TL;DR#
Many advanced reasoning language models, like DeepSeek R1, primarily excel in high-resource languages such as English and Chinese. This creates a significant gap for low-resource languages due to the dominance of English-centric training data. Local and regional LLM initiatives aim to bridge this gap by focusing on improving linguistic fidelity in specific languages. However, these models often lack robust reasoning capabilities.
This research introduces a novel method to enhance the reasoning capabilities of language-specific LLMs in low-resource languages. The researchers successfully merged a Thai-language LLM with DeepSeek R1, a strong reasoning model, using a cost-effective approach. This resulted in a model that matches the reasoning performance of DeepSeek R1 without compromising the original model’s language proficiency. The researchers also made their data, code and model weights publicly available to benefit the research community.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and effective method for enhancing the reasoning capabilities of language-specific LLMs, particularly those for low-resource languages. It offers a practical solution to a significant challenge in the field, bridging the performance gap between high-resource and low-resource language models. The publicly available data, merge configurations, and model weights contribute significantly to the advancement of LLM initiatives, facilitating further research and development in this area.
Visual Insights#

🔼 This figure illustrates the process of creating the Typhoon2 R1 70B model, which enhances the reasoning capabilities of a Thai language model. It starts with selecting two specialized LLMs: Typhoon2 70B (a Thai language model) and DeepSeek R1 70B (a reasoning model). These models undergo representation alignment using Supervised Fine-Tuning (SFT) with a curated dataset. Finally, an Ability-Aware Model Merging technique combines the fine-tuned Typhoon2 and DeepSeek R1 models, resulting in the final Typhoon2 R1 70B model. The diagram visually depicts the data used at each step and the resulting model.
read the caption
Figure 1: Overview of our Typhoon2 R1 70B recipe
| Experiment | IFEval | MT-Bench | Response Acc | AIME | MATH500 | LCB | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | TH | EN | TH | Lang | Think | EN | TH | EN | TH | EN | TH | ||
| Typhoon2 70B | 88.7 | 81.4 | 8.856 | 7.362 | 98.8 | 0.0 | 10.0 | 3.3 | 66.2 | 60.9 | 39.9 | 36.4 | 54.0 |
| Deepseek R1 70B | 85.7 | 74.3 | 8.939 | 6.329 | 19.0 | 84.2 | 63.3 | 40.0 | 88.4 | 78.7 | 64.7 | 62.8 | 67.8 |
🔼 This table compares the performance of two large language models (LLMs): Typhoon2 70B Instruct and DeepSeek R1 70B Distill, across various tasks including instruction following (IFEval), machine translation (MT-Bench), language accuracy, and reasoning (AIME, MATH500, LiveCodeBench). Typhoon2 excels in language tasks, demonstrating significantly higher accuracy on Thai-specific instruction-following and translation tasks. In contrast, DeepSeek R1 shows better performance on reasoning tasks, outperforming Typhoon2 on mathematics and coding benchmarks. However, neither model exhibits strong performance across both language and reasoning tasks, highlighting a trade-off between these capabilities.
read the caption
Table 1: Performance comparison between Typhoon2 70B Instruct and DeepSeek R1 70B Distill, Showing that Typhoon2 have stronger language task performance, while DeepSeek has stronger reasoning performance. However, neither model compensates for its weakness.
In-depth insights#
Reasoning LLM Merge#
The concept of “Reasoning LLM Merge” explores combining the strengths of large language models (LLMs) specialized in reasoning with those proficient in specific languages. This approach directly addresses the limitations of reasoning models, which often excel in high-resource languages like English but struggle with low-resource languages. Merging allows for the integration of advanced reasoning capabilities without sacrificing the target language fluency of the language-specific LLM. The process typically involves aligning the internal representations of both models, potentially through supervised fine-tuning on a bilingual dataset, then strategically merging their parameters, often weighting the contribution of each model based on layer-specific importance for reasoning versus language generation. The success hinges on carefully selecting appropriate models with compatible architectures and optimizing the merging ratios and fine-tuning data to balance reasoning and language performance. This technique offers a potentially efficient and effective solution for enhancing the reasoning abilities of LLMs in under-resourced languages, leveraging existing resources and bypassing the computationally expensive process of training a new model from scratch.
