models (LLMs) via few-shot prompting to generate corresponding detoxified text. The LLM-generated detoxification candidates are scored and filtered based on quality metrics such as toxicity and semantic similarity to the original text. Finally, the best detoxification candidates are selected to form the SynthDetoxM dataset.
read the caption
Рис. 1: An illustration of the proposed approach for collecting and generating the multilingual text detoxification dataset SynthDetoxM.
| Toxic Text | Detoxified Text | |
|---|---|---|
| German | Wie be**oppt muss man sein? | Wie verwirrt muss man sein? |
| Spanish | Que os den por el c**o. | Que os dé muy mala suerte. |
| French | c’est moi at***dé ! je suis tombé ! | C’est moi qui suis tombé ! |
| Russian | я мужик а вы г**но | Я мужчина, а вы неправы |
🔼 This table displays examples from the SynthDetoxM dataset, showcasing how toxic text in four different languages (German, French, Spanish, and Russian) was transformed into their detoxified counterparts using Large Language Models (LLMs). Each row presents a pair of toxic and detoxified sentences, illustrating the ability of the proposed method to successfully mitigate toxicity while retaining the original meaning.
read the caption
Таблица 1: Examples of the source toxic texts across different languages and their respective synthetic detoxifications from our SynthDetoxM.
In-depth insights#
LLM Detoxification#
The concept of “LLM Detoxification” centers on harnessing the capabilities of large language models (LLMs) to mitigate online toxicity. This involves using LLMs to rewrite toxic text while preserving its original meaning, effectively transforming harmful language into a safer, more acceptable form. This approach is particularly valuable in the context of multilingual text, where the scarcity of parallel datasets presents a significant challenge for traditional methods. Few-shot learning emerges as a crucial technique, allowing LLMs to perform detoxification tasks with minimal labeled data, thereby addressing the resource limitations inherent in multilingual settings. Furthermore, the use of LLMs enables the creation of large-scale, synthetic parallel datasets for training detoxification models, significantly improving model performance. The research highlights the potential for LLMs to automate the generation of high-quality detoxification data, reducing the cost and time associated with traditional crowdsourcing methods. However, ethical considerations are paramount, requiring careful attention to the potential misuse of such technology and the need for responsible development to prevent the exacerbation of harmful biases.
Parallel Data Gen#
The heading ‘Parallel Data Gen’ likely refers to the methods used in generating parallel datasets for multilingual text detoxification. This is a crucial aspect of the research, as high-quality parallel data is scarce and essential for training effective models. The paper likely details the pipeline for creating these datasets, which probably involves using large language models (LLMs) for few-shot prompting and detoxification of toxic sentences across multiple languages. A key aspect will be the strategies employed for ensuring data quality, such as filtering, evaluation using metrics (like STA and SIM), and potentially manual review. The process may also involve techniques like data augmentation to address the scarcity of parallel data. The effectiveness of this ‘Parallel Data Gen’ process significantly impacts the overall results and the generalizability of the trained models, so this section would likely include a detailed explanation of its methodologies and justification for choices made.
Multilingual TST#
Multilingual Text Style Transfer (TST) presents a significant challenge due to scarcity of parallel, high-quality datasets across multiple languages. Existing monolingual methods don’t readily translate, highlighting the need for innovative approaches. The research emphasizes the importance of parallel data in multilingual TST, proposing a novel framework to generate synthetic parallel datasets. This approach uses the strengths of modern large language models (LLMs) to perform few-shot detoxification, effectively addressing data limitations. LLMs act as efficient few-shot annotators, creating high-quality parallel data at scale. The success of this method hinges on careful prompt engineering and effective filtering to eliminate low-quality or unsuitable examples. This approach addresses limitations of relying solely on manual annotation, paving the way for broader multilingual TST applications. The resulting datasets are crucial for training robust and accurate multilingual models, proving that synthetic data can significantly enhance performance even in resource-constrained settings.
SynthDetoxM Eval#
A hypothetical ‘SynthDetoxM Eval’ section would delve into a rigorous evaluation of the SynthDetoxM dataset. This would likely involve automatic metrics such as Style Transfer Accuracy (STA), measuring the reduction in toxicity, and Content Similarity (SIM), assessing the preservation of original meaning. A crucial aspect would be comparing SynthDetoxM’s performance against existing, human-annotated datasets like MultiParaDetox, using various machine learning models to highlight the strengths and weaknesses of the synthetic dataset. Further investigation might involve human evaluation to gauge fluency and overall detoxification quality, complementing the quantitative findings. The analysis should address any potential biases or limitations inherent in the synthetic data generation process, such as over-reliance on specific LLM models or issues with certain languages. Finally, a discussion on the broader implications of using synthetic datasets for multilingual text detoxification, considering costs and ethical concerns, would be vital to a comprehensive evaluation.
Future Work#
Future work in multilingual text detoxification could focus on expanding the dataset to include more languages and address the limitations of relying solely on explicit toxicity detection. Investigating implicit toxicity and nuances across languages is crucial. Improving fluency evaluation metrics beyond ChrF1 is also vital; methods incorporating semantic understanding and human judgment would offer more accurate assessments. Exploring advanced prompting techniques and fine-tuning strategies for LLMs could significantly enhance the quality and diversity of synthetic data. Finally, research should thoroughly address the ethical implications of automated detoxification, including bias mitigation and the potential for misuse of such technologies. Benchmarking against a wider range of LLMs would provide a more robust evaluation of the dataset’s effectiveness.
More visual insights#
More on figures

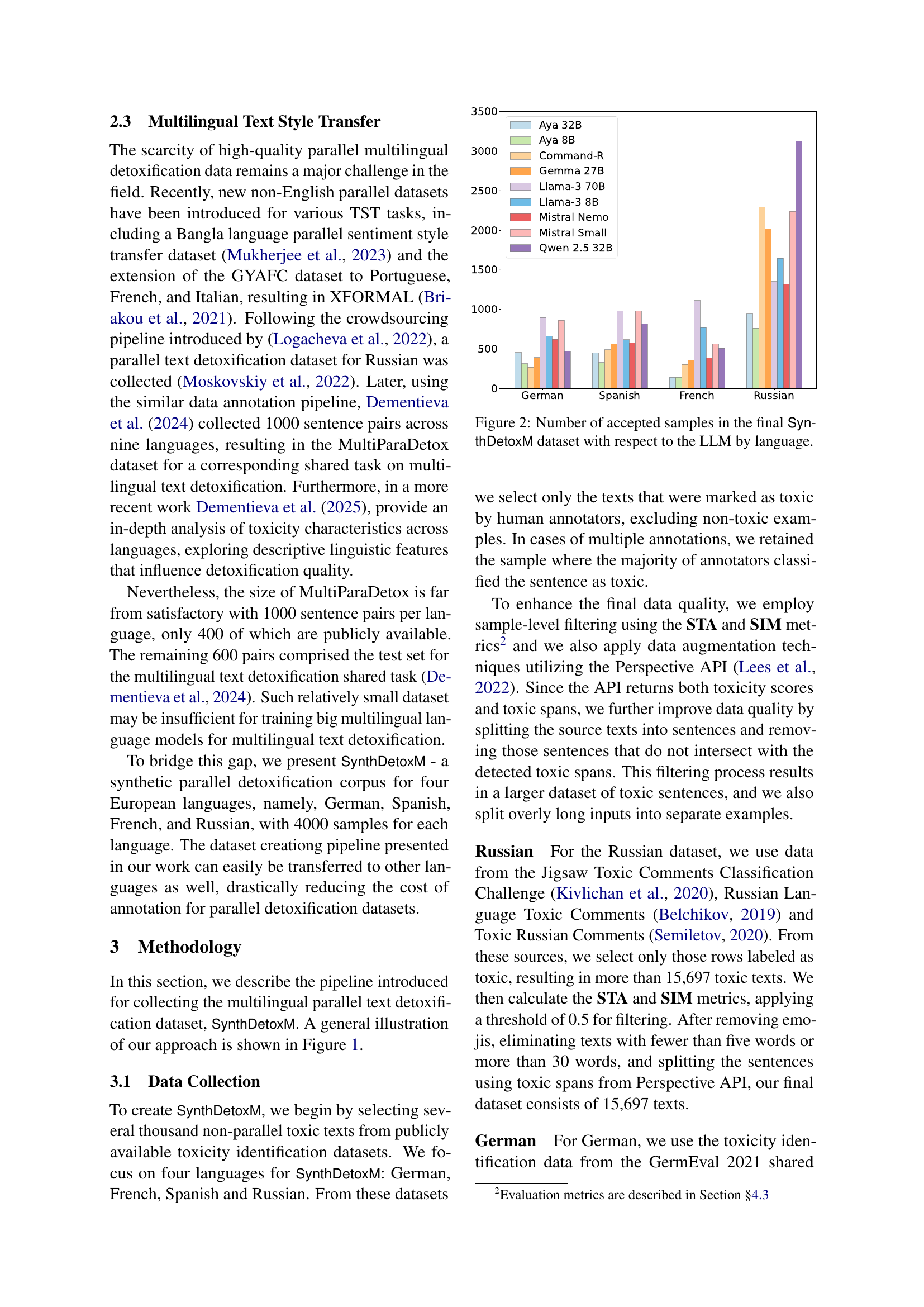
🔼 This figure shows the number of samples accepted into the final SynthDetoxM dataset for each language (German, Spanish, French, Russian) and for each of the nine Large Language Models (LLMs) used in its creation. The bar chart allows for a comparison of the contribution of each LLM to the overall size of the dataset for each language.
