TL;DR#
Mathematical reasoning in large language models (LLMs) is a challenging problem. Existing methods often rely on complex techniques and abundant data, hindering the development of efficient and robust reasoning models. The sparse nature of binary feedback in mathematical problems poses a significant challenge for reinforcement learning (RL) approaches. Prior research has used different approaches such as distillation, however, those methods have limitations in scalability and fundamental reasoning capability. This paper introduces OREAL, a new RL framework designed to overcome these limitations.
OREAL uses a theoretically sound approach, leveraging the properties of best-of-N sampling to learn from positive examples and incorporating reward shaping to handle negative samples effectively. A token-level reward model further enhances learning by focusing on important steps in the reasoning process. Experiments show OREAL achieves state-of-the-art results on various mathematical reasoning benchmarks, surpassing previous models in terms of accuracy and efficiency. The findings demonstrate the potential of OREAL to push the boundaries of mathematical reasoning capabilities in LLMs and its applicability to other similar tasks involving sparse rewards.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI and machine learning, particularly those working on large language models and reinforcement learning. It pushes the boundaries of mathematical reasoning capabilities in LLMs by introducing a novel RL framework that effectively leverages sparse binary feedback. This work also provides valuable theoretical insights into reward-based RL for reasoning tasks and demonstrates state-of-the-art results on various benchmark datasets. The findings and techniques presented open exciting new avenues for research in more complex reasoning problems and for creating more robust and powerful AI systems.
Visual Insights#

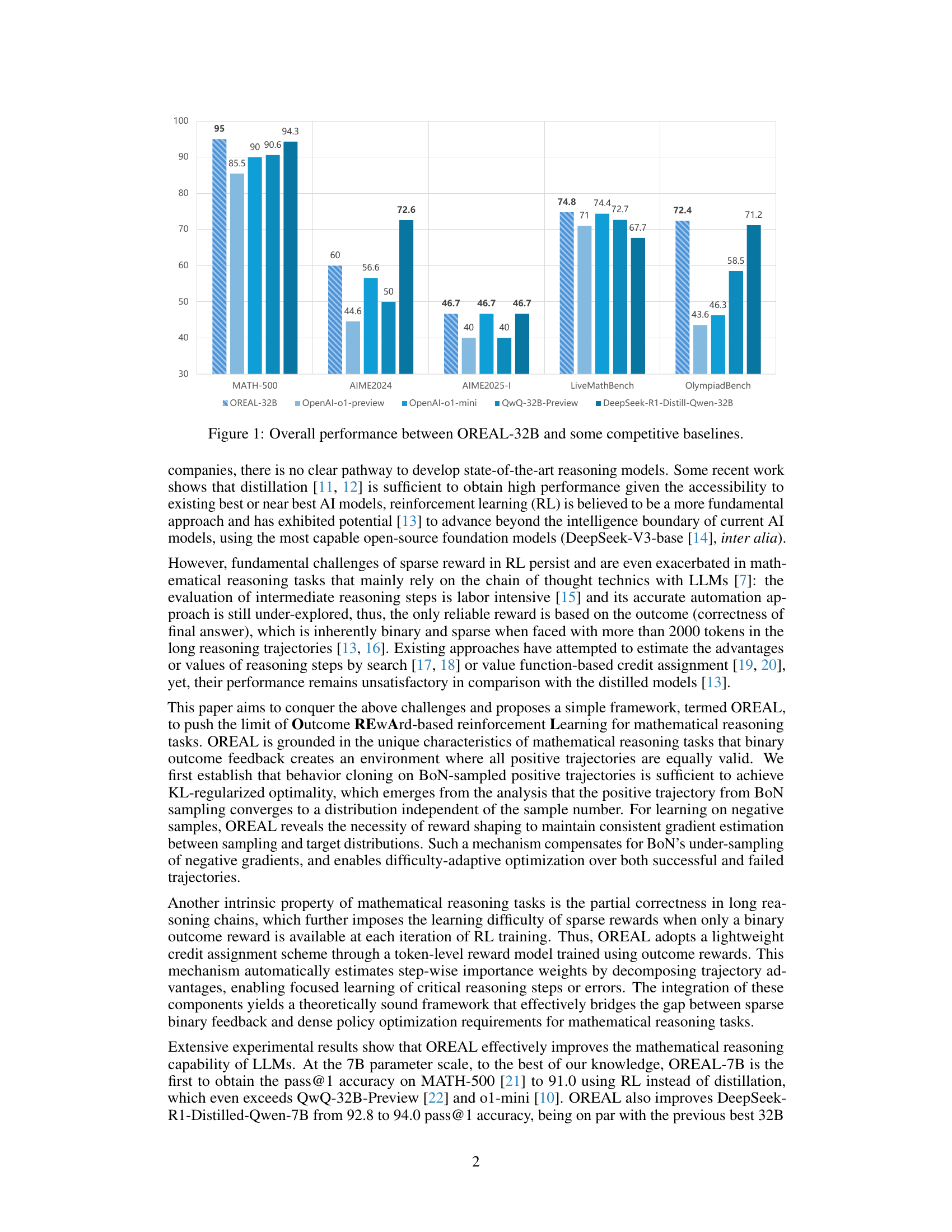
🔼 This bar chart compares the performance of the OREAL-32B model against several other state-of-the-art large language models on the MATH-500 benchmark dataset. The chart displays the pass@1 accuracy (the percentage of times the model correctly answered the question on the first try) for each model. Models are compared across multiple benchmarks including MATH-500, AIME2024, AIME2025-1, LiveMathBench, and OlympiadBench, showcasing performance across different question difficulty levels and mathematical topics. The figure highlights that OREAL-32B significantly outperforms many existing models, achieving the best performance overall.
read the caption
Figure 1: Overall performance between OREAL-32B and some competitive baselines.
| Model | MATH-500 | AIME2024 | AIME2025-I | LiveMath | Olympiad |
| API Models | |||||
| GPT-4o-1120 [42] | 72.8 | 16.7 | 13.3 | 44.8 | 33.7 |
| Claude-3.5-Sonnet-1022 [43] | 78.3 | 13.3 | 3.3 | 46.7 | 35.4 |
| OpenAI-o1-preview [10] | 85.5 | 44.6 | 40.0 | 71.0 | 43.6 |
| OpenAI-o1-mini [10] | 90.0 | 56.6 | 46.7 | 74.4 | 46.3 |
