TL;DR#
Current diffusion transformer (DiT) models for video generation struggle with temporal inconsistencies and subpar visual quality, hindering real-world applications. These models generate videos with unnatural transitions, blurry details, and lack of coherence between frames. Existing enhancement methods primarily focus on UNet-based models, leaving DiT model improvement relatively unexplored.
Enhance-A-Video tackles this problem with a novel, training-free approach. It enhances cross-frame correlations in DiT models by adjusting the distribution of temporal attention weights. This method doesn’t require retraining or additional parameters, making it easily integrated into existing DiT-based video generation frameworks. Experimental results across multiple models demonstrate significant improvements in video quality, showcasing the effectiveness and adaptability of this simple yet impactful solution.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel, training-free method to improve the quality of videos generated by diffusion transformer models. This addresses a key challenge in the field and opens up new avenues for research in video generation enhancement. The method’s simplicity and effectiveness make it easily adaptable to existing frameworks, potentially leading to significant advancements in various applications.
Visual Insights#

🔼 This figure demonstrates the effectiveness of Enhance-A-Video in improving the quality of videos generated by diffusion transformer models. The top row shows examples of videos generated by a baseline model, highlighting issues such as blurry faces, incorrect details (e.g., extra toes), and poor overall coherence. The bottom row displays the same videos processed with Enhance-A-Video, showcasing improvements such as clearer faces, corrected details, and greater visual consistency. Enhance-A-Video achieves this improvement without requiring any additional training, parameters, or memory.
read the caption
Figure 1: Enhance-A-Video boosts diffusion transformers-based video generation quality at minimal cost - no training needed, no extra learnable parameters, no memory overhead. Detailed captions are available in Appendix F.
| Model | Time (min) | Overhead | |
|---|---|---|---|
| w/o EAV | w/ EAV | ||
| HunyuanVideo | 50.32 | 50.72 | 0.8% |
| CogVideoX | 1.53 | 1.57 | 2.1% |
🔼 This table presents a quantitative comparison of video generation quality using the VBench metric. It shows the scores achieved by three different diffusion transformer-based video generation models (CogVideoX, Open-Sora, and LTX-Video) both before and after applying the Enhance-A-Video method. The comparison highlights the improvement in VBench scores resulting from using Enhance-A-Video, demonstrating its effectiveness in enhancing video generation quality.
read the caption
Table 1: Comparison of VBench Score for CogVideoX, Open-Sora, and LTX-Video models without and with Enhance-A-Video.
In-depth insights#
DiT Enhancement#
The concept of ‘DiT Enhancement’ centers on improving the quality and coherence of Diffusion Transformer (DiT)-based video generation. The core issue addressed is the inherent challenge of maintaining temporal consistency while preserving fine-grained details in videos produced by DiTs. Existing methods often struggle with unnatural transitions and degraded quality, limiting their practical applicability. Enhance-A-Video, presented in this paper, tackles this directly by improving cross-frame correlations through a training-free method. This is achieved by modifying the temporal attention mechanism, specifically by scaling non-diagonal attention elements using a calculated ‘cross-frame intensity’ and an ’enhance temperature’ parameter. This approach is computationally efficient and readily integrates into existing DiT frameworks without retraining. The key insight is that enhancing the balance of cross-frame and intra-frame attention yields better temporal coherence and visual fidelity. Experimental results demonstrate significant improvements across various DiT models, showcasing the effectiveness of this training-free enhancement strategy for enhancing video generation quality.
Training-Free Boost#
A ‘Training-Free Boost’ in a video generation model implies a significant enhancement achieved without retraining the model. This is highly desirable as it avoids the computational cost and time associated with traditional training processes. The approach likely involves manipulating the model’s internal parameters or attention mechanisms during inference, effectively tuning its behavior on a per-video basis. This could be achieved by adjusting existing hyperparameters, modifying attention weights dynamically based on the input, or integrating a lightweight module that refines intermediate representations. Such a method offers significant advantages: it’s readily applicable to existing models, easily integrable into existing pipelines, and significantly reduces deployment overhead. However, the potential drawbacks include limitations in the degree of enhancement possible and potential unpredictability in performance across diverse input videos. A thoughtful analysis of the technique is critical to assess its generalizability and potential limitations. Furthermore, careful evaluation metrics are crucial to ascertain whether the improved results translate into tangible improvements in user experience. Ultimately, the success of a ‘Training-Free Boost’ hinges on striking a balance between improvement gains and the computational simplicity of its implementation.
