TL;DR#
Reasoning models, a new type of generative AI, improve performance on complex tasks by generating a detailed chain of thought before producing an answer. However, such models, especially those capable of generating reasoning traces in low-resource languages, are limited. This scarcity of resources hinders research in this field.
This research paper introduces Typhoon T1, an open-source Thai reasoning model that aims to address these issues. It details a cost-effective methodology using supervised fine-tuning and open datasets, eliminating the need for resource-intensive reinforcement learning. The study includes insights into data generation and training, as well as the release of the dataset and model weights. The researchers demonstrate the impact of several factors on performance (thinking format, training data size and mixture, and the inclusion of safety-related data) and found that “structured thinking” along with a well-balanced dataset leads to the best results.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Typhoon T1, the first open-source Thai reasoning model. This addresses the scarcity of such resources in low-resource languages, fostering further research and development. The open-source nature promotes collaboration and accelerates progress in multilingual reasoning models, aligning with current trends towards greater transparency and accessibility in AI research. The detailed methodology and analysis contribute valuable insights for researchers working with both high and low resource languages.
Visual Insights#

🔼 This figure illustrates the data processing pipeline for creating a Thai reasoning model. The top panel shows the transformation and refinement stages used to convert existing datasets into the ’long-thinking’ format required for training. The bottom-left panel details the training process for the Typhoon T model, which uses the structured long-thinking format. The bottom-right panel shows how the bilingual Typhoon T1 model is trained using the structured data generated and both English and Thai languages.
read the caption
Figure 1: Top: The transformation-and-refinement pipeline used for long-thinking data generation described in Sections 2.2.1 and 2.2.2. Bottom-Left: The structured long-thinking (the best thinking format) training pipeline for Typhoon T, as described in Section 3.1. Bottom-Right: The bilingual English-Thai Typhoon T1 model training pipeline detailed in Section 3.4.
| Model | Datasets | Data Recipe | Training Recipe | Model Weights |
|---|---|---|---|---|
| OpenAI’s o-series | ✗ | ✗ | ✗ | ✗ |
| Google’s Gemini 2.0 Flash Thinking | ✗ | ✗ | ✗ | ✗ |
| Qwen’s QwQ | ✗ | ✗ | ✗ | ✓ |
| DeepSeek R1 | ✗ | ✗ | P | ✓ |
| Typhoon T1 | ✓ | ✓ | ✓ | ✓ |
🔼 This table compares the openness of several popular reasoning models. Openness is assessed across four key aspects: the availability of the datasets used to train the models, the transparency of the data processing steps, the details of the training methodology employed, and the accessibility of the trained model weights. The table uses checkmarks to indicate full disclosure, ‘P’ to indicate partial disclosure, and ‘X’ to indicate a lack of disclosure for each aspect. The comparison highlights Typhoon T1 as the only model offering complete openness across all four categories, including a detailed description of its data preparation steps.
read the caption
Table 1: A comparison of openness among popular reasoning models, focusing on dataset availability, data processing transparency, training methodology, and model accessibility. P denotes partial details. Typhoon T1 is the only model providing full openness across all categories, including its data recipe.
In-depth insights#
Open Thai Reasoning#
The concept of “Open Thai Reasoning” presents a compelling vision for advancing natural language processing (NLP) research and applications in the Thai language. Openness is crucial, fostering collaboration and reproducibility by making models, datasets, and methodologies publicly accessible. This contrasts with proprietary models, limiting progress due to restricted access. Focusing on reasoning goes beyond simple text generation; it targets complex tasks demanding logical steps and inference. This is particularly important in low-resource languages like Thai, where data scarcity poses significant challenges. The integration of Thai as the target language directly addresses the need for NLP tools tailored to specific linguistic contexts. Thai’s unique grammatical structure and nuances require specialized models. Developing an open Thai reasoning model is therefore a significant step toward bridging the gap in NLP capabilities for the Thai-speaking population, promoting technological advancements, and benefiting the wider research community.
