TL;DR#
Current LLM-based autonomous agents suffer from limited capabilities due to scarcity of agent-oriented pre-training data and over-reliance on complex prompting or extensive fine-tuning. These methods often hinder generalization and fail to introduce new capabilities. Existing approaches primarily focus on fine-tuning, neglecting the crucial role of pre-training in establishing fundamental agentic abilities.
To overcome these challenges, the researchers introduce Hephaestus-Forge, a large-scale pre-training corpus designed to improve LLM agents’ abilities in API function calling, reasoning, planning, and environmental adaptation. They investigate optimal data mixing ratios through scaling laws and continually pre-train a new open-source LLM called Hephaestus. Results show that Hephaestus outperforms other open-source LLMs and rivals commercial LLMs in several agent benchmarks, demonstrating the effectiveness of Hephaestus-Forge in enhancing fundamental agentic capabilities and improving generalization to new tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) as it addresses the critical issue of limited agent capabilities due to scarce training data. It introduces a novel large-scale pre-training corpus and demonstrates how continual pre-training can significantly enhance the performance of LLM agents. This opens new avenues for improving LLM agent generalization, particularly for complex, multi-step tasks, and makes a significant contribution to the field of LLM-based autonomous agents.
Visual Insights#

🔼 This figure illustrates four different approaches to training large language model (LLM) agents. (A) Prompting uses only prompts to guide the LLM, without adding new knowledge or capabilities. This is the simplest but least effective approach. (B) Fine-tuning uses task-specific data to train the LLM. Although this improves performance on the specific task, it can hinder generalization to other tasks and negatively affect performance in non-agent contexts. (C) Instruction fine-tuning improves on fine-tuning by using instruction data for training. While this improves generalization, the limitations similar to (B) still apply. (D) The proposed approach (Hephaestus-Forge) uses continual pre-training on a multi-source corpus designed to enhance the fundamental capabilities of the LLM agents, leading to better generalization and performance across a range of tasks. The figure highlights that continual pre-training is superior to other approaches in terms of generalization and retaining the original model’s capabilities.
read the caption
Figure 1: Training paradigms of LLM agents. Prompting alone fails to introduce new knowledge and capabilities, while heavy fine-tuning can hinder generalization and degrade performance in non-agent use cases, potentially suppressing the original base model capabilities.