read the caption
Рис. 2: Number of accepted samples in the final SynthDetoxM dataset with respect to the LLM by language.

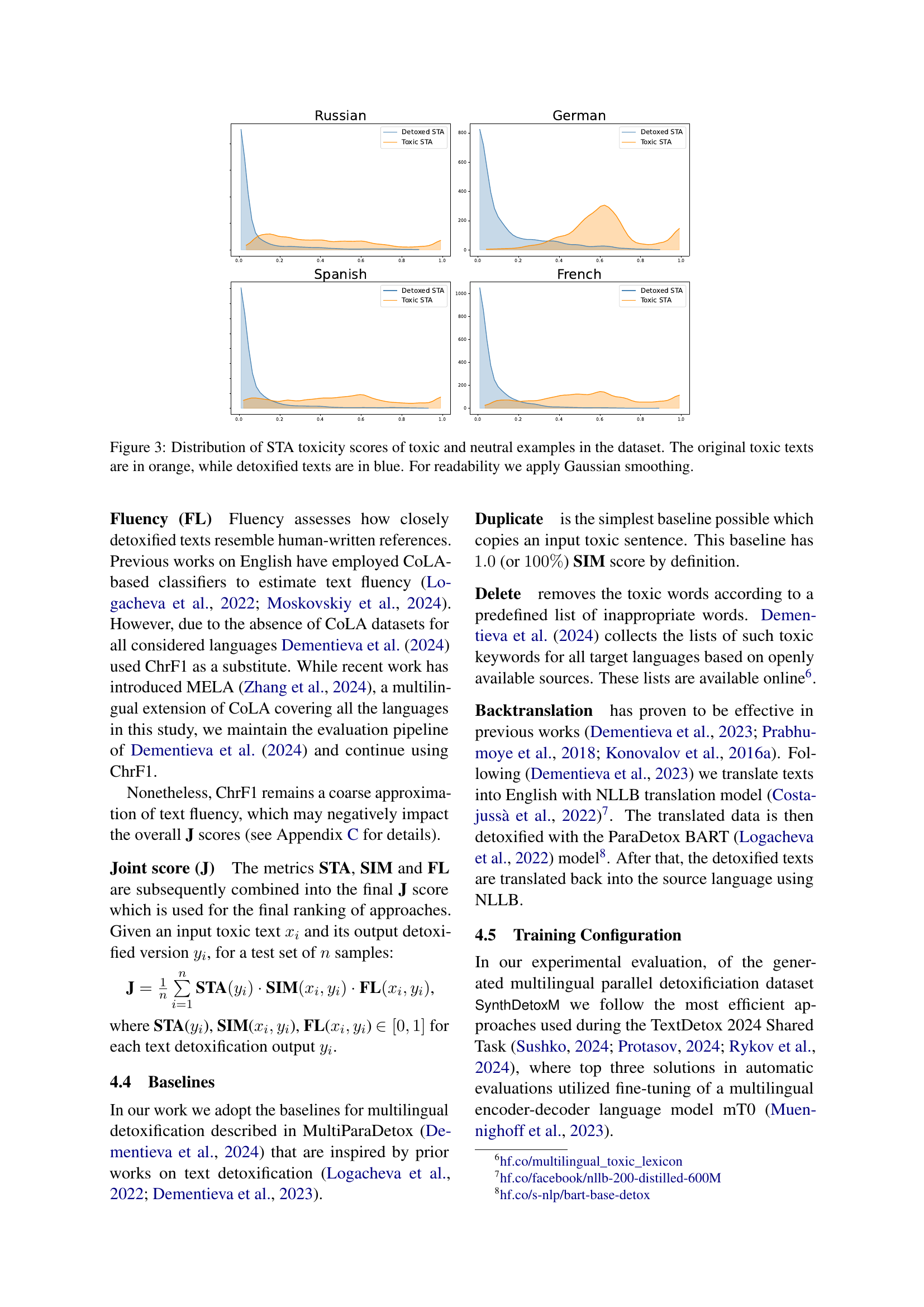
🔼 Figure 3 presents the distribution of toxicity scores (STA) for both original toxic and their corresponding detoxified versions across four different languages. The x-axis represents the STA score, ranging from 0 (non-toxic) to 1 (highly toxic). The y-axis represents the frequency or count of texts within a given STA score range. Original toxic texts are displayed in orange, while their detoxified counterparts are shown in blue. A Gaussian smoothing technique has been applied to enhance the visual clarity and readability of the distributions. This visualization helps illustrate the effectiveness of the detoxification process in reducing the toxicity levels of the text.
read the caption
Рис. 3: Distribution of STA toxicity scores of toxic and neutral examples in the dataset. The original toxic texts are in orange, while detoxified texts are in blue. For readability we apply Gaussian smoothing.
🔼 Figure 4 presents a side-by-side comparison of the outputs generated by different models when detoxifying text in German, Russian, and Spanish. GPT-4 acted as an evaluator to determine which of the two model outputs (one from a model trained on the SynthDetoxM dataset and the other from a model trained on MultiParaDetox) produced a better detoxification result for each example. The results visualize the relative performance of models trained on SynthDetoxM compared to models trained on the smaller MultiParaDetox dataset, illustrating the effectiveness of SynthDetoxM in training high-performing detoxification models. The color-coding and bar lengths in the chart represent the percentage of times each model was preferred by GPT-4, and the notation aligns with that of Table 3.
read the caption
Рис. 4: Side-by-side comparison of model outputs across all languages, evaluated by GPT-4o. The results highlight the relative performance of the models in generating detoxified text for German, Russian, and Spanish. The notation is similar to the notation from Table 3.

🔼 This figure illustrates the prompt used to generate synthetic parallel data for text detoxification. The prompt instructs a large language model (LLM) to rewrite a given toxic text into a non-toxic version while preserving the original meaning. The {toxic_text} placeholder represents the input toxic sentence. The prompt also includes a few-shot learning component, where a few example pairs of toxic and detoxified texts are provided to guide the model’s generation. The instruction to provide only the generated text (and not the input text again) helps maintain data quality and avoid unnecessary repetition.
read the caption
Рис. 5: Detoxification prompt we use for synthetic parallel data generation. {toxic_text} stands for a placeholder for a given toxic text being prompted into LLM. In few-shot setting we add few examples of detoxification before last two lines and write: Here are few examples:.