SFT vs. RL Approach#
The choice between supervised fine-tuning (SFT) and reinforcement learning (RL) for training reasoning models presents a critical design decision. SFT offers a more straightforward and cost-effective approach, leveraging readily available labeled datasets for training. This contrasts with RL, which necessitates the design and implementation of a reward system to guide the model’s learning process. While RL can potentially achieve higher performance, particularly when aiming for nuanced reasoning behaviors, it often requires significant computational resources and expertise, posing considerable challenges, especially in low-resource settings. The inherent instability of RL algorithms also adds complexity. Therefore, the selection hinges on a trade-off between resource constraints, available expertise, and desired performance levels. For researchers with limited resources or specialized expertise, SFT provides a more practical starting point, allowing for easier replication and fostering wider collaboration. The selection of SFT or RL ultimately depends on the specific goals and resource availability of the research endeavor.
Structured Thinking#
The concept of “Structured Thinking” presented in the research paper offers a novel approach to enhance the reasoning capabilities of large language models (LLMs). By introducing a hierarchical structure using XML tags, the authors aim to guide the LLM’s thought process in a more organized and deliberate manner. This structured format, unlike unstructured or semi-structured approaches, encourages a step-by-step reasoning process, akin to human problem-solving. Key features include explicit separation of planning, thought steps, scratchpad notes (for intermediate calculations or observations), and summaries for each step. This approach facilitates clear separation of thoughts, promotes self-correction through intermediate summaries, and improves traceability. The effectiveness of structured thinking is empirically validated through experiments, demonstrating superior performance compared to unstructured and semi-structured counterparts, particularly in mathematical and coding tasks. The overall impact suggests that imposing a structured format on LLM reasoning significantly improves both the accuracy and efficiency of the model’s responses.
Data Quantity & Quality#
The optimal balance between data quantity and quality is crucial for effective model training. Insufficient data, regardless of quality, leads to underfitting and poor generalization. Conversely, excessive data may introduce noise or redundant information, hindering model performance. High-quality data, characterized by accuracy, completeness, and relevance, is paramount, even with limited quantity. Careful data curation, including cleaning and preprocessing, is essential to enhance quality. A well-defined data strategy that considers both quantity and quality, potentially through techniques like data augmentation or careful sampling, is vital for achieving optimal model performance and generalization.
Multilingual Reasoning#
Multilingual reasoning presents exciting challenges and opportunities in AI. Developing models capable of reasoning across multiple languages requires addressing significant linguistic and cultural differences. A key consideration is the availability of high-quality, diverse datasets for training, as many languages lack the extensive resources found for English. The choice of architecture and training methodology also greatly impacts performance. Approaches might involve multilingual fine-tuning of existing models or training specialized multilingual reasoning models from scratch. Evaluation is particularly crucial, as benchmarks need to account for variations in linguistic complexity and cultural nuances across languages. Research efforts should focus on developing robust evaluation metrics and standardized benchmarks that capture the true multilingual reasoning capabilities of models. Ultimately, successful multilingual reasoning models will be a significant step toward achieving truly inclusive and globally accessible AI systems. The open-sourcing of models and datasets, as demonstrated in the example of Typhoon T1, is essential to foster collaborative development and accelerate progress in this challenging field.
More visual insights#
More on figures

🔼 This figure illustrates three different formats for representing the reasoning process of a large language model (LLM). Panel (a) shows unstructured thinking, where the LLM’s reasoning and final answer are presented as a single, continuous text stream without any explicit separation or structure. Panel (b) demonstrates semi-structured thinking, which adds simple XML tags such as
and to delineate the reasoning steps from the final answer. Panel (c) shows structured thinking, a more advanced format that utilizes additional XML tags within the section to further organize and structure the LLM’s reasoning process, helping to clarify the intermediate steps and sub-goals involved in arriving at the final answer. This structured format is designed to improve the clarity and organization of the LLM’s thinking. read the caption
Figure 2: Differences between three thinking formats: (a) Unstructured thinking, where no XML structural tags are included; (b) Semi-structured thinking, which is similar to unstructured thinking but addsand tags to separate thoughts and responses; (c) Structured thinking, which introduces additional XML tags for structural purposes in the thoughts section.