| Methods | Datasets |
|
|
| # APIs | Code |
|
|
|
|
|
|
| ||||||||||||||||||||
| Instruction Finetuning-based LLM Agents for Intrinsic Reasoning | |||||||||||||||||||||||||||||||||
| FireAct Chen et al. (2023) | FireAct | IFT | - | 2.1K | 10 | ✗ | ✔ | ✔ | ✗ | ✔ | ✗ | ✔ | ✗ | ||||||||||||||||||||
| ToolAlpaca Tang et al. (2023) | ToolAlpaca | IFT | - | 4.0K | 400 | ✗ | ✔ | ✔ | ✗ | ✔ | ✗ | ✔ | ✗ | ||||||||||||||||||||
| ToolLLaMA Qin et al. (2024) | ToolBench | IFT | - | 12.7K | 16,464 | ✗ | ✔ | ✔ | ✗ | ✔ | ✔ | ✔ | ✔ | ||||||||||||||||||||
| AgentEvol (Xi et al., 2024) | AgentTraj-L | IFT | - | 14.5K | 24 | ✗ | ✔ | ✔ | ✗ | ✔ | ✗ | ✗ | ✔ | ||||||||||||||||||||
| Lumos Yin et al. (2024) | Lumos | IFT | - | 20.0K | 16 | ✗ | ✔ | ✔ | ✗ | ✔ | ✔ | ✗ | ✔ | ||||||||||||||||||||
| Agent-FLAN Chen et al. (2024b) | Agent-FLAN | IFT | - | 24.7K | 20 | ✗ | ✔ | ✔ | ✗ | ✔ | ✔ | ✗ | ✔ | ||||||||||||||||||||
| AgentTuning (Zeng et al., 2023) | AgentInstruct | IFT | - | 35.0K | - | ✗ | ✔ | ✔ | ✗ | ✔ | ✗ | ✗ | ✔ | ||||||||||||||||||||
| Instruction Finetuning-based LLM Agents for Function Calling | |||||||||||||||||||||||||||||||||
| NexusRaven (Srinivasan et al., 2023) | NexusRaven | IFT | - | - | 116 | ✔ | ✔ | ✔ | ✗ | ✔ | ✗ | ✗ | ✗ | ||||||||||||||||||||
| Gorilla (Patil et al., 2023) | Gorilla | IFT | - | 16.0K | 1,645 | ✔ | ✗ | ✗ | ✔ | ✔ | ✗ | ✗ | ✗ | ||||||||||||||||||||
| OpenFunctions-v2 (Patil et al., 2023) | OpenFunctions-v2 | IFT | - | 65.0K | - | ✔ | ✔ | ✗ | ✔ | ✔ | ✗ | ✗ | ✗ | ||||||||||||||||||||
| API Pack Guo et al. (2024b) | API Pack | IFT | - | 1.1M | 11,213 | ✔ | ✗ | ✔ | ✗ | ✔ | ✗ | ✗ | ✗ | ||||||||||||||||||||
| LAM (Zhang et al., 2024a) | AgentOhana | IFT | - | 42.6K | - | ✔ | ✔ | ✔ | ✗ | ✔ | ✗ | ✔ | ✔ | ||||||||||||||||||||
| xLAM (Liu et al., 2024e) | APIGen | IFT | - | 60.0K | 3,673 | ✔ | ✔ | ✔ | ✗ | ✔ | ✗ | ✔ | ✔ | ||||||||||||||||||||
| Pretraining-based LLM Agents | |||||||||||||||||||||||||||||||||
| Hephaestus | Hephaestus-Forge | PT | 103B | 95.0K | 76,537 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ||||||||||||||||||||
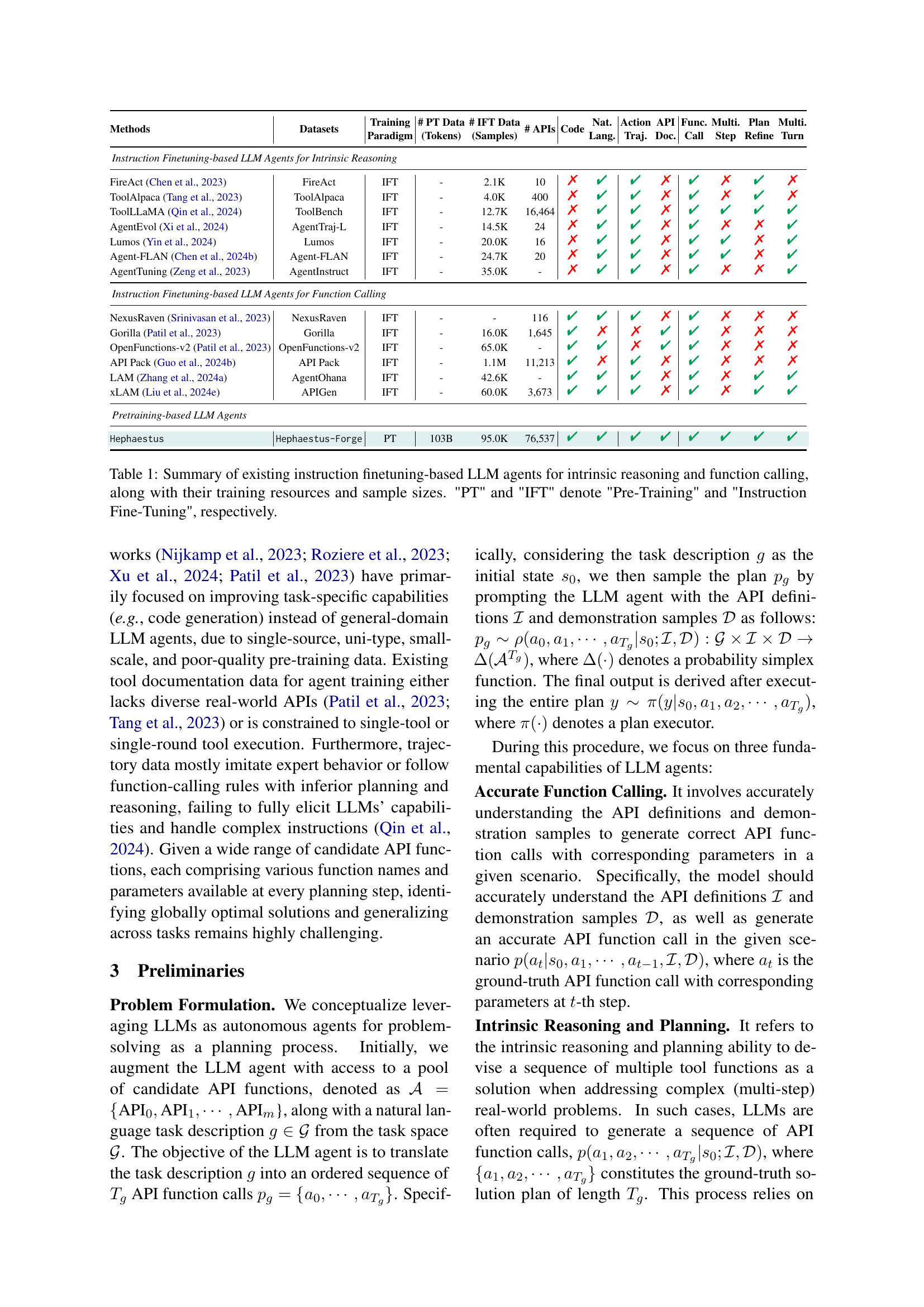
🔼 This table compares various existing Large Language Model (LLM) agents that utilize instruction fine-tuning for intrinsic reasoning and function calling. It details the methodology (Instruction Fine-Tuning), the dataset used for training (size, number of samples, and APIs), and whether the agent exhibits capabilities in natural language, action trajectories, API documentation, API function calling, multi-step refinement, and planning. The table highlights the limitations of instruction fine-tuning-only approaches by showing the scarcity of agent-specific pre-training data, emphasizing the differences between general-purpose and agent-oriented datasets. The abbreviations ‘PT’ and ‘IFT’ stand for ‘Pre-Training’ and ‘Instruction Fine-Tuning’, respectively.
