TL;DR#
Many large language models (LLMs) lack transparency, accessibility, and resource efficiency. Existing open-source LLMs often fall short in providing detailed model-building processes, hindering reproducibility and limiting contribution to the field. This research addresses these issues by focusing on the Chinese language, with a smaller proportion of English data, to offer a more complete and practical account of the model-building journey.
This paper introduces Steel-LLM, a fully open-source Chinese-centric LLM developed with limited resources. Steel-LLM’s resource-efficient model development, achieved using only 8 GPUs, showcases how high-quality LLMs can be built without large-scale infrastructure. The project prioritizes complete transparency by releasing the training pipeline, dataset, model architecture, and intermediate checkpoints, promoting reproducibility and facilitating further research. Practical guidance provided for small-scale research enables others to build upon this work, while its competitive performance on Chinese benchmarks validates its effectiveness. The model’s open-source nature fosters collaboration and contributes to a more accessible LLM development field.
Key Takeaways#
Why does it matter?#
This paper is important because it demonstrates that high-quality language models can be developed with limited resources and transparency, opening up possibilities for researchers and practitioners with fewer resources. It offers practical guidance and reproducible results, addressing challenges in open-source LLM development. Its focus on a Chinese-centric model fills a gap in the field. This work promotes collaboration by openly sharing data, code, and training processes.
Visual Insights#

🔼 This figure illustrates the architecture of a Transformer block within the Steel-LLM model. It shows the flow of information through the self-attention mechanism and the enhanced feed-forward network (FFN). The self-attention module processes input tokens, and the FFN, enhanced with Soft Mixture of Experts (Soft MOE), further transforms the results. The diagram details the components within the FFN, including MLP layers and the Swish activation function, and highlights the use of Soft MOE for efficient processing of large numbers of tokens.
read the caption
Figure 1: The architecture of Steel-LLM Transformer block
| Parameters | Value |
| Layers | 18 |
| Heads | 32 |
| KV heads | 32 |
| Num_experts | 6 |
| Slots_per_expert | 1 |
| Hidden size | 1,792 |
| Intermediate size | 1,792 |
| Vocab size | 151,936 |
🔼 This table lists the key hyperparameters used in the architecture of the Steel-LLM model. It includes details such as the number of layers, attention heads, hidden size, the number of experts and slots used in the Soft Mixture of Experts (Soft MOE) layer, and the vocabulary size. These parameters are crucial for understanding the model’s size, computational requirements, and capacity.
read the caption
Table 1: Key model parameters.
In-depth insights#
Open LLM Creation#
Open LLM creation presents a compelling vision: democratizing access to powerful language models. Transparency is paramount, requiring open-sourcing not only model weights but also training data, code, and methodologies. This fosters reproducibility and accelerates progress, allowing researchers with limited resources to contribute meaningfully. However, the resource intensity of training LLMs poses a significant barrier. Open initiatives must address this by developing efficient training techniques, smaller models, or collaborative training approaches, potentially leveraging decentralized infrastructure. Community involvement is vital: open projects can flourish through shared expertise and collective effort. Balancing the need for robust model performance with practical accessibility will define the success of open LLM initiatives. Ethical considerations must be at the forefront, addressing biases in training data and ensuring responsible use. Ultimately, successful open LLM creation should lead to a more inclusive and innovative landscape for NLP research and applications.
Resource-Frugal LLM#
The concept of a ‘Resource-Frugal LLM’ is crucial for democratizing access to large language models. Reducing computational costs associated with training and inference is key. This involves exploring model architectures that are efficient with parameters, like smaller models with innovative designs, or those using techniques like quantization and pruning. Furthermore, efficient training methods are essential, such as utilizing optimized hardware and software. Data efficiency is another important factor; using smaller, higher-quality datasets tailored for a specific task rather than massive general datasets reduces resource needs. Open-sourcing these resource-frugal models and their training procedures is vital. Transparency and reproducibility enable the broader research community to build upon this work and further advance the field, rather than relying on resource-intensive models developed by large corporations. Such advancements are critical in making LLMs accessible to researchers and developers with limited resources, promoting wider adoption and innovation in NLP.