| 7B Models | |||||
| Qwen2.5-Instrust-7B [39] | 76.6 | 13.3 | 0.0 | 37.0 | 29.1 |
| Qwen2.5-Math-Instrust-7B [39] | 81.8 | 20.0 | 13.3 | 44.1 | 31.1 |
| rStar-Math-7B [45] | 78.4* | 26.7* | - | - | 47.1* |
| Qwen2.5-7B-SimpleRL [44] | 82.4* | 26.7* | - | - | 37.6* |
| Eurus-2-7B-PRIME [20] | 79.2* | 26.7* | - | - | 42.1* |
| DeepSeek-R1-Distill-Qwen-7B [13] | 92.8* | 55.5* | 40.0 | 65.6 | 64.1 |
| OREAL-7B | 91.0 | 33.3 | 33.3 | 62.6 | 59.9 |
| OREAL-DSR1-Distill-Qwen-7B | 94.0 | 50.0 | 40.0 | 65.6 | 66.1 |
| 32B Models | |||||
| Qwen2.5-Instrust-32B [39] | 80.6 | 20.0 | 13.3 | 50.8 | 40.4 |
| QwQ-32B-Preview [22] | 90.6 | 50.0 | 40.0 | 72.7 | 58.5 |
| DeepSeek-R1-Distill-Qwen-32B [13] | 94.3* | 72.6* | 46.7 | 67.7 | 71.2 |
| OREAL-32B | 95.0 | 60.0 | 46.7 | 74.8 | 72.4 |
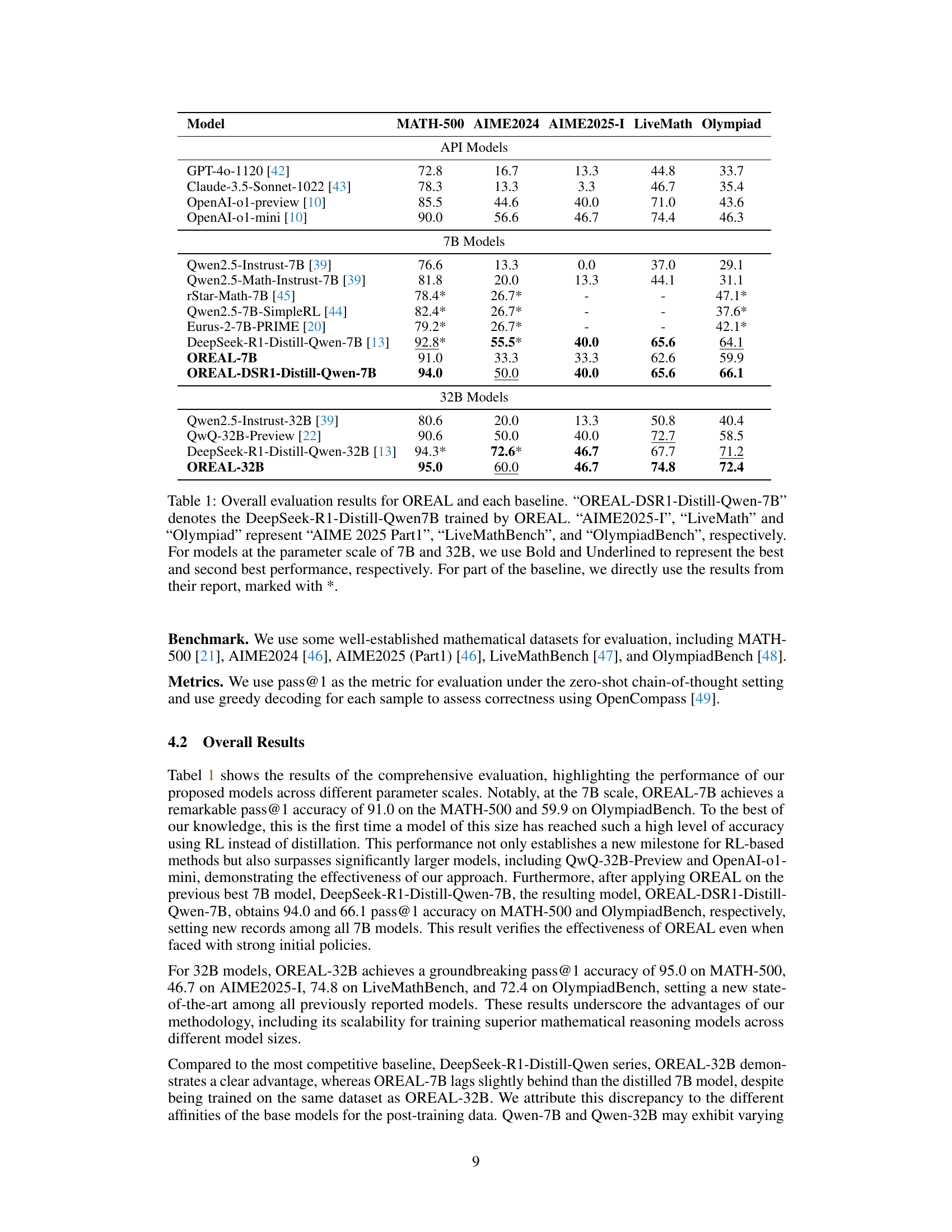
🔼 This table presents a comprehensive comparison of the performance of the OREAL model against various baselines across multiple benchmark datasets. It shows pass@1 accuracy for MATH-500, AIME2024, AIME2025 Part 1, LiveMathBench, and OlympiadBench. The table highlights OREAL’s performance at both 7B and 32B parameter scales, indicating improvements over existing models. It also includes a row for a model where DeepSeek-R1-Distill-Qwen-7B was further trained using the OREAL framework. Note that some baseline results are directly taken from published reports, marked with an asterisk (*). The best and second-best performing models at the 7B and 32B scales are highlighted in bold and underlined.
