TL;DR#
Chain-of-Thought (CoT) significantly enhances reasoning in large language models, but long reasoning chains increase inference costs. Existing methods for shortening chains often lead to performance degradation. The paper identifies a problem where existing methods are not efficient enough and sometimes even produce worse results compared to the original method. The focus is on optimizing the reasoning process for efficiency, making it crucial for practical applications and resource-constrained scenarios.
CoT-Valve tackles this by introducing a novel tuning and inference strategy. It uses a single model to generate reasoning chains of varying lengths, dynamically adjusting based on task complexity. This approach results in significantly shorter chains, reducing computation cost, with minimal impact on accuracy. The paper demonstrates its effectiveness across multiple models and datasets, showcasing its potential for broader applications.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the high computational cost of Chain-of-Thought (CoT) reasoning in large language models. By introducing CoT-Valve, a novel tuning and inference strategy, it enables dynamic control over the length of reasoning chains, improving efficiency without significant performance loss. This work is highly relevant to current research trends in efficient and controllable reasoning and opens up new avenues for research in optimizing CoT reasoning. The proposed method’s improved efficiency and controllability are valuable for various downstream applications.
Visual Insights#

🔼 This figure illustrates the core concept of CoT-Valve, a novel method for controlling the length of reasoning chains generated by a large language model. Before CoT-Valve tuning, the model produces lengthy reasoning paths, particularly for relatively straightforward tasks. CoT-Valve leverages the LoRA technique (Low-Rank Adaptation) to introduce a parameter adjustment that acts like a ‘valve’, allowing the model to generate reasoning chains of varying length depending on the task’s complexity. The figure demonstrates this by showing a single question’s reasoning path generated at different lengths (long, medium, short) using the same model. The example is taken from the MixChain dataset, a new dataset specifically constructed to train and evaluate CoT-Valve’s length-control capabilities. The different lengths of reasoning paths showcase the ability of the model to compress its reasoning process for simpler questions, thereby improving efficiency without significantly sacrificing accuracy.
read the caption
Figure 1: The reasoning model, after the length-compressible CoT tuning, can generate reasoning paths from long to short, leveraging LoRA as a ‘Valve’. We show one example from our constructed dataset MixChain.
| Method | Accuracy | #Token | ACU |
|---|---|---|---|
| Llama-3.3-70B-Instruct | 92.6 | 235.4 | 0.56 |
| Llama-3.1-405B-Instruct | 95.6 | 186.7 | 0.13 |
| Qwen2.5-32B-Instruct | 93.1 | 269.3 | 1.09 |
| Qwen2.5-Math-72B-Instruct | 95.8 | 312.1 | 0.43 |
| QwQ-32B-Preview | 95.1 | 741.1 | 0.40 |
| Prompt Han et al. (2024) | 93.6 | 355.5 | 0.82 |
| Prompt Ding et al. (2024) | 95.5 | 617.7 | 0.48 |
| In-domain Train Set: GSM8K | |||
| CoT-Valve - Ground-Truth | 94.0 | 352.8 | 0.83 |
| CoT-Valve++ - MixChain-C | 94.4 | 276.3 | 1.07 |
| CoT-Valve+P - MixChain-Z | 96.1 | 317.1 | 0.95 |
| CoT-Valve+P - MixChain-Z | 94.9 | 225.5 | 1.32 |
| Out-of-Domain Train Set: PRM12K | |||
| OverthinkChen et al. (2024) - SFT | 94.8 | 749.5 | 0.40 |
| OverthinkChen et al. (2024) - SimPO | 94.8 | 326.2 | 0.91 |
| O1-PrunerLuo et al. (2025a) - SFT | 95.7 | 717 | 0.42 |
| O1-PrunerLuo et al. (2025a) | 96.5 | 534 | 0.56 |
| CoT-Valve+P - MixChain-Z | 95.4 | 288.5 | 1.03 |
🔼 This table presents the results of the QwQ-32B-Preview model on the GSM8K benchmark. It compares various methods for generating chain-of-thought (CoT) reasoning, including prompt-based methods and the proposed CoT-Valve approach. The key metrics are accuracy (percentage of correct answers), the number of tokens used in the generated reasoning, and the accuracy per computation unit (ACU), a metric that balances accuracy with computational efficiency. ACU values are scaled for readability. The dataset used for each method is indicated in the last column.
read the caption
Table 1: Results of QwQ-32B-Preview on GSM8K. Values of ACU are scaled by 102superscript10210^{2}10 start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT for readability. We list the dataset we use after the method name.
