TL;DR#
Current video generation methods face challenges in modeling spatiotemporal complexity and achieving high computational efficiency. Existing Diffusion Transformers (DiTs), while successful in image generation, often struggle with the added complexities of video data, leading to inefficient models. The high computational costs and limitations in controlling dynamic aspects are significant hurdles.
Lumina-Video addresses these challenges with a novel framework built upon a multi-scale Next-DiT architecture. This allows for efficient learning across different scales and resource allocation, improving efficiency and flexibility. The incorporation of motion scores as explicit conditions enables direct control of video dynamics. Progressive training and a multi-source data strategy further enhance the model’s performance and the quality of the generated videos. Overall, Lumina-Video demonstrates superior performance and flexibility compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances video generation by introducing Lumina-Video, a novel framework that leverages the strengths of Next-DiT while addressing the unique challenges of video synthesis. Its multi-scale architecture and motion control offer greater flexibility and efficiency, opening up new avenues for research in high-quality, high-fidelity video generation. The open-sourcing of the framework and model parameters further enhances its impact by fostering collaboration and accelerating progress in the field.
Visual Insights#

🔼 This figure showcases four example videos generated by Lumina-Video, each corresponding to a different text prompt. The prompts range in complexity from simple descriptions (e.g., ‘A massive explosion’) to more detailed and specific scenarios (e.g., ‘A red-haired child in glasses, dressed in a brown shirt and holding a large shoulder bag, looks off-camera with curiosity or anticipation. The softly blurred background, likely a living room or study with a bookshelf or bulletin board, adds a homely feel to the scene.’). The generated videos demonstrate Lumina-Video’s capacity to produce high-quality, visually rich results, with details that match the provided textual prompts. Additionally, the videos exhibit remarkable temporal coherence, demonstrating Lumina-Video’s strength in accurately capturing motion and ensuring smooth transitions throughout the video sequences.
read the caption
Figure 1: Lumina-Video demonstrates a strong ability to generate high-quality videos with rich details and remarkable temporal coherence, accurately following both simple and detailed text prompts.
| Model | Param | Total Score (%) | Quality Score (%) | Semantic Score (%) | Motion Smoothness (%) | Dynamic Degree (%) |
| Proprietary Models | ||||||
| Pika-1.0 (Labs, 2024) | - | 80.69 | 82.92 | 71.77 | 99.50 | 47.50 |
| Kling (Kuaishou, 2024) | - | 81.85 | 83.39 | 75.68 | 99.40 | 46.94 |
| Vidu (VIDU, 2025) | - | 81.89 | 83.85 | 74.04 | 97.71 | 82.64 |
| Gen-3 (Runway Research, 2024) | - | 82.32 | 84.11 | 75.17 | 99.23 | 60.14 |
| Luma (LumaLab, 2024) | - | 83.61 | 83.47 | 84.17 | 99.35 | 44.26 |
| Sora (OpenAI, 2024) | - | 84.28 | 85.51 | 79.35 | 98.74 | 79.91 |
| Open-Source Models | ||||||
| OpenSora Plan V1.3 (Lab & etc., 2024) | 2.7B | 77.23 | 80.14 | 65.62 | 99.05 | 30.28 |
| OpenSora V1.2 (8s) (Zheng et al., 2024b) | 1.1B | 79.76 | 81.35 | 73.39 | 98.50 | 42.39 |
| VideoCrafter 2.0 (Chen et al., 2024a) | 1.4B | 80.44 | 82.20 | 73.42 | 97.73 | 42.50 |
| Allegro (Zhou et al., 2024) | 3B | 81.09 | 83.12 | 72.98 | 98.82 | 55.00 |
| CogVideoX (Yang et al., 2024) | 5B | 81.61 | 82.75 | 77.04 | 96.92 | 70.97 |
| Pyramid Flow (Jin et al., 2024a) | 2B | 81.72 | 84.74 | 69.62 | 99.12 | 64.63 |
| CogVideoX 1.5 (Yang et al., 2024) | 5B | 82.17 | 82.78 | 79.76 | 98.31 | 50.93 |
| Vchitect 2.0 (Fan et al., 2025) | 2B | 82.24 | 83.54 | 77.06 | 98.98 | 63.89 |
| HunyuanVideo (Kong et al., 2024) | 13B | 83.24 | 85.09 | 75.82 | 98.99 | 70.83 |
| Lumina-Video (Single Scale) | 2B | 82.99 | 83.92 | 79.27 | 98.90 | 67.13 |
| Lumina-Video (Multi Scale) | 2B | 82.94 | 84.08 | 78.39 | 98.92 | 71.76 |
🔼 This table presents a quantitative comparison of Lumina-Video’s performance against various proprietary and open-source video generation models using the VBench benchmark. VBench evaluates video quality across multiple dimensions, including overall quality, semantic consistency (alignment of video content with the text prompt), and other aspects like motion smoothness and dynamic degree. The table is divided into sections for proprietary and open-source models to facilitate better comparison. Model parameters, scores for each evaluation metric, and a dynamic degree score are shown for each model.
