TL;DR#
Large Language Models (LLMs) have shown impressive capabilities but struggle with complex reasoning tasks like solving mathematical problems. Existing methods often face challenges with efficiency and generalizability, especially when dealing with complex problems requiring multiple reasoning steps. This necessitates more efficient and generalizable inference scaling approaches for enhanced reasoning performance.
ReasonFlux addresses this challenge by introducing a hierarchical LLM reasoning framework that leverages a structured library of thought templates, hierarchical reinforcement learning to optimize template trajectories, and a novel inference scaling system. This allows ReasonFlux to effectively scale its reasoning capabilities to complex problems. Results demonstrate ReasonFlux’s significant outperformance over state-of-the-art LLMs in mathematical reasoning benchmarks, showcasing its efficiency and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is important because it presents ReasonFlux, a novel approach to improve large language model reasoning capabilities. ReasonFlux’s hierarchical framework and efficient template scaling system offers a significant advancement over existing methods, achieving state-of-the-art results on various mathematical reasoning benchmarks. This work opens new avenues for research in hierarchical reasoning, efficient inference scaling, and the design of structured knowledge bases for LLMs.
Visual Insights#

🔼 The figure illustrates the training process of ReasonFlux, a hierarchical LLM reasoning framework. ReasonFlux uses hierarchical reinforcement learning to learn an optimal sequence of thought templates for solving problems. The process begins with input problems that are analyzed and retrieved from a thought template library. These templates are evaluated and scored to create preference trajectory pairs which are then used in the hierarchical reinforcement learning stage. The result is a model that can plan an optimal and generalizable thought template trajectory for a given problem. A more detailed inference-scaling framework is described in Figure 2 of the paper.
read the caption
Figure 1: Training framework for our ReasonFlux. We train with hierarchical reinforcement learning to enable the model to plan out an optimal and generalizable thought template trajectory for an input problem. Our new inference-scaling framework is in Figure 2.
| Task | ReasonFlux | DeepSeek | OpenAI | OpenAI | QWQ | GPT |
|---|---|---|---|---|---|---|
| 32B | V3 | o1-preview | o1-mini | 32B-preview | 4o | |
| MATH | 91.2 | 90.2 | 85.5 | 90.0 | 90.6 | 76.6 |
| AIME 2024 | 56.7 | 39.2 | 44.6 | 56.7 | 50.0 | 9.3 |
| Olympiad Bench | 63.3 | 55.4 | - | 65.3 | 61.2 | 43.3 |
| GaokaoEn 2023 | 83.6 | - | 71.4 | 78.4 | 65.3 | 67.5 |
| AMC2023 | 85.0 | 80.0 | 90.0 | 95.0 | - | 47.5 |
🔼 This table presents a performance comparison of various LLMs on several mathematical reasoning benchmarks. The benchmarks used are MATH, AIME 2024, an Olympiad benchmark, GaokaoEn 2023, and AMC 2023. For each model and benchmark, the table shows the Pass@1 accuracy, which represents the percentage of problems solved correctly in the first attempt. The LLMs compared are ReasonFlux-32B, DeepSeek V3, OpenAI’s 01-preview and 01-mini models, and GPT-40. The table highlights ReasonFlux-32B’s superior performance on these benchmarks compared to other LLMs.
read the caption
Table 1: Performance Comparison on Various Math Reasoning Benchmarks (Pass@1 Accuracy)
In-depth insights#
Hierarchical Reasoning#
Hierarchical reasoning, a crucial aspect of advanced cognitive functions, involves breaking down complex problems into a hierarchy of subproblems. This approach allows for a more manageable and efficient solution process. Each subproblem can be addressed using simpler reasoning methods, potentially leading to a solution for the larger problem. The concept of hierarchical reasoning is particularly relevant in the context of LLMs, as it directly addresses the challenge of handling complex tasks that demand multi-step reasoning. ReasonFlux leverages hierarchical reasoning by employing a library of high-level thought templates. These templates guide the LLM’s reasoning process in a structured manner, moving gradually from high-level to more specific reasoning steps. This approach significantly reduces the search space and enhances efficiency compared to traditional flat reasoning approaches. The hierarchical structure allows for adaptive scaling during inference. The LLM dynamically selects the most appropriate template for each subproblem, optimizing resource allocation and enhancing accuracy. This adaptive scaling is key to efficiently solving complex problems. The success of hierarchical reasoning is highly reliant on a well-structured knowledge base that supports efficient retrieval and application of relevant thought templates, as exemplified by the ReasonFlux’s structured thought template library.