read the caption
Table 1: Overall evaluation results for OREAL and each baseline. “OREAL-DSR1-Distill-Qwen-7B” denotes the DeepSeek-R1-Distill-Qwen7B trained by OREAL. “AIME2025-I”, “LiveMath” and “Olympiad” represent “AIME 2025 Part1”, “LiveMathBench”, and “OlympiadBench”, respectively. For models at the parameter scale of 7B and 32B, we use Bold and Underlined to represent the best and second best performance, respectively. For part of the baseline, we directly use the results from their report, marked with *.
In-depth insights#
OREAL Framework#
The OREAL framework represents a novel reinforcement learning approach designed to push the boundaries of mathematical reasoning in large language models (LLMs). Its core innovation lies in addressing the inherent sparsity of outcome-based rewards in such tasks. By leveraging best-of-N sampling for positive examples and theoretically-grounded reward shaping for negative ones, OREAL ensures effective policy gradient estimation, even with limited feedback. The integration of a token-level reward model further enhances learning by providing granular credit assignment, mitigating the difficulties posed by long reasoning chains and partial correctness. This framework’s theoretical rigor, coupled with its empirical success in achieving state-of-the-art results on benchmark datasets, highlights its potential for significantly advancing the capabilities of LLMs in mathematical problem-solving. Importantly, OREAL demonstrates that even relatively smaller models can achieve top performance using its approach, a significant departure from previous reliance on massive-scale, distilled models.
BoN Sampling#
Best-of-N (BoN) sampling is a crucial technique in reinforcement learning, particularly effective when dealing with sparse reward environments. BoN’s core idea is to run multiple trials of a policy, selecting the single best outcome from these trials. This approach addresses the challenge of sparse rewards by focusing on successful trajectories, thereby improving data efficiency. The paper highlights that behavior cloning using BoN-sampled positive trajectories is sufficient for learning a near-optimal policy in such environments, offering a theoretically grounded justification for its effectiveness. However, the inherent bias of BoN sampling, favoring successful trajectories and under-representing failures, is addressed through reward reshaping techniques, ensuring gradient consistency and optimizing the learning process across all trajectories. This sophisticated approach allows for effective learning even with limited positive examples. The authors emphasize that BoN sampling, while advantageous, needs careful consideration to counteract the imbalance in positive and negative sample distributions; this is crucial for effective RL in complex reasoning tasks.
Reward Shaping#
Reward shaping in reinforcement learning (RL), particularly within the context of mathematical reasoning, addresses the challenge of sparse rewards. In mathematical problems, the feedback is typically binary (correct/incorrect), making it difficult for an RL agent to learn effectively from its mistakes. Reward shaping modifies the raw reward signal to guide the agent’s learning process by providing more informative feedback during training. This can involve assigning partial credit for intermediate steps or progress towards a solution, thereby alleviating the sparsity issue and accelerating learning. Theoretical analysis can provide insights on how to optimally design reward shaping functions to ensure convergence to a good policy. Effective reward shaping strategies in mathematical reasoning often require careful consideration of the problem structure and partial correctness of reasoning steps, and techniques like token-level rewards provide a promising avenue.