🔼 This figure shows the text of the prompt used for fine-tuning the mT0 model in the paper. The prompt instructs the model to rewrite toxic text into non-toxic text while maintaining the original meaning and style as much as possible. The few-shot learning setting is implied, though not explicitly stated in the prompt itself. This is a crucial component of the methodology described in the paper, as it details how the model is trained to perform the text detoxification task.
read the caption
Рис. 6: Detoxification prompt we use for mT0.

🔼 This figure shows the prompt used to generate synthetic refusal data for training a refusal classification model. The prompt instructs a large language model (LLM) to politely refuse to answer a given input text and to provide a reason for the refusal. The refusal should be relevant to the input text. The prompt ensures the LLM’s response is concise and focuses only on the refusal itself without adding unrelated information.
read the caption
Рис. 7: Refusal generation prompt for synthetic refusals dataset.
More on tables
| STA | STA | SIM | STASIM | |
|---|---|---|---|---|
| German | 0.389 | 0.853 | 0.793 | 0.675 |
| Spanish | 0.514 | 0.920 | 0.736 | 0.681 |
| French | 0.583 | 0.913 | 0.677 | 0.624 |
| Russian | 0.467 | 0.924 | 0.731 | 0.678 |
🔼 Table 2 presents the average toxicity scores for both original toxic texts and their generated detoxified counterparts across four different languages (German, Spanish, French, and Russian). The table showcases the toxicity levels using two metrics: STA (Style Transfer Accuracy) for both toxic and detoxified texts, and SIM (similarity) measuring the semantic similarity between original and detoxified texts. The column ‘STADSIM’ represents the product of STA scores for detoxified texts and their SIM scores, providing a combined measure of both toxicity reduction and semantic preservation. For a given text x, the STA score STA(x) is calculated as 1 - P(toxic|x), where P(toxic|x) represents the probability of the text being toxic.
read the caption
Таблица 2: Average toxicity levels across different languages for source toxic (T) and generated detoxified (D) texts, along with similarity scores. STATT{}_{\text{T}}start_FLOATSUBSCRIPT T end_FLOATSUBSCRIPT represents the toxicity level of the original text, while STADD{}_{\text{D}}start_FLOATSUBSCRIPT D end_FLOATSUBSCRIPT corresponds to the detoxified text. In our work, for a text x𝑥xitalic_x the score STA(x)=1−P(toxic|x)𝑥1𝑃conditionaltoxic𝑥(x)=1-P(\text{toxic}|x)( italic_x ) = 1 - italic_P ( toxic | italic_x ).
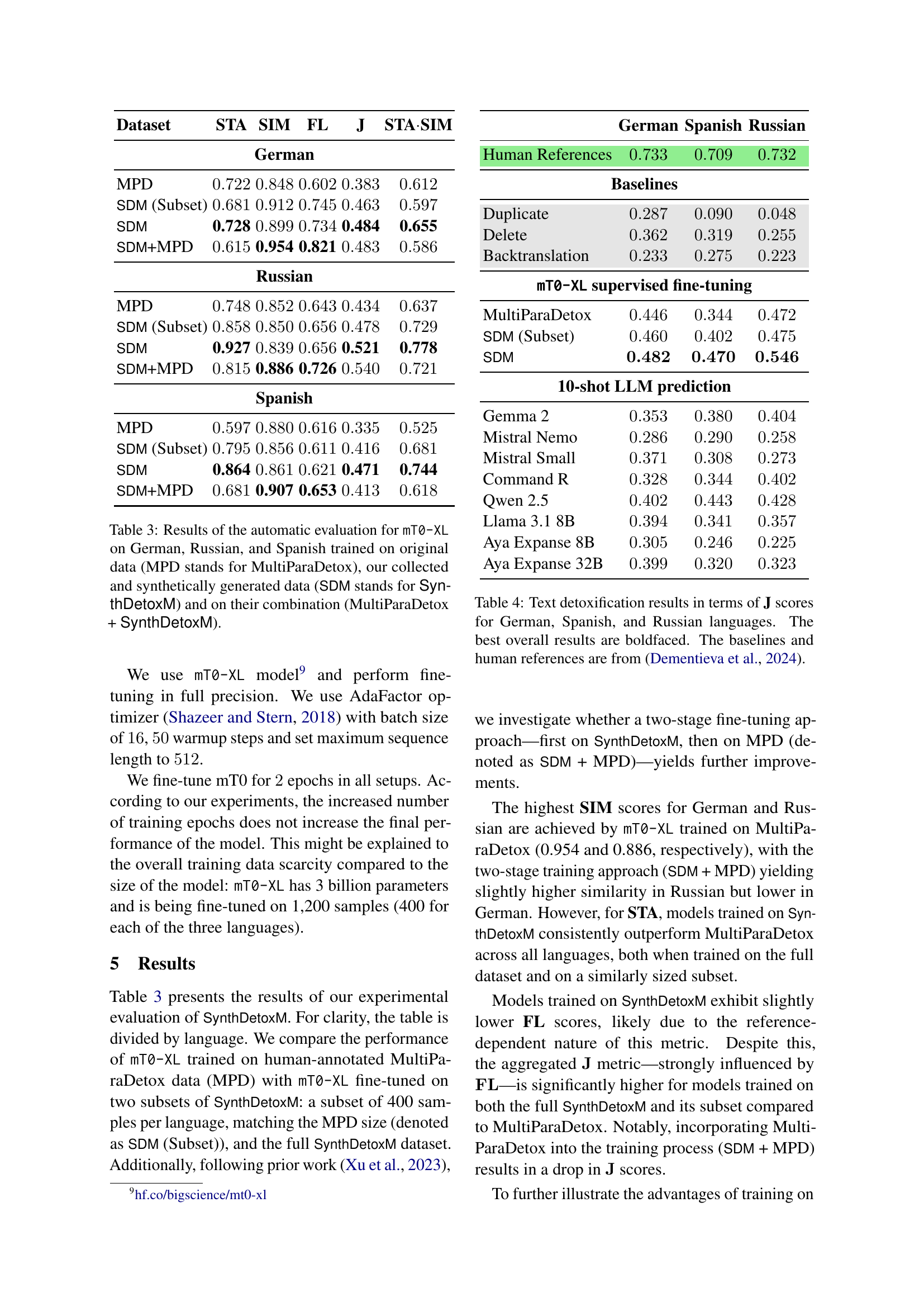
| Dataset | STA | SIM | FL | J | STASIM |
|---|---|---|---|---|---|
| German | |||||
| MPD | |||||
| SDM (Subset) | |||||
| SDM | 0.728 | 0.484 | 0.655 | ||
| SDM+MPD | 0.954 | 0.821 | |||
| Russian | |||||
| MPD | |||||
| SDM (Subset) | |||||
| SDM | 0.927 | 0.521 | 0.778 | ||
| SDM+MPD | 0.886 | 0.726 | |||
| Spanish | |||||
| MPD | |||||
| SDM (Subset) | |||||
| SDM | 0.864 | 0.471 | 0.744 | ||
| SDM+MPD | 0.907 | 0.653 | |||
🔼 Table 3 presents the results of an automatic evaluation of the mT0-XL model’s performance on German, Russian, and Spanish text detoxification tasks. The model was trained on three different datasets: the original MultiParaDetox (MPD) dataset, a newly collected and synthetically generated dataset (SynthDetoxM, SDM), and a combined dataset consisting of both MPD and SDM. The table shows the results in terms of several key metrics: Style Transfer Accuracy (STA), which measures the success of the model in reducing toxicity; Content Similarity (SIM), indicating how well the meaning of the original text is preserved after detoxification; Fluency (FL), reflecting the grammatical correctness and readability of the detoxified text; and a combined Joint Score (J) that considers all three metrics. This allows for a comparison of the model’s performance when trained on different amounts and types of data, revealing the impact of synthetic data on the quality of text detoxification.