🔼 This figure presents the results of an experiment assessing the impact of training data size on the performance of a reasoning model. Multiple datasets were used, and varying percentages of the training data (5%, 10%, 25%, 50%, 75%, and 100%) were used to train separate models. The results show that for most datasets, using more than 75% of the training data did not significantly improve performance, and in some cases even led to performance degradation. The exception is the GSM8K dataset, which demonstrated a consistent performance improvement as more training data was used.
read the caption
Figure 3: Increasing the proportion of the training set beyond 75% results in performance degradation for some datasets, while GSM8K generally shows a trend of performance improvement with the proportion.

🔼 Figure 4 presents a comparative analysis of the performance of three different models: Typhoon T1-EN, Typhoon T1, and the baseline Typhoon 2 3B Instruct model, across six distinct evaluation benchmarks. It visually represents the relative performance of each model on each benchmark, enabling easy comparison of their strengths and weaknesses. The benchmarks likely represent a variety of tasks to assess the models’ reasoning capabilities comprehensively.
read the caption
Figure 4: Final performance comparison of Typhoon T1-EN and Typhoon T1 against the baseline Typhoon T1 3B Instruct model across six evaluation benchmarks.

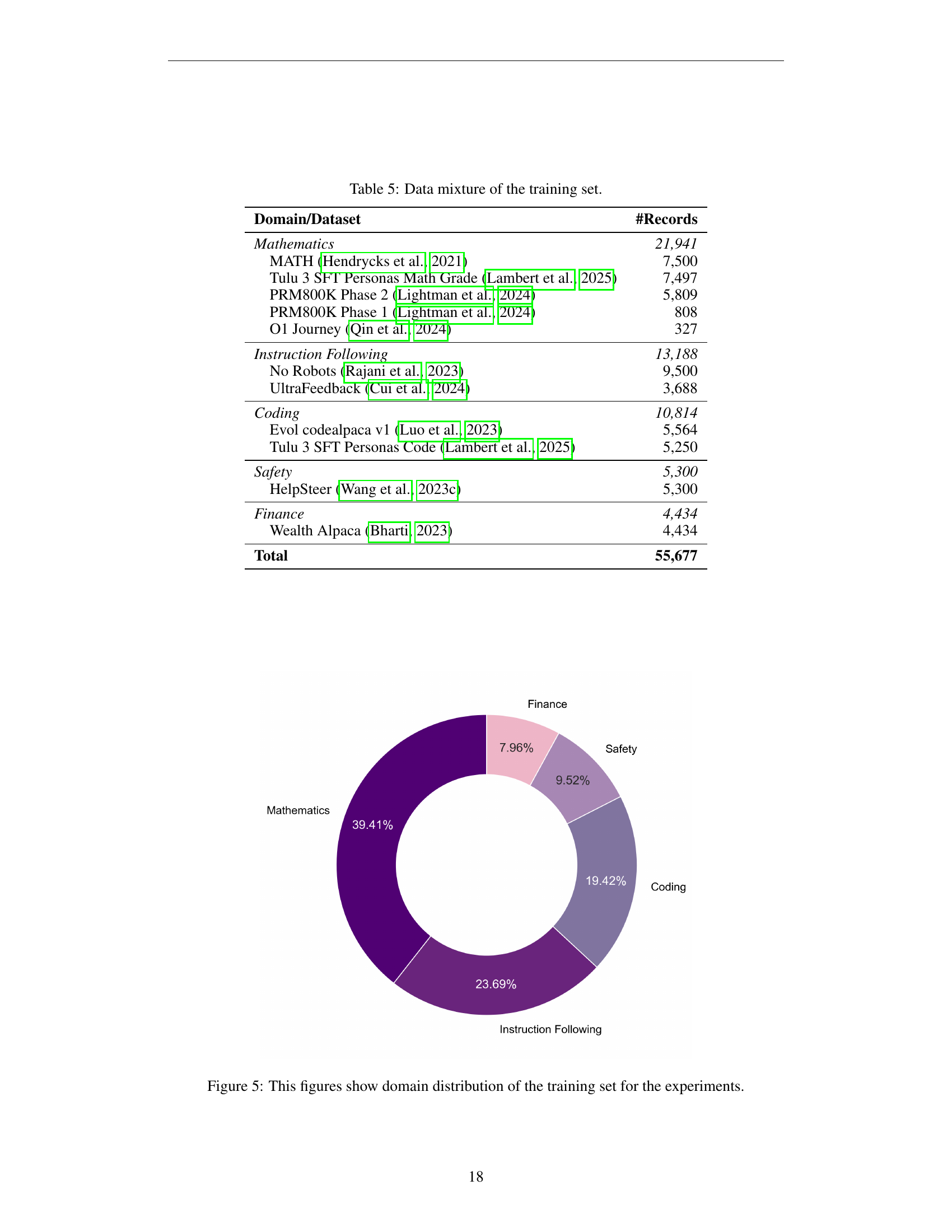