Chinese-centric Focus#
The research paper’s “Chinese-centric Focus” is a noteworthy aspect, highlighting a crucial gap in the current LLM landscape. The dominance of English-centric models creates limitations for understanding and serving the nuances of other languages. This focus is commendable because it addresses the underrepresentation of Chinese in the field of large language models. By prioritizing Chinese data in training, the researchers directly tackle the issue of linguistic bias. The inclusion of a smaller proportion of English data is a strategic move, aiming to improve the model’s multilingual capabilities without sacrificing performance in its primary language. This approach fosters the development of more inclusive and representative AI technology. The results demonstrate the viability of creating high-quality LLMs with a focus on a non-English language, even with limited computational resources. This success is especially important for promoting linguistic diversity and accessibility in AI, potentially impacting numerous applications within the Chinese-speaking world and contributing to global advancements in multilingual natural language processing. The model’s open-source nature further amplifies the significance of the Chinese-centric approach. It allows researchers and developers worldwide to build upon the work, leading to further refinements and innovations that address specific Chinese linguistic challenges and potentially benefit other language communities facing similar issues. This proactive strategy shows the potential to empower language-specific AI development.
Soft MOE & FFN#
The section on “Soft MOE & FFN” would delve into the model’s architecture, specifically focusing on how the authors improved the Feed-Forward Network (FFN) layer within the Transformer blocks. A key innovation is the use of Soft Mixture of Experts (Soft MOE), a technique that enhances model performance and efficiency. Unlike traditional FFNs, Soft MOE uses a gating network to route input tokens to specialized expert networks, offering a significant advantage in terms of parameter efficiency. The description would likely discuss the design choices behind implementing Soft MOE, including the number of experts and slots used, and how these choices impact computational cost. The paragraph will also likely discuss any modifications made to the two MLP layers within the FFN, possibly highlighting the use of SwiGLU activation functions to improve non-linearity. Further, there would be a detailed explanation of the mathematical formulation of the Soft MOE, illustrating how the input tokens are routed and combined to generate the final output. Finally, the authors would likely discuss the trade-offs between the use of Soft MOE, computational constraints (given their limited resources), and the overall effect on model performance. The improved efficiency due to Soft MOE would be a significant highlight, as it allowed them to train a high-quality, billion-parameter model without requiring excessive computational power.
Future Directions#
Future directions for Steel-LLM research should prioritize expanding its multilingual capabilities beyond the current Chinese-centric focus. Improving the model’s robustness to noisy or low-quality data is crucial for wider accessibility. Investigating more efficient training methods could reduce computational costs, making it more accessible to resource-constrained researchers. Exploration of different model architectures, perhaps exploring the potential benefits of incorporating other innovative techniques like different attention mechanisms or hybrid approaches, could lead to performance improvements. Finally, rigorous evaluations on a broader set of benchmarks, including those specifically designed for measuring biases or ethical implications, are necessary to ensure the model’s responsible deployment. Addressing ethical considerations throughout the development lifecycle is paramount to mitigate risks associated with large language models. The focus should be on creating transparent, reliable, and beneficial tools for the global research community.
More visual insights#
More on figures

🔼 This figure shows the distribution of the pretraining data across different sources and languages. The data primarily consists of Chinese text (67%), drawn from various sources such as SkyPile (33%), WanJuan (32.3%), and Wikipedia-cn. A smaller portion (21.8%) is English data from sources like WanJuan and Code. A small fraction (1.6%) is Chat Data, and another 11.3% consists of code data from Starcode.