read the caption
Table 1: Summary of existing instruction finetuning-based LLM agents for intrinsic reasoning and function calling, along with their training resources and sample sizes. 'PT' and 'IFT' denote 'Pre-Training' and 'Instruction Fine-Tuning', respectively.
In-depth insights#
Agent LLM Pretraining#
Agent LLM pretraining is a crucial area of research focusing on enhancing the fundamental capabilities of large language models (LLMs) for autonomous agent applications. Current methods often rely on complex prompting or extensive fine-tuning, which limits generalization and scalability. Agent-oriented pretraining addresses this by creating large-scale datasets specifically designed to improve core agentic skills, such as API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. This approach moves beyond superficial alignment by focusing on foundational capabilities rather than task-specific instruction following. A key challenge lies in the scarcity of suitable agent-specific data; therefore, innovative data curation and augmentation techniques are critical. Optimal data composition, including the balance of agent-specific data and general text/code, is a further critical research area, often explored via scaling laws. Successful agent LLM pretraining should result in enhanced performance across various agent benchmarks and improved generalization to new tasks and environments, ultimately bridging the gap between open-source and commercial LLMs in the field of autonomous agents.
Hephaestus-Forge Data#
The Hephaestus-Forge data is a multi-faceted, large-scale dataset designed to improve the fundamental capabilities of large language model (LLM) agents. It addresses the scarcity of agent-oriented pre-training data by including diverse sources such as API documentation, function-calling trajectories, code, and general text. This approach is crucial as it moves beyond instruction fine-tuning, acknowledging that foundational knowledge significantly impacts an agent’s generalizability. The dataset’s multi-modal nature enhances the LLM’s understanding of APIs and their usage, fostering enhanced intrinsic reasoning, planning, and adaptability. A notable aspect is the use of scaling laws to optimize the dataset’s composition, ensuring a balance between specialized agent data and general knowledge for robust performance. This highlights a data-driven approach to LLM agent development, focusing on the pre-training phase to build strong foundations, unlike methods relying heavily on post-training techniques that sometimes sacrifice generalization.