In-depth insights#
Elastic CoT Tuning#
Elastic CoT tuning presents a novel approach to enhance the efficiency and effectiveness of chain-of-thought (CoT) reasoning in large language models (LLMs). The core idea revolves around dynamically adjusting the length of the reasoning chain based on the complexity of the task. Unlike traditional methods that rely on fixed-length CoT or heuristic length control, this technique offers a more flexible and adaptive mechanism. A key innovation is the identification of a specific direction within the model’s parameter space. Manipulating this direction allows for precise control over CoT length, enabling the generation of both concise and elaborate reasoning paths with a single model. This approach addresses the limitations of existing methods, which often struggle to balance accuracy and efficiency due to either overly long chains or overly short, inaccurate ones. The tuning process itself is designed to be both precise and progressive. Initial tuning establishes a direction for controlling CoT length, which can then be refined through further training with datasets featuring paired short and long reasoning chains for identical questions. By doing so, the model learns to generate appropriate chain lengths on demand, optimizing for both performance and resource efficiency. The end result is a more robust and versatile LLM with improved reasoning capabilities, particularly in scenarios demanding fine-grained control of computational cost and accuracy.
MixChain Dataset#
The MixChain dataset is a crucial contribution of this research, designed to address limitations in existing chain-of-thought (CoT) datasets. Unlike datasets relying on multiple sampling rounds or manual curation of chain lengths, MixChain provides a more controlled and efficient method for creating training data. Its key innovation is the systematic generation of reasoning chains of varying lengths for the same question, making it ideal for training length-compressible CoT models. This progressive compression strategy helps refine the model’s ability to generate both succinct and detailed reasoning, potentially improving efficiency without sacrificing accuracy. The dataset’s inherent structure facilitates easier and more precise control over the reasoning path length at inference time, significantly improving the model’s ability to adapt to varying task complexities. This is achieved by directly leveraging the learned parameter update direction (‘valve’) during the training process, a more nuanced approach than prior prompt-based control methods.
CoT-Valve Variants#
The concept of “CoT-Valve Variants” suggests exploring modifications to the core CoT-Valve method for enhanced performance and efficiency. One key variant could focus on refining the parameter update direction (Δθ) for more precise control over CoT length. This might involve incorporating additional constraints during training to ensure consistent length control across various points along the update direction. Another variant could explore a progressive compression strategy. This would involve training the model iteratively with increasingly shorter reasoning chains, gradually reducing redundancy and optimizing inference costs. The success of these variants would depend heavily on the quality of the training data, and potentially require more sophisticated methods for selecting and generating shorter, yet effective, reasoning chains. Ultimately, the value of these variants lies in balancing the trade-off between CoT length and accuracy. While longer chains might provide more detail, shorter ones improve efficiency, especially in situations with sufficient information for accurate, concise reasoning.
Model Efficiency#
Model efficiency in large language models (LLMs) is crucial, particularly for reasoning tasks where chain-of-thought (CoT) methods can significantly increase computational costs. This paper introduces CoT-Valve, a novel approach to dynamically control the length of reasoning chains based on task complexity. The key insight is that simpler tasks often benefit from shorter chains, while complex tasks require longer ones. CoT-Valve achieves this by identifying a parameter direction that effectively compresses or expands the reasoning chain’s length, offering better control than prompt-based techniques. This leads to significant improvements in model efficiency without substantial performance degradation. The ability to compress CoT chains is valuable, especially considering the high token costs of long reasoning. The introduction of MixChain, a dataset with varied reasoning chain lengths for the same questions, further enhances the effectiveness of CoT-Valve’s training and fine-tuning. The approach shows promising results in reducing the number of tokens needed, achieving state-of-the-art performance with compressed chains.
Future of CoT#
The future of Chain-of-Thought (CoT) reasoning hinges on addressing its current limitations. Improving efficiency is crucial; current CoT methods often lead to excessively long reasoning chains, increasing computational costs and hindering real-world applications. Research should focus on developing techniques for generating concise and effective reasoning paths, perhaps through better reward mechanisms, more sophisticated pruning strategies, or the incorporation of external knowledge to guide the reasoning process. Enhanced controllability is also vital. Methods for precisely controlling the length and complexity of CoT chains are needed to adapt to varying task complexities and resource constraints. Further exploration of model architectures optimized for CoT is warranted, potentially including specialized modules for intermediate reasoning steps or more efficient knowledge representation. Finally, broader application domains should be explored. While CoT has shown promise in specific areas like math and commonsense reasoning, its potential benefits need to be investigated across a wider range of tasks and modalities. Ultimately, the future of CoT rests on creating more efficient, controllable, and versatile methods that unlock its potential for advanced reasoning in diverse applications.