read the caption
Figure 2: Pretraining Data Distribution

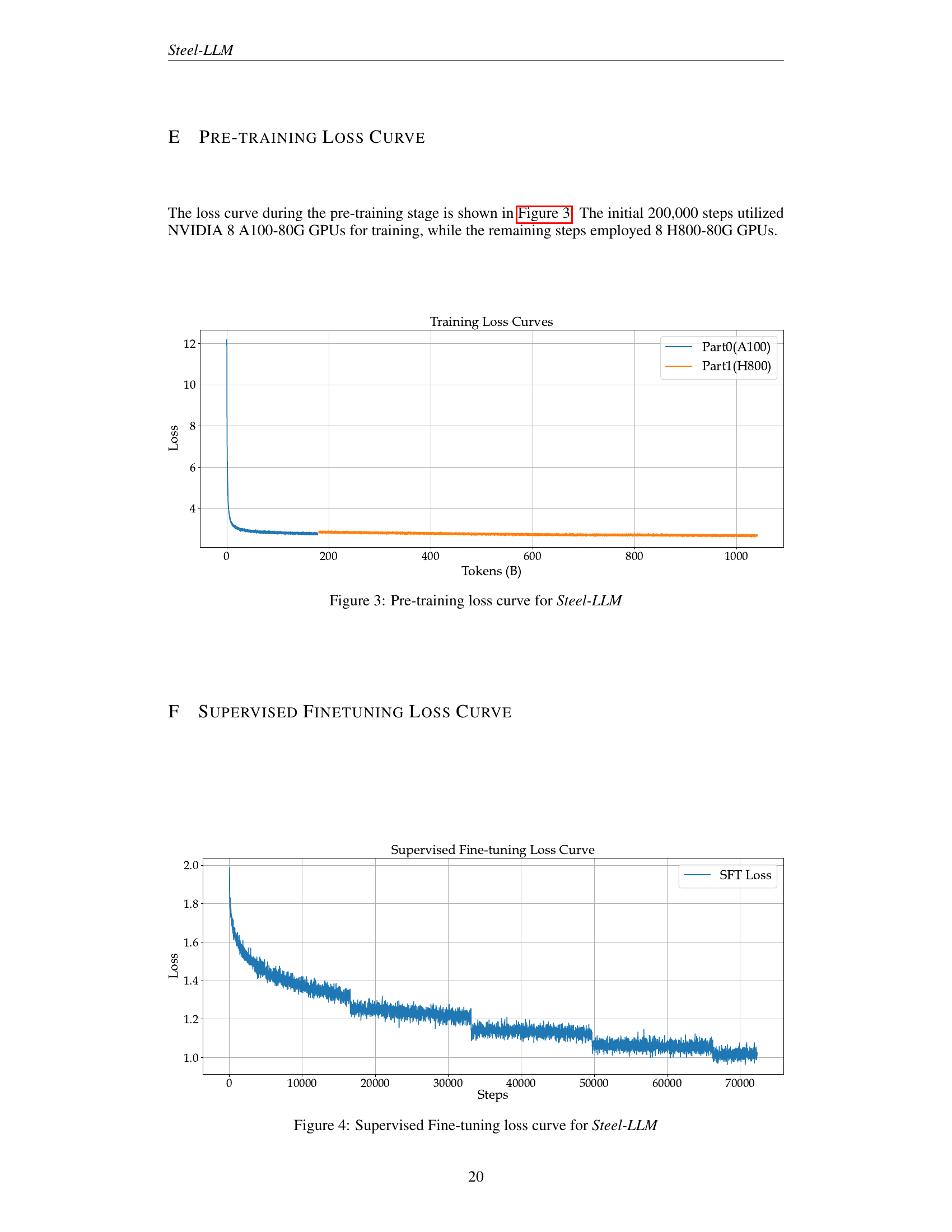
🔼 This figure shows the loss curve during the pre-training phase of the Steel-LLM model. The x-axis represents the number of tokens processed, and the y-axis represents the training loss. The curve displays a steep initial drop in loss, followed by a gradual decrease as training progresses. The figure highlights that the first 200,000 training steps used NVIDIA A100-80G GPUs, while the remaining steps used NVIDIA H800-80G GPUs, potentially explaining any noticeable changes in the curve’s slope. This visualization provides insight into the training process’s stability and efficiency.
read the caption
Figure 3: Pre-training loss curve for Steel-LLM

🔼 This figure shows the training loss curve during the supervised fine-tuning stage of the Steel-LLM model. The x-axis represents the training steps, while the y-axis represents the loss value. The curve illustrates how the model’s performance improved as the training progressed. The consistent downward trend of the loss curve demonstrates the model’s learning and optimization during the fine-tuning phase. It helps visualize the model’s convergence and efficiency of the fine-tuning process.