🔼 This pie chart visualizes the distribution of the training data across five different domains used in the experiments described in the paper. Each slice of the pie represents a domain, and its size corresponds to the proportion of data samples from that domain within the overall training dataset. The domains are: Mathematics, Instruction Following, Coding, Safety, and Finance.
read the caption
Figure 5: This figures show domain distribution of the training set for the experiments.

🔼 This figure presents a side-by-side comparison of the reasoning traces generated by two models: Typhoon T1 and Typhoon T1-EN. Typhoon T1, trained with Thai-translated data, produces a reasoning trace in Thai, showcasing its ability to generate reasoning steps in a low-resource language. In contrast, Typhoon T1-EN, trained without Thai data, provides a reasoning trace in English. The comparison highlights the impact of training data on the model’s ability to perform reasoning and generate traces in different languages. Both models answer the same question, allowing for a direct comparison of their respective reasoning processes and language usage.
read the caption
Figure 6: This figure shows Typhoon T1’s Thai thinking trace and Typhoon T1-EN’s English thinking trace.
More on tables
| Model | GSM8K | HumanEval+ | IFEval | GPQA | MMLU Pro | ThaiExam |
|---|---|---|---|---|---|---|
| Typhoon 2 | ||||||
| Zero-Shot | 57.32 | 63.51 | 69.32 | 25.00 | 26.61 | 32.69 |
| Zero-Shot CoT | 53.83 | 0.00 | 68.95 | 25.45 | 23.36 | 33.27 |