More visual insights#
More on figures
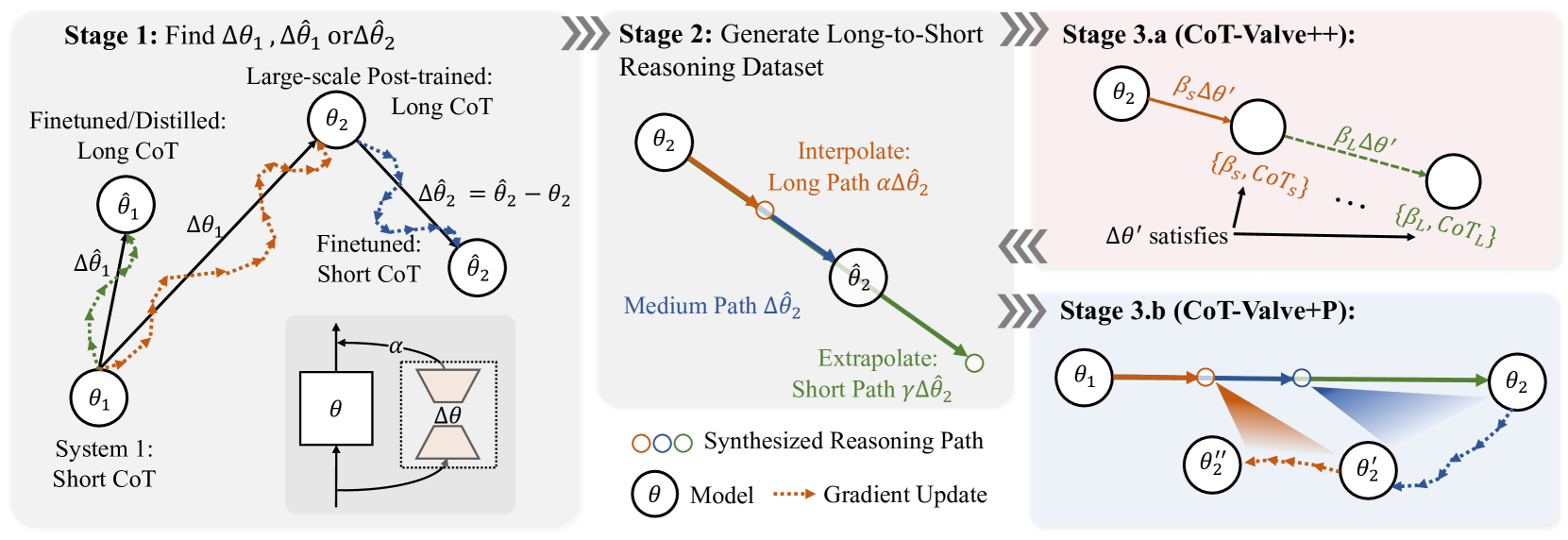
🔼 This figure illustrates the CoT-Valve method, which dynamically controls the length of reasoning chains generated by a language model. It involves three stages. Stage 1 determines a parameter (Δθ) that governs the length of the chain, obtained through model distillation or post-training. Stage 2 uses this parameter to generate a dataset (MixChain) with varying lengths of reasoning chains for the same questions. Stage 3 applies enhanced training methods, CoT-Valve++ and CoT-Valve+P, on the MixChain dataset to improve control and compression of reasoning paths.
read the caption
Figure 2: Illustration of CoT-Valve. In Stage 1, we first determine ΔθΔ𝜃\Delta\thetaroman_Δ italic_θ from distilling or post-training. Then, the trained ΔθΔ𝜃\Delta\thetaroman_Δ italic_θ is utilized to construct the MixChain dataset. Using this dataset, we can then apply two enhanced training methods to achieve more precise control over reasoning paths, or to shorten the reasoning paths as needed.