Scaling Laws & Mix#
The heading ‘Scaling Laws & Mix’ suggests an investigation into how the quantity and types of data used in training a large language model (LLM) impact its performance. Scaling laws explore the relationship between model size, dataset size, and performance, allowing researchers to predict the performance of larger models based on smaller-scale experiments. The ‘Mix’ component likely refers to the composition of the training dataset. This could involve combining different types of data, such as text, code, and agent-specific instructions, in various proportions. The research likely explores how these different data types contribute to the LLM’s abilities in tasks involving planning, reasoning, and function calling. The optimal mix of data types and the scaling behavior across various mixes is crucial for building effective and efficient LLMs, and understanding these aspects is paramount for improving the fundamental agent capabilities of LLMs. The study probably demonstrates an empirically derived optimal data composition ratio based on experiments using scaling laws, showing how specific data mixes affect agent performance and generalization capabilities.
Hephaestus Model#
The Hephaestus model, as described in the research paper, is a novel large language model (LLM) specifically designed to enhance the fundamental capabilities of LLM agents. Key improvements focus on API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. Unlike previous approaches that heavily rely on complex prompting or extensive fine-tuning, Hephaestus leverages a large-scale pre-training corpus called Hephaestus-Forge. This corpus contains a meticulously curated mix of agent-specific data (including API documentation and usage trajectories), code, and general text data, addressing the scarcity of agent-oriented pre-training data. The continual pre-training process results in a model that outperforms other open-source LLMs and rivals commercial LLMs in various agent benchmarks. This demonstrates the model’s effectiveness in improving fundamental agentic capabilities and its ability to generalize to new tasks and environments. A key innovation is the use of scaling laws to determine the optimal data mixing ratio in the pre-training corpus, leading to improved performance. The two-stage pre-training process, followed by instruction fine-tuning, contributes to the model’s robustness and strong performance across diverse tasks.
Ablation & Generalization#
An ablation study systematically removes components to isolate their individual contributions. In the context of a large language model (LLM) for agent tasks, this might involve removing specific pre-training data sources, such as API documentation or code examples, to assess their impact on performance. Generalization, on the other hand, measures the model’s ability to apply learned knowledge to new, unseen tasks or situations. A strong generalization capability is crucial for robust agent performance. The combination of ablation and generalization studies provides strong evidence of the model’s architecture. By carefully removing parts of the training process, researchers can pinpoint the specific components responsible for performance gains and identify any potential overfitting to specific tasks within the training data. This combination provides a more robust model with better transferability and reliability in various scenarios.
More visual insights#
More on figures

🔼 This figure shows a pie chart illustrating the composition of the Hephaestus-Forge dataset. It breaks down the dataset into its constituent parts: API documentation, function calls, code, multi-modality data, reasoning data, coding data, and various text sources (e.g. Arxiv, Wikipedia, web crawls). The proportions of each data type indicate the relative emphasis placed on different aspects of agent capabilities during pre-training.
read the caption
(a) Hephaestus-Forge

🔼 This figure shows the seed data used to create the Hephaestus-Forge pre-training corpus. It specifically details the ‘Tool Data’ component, illustrating the various sources of information included. These sources represent diverse types of agent-related data and include API trajectories, tool documentation from multiple sources (e.g., StarCoder APIs, API-Pack, ToolBench, etc.), code examples, and natural language planning data.
read the caption
(b) Tool Data

🔼 This figure shows a t-SNE visualization of the retrieved web data used in the Hephaestus-Forge dataset. The visualization plots the data points in a two-dimensional space, where proximity indicates semantic similarity. The colorful points represent the seed data from various sources, while the black points represent the retrieved data. The gray points represent the general text data. The visualization demonstrates that the retrieved data is more semantically similar to the seed data than to the general text, indicating successful retrieval of relevant agent data from the web.
