TL;DR#
Large Language Models (LLMs) are increasingly used for tasks requiring formally correct outputs (e.g., code generation, symbolic math). However, enforcing strict grammatical constraints during LLM generation often reduces their reasoning ability, a problem that current constrained decoding methods struggle to resolve. This paper investigates the theoretical reasons behind this accuracy decrease.
The researchers propose CRANE, a novel algorithm that addresses this limitation. CRANE cleverly interleaves unconstrained generation for reasoning steps with constrained generation for ensuring syntactical correctness. Experimental results show that CRANE substantially improves accuracy compared to both standard unconstrained and state-of-the-art constrained decoding methods across multiple LLMs and datasets, highlighting its effectiveness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs because it directly addresses the critical challenge of balancing accuracy and reasoning capabilities under constrained generation. The proposed CRANE algorithm offers a practical solution to improve the performance of LLMs on complex tasks involving formal constraints, opening new avenues for research and applications. Its theoretical analysis of the limitations of constrained decoding and the introduction of a novel, cost-effective approach are significant contributions to the field.
Visual Insights#

🔼 The figure illustrates a comparison of different LLM decoding methods on a symbolic math problem from the GSM-symbolic dataset. The problem involves calculating a cost based on rental hours, free hours, and cost per hour. The unconstrained method produces a syntactically incorrect answer (a Python expression with a syntax error). A constrained method produces a syntactically correct but numerically incorrect answer. CRANE, the proposed method, generates both a syntactically correct and numerically correct answer, demonstrating its ability to balance correctness and reasoning capability.
read the caption
Figure 1: An example from the GSM-symbolic dataset (variables in blue) where unconstrained generation produces syntactically incorrect output, while constrained generation provides a syntactically valid but incorrect answer. CRANE, however, generates a correct answer.
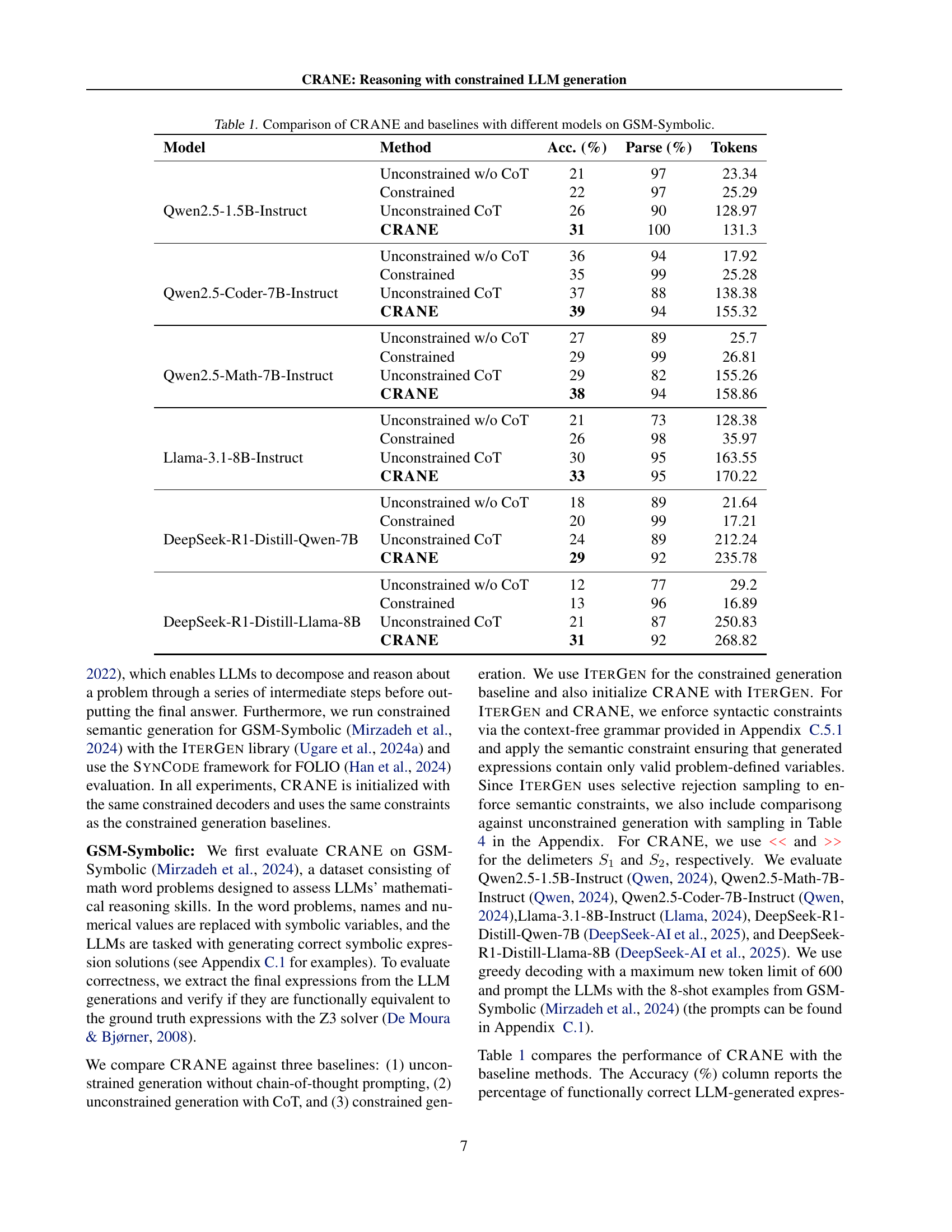
| Model | Method | Acc. (%) | Parse (%) | Tokens |
|---|---|---|---|---|
| Unconstrained w/o CoT | 21 | 97 | 23.34 | |
| Constrained | 22 | 97 | 25.29 | |
| Qwen2.5-1.5B-Instruct | Unconstrained CoT | 26 | 90 | 128.97 |
| CRANE | 31 | 100 | 131.3 | |
| Unconstrained w/o CoT | 36 | 94 | 17.92 | |
| Constrained | 35 | 99 | 25.28 | |
| Qwen2.5-Coder-7B-Instruct | Unconstrained CoT | 37 | 88 | 138.38 |
| CRANE | 39 | 94 | 155.32 | |
| Unconstrained w/o CoT | 27 | 89 | 25.7 | |