🔼 The figure shows the relationship between the number of tokens and accuracy achieved by different methods on the GSM8K dataset using the QwQ-32B-Preview model. It compares the performance of the baseline (prompt), CoT-Valve, CoT-Valve with extrapolation, and CoT-Valve++. The x-axis represents the number of tokens used in the reasoning process, and the y-axis represents the accuracy achieved. This visualization helps illustrate the impact of CoT-Valve on controlling reasoning chain length and its effect on model performance.
read the caption
(a) GSM8K, QwQ-32B-Preview

🔼 This figure shows the token length and accuracy results for the GSM8K dataset using the Llama-3.2-1B-Instruct model. It compares different methods, including prompt-based control and the CoT-Valve methods (with and without extrapolation) and shows how the token count and accuracy vary based on the approach. The x-axis represents the number of tokens in the generated response, and the y-axis represents the accuracy.
read the caption
(b) GSM8K, Llama-3.2-1B-Instruct

🔼 The figure shows the relationship between the number of tokens and accuracy for the AIME dataset using the Qwen-2.5-32B instruction-tuned model with LIMO. It compares several methods including prompt-based methods, CoT-Valve, and its enhanced variants. The x-axis represents the number of tokens used in the reasoning chain, and the y-axis represents the accuracy of the model’s predictions. The graph illustrates the performance trade-off between reasoning chain length and accuracy for different methods. The enhanced CoT-Valve methods aim for better controllability and compressibility of the reasoning chain while maintaining accuracy.
read the caption
(c) AIME, Qwen2.5-32B-I w/ LIMO
More on tables
| Method | AIME24 | #Token | ACU |
|---|---|---|---|
| Qwen2.5-32B-Instruct | 4/30 | 1794.2 | 0.023 |
| Qwen2.5-Math-72B-Instruct | 7/30 | 1204.5 | 0.061 |
| Gemini-Flash-Thinking (Team et al., 2023) | 15/30 | 10810.5 | - |
| QwQ-32B-Preview.Train set: GSM8K | |||
| QwQ-32B-Preview | 14/30 | 6827.3 | 0.021 |
| Prompt Han et al. (2024) | 13/30 | 6102.5 | 0.022 |
| Prompt Ding et al. (2024) | 13/30 | 5562.3 | 0.024 |
| Overthink Chen et al. (2024) | 13/30 | 5154.5 | 0.026 |
| CoT-Valve - GSM8K | 14/30 | 5975.0 | 0.024 |
| CoT-Valve++ - MixChain-C | 13/30 | 5360.5 | 0.025 |
| CoT-Valve+P - MixChain-Z | 13/30 | 4629.6 | 0.029 |
| Qwen-32B-Instruct. Train set: LIMO | |||
| Qwen-32B-LIMO | 15/30 | 10498.2 | 0.015 |
| CoT-Valve | 11/30 | 6365.2 | 0.018 |
| SFT - MixChain - Solution 1 | 13/30 | 5368.0 | 0.025 |
| CoT-Valve - MixChain - Solution 1 | 15/30 | 8174.8 | 0.019 |
🔼 This table presents the performance comparison of two large language models, QwQ-32B-Preview and Qwen-32B-Instruct with LIMO, on the AIME 24 benchmark dataset. The table shows the accuracy and the number of tokens used by each model to solve the problems in AIME 24. This allows for an evaluation of both the reasoning capabilities and efficiency of the models. The inclusion of LIMO (a method for improving reasoning) in one of the models provides a direct comparison of performance with and without this technique.
read the caption
Table 2: Results of QwQ-32B-Preview and Qwen-32B-Instruct w/ LIMO on AIME 24.
| GSM8k | AIME24 | |||
| Model | Acc | #Token | Acc | # Token |
| Llama-3.1-8B (0-shot) | 15.7 | 915.0 | 0/30 | 1517.6 |
| R1-Distill-Llama-8B | 87.1 | 1636.6 | 14/30 | 12359.9 |
| CoT-Valve | 87.3 | 1315.2 | 6/30 | 7410.5 |
| CoT-Valve+P - MixChain-Z | 84.0 | 755.2 | 11/30 | 9039.0 |
🔼 This table presents the results of experiments conducted using the DeepSeek-R1-Distill-Llama-8B model. It shows the accuracy and the number of tokens used for different methods, including the baseline, CoT-Valve, and CoT-Valve+P. The results are further divided by whether the dataset is GSM8K or AIME24. The ACU (Accuracy per Computation Unit) metric is also provided to evaluate the overall efficiency of each method.
read the caption
Table 3: Result of DeepSeek-R1-Distill-Llama-8B.