read the caption
Figure 4: Supervised Fine-tuning loss curve for Steel-LLM

🔼 This figure shows the loss curve during the Direct Preference Optimization (DPO) process for the Steel-LLM model. The x-axis represents the training steps, and the y-axis shows the loss value. The curve illustrates how the loss decreased over the training process, indicating that the model’s performance improved as it learned to align with human preferences. A lower loss indicates a better alignment of the model’s output with preferred responses.
read the caption
Figure 5: Direct Preference Optimization loss curve for Steel-LLM
More on tables
| Exp 1 | Exp 2 | Exp 3 | Exp 4 | Exp 5 | Exp 6 | Exp 7 | Exp 8 | |
| FlashAttention | ||||||||
| SelfAttention(PyTorch) | ||||||||
| RoPE(CUDA) | ||||||||
| RoPE(PyTorch) | ||||||||
| RMSNorm(CUDA) | ||||||||
| RMSNorm(PyTorch) | ||||||||
| Loss Function(Triton) | ||||||||
| Loss Function(PyTorch) | ||||||||
| FSDP | ||||||||
| FSDP(no share param) | ||||||||
| Speed(tokens/s/gpu) | 13400 | 12500 | 10600 | 13800 | 14600 | 13000 | 15000 | 10500 |
| GPU Memory(GB) | 65 | 65 | 69 | 69 | 61 | 75 | 66 | 75 |
🔼 This table compares different training configurations for the Steel-LLM model, showing the impact of various techniques on training speed and GPU memory usage. The configurations involve using different implementations of FlashAttention, ROPE (Rotary Position Embedding), RMSNorm, and the loss function, as well as comparing training with and without FSDP (Fully Sharded Data Parallel). The results are presented in terms of training speed (tokens per second per GPU) and GPU memory consumption (in gigabytes).
read the caption
Table 2: Comparison of different training configurations.
| Experiment | CEVAL Acc. | CMMLU Acc. | MMLU Acc. |
| Full Infinity-Instruct + Wanjuan MCQ | 32.35 | 26.32 | 25.50 |
| 700K Chinese Infinity-Instruct + Wanjuan MCQ | 38.57 | 33.48 | 23.26 |
| Chinese + 100% English Data | 39.21 | 33.20 | 26.73 |
| Chinese + 20% English Data (Balanced) | 40.43 | 35.86 | 26.75 |
| Chinese + 20% English + English MCQ | 41.90 | 36.08 | 30.82 |
🔼 This table presents the results of several experiments evaluating different fine-tuning strategies on the Steel-LLM model. It compares the model’s performance across three benchmark datasets (CEVAL, CMMLU, and MMLU) using various combinations and proportions of Chinese and English data in the fine-tuning process. The variations allow for analysis of the impact of data composition and language balance on the overall effectiveness of the fine-tuning procedure. Each row represents a distinct experiment, showing the accuracy achieved on each benchmark dataset.
read the caption
Table 3: Performance of different fine-tuning strategies.
| Model | CEVAL | CMMLU |
| Tiny-Llama-1.1B (Zhang et al., 2024c) | 25.02 | 24.03 |
| MiniCPM-1.2B (min, 2024) | 49.14 | 46.81 |
| Qwen1.5-1.8B-Chat (Bai et al., 2023b) | 56.84 | 54.11 |
| Phi2(2B)(Abdin et al., 2023) | 23.37 | 24.18 |
| Gemma-2b-it (Gemma Team et al., 2024) | 32.30 | 33.07 |
| CT-LLM-SFT-2B (Du et al., 2024) | 41.54 | 41.48 |
| ChatGLM-6B (GLM et al., 2024) | 38.90 | 37.48 |
| Llama2-7B Touvron et al. (2023b) | 32.42 | 31.11 |
| OLMo-7B (Groeneveld et al., 2024b) | 35.18 | 35.55 |
| Gemma-7B (Gemma Team et al., 2024) | 42.57 | 44.20 |
| MAP-Neo-7B (Zhang et al., 2024a) | 56.97 | 55.01 |
| Llama2-13B Touvron et al. (2023b) | 37.32 | 37.06 |
| Steel-LLM-1B-Chat | 41.90 | 36.08 |
| Steel-LLM-1B-Chat-DPO | 42.04 | 36.04 |
🔼 This table compares the performance of several large language models (LLMs) on two widely used Chinese language evaluation benchmarks: CEVAL and CMMLU. It lists the models, their sizes (where available), and their accuracy scores on both benchmarks, allowing for a direct comparison of model performance and highlighting Steel-LLM’s competitive standing.
read the caption
Table 4: Performance comparison of models on CEVAL and CMMLU benchmarks.