SFT Data Optimizations#
Optimizing supervised fine-tuning (SFT) data is crucial for effectively enhancing the reasoning capabilities of language models. Careful data selection is paramount; a balanced dataset representing diverse reasoning tasks and avoiding biases is essential. Data augmentation techniques such as back-translation or paraphrasing can increase dataset size and diversity, but must be applied judiciously to avoid introducing noise or inaccuracies. The inclusion of high-quality reasoning traces can significantly improve model performance, but obtaining these traces might be expensive. Exploring techniques like curriculum learning, where models gradually learn from simpler to more complex reasoning tasks, can also boost SFT efficiency. Ultimately, the success of SFT data optimization hinges on a deep understanding of the target model and task, necessitating a well-defined evaluation metric to guide the optimization process and ensure the improvements generalize well to unseen data.
Cross-lingual Reasoning#
Cross-lingual reasoning presents a significant challenge in natural language processing, demanding models capable of understanding and generating text across different languages while performing complex reasoning tasks. Existing multilingual models often struggle with this, particularly when dealing with low-resource languages or tasks involving nuanced linguistic features. A key aspect is bridging the gap between language-specific capabilities and reasoning abilities. This requires careful consideration of data selection and model training, potentially involving techniques like cross-lingual knowledge transfer or model merging to integrate high-performing reasoning models with strong language-specific LLMs. The evaluation of such models needs to be comprehensive, extending beyond standard accuracy metrics to include assessments of reasoning capabilities in various languages and a focus on the quality of the reasoning process itself. This area presents significant opportunities for improving multilingual AI’s ability to reason accurately and effectively across diverse linguistic contexts.
Low-Resource LLM Boost#
The concept of a ‘Low-Resource LLM Boost’ is crucial in bridging the technological gap between high-resource and low-resource languages. It highlights the need for methods that effectively enhance the capabilities of Large Language Models (LLMs) trained on limited data for low-resource languages. Model merging, as explored in the research paper, presents a promising approach, combining the strengths of a reasoning model trained on high-resource data with a language-specific model trained on the low-resource language. This technique aims to transfer reasoning abilities without sacrificing linguistic fidelity. Data selection and augmentation are also key; carefully curating and expanding available datasets for the low-resource language is critical for successful model training and fine-tuning. A successful ‘Low-Resource LLM Boost’ necessitates careful consideration of computational cost-effectiveness and the balance between model size, performance, and accessibility, ultimately promoting greater inclusivity and fairness in AI technology.
Merge Ratio Effects#
The merge ratio significantly impacts the resulting model’s performance. Varying the ratio of the language-specific LLM to the reasoning LLM across different layers reveals crucial insights. Assigning a higher ratio of the reasoning model to earlier layers, which handle high-level comprehension and abstraction, enhances reasoning capabilities. Conversely, a higher language-specific model ratio in later layers, focused on output generation, improves fluency and adherence to the target language. Finding the optimal balance avoids compromising either linguistic fidelity or reasoning accuracy. Experimentation with different merge ratios, especially those that vary across model layers, is crucial for maximizing the benefits of this merging technique. The results show that a carefully tuned merge ratio can lead to a model that surpasses the capabilities of either component model individually, highlighting the potential of this methodology for advancing LLMs in low-resource languages.
More visual insights#
More on figures

🔼 Figure 2 shows an example of the code-switching and language accuracy issues that can arise when using language models like DeepSeek R1 70B Distill, especially in low-resource languages. The model attempts to answer the question of ‘Which came first, the chicken or the egg?’ but includes unexpected code-switching (mixing languages) in its response, which is not natural Thai. This illustrates the limitations of relying on English-centric training data when working with languages other than English.
read the caption
Figure 2: Example demonstrate code-switching / language accuracy problem in DeepSeek R1 70B Distill. - The question is ”Which came first, the chicken or the egg?” - The model generated a final response, but it was unsatisfactory as it contained unnatural code-switching that not in Thai.