| SFT | 20.62 | 46.24 | 17.74 | 16.74 | 13.96 | 15.65 |
| Typhoon T | ||||||
| Unstructured | 59.82 | 67.88 | 34.01 | 24.78 | 20.44 | 21.36 |
| Semi-structured | 57.24 | 72.87 | 55.27 | 27.68 | 19.46 | 21.92 |
| Structured | 62.02 | 69.76 | 53.60 | 27.23 | 23.56 | 22.84 |
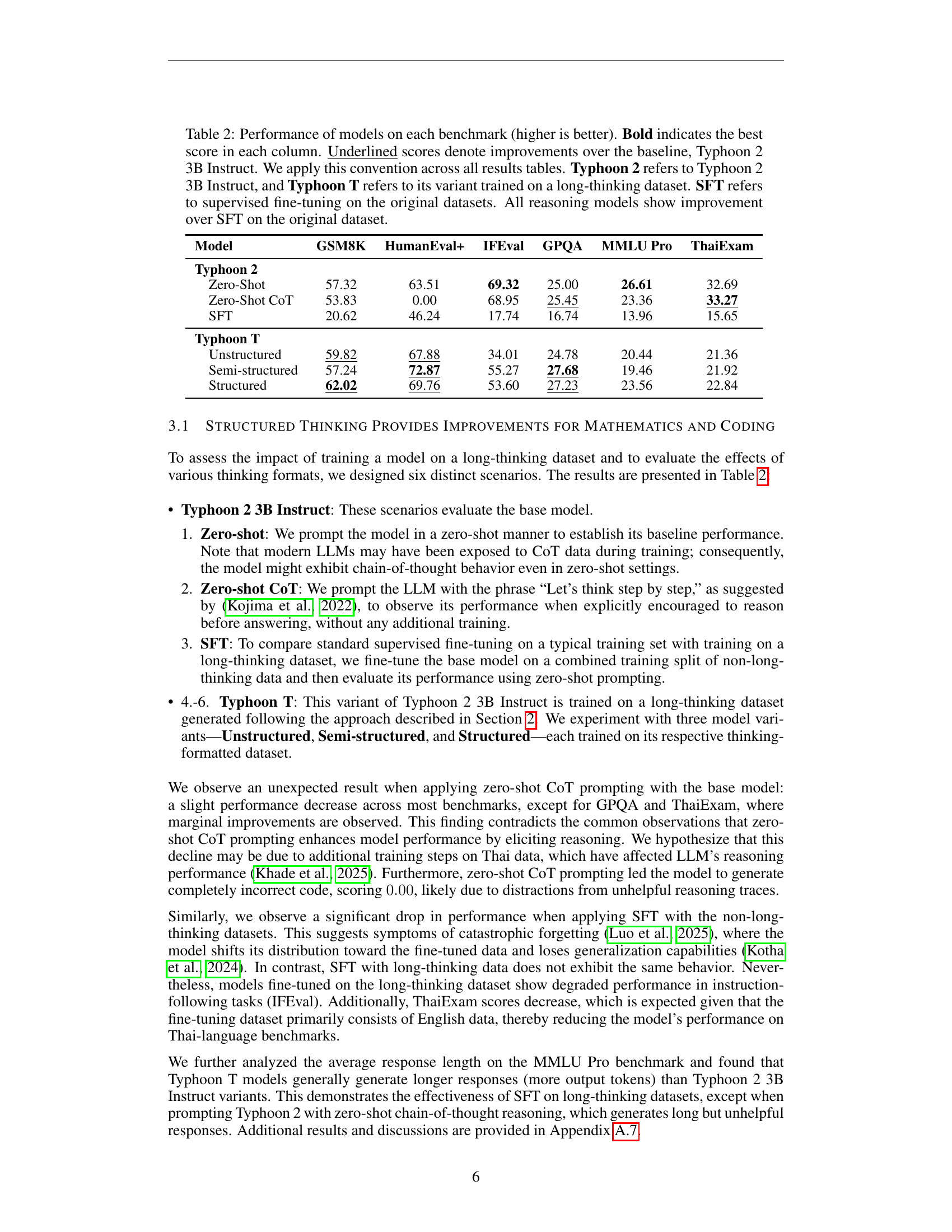
🔼 This table compares the performance of different language models across six benchmarks: GSM8K, HumanEval+, IFEval, GPQA, MMLU Pro, and ThaiExam. The models compared include the baseline Typhoon 2 3B Instruct (Typhoon 2), variants trained with different thinking methods (zero-shot, zero-shot CoT, and supervised fine-tuning, SFT), and the Typhoon T model trained on long-thinking datasets. Higher scores indicate better performance. Bold values highlight the best score for each benchmark. Underlined scores show improvements compared to the Typhoon 2 3B Instruct baseline. The results demonstrate that all reasoning models perform better than SFT on the original dataset.
read the caption
Table 2: Performance of models on each benchmark (higher is better). Bold indicates the best score in each column. Underlined scores denote improvements over the baseline, Typhoon 2 3B Instruct. We apply this convention across all results tables. Typhoon 2 refers to Typhoon 2 3B Instruct, and Typhoon T refers to its variant trained on a long-thinking dataset. SFT refers to supervised fine-tuning on the original datasets. All reasoning models show improvement over SFT on the original dataset.