Cross-Frame Focus#
The concept of ‘Cross-Frame Focus’ in video generation highlights the crucial role of inter-frame relationships in enhancing video coherence and quality. Effective cross-frame attention mechanisms are key to generating videos with smooth transitions and consistent visual elements across frames. A lack of focus on these relationships often leads to inconsistencies such as abrupt transitions or blurry details. Therefore, a method that effectively strengthens cross-frame correlations while preserving fine-grained details within individual frames would significantly improve the quality of generated videos. This involves carefully balancing intra-frame and inter-frame attention weights to prevent issues stemming from an overemphasis on either. Techniques such as adjusting attention distributions through a temperature parameter or directly enhancing cross-frame intensity offer promising avenues to achieve this balance. However, simply increasing temperature or cross-frame intensity can lead to unintended artifacts, thus the need for sophisticated methods of selectively amplifying the desired inter-frame connections. The optimal ‘Cross-Frame Focus’ would ensure a cohesive narrative while maintaining a high level of visual fidelity and avoiding unwanted distortions or artifacts.
Temp. Parameter#
The concept of a temperature parameter, commonly used in large language models to control the randomness of output, is explored in the context of diffusion transformer (DiT)-based video generation. The authors observe that a balanced distribution of attention weights between frames is crucial for temporal consistency in generated videos. Standard DiT models often exhibit an unbalanced distribution, with significantly lower attention weights for cross-frame interactions (non-diagonal elements) than for intra-frame ones. The paper proposes using a temperature parameter to scale the cross-frame intensity, calculated by averaging non-diagonal attention weights. This adjustment aims to strengthen the cross-frame correlations without retraining the model, improving both temporal coherence and visual quality. The temperature parameter acts as a control mechanism, allowing for a balance between deterministic and diverse output, analogous to its role in text generation. However, directly applying temperature to the attention matrix proved ineffective. Therefore, a novel enhance block is designed which uses a scaled Cross-Frame Intensity to enhance the temporal attention outputs. This novel approach is shown to be a training-free and efficient method to improve various DiT models, showcasing improved quality and temporal consistency in generated videos.
Future Enhancements#
Future enhancements for Enhance-A-Video could involve several key areas. Adaptive temperature control, replacing the fixed temperature parameter with a mechanism that learns optimal values based on prompt context, is crucial for maximizing performance across diverse video generation tasks. This would require integrating reinforcement learning from human feedback (RLHF) or similar techniques. Secondly, extending the approach beyond temporal attention to encompass spatial attention and cross-attention mechanisms would improve overall video quality, addressing current limitations in preserving spatial coherence and prompt alignment. Investigating more sophisticated cross-frame correlation methods could also yield notable improvements. Finally, thorough exploration of different DiT architectures and incorporating Enhance-A-Video into newer model designs is vital. A comparative analysis of its efficacy across various architectures would provide a more comprehensive understanding and enable optimizations to further enhance video generation quality.
More visual insights#
More on figures

🔼 The figure shows a video still from the HunyuanVideo model. Several issues with the video generation are highlighted, including unnatural head movements that appear jerky or unrealistic, repeated instances of the right hand in multiple frames which suggests a lack of variability in pose generation, and inconsistencies in the glove color, where the color changes between frames.
read the caption
Figure 2: Video sample of HunyuanVideo model with unnatural head movements, repeated right hands and conflicting glove color.