| Constrained | 29 | 99 | 26.81 | |
| Qwen2.5-Math-7B-Instruct | Unconstrained CoT | 29 | 82 | 155.26 |
| CRANE | 38 | 94 | 158.86 | |
| Unconstrained w/o CoT | 21 | 73 | 128.38 | |
| Constrained | 26 | 98 | 35.97 | |
| Llama-3.1-8B-Instruct | Unconstrained CoT | 30 | 95 | 163.55 |
| CRANE | 33 | 95 | 170.22 | |
| Unconstrained w/o CoT | 18 | 89 | 21.64 | |
| Constrained | 20 | 99 | 17.21 | |
| DeepSeek-R1-Distill-Qwen-7B | Unconstrained CoT | 24 | 89 | 212.24 |
| CRANE | 29 | 92 | 235.78 | |
| Unconstrained w/o CoT | 12 | 77 | 29.2 | |
| Constrained | 13 | 96 | 16.89 | |
| DeepSeek-R1-Distill-Llama-8B | Unconstrained CoT | 21 | 87 | 250.83 |
| CRANE | 31 | 92 | 268.82 |
🔼 This table presents a comparison of the performance of the CRANE algorithm against several baseline methods on the GSM-Symbolic benchmark. The baseline methods include unconstrained generation without chain-of-thought prompting, unconstrained generation with chain-of-thought prompting, and a state-of-the-art constrained decoding method. The table shows the accuracy (percentage of functionally correct expressions), parse rate (percentage of syntactically correct expressions), and the average number of tokens generated by each method for different large language models (LLMs). This allows for a comprehensive evaluation of CRANE’s effectiveness in balancing accuracy and syntactic correctness.
read the caption
Table 1: Comparison of CRANE and baselines with different models on GSM-Symbolic.
In-depth insights#
Constrained LLM Limits#
The heading ‘Constrained LLM Limits’ suggests an exploration of the inherent boundaries and shortcomings when imposing constraints on large language models (LLMs). A thoughtful analysis would likely investigate how restrictive grammars, while improving syntactic correctness, can severely limit the reasoning capabilities of LLMs. This limitation arises because overly strict constraints may prevent the model from exploring the necessary intermediate reasoning steps required to solve complex problems. The discussion would likely delve into the trade-off between ensuring syntactically valid outputs and preserving the model’s problem-solving abilities. Formal proofs or theoretical arguments might be presented to demonstrate this reduced expressivity under constrained decoding. The analysis would probably explore the relationship between the complexity of the problem, the restrictiveness of the grammar, and the LLM’s capacity to find solutions. Ultimately, a key insight would likely be that a balance is needed—carefully designed constraints can enhance output quality while avoiding a significant reduction in reasoning power. The authors might propose solutions or suggest alternative methods to mitigate these constraints-induced limitations.