read the caption
Table 1: Comparison on VBench. Proprietary models and open-source models are listed separately for better comparison.
In-depth insights#
Multi-Scale DiT#
The concept of “Multi-Scale DiT” suggests a significant advancement in diffusion transformer models for video generation. It likely addresses the limitations of single-scale approaches by incorporating multiple patch sizes within the DiT architecture. This allows the model to learn video structures at varying levels of granularity simultaneously, enhancing both efficiency and flexibility. Smaller patch sizes capture fine details, while larger ones process broader contextual information. This multi-scale strategy likely improves computational efficiency by reducing the number of tokens processed, thereby mitigating the computational burden associated with high-resolution videos. The model’s ability to dynamically adjust its computational cost based on resource constraints and specific requirements enhances flexibility, allowing for optimization across various hardware platforms and task complexities. The joint training of multiple patch sizes likely enables knowledge sharing and improved generalization across different scales, leading to more robust and high-quality video generation.
Motion Control#
Controlling motion in video generation is crucial for creating realistic and engaging content. A thoughtful approach would involve explicitly modeling motion rather than relying on implicit learning. This could involve incorporating optical flow or other motion estimation techniques as input features to guide the generation process. Different levels of motion control could be implemented, allowing users to specify the desired degree of dynamism, from subtle movements to intense action. A key challenge is balancing realism with computational efficiency, since high-fidelity motion often requires significant resources. An elegant solution could potentially involve a hierarchical approach where different levels of detail are modeled at different scales, with coarser motion being handled at larger scales and fine details at smaller scales. Progressive training could be particularly useful, starting with simpler motion and gradually increasing complexity. The quality of motion control should be evaluated both subjectively (visual appeal) and objectively (metrics like temporal consistency and smoothness). Finally, user control over motion parameters would enhance usability, empowering users to customize generated videos to meet specific requirements and creative visions.
Progressive Training#
Progressive training, as discussed in the context of generative models, is a crucial technique for efficiently training large-scale models. It involves a stepwise increase in model complexity and data resolution, starting with simpler tasks and gradually increasing the difficulty. This approach is particularly useful for video generation because of the increased computational cost and complexity associated with handling high-resolution spatiotemporal data. The incremental nature allows the model to learn fundamental concepts at lower resolutions and then refine its understanding at progressively higher resolutions and frame rates. This prevents the model from being overwhelmed by the sheer volume of data and complexity early in training. Multi-stage training complements progressive training by combining multiple training stages to effectively leverage different data sources at different resolutions and frame rates. A carefully crafted training strategy is essential, involving consideration of suitable patch sizes, timestep shifting, and the integration of multiple data sources to achieve optimal results. In this context, progressive training is not merely a training schedule but a fundamental strategy that enhances training efficiency and overall model quality.
Video-Audio Model#
A video-audio model, in the context of this research paper, seeks to generate synchronized audio for videos, enriching the viewing experience. The core challenge lies in creating audio that is both semantically relevant to the video content and temporally aligned with the visual events. This is a complex task demanding a sophisticated model capable of understanding the relationship between visual and auditory information. The success hinges on efficient integration of various modalities including visual features, text descriptions, and audio representations, all processed to predict a waveform that matches the video. Multimodal conditioning is key to aligning the diverse input sources and ensuring the generated audio is both coherent and high-fidelity. Advanced architectures like Next-DiT or similar are likely employed due to their capability for handling long sequences and intricate relationships, crucial for video-audio synchronization. The model’s training needs a substantial dataset of synchronized audio-visual pairs which would ideally include diverse scenarios to enable broad generalization.