read the caption
(c) Retrieved Data

🔼 This t-SNE plot visualizes the semantic relationships between different data sources used in the Hephaestus-Forge dataset. Seed data (colorful points) from various sources like API documentation, code, and web crawls are shown, along with the retrieved web data (black points) and general text data (gray points). The proximity of the retrieved data points to the seed data points illustrates the effectiveness of the semantic matching process in retrieving relevant web data for pre-training.
read the caption
(d) t-SNE: Retrieved Data

🔼 Figure 2 illustrates the composition of the Hephaestus-Forge dataset. Panel (a) shows an overview of the entire dataset, highlighting the diverse data sources. Panel (b) details the seed data collection process, outlining the different sources and their relative contributions. Panel (c) shows the retrieved agent data obtained from the open web, expanding the dataset further. Finally, panel (d) provides a t-SNE visualization of the semantic space, demonstrating that the retrieved data points cluster closely to the seed data points and are clearly distinct from general text. This highlights the quality and relevance of the retrieved data.
read the caption
Figure 2: Data composition of (a) the entire Hephaestus-Forge, (b) seed data collection (§ 4.1), and (c) retrieved agent data from the open web (§ 4.2). A t-SNE visualization (d) depicts seed data (colorful points, with each color representing different data sources), retrieved data (black), and general text (gray) within the semantic space, where retrieved data is closer to the selected seed data than to the general text. Detailed data sources are in § A.1.

🔼 This figure shows the results of experiments investigating the optimal ratio of agent data within a pre-training corpus for large language models (LLMs). The x-axis represents the percentage of agent data in the training corpus, while the y-axis displays the benchmark loss (a measure of model performance). Multiple lines represent different benchmarks, demonstrating how the loss changes as the proportion of agent data varies. The figure demonstrates that an optimal mixing ratio exists, where including too little or too much agent data negatively impacts performance.
read the caption