| Model | GSM8K | HumanEval+ | IFEval | GPQA | MMLU Pro | ThaiExam |
|---|---|---|---|---|---|---|
| Typhoon T1-EN | 62.09 | 70.60 | 49.54 | 30.80 | 27.39 | 21.71 |
| + 1.5k, CSFT | 41.39 | 65.79 | 33.83 | 23.66 | 4.30 | 21.20 |
| + 1.5k | 60.12 | 67.90 | 51.76 | 29.91 | 19.32 | 23.56 |
| + 1k | 61.94 | 66.77 | 50.09 | 24.55 | 23.48 | 21.57 |
| + 0.5k | 60.88 | 68.24 | 49.72 | 25.45 | 23.05 | 22.62 |
🔼 This table presents the performance of different model variants on various benchmark datasets. The models were trained with varying amounts of additional data, including a baseline model (Typhoon T1-EN) and variants trained with an additional 1.5k samples and with continual supervised fine-tuning (CSFT). The results show the impact of the additional training data on the model’s performance across several reasoning tasks, revealing that adding 1.5k samples improved scores on instruction following (IFEval) and the Thai language exam (ThaiExam). Continual SFT, however, led to a significant reduction in overall performance.
read the caption
Table 3: Performance of model variants on various benchmarks, evaluating the impact of additional training data. CSFT refers to continual SFT. Adding 1.5k samples improves IFEval and ThaiExam scores, while CSFT significantly reduces overall performance.
| Model | GSM8K | HumanEval+ | IFEval | GPQA | MMLU Pro | ThaiExam |
|---|---|---|---|---|---|---|
| Typhoon T1 | 60.12 | 67.90 | 51.76 | 29.91 | 19.32 | 23.56 |
| + EN | 46.17 | 0.00 | 48.98 | 26.56 | 16.55 | 25.31 |
| + TH | 48.29 | 0.00 | 44.73 | 25.67 | 16.05 | 24.66 |
🔼 This table presents the results of an experiment where the multilingual reasoning model Typhoon T1 was constrained to reason in either English or Thai, and its performance was compared against when it was allowed to choose its own reasoning language. The results show that constraining the model to a specific language (either English or Thai) leads to a decrease in overall accuracy across various benchmarks. Although English-forced reasoning performed slightly better than Thai-forced reasoning, allowing the model to select its own language resulted in the highest accuracy, demonstrating the importance of flexibility in multilingual reasoning.
read the caption
Table 4: EN denotes forced reasoning in English, and TH denotes forced reasoning in Thai. Constraining Typhoon T1 to reason in a specific language degrades overall accuracy. English reasoning is slightly more effective than Thai reasoning across most benchmarks. However, allowing the model to choose its own thinking language yields the best performance.
| Domain/Dataset | #Records |
|---|---|
| Mathematics | 21,941 |
| MATH (Hendrycks et al., 2021) | 7,500 |
| Tulu 3 SFT Personas Math Grade (Lambert et al., 2025) | 7,497 |
| PRM800K Phase 2 (Lightman et al., 2024) | 5,809 |
| PRM800K Phase 1 (Lightman et al., 2024) | 808 |
| O1 Journey (Qin et al., 2024) | 327 |
| Instruction Following | 13,188 |
| No Robots (Rajani et al., 2023) | 9,500 |
| UltraFeedback (Cui et al., 2024) | 3,688 |
| Coding | 10,814 |
| Evol codealpaca v1 (Luo et al., 2023) | 5,564 |
| Tulu 3 SFT Personas Code (Lambert et al., 2025) | 5,250 |
| Safety | 5,300 |
| HelpSteer (Wang et al., 2023c) | 5,300 |
| Finance | 4,434 |
| Wealth Alpaca (Bharti, 2023) | 4,434 |
| Total | 55,677 |
🔼 Table 5 details the composition of the training dataset used to develop the Typhoon T1 reasoning model. It breaks down the number of records from each dataset used across five different domains: mathematics, instruction following, coding, safety, and finance. The table provides context on the diversity of tasks and data sources used for model training, highlighting the quantity of data drawn from each source dataset within each domain.
read the caption
Table 5: Data mixture of the training set.
