TL;DR#
Large language models (LLMs) are increasingly used for information gathering, but they often produce inaccurate or fabricated information (hallucinations) and lack proper context attribution. Existing methods to mitigate these issues typically rely on manual annotations which are costly and time-consuming. This creates a need for self-supervised methods that can improve LLM reliability and citation quality without human intervention.
SelfCite tackles this challenge by using a self-supervised approach that aligns LLMs to generate high-quality citations. It leverages a reward signal derived from context ablation—removing or isolating cited text to evaluate citation necessity and sufficiency. This reward signal guides a best-of-N sampling strategy and preference optimization to improve citation quality, leading to improvements in citation F1 scores of up to 5.3 points on the LongBench-Cite benchmark. The self-supervised nature of SelfCite makes it a more efficient and scalable solution compared to methods relying on human annotation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) because it introduces a novel self-supervised method for improving citation quality in LLM-generated text. This addresses a significant limitation of current LLMs, namely their tendency to hallucinate or misattribute information. The self-supervised nature of the approach reduces reliance on expensive and time-consuming human annotation, making it more practical for real-world applications. The findings also open avenues for further research into self-supervised alignment techniques and improving the reliability of LLMs.
Visual Insights#

🔼 The SelfCite framework uses context ablation to determine if a citation is necessary and sufficient. First, a model generates a response given the full context. Next, the model generates responses with the cited sentences (1) removed and (2) retained alone. If removing the cited text significantly reduces the probability of generating the same response, the citation is deemed necessary. If keeping only the cited sentences maintains a high probability of the same response, the citation is deemed sufficient. The necessity score (probability drop) and sufficiency score (probability hold) are combined to compute a final reward used in training.