Scaling Thought Templates#
Scaling thought templates in large language models (LLMs) presents a powerful mechanism for enhancing reasoning capabilities. The core idea revolves around creating a structured library of reusable thought templates, each designed to address specific reasoning sub-tasks. These templates are not merely prompts, but rather compact, structured representations of reasoning strategies, encompassing descriptions, tags, and example applications. The scaling aspect manifests in two key ways: firstly, the adaptive selection of relevant templates based on the problem’s characteristics, creating an optimal sequence of reasoning steps; and secondly, the hierarchical application of templates, breaking down complex problems into simpler sub-problems solved by different templates, enabling the LLM to tackle complex reasoning tasks efficiently. This hierarchical approach, combined with structured retrieval, aims to significantly improve both the efficiency and accuracy of LLM reasoning, surpassing simpler, linear approaches. Reinforcement learning plays a crucial role in training the LLM to effectively select and sequence these templates, creating generalizable strategies for problem-solving.
RL-based Optimization#
Reinforcement learning (RL) offers a powerful paradigm for optimizing complex systems, and its application to language model (LM) training is rapidly gaining traction. RL-based optimization methods aim to improve LMs by training them to maximize a reward signal, which can represent various desirable properties like accuracy, fluency, or adherence to user instructions. These methods often leverage techniques like Proximal Policy Optimization (PPO) to efficiently update LM parameters, learning optimal policies through interactions with an environment. A key challenge in RL-based optimization is defining appropriate reward functions that accurately capture the desired behavior, as poorly designed rewards can lead to unintended or suboptimal outcomes. Human feedback, either directly or through preference learning, is often incorporated to guide the reward shaping process. The computational cost of RL-based training is another significant consideration, often requiring substantial computational resources. However, recent advancements in model architectures and training techniques are continuously improving the scalability and efficiency of RL-based optimization for LLMs, enabling the development of increasingly sophisticated and capable language models. Further research is needed to explore innovative reward designs, develop more efficient algorithms, and address the limitations of current approaches, ultimately paving the way for more robust, aligned, and effective LLMs.
Inference Scaling System#
An effective inference scaling system is crucial for handling complex reasoning tasks in large language models (LLMs). ReasonFlux’s approach is noteworthy for its hierarchical structure, employing a sequence of high-level thought templates rather than relying on lengthy chain-of-thought sequences. This hierarchical approach significantly reduces the search space, making the process more efficient. The system’s adaptive scaling of templates based on problem complexity is a key innovation; it dynamically selects the appropriate level of detail in the reasoning process, achieving a balance between exploration and exploitation. This intelligent scaling is facilitated by a structured template library, enabling efficient retrieval of relevant templates at each step. Overall, this system demonstrates a more robust and efficient approach to scaling inference, addressing the computational costs and generalization limitations often associated with traditional methods. The dynamic selection of templates represents a significant step towards more adaptable and effective complex reasoning in LLMs.
Generalization & Limits#
A section titled ‘Generalization & Limits’ in a research paper would explore the extent to which a model’s capabilities extend beyond its training data and the boundaries of its performance. Generalization would assess how well the model performs on unseen data, ideally demonstrating robustness and adaptability to new, similar problems. This includes evaluating performance across different datasets and problem types. Limits would identify the model’s shortcomings and areas where it struggles, perhaps encountering specific types of problems or data it cannot handle effectively. Discussion of limits might involve analysis of error types, edge cases where the model fails, or scenarios where its performance degrades significantly. The interplay between generalization and limits is crucial; a model exhibiting strong generalization will likely reveal specific types of data that push its boundaries, highlighting opportunities for future improvements. The section should offer insights into the model’s real-world applicability, acknowledging its strengths and limitations to inform responsible deployment and further research.