| Model | GSM8K | GPQA | MMLU Pro | ThaiExam |
|---|---|---|---|---|
| Typhoon 2 | ||||
| Zero-shot | 104.61 | 384.78 | 130.41 | 21.90 |
| Zero-shot CoT | 741.97 | 1238.54 | 1697.96 | 149.19 |
| SFT | 72.22 | 479.55 | 91.25 | 587.95 |
| Typhoon T | ||||
| Unstructured | 169.03 | 478.53 | 491.33 | 829.21 |
| Semi-structured | 170.20 | 795.38 | 487.39 | 900.90 |
| Structured | 102.96 | 466.21 | 293.23 | 995.04 |
🔼 This table presents the average number of tokens generated by different language models across various benchmark datasets. The models include Typhoon 2 (with zero-shot and zero-shot chain-of-thought prompting) and Typhoon T (with unstructured, semi-structured, and structured thinking formats). The benchmarks show the average token count for each model configuration, providing insights into the length and complexity of the generated responses.
read the caption
Table 6: Average number of output tokens generated by each model on the benchmarks.
| Dataset Size | GSM8K | HumanEval+ | IFEval | GPQA | MMLU Pro | ThaiExam |
|---|---|---|---|---|---|---|
| 100% | 62.02 | 69.76 | 53.60 | 27.23 | 23.56 | 22.84 |
| 75% | 62.09 | 70.60 | 49.54 | 30.80 | 27.39 | 21.71 |
| 50% | 61.87 | 64.59 | 48.80 | 29.46 | 27.63 | 20.36 |
| 25% | 62.09 | 66.93 | 50.46 | 29.69 | 30.05 | 20.54 |
| 10% | 60.20 | 65.51 | 50.65 | 29.24 | 29.03 | 21.07 |
| 5% | 60.88 | 64.62 | 47.13 | 30.13 | 29.65 | 19.91 |
🔼 This table presents the performance of reasoning models trained on different sizes of the training dataset, ranging from 5% to 100%. The results are evaluated across six benchmarks: GSM8K, HumanEval+, IFEval, GPQA, MMLU Pro, and ThaiExam. The table shows that smaller datasets sometimes achieve better performance than the full dataset, especially on the GPQA and MMLU Pro benchmarks. This suggests that there is a potential optimal dataset size for training these models, and that overtraining on very large datasets might not necessarily result in improved performance.
read the caption
Table 7: Performance at different dataset sizes. Smaller dataset sizes can sometimes outperform the 100% baseline, particularly in GPQA and MMLU Pro.
| Model | GSM8K | HumanEval+ | IFEval | GPQA | MMLU Pro | ThaiExam |
|---|---|---|---|---|---|---|
| Typhoon T1-EN | 62.09 | 70.60 | 49.54 | 30.80 | 27.39 | 21.71 |
| - IF | 59.59 | 69.57 | 46.58 | 29.02 | 26.34 | 22.64 |
| - Math | 59.51 | 69.47 | 53.60 | 25.45 | 28.52 | 20.88 |
| - Code | 56.94 | 64.24 | 41.96 | 27.68 | 27.65 | 19.57 |
| - Safety | 56.71 | 64.35 | 41.59 | 30.13 | 29.38 | 17.19 |
| - Finance | 61.94 | 67.06 | 50.65 | 27.90 | 20.45 | 18.68 |
🔼 This table presents the results of a leave-one-out experiment designed to analyze the impact of removing specific domains from the training dataset on the model’s performance across various benchmarks. Each row represents a model trained without a particular domain (indicated by ‘-’). The columns show the performance metrics (GSM8K, HumanEval+, IFEval, GPQA, MMLU Pro, ThaiExam) for each model variant. Red values highlight the largest performance drop observed after excluding a specific domain. The results demonstrate that the removal of certain domains, like mathematical reasoning, significantly affects some benchmarks (IFEval) while surprisingly increasing performance on others (MMLU Pro after removing the safety domain).
read the caption
Table 8: Leave-one-out experiment results, assessing the impact of removing specific domains from training. red values highlight the largest performance drop in each column. The “-” symbol denotes the removal of the corresponding domain from training. Excluding mathematical reasoning strongly improves IFEval performance, while safety removal boosts MMLU Pro.
Full paper#