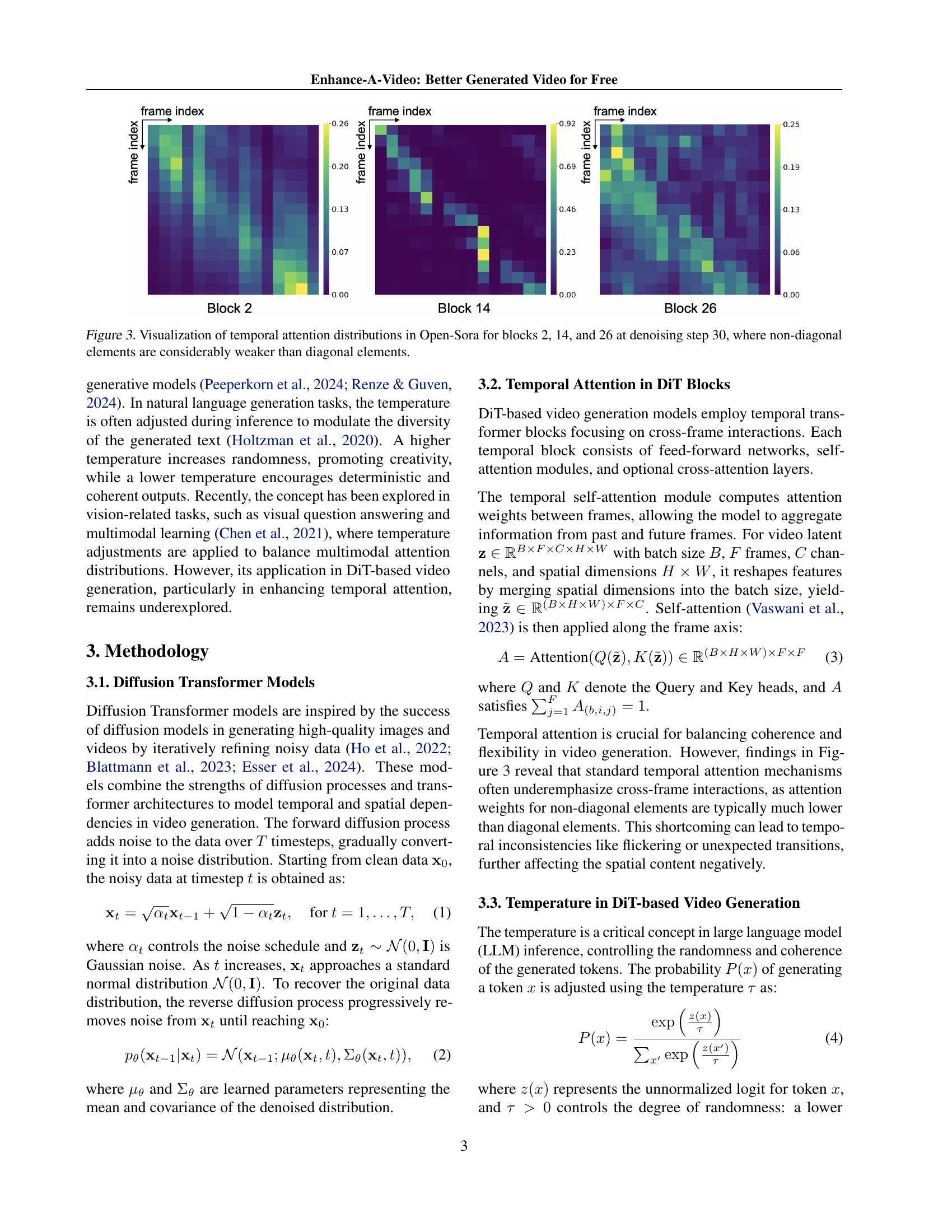
🔼 This figure visualizes the temporal attention distributions within three different blocks (Block 2, Block 14, and Block 26) of the Open-Sora model at denoising step 30. Each heatmap represents the attention weights between different frames in a video sequence. The diagonal elements of the heatmaps show the attention weights between a frame and itself (intra-frame attention). The off-diagonal elements show the attention weights between different frames (inter-frame attention). The figure highlights that the inter-frame attention weights (off-diagonal elements) are significantly weaker than the intra-frame attention weights (diagonal elements) in all three blocks. This observation suggests that the model struggles to effectively utilize information from other frames, potentially leading to inconsistencies in the generated video.
read the caption
Figure 3: Visualization of temporal attention distributions in Open-Sora for blocks 2, 14, and 26 at denoising step 30, where non-diagonal elements are considerably weaker than diagonal elements.