🔼 Figure 3 demonstrates a code-switching and language accuracy issue within the DeepSeek R1 70B Distill model. The model was given a question requiring the conversion of rectangular coordinates (0,3) into polar coordinates. The expected response was in Thai, but instead, the model’s response was entirely in Chinese, illustrating its failure to maintain the target language (Thai) while performing a reasoning task.
read the caption
Figure 3: Example demonstrate code-switching / language accuracy problem in DeepSeek R1 70B Distill. - The question is “Convert the point (0,3) in rectangular coordinates to polar coordinates.Convert the point 03 in rectangular coordinates to polar coordinates.\text{Convert the point }(0,3)\text{ in rectangular coordinates to polar % coordinates.}Convert the point ( 0 , 3 ) in rectangular coordinates to polar coordinates. Enter your answer in the form (r,θ),wherer>0,0≤θ<2π.formulae-sequence𝑟𝜃where𝑟00𝜃2𝜋(r,\theta),\quad\text{where}\quad r>0,\quad 0\leq\theta<2\pi.( italic_r , italic_θ ) , where italic_r > 0 , 0 ≤ italic_θ < 2 italic_π .” - The model generated a final response, but it was entirely in Chinese, which is not the usual language in Thai.

🔼 This figure showcases an example of the Typhoon2-R1-70B model’s response to the question: ‘Which came first, the chicken or the egg?’ The model not only provides a complete and accurate answer in Thai, but also demonstrates its reasoning process by clearly articulating the different perspectives and arguments involved in addressing this classic philosophical question. This exemplifies the model’s enhanced reasoning capabilities while maintaining fluency in the target language.
read the caption
Figure 4: Example from our model: The question is, ’Which came first, the chicken or the egg?’ - The model successfully responds fully in Thai while reasoning through its thought process on general question.

🔼 Figure 5 demonstrates the successful application of the model merging technique. The model accurately answers a math question (converting rectangular coordinates to polar coordinates) entirely in Thai, showcasing both its reasoning capabilities and strong Thai language proficiency. The response includes a step-by-step solution, illustrating the model’s thought process.
read the caption
Figure 5: Example demonstrate code-switching / language accuracy problem in DeepSeek R1 70B Distill. - The question is “Convert the point (0,3) in rectangular coordinates to polar coordinates.Convert the point 03 in rectangular coordinates to polar coordinates.\text{Convert the point }(0,3)\text{ in rectangular coordinates to polar % coordinates.}Convert the point ( 0 , 3 ) in rectangular coordinates to polar coordinates. Enter your answer in the form (r,θ),wherer>0,0≤θ<2π.formulae-sequence𝑟𝜃where𝑟00𝜃2𝜋(r,\theta),\quad\text{where}\quad r>0,\quad 0\leq\theta<2\pi.( italic_r , italic_θ ) , where italic_r > 0 , 0 ≤ italic_θ < 2 italic_π .” - The model successfully responds fully in Thai while reasoning through its thought process on math question.
