TL;DR#
Generating high-quality videos quickly remains a challenge. Existing methods are computationally expensive and time-consuming. Current video generation models often compromise on quality to reduce processing time. Also, existing diffusion models need hundreds or thousands of steps to produce a video, leading to high computational costs.
This paper introduces Magic141, which addresses these issues. It factorizes the video generation process, making it more efficient. It uses several optimization techniques, such as multi-modal prior condition injection and parameter sparsification, to significantly reduce computational costs and memory usage during training and inference. The result is a model that generates a minute-long video within one minute maintaining high quality. This is achieved by using a two-stage process and a variety of optimizations techniques.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to significantly speed up video generation, a crucial task in various applications. The proposed method’s efficiency and quality improvements are relevant to researchers in computer vision, machine learning, and multimedia. It paves the way for real-time video generation and broadens the scope of applications for this technology.
Visual Insights#

🔼 This figure displays a bar chart and a line chart comparing the performance and efficiency of Magic 1-For-1 against several other open-source text-to-image-to-video (TI2V) models on the General VBench benchmark. The bar chart shows that Magic 1-For-1 outperforms the other models across multiple performance metrics (motion smoothness, dynamic degree, subject consistency, etc.). The line chart illustrates Magic 1-For-1’s superior efficiency, requiring significantly fewer function evaluations to achieve comparable or better performance than its counterparts. The results demonstrate Magic 1-For-1’s strong performance and efficiency in generating videos.
read the caption
Figure 1: The comparative experimental results on General VBench highlight the strong performance of Magic 1-For-1. Our model surpasses other open-source TI2V models, including CogVideoX-I2V-SAT, I2Vgen-XL, SEINE-512x320, VideoCrafter-I2V, and SVD-XT-1.0, in terms of both performance and efficiency.
| #Steps | Approach | i2v | Subject | Motion | Dynamic | Aesthetic | Imaging | Temporal | Average |
| Subject (↑) | Consistency (↑) | Smoothness (↑) | Degree (↑) | Quality (↑) | Quality (↑) | Flickering (↑) | (↑) | ||
| 56-step | Euler (baseline) | 0.9804 | 0.9603 | 0.9954 | 0.2103 | 0.5884 | 0.6896 | 0.9937 | 0.7740 |
| 28-step | Euler (baseline) | 0.9274 | 0.9397 | 0.9953 | 0.2448 | 0.5687 | 0.6671 | 0.9935 | 0.7623 |
| 16-step | Euler (baseline) | 0.9750 | 0.9366 | 0.9957 | 0.1241 | 0.5590 | 0.6238 | 0.9946 | 0.7441 |
| 8-step | Euler (baseline) | 0.9787 | 0.9000 | 0.9962 | 0.0068 | 0.4994 | 0.5013 | 0.9961 | 0.6969 |
| DMD2 | 0.9677 | 0.9634 | 0.9945 | 0.3207 | 0.5993 | 0.7125 | 0.9921 | 0.7928 | |
| 4-step | Euler (baseline) | 0.9803 | 0.8593 | 0.9965 | 0.0034 | 0.4440 | 0.3693 | 0.9972 | 0.6642 |
| DMD2 | 0.9812 | 0.9762 | 0.9934 | 0.4123 | 0.6123 | 0.7234 | 0.9950 | 0.8134 |
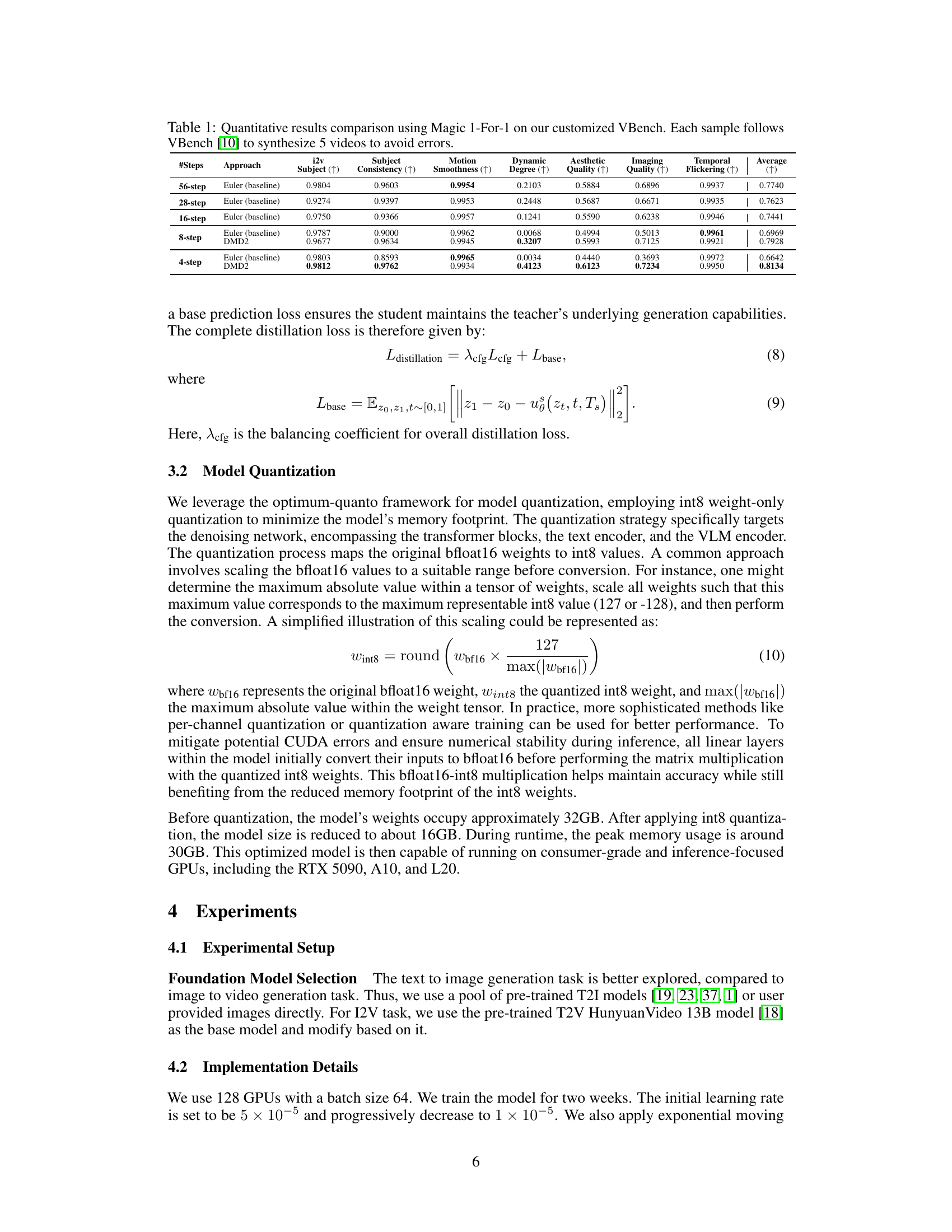