🔼 The Enhance Block in Figure 4 takes the temporal attention map as input. It calculates the average of the non-diagonal elements, representing the cross-frame intensity (CFI). This CFI is then scaled using a temperature parameter. Finally, the scaled CFI is added back to the original temporal attention map to enhance the output, strengthening cross-frame correlations and improving the model’s ability to maintain consistency between frames.
read the caption
Figure 4: Overview of the Enhance Block. The block computes the average of non-diagonal elements from the temporal attention map as Cross-Frame Intensity (CFI). The CFI is scaled by the temperature parameter and fused back to enhance the temporal attention output.

🔼 This figure visualizes the impact of Enhance-A-Video on the temporal attention mechanism of the CogVideoX model. It displays a heatmap representing the difference in temporal attention weights between the original CogVideoX model and the same model enhanced with Enhance-A-Video. The heatmap is generated at layer 29 during denoising step 50. Blue regions indicate that the enhanced model has stronger cross-frame attention (non-diagonal elements of the attention matrix), signifying improved coherence between frames. Conversely, red regions indicate that the enhanced model exhibits weaker intra-frame attention (diagonal elements), suggesting the model focuses less on individual frames and more on the overall temporal flow, leading to improved consistency.
read the caption
Figure 5: Temporal attention difference map between original CogVideoX model and w/ Enhance-A-Video of layer 29 at denoising step 50. Non-diagonal elements in the attention matrix of w/ Enhance-A-Video show higher values (shown in blue), while diagonal elements have reduced values (shown in red).

🔼 Figure 6 presents a qualitative comparison of video generation results from the HunyuanVideo model with and without Enhance-A-Video. The two subfigures showcase the improvements achieved in video generation quality and temporal consistency. (a) depicts an antique car driving through a wheat field, demonstrating the improved realism and detail in the enhanced video (dust rising, wheat brushing against the car). (b) shows a baseball player, where Enhance-A-Video corrects issues in the original HunyuanVideo such as inconsistent glove color and unnatural hand/head movements, leading to a more coherent and natural-looking video.
read the caption
Figure 6: Qualitative results of Enhance-A-Video on HunyuanVideo. Captions: (a) An antique car drives along a dirt road through golden wheat fields. Dust rises softly as wheat brushes against the car with distant trees meeting a blue sky. (b) A baseball player grips a bat in black gloves, wearing a blue-and-white uniform and cap, with a blurred crowd and green field highlighting his focused stance.

🔼 Figure 7 presents a comparison of video generation results using the CogVideoX model with and without Enhance-A-Video. Two scenarios are shown: (a) a Corgi dog in a surreal park setting, and (b) a water balloon exploding in extreme slow motion. Enhance-A-Video is shown to improve visual details and the overall quality of the generated videos.
read the caption
Figure 7: Qualitative results of Enhance-A-Video on CogVideoX. Captions: (a) A cute and happy Corgi playing in the park, in a surrealistic style. (b) Balloon full of water exploding in extreme slow motion.