| Method | Accuracy | #Tokens | ACU |
|---|---|---|---|
| LLaMA-3.2-1B-Instruct(8-shot) | 45.9 | 104.3 | 44.008 |
| LLaMA-3.2-1B-Instruct(0-shot) | 45.9 | 199.8 | 22.973 |
| SFT-Full Finetune - GSM8k | 46.1 | 139.4 | 33.070 |
| SFT - GSM8k | 43.8 | 137.7 | 31.808 |
| Prompt | 46.7 | 209.9 | 22.249 |
| SFT - QwQ Distill | 52.7 | 759.3 | 6.941 |
| CoT-Valve - QwQ Distill | 55.5 | 267.0 | 20.786 |
| CoT-Valve+P - MixChain-Z | 55.8 | 291.0 | 19.175 |
| SFT - MixChain-Z - Solution 1 | 57.0 | 288.4 | 19.764 |
| CoT-Valve - MixChain-Z - Solution 1 | 58.9 | 275.4 | 21.387 |
🔼 This table presents the performance of different methods on the LLaMA-3.2-1B-Instruct model for the AIME24 dataset. It compares the accuracy and the number of tokens used by various approaches. The ‘QwQ Distill’ method indicates that the QwQ model was used to generate solutions which were then used for training the LLaMA-3.2-1B-Instruct model. Flexible Match refers to a metric that accounts for minor variations in the numerical answers.
read the caption
Table 4: Results on LLaMA-3-2-1B-Instruct. We report the result of Flexible Match here. QwQ Distill means we use QwQ to synthesize the solution and distill it.
| Method | Accuracy | #Tokens | ACU |
|---|---|---|---|
| LLaMA-3.1-8B (8-shot) | 56.9 | 282.1 | 2.521 |
| LLaMA-3.1-8B (0-shot) | 15.7 | 915.0 | 0.214 |
| SFT-LoRA - GSM8k | 59.0 | 191.9 | 3.843 |
| SFT-LoRA - QwQ Distill | 76.3 | 644.8 | 1.479 |
| CoT-Valve - QwQ Distill | 77.5 | 569.8 | 1.700 |
| CoT-Valve+P - MixChain-Z | 77.1 | 371.2 | 2.596 |
| CoT-Valve + MixChain-Z - Solution 1 | 75.7 | 264.1 | 3.583 |
🔼 This table presents the results of experiments conducted on the LLaMA-3.1-8B model. The model’s performance is evaluated using the ‘Strict Match’ metric, meaning that the generated answer must exactly match the ground truth answer to be considered correct. The table likely shows the accuracy, the number of tokens used in the generated answer, and a performance metric (like ACU) for different experimental setups or methods applied to the LLaMA-3.1-8B model. These setups may involve different training techniques or data used for fine-tuning the model.