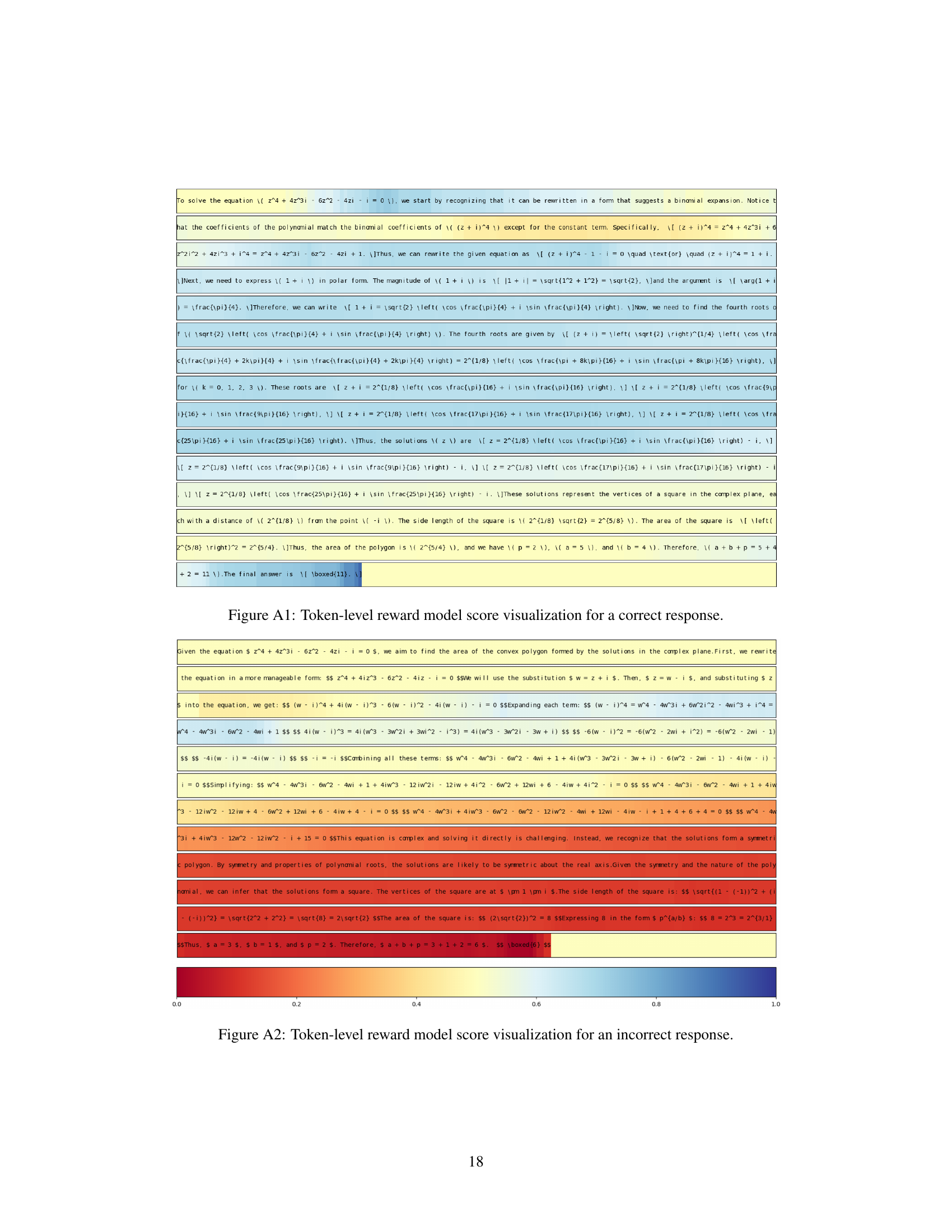
Token Rewards#
The concept of ‘Token Rewards’ in the context of reinforcement learning for mathematical reasoning is crucial for addressing the sparsity of traditional outcome-based rewards. By assigning rewards at the token level, the model receives more frequent feedback, guiding the learning process towards better intermediate steps and not just the final answer. This approach is particularly beneficial for tasks involving long reasoning chains where partial correctness is common. Effective token reward design requires careful consideration of token importance and how to balance exploration and exploitation to maximize learning efficiency. A well-designed token reward system can significantly improve the model’s ability to generate correct reasoning steps and ultimately achieve higher accuracy on complex mathematical problems. The method allows for finer-grained control over the learning process, leading to more robust and generalizable solutions compared to only using final outcome rewards.