CRANE Algorithm#
The CRANE algorithm section details a novel decoding strategy that intelligently balances the benefits of constrained and unconstrained LLM generation. CRANE addresses the shortcomings of existing methods that either compromise reasoning capabilities by enforcing strict grammatical constraints or sacrifice syntactic correctness with unconstrained generation. The algorithm cleverly incorporates delimiters to signal transitions between constrained and unconstrained modes. This adaptive approach allows the LLM to freely explore reasoning steps during unconstrained phases, while maintaining grammatical adherence during the constrained phases. The key insight is that selectively applying constraints, rather than imposing them throughout the generation process, preserves the model’s reasoning abilities while ensuring syntactically and semantically correct outputs. This approach results in a decoding algorithm that is both efficient and effective, demonstrated by significant improvements over existing techniques in experimental evaluations. The formal definition of the algorithm and its integration with different LLMs and decoding strategies are also important components, highlighting CRANE’s versatility and adaptability.
Expressivity Analysis#
An expressivity analysis in a research paper would deeply investigate the limitations of language models (LLMs) when constrained. It would likely begin by formally defining expressivity in the context of LLMs, perhaps relating it to the complexity classes of problems solvable by the model with and without constraints. A key component would be demonstrating a theoretical link between restrictive grammars and reduced problem-solving capabilities. This could involve proving that enforcing highly restrictive grammars limits the LLM to a lower complexity class than it would otherwise be capable of achieving. The analysis should also consider the impact of grammar augmentation. A well-structured analysis would show how carefully designed additions to the grammar can restore, or at least mitigate, the loss of expressivity, allowing the LLM to perform complex reasoning while ensuring syntactic correctness. The analysis should ideally extend beyond specific LLMs or problem domains to offer generalizable results applicable across various language models and tasks. Finally, the study may suggest optimal decoding strategies that balance constraint enforcement with the preservation of expressive power and reasoning capabilities.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper would ideally present a thorough evaluation of the proposed method against established baselines. This would involve using multiple, well-recognized datasets to assess performance across various aspects such as accuracy, efficiency, and robustness. The results should be clearly presented using tables and graphs that compare the proposed approach’s performance with the baselines. Statistical significance tests, such as t-tests or ANOVA, should be used to verify whether any performance differences are statistically significant. Furthermore, an analysis of the results should be included, discussing any unexpected findings and offering potential explanations for observed strengths and weaknesses. A key consideration is the reproducibility of the experiments, with detailed descriptions of the experimental setup and the specific versions of any software or datasets used to enable others to independently validate the findings. Finally, the results should be interpreted within the broader context of the research questions, highlighting the overall implications of the findings for the field.
Future Directions#
Future research could explore extending CRANE’s adaptability to a wider array of LLMs and decoding strategies, potentially improving efficiency and performance. Investigating the theoretical limits of CRANE’s expressivity with non-finite output grammars is another crucial area. Developing more sophisticated methods for dynamically determining the transition points between constrained and unconstrained generation could further refine CRANE’s effectiveness. A deeper analysis of the trade-offs between reasoning capabilities and syntactic correctness under various constraint levels is needed to enhance the algorithm’s robustness. Exploring the application of CRANE to other challenging tasks, such as program synthesis or theorem proving, would demonstrate its broader applicability and potential impact. Finally, investigating the impact of CRANE on different LLM architectures and sizes would provide valuable insights into scaling and optimization.
More visual insights#
More on figures

🔼 The figure illustrates how CRANE, a novel decoding algorithm, dynamically switches between constrained and unconstrained large language model (LLM) generation. The transition between modes is controlled by start and end delimiters (e.g., « and »). When the model encounters a start delimiter, CRANE enters constrained generation mode, ensuring the output adheres to specific grammatical constraints. The constrained generation is highlighted visually. When the end delimiter is encountered, the model returns to unconstrained generation, allowing for more flexible reasoning. This adaptive approach enables CRANE to balance the benefits of both constrained and unconstrained decoding.
read the caption
Figure 2: CRANE adaptively switches between constrained LLM generation and unconstrained LLM generation based on start and end delimiters (in this example << and >>). Using these delimiters, CRANE dynamically tracks which windows (highlighted in the figure) of the LLM generation constraints should be applied to.