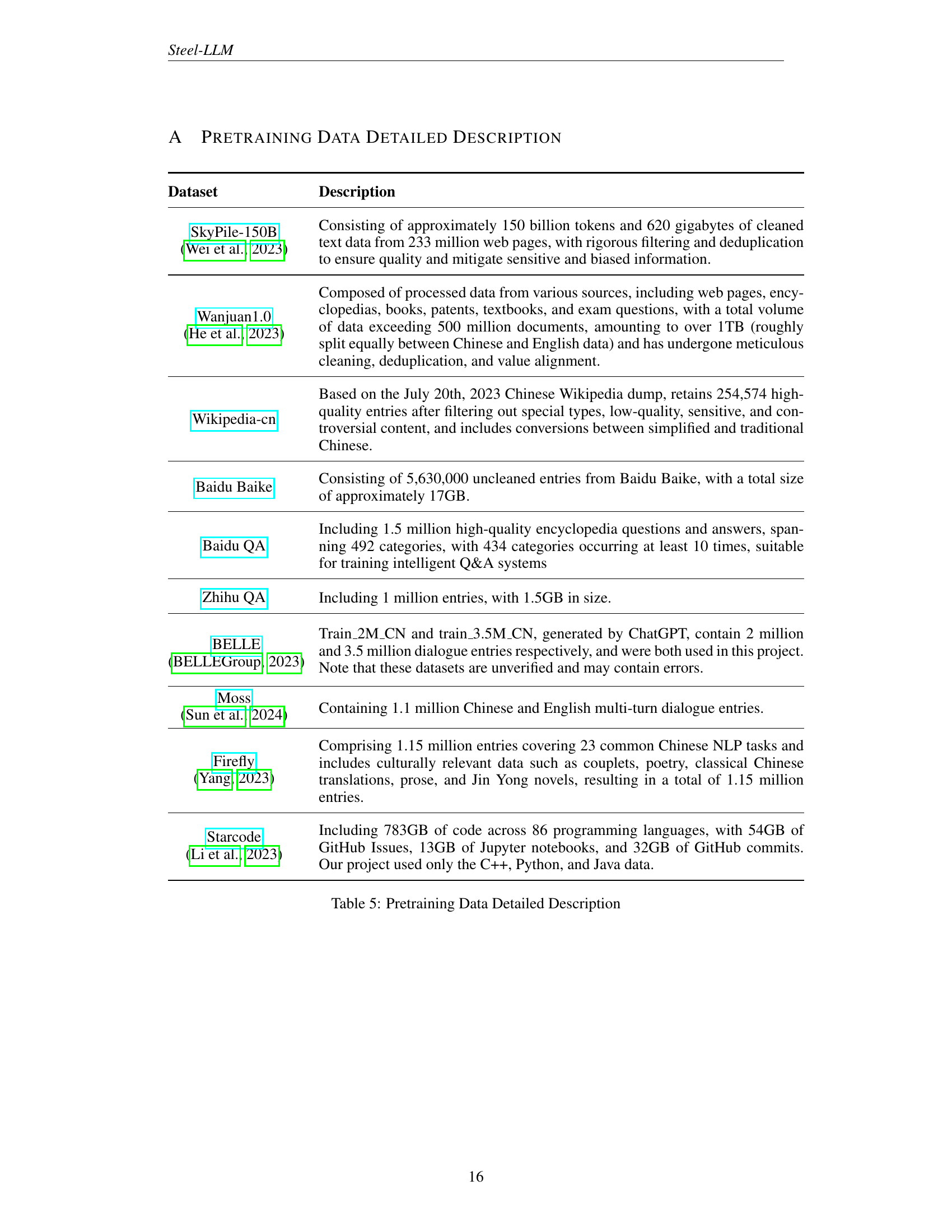
| Dataset | Description |
| SkyPile-150B (Wei et al., 2023) | Consisting of approximately 150 billion tokens and 620 gigabytes of cleaned text data from 233 million web pages, with rigorous filtering and deduplication to ensure quality and mitigate sensitive and biased information. |
| Wanjuan1.0 (He et al., 2023) | Composed of processed data from various sources, including web pages, encyclopedias, books, patents, textbooks, and exam questions, with a total volume of data exceeding 500 million documents, amounting to over 1TB (roughly split equally between Chinese and English data) and has undergone meticulous cleaning, deduplication, and value alignment. |
| Wikipedia-cn | Based on the July 20th, 2023 Chinese Wikipedia dump, retains 254,574 high-quality entries after filtering out special types, low-quality, sensitive, and controversial content, and includes conversions between simplified and traditional Chinese. |
| Baidu Baike | Consisting of 5,630,000 uncleaned entries from Baidu Baike, with a total size of approximately 17GB. |
| Baidu QA | Including 1.5 million high-quality encyclopedia questions and answers, spanning 492 categories, with 434 categories occurring at least 10 times, suitable for training intelligent Q&A systems |
| Zhihu QA | Including 1 million entries, with 1.5GB in size. |
| BELLE (BELLEGroup, 2023) | Train_2M_CN and train_3.5M_CN, generated by ChatGPT, contain 2 million and 3.5 million dialogue entries respectively, and were both used in this project. Note that these datasets are unverified and may contain errors. |
| Moss (Sun et al., 2024) | Containing 1.1 million Chinese and English multi-turn dialogue entries. |
| Firefly (Yang, 2023) | Comprising 1.15 million entries covering 23 common Chinese NLP tasks and includes culturally relevant data such as couplets, poetry, classical Chinese translations, prose, and Jin Yong novels, resulting in a total of 1.15 million entries. |
| Starcode (Li et al., 2023) | Including 783GB of code across 86 programming languages, with 54GB of GitHub Issues, 13GB of Jupyter notebooks, and 32GB of GitHub commits. Our project used only the C++, Python, and Java data. |