Future of OREAL#
The future of OREAL hinges on addressing its limitations and exploring its potential. Extending OREAL to more complex mathematical domains beyond MATH-500, AIME, and Olympiad problems is crucial. This involves tackling problems requiring diverse reasoning skills and potentially incorporating external knowledge sources. Improving the efficiency of the RL training process is vital. The current method’s computational cost is significant; hence, research into more efficient RL algorithms or approximations could greatly improve scalability. Investigating alternative reward mechanisms beyond binary outcome rewards is also essential. Developing methods for assigning credit to intermediate steps in reasoning trajectories would enable finer-grained learning and potentially enhance performance. Finally, thorough analysis of the impact of initial policy models is needed. The success of OREAL is partly dependent on the strength of the pre-trained language model; hence, researching ways to optimally select and enhance the initial policy will be key to future advancements.
More visual insights#
More on tables
| Setting | MATH-500 |
| Initial Policy | 84.8 |
| + REINFORCE (baseline) | 85.8 |
| + Reward Shaping | 86.6 |
| + Behavior Cloning | 87.6 |
| + Importance Sampling | 89.0 |
| + Skill-based Enhancement | 91.0 |
🔼 This table presents an ablation study evaluating the impact of various reinforcement learning (RL) components on the performance of a 7B parameter language model on the MATH-500 benchmark. It shows the pass@1 accuracy achieved by incrementally adding different RL techniques: Reward Shaping, Behavior Cloning, and Importance Sampling. The baseline uses REINFORCE. The results demonstrate the contribution of each component towards improving the model’s mathematical reasoning abilities.