Figure 3: Scaling law of the relationship between agent data mixing ratio (%percent\%%) and benchmark loss.

🔼 This figure illustrates the three-stage training process for the Hephaestus model. Stage I involves injecting general agent knowledge through pre-training on a large dataset containing diverse data sources like general text, code, and API documentation. In Stage II, the model further enhances its agent-specific capabilities using a high-quality seed dataset of agent-relevant data. Finally, Stage III includes instruction fine-tuning using instruction-completion datasets to align the model with specific task requirements and user preferences.
read the caption
Figure 4: Overview of the pre-training (Stages I & II) and instruction fine-tuning (III) framework in Hephaestus.

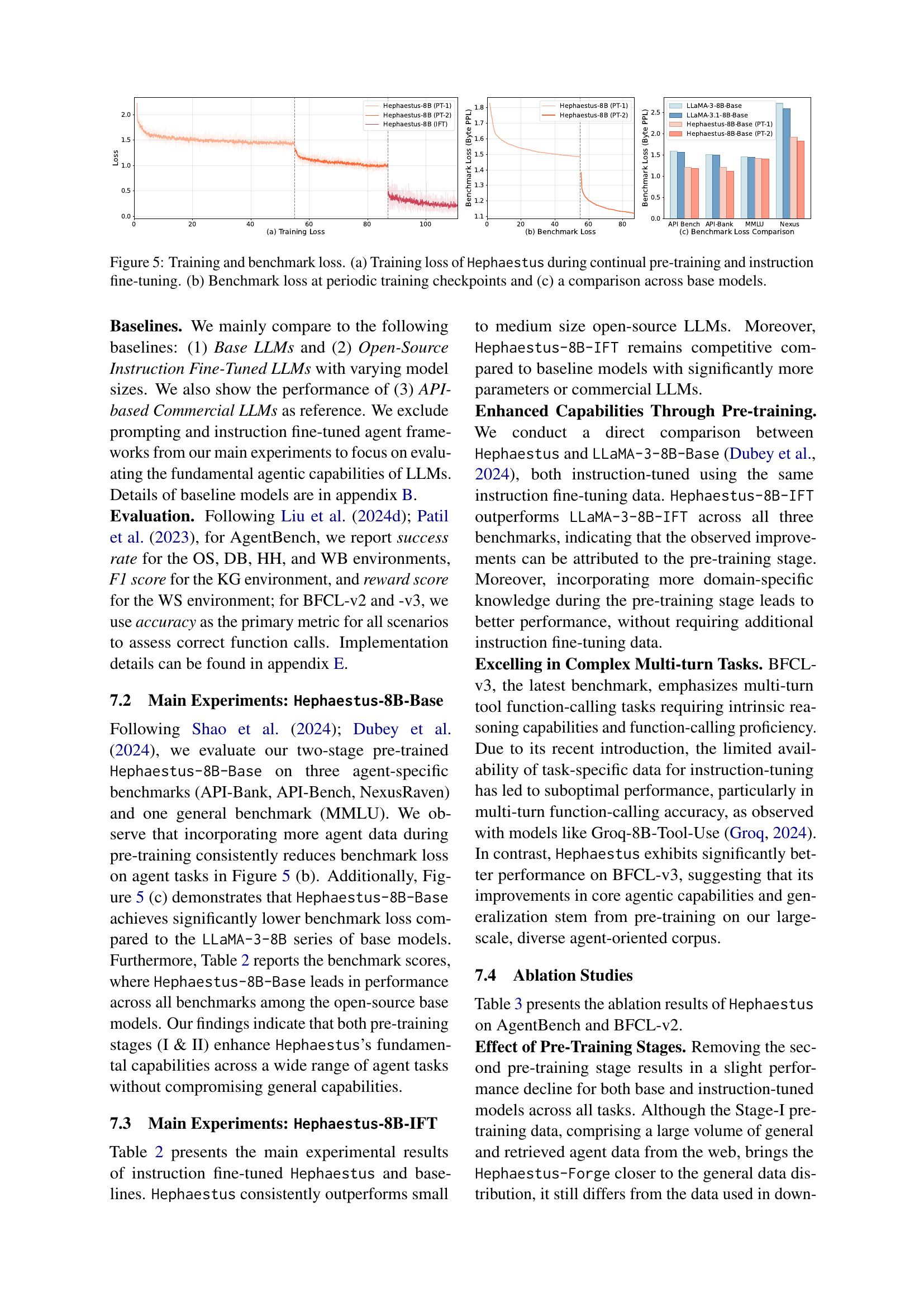
🔼 Figure 5 illustrates the training and evaluation results for the Hephaestus model. Panel (a) shows the training loss curve during both continual pre-training (with two distinct stages) and subsequent instruction fine-tuning. Panel (b) displays the benchmark loss at various checkpoints during the training process, demonstrating performance improvement over time. Finally, panel (c) provides a comparative analysis of the benchmark loss across different base models, highlighting Hephaestus’s superior performance.
read the caption
Figure 5: Training and benchmark loss. (a) Training loss of Hephaestus during continual pre-training and instruction fine-tuning. (b) Benchmark loss at periodic training checkpoints and (c) a comparison across base models.

🔼 Figure 6 presents example task formats from the Hephaestus-Forge dataset, illustrating the diversity of data included. It showcases three key aspects: Tool documentation provides structured information about APIs, detailing parameters and functionalities. Action trajectories, often with environmental feedback, show sequences of actions taken by an agent to solve a problem, including observations and resulting responses. Code data includes actual code examples that are relevant to the tasks and contribute to the model’s understanding of both problem-solving strategies and implementation details.
read the caption
Figure 6: Examples of different task formats in Hephaestus-Forge, including tool documentation, action trajectory (w/ environmental feedback), and code data.