🔼 This table presents a quantitative comparison of different video generation approaches using a customized version of the VBench benchmark. The comparison focuses on several key metrics, including subject consistency, motion smoothness, and overall visual quality. Each method was used to generate five videos for each sample to ensure robustness and minimize the impact of random variations. The table allows readers to compare various methods across the VBench metrics to assess their relative performance in terms of both efficiency and video quality.
read the caption
Table 1: Quantitative results comparison using Magic 1-For-1 on our customized VBench. Each sample follows VBench [10] to synthesize 5 videos to avoid errors.
In-depth insights#
I2V Step Distillation#
I2V step distillation, within the context of efficient video generation, focuses on accelerating the image-to-video (I2V) process by significantly reducing the number of diffusion steps. This is crucial because standard diffusion models require numerous steps for high-quality video synthesis, resulting in high computational costs and slow inference times. The core idea revolves around distilling a complex, multi-step I2V model into a simpler, few-step model that maintains comparable video quality. This distillation process often involves training a student model (the few-step model) to mimic the output of a teacher model (the multi-step model), leveraging techniques like knowledge distillation or adversarial training. Key advantages include faster generation speeds, lower memory requirements, and the potential for deployment on resource-constrained devices. However, challenges exist in preserving the quality of the generated videos during the distillation process, as simplifying the model can lead to artifacts, reduced motion fidelity, or loss of detail. Therefore, successful I2V step distillation relies on carefully designed architectures, optimization strategies, and effective loss functions to balance computational efficiency with the preservation of visual quality.
Multimodal Prior#
The concept of a “Multimodal Prior” in the context of video generation using diffusion models is a powerful idea. It leverages the inherent synergy between different data modalities, such as text and images, to improve the quality and efficiency of the generation process. By incorporating both textual descriptions and visual input (e.g., a reference image) as priors, the model benefits from a richer, more comprehensive understanding of the desired output. This reduces ambiguity and guides the generation process more effectively, potentially leading to more coherent and higher-quality videos. The effectiveness of this approach stems from the ability to regularize the model’s output by explicitly constraining it with multi-modal information. This constraint is especially beneficial for diffusion models, which can sometimes struggle with generating temporally consistent and semantically meaningful content. The key advantages include faster convergence during training, improved sample quality, and potentially reduced inference times. Efficient implementation of this concept necessitates careful consideration of how to fuse these diverse data types to avoid conflicts or negative interference. Furthermore, the choice of architecture, particularly how the text and image encoders are integrated, will directly impact the effectiveness of the multimodal prior.