More on tables
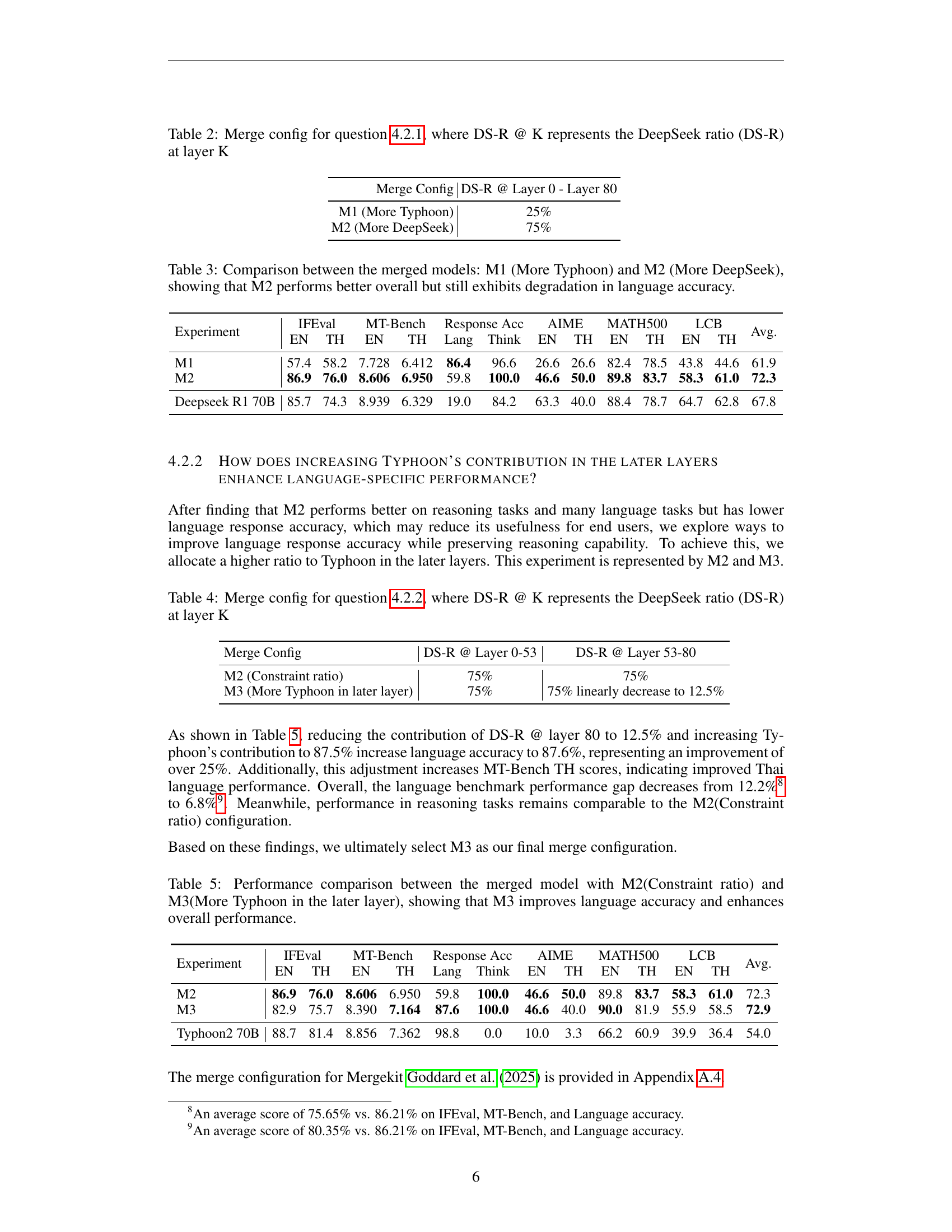
| Merge Config | DS-R @ Layer 0 - Layer 80 |
|---|---|
| M1 (More Typhoon) | 25% |
| M2 (More DeepSeek) | 75% |
🔼 This table details the configuration used for merging two language models in experiment 4.2.1. It shows how the DeepSeek ratio (DS-R), representing the weighting of the reasoning model (DeepSeek R1), is applied at different layers (K) of the model. Two merge configurations are presented: M1 (More Typhoon) and M2 (More DeepSeek). Each configuration specifies the DS-R for layers 0 through 80, illustrating how the weighting of the DeepSeek model changes across different model layers during the merge process.
read the caption
Table 2: Merge config for question 4.2.1, where DS-R @ K represents the DeepSeek ratio (DS-R) at layer K
| Experiment | IFEval | MT-Bench | Response Acc | AIME | MATH500 | LCB | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | TH | EN | TH | Lang | Think | EN | TH | EN | TH | EN | TH | ||
| M1 | 57.4 | 58.2 | 7.728 | 6.412 | 86.4 | 96.6 | 26.6 | 26.6 | 82.4 | 78.5 | 43.8 | 44.6 | 61.9 |
| M2 | 86.9 | 76.0 | 8.606 | 6.950 | 59.8 | 100.0 | 46.6 | 50.0 | 89.8 | 83.7 | 58.3 | 61.0 | 72.3 |
| Deepseek R1 70B | 85.7 | 74.3 | 8.939 | 6.329 | 19.0 | 84.2 | 63.3 | 40.0 | 88.4 | 78.7 | 64.7 | 62.8 | 67.8 |
🔼 This table compares the performance of two merged language models: M1, which incorporates more of the Thai-language model ‘Typhoon2’, and M2, which uses more of the reasoning model ‘DeepSeek R1’. The results show that M2, with its greater emphasis on DeepSeek R1, achieves better overall performance across various reasoning tasks. However, M2 shows a decrease in the accuracy of language tasks, specifically in generating correct Thai text. This indicates a trade-off between enhanced reasoning abilities and maintaining strong language proficiency in the merged model.