More on tables
| Training |
| Paradigm |
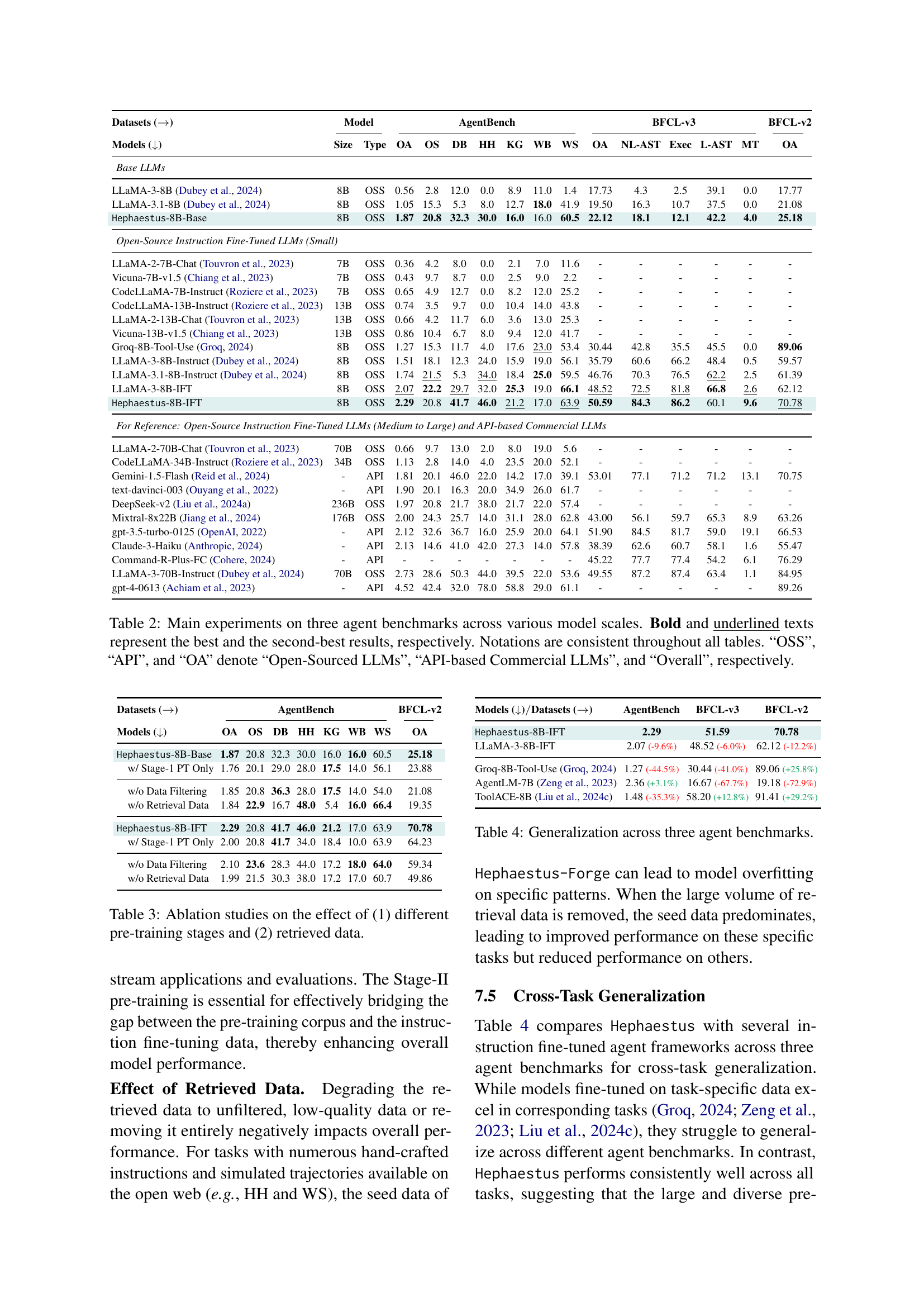
🔼 This table presents the results of the main experiments comparing the performance of the Hephaestus model with various baselines across three agent benchmarks: AgentBench, BFCL-v3, and BFCL-v2. Different model sizes are included in the comparison, ranging from small open-source LLMs to larger, commercial API-based models. The best and second-best results for each benchmark are highlighted in bold and underlined text, respectively. The table also provides a clear indication of whether the models are open-source (OSS) or API-based commercial LLMs.
read the caption
Table 2: Main experiments on three agent benchmarks across various model scales. Bold and underlined texts represent the best and the second-best results, respectively. Notations are consistent throughout all tables. “OSS”, “API”, and “OA” denote “Open-Sourced LLMs”, “API-based Commercial LLMs”, and “Overall”, respectively.