More visual insights#
More on figures

🔼 ReasonFlux’s inference process begins by retrieving a series of high-level thought templates from its template library. These templates are selected based on the complexity of the input problem. The system then uses these templates to guide a step-by-step reasoning process, breaking down the complex problem into a sequence of simpler sub-problems. Each sub-problem is solved using an instantiated version of the appropriate template, and the results are fed back into the system. This iterative refinement process continues until the complete solution is obtained. The figure illustrates this hierarchical approach, showcasing the interplay between high-level template selection and instantiated reasoning at each step.
read the caption
Figure 2: New inference scaling system based on hierarchical reasoning. We retrieve a series of high-level thought templates for complex problems, and gradually conduct instantiated reasoning for a sequence of sub-problems.

🔼 This figure compares the reasoning process of OpenAI’s 01-mini model and the ReasonFlux model on a sample mathematical problem. It illustrates the step-by-step approach taken by each model to arrive at the solution. 01-mini’s process is shown as a sequence of attempts, some leading to dead ends, highlighting its less directed approach. In contrast, ReasonFlux demonstrates a more efficient and organized approach, utilizing a hierarchical reasoning strategy guided by its structured template library to reach the solution effectively and precisely. The visualization of the reasoning paths reveals the significant difference in efficiency and effectiveness between the two models.
read the caption
Figure 3: Comprasion between o1-mini and ReasonFlux.

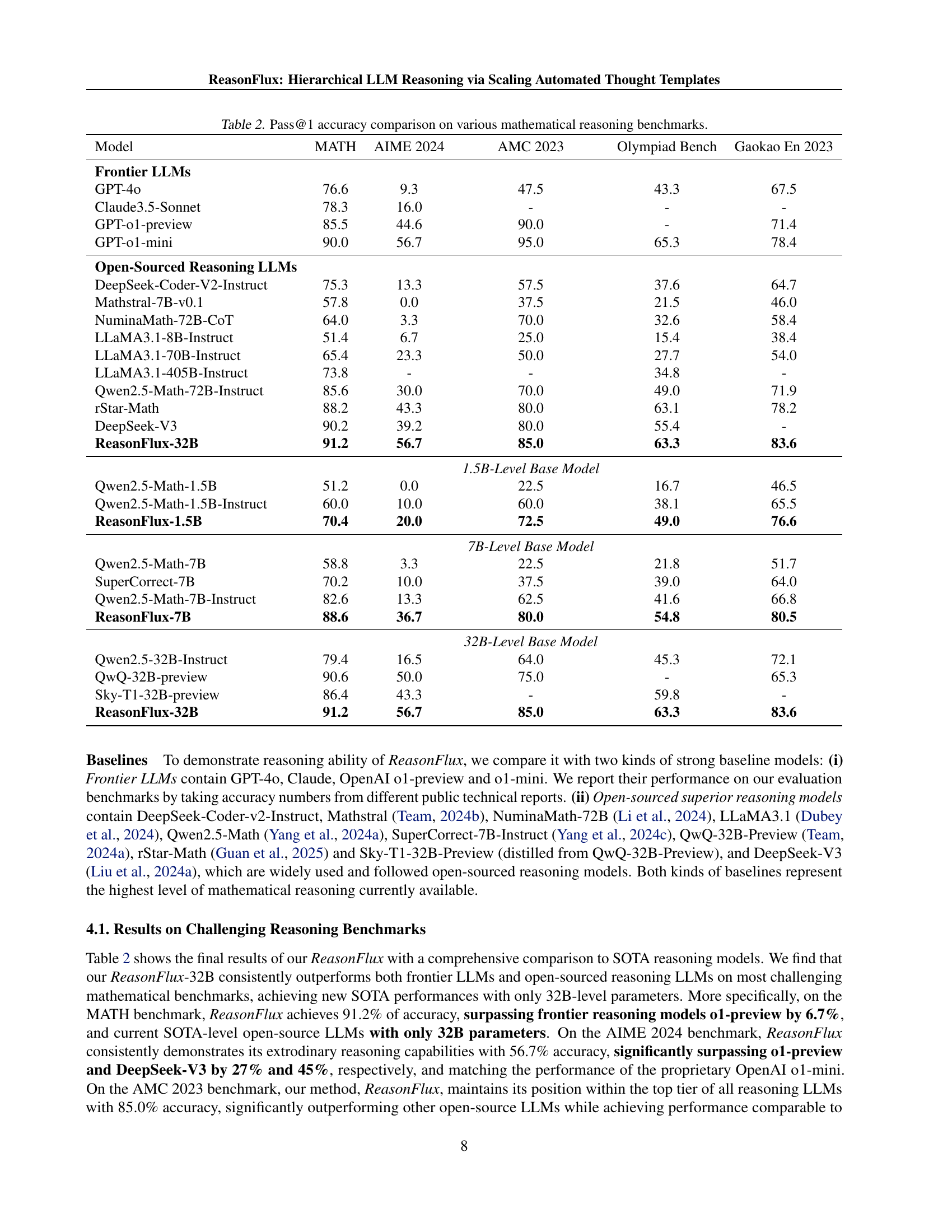
🔼 Figure 4 illustrates the inference scaling laws observed in the ReasonFlux model. Specifically, it shows how the number of interplay rounds (planning and instantiation steps) and the number of retrieved templates scale in response to increasing problem complexity. Panel (a) demonstrates the relationship between interplay rounds and problem complexity, while panel (b) shows the relationship between retrieved templates and problem complexity. The plots visually represent how the model adapts its reasoning process (number of steps and amount of knowledge used) based on the difficulty of the task.
read the caption
Figure 4: Inference scaling laws for template-augmented reasoning in ReasonFlux. (a) Scaling interplay rounds between planning and instantiation with increased level of problem complexity. (b) Scaling retrieved templates with increased level of problem complexity.