read the caption
Table 3: Comparison between the merged models: M1 (More Typhoon) and M2 (More DeepSeek), showing that M2 performs better overall but still exhibits degradation in language accuracy.
| Merge Config | DS-R @ Layer 0-53 | DS-R @ Layer 53-80 |
|---|---|---|
| M2 (Constraint ratio) | 75% | 75% |
| M3 (More Typhoon in later layer) | 75% | 75% linearly decrease to 12.5% |
🔼 This table details the configuration used for merging the Typhoon and DeepSeek models in experiment 4.2.2. It shows how the DeepSeek ratio (DS-R), representing the proportion of DeepSeek model weights, varies across different layers (K) of the model. This experiment explores the impact of adjusting the DeepSeek ratio across different layers to optimize reasoning ability while maintaining the target language fluency. Specifically, it contrasts a configuration with a constant DeepSeek ratio across all layers with one where the ratio decreases linearly from higher to lower layers.
read the caption
Table 4: Merge config for question 4.2.2, where DS-R @ K represents the DeepSeek ratio (DS-R) at layer K
| Experiment | IFEval | MT-Bench | Response Acc | AIME | MATH500 | LCB | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | TH | EN | TH | Lang | Think | EN | TH | EN | TH | EN | TH | ||
| M2 | 86.9 | 76.0 | 8.606 | 6.950 | 59.8 | 100.0 | 46.6 | 50.0 | 89.8 | 83.7 | 58.3 | 61.0 | 72.3 |
| M3 | 82.9 | 75.7 | 8.390 | 7.164 | 87.6 | 100.0 | 46.6 | 40.0 | 90.0 | 81.9 | 55.9 | 58.5 | 72.9 |
| Typhoon2 70B | 88.7 | 81.4 | 8.856 | 7.362 | 98.8 | 0.0 | 10.0 | 3.3 | 66.2 | 60.9 | 39.9 | 36.4 | 54.0 |
🔼 Table 5 presents a comparison of the performance of two merged language models: M2 and M3. Model M2 uses a fixed merge ratio across all layers, whereas Model M3 assigns a higher weight to the language-specific model in later layers. The table shows that model M3 significantly improves language accuracy while maintaining comparable performance in reasoning tasks, demonstrating the effectiveness of adjusting layer-specific merge ratios for enhanced overall model performance.
read the caption
Table 5: Performance comparison between the merged model with M2(Constraint ratio) and M3(More Typhoon in the later layer), showing that M3 improves language accuracy and enhances overall performance.
| Dataset | Language | #Examples | SFT-V1 | SFT-V2 | SFT-V3 | SFT-V4 |
|---|---|---|---|---|---|---|
| Bespoke-Stratos (Original) | EN | 17K | ✓ | ✓ | ✓ | ✓ |
| Bespoke-Stratos TH Translate (Small) | TH | 2K | ✓ | ✗ | ✗ | ✗ |
| Bespoke-Stratos TH Translate (Large) | TH | 6.5K | ✗ | ✓ | ✓ | ✓ |
| Deepseek R1 Distill thai_instruction_sft | TH | 0.5K | ✗ | ✗ | ✓ | ✓ |
| Capybara (Original) | EN | 10K | ✗ | ✗ | ✗ | ✓ |
| thai_instruction_sft (Original) | TH | 10K | ✗ | ✗ | ✗ | ✓ |
🔼 This table summarizes the different configurations of the Supervised Fine-Tuning (SFT) data used in the experiments. Each row represents a different experiment, showing which datasets were included (Bespoke-Stratos, Thai translations of Bespoke-Stratos, distilled Thai reasoning traces, Capybara (English general instruction data), and thai_instruction_sft (Thai general instruction data)) and the number of examples in each dataset for that experiment. This allows comparison of the impact of different data compositions on the model’s performance before merging with the reasoning model.