read the caption
Table 2: Ablation study for 7B models performance on MATH-500 with different reinforcement learning settings.
| Model | MATH-500 | AIME2024 | AIME2025-I | LiveMath | Olympiad |
| OREAL-7B-SFT-wo-enhance | 84.8 | 26.7 | 26.7 | 55.0 | 55.1 |
| OREAL-7B-wo-enhance | 89.0 | 36.7 | 40.0 | 60.1 | 58.1 |
| OREAL-7B-SFT | 86.4 | 26.7 | 26.7 | 54.2 | 56.0 |
| OREAL-7B | 91.0 | 33.3 | 33.3 | 62.6 | 59.9 |
| DeepSeek-R1-Distill-Qwen-7B [13] | 92.8* | 55.5* | 40.0 | 65.6 | 64.1 |
| OREAL-DSR1-Distill-Qwen-7B | 94.0 | 50.0 | 40.0 | 65.6 | 66.1 |
| OREAL-32B-SFT | 92.6 | 43.3 | 46.7 | 71.9 | 68.7 |
| OREAL-32B | 95.0 | 60.0 | 46.7 | 74.8 | 72.4 |
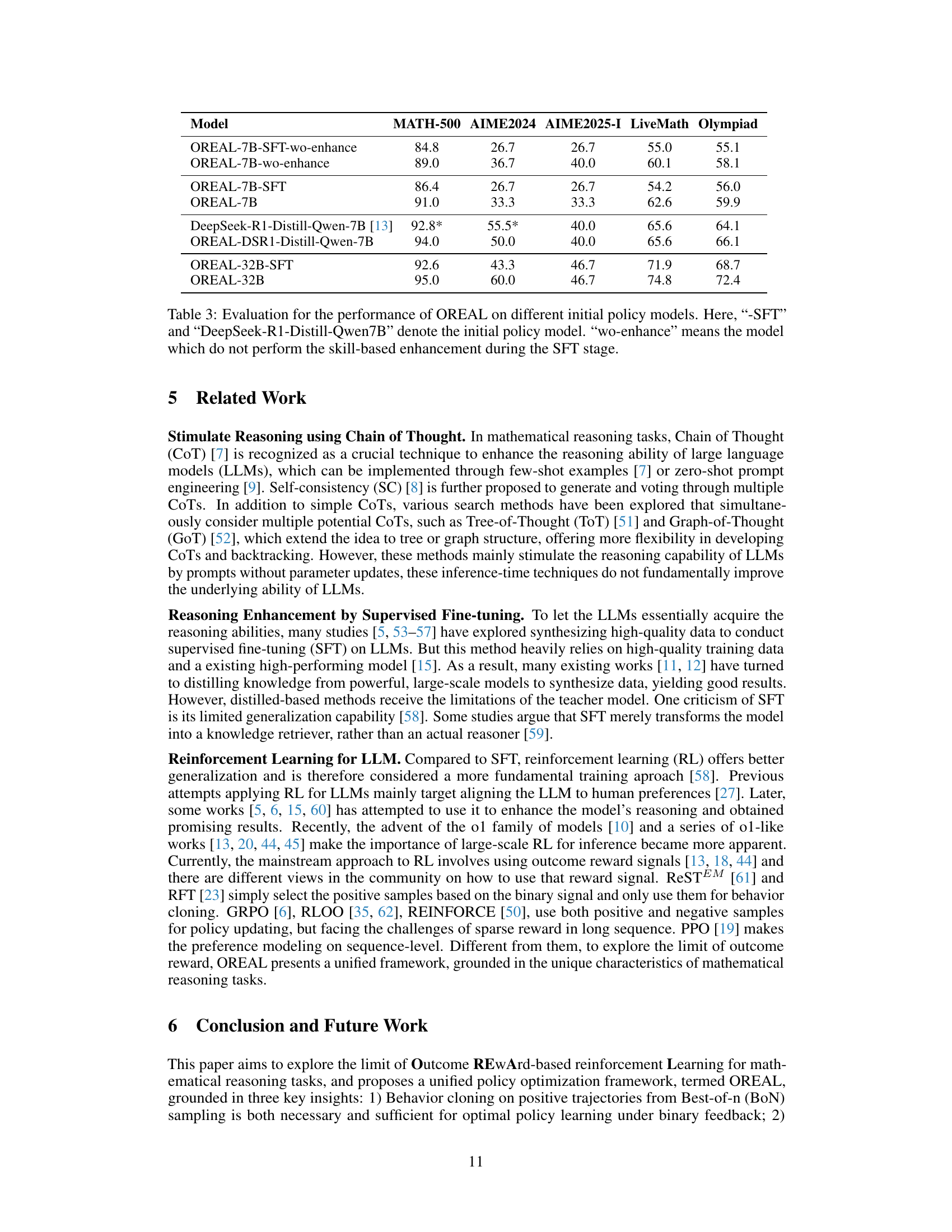
🔼 This table presents a comparison of the performance of the OREAL reinforcement learning framework when initialized with different pre-trained language models. The models compared include those fine-tuned with supervised learning (’-SFT’) and a specific model, DeepSeek-R1-Distill-Qwen-7B, along with variations where skill-based enhancement was not applied during supervised fine-tuning (‘wo-enhance’). The table shows the performance metrics (pass@1 accuracy) on several benchmark datasets (MATH-500, AIME2024, AIME2025-I, LiveMath, Olympiad) for each model, highlighting the impact of the initial policy model and the skill-based enhancement technique on the overall performance of the OREAL framework.
read the caption
Table 3: Evaluation for the performance of OREAL on different initial policy models. Here, “-SFT” and “DeepSeek-R1-Distill-Qwen7B” denote the initial policy model. “wo-enhance” means the model which do not perform the skill-based enhancement during the SFT stage.
Full paper#