🔼 Figure 8 presents qualitative results demonstrating the effectiveness of Enhance-A-Video when applied to the LTX-Video model. Two example video generations are shown. (a) showcases the enhanced model’s ability to generate a realistic and detailed snow-covered mountain scene with clearly defined peaks, valleys, and shadows, improving upon the original LTX-Video output. (b) displays another example where the enhanced model generates a visually rich and detailed scene, showing an emerald-green river flowing through a rocky canyon. This improved output exhibits better texture and color rendering, especially in the river, rocks, and surrounding environment, highlighting the Enhance-A-Video’s capacity to enrich the details and coherence of the generated video.
read the caption
Figure 8: Qualitative results of Enhance-A-Video on LTX-Video. Captions: (a) The camera pans over snow-covered mountains, revealing jagged peaks and deep, narrow valleys. (b) An emerald-green river winds through a rocky canyon, forming reflective pools amid pine trees and brown-gray rocks.

🔼 This figure displays the results of applying Enhance-A-Video to the Open-Sora model for generating images of cakes. The left side shows the output of the original Open-Sora model, while the right side presents the results after applying Enhance-A-Video. The images demonstrate a visual comparison highlighting improved clarity, detail, and visual quality in the enhanced versions produced by Enhance-A-Video.
read the caption
Figure 9: Qualitative results of Enhance-A-Video on Open-Sora. Caption: A cake.

🔼 This figure presents the results of a user study comparing the performance of several video generation models with and without Enhance-A-Video. The study evaluated three criteria: temporal consistency, prompt-video consistency, and overall visual quality. The results demonstrate that Enhance-A-Video significantly improves video generation quality across all three criteria.
read the caption
Figure 10: User study results comparing baseline models and w/ Enhance-A-Video across evaluation criteria.

🔼 This ablation study investigates the impact of the enhance temperature parameter within the Enhance Block on video generation quality. The results show that moderate values of the parameter effectively balance temporal consistency (smoothness of motion between frames) and visual diversity (variability and richness of details). However, extreme values (either very high or very low) lead to a degradation in overall video quality, indicating an optimal range for this parameter.
read the caption
Figure 11: Ablation study on the enhance temperature parameter in the Enhance Block. Moderate values balance temporal consistency and visual diversity, while extreme values degrade performance.

🔼 This figure shows a visual comparison of video generation results produced by the Enhance-A-Video model with and without the clipping mechanism applied in the Enhance Block. The clipping mechanism, part of the proposed method, prevents the cross-frame intensity from becoming overly amplified and helps to maintain the balance between cross-frame and intra-frame correlations within the temporal attention mechanism. The images demonstrate the impact of this mechanism on temporal consistency and overall quality. The absence of clipping can lead to visual artifacts, such as unexpected transitions or blurriness.
read the caption
Figure 12: Visual comparison of video generation results with and without the clipping mechanism in the Enhance Block.

🔼 Figure 13 presents a comparison of three different methods for enhancing video generation quality using temperature adjustments. Specifically, it visualizes the temporal attention maps (heatmaps showing relationships between frames) and the resulting generated video frames for each method. (a) shows the results using direct temperature scaling on the temporal attention mechanism with τ=1 (a lower temperature value). (b) shows the results of using Cross-Frame Intensity (CFI) scaling of the attention map. (c) shows the results obtained with the proposed Enhance-A-Video method, which combines aspects of (a) and (b) for a more balanced approach. The differences in the attention maps and the visual quality of the generated videos clearly illustrate the superior performance of Enhance-A-Video.
read the caption
Figure 13: Temporal attention difference maps and corresponding generated videos comparing three temperature enhancement methods. (a) Temperature Attention Scaling τ=1𝜏1\tau=1italic_τ = 1. (b) CFI Attention Scaling. (c) Enhance-A-Video Method.