Future Work#
The authors outline promising avenues for future research. Multi-scale patchification, drawing parallels to dynamic neural networks, suggests exploring more nuanced compression across multiple dimensions (depth, width, tokens) to enhance efficiency further. Addressing remaining shortcomings in video aesthetics, specifically tackling complex motion synthesis and artifact reduction, is also highlighted. The need for improved data curation and pipeline optimization is acknowledged, implying a focus on better training data and streamlining the generation process for higher quality outputs. Finally, investigating the interplay between motion conditioning and the quality of generated content represents a significant opportunity to refine control over video dynamics without sacrificing fidelity.
More visual insights#
More on figures

🔼 This figure illustrates the architecture of Lumina-Video, a novel framework for efficient and flexible video generation. It highlights the use of a Multi-scale Next-DiT architecture, which incorporates multiple patch sizes to learn video structures at various scales, improving both efficiency and flexibility. The diagram also shows how motion scores, derived from optical flow, are incorporated as explicit conditions to directly control the dynamic degree of the generated videos. The process involves 3D encoding of the input video, text embedding, and motion embedding, which are then processed by the multi-scale Next-DiT blocks before unpatchifying and generating the final video output. The figure visually represents the multi-stage processing, highlighting the interplay between different scales and the motion conditioning in the video generation process.
read the caption
Figure 2: Architecture of Lumina-Video with Multi-scale Next-DiT and Motion Conditioning.

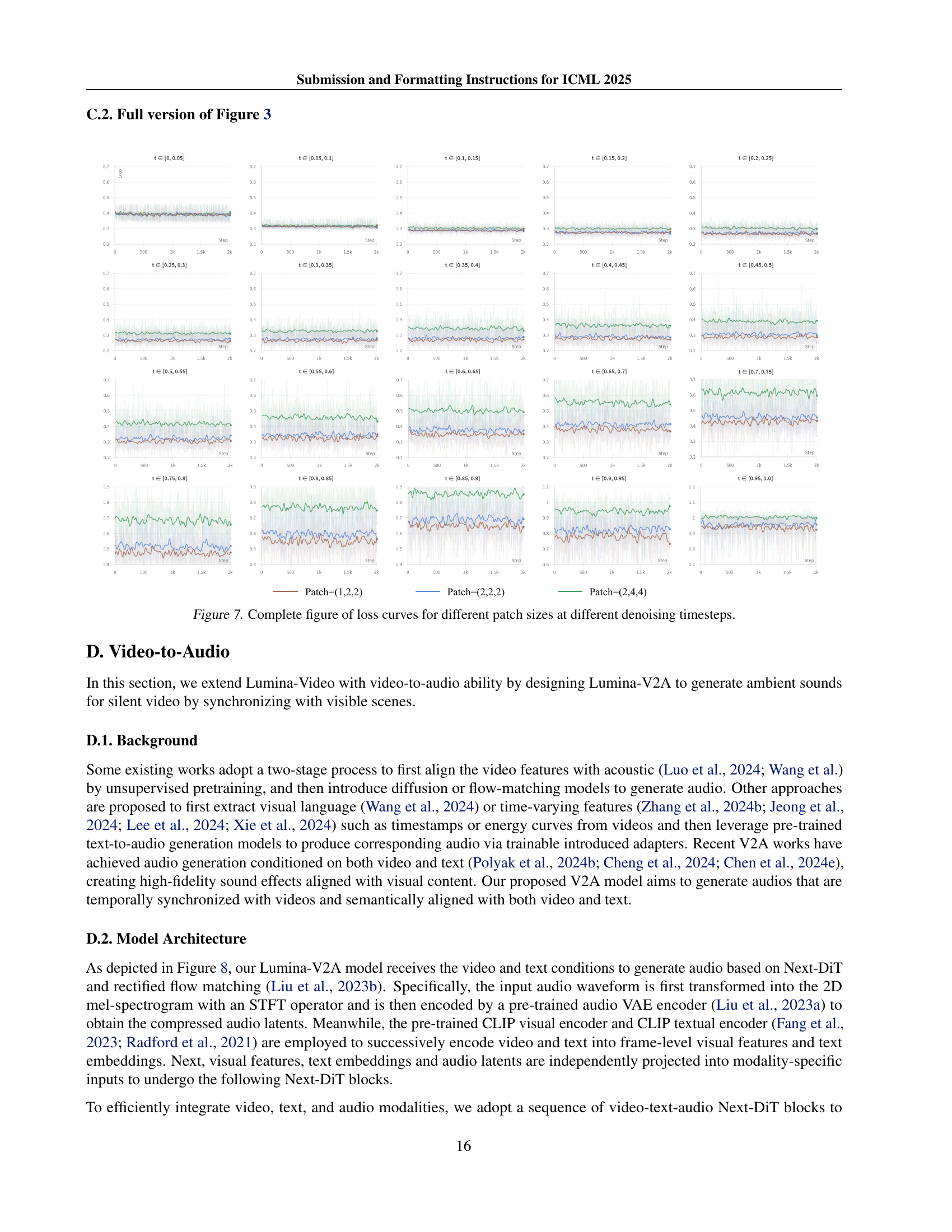
🔼 This figure displays the training loss curves for three different patch sizes used in the Lumina-Video model at various stages of the denoising process. The x-axis represents the denoising timestep, progressing from early stages (t close to 0) to later stages (t close to 1), while the y-axis shows the training loss. The three lines represent different patch sizes: (1,2,2), (2,2,2), and (2,4,4), each corresponding to a different level of detail in the representation. The curves illustrate how the loss changes for each patch size as the model progresses through the denoising process. This helps visualize the effectiveness of the multi-scale approach used in Lumina-Video, where different patch sizes are utilized at different stages to balance efficiency and quality.
read the caption
Figure 3: Loss curves for different patch sizes at different denoising timesteps. See Sec. C.2 for the complete figure.