DMD2 & CFG#
The core of the proposed method lies in its dual distillation approach, combining DMD2 (Distribution Matching Distillation 2) and CFG (Classifier-Free Diffusion Guidance) distillation. DMD2 accelerates the training process by cleverly aligning the distributions of a simplified, faster model with a more complex, high-quality model. This is achieved through a coordinated training of three models: a fast generator, a real data distribution approximator, and a fake data distribution approximator, improving convergence speed. CFG distillation further enhances efficiency by distilling the knowledge of CFG into the fast generator, eliminating the need for computationally expensive CFG calculations during inference. The synergistic combination of DMD2 and CFG distillation represents a significant advancement, allowing for high-quality video generation at a fraction of the computational cost compared to traditional methods. This approach makes generating high-quality videos significantly faster and more accessible.
Quantization#
The research paper section on “Quantization” focuses on optimizing model efficiency by reducing memory consumption. The authors employ int8 weight-only quantization, a technique that reduces the precision of model weights from bfloat16 to int8, thereby decreasing memory usage. This approach is applied specifically to the denoising network, including transformer blocks and encoders, and involves carefully scaling weights to maintain numerical stability during inference. The results demonstrate a significant reduction in model size, from approximately 32GB to 16GB, enabling the model to run on consumer-grade GPUs. This optimization is crucial for deploying the model on resource-constrained devices, a key factor in making the technology widely accessible. The methodology suggests a potential trade-off between reduced precision and model performance; the authors mitigate this through specific techniques that maintain the necessary accuracy for the model to function effectively. The impact of this optimization is significant for the model’s accessibility and usability.
Future Work#
Future work for this efficient video generation model, Magic 1-For-1, could significantly improve its capabilities and applicability. Extending the model’s capacity to handle longer videos beyond the current one-minute limit is crucial for real-world applications. This could involve exploring more sophisticated temporal modeling techniques or investigating alternative architectures better suited for longer sequences. Addressing the current dataset bias towards human-centric and movie-style videos is also vital. Training on a more diverse and balanced dataset will significantly enhance the model’s generalization ability and reduce biases in generated video content. Improving the model’s performance on low-resolution videos and challenging visual effects such as complex motions and high-resolution