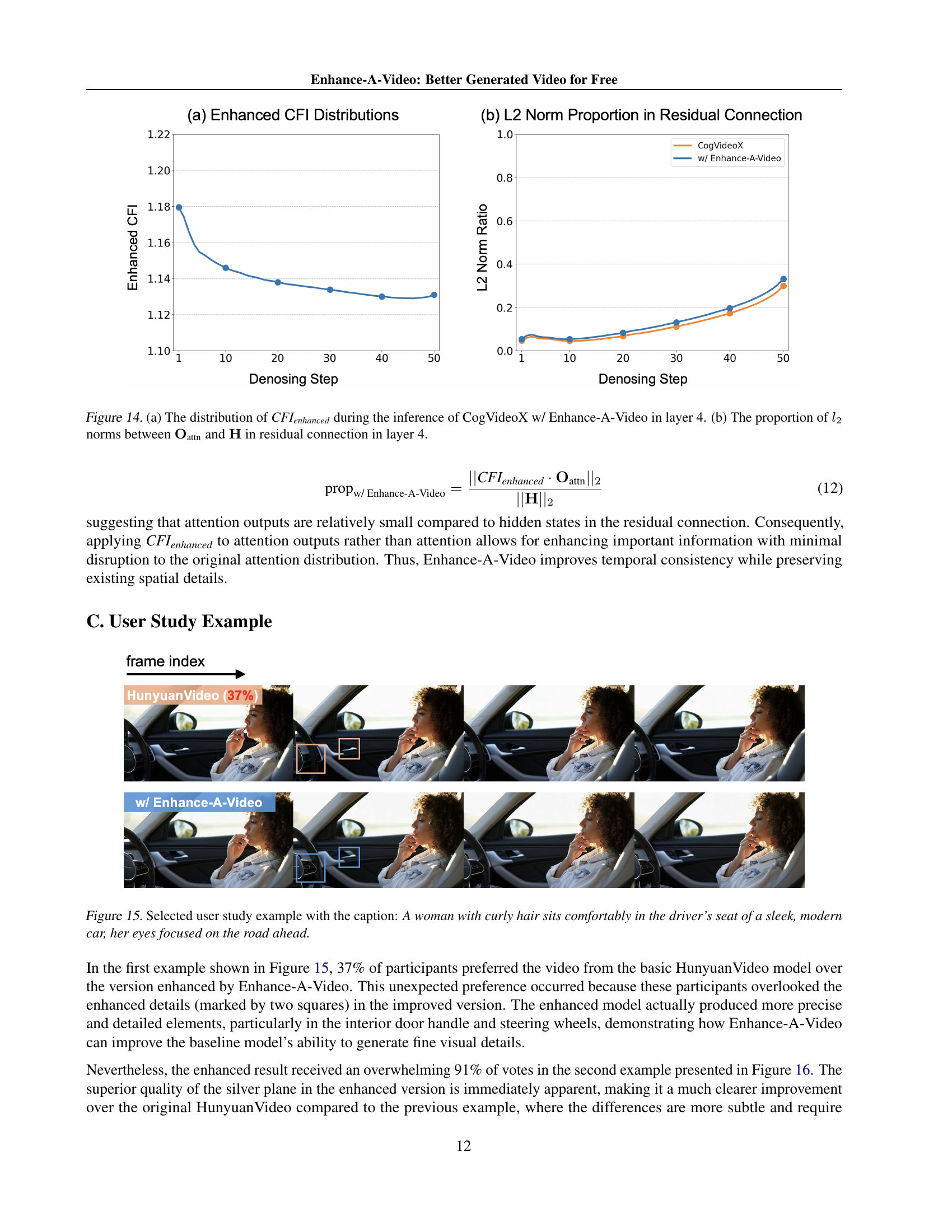
🔼 Figure 14 presents a dual analysis of the Enhance-A-Video model’s impact on the temporal attention mechanism within a specific layer (layer 4) of the CogVideoX video generation model. Panel (a) displays the distribution of the enhanced cross-frame intensity (CFIenhanced) across different denoising steps during the video generation process. This shows how the model modulates the strength of cross-frame connections over time. Panel (b) illustrates the relative magnitudes (proportions) of the L2 norms of the enhanced temporal attention output (Oattn) compared to the hidden states (H) within the residual connection of the network. This comparison helps to understand the influence of the enhanced cross-frame information on the overall network dynamics.
read the caption
Figure 14: (a) The distribution of CFIenhancedsubscriptCFIenhanced\textit{CFI}_{\textit{enhanced}}CFI start_POSTSUBSCRIPT enhanced end_POSTSUBSCRIPT during the inference of CogVideoX w/ Enhance-A-Video in layer 4. (b) The proportion of l2subscript𝑙2l_{2}italic_l start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT norms between 𝐎attnsubscript𝐎attn\mathbf{O}_{\text{attn}}bold_O start_POSTSUBSCRIPT attn end_POSTSUBSCRIPT and 𝐇𝐇\mathbf{H}bold_H in residual connection in layer 4.