🔼 The figure illustrates how Lumina-Video’s multi-scale patchification approach enables flexible multi-stage denoising during inference. By using smaller patches at earlier stages, the model efficiently captures the overall video structure. Progressively, it switches to larger patches to refine details. This flexible strategy balances computational cost and quality, making inference adaptable to different resource constraints and improving the overall efficiency without sacrificing too much quality.
read the caption
Figure 4: Multi-scale Patchification allows Lumina-Video to perform flexible multi-stage denoising during inference, leading to a better tradeoff between quality and efficiency.

🔼 This figure showcases the impact of different patchification strategies on the quality of generated videos using Lumina-Video. It visually demonstrates how altering the patch size (the spatial and temporal resolution at which the video is processed) affects the final output. By comparing videos generated with different patch sizes, the figure provides a qualitative assessment of the trade-off between computational efficiency (larger patch sizes) and the level of detail and fidelity in the generated content (smaller patch sizes).
read the caption
Figure 5: Comparison of generated videos using different patchification strategies.

🔼 This figure displays a comparison of videos generated using different combinations of positive and negative motion scores. The motion score is a control mechanism in Lumina-Video that allows for adjusting the intensity of motion in generated videos. By varying the positive and negative motion scores, the model can produce videos with different levels of dynamism, ranging from very static to highly dynamic. The figure visually demonstrates the effect of this control mechanism, illustrating how the choice of motion scores impacts the overall visual flow and movement within the generated video sequences.
read the caption
Figure 6: Comparison of generated videos using different positive and negative motion scores.

🔼 This figure displays a comprehensive set of loss curves, illustrating the impact of various patch sizes on the quality of video denoising at different stages of the process. Each curve represents the loss magnitude across multiple timesteps for a specific patch size. By comparing these curves, one can analyze the performance of various patch sizes during different phases of denoising. This visualization helps illustrate the benefits of employing a multi-scale approach by highlighting how different patch sizes are better suited for different stages in the process, with smaller patch sizes showing improved performance in later stages focused on finer detail and larger patch sizes performing better in earlier stages when capturing broad structures.
read the caption
Figure 7: Complete figure of loss curves for different patch sizes at different denoising timesteps.

