TL;DR#
Current 3D shape generation methods struggle with output quality, generalization, and alignment with input conditions. Existing approaches often rely on limited datasets and face challenges in processing complex 3D data. They also struggle with creating high-fidelity models aligned with input images and often suffer from artifacts.
This paper introduces TripoSG, a novel framework addressing these challenges. It uses a large-scale rectified flow transformer trained on a meticulously curated dataset of 2 million high-quality 3D samples. The approach uses a hybrid training strategy that combines SDF (Signed Distance Function), surface normal, and eikonal loss for high-fidelity 3D mesh generation. The system also incorporates a sophisticated data processing pipeline to ensure high-quality training data. Results demonstrate TripoSG achieves state-of-the-art performance in 3D shape synthesis.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D shape generation because it presents TripoSG, a novel method achieving state-of-the-art results. It addresses key challenges in the field through a combination of data processing, a novel architecture (rectified flow transformer), and training techniques, offering significant potential for advancements in image-to-3D generation applications. The public availability of the model further enhances its impact, accelerating future research and development.
Visual Insights#

🔼 This figure showcases a diverse range of high-quality 3D models generated by the TripoSG model. The examples highlight the model’s ability to create complex shapes with intricate details, demonstrating its capacity to handle various styles and incorporate multiple objects within a single scene. The variety of designs, from realistic to imaginative, underscores the model’s powerful generative capabilities and its potential for diverse applications.
read the caption
Figure 1: High-quality 3D shape samples from our largest TripoSG model. Covering various complex structures, diverse styles, imaginative designs, multi-object compositions, and richly detailed outputs, demonstrates its powerful generation capabilities.
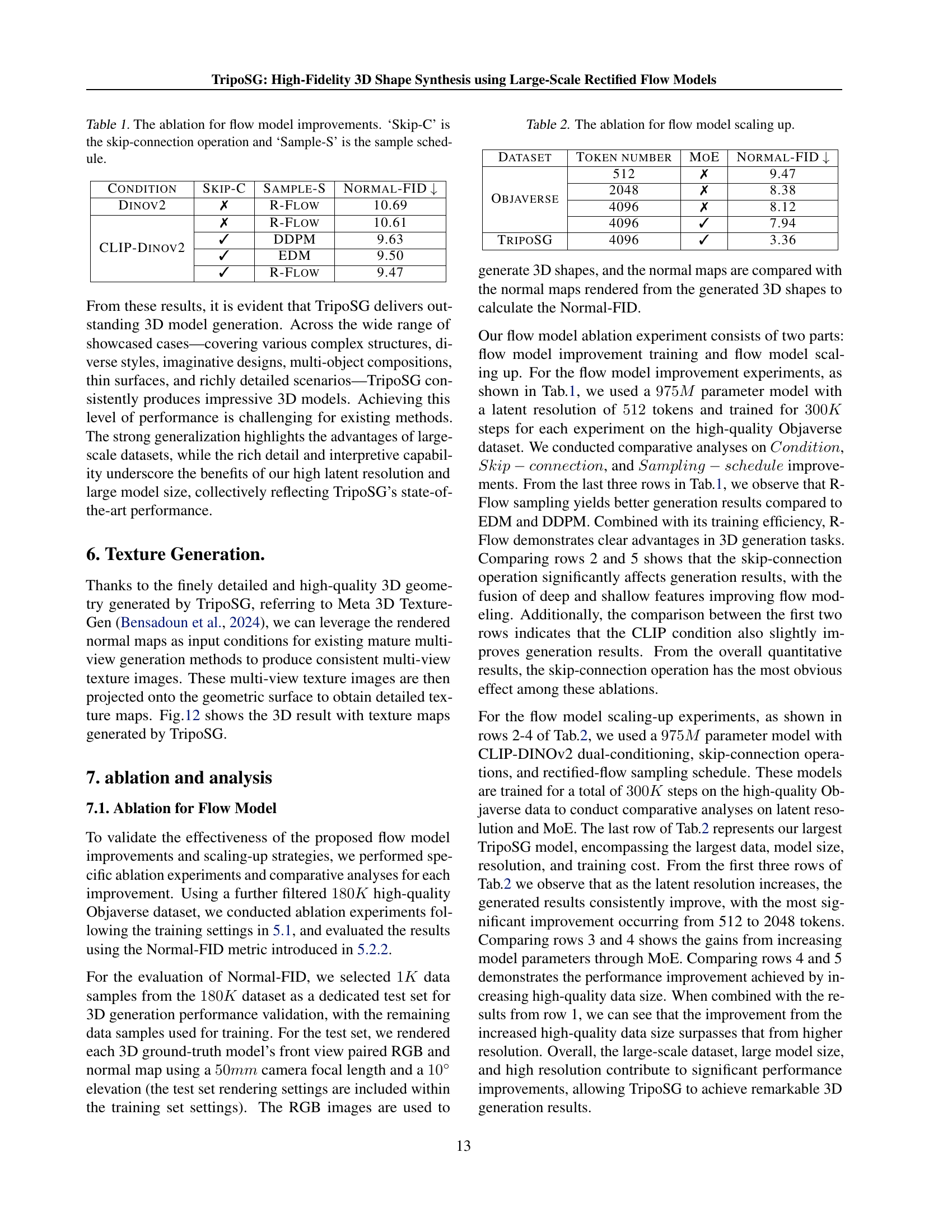
| Condition | Skip-C | Sample-S | Normal-FID |
|---|---|---|---|
| Dinov2 | ✗ | R-Flow | 10.69 |
| CLIP-Dinov2 | ✗ | R-Flow | 10.61 |
| ✓ | DDPM | 9.63 | |
| ✓ | EDM | 9.50 | |
| ✓ | R-Flow | 9.47 |
🔼 This table presents the results of ablation studies conducted on the flow model to analyze the impact of various design choices on model performance. The studies involved removing or modifying specific components, such as skip connections and the sample schedule. The results are evaluated using Normal-FID, which measures the discrepancy between generated 3D models’ normal maps and ground-truth normal maps. Lower scores indicate better performance.