read the caption
Table 5: Result on LLaMA-3.1-8B. We report the result of Strict Match here.
| Solution | Solution Length | Accuracy | #Token |
|---|---|---|---|
| Ground-Truth (Solution 0) | 116.0 | 43.8 | 139.4 |
| Solution 1 | 279.6 | 57.0 | 288.4 |
| Solution 2 | 310.7 | 55.1 | 330.0 |
| Solution 3 | 386.7 | 56.5 | 414.6 |
| Solution 4 | 497.2 | 52.5 | 558.3 |
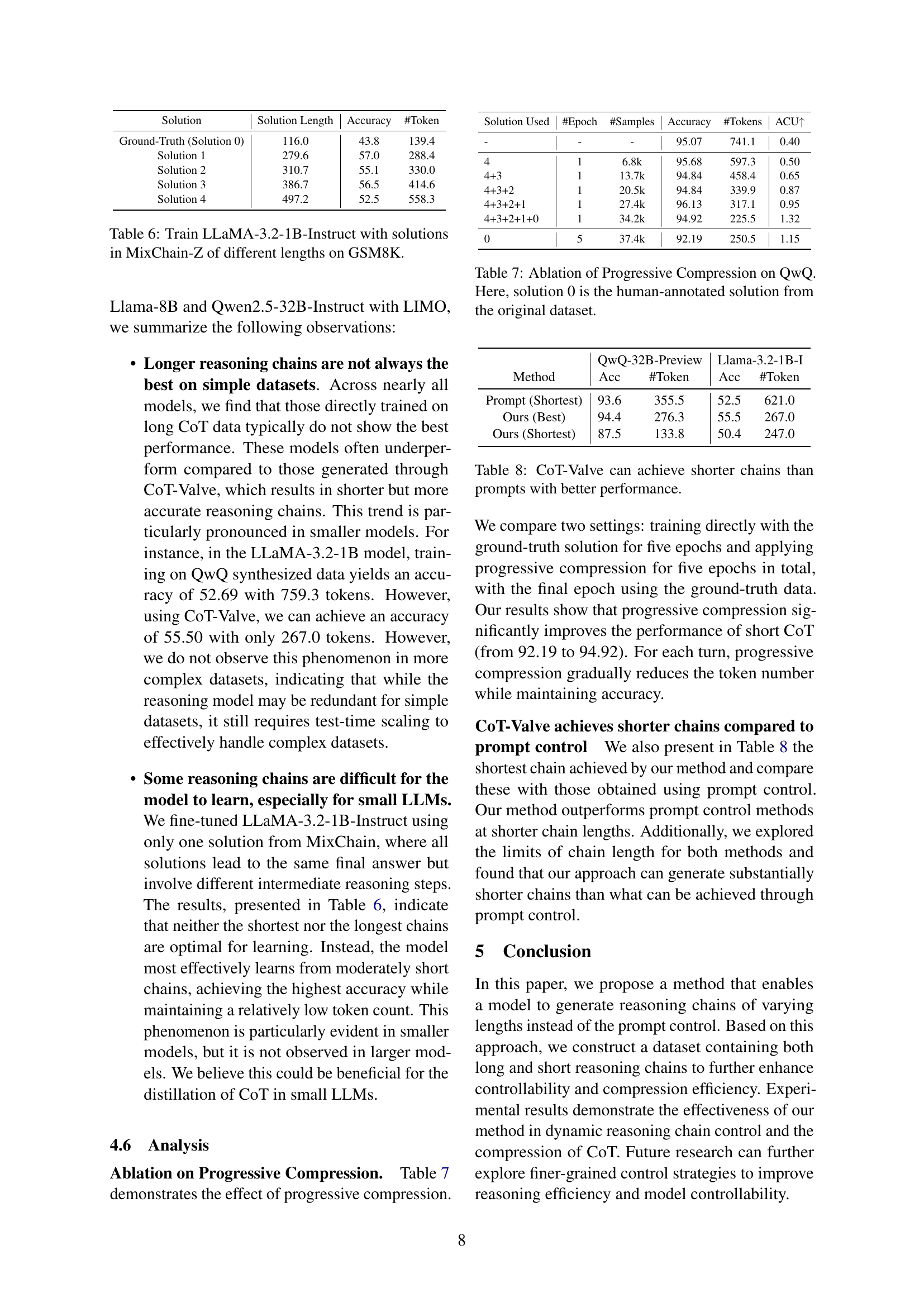
🔼 This table presents the results of training the LLaMA-3.2-1B-Instruct language model on the GSM8K dataset using different solution lengths from the MixChain-Z dataset. MixChain-Z contains multiple reasoning chains of varying lengths for the same questions. The table shows how training with different length solutions affects the model’s accuracy and the number of tokens generated. It also lists details about the training process, like the number of epochs and samples used for each solution length, allowing for a comparison of model performance under various conditions.
read the caption
Table 6: Train LLaMA-3.2-1B-Instruct with solutions in MixChain-Z of different lengths on GSM8K.
| Solution Used | #Epoch | #Samples | Accuracy | #Tokens | ACU |
|---|---|---|---|---|---|
| - | - | - | 95.07 | 741.1 | 0.40 |
| 4 | 1 | 6.8k | 95.68 | 597.3 | 0.50 |
| 4+3 | 1 | 13.7k | 94.84 | 458.4 | 0.65 |
| 4+3+2 | 1 | 20.5k | 94.84 | 339.9 | 0.87 |
| 4+3+2+1 | 1 | 27.4k | 96.13 | 317.1 | 0.95 |
| 4+3+2+1+0 | 1 | 34.2k | 94.92 | 225.5 | 1.32 |
| 0 | 5 | 37.4k | 92.19 | 250.5 | 1.15 |
🔼 This table presents an ablation study evaluating the impact of progressive chain compression on the QwQ model’s performance. It shows the results obtained by training with successively shorter reasoning chains (Solution 1 through Solution 4), starting from the human-annotated solution (Solution 0). The experiment measures accuracy and the number of tokens used for each progressively shorter chain length, demonstrating the effect of compressing reasoning paths on model performance and efficiency.
read the caption
Table 7: Ablation of Progressive Compression on QwQ. Here, solution 0 is the human-annotated solution from the original dataset.