read the caption
Table 6: A summary of the SFT data configurations used in our SFT: data mixture experiment.
| Experiment | IFEval | MT-Bench | Response Acc | AIME | MATH500 | LCB | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | TH | EN | TH | Lang | Think | EN | TH | EN | TH | TH | EN | ||
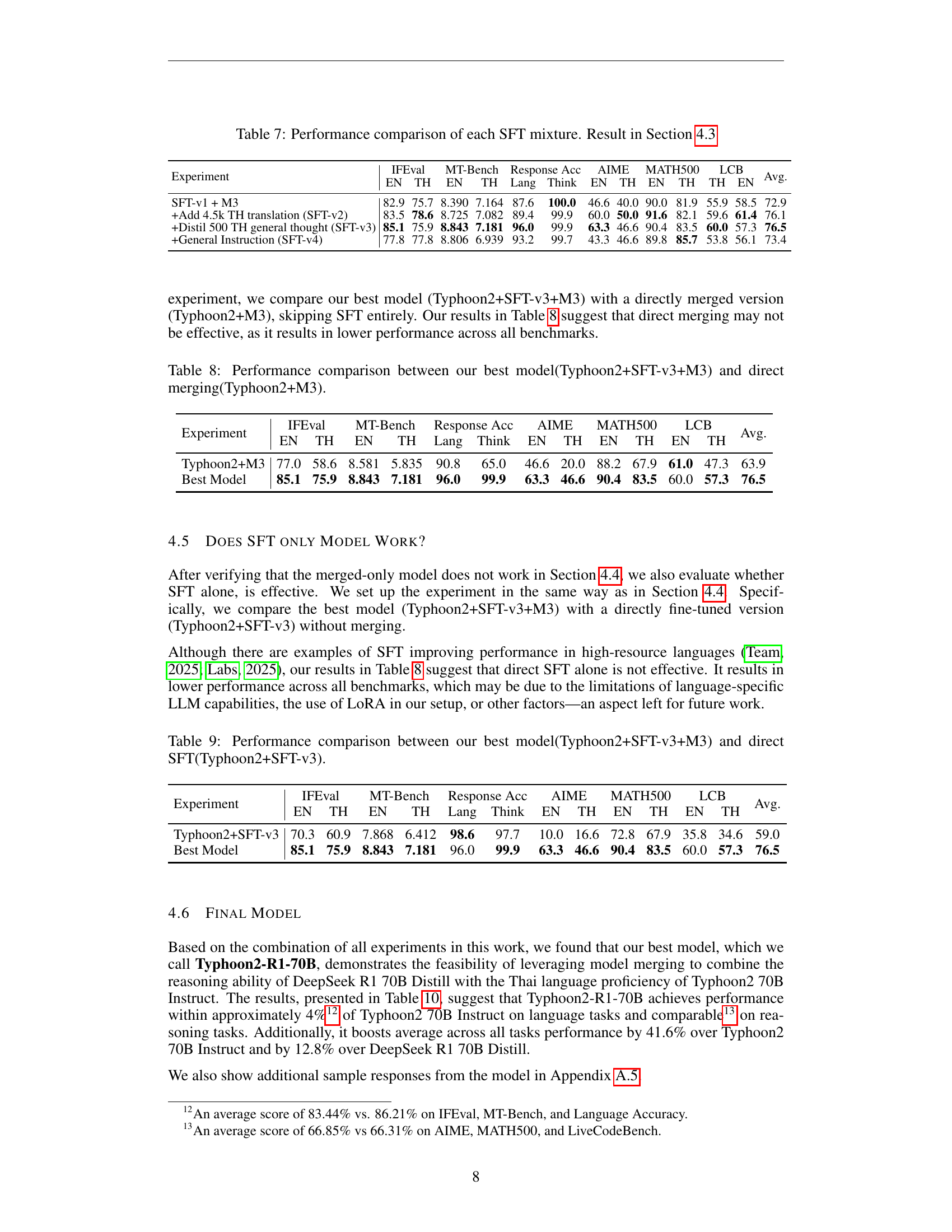
| SFT-v1 + M3 | 82.9 | 75.7 | 8.390 | 7.164 | 87.6 | 100.0 | 46.6 | 40.0 | 90.0 | 81.9 | 55.9 | 58.5 | 72.9 |
| +Add 4.5k TH translation (SFT-v2) | 83.5 | 78.6 | 8.725 | 7.082 | 89.4 | 99.9 | 60.0 | 50.0 | 91.6 | 82.1 | 59.6 | 61.4 | 76.1 |
| +Distil 500 TH general thought (SFT-v3) | 85.1 | 75.9 | 8.843 | 7.181 | 96.0 | 99.9 | 63.3 | 46.6 | 90.4 | 83.5 | 60.0 | 57.3 | 76.5 |
| +General Instruction (SFT-v4) | 77.8 | 77.8 | 8.806 | 6.939 | 93.2 | 99.7 | 43.3 | 46.6 | 89.8 | 85.7 | 53.8 | 56.1 | 73.4 |
🔼 This table compares the performance of four different supervised fine-tuning (SFT) data mixture configurations on a language model. The configurations vary in the proportion of Thai and English data, the inclusion of distilled reasoning traces, and the addition of general instruction data. The goal is to find the optimal data mixture that enhances the model’s performance on reasoning and language tasks. The table presents results for multiple metrics, including IFEval, MT-Bench, language accuracy, AIME, MATH500, and LCB across English and Thai languages.
read the caption
Table 7: Performance comparison of each SFT mixture. Result in Section 4.3
| Experiment | IFEval | MT-Bench | Response Acc | AIME | MATH500 | LCB | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | TH | EN | TH | Lang | Think | EN | TH | EN | TH | EN | TH | ||
| Typhoon2+M3 | 77.0 | 58.6 | 8.581 | 5.835 | 90.8 | 65.0 | 46.6 | 20.0 | 88.2 | 67.9 | 61.0 | 47.3 | 63.9 |