read the caption
Таблица 3: Results of the automatic evaluation for mT0-XL on German, Russian, and Spanish trained on original data (MPD stands for MultiParaDetox), our collected and synthetically generated data (SDM stands for SynthDetoxM) and on their combination (MultiParaDetox + SynthDetoxM).
| German | Spanish | Russian | |
| Human References | |||
| Baselines | |||
| Duplicate | |||
| Delete | |||
| Backtranslation | |||
| mT0-XL supervised fine-tuning | |||
| MultiParaDetox | |||
| SDM (Subset) | |||
| SDM | |||
| 10-shot LLM prediction | |||
| Gemma 2 | |||
| Mistral Nemo | |||
| Mistral Small | |||
| Command R | |||
| Qwen 2.5 | |||
| Llama 3.1 8B | |||
| Aya Expanse 8B | |||
| Aya Expanse 32B | |||
🔼 Table 4 presents the results of an automatic evaluation of text detoxification models trained on different datasets. The evaluation metric used is the J score, which combines three sub-metrics: style transfer accuracy (STA), content similarity (SIM), and fluency (FL). The table shows the performance of models trained on the MultiParaDetox dataset (MPD), the SynthDetoxM dataset (SDM), a subset of the SynthDetoxM dataset, and a combination of both datasets. Baselines (human references, duplicate, delete, and back-translation) are included for comparison. The best overall results for each language are highlighted in bold. This table helps to assess the quality of the SynthDetoxM dataset by comparing the performance of models trained on it to models trained on the human-annotated MultiParaDetox dataset and standard baselines.
read the caption
Таблица 4: Text detoxification results in terms of J scores for German, Spanish, and Russian languages. The best overall results are boldfaced. The baselines and human references are from Dementieva et al. (2024).
| Model | German | Spanish | French | Russian |
|---|---|---|---|---|
| Llama 3.1 8B | 662 | 619 | 773 | 1648 |
| Llama 3.1 70B | 898 | 981 | 1114 | 1354 |
| Mistral Nemo | 622 | 583 | 392 | 1320 |
| Mistral Small | 862 | 985 | 565 | 2237 |
| Qwen 2.5 32B | 477 | 819 | 513 | 3128 |
| Aya Exp. 32B | 458 | 453 | 142 | 945 |
| Aya Exp. 8B | 316 | 330 | 143 | 765 |
| Command-R 32B | 273 | 492 | 308 | 2294 |
| Gemma 2 27B | 394 | 564 | 360 | 2019 |
🔼 This table presents the counts of high-quality synthetic detoxification pairs generated for the SynthDetoxM dataset. The data is categorized by language (German, Spanish, French, Russian) and the specific large language model (LLM) used to generate the detoxified text. It shows how many examples were successfully generated for each language-model combination after filtering based on quality criteria. This reflects the contribution of different LLMs to the overall dataset size.
read the caption
Таблица 5: Number of accepted samples in the final SynthDetoxM dataset, broken down by language and LLMs.
| Dataset | STA | SIM | CHRF | J |
|---|---|---|---|---|
| German | ||||
| MPD | ||||
| SDM (Subset) | ||||
| SDM (Full) | ||||
| SDM+MPD | ||||
| Russian | ||||
| MPD | ||||
| SDM (Subset) | ||||
| SDM (Full) | ||||
| SDM+MPD | ||||
| Spanish | ||||
| MPD | ||||
| SDM (Subset) | ||||
| SDM (Full) | ||||
| SDM+MPD | ||||
🔼 This table presents the results of an automatic evaluation of the multilingual text detoxification model, mT0-XL. The model was trained on three different datasets: the original MultiParaDetox dataset (MPD), the researchers’ newly collected and synthetically generated dataset (SDM), and a combination of both (MPD+SDM). The evaluation metrics used are Style Transfer Accuracy (STA), Content Similarity (SIM), and Fluency (FL), with their combined score J. The table shows the performance of the model across these datasets for three different languages: German, Russian, and Spanish.
read the caption
Таблица 6: Results of the automatic evaluation for mT0-XL on German, Russian, and Spanish trained on original data (MPD stands for MultiParaDetox), our collected and synthetically generated data (SDM stands for SynthDetoxM) and on their combination (MultiParaDetox + SynthDetoxM).
| Spanish | German | Russian | |
|---|---|---|---|
| Toxic | 2089 | 323 | 4467 |
| Detoxified | 27 | 102 | 14 |
🔼 This table shows the total number of toxic words present in both the original toxic text and the corresponding detoxified text generated by the model, categorized by language (Spanish, German, and Russian). It demonstrates the effectiveness of the detoxification process by comparing the count of toxic words before and after the detoxification.
read the caption
Таблица 7: Total amount of toxic words for toxic and detoxified subsets of SynthDetoxM with respect to language.
| Spanish | German | Russian | |
|---|---|---|---|
| Toxic | 0.522 | 0.081 | 1.117 |
| Detoxified | 0.007 | 0.036 | 0.004 |
🔼 This table presents the average number of toxic words found per text in both the original toxic and the generated detoxified versions of the SynthDetoxM dataset. The average is calculated separately for each of the four languages included in the dataset: Spanish, German, Russian, and French. This data provides insights into the effectiveness of the detoxification process in reducing toxicity across different languages.
read the caption
Таблица 8: Average number of toxic words per text in the toxic and detoxified SynthDetoxM with respect to language.