details represents another promising avenue of research. This requires further refinement of the diffusion steps or exploration of alternative approaches that can balance computational efficiency with the high-quality results desired. Finally, exploring different ways to incorporate user control and feedback directly into the generative process will add valuable functionality. This could involve methods for user-guided video editing or interactive steering of the generation process to better reflect user intent.
More visual insights#
More on figures

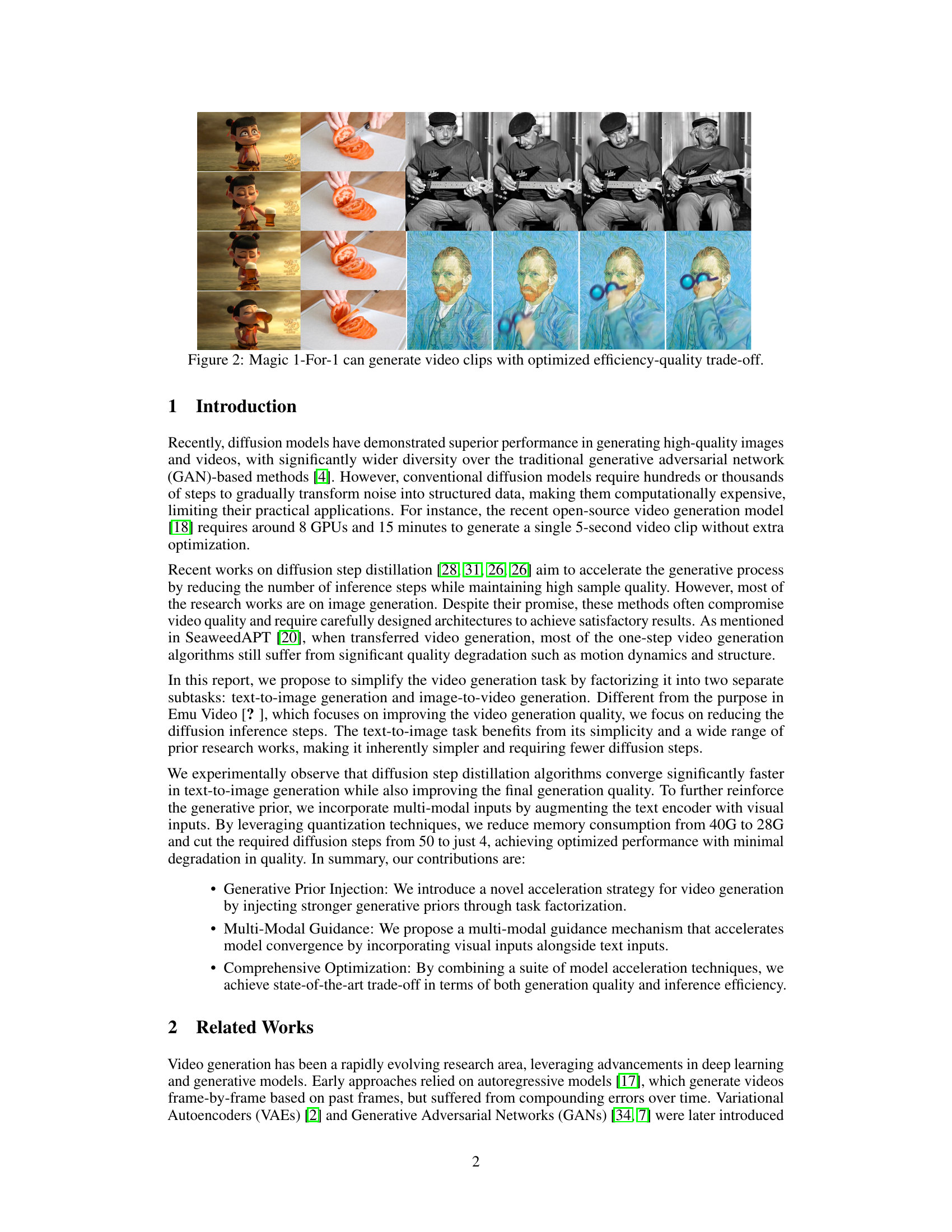
🔼 Figure 2 showcases the video generation capabilities of Magic 1-For-1. It presents several video clips generated by the model, highlighting its ability to produce high-quality, one-minute-long videos within a minute. The samples demonstrate various scenes and styles, illustrating the model’s capacity for diverse video generation. The figure visually represents the optimized balance achieved by Magic 1-For-1 between the efficiency of video generation and the quality of the produced videos.
read the caption
Figure 2: Magic 1-For-1 can generate video clips with optimized efficiency-quality trade-off.

🔼 Figure 3 provides a detailed illustration of the Magic 1-For-1 model’s architecture, focusing on the image prior injection and multi-modal guidance mechanisms. The diagram showcases how text and image inputs are processed through separate but interacting pathways. The text input is processed using a CLIP-Large and LLAMA model, generating textual embeddings which inform the video generation. Simultaneously, a reference image undergoes processing via a CLIP-Large model, yielding visual embeddings that complement and guide the textual information. The text and visual embeddings are then concatenated and fed into a dual-stream DiT block, where video generation occurs. This integrated approach ensures the generated video aligns with both the textual description and initial image. The dual-stream architecture uses the image as a prior, enhancing the generation efficiency and quality.
read the caption
Figure 3: Overall Architecture of Magic 1-For-1.

🔼 Figure 4 illustrates the model acceleration techniques used in Magic 1-For-1. It highlights the two main methods: DMD2 (Distribution Matching Distillation 2), a step distillation method to speed up the generation process by reducing the number of diffusion steps, and CFG (Classifier-Free Guidance) distillation, which accelerates inference by distilling the guidance process into a more efficient form. The diagram shows how these techniques are integrated, starting with a pre-trained Magic 1-For-1 model which is then modified and used within the DMD2 framework and CFG distillation. The result is a faster and more efficient video generation pipeline.
read the caption
Figure 4: The overview of model acceleration techniques, including DMD2 and CFG distillation.