read the caption
Figure 1: The SelfCite framework calculates rewards based on two metrics: necessity score (probability drop) and sufficiency score (probability hold). First, the full context is used to generate a response. Then, the framework evaluates the probability of generating the same response after (1) removing the cited sentences from the context and (2) using only the cited sentences in the context. The probability drop and hold are computed from these probability differences, and their sum is used as the final reward.
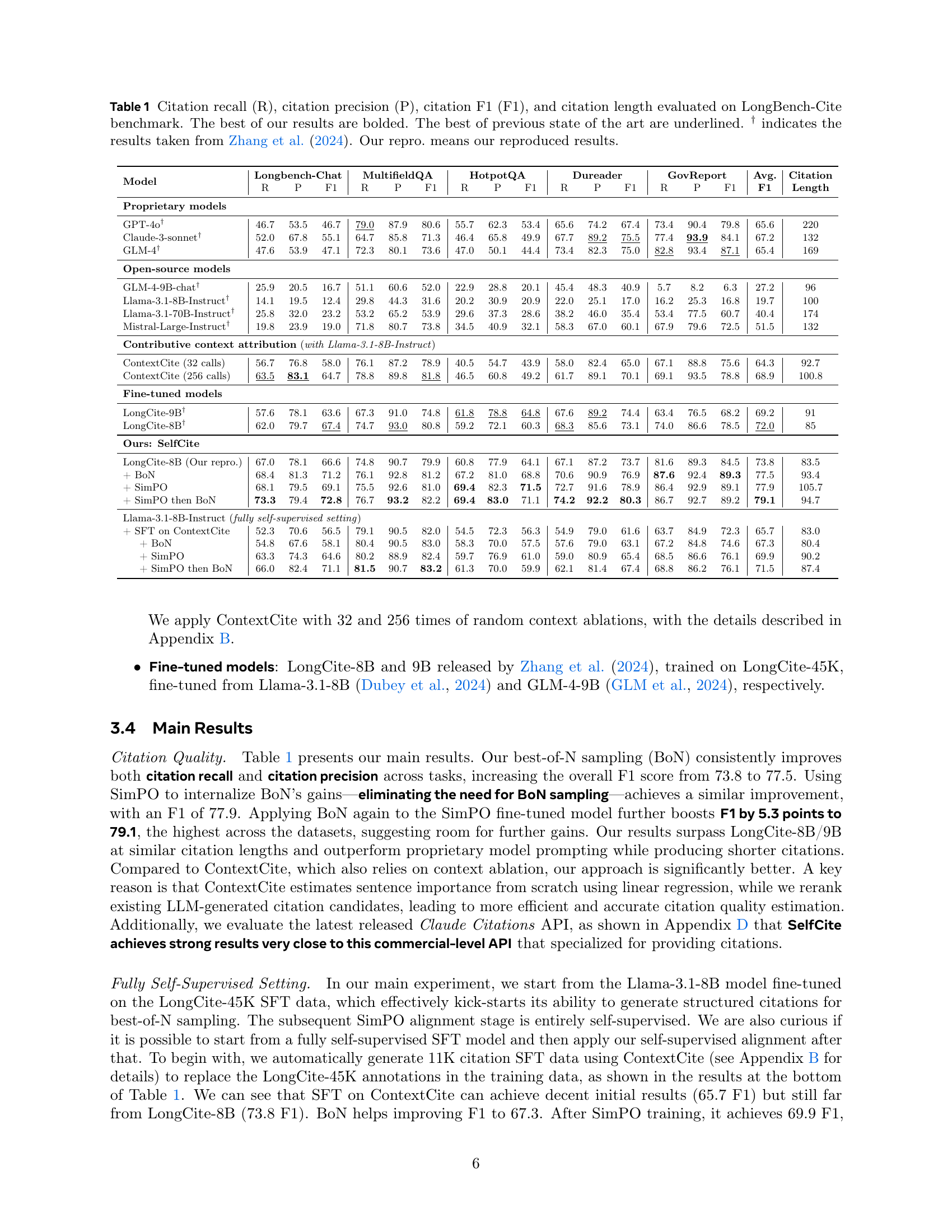
| Model | Longbench-Chat | MultifieldQA | HotpotQA | Dureader | GovReport | Avg. | Citation | ||||||||||
| R | P | F1 | R | P | F1 | R | P | F1 | R | P | F1 | R | P | F1 | F1 | Length | |
| Proprietary models | |||||||||||||||||
| GPT-4o† | 46.7 | 53.5 | 46.7 | 79.0 | 87.9 | 80.6 | 55.7 | 62.3 | 53.4 | 65.6 | 74.2 | 67.4 | 73.4 | 90.4 | 79.8 | 65.6 | 220 |
| Claude-3-sonnet† | 52.0 | 67.8 | 55.1 | 64.7 | 85.8 | 71.3 | 46.4 | 65.8 | 49.9 | 67.7 | 89.2 | 75.5 | 77.4 | 93.9 | 84.1 | 67.2 | 132 |
| GLM-4† | 47.6 | 53.9 | 47.1 | 72.3 | 80.1 | 73.6 | 47.0 | 50.1 | 44.4 | 73.4 | 82.3 | 75.0 | 82.8 | 93.4 | 87.1 | 65.4 | 169 |
| Open-source models | |||||||||||||||||
| GLM-4-9B-chat† | 25.9 | 20.5 | 16.7 | 51.1 | 60.6 | 52.0 | 22.9 | 28.8 | 20.1 | 45.4 | 48.3 | 40.9 | 5.7 | 8.2 | 6.3 | 27.2 | 96 |
| Llama-3.1-8B-Instruct† | 14.1 | 19.5 | 12.4 | 29.8 | 44.3 | 31.6 | 20.2 | 30.9 | 20.9 | 22.0 | 25.1 | 17.0 | 16.2 | 25.3 | 16.8 | 19.7 | 100 |
| Llama-3.1-70B-Instruct† | 25.8 | 32.0 | 23.2 | 53.2 | 65.2 | 53.9 | 29.6 | 37.3 | 28.6 | 38.2 | 46.0 | 35.4 | 53.4 | 77.5 | 60.7 | 40.4 | 174 |
| Mistral-Large-Instruct† | 19.8 | 23.9 | 19.0 | 71.8 | 80.7 | 73.8 | 34.5 | 40.9 | 32.1 | 58.3 | 67.0 | 60.1 | 67.9 | 79.6 | 72.5 | 51.5 | 132 |
| Contributive context attribution (with Llama-3.1-8B-Instruct) | |||||||||||||||||
| ContextCite (32 calls) | 56.7 | 76.8 | 58.0 | 76.1 | 87.2 | 78.9 | 40.5 | 54.7 | 43.9 | 58.0 | 82.4 | 65.0 | 67.1 | 88.8 | 75.6 | 64.3 | 92.7 |
| ContextCite (256 calls) | 63.5 | 83.1 | 64.7 | 78.8 | 89.8 | 81.8 | 46.5 | 60.8 | 49.2 | 61.7 | 89.1 | 70.1 | 69.1 | 93.5 | 78.8 | 68.9 | 100.8 |