| Type | Text | Perspective API Score | XLM-R Score |
|---|---|---|---|
| Toxic | тварь присягу один раз,а проебал всю страну The bastard swore an oath once, but screwed over the whole country. | 0.820 | 1.000 |
| Neutral | Присягу дал один раз, а разрушил всю страну He took the oath once, but destroyed the whole country | 0.360 | 0.001 |
| Toxic | нахрена этого придурка клоуна сюда впихивают? why the fuck is this idiot clown being pushed in here? | 0.743 | 1.000 |
| Neutral | Зачем этого человека сюда впихивают? Why is this man being pushed in here? | 0.042 | 0.005 |
| Toxic | молись не молись,всё - равно получишь хуй. ну, разве что блядям на радость Pray or don’t pray, you’ll get a dick anyway. Well, except for the joy of whores. | 0.757 | 1.000 |
| Neutral | Молись не молись, всё - равно ничего не получишь. ну, разве что завистникам на радость. Pray or don’t pray, you won’t get anything anyway. well, except for the envy of the joy. | 0.156 | 0.998 |
| Toxic | её муженька козла на кол надо посадить Her scoundrel of a husband needs to be impaled. | 0.553 | 0.999 |
| Neutral | Её муженька нужно сурово наказать Her hubby needs to be severely punished | 0.029 | 0.988 |
| Toxic | хорошо пизды не получил уёбок good thing the bastard didn’t get his ass kicked. | 0.853 | 1.000 |
| Neutral | хорошо что он не был избит it’s a good thing he wasn’t beaten up | 0.037 | 0.000 |
| Toxic | да что ты доебалась до этих клумб? людям жрать нечего! по мусоркам лазают! why are you so fixated on those flower beds? people have nothing to eat! they’re rummaging through trash! | 0.548 | 1.000 |
| Neutral | да что ты докопалась до этих клумб? Людям есть нечего! по мусоркам лазают! why did you get to these flower beds? People have nothing to eat! they’re climbing through the trash! | 0.115 | 0.000 |
| Toxic | именно благодаря этому президенту, россия еще жива. а такие долбоёбы, только могут воду мутить. дебилоид. It’s precisely thanks to this president that Russia is still alive. And idiots like you can only stir up trouble. Moron. | 0.863 | 1.000 |
| Neutral | Именно благодаря этому президенту, Россия ещё жива, а такие люди, как ты, только и могут, что наводить смуту. It is thanks to this president that Russia is still alive, and people like you can only cause trouble. | 0.369 | 0.003 |
| Toxic | ты просто пидор,а не немец.я за свои слова отвечу, you’re just a faggot, not a german. I stand by my words, but you won’t, because you’re a couch scumbag. | 0.906 | 1.000 |
| Neutral | ты просто не немец. я за свои слова отвечу, а ты н you’re just not german. i’ll answer for my words, but you won’t, because you’re writing from the couch | 0.399 | 0.002 |
| Toxic | да, блядь, кто это говнище постоянно сюда сливает?! Yeah, fuck, who keeps dumping this shit here all the time?! | 0.654 | 1.000 |
| Neutral | да кто эту ерунду постоянно сюда сливает?! who is constantly pouring this nonsense here?! | 0.096 | 0.001 |
| Toxic | да вы заебали этим постом уже, пидарасы!!! I’m sick of this post already, you bastards!!! | 0.903 | 1.000 |
| Neutral | да вы надоели этим постом уже, люди!!! Yes, people, I am tired of this post already!!! | 0.012 | 0.001 |
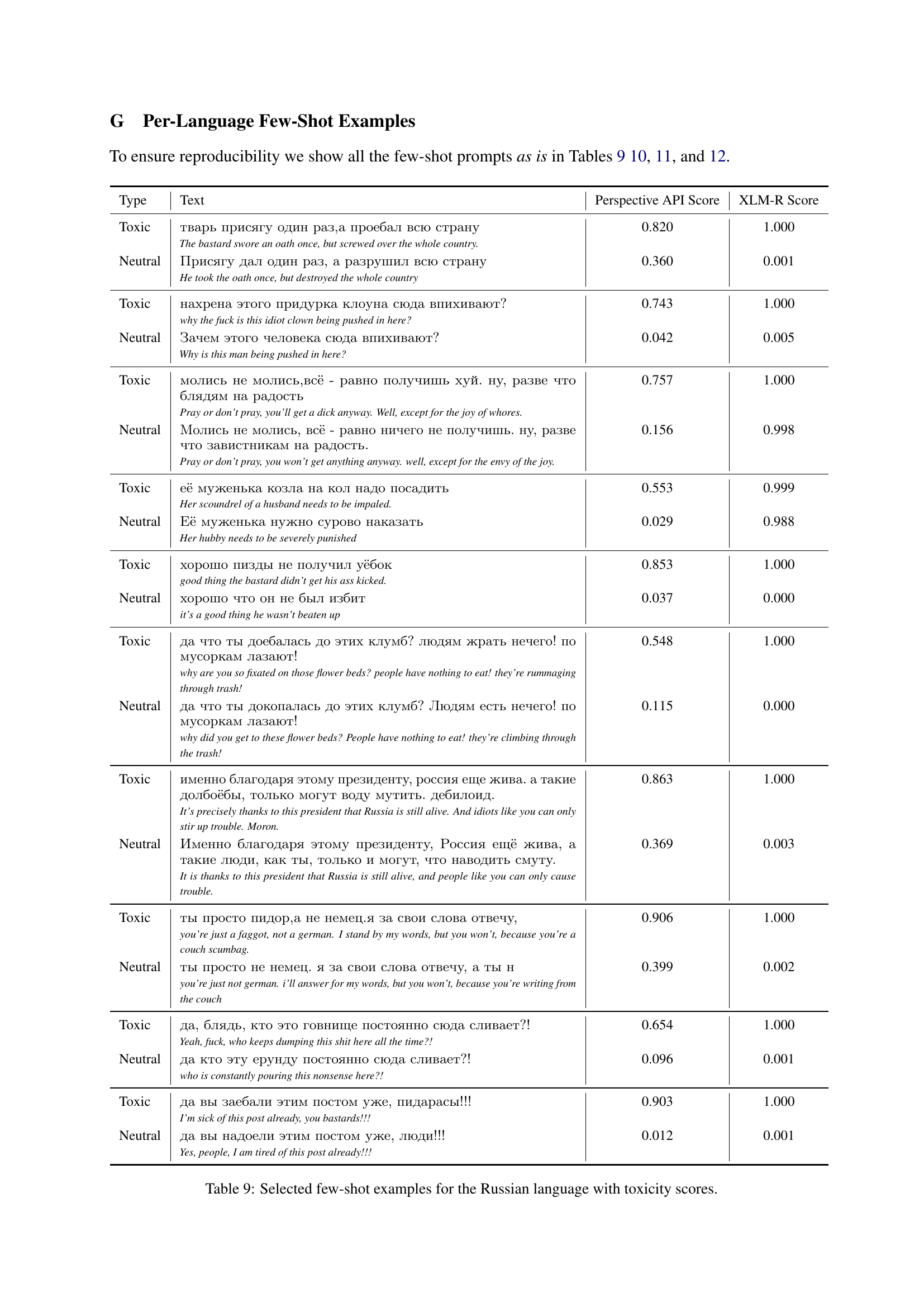
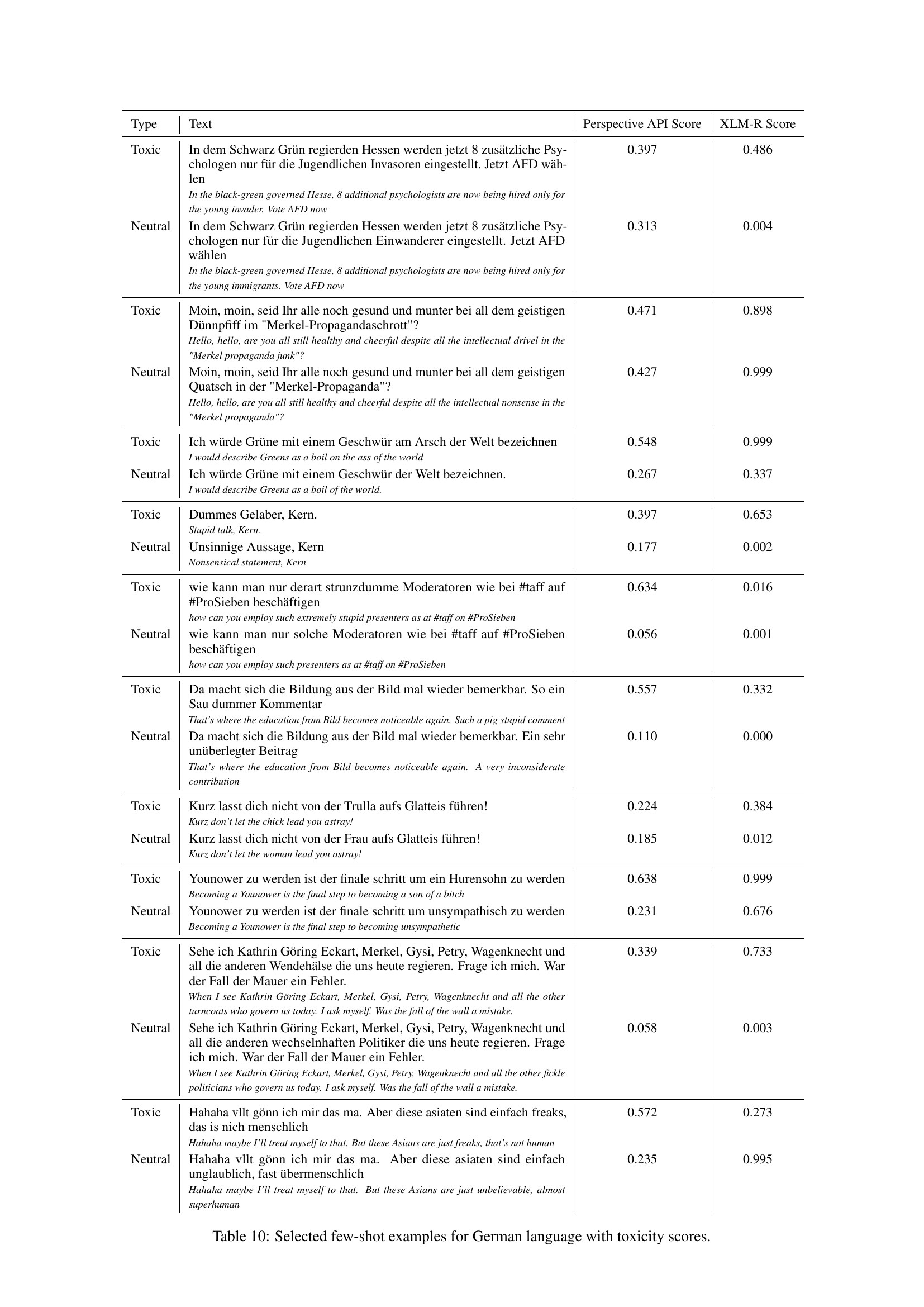
🔼 This table displays a selection of few-shot examples used for the Russian language in the SynthDetoxM dataset creation. Each row shows a toxic sentence and its corresponding neutral paraphrase, along with toxicity scores generated by two different methods: Perspective API and XLM-R. The table is used to illustrate the quality of the generated detoxification pairs in the dataset and how the LLM models handle various types of toxicity in the Russian language.