read the caption
Table 1: The ablation for flow model improvements. ‘Skip-C’ is the skip-connection operation and ‘Sample-S’ is the sample schedule.
In-depth insights#
Rectified Flow in 3D#
Rectified flow models, known for their success in 2D image generation, present a compelling approach to 3D shape synthesis. The core idea involves learning a transformation (flow) that maps a simple, easily sampled distribution (like Gaussian noise) to the complex distribution of 3D shapes. This avoids the difficulties associated with directly modeling the intricate probability distribution of 3D shapes. A key advantage is the potential for improved training stability and efficiency. Unlike methods relying on occupancy grids or voxel representations, rectified flow can potentially handle high-fidelity details and complex geometries more effectively, leading to higher-quality 3D outputs. However, challenges remain in scaling to high-dimensional 3D spaces and ensuring efficient inference. The success hinges critically on the availability of large-scale, high-quality 3D training data, which is a significant hurdle in the field. Furthermore, the effectiveness of the learned flow in capturing the intricate relationships and dependencies within 3D shapes needs further investigation. Addressing these challenges through novel architectural designs and data augmentation techniques will be crucial to unlocking the full potential of rectified flow for advanced 3D shape generation.
VAE Improvements#
The research paper significantly advances 3D shape generation by introducing crucial improvements to the Variational Autoencoder (VAE). The core innovation lies in employing a Signed Distance Function (SDF) representation for 3D shapes, which offers superior geometric expressiveness compared to traditional occupancy grids. This leads to sharper and more precise 3D models, mitigating the aliasing artifacts common in other approaches. Furthermore, geometry-aware supervision is incorporated through the integration of surface normal guidance and eikonal regularization into the VAE training process. This refined training strategy significantly enhances the reconstruction quality, capturing intricate geometric details. The VAE’s capacity is scaled up by training it at an unprecedented resolution, enabling the encoder to produce highly detailed and geometrically precise latent representations of complex shapes, ready for downstream processing by the flow-based diffusion model. The paper also highlights the importance of high-quality data in achieving state-of-the-art results, underscoring the need for a robust data pipeline and processing to guarantee superior fidelity in the generated 3D models.