| # PT Data |
| (Tokens) |
🔼 This ablation study investigates the impact of the two-stage continual pre-training and the retrieved web data on the model’s performance. It compares the full model’s results against versions where one or both of these components have been removed, allowing for a quantitative analysis of their individual contributions. The metrics used likely reflect the model’s performance on benchmark tasks such as intrinsic reasoning and function calling.
read the caption
Table 3: Ablation studies on the effect of (1) different pre-training stages and (2) retrieved data.
| # IFT Data |
| (Samples) |
🔼 This table presents a comparison of various LLMs’ performance across three agent benchmark tasks: AgentBench, BFCL-v3, and BFCL-v2. It demonstrates the ability of Hephaestus to generalize its capabilities beyond the specific tasks it was trained on, unlike models fine-tuned for specific tasks. The results highlight Hephaestus’s superior performance, particularly in multi-turn complex tasks.
read the caption
Table 4: Generalization across three agent benchmarks.
| Nat. |
| Lang. |
🔼 Table 5 presents a comprehensive evaluation of Hephaestus and other LLMs across various benchmarks. It demonstrates Hephaestus’s ability to maintain strong general language model capabilities while also exhibiting competitive performance on tasks specifically designed for agent-based LLMs. The benchmarks cover a range of tasks, including mathematical reasoning, code generation, commonsense reasoning, and instruction following. The results show that Hephaestus performs competitively with or better than many base and specialized models, highlighting its effectiveness in balancing general abilities with specific agent capabilities.
read the caption
Table 5: Comprehensive evaluation of general model capabilities across diverse benchmarks. Hephaestus maintains general capabilities while achieving competitive performance against baseline and specialized models.
| Action |
| Traj. |
🔼 This table presents the performance of the fastText filter in classifying agent-relevant data from general web data. It shows the accuracy, F1-score, precision, and recall achieved by the filter. These metrics help assess the effectiveness of the filter in identifying relevant data for training the Hephaestus model and removing noisy or irrelevant information.
read the caption
Table 6: Classification results of the fastText filter.
| API |
| Doc. |
🔼 Table 7 presents the main experimental results for the Berkeley Function Calling Leaderboard (BFCL)-v2 benchmark. It shows the performance of various LLMs, including Hephaestus and several baselines, across multiple aspects of function calling. The metrics include overall accuracy, as well as performance broken down by function type (Simple, Python, Java, Javascript, Multi-Function, Parallel Function, Parallel Multi-Function), and execution success rate. This detailed breakdown allows for a precise comparison of the different models’ capabilities in handling various aspects of function calling and execution, highlighting the strengths and weaknesses of each approach.
read the caption
Table 7: Main experiment results on BFCL-v2.
| Func. |
| Call |
🔼 This table presents a comparison of the performance of different models on the AgentBench benchmark. It specifically focuses on the results obtained using Hephaestus-7B, which is based on the Mistral-7B-v0.3 large language model (LLM), and compares its performance against other baselines such as the Mistral-7B-v0.3 model itself, both with and without instruction fine-tuning. The comparison allows for an assessment of the impact of the Hephaestus pre-training methodology on AgentBench performance and highlights the effects of using a specific backbone LLM (Mistral-7B-v0.3) on overall results.
read the caption
Table 8: Experimental results of Hephaestus-7B (Mistral) with Mistral-7B-v0.3 as backbone LLM on AgentBench.
| Multi. |
| Step |
🔼 Table 9 details the sources of seed data used to create the Hephaestus-Forge pre-training corpus. It lists each data source, its type (e.g., trajectory data, documentation), format, size in billions of tokens, and a URL link to access the data. The table provides transparency regarding the diverse and extensive resources used to build the dataset.
read the caption
Table 9: Data sources of the seed data in Hephaestus-Forge.
| Plan |
| Refine |
🔼 This table lists the additional seed data sources used in creating the Hephaestus-Forge pre-training corpus. It details the type of data (e.g., Trajectories, Documentation), the format, the size in billions of tokens, and a link to the data source for each entry. This is a continuation of Table 9, providing a more complete picture of the diverse data used to build the corpus.
read the caption
Table 10: Data sources of the seed data in Hephaestus-Forge (Cont’d).
Full paper#