🔼 This table details the datasets used for pretraining the Steel-LLM model. It lists each dataset’s name, source, and a description of its contents, including size and the type of data included (e.g., web text, code, encyclopedias). The table provides a comprehensive overview of the diverse data sources contributing to the model’s knowledge base.
read the caption
Table 5: Pretraining Data Detailed Description
| Dataset | Description |
| Infinity-Instruct-7M (BAAI, 2024) | A large-scale, high-quality instruction dataset with only 0.7M of Chinese data used in this project. |
| Wanjuan1.0 (He et al., 2023) | Consistent with the one used during the pre-training stage, but with the Chinese choice question data repurposed for fine-tuning. |
| Ruozhiba (Ruozhiba, 2024) | Questions from Baidu Tieba “Ruozhiba” were answered by GPT-4, then manually reviewed and edited for formatting errors and improved responses. |
| Self-awareness Dataset (Team, 2024a) | Consisting of various “Who are you?” questions from the EmoLLM project templates. |
| Code-Feedback (Zheng et al., 2025) | A code SFT dataset consists of 66,000 entries from various open-source code datasets and LeetCode, after undergoing a series of filtering and selection processes. |
| WebInstructSub (Yue et al., 2024) | Containing 2.33 million SFT entries across fields such as mathematics, physics, biology, chemistry, and computer science. |
| OpenHermes-2.5 (Teknium, 2023) | Consisting of samples synthesized by large models and chat samples, filtered from open-source data like Airoboros, ChatBot Arena, and Evol Instruct, totaling 1 million entries. |
🔼 This table details the datasets used in the supervised fine-tuning stage of the Steel-LLM model’s training. It lists each dataset’s name, a brief description of its contents and source, and the quantity of data used for fine-tuning the model. This information helps readers understand the composition and size of the data used to refine the Steel-LLM model after its initial pre-training phase.