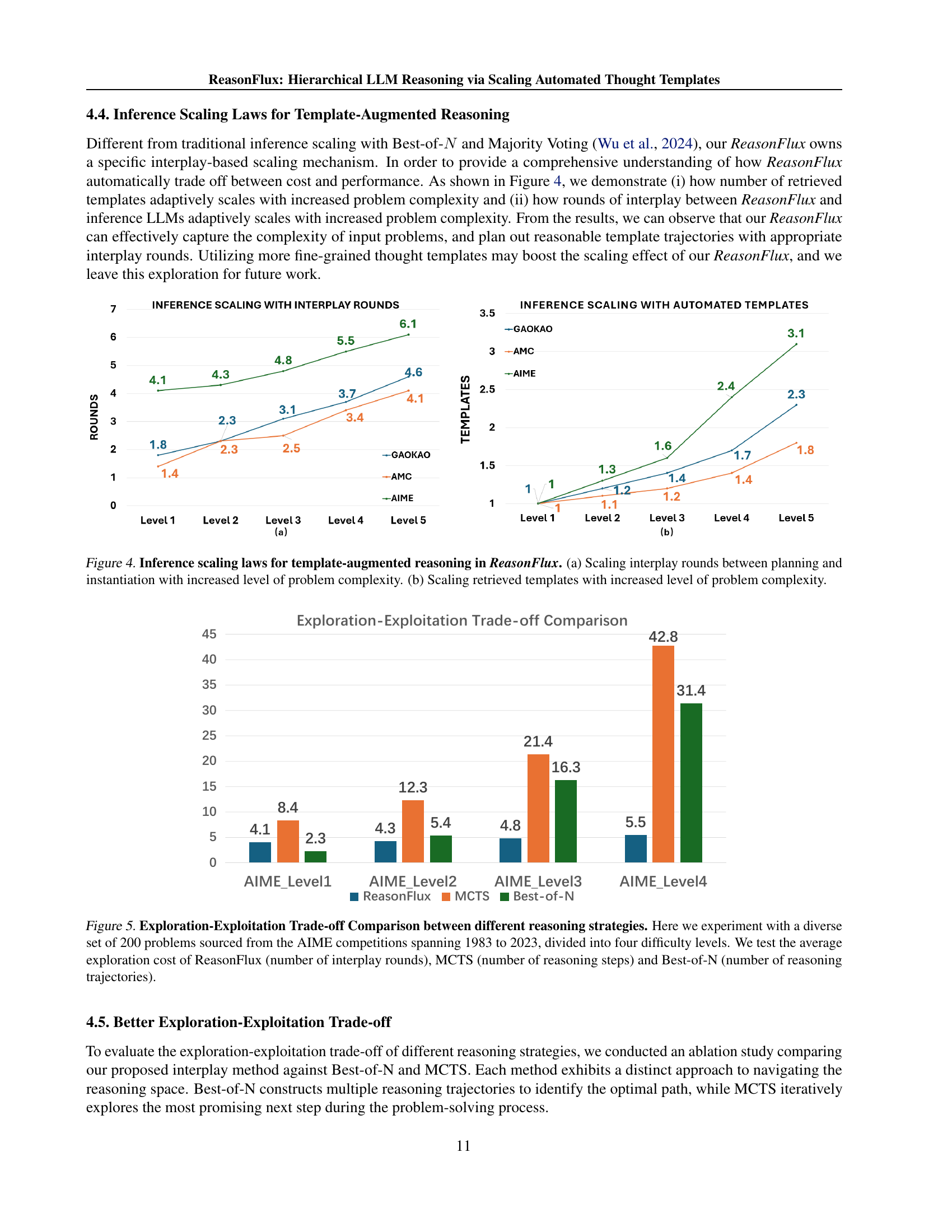
🔼 Figure 5 illustrates the exploration-exploitation trade-off comparison of three different reasoning strategies: ReasonFlux, Monte Carlo Tree Search (MCTS), and Best-of-N. Using 200 problems from the AIME competitions (1983-2023) divided into four difficulty levels, the figure compares the average computational cost (exploration cost) each strategy requires to solve the problems. For ReasonFlux, the exploration cost represents the number of interplay rounds between the planning and instantiation phases. For MCTS, it’s the number of reasoning steps. Finally, for Best-of-N, it’s the number of reasoning trajectories explored. The figure visually demonstrates how the cost changes across the four difficulty levels for each strategy, allowing for a direct comparison of their efficiency and effectiveness in solving increasingly complex mathematical problems.
read the caption
Figure 5: Exploration-Exploitation Trade-off Comparison between different reasoning strategies. Here we experiment with a diverse set of 200 problems sourced from the AIME competitions spanning 1983 to 2023, divided into four difficulty levels. We test the average exploration cost of ReasonFlux (number of interplay rounds), MCTS (number of reasoning steps) and Best-of-N (number of reasoning trajectories).