| QwQ-32B-Preview | Llama-3.2-1B-I | |||
|---|---|---|---|---|
| Method | Acc | #Token | Acc | #Token |
| Prompt (Shortest) | 93.6 | 355.5 | 52.5 | 621.0 |
| Ours (Best) | 94.4 | 276.3 | 55.5 | 267.0 |
| Ours (Shortest) | 87.5 | 133.8 | 50.4 | 247.0 |
🔼 This table compares the performance of CoT-Valve and prompt-based methods in generating reasoning chains. It shows that CoT-Valve produces shorter chains while maintaining or improving accuracy compared to prompt-based approaches, demonstrating its effectiveness in controlling the length of reasoning paths.
read the caption
Table 8: CoT-Valve can achieve shorter chains than prompts with better performance.
| Dataset | Solution Index | #Samples | #Avg Token |
|---|---|---|---|
| GSM8K | |||
| Ground-Truth | 1 | 7473 | 121.8 |
| MixChain-C | 1 | 22419 | 294.8 |
| 0 (Ground-Truth) | 116.0 | ||
| 1 | 279.6 | ||
| 2 | 310.7 | ||
| 3 | 386.7 | ||
| MixChain-Z | 4 | 6863 | 497.2 |
| PRM12K | |||
| Ground-Truth | 1 | 12000 | 223.1 |
| 0 (Ground-Truth) | 172.3 | ||
| 1 | 583.2 | ||
| 2 | 613.7 | ||
| 3 | 739.3 | ||
| MixChain-Z | 4 | 8841 | 1003.2 |
| LIMO | |||
| Ground-Truth | 1 | 817 | 6984.1 |
| 1 | 474 | 2994.7 | |
| MixChain-C | 2 | 564 | 4890.6 |
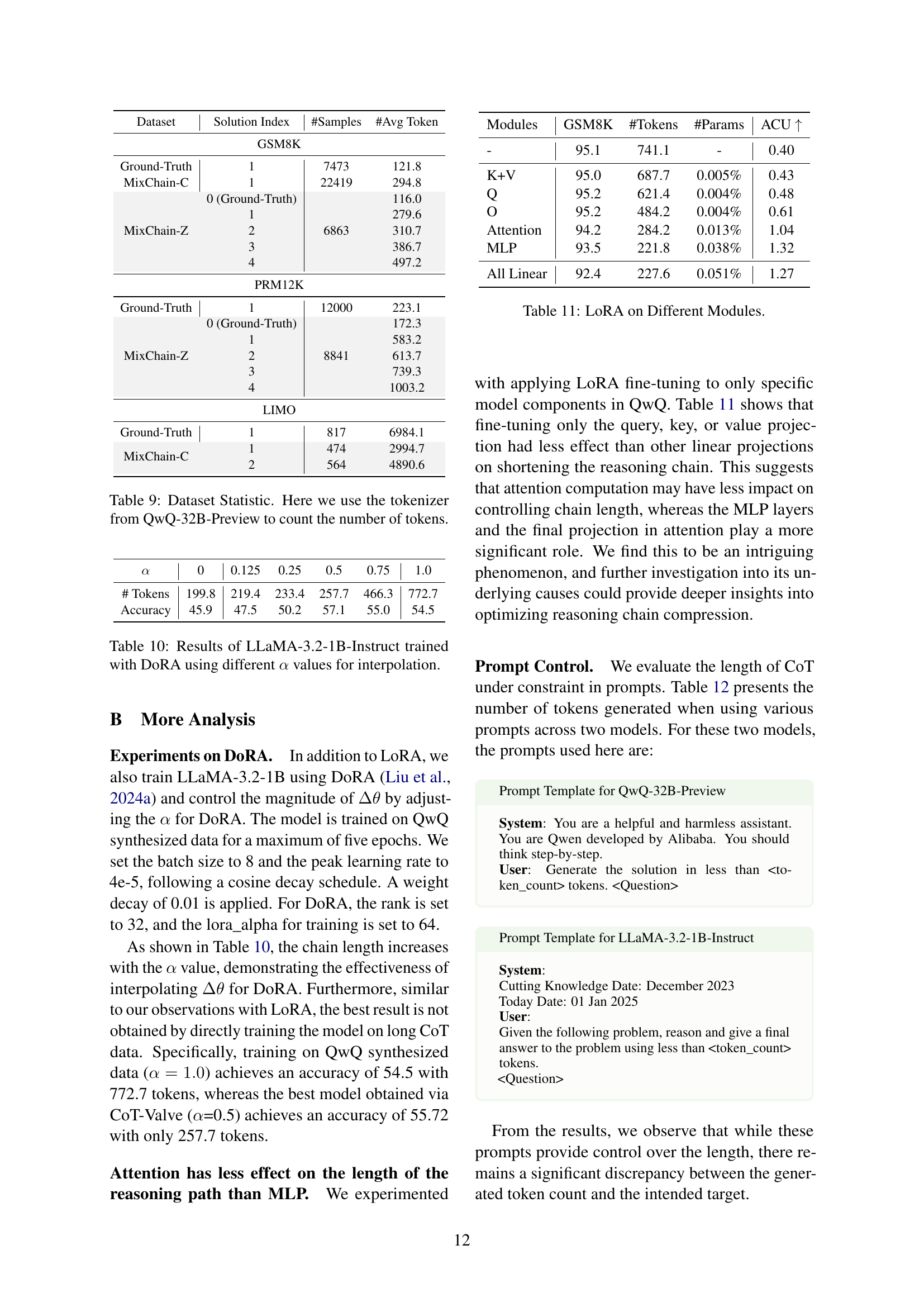
🔼 This table presents a statistical overview of the datasets used in the experiments. It shows the number of samples and the average token count for each dataset and solution type. The token counts are calculated using the tokenizer from the QwQ-32B-Preview model.