Data Quality Focus#
A critical aspect of the research is the emphasis on data quality. The authors don’t merely focus on quantity; they implement a rigorous data processing pipeline to ensure that the training data is of sufficiently high quality to enable the generation of high-fidelity 3D models. This involves several key steps: scoring, filtering, fixing and augmentation, and field data production. The scoring process assigns quality scores to the 3D models, allowing for the filtering of low-quality data. Fixing and augmentation address inconsistencies, and field data production generates additional high-quality data. The meticulous attention to data quality, which is frequently overlooked in similar studies, directly contributes to the superior results achieved by TripoSG. The authors demonstrate that high-quality data is a necessary condition for high-fidelity 3D shape synthesis, and that merely having a large amount of data is not sufficient. They show that improperly processed data can substantially hinder the training process, highlighting the importance of their data-building system and its rigorous approach. This focus on quality and quantity provides a valuable contribution to the field of generative AI.
Hybrid Supervised Training#
Hybrid supervised training, in the context of 3D shape generation, likely refers to a method that combines multiple loss functions to guide the training process. This approach moves beyond single-loss methods, such as solely relying on reconstruction loss, by incorporating additional signals. This multi-faceted approach is crucial because accurately reconstructing 3D shapes from limited data (like a single image) is an inherently ill-posed problem. A hybrid approach might leverage a combination of losses like: 1) Reconstruction loss (comparing generated shape to ground truth), ensuring the model creates a geometrically faithful representation. 2) Perceptual loss (measuring similarity in feature space using metrics like LPIPS), encouraging the generated shapes to resemble the real object in terms of visual appearance. 3) Geometric consistency losses (e.g., enforcing manifold constraints or penalizing non-watertight meshes), improving the quality and validity of the generated 3D model. The effectiveness of hybrid supervised training hinges on carefully selecting and weighting these losses. An inappropriate balance could lead to suboptimal results where the model prioritizes one aspect (e.g., visual similarity) at the expense of accuracy (e.g., geometric fidelity). A successful strategy will involve a well-tuned optimization process that balances these competing goals, thereby leading to high-fidelity 3D shape synthesis with improved generalization across diverse input conditions. Furthermore, the use of large-scale, high-quality datasets is paramount for the success of any hybrid supervised training strategy as it provides the model with the necessary data to learn complex relationships and generalize well.
Large-Scale 3D Gen#
Generating high-fidelity 3D models requires overcoming significant hurdles, primarily the scarcity of large-scale, high-quality datasets for training. Large-scale 3D generation necessitates a paradigm shift from reliance on limited datasets to leveraging extensive, curated data. This shift demands a robust data pipeline, including sophisticated data processing, filtering, and augmentation techniques, to generate high-quality training samples. Effective data processing is crucial not only for quantity but also for ensuring data consistency and preventing training instability. Furthermore, innovative model architectures are needed to handle the complexity of large-scale 3D data, potentially incorporating advanced techniques like rectified flow transformers or mixture-of-experts models. These architectures must allow for efficient training and inference while maintaining fidelity and geometric precision in generated outputs. Finally, evaluation metrics for assessing the quality of large-scale 3D models require refinement beyond standard metrics to capture details like fine-grained geometry and texture fidelity. Addressing these challenges is paramount for achieving true breakthroughs in large-scale 3D generation.
More visual insights#
More on figures
🔼 This figure illustrates the two main components of the TripoSG method: the Data-Building System and the TripoSG model. The Data-Building System takes 3D models from diverse datasets like Objaverse and ShapeNet. It then processes these models through several steps to improve their quality and suitability for training. The cleaned and enhanced 3D models are used to train the TripoSG model. Once trained, this TripoSG model can generate high-fidelity 3D shapes from a single input image.
read the caption
Figure 2: The overview of our method consists of two main components: (i) Data-Building System and (ii) TripoSG Model. The data-building system processes the 3D models from various datasets (e.g., Objaverse and ShapeNet) through a series of data processing steps to create the training data. Our TripoSG model is then trained on this curated dataset for high-fidelity shape generation from a single input image.