🔼 A woman with curly hair is sitting in the driver’s seat of a modern car, her eyes focused on the road. The image shows a detail comparison of the car’s interior between the original HunyuanVideo model and an enhanced version using Enhance-A-Video. The enhanced version shows improvements in visual details and clarity.
read the caption
Figure 15: Selected user study example with the caption: A woman with curly hair sits comfortably in the driver’s seat of a sleek, modern car, her eyes focused on the road ahead.

🔼 A sleek, silver airplane gracefully soars through a vast, azure sky. Sunlight glints off its polished surface, creating a dazzling spectacle against the endless blue expanse. As it glides effortlessly, the contrail forms a delicate, white ribbon trailing behind, adding to the scene’s ethereal beauty. The aircraft’s engines emit a soft, distant hum, blending harmoniously with the serene atmosphere. Below, the earth’s curvature is faintly visible, enhancing the sense of altitude and freedom. The scene captures the essence of flight, evoking a feeling of wonder and exploration.
read the caption
Figure 16: Selected user study example with the caption: A sleek, silver airplane soars gracefully through a vast, azure sky, its wings cutting through wispy, cotton-like clouds.

🔼 This figure shows a comparison of video generation results between the baseline Open-Sora-Plan model and the same model enhanced with Enhance-A-Video. Two example video clips are shown, one of plants with blooming flowers and another of a waterfall in a mountain setting. The enhancements showcase how Enhance-A-Video improves the visual detail and clarity of the generated videos, leading to more natural and visually appealing results.
read the caption
Figure 17: Qualitative results of Enhance-A-Video on Open-Sora-Plan.

🔼 A sleek, silver airplane gracefully soars through a vast, azure sky, its wings cutting through wispy clouds. Sunlight glints off its polished surface, creating a dazzling spectacle against the endless blue expanse. The airplane glides effortlessly, leaving a delicate, white contrail trailing behind, enhancing the scene’s ethereal beauty. A soft, distant hum from the aircraft’s engines blends harmoniously with the serene atmosphere. From the plane’s altitude, the earth’s curvature is faintly visible, amplifying the sense of altitude and freedom. This scene captures the essence of flight, evoking a feeling of wonder and exploration. This figure compares the video quality of this scene generated by the HunyuanVideo model and the same scene enhanced by Enhance-A-Video.
read the caption
Figure 18: Comparison of video quality between HunyuanVideo and w/ Enhance-A-Video on a caption: A sleek, silver airplane soars gracefully through a vast, azure sky, its wings cutting through wispy, cotton-like clouds. The sun glints off its polished surface, creating a dazzling spectacle against the endless blue expanse. As it glides effortlessly, the contrail forms a delicate, white ribbon trailing behind, adding to the scene’s ethereal beauty. The aircraft’s engines emit a soft, distant hum, blending harmoniously with the serene atmosphere. Below, the earth’s curvature is faintly visible, enhancing the sense of altitude and freedom. The scene captures the essence of flight, evoking a feeling of wonder and exploration.
Full paper#