read the caption
Table 6: Supervised Finetuning Data Detailed Description
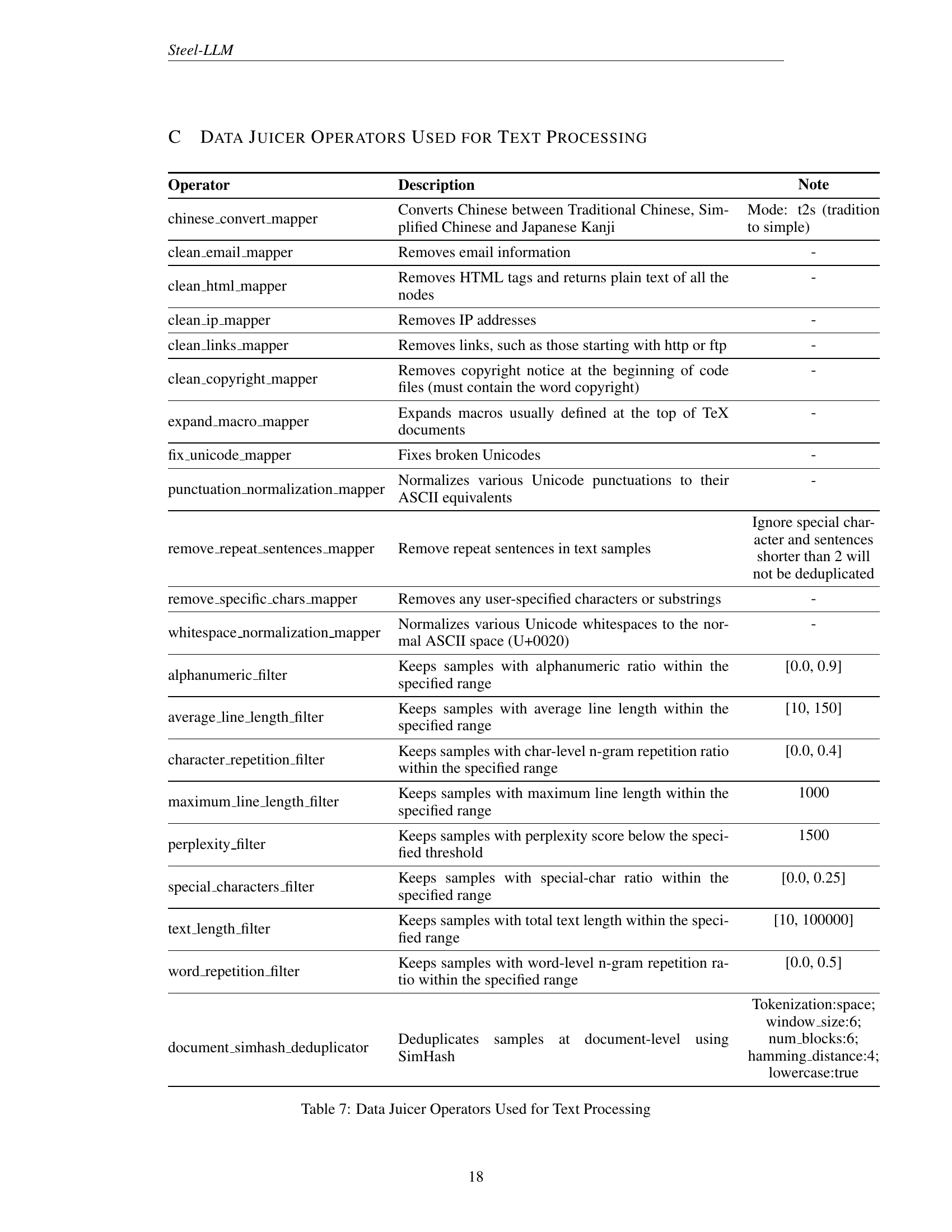
| Operator | Description | Note |
| chinese_convert_mapper | Converts Chinese between Traditional Chinese, Simplified Chinese and Japanese Kanji | Mode: t2s (tradition to simple) |
| clean_email_mapper | Removes email information | - |
| clean_html_mapper | Removes HTML tags and returns plain text of all the nodes | - |
| clean_ip_mapper | Removes IP addresses | - |
| clean_links_mapper | Removes links, such as those starting with http or ftp | - |
| clean_copyright_mapper | Removes copyright notice at the beginning of code files (must contain the word copyright) | - |
| expand_macro_mapper | Expands macros usually defined at the top of TeX documents | - |
| fix_unicode_mapper | Fixes broken Unicodes | - |
| punctuation_normalization_mapper | Normalizes various Unicode punctuations to their ASCII equivalents | - |
| remove_repeat_sentences_mapper | Remove repeat sentences in text samples | Ignore special char- acter and sentences shorter than 2 will not be deduplicated |
| remove_specific_chars_mapper | Removes any user-specified characters or substrings | - |
| whitespace_normalization_mapper | Normalizes various Unicode whitespaces to the normal ASCII space (U+0020) | - |
| alphanumeric_filter | Keeps samples with alphanumeric ratio within the specified range | [0.0, 0.9] |
| average_line_length_filter | Keeps samples with average line length within the specified range | [10, 150] |
| character_repetition_filter | Keeps samples with char-level n-gram repetition ratio within the specified range | [0.0, 0.4] |
| maximum_line_length_filter | Keeps samples with maximum line length within the specified range | 1000 |
| perplexity_filter | Keeps samples with perplexity score below the specified threshold | 1500 |
| special_characters_filter | Keeps samples with special-char ratio within the specified range | [0.0, 0.25] |
| text_length_filter | Keeps samples with total text length within the specified range | [10, 100000] |
| word_repetition_filter | Keeps samples with word-level n-gram repetition ratio within the specified range | [0.0, 0.5] |
| document_simhash_deduplicator | Deduplicates samples at document-level using SimHash | Tokenization:space; window_size:6; num_blocks:6; hamming_distance:4; lowercase:true |