🔼 Lumina-V2A, a video-to-audio model, uses a Next-DiT architecture. It processes video, text, and audio features using a co-attention mechanism to ensure semantic consistency and temporal synchronization. The model’s input includes a noisy audio latent representation from a pre-trained 2D VAE and visual and textual embeddings from CLIP. Time embeddings and high-frame-rate visual features from Synchformer help align the audio with the visual and textual information. The model outputs a refined audio latent representation, then reconstructs it into a mel-spectrogram and finally an audio waveform using a pre-trained HiFi-GAN vocoder. The training data includes audio-visual pairs from VGGSound, selected for high temporal alignment.
read the caption
Figure 8: Illustration of Lumina-V2A Model based on Next-DiT
More on tables
| Patch | Time cost | Quality | Semantic | Total |
| (1, 2, 2) | 1.00 | 83.92 | 79.27 | 82.99 |
| (2, 2, 2) | 0.36 | 83.50 | 78.33 | 82.47 |
| (2, 4, 4) | 0.07 | 82.47 | 77.77 | 81.53 |
| Combined | 0.34 | 84.08 | 78.39 | 82.94 |
🔼 This table presents an ablation study on the impact of different patch sizes used in the Multi-scale Next-DiT architecture within the Lumina-Video model. It compares the computational cost (Time Cost), and the video generation quality (Quality, Semantic, Total) achieved using various patch sizes: (1,2,2), (2,2,2), (2,4,4) and a combination of these. The results demonstrate the trade-off between computational efficiency and generation quality across different scales.
read the caption
Table 2: Ablation study on patchification.
| Positive Motion | Negtive Motion | Dynamic Degree | Quality Score* | Semantic Score | Total Score |
| 4 | 4 | 45.37 | 86.11 | 79.28 | 82.24 |
| 8 | 8 | 53.70 | 86.18 | 78.88 | 82.72 |
| 4 | 2 | 72.78 | 84.11 | 79.10 | 82.41 |
| 8 | 2 | 85.89 | 83.51 | 78.36 | 82.63 |
| 4 | 2-[0.05-4] | 67.13 | 85.31 | 79.27 | 82.99 |
| 8 | 2-[0.05-8] | 83.33 | 84.58 | 78.55 | 83.28 |