read the caption
Таблица 9: Selected few-shot examples for the Russian language with toxicity scores.
| Type | Text | Perspective API Score | XLM-R Score |
|---|---|---|---|
| Toxic | In dem Schwarz Grün regierden Hessen werden jetzt 8 zusätzliche Psychologen nur für die Jugendlichen Invasoren eingestellt. Jetzt AFD wählen In the black-green governed Hesse, 8 additional psychologists are now being hired only for the young invader. Vote AFD now | 0.397 | 0.486 |
| Neutral | In dem Schwarz Grün regierden Hessen werden jetzt 8 zusätzliche Psychologen nur für die Jugendlichen Einwanderer eingestellt. Jetzt AFD wählen In the black-green governed Hesse, 8 additional psychologists are now being hired only for the young immigrants. Vote AFD now | 0.313 | 0.004 |
| Toxic | Moin, moin, seid Ihr alle noch gesund und munter bei all dem geistigen Dünnpfiff im ”Merkel-Propagandaschrott”? Hello, hello, are you all still healthy and cheerful despite all the intellectual drivel in the "Merkel propaganda junk"? | 0.471 | 0.898 |
| Neutral | Moin, moin, seid Ihr alle noch gesund und munter bei all dem geistigen Quatsch in der ”Merkel-Propaganda”? Hello, hello, are you all still healthy and cheerful despite all the intellectual nonsense in the "Merkel propaganda"? | 0.427 | 0.999 |
| Toxic | Ich würde Grüne mit einem Geschwür am Arsch der Welt bezeichnen I would describe Greens as a boil on the ass of the world | 0.548 | 0.999 |
| Neutral | Ich würde Grüne mit einem Geschwür der Welt bezeichnen. I would describe Greens as a boil of the world. | 0.267 | 0.337 |
| Toxic | Dummes Gelaber, Kern. Stupid talk, Kern. | 0.397 | 0.653 |
| Neutral | Unsinnige Aussage, Kern Nonsensical statement, Kern | 0.177 | 0.002 |
| Toxic | wie kann man nur derart strunzdumme Moderatoren wie bei #taff auf #ProSieben beschäftigen how can you employ such extremely stupid presenters as at #taff on #ProSieben | 0.634 | 0.016 |
| Neutral | wie kann man nur solche Moderatoren wie bei #taff auf #ProSieben beschäftigen how can you employ such presenters as at #taff on #ProSieben | 0.056 | 0.001 |
| Toxic | Da macht sich die Bildung aus der Bild mal wieder bemerkbar. So ein Sau dummer Kommentar That’s where the education from Bild becomes noticeable again. Such a pig stupid comment | 0.557 | 0.332 |
| Neutral | Da macht sich die Bildung aus der Bild mal wieder bemerkbar. Ein sehr unüberlegter Beitrag That’s where the education from Bild becomes noticeable again. A very inconsiderate contribution | 0.110 | 0.000 |
| Toxic | Kurz lasst dich nicht von der Trulla aufs Glatteis führen! Kurz don’t let the chick lead you astray! | 0.224 | 0.384 |
| Neutral | Kurz lasst dich nicht von der Frau aufs Glatteis führen! Kurz don’t let the woman lead you astray! | 0.185 | 0.012 |
| Toxic | Younower zu werden ist der finale schritt um ein Hurensohn zu werden Becoming a Younower is the final step to becoming a son of a bitch | 0.638 | 0.999 |
| Neutral | Younower zu werden ist der finale schritt um unsympathisch zu werden Becoming a Younower is the final step to becoming unsympathetic | 0.231 | 0.676 |
| Toxic | Sehe ich Kathrin Göring Eckart, Merkel, Gysi, Petry, Wagenknecht und all die anderen Wendehälse die uns heute regieren. Frage ich mich. War der Fall der Mauer ein Fehler. When I see Kathrin Göring Eckart, Merkel, Gysi, Petry, Wagenknecht and all the other turncoats who govern us today. I ask myself. Was the fall of the wall a mistake. | 0.339 | 0.733 |
| Neutral | Sehe ich Kathrin Göring Eckart, Merkel, Gysi, Petry, Wagenknecht und all die anderen wechselnhaften Politiker die uns heute regieren. Frage ich mich. War der Fall der Mauer ein Fehler. When I see Kathrin Göring Eckart, Merkel, Gysi, Petry, Wagenknecht and all the other fickle politicians who govern us today. I ask myself. Was the fall of the wall a mistake. | 0.058 | 0.003 |
| Toxic | Hahaha vllt gönn ich mir das ma. Aber diese asiaten sind einfach freaks, das is nich menschlich Hahaha maybe I’ll treat myself to that. But these Asians are just freaks, that’s not human | 0.572 | 0.273 |
| Neutral | Hahaha vllt gönn ich mir das ma. Aber diese asiaten sind einfach unglaublich, fast übermenschlich Hahaha maybe I’ll treat myself to that. But these Asians are just unbelievable, almost superhuman | 0.235 | 0.995 |
🔼 This table presents a selection of few-shot examples used for the German language in the text detoxification process. Each example includes the original toxic text, its neutral counterpart generated by the model, and the toxicity scores obtained from the Perspective API and the XLM-R model. This allows for an understanding of the model’s performance in neutralizing toxic language while maintaining semantic similarity.
read the caption
Таблица 10: Selected few-shot examples for German language with toxicity scores.