🔼 This figure shows the accuracy of the Qwen2.5-Math-7B-Instruct language model on the GSM-Symbolic benchmark across different methods (unconstrained, constrained, unconstrained with Chain-of-Thought prompting, and CRANE) and varying numbers of few-shot examples provided during training. It visualizes the impact of both the decoding method and the amount of training data on the model’s performance in solving symbolic math word problems.
read the caption
Figure 3: Accuracy (%) of Qwen2.5-Math-7B-Instruct By Method and Number of Shots on GSM-Symbolic
More on tables
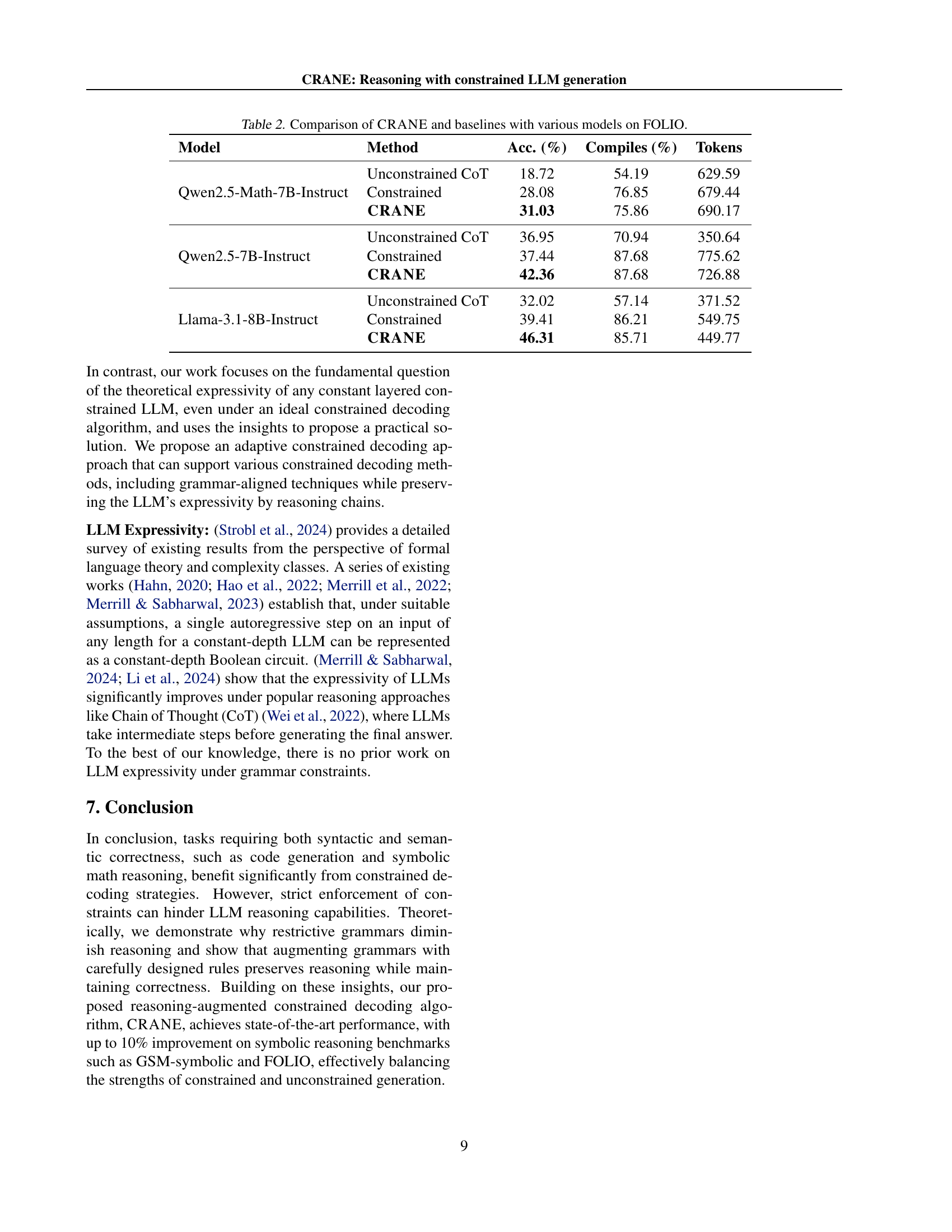
| Model | Method | Acc. (%) | Compiles (%) | Tokens |
|---|---|---|---|---|
| Unconstrained CoT | 18.72 | 54.19 | 629.59 | |
| Qwen2.5-Math-7B-Instruct | Constrained | 28.08 | 76.85 | 679.44 |
| CRANE | 31.03 | 75.86 | 690.17 | |
| Unconstrained CoT | 36.95 | 70.94 | 350.64 | |
| Qwen2.5-7B-Instruct | Constrained | 37.44 | 87.68 | 775.62 |
| CRANE | 42.36 | 87.68 | 726.88 | |
| Unconstrained CoT | 32.02 | 57.14 | 371.52 | |
| Llama-3.1-8B-Instruct | Constrained | 39.41 | 86.21 | 549.75 |
| CRANE | 46.31 | 85.71 | 449.77 |
🔼 This table presents a comparison of the performance of CRANE against several baseline methods on the FOLIO benchmark. The baseline methods include unconstrained generation with Chain-of-Thought prompting, constrained generation, and CRANE itself. The table shows the accuracy (percentage of correct answers), the compile rate (percentage of generated first-order logic formulas that are syntactically valid and successfully compiled by the Prover9 theorem prover), and the average number of tokens generated for each model and method.