read the caption
Table 9: Dataset Statistic. Here we use the tokenizer from QwQ-32B-Preview to count the number of tokens.
| 0 | 0.125 | 0.25 | 0.5 | 0.75 | 1.0 | |
|---|---|---|---|---|---|---|
| # Tokens | 199.8 | 219.4 | 233.4 | 257.7 | 466.3 | 772.7 |
| Accuracy | 45.9 | 47.5 | 50.2 | 57.1 | 55.0 | 54.5 |
🔼 This table presents the results of training the LLaMA-3.2-1B-Instruct language model using the DoRA (Direct Optimization of Reasoning Abilities) method with varying interpolation factors (α). Different values of α were used to control the length of the reasoning chains generated by the model. The table shows the resulting number of tokens in the generated reasoning chains and the accuracy achieved for each α value. This demonstrates how the interpolation factor influences the balance between chain length and accuracy.
read the caption
Table 10: Results of LLaMA-3.2-1B-Instruct trained with DoRA using different α𝛼\alphaitalic_α values for interpolation.
| Modules | GSM8K | #Tokens | #Params | ACU |
|---|---|---|---|---|
| - | 95.1 | 741.1 | - | 0.40 |
| K+V | 95.0 | 687.7 | 0.005% | 0.43 |
| Q | 95.2 | 621.4 | 0.004% | 0.48 |
| O | 95.2 | 484.2 | 0.004% | 0.61 |
| Attention | 94.2 | 284.2 | 0.013% | 1.04 |
| MLP | 93.5 | 221.8 | 0.038% | 1.32 |
| All Linear | 92.4 | 227.6 | 0.051% | 1.27 |
🔼 This table presents the results of an ablation study conducted to investigate the impact of applying LoRA (Low-Rank Adaptation) to different modules within the QwQ model. It shows the accuracy and the number of tokens generated when LoRA is applied to different components such as the query, key, value projections, an MLP layer, and all linear layers. This helps in understanding which model components are most effective in achieving control over the length of the generated reasoning chain, and which components contribute most to the overall performance.
read the caption
Table 11: LoRA on Different Modules.
| QwQ-32B-Preview | Llama-3.2-1B Instruct | ||
|---|---|---|---|
| Token in Prompt | #Token Generated | Token in Prompt | #Token Generated |
| 20 | 355 | 50 | 118 |
| 50 | 422 | 100 | 132 |
| 100 | 511 | 200 | 141 |
| 200 | 569 | 300 | 160 |
| 300 | 623 | 400 | 183 |
| 400 | 666 | 500 | 186 |
🔼 This table presents a comparison of the number of tokens generated by two different large language models (QwQ-32B-Preview and LLaMA-3.2-1B-Instruct) in response to prompts specifying a token limit. The results reveal a significant mismatch between the requested token limit (as set in the prompt) and the actual number of tokens generated by the models. This highlights the challenges in precisely controlling the length of generated text using simple prompt instructions, and emphasizes the need for more sophisticated techniques like the one proposed in the paper (CoT-Valve) to achieve finer-grained control over the length of chain-of-thought reasoning.
read the caption
Table 12: Significant discrepancies exist between the conditions specified in the prompt and the number of generated tokens on GSM8k.
Full paper#