| Type | Text | Perspective API Score | XLM-R Score |
|---|---|---|---|
| Toxic | Y lo bien que les va siendo fachas, que no es gratis And how well they are doing being fascists, which is not free | 0.184 | 0.002 |
| Neutral | Y lo bien que les va siendo conservadores, que no es gratis And how well they are doing being conservatives, which is not free | 0.012 | 0.574 |
| Toxic | Y a mí qué me importa lo que tú ”notes”, facha? And what do I care what you "notice fascist? | 0.427 | 0.391 |
| Neutral | Y a mí qué me importa lo que tú ”notes”? And what do I care what you "notice"? | 0.080 | 0.001 |
| Toxic | ya ves además a los policías nazis que tendrá esa en el whatsapp… como para creerse algo. you see also the nazi policemen that she will have on whatsapp… as if to believe something. | 0.261 | 0.608 |
| Neutral | ya ves además a los policías que tendrá esa en el whatsapp… como para creerse algo. you see also the policemen that she will have on whatsapp… as if to believe something. | 0.035 | 0.003 |
| Toxic | #YoSoyAnonymousUE basta de absurda represión victimista por parte del Estado Fascista #YoSoyAnonymousUE enough of absurd victimist repression by the Fascist State | 0.255 | 0.352 |
| Neutral | #YoSoyAnonymousUE basta de absurda represión victimista por parte del Estado #YoSoyAnonymousUE enough of absurd victimist repression by the State | 0.106 | 0.034 |
| Toxic | Supongo que Perro le dará asilo en la Moncloa I suppose Dog will give him asylum in La Moncloa | 0.314 | 0.283 |
| Neutral | Supongo que el presidente le dara asilo en la Moncloa I suppose the president will give him asylum in La Moncloa | 0.039 | 0.004 |
| Toxic | Los halagos y buenos modales siempre hacen bien, menos a los izquierdistas de la cultura del odio. Flattery and good manners are always good, except for the leftists of the culture of hatred. | 0.285 | 0.969 |
| Neutral | Los halagos y buenos modales siempre hacen bien, menos a los izquierdas de la cultura del odio. Flattery and good manners are always good, except for the leftists of the culture of hatred. | 0.280 | 0.236 |
| Toxic | Yo me quiero escapar también, dan paguita al llega I want to escape too, they give a small handout to the newcomer | 0.011 | 0.423 |
| Neutral | ¿Ofrecen algún tipo de apoyo al llegar? Do they offer any kind of support upon arrival? | 0.002 | 0.000 |
| Toxic | Mire la saga de 50 sombras de Grey…casi todo eran.lectoras…les va el.morbillo no lo.nieguen Look at the 50 Shades of Grey saga…almost all were.readers…they like.morbid curiosity don’t.deny it | 0.039 | 0.811 |
| Neutral | Miren la saga de 50 sombras de Grey.. casi todo eran lectoras… le encanta Look at the 50 Shades of Grey saga… almost all were readers… they love it | 0.011 | 0.000 |
| Toxic | Cortocircuito buenrrollista, pobres inmigrantes vs chica atacada sexualmente. Good-natured short circuit, poor immigrants vs sexually attacked girl. | 0.305 | 0.719 |
| Neutral | Es un conflicto entre el enfoque positivo y la compasión por los inmigrantes, frente a la preocupación por una chica atacada sexualmente. It is a conflict between the positive approach and compassion for immigrants, versus concern for a sexually attacked girl. | 0.082 | 0.002 |
| Toxic | menudos fachas xD HIJOS DE PUTA what fascists xD SONS OF BITCHES | 0.921 | 0.802 |
| Neutral | menudos fachas xD what fascists xD | 0.327 | 0.982 |
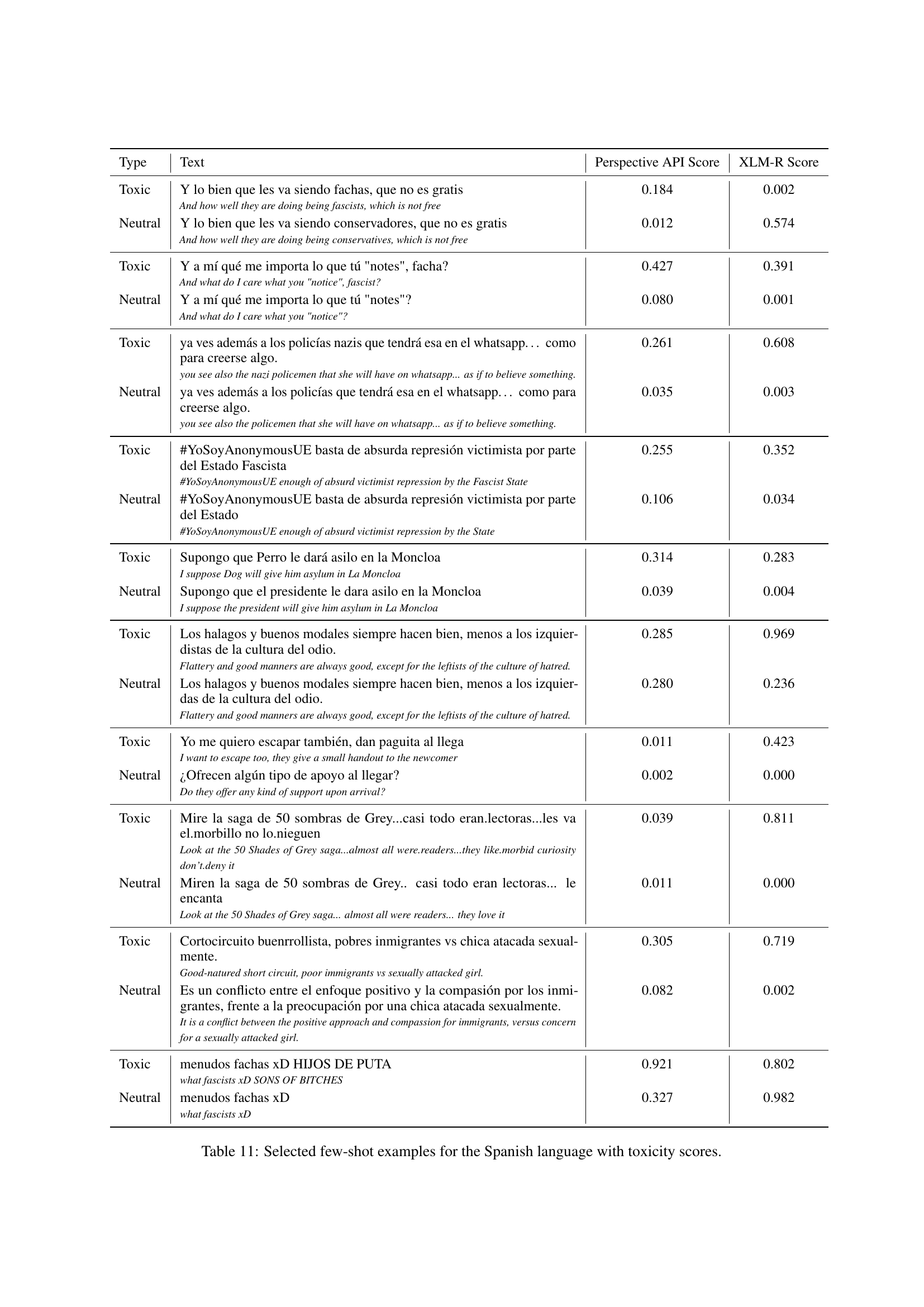
🔼 This table displays several examples of few-shot prompts used for the Spanish language in the SynthDetoxM dataset creation. For each example, it shows the original toxic text, a neutral (detoxified) paraphrase generated by the model, and the toxicity scores assigned by Perspective API and XLM-R. This demonstrates the model’s ability to generate neutral paraphrases and helps evaluate the effectiveness of the few-shot learning approach.
read the caption
Таблица 11: Selected few-shot examples for the Spanish language with toxicity scores.