| Best Model | 85.1 | 75.9 | 8.843 | 7.181 | 96.0 | 99.9 | 63.3 | 46.6 | 90.4 | 83.5 | 60.0 | 57.3 | 76.5 |
🔼 This table compares the performance of two approaches: (1) our best-performing model, which combines Typhoon2 (a Thai-language LLM) with DeepSeek R1 (a reasoning LLM) using supervised fine-tuning (SFT) and ability-aware model merging (M3); and (2) a model created by directly merging Typhoon2 and DeepSeek R1 without SFT. The comparison covers several evaluation metrics including IFEval (instruction-following), MT-Bench (multilingual translation benchmark), response accuracy, language accuracy, Think accuracy, AIME (American Invitational Mathematics Examination), MATH500, and LiveCodeBench (coding benchmark) to assess both language capabilities and reasoning abilities.
read the caption
Table 8: Performance comparison between our best model(Typhoon2+SFT-v3+M3) and direct merging(Typhoon2+M3).
| Experiment | IFEval | MT-Bench | Response Acc | AIME | MATH500 | LCB | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | TH | EN | TH | Lang | Think | EN | TH | EN | TH | EN | TH | ||
| Typhoon2+SFT-v3 | 70.3 | 60.9 | 7.868 | 6.412 | 98.6 | 97.7 | 10.0 | 16.6 | 72.8 | 67.9 | 35.8 | 34.6 | 59.0 |
| Best Model | 85.1 | 75.9 | 8.843 | 7.181 | 96.0 | 99.9 | 63.3 | 46.6 | 90.4 | 83.5 | 60.0 | 57.3 | 76.5 |
🔼 This table compares the performance of two models: (1) Typhoon2+SFT-v3+M3, which represents the best-performing model obtained through a combination of supervised fine-tuning (SFT) and model merging, and (2) Typhoon2+SFT-v3, which utilizes only SFT without merging. The comparison assesses their performance across various metrics including IFEval, MT-Bench, language accuracy, AIME, MATH500, and LiveCodeBench. This helps in understanding the contribution of model merging to the overall performance improvement, and whether SFT alone is sufficient to achieve comparable results.