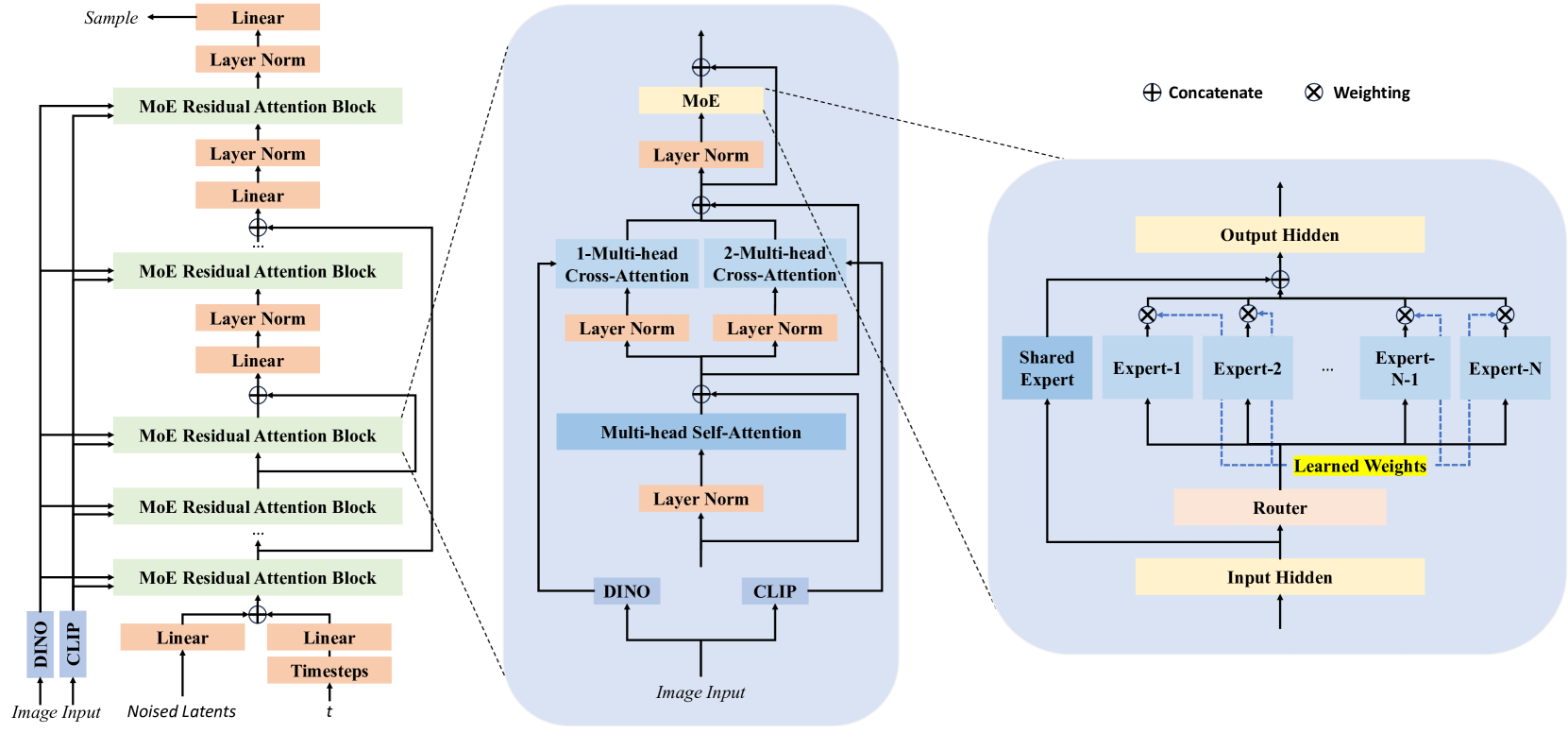
🔼 Figure 3 provides a comprehensive visual explanation of the TripoSG model’s architecture. The left panel presents a high-level overview of the entire model, showing the flow of data from image input to 3D shape output. The central panel zooms in on a single block within the model, detailing its internal structure—including multi-head cross-attention, MoE residual attention blocks, and skip connections. The right panel further dissects the Mixture-of-Experts (MoE) mechanism itself, illustrating its individual components and how it works in the architecture. Together, these three parts offer a clear and detailed understanding of the TripoSG model’s design and functionality, from its global structure to its most granular components.
read the caption
Figure 3: Left: the overall architecture of TripoSG. Middle: the detailed internal module of each block. Right: the detailed internal components of the MoE.