read the caption
Table 2: Comparison of CRANE and baselines with various models on FOLIO.
| Model | k | Method | Acc. (%) | Parse (%) | Tokens |
|---|---|---|---|---|---|
| Unconstrained w/o CoT | 20 | 98 | 18.23 | ||
| Constrained | 21 | 95 | 34.28 | ||
| Qwen2.5-1.5B-Instruct | 2 | Unconstrained CoT | 22 | 90 | 130.74 |
| CRANE | 28 | 96 | 140.52 | ||
| Unconstrained w/o CoT | 18 | 95 | 18.23 | ||
| Constrained | 18 | 96 | 34.28 | ||
| Qwen2.5-1.5B-Instruct | 4 | Unconstrained CoT | 24 | 94 | 130.74 |
| CRANE | 30 | 98 | 140.52 | ||
| Unconstrained w/o CoT | 21 | 97 | 23.34 | ||
| Constrained | 22 | 97 | 25.29 | ||
| Qwen2.5-1.5B-Instruct | 8 | Unconstrained CoT | 26 | 90 | 128.97 |
| CRANE | 31 | 100 | 131.3 | ||
| Unconstrained w/o CoT | 37 | 96 | 17.22 | ||
| Constrained | 36 | 99 | 18.61 | ||
| Qwen2.5-Coder-7B-Instruct | 2 | Unconstrained CoT | 32 | 84 | 148.87 |
| CRANE | 37 | 96 | 155.65 | ||
| Unconstrained w/o CoT | 36 | 96 | 16.89 | ||
| Constrained | 36 | 100 | 18.81 | ||
| Qwen2.5-Coder-7B-Instruct | 4 | Unconstrained CoT | 35 | 89 | 151.29 |
| CRANE | 37 | 97 | 163.21 | ||
| Unconstrained w/o CoT | 36 | 94 | 17.92 | ||
| Constrained | 35 | 99 | 25.28 | ||
| Qwen2.5-Coder-7B-Instruct | 8 | Unconstrained CoT | 37 | 88 | 138.38 |
| CRANE | 39 | 94 | 155.32 | ||
| Unconstrained w/o CoT | 20 | 66 | 115.22 | ||
| Constrained | 26 | 95 | 26.99 | ||
| Qwen2.5-Math-7B-Instruct | 2 | Unconstrained CoT | 28 | 72 | 190.51 |
| CRANE | 32 | 89 | 195.65 | ||
| Unconstrained w/o CoT | 22 | 83 | 47 | ||
| Constrained | 29 | 98 | 27.08 | ||
| Qwen2.5-Math-7B-Instruct | 4 | Unconstrained CoT | 28 | 76 | 184.35 |
| CRANE | 37 | 88 | 194.77 | ||
| Unconstrained w/o CoT | 27 | 89 | 25.7 | ||
| Constrained | 29 | 99 | 26.81 | ||
| Qwen2.5-Math-7B-Instruct | 8 | Unconstrained CoT | 29 | 82 | 155.26 |
| CRANE | 38 | 94 | 158.86 | ||
| Unconstrained w/o CoT | 19 | 61 | 157.36 | ||
| Constrained | 23 | 95 | 45.58 | ||
| Llama-3.1-8B-Instruct | 2 | Unconstrained CoT | 29 | 84 | 198.64 |
| CRANE | 35 | 94 | 206.85 | ||
| Unconstrained w/o CoT | 18 | 68 | 131.5 | ||
| Constrained | 24 | 96 | 37.38 | ||
| Llama-3.1-8B-Instruct | 4 | Unconstrained CoT | 26 | 92 | 172.21 |
| CRANE | 30 | 97 | 179.95 | ||
| Unconstrained w/o CoT | 21 | 73 | 128.38 | ||
| Constrained | 26 | 98 | 35.97 | ||
| Llama-3.1-8B-Instruct | 8 | Unconstrained CoT | 30 | 95 | 163.55 |
| CRANE | 33 | 95 | 170.22 |
🔼 This table presents a comparative analysis of CRANE’s performance against various baseline methods on the GSM-Symbolic benchmark. It shows the accuracy (percentage of correctly generated symbolic expressions), the parse rate (percentage of syntactically valid expressions), the average number of tokens generated, and the average inference time for different models (Qwen-2.5, Llama, DeepSeek-R1) and varying numbers of few-shot examples (2, 4, and 8). The baselines include unconstrained generation without chain-of-thought prompting, unconstrained generation with chain-of-thought prompting, and standard constrained decoding.