read the caption
Table 9: Performance comparison between our best model(Typhoon2+SFT-v3+M3) and direct SFT(Typhoon2+SFT-v3).
| Experiment | IFEval | MT-Bench | Response Acc | AIME | MATH500 | LCB | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | TH | EN | TH | Lang | Think | EN | TH | EN | TH | EN | TH | ||
| Typhoon2 70B Instruct | 88.7 | 81.4 | 8.856 | 7.362 | 98.8 | 0.0 | 10.0 | 3.3 | 66.2 | 60.9 | 39.9 | 36.4 | 54.0 |
| Typhoon2-R1-70B(Best Model) | 85.1 | 75.9 | 8.843 | 7.181 | 96.0 | 99.9 | 63.3 | 46.6 | 90.4 | 83.5 | 60.0 | 57.3 | 76.5 |
| Deepseek R1 70B | 85.7 | 74.3 | 8.939 | 6.329 | 19.0 | 84.2 | 63.3 | 40.0 | 88.4 | 78.7 | 64.7 | 62.8 | 67.8 |
🔼 This table compares the performance of three different language models: Typhoon2 70B Instruct (a Thai-specialized model), Typhoon2 R1 70B (the best-performing model from the study, which combines Typhoon2 70B with DeepSeek R1 70B), and DeepSeek R1 70B Distill (a reasoning-focused model). It evaluates their capabilities on various tasks, including instruction following (IFEval), machine translation (MT-Bench), language accuracy (Lang Acc), reasoning ability (AIME, MATH500, LiveCodeBench), and the tendency to generate ’thinking traces’ (Think Acc). The results demonstrate the effectiveness of combining the strengths of a language-specific model and a reasoning-focused model using supervised fine-tuning (SFT) and model merging.
read the caption
Table 10: Performance comparison of Typhoon2 70B Instruct, Typhoon2 R1 70B (Best Model), and DeepSeek R1 70B Distill shows that we can combine the performance of two models into one using SFT and model merging.
| Experiment | IFEval | MT-Bench | Response Acc | AIME | MATH500 | LCB | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | TH | EN | TH | Lang | Think | EN | TH | EN | TH | EN | TH | ||
| Sealion 70B Instruct | 89.5 | 78.2 | 9.056 | 6.972 | 90.0 | 0.0 | 20.0 | 6.66 | 69.8 | 58.9 | 35.4 | 25.2 | 52.8 |
| Sealion 70B+SFT-v3+M3 | 83.3 | 78.0 | 8.653 | 7.104 | 90.4 | 100.0 | 50.0 | 43.3 | 89.4 | 83.5 | 59.4 | 60.0 | 74.6 |
| Deepseek R1 70B | 85.7 | 74.3 | 8.939 | 6.329 | 19.0 | 84.2 | 63.3 | 40.0 | 88.4 | 78.7 | 64.7 | 62.8 | 67.8 |
🔼 This table compares the performance of three different language models: the original Sealion 70B Instruct model, the Sealion model after applying the SFT-v3 and M3 methods (referred to as the ‘best recipe’), and the DeepSeek R1 70B Distill model. It shows the performance across several evaluation metrics including IFEval, MT-Bench, Language Accuracy, AIME, MATH500, and LiveCodeBench. The goal is to demonstrate the transferability and effectiveness of the SFT-v3+M3 recipe to different models, specifically showcasing that the recipe can enhance the reasoning capabilities of a language-specific LLM (Sealion) without significantly compromising its performance on language tasks. The comparison highlights how the recipe improves reasoning capabilities while maintaining acceptable language performance.
read the caption
Table 11: Performance comparison of Sealion 70B Instruct, Sealion 70B Instruct+SFT-v3+M3 (Best recipe), and DeepSeek R1 70B Distill demonstrates that this recipe can be transferred between different CPT/SFT recipes of language-specific LLMs.
Full paper#