🔼 This figure details TripoSG’s Variational Autoencoder (VAE), a crucial component for compressing and decompressing 3D shape information into a latent representation. The diagram showcases a transformer-based architecture, divided into an encoder (top) and decoder (bottom). The encoder processes input 3D data (SDF, Occupancy, Normal, Texture) and maps it to latent tokens. Conversely, the decoder uses these latent tokens to reconstruct the 3D mesh. Key aspects like skip connections and the use of Signed Distance Function (SDF) representation for superior geometric detail are implicitly shown in the architecture. The figure highlights the use of several loss functions to enhance the learning process, including SDF loss, surface normal guidance, and eikonal loss. These techniques help to improve the reconstruction quality.
read the caption
Figure 4: TripoSG’s transformer-based VAE architecture. The upper is the encoder and the lower is the decoder.

🔼 This figure compares the 3D model reconstructions generated using occupancy representation (top) and signed distance function (SDF) representation (bottom). It highlights the superior geometric detail and precision achieved using SDF compared to occupancy, showcasing the sharper and cleaner rendering results obtained with SDF. Aliasing artifacts, common in occupancy-based reconstructions, are noticeably absent in the SDF reconstruction.
read the caption
Figure 5: Comparison between model reconstruction based on Occupancy (top) and SDF (bottom).

🔼 This figure illustrates the TripoSG data-building system, a four-stage pipeline designed to create high-quality training data for 3D shape generation models. Stage I involves scoring the quality of raw 3D data using a trained scoring model. Stage II filters out low-quality models based on criteria like planar bases, animation errors, and multiple objects. Stage III focuses on fixing orientation inconsistencies and adding augmentations for more comprehensive training. Finally, Stage IV involves generating the final training data by converting the models into signed distance functions and sampling surface points for further processing.
read the caption
Figure 6: Demonstration of the TripoSG data-building system. I: Data scoring procedure; II: Data filtering procedure; III: Data fixing and augmentation procedure. IV: Field data producing procedure.

🔼 Figure 7 presents a detailed comparison of 3D model generation results from TripoSG and several other state-of-the-art methods. Using identical input images for each method, the figure showcases generated models using different approaches. This allows for a visual assessment of each method’s strengths and weaknesses in terms of detail, accuracy, and overall fidelity to the original input image. The models are presented in multiple views to highlight the 3D aspects. The purpose is to demonstrate TripoSG’s superior performance in generating high-quality, realistic 3D shapes.
read the caption
Figure 7: Comparison of 3D generation performance of TripoSG and other previous state-of-the-art methods under the same image input.

🔼 Figure 8 is a radar chart comparing different 3D generation methods across five key aspects: 3D plausibility (how realistic the generated 3D model looks), text-asset alignment (how well the generated model matches the text description or input image), geometry details (level of detail and accuracy of the 3D shape), texture details (quality and realism of the surface textures), and texture-geometry coherency (how well the textures blend with the 3D geometry). Each method’s performance in each of these aspects is scored, and the scores are visually represented using a radar chart to provide a comprehensive comparison.
read the caption
Figure 8: Radar chart of the score of different methods in 5 aspects, including 3D plausibility, text-asset alignment, geometry details, texture details, texture-geometry coherency.

🔼 This figure shows a qualitative comparison of the results from training a Variational Autoencoder (VAE) using different 3D representations and training supervision methods. The different approaches compared include using occupancy grids versus signed distance functions (SDFs), with and without surface normal guidance, and with and without eikonal regularization. This allows for a visual comparison of the quality of 3D model reconstruction and the presence of artifacts like aliasing and ‘floaters’ in the resulting 3D models.
read the caption
Figure 9: Qualitative comparison for the ablation of VAE with different types of 3D representation and training supervision.