🔼 This table presents an ablation study analyzing the impact of motion conditioning in the Lumina-Video model. It shows how varying the positive and negative motion scores during classifier-free guidance affects the generated video’s dynamic degree, quality score (excluding dynamic degree), semantic score, and total score. The results demonstrate that controlling the difference between positive and negative motion scores, rather than their absolute values, is crucial for achieving high-quality videos with the desired level of dynamism.
read the caption
Table 3: Impact of Motion Score. * means Dynamic Degree is excluded from Quality Score.
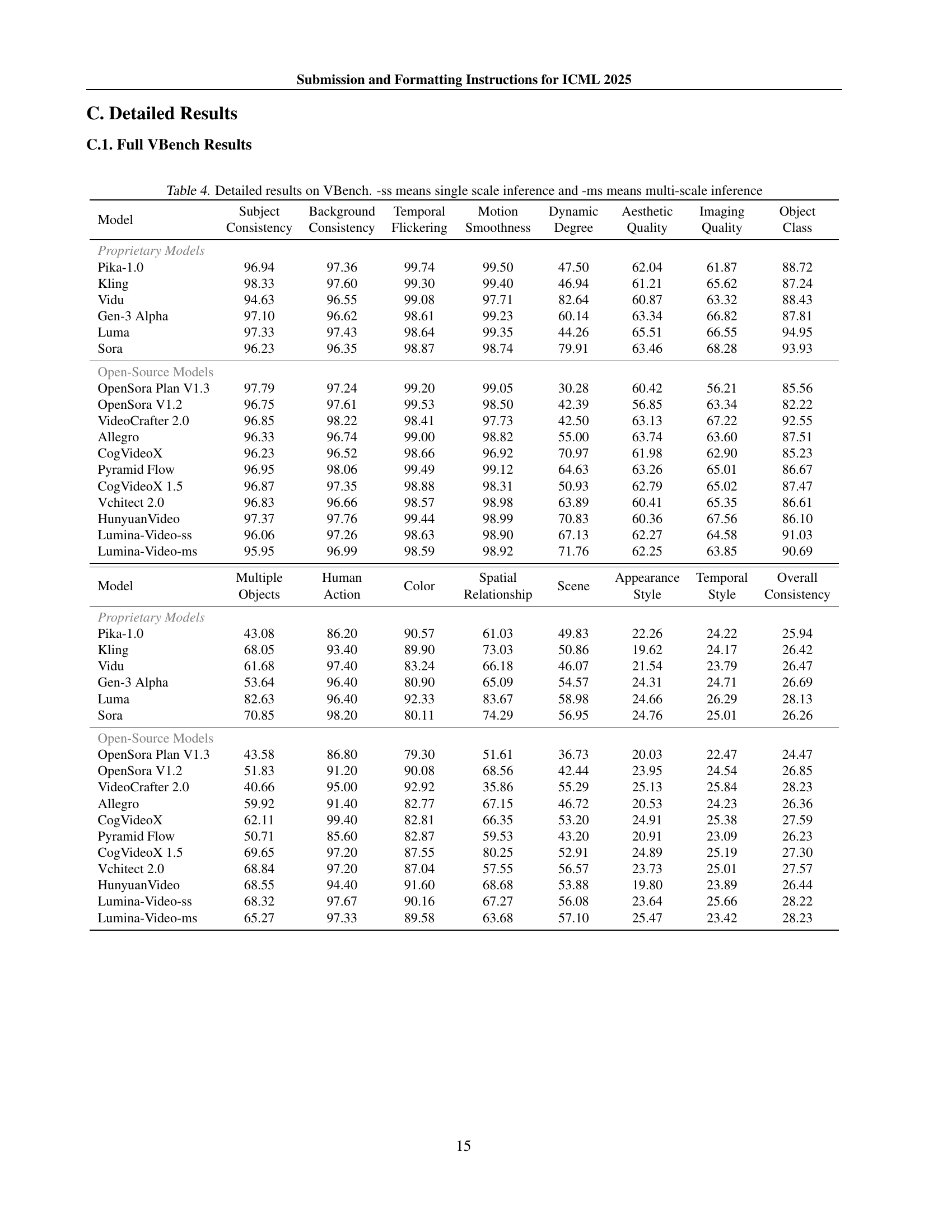
| Model | Subject Consistency | Background Consistency | Temporal Flickering | Motion Smoothness | Dynamic Degree | Aesthetic Quality | Imaging Quality | Object Class |
| Proprietary Models | ||||||||
| Pika-1.0 | 96.94 | 97.36 | 99.74 | 99.50 | 47.50 | 62.04 | 61.87 | 88.72 |
| Kling | 98.33 | 97.60 | 99.30 | 99.40 | 46.94 | 61.21 | 65.62 | 87.24 |
| Vidu | 94.63 | 96.55 | 99.08 | 97.71 | 82.64 | 60.87 | 63.32 | 88.43 |
| Gen-3 Alpha | 97.10 | 96.62 | 98.61 | 99.23 | 60.14 | 63.34 | 66.82 | 87.81 |
| Luma | 97.33 | 97.43 | 98.64 | 99.35 | 44.26 | 65.51 | 66.55 | 94.95 |
| Sora | 96.23 | 96.35 | 98.87 | 98.74 | 79.91 | 63.46 | 68.28 | 93.93 |
| Open-Source Models | ||||||||
| OpenSora Plan V1.3 | 97.79 | 97.24 | 99.20 | 99.05 | 30.28 | 60.42 | 56.21 | 85.56 |
| OpenSora V1.2 | 96.75 | 97.61 | 99.53 | 98.50 | 42.39 | 56.85 | 63.34 | 82.22 |
| VideoCrafter 2.0 | 96.85 | 98.22 | 98.41 | 97.73 | 42.50 | 63.13 | 67.22 | 92.55 |
| Allegro | 96.33 | 96.74 | 99.00 | 98.82 | 55.00 | 63.74 | 63.60 | 87.51 |
| CogVideoX | 96.23 | 96.52 | 98.66 | 96.92 | 70.97 | 61.98 | 62.90 | 85.23 |
| Pyramid Flow | 96.95 | 98.06 | 99.49 | 99.12 | 64.63 | 63.26 | 65.01 | 86.67 |
| CogVideoX 1.5 | 96.87 | 97.35 | 98.88 | 98.31 | 50.93 | 62.79 | 65.02 | 87.47 |
| Vchitect 2.0 | 96.83 | 96.66 | 98.57 | 98.98 | 63.89 | 60.41 | 65.35 | 86.61 |
| HunyuanVideo | 97.37 | 97.76 | 99.44 | 98.99 | 70.83 | 60.36 | 67.56 | 86.10 |
| Lumina-Video-ss | 96.06 | 97.26 | 98.63 | 98.90 | 67.13 | 62.27 | 64.58 | 91.03 |
| Lumina-Video-ms | 95.95 | 96.99 | 98.59 | 98.92 | 71.76 | 62.25 | 63.85 | 90.69 |
| Model | Multiple Objects | Human Action | Color | Spatial Relationship | Scene | Appearance Style | Temporal Style | Overall Consistency |
| Proprietary Models | ||||||||