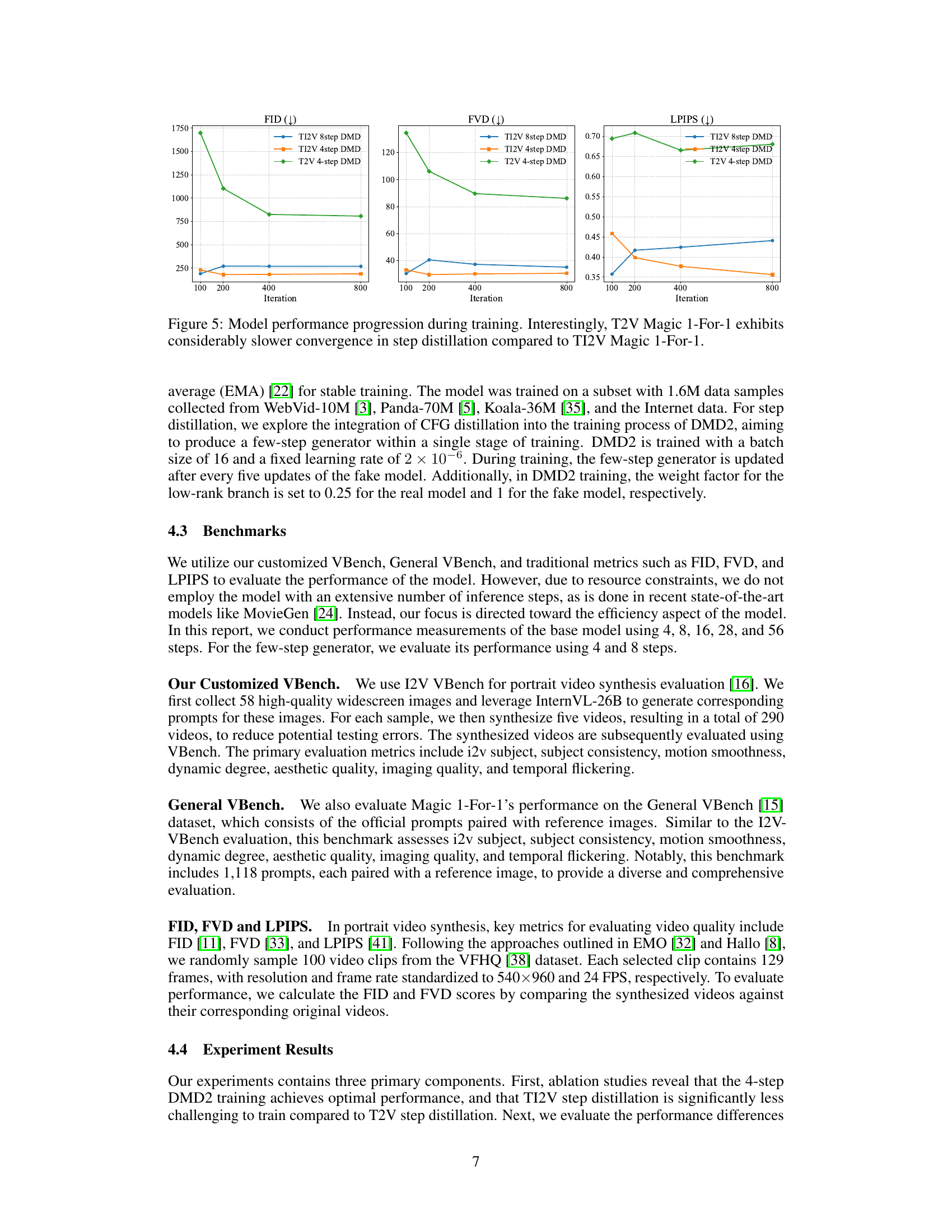
🔼 Figure 5 presents the training curves for different metrics (FVD, LPIPS, and FID) during the step distillation process for both text-to-video (T2V) and text-to-image-to-video (TI2V) models using Magic 1-For-1. The plots illustrate the convergence speed of the models. The key takeaway is that the T2V model shows substantially slower convergence than its TI2V counterpart. This observation highlights the impact of task factorization (breaking down the text-to-video task into text-to-image and image-to-video stages) on the efficiency of the step distillation process, making TI2V significantly more efficient to train.
read the caption
Figure 5: Model performance progression during training. Interestingly, T2V Magic 1-For-1 exhibits considerably slower convergence in step distillation compared to TI2V Magic 1-For-1.

🔼 Figure 6 presents a qualitative comparison of video clips generated by Magic 1-For-1 and other state-of-the-art open-source image-to-video generation models. The figure visually showcases the differences in video quality and style across different models, allowing for a direct comparison of their capabilities in generating coherent and visually appealing video content from a given image. This comparison highlights Magic 1-For-1’s strengths in terms of visual clarity, motion smoothness and overall video quality.
read the caption
Figure 6: Qualitative comparison of Magic 1-For-1 with recent state-of-the-art open source image-to-video generation models.
Full paper#