read the caption
Table 3: Comparison of CRANE and baselines with various models on GSM-Symbolic based on accuracy, number of tokens, and average time.
| Model | Method | pass@1/2/3 (%) | Parse (%) | Tokens |
|---|---|---|---|---|
| Unconstrained w/o CoT (Greedy) | 21 | 97 | 23.34 | |
| Unconstrained w/o CoT (t = 0.7) | 15/19/22 | 88/96/98 | 20.19/39.76/60.57 | |
| Constrained (Greedy) | 22 | 97 | 25.29 | |
| Qwen2.5-1.5B-Instruct | Unconstrained CoT (Greedy) | 26 | 90 | 128.97 |
| Unconstrained CoT (t = 0.7) | 21/25/30 | 78/91/96 | 146.22/292.96/444.61 | |
| CRANE | 31 | 100 | 131.3 | |
| Unconstrained w/o CoT (Greedy) | 21 | 73 | 128.38 | |
| Unconstrained w/o CoT (t = 0.7) | 15/21/25 | 51/74/84 | 106.88/232.75/369.86 | |
| Constrained (Greedy) | 26 | 98 | 35.97 | |
| Llama-3.1-8B-Instruct | Unconstrained CoT (Greedy) | 30 | 95 | 163.55 |
| Unconstrained CoT (t = 0.7) | 24/29/35 | 89/98/98 | 196.01/403.68/607.7 | |
| CRANE (Greedy) | 33 | 95 | 170.22 |
🔼 This table presents a comparison of the performance of CRANE against several baselines on the GSM-Symbolic benchmark. The baselines include unconstrained generation without chain-of-thought prompting (using greedy decoding and temperature sampling), constrained generation (using greedy decoding), and unconstrained generation with chain-of-thought prompting (using greedy decoding and temperature sampling). The table shows the accuracy, the percentage of syntactically valid expressions (Parse %), and the average number of tokens generated for each method and model. The temperature sampling results show pass@1/2/3, indicating the percentage of times the model generated a correct answer within 1, 2, or 3 samples.
read the caption
Table 4: Comparison of CRANE and greedy and sampling baselines with different models on GSM-Symbolic.
| Model | Method | pass@1/2/3 (%) | Compile (%) | Tokens |
|---|---|---|---|---|
| Unconstrained CoT (Greedy) | 36.95 | 70.94 | 350.64 | |
| Unconstrained CoT (t = 0.7) | 16.75/28.57/34.98 | 35.96/55.67/68.47 | 401.5/800.19/1219.33 | |
| Qwen2.5-7B-Instruct | Constrained (Greedy) | 37.44 | 87.68 | 775.62 |
| CRANE (Greedy) | 42.36 | 87.68 | 726.88 | |
| Unconstrained CoT (Greedy) | 32.02 | 57.14 | 371.52 | |
| Unconstrained CoT (t = 0.7) | 14.29/22.66/29.06 | 33.99/46.8/57.64 | 435.35/877.33/1307.45 | |
| Llama-3.1-8B-Instruct | Constrained (Greedy) | 39.41 | 86.21 | 549.75 |
| CRANE (Greedy) | 46.31 | 85.71 | 449.77 |
🔼 This table presents a comparison of the performance of CRANE against greedy decoding and sampling baselines on the FOLIO dataset. The comparison considers different language models and evaluates the accuracy (percentage of functionally correct FOL translations), the percentage of generated FOL formulas that compile successfully, and the average number of tokens generated for each method.
read the caption
Table 5: Comparison of CRANE and greedy and sampling baselines with different models on FOLIO.
Full paper#