🔼 Figure 10 visualizes the results of ablation experiments performed on the flow model. The goal was to isolate the impact of different aspects of the TripoSG model on its performance. Each row shows a set of 3D model generations, comparing results from different configurations: using or omitting the data-building system (DBS), varying the latent token number, and using a larger (2M) dataset. ‘DBS’ refers to the system used for processing raw data into a high-quality training dataset. The figure showcases how these changes affected the quality of 3D model generation, highlighting the contributions of the individual model elements and the importance of the data-building system. Visual comparison enables an easy understanding of the impact of these different factors on the generated 3D models.
read the caption
Figure 10: Visualization results of the flow model ablation experiments. ‘DBS’ is the abbreviation for Data-Building System.

🔼 This figure showcases a wide variety of 3D models generated by the TripoSG model. The models are presented without textures, highlighting the underlying geometric detail and diversity of shapes achievable by the system. The range of shapes includes both organic and inorganic forms, with varying levels of complexity and realism, demonstrating the TripoSG model’s capability to generate diverse and intricate 3D structures.
read the caption
Figure 11: A diverse array of texture-free 3D shapes generated by TripoSG.
More on tables
| Dataset | Token number | MoE | Normal-FID |
|---|---|---|---|
| Objaverse | 512 | ✗ | 9.47 |
| 2048 | ✗ | 8.38 | |
| 4096 | ✗ | 8.12 | |
| 4096 | ✓ | 7.94 | |
| TripoSG | 4096 | ✓ | 3.36 |
🔼 This table presents the results of ablation experiments conducted to evaluate the effectiveness of different strategies for scaling up the flow model. It shows how the Normal-FID (a metric for evaluating the fidelity of generated 3D shapes) changes as the model’s latent token number and the use of Mixture-of-Experts (MoE) are varied. The experiments were performed using the Objaverse dataset, with different sizes of the dataset used across several rows. The results highlight the impact of increasing model size and latent resolution on the quality of generated 3D shapes.
read the caption
Table 2: The ablation for flow model scaling up.
| Dataset | Repr. | Chamfer | F-score | N.C. | ||
|---|---|---|---|---|---|---|
| Objaverse | Occ | ✗ | ✗ | 4.59 | 0.999 | 0.952 |
| SDF | ✗ | ✗ | 4.60 | 0.999 | 0.955 | |
| SDF | ✓ | ✗ | 4.56 | 0.999 | 0.956 | |
| SDF | ✓ | ✓ | 4.57 | 0.999 | 0.957 | |
| TripoSG | SDF | ✓ | ✓ | 4.51 | 0.999 | 0.958 |
🔼 This table presents an ablation study analyzing the impact of various factors on the Variational Autoencoder (VAE) component of the TripoSG model. It compares different 3D representations (Occupancy vs. SDF), training supervision methods (with and without surface normal loss and eikonal regularization), and dataset sizes (large TripoSG dataset vs. smaller Objaverse dataset) to evaluate their effects on the VAE’s performance. The metrics used to assess performance include Chamfer distance, F-score, and normal consistency.
read the caption
Table 3: The ablation of different VAE, including 3D representation, training supervision and training dataset. ‘Repr’ refers to the type of 3D representation used, and ‘ℒsnsubscriptℒsn\mathcal{L}_{\text{sn}}caligraphic_L start_POSTSUBSCRIPT sn end_POSTSUBSCRIPT’ and ‘ℒeiksubscriptℒeik\mathcal{L}_{\text{eik}}caligraphic_L start_POSTSUBSCRIPT eik end_POSTSUBSCRIPT’ refer to surface normal loss and eikonal regularization respectively. The ‘Dataset’ indicates whether a large (TripoSG) or a small dataset (Objaverse) is used.
| Dataset | Size | Data-building System | Normal-FID |
|---|---|---|---|
| Objaverse | ✗ | 11.61 | |
| ✓ | 9.47 | ||
| TripoSG | ✓ | 5.81 |
🔼 This table presents ablation study results focusing on the impact of data quality and quantity on the model’s performance. It shows how using a data-building system to improve data quality (by filtering, fixing, etc.) affects the model’s Normal-FID score, compared to using the raw dataset. It also demonstrates the performance gain from increasing the size of the high-quality dataset.
read the caption
Table 4: The ablation for data quality and quantity.
Full paper#