| Type | Text | Perspective API Score | XLM-R Score |
|---|---|---|---|
| Toxic | Pour le crétin qui remet à chaque fois une soi-disant citation de Nietzsche, l’expression ”tout s’enjuive” est attribuée par Nietzsche à un libre-penseur démocrate, autrement dit Nietzsche identifie l’antisémitisme aux valeurs chrétiennes de la ”libre pensée”. For the idiot who always puts a so-called quote from Nietzsche, the expression "everything is becoming Jewish"is attributed by Nietzsche to a democratic freethinker, in other words Nietzsche identifies anti-Semitism with the Christian values of "free thought". | 0.255 | - |
| Neutral | Pour la personne qui remet à chacun une s citation de Nietzsche l’expression tout s’enjuive est attribuée par Nietzsche à un libre-penseur démocrate, autrement dit Nietzsche identifie l’antisémitisme aux valeurs chrétiennes de la libre pensée. For the person who gives everyone a quote from Nietzsche, the expression "everything is becoming Jewish"is attributed by Nietzsche to a democratic freethinker, in other words Nietzsche identifies anti-Semitism with the Christian values of free thought. | 0.000 | - |
| Toxic | Et toi aussi tu commences sérieusement à me gonfler. And you too are seriously starting to annoy me. | 0.238 | - |
| Neutral | Et toi aussi tu commences sérieusement à m’énerver. And you too are seriously starting to irritate me. | 0.285 | - |
| Toxic | Tout est trop nul, tout est faux ou ou ou! Everything is too rubbish, everything is false or or or! | 0.167 | - |
| Neutral | Tout est médiocre et faux ! Everything is mediocre and false! | 0.195 | - |
| Toxic | Continuez tout seul si ça vous amuse. Je ne perdrai pas plus de temps avec un pénible de votre espèce. Continue on your own if that amuses you. I won’t waste any more time with a pain in the ass like you. | 0.498 | - |
| Neutral | Continuez tout seul si ça vous amuse. Je ne perdrai pas plus de temps avec une telle personne. Continue on your own if that amuses you. I won’t waste any more time with such a person. | 0.309 | - |
| Toxic | Salut, j ai restauré cet article et réverté tes su Hi, I restored this article and reverted your su | 0.383 | - |
| Neutral | Salut, j ai restauré cet article et réverté tes su Hi, I restored this article and reverted your su | 0.152 | - |
| Toxic | Encore un vieux qui fait chier, je ne fais plus attention à force. Another old man who’s a pain in the ass, I don’t pay attention anymore. | 0.509 | - |
| Neutral | Encore un vieux ennuyeux, je ne fais plus attention à force. Another boring old man, I don’t pay attention anymore. | 0.378 | - |
| Toxic | Oue et on s en tape de ta façon a toi et on s en tape que t as eu d emmerdes avec personne c est pas mon problème donc comme je l ai dis tout a l heure je fais a ma façon. Yeah and we don’t care about your way and we don’t care that you had troubles with anyone it’s not my problem so as I said earlier I do it my way. | 0.373 | - |
| Neutral | Oue et ça n’a rien à voir avec ta vie, le fait que tu aies eu des problèmes, ça ne me regarde pas, donc comme je l ai dis tout a l heure je fais a ma façon. Yeah and it has nothing to do with your life, the fact that you had problems, it’s none of my business, so as I said earlier I do it my way. | 0.049 | - |
| Toxic | Ta réponse est confondante… Et tu continues tes manigances ! Je te prie de t arrêter immédiatement! Your answer is confusing… And you continue your schemes! I beg you to stop immediately! | 0.304 | - |
| Neutral | Ta réponse est confondante… Et tu continues tes tricks! Je te prie de t arrêter immédiatement ! Your answer is confusing… And you continue your tricks! I beg you to stop immediately! | 0.255 | - |
| Toxic | Faut croire que les amateurs de musique sont des malades mentaux You have to believe that music lovers are mentally ill | 0.386 | - |
| Neutral | Faut croire que les amateurs de musique ont des préférences étranges You have to believe that music lovers have strange preferences | 0.046 | - |
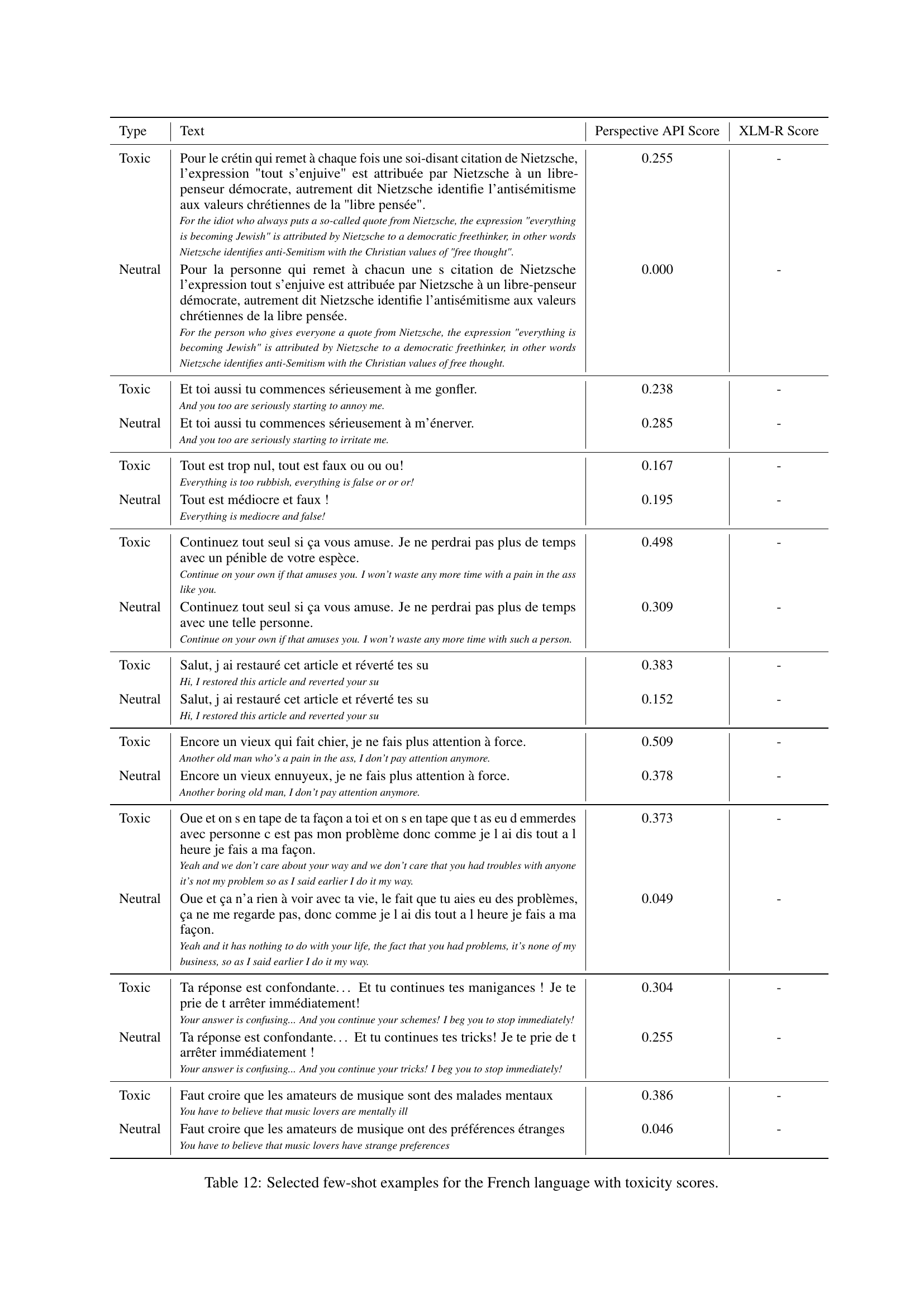
🔼 This table displays several examples of few-shot prompts used for the French language in the SynthDetoxM dataset creation process. Each row shows a toxic sentence and its corresponding non-toxic paraphrase generated by a large language model. The table also provides toxicity scores (Perspective API and XLM-R) for both the original toxic sentence and its generated counterpart. These scores help in evaluating the effectiveness of the detoxification process.
read the caption
Таблица 12: Selected few-shot examples for the French language with toxicity scores.
Full paper#