🔼 This table lists the text processing operators used in the Steel-LLM project, which are part of the Data Juicer framework. For each operator, it provides a description of its function and any specific parameters or notes. This detailed information helps in understanding the data preprocessing pipeline used to prepare the massive dataset for training the Steel-LLM model. The table is crucial for reproducibility and allows researchers to understand the specific steps involved in data cleaning and normalization.
read the caption
Table 7: Data Juicer Operators Used for Text Processing
| Operator | Description | Note |
| clean_copyright_mapper | Removes copyright notice at the beginning of code files (must contain the word copyright) | - |
| clean_email_mapper | Removes email information | - |
| clean_links_mapper | Removes links, such as those starting with http or ftp | - |
| fix_unicode_mapper | Fixes broken Unicodes | - |
| punctuation_normalization_mapper | Normalizes various Unicode punctuations to their ASCII equivalents | - |
| alphanumeric_filter | Keeps samples with alphanumeric ratio within the specified range | [0.546, 3.65] |
| average_line_length_filter | Keeps samples with average line length within the specified range | [10, 150] |
| character_repetition_filter | Keeps samples with char-level n-gram repetition ratio within the specified range | 0.36 |
| maximum_line_length_filter | Keeps samples with maximum line length within the specified range | 1000 |
| text_length_filter | Keeps samples with total text length within the specified range | 96714 |
| words_num_filter | Keeps samples with word count within the specified range | [20,6640] |
| word_repetition_filter | Keeps samples with word-level n-gram repetition ratio within the specified range | [10, 0.357] |
| document_simhash_deduplicator | Deduplicates samples at document-level using SimHash | Tokenization:space; window_size:6; num_blocks:6; hamming_distance:4; lowercase:true |
🔼 This table lists the data processing operators used in the Data Juicer framework for cleaning and preparing code data for the Steel-LLM project. For each operator, it specifies the function or transformation applied to the code data (e.g., removing copyright notices, removing email addresses, normalizing punctuation). Some operators include parameters, such as specifying a range for alphanumeric ratios or line lengths. The table also indicates any special notes, such as whether an operator uses SimHash for deduplication.
read the caption
Table 8: Data Juicer Operators Used for Code Processing
Full paper#