| Pika-1.0 | 43.08 | 86.20 | 90.57 | 61.03 | 49.83 | 22.26 | 24.22 | 25.94 |
| Kling | 68.05 | 93.40 | 89.90 | 73.03 | 50.86 | 19.62 | 24.17 | 26.42 |
| Vidu | 61.68 | 97.40 | 83.24 | 66.18 | 46.07 | 21.54 | 23.79 | 26.47 |
| Gen-3 Alpha | 53.64 | 96.40 | 80.90 | 65.09 | 54.57 | 24.31 | 24.71 | 26.69 |
| Luma | 82.63 | 96.40 | 92.33 | 83.67 | 58.98 | 24.66 | 26.29 | 28.13 |
| Sora | 70.85 | 98.20 | 80.11 | 74.29 | 56.95 | 24.76 | 25.01 | 26.26 |
| Open-Source Models | ||||||||
| OpenSora Plan V1.3 | 43.58 | 86.80 | 79.30 | 51.61 | 36.73 | 20.03 | 22.47 | 24.47 |
| OpenSora V1.2 | 51.83 | 91.20 | 90.08 | 68.56 | 42.44 | 23.95 | 24.54 | 26.85 |
| VideoCrafter 2.0 | 40.66 | 95.00 | 92.92 | 35.86 | 55.29 | 25.13 | 25.84 | 28.23 |
| Allegro | 59.92 | 91.40 | 82.77 | 67.15 | 46.72 | 20.53 | 24.23 | 26.36 |
| CogVideoX | 62.11 | 99.40 | 82.81 | 66.35 | 53.20 | 24.91 | 25.38 | 27.59 |
| Pyramid Flow | 50.71 | 85.60 | 82.87 | 59.53 | 43.20 | 20.91 | 23.09 | 26.23 |
| CogVideoX 1.5 | 69.65 | 97.20 | 87.55 | 80.25 | 52.91 | 24.89 | 25.19 | 27.30 |
| Vchitect 2.0 | 68.84 | 97.20 | 87.04 | 57.55 | 56.57 | 23.73 | 25.01 | 27.57 |
| HunyuanVideo | 68.55 | 94.40 | 91.60 | 68.68 | 53.88 | 19.80 | 23.89 | 26.44 |
| Lumina-Video-ss | 68.32 | 97.67 | 90.16 | 67.27 | 56.08 | 23.64 | 25.66 | 28.22 |
| Lumina-Video-ms | 65.27 | 97.33 | 89.58 | 63.68 | 57.10 | 25.47 | 23.42 | 28.23 |
🔼 This table presents a comprehensive breakdown of Lumina-Video’s performance on the VBench benchmark, a standardized evaluation suite for text-to-video generation models. It details the model’s scores across various metrics, categorized by aspects of video quality (such as temporal consistency, motion smoothness, and aesthetic quality) and alignment with the input text prompt. The results are broken down for both single-scale (-ss) and multi-scale (-ms) inference strategies, providing a comparison of performance and efficiency. The table further compares Lumina-Video’s results with those of other leading proprietary and open-source models, offering a clear picture of its strengths and weaknesses.
read the caption
Table 4: Detailed results on VBench. -ss means single scale inference and -ms means multi-scale inference
Full paper#