More on tables
| Model | MATH | AIME 2024 | AMC 2023 | Olympiad Bench | Gaokao En 2023 |
|---|---|---|---|---|---|
| Frontier LLMs | |||||
| GPT-4o | 76.6 | 9.3 | 47.5 | 43.3 | 67.5 |
| Claude3.5-Sonnet | 78.3 | 16.0 | - | - | - |
| GPT-o1-preview | 85.5 | 44.6 | 90.0 | - | 71.4 |
| GPT-o1-mini | 90.0 | 56.7 | 95.0 | 65.3 | 78.4 |
| Open-Sourced Reasoning LLMs | |||||
| DeepSeek-Coder-V2-Instruct | 75.3 | 13.3 | 57.5 | 37.6 | 64.7 |
| Mathstral-7B-v0.1 | 57.8 | 0.0 | 37.5 | 21.5 | 46.0 |
| NuminaMath-72B-CoT | 64.0 | 3.3 | 70.0 | 32.6 | 58.4 |
| LLaMA3.1-8B-Instruct | 51.4 | 6.7 | 25.0 | 15.4 | 38.4 |
| LLaMA3.1-70B-Instruct | 65.4 | 23.3 | 50.0 | 27.7 | 54.0 |
| LLaMA3.1-405B-Instruct | 73.8 | - | - | 34.8 | - |
| Qwen2.5-Math-72B-Instruct | 85.6 | 30.0 | 70.0 | 49.0 | 71.9 |
| rStar-Math | 88.2 | 43.3 | 80.0 | 63.1 | 78.2 |
| DeepSeek-V3 | 90.2 | 39.2 | 80.0 | 55.4 | - |
| ReasonFlux-32B | 91.2 | 56.7 | 85.0 | 63.3 | 83.6 |
| 1.5B-Level Base Model | |||||
| Qwen2.5-Math-1.5B | 51.2 | 0.0 | 22.5 | 16.7 | 46.5 |
| Qwen2.5-Math-1.5B-Instruct | 60.0 | 10.0 | 60.0 | 38.1 | 65.5 |
| ReasonFlux-1.5B | 70.4 | 20.0 | 72.5 | 49.0 | 76.6 |
| 7B-Level Base Model | |||||
| Qwen2.5-Math-7B | 58.8 | 3.3 | 22.5 | 21.8 | 51.7 |
| SuperCorrect-7B | 70.2 | 10.0 | 37.5 | 39.0 | 64.0 |
| Qwen2.5-Math-7B-Instruct | 82.6 | 13.3 | 62.5 | 41.6 | 66.8 |
| ReasonFlux-7B | 88.6 | 36.7 | 80.0 | 54.8 | 80.5 |
| 32B-Level Base Model | |||||
| Qwen2.5-32B-Instruct | 79.4 | 16.5 | 64.0 | 45.3 | 72.1 |
| QwQ-32B-preview | 90.6 | 50.0 | 75.0 | - | 65.3 |
| Sky-T1-32B-preview | 86.4 | 43.3 | - | 59.8 | - |
| ReasonFlux-32B | 91.2 | 56.7 | 85.0 | 63.3 | 83.6 |
🔼 This table presents a comprehensive comparison of the ReasonFlux model’s performance against other state-of-the-art (SOTA) Large Language Models (LLMs) across five challenging mathematical reasoning benchmarks: MATH, AIME 2024, AMC 2023, OlympiadBench, and GaokaoEn 2023. It shows the Pass@1 accuracy (the percentage of problems correctly solved in one attempt) for each model on each benchmark, highlighting the superior performance of ReasonFlux, particularly its 32B parameter version, which surpasses other LLMs by a significant margin on multiple benchmarks. The table also includes results for smaller versions of ReasonFlux and other base LLMs to illustrate the impact of model size and the effectiveness of the ReasonFlux architecture.
read the caption
Table 2: Pass@1 accuracy comparison on various mathematical reasoning benchmarks.
| Model | direct reasoning (%) | with Template (%) |
|---|---|---|
| Llama-3.1-8B-Instruct | 47.6 | 75.1 (+27.5) |
| Qwen2.5-7B-Instruct | 59.2 | 82.7 (+23.5) |
| Qwen2.5-Math-7B-Instruct | 66.5 | 88.4 (+21.9) |
| Llama-3.1-70B-Instruct | 67.4 | 91.2 (+23.8) |
| Qwen2.5-32B-Instruct | 69.2 | 94.3 (+25.1) |
| Qwen2.5-Math-32B-Instruct | 71.1 | 95.9 (+24.8) |
🔼 This table presents the results of an experiment designed to evaluate the generalization capability of the structured thought template library developed in the ReasonFlux model. It shows how different Large Language Models (LLMs), acting as base models, perform on a set of similar mathematical problems when guided by the ReasonFlux thought templates compared to when solving the problems without the templates. This demonstrates the effectiveness of the templates in improving reasoning accuracy across various LLMs and problem variations.
read the caption
Table 3: Generalization ability of our thought templates with different base LLMs on a series of similar mathematical problems.
Full paper#