| Fine-tuned models | |||||||||||||||||
| LongCite-9B† | 57.6 | 78.1 | 63.6 | 67.3 | 91.0 | 74.8 | 61.8 | 78.8 | 64.8 | 67.6 | 89.2 | 74.4 | 63.4 | 76.5 | 68.2 | 69.2 | 91 |
| LongCite-8B† | 62.0 | 79.7 | 67.4 | 74.7 | 93.0 | 80.8 | 59.2 | 72.1 | 60.3 | 68.3 | 85.6 | 73.1 | 74.0 | 86.6 | 78.5 | 72.0 | 85 |
| Ours: SelfCite | |||||||||||||||||
| LongCite-8B (Our repro.) | 67.0 | 78.1 | 66.6 | 74.8 | 90.7 | 79.9 | 60.8 | 77.9 | 64.1 | 67.1 | 87.2 | 73.7 | 81.6 | 89.3 | 84.5 | 73.8 | 83.5 |
| + BoN | 68.4 | 81.3 | 71.2 | 76.1 | 92.8 | 81.2 | 67.2 | 81.0 | 68.8 | 70.6 | 90.9 | 76.9 | 87.6 | 92.4 | 89.3 | 77.5 | 93.4 |
| + SimPO | 68.1 | 79.5 | 69.1 | 75.5 | 92.6 | 81.0 | 69.4 | 82.3 | 71.5 | 72.7 | 91.6 | 78.9 | 86.4 | 92.9 | 89.1 | 77.9 | 105.7 |
| + SimPO then BoN | 73.3 | 79.4 | 72.8 | 76.7 | 93.2 | 82.2 | 69.4 | 83.0 | 71.1 | 74.2 | 92.2 | 80.3 | 86.7 | 92.7 | 89.2 | 79.1 | 94.7 |
| Llama-3.1-8B-Instruct (fully self-supervised setting) | |||||||||||||||||
| + SFT on ContextCite | 52.3 | 70.6 | 56.5 | 79.1 | 90.5 | 82.0 | 54.5 | 72.3 | 56.3 | 54.9 | 79.0 | 61.6 | 63.7 | 84.9 | 72.3 | 65.7 | 83.0 |
| + BoN | 54.8 | 67.6 | 58.1 | 80.4 | 90.5 | 83.0 | 58.3 | 70.0 | 57.5 | 57.6 | 79.0 | 63.1 | 67.2 | 84.8 | 74.6 | 67.3 | 80.4 |
| + SimPO | 63.3 | 74.3 | 64.6 | 80.2 | 88.9 | 82.4 | 59.7 | 76.9 | 61.0 | 59.0 | 80.9 | 65.4 | 68.5 | 86.6 | 76.1 | 69.9 | 90.2 |
| + SimPO then BoN | 66.0 | 82.4 | 71.1 | 81.5 | 90.7 | 83.2 | 61.3 | 70.0 | 59.9 | 62.1 | 81.4 | 67.4 | 68.8 | 86.2 | 76.1 | 71.5 | 87.4 |
🔼 Table 1 presents a comprehensive evaluation of different models’ performance on the LongBench-Cite benchmark, focusing on citation quality. The benchmark assesses the accuracy and completeness of citations within long-form question answering tasks. The table shows the recall (R), precision (P), and F1-score (F1) for citation generation, along with the average citation length in tokens. Results are provided for various models, including proprietary models (GPT-40, Claude-3-sonnet, GLM-4) and open-source models. For comparison, results are shown for the LongCite models from Zhang et al. (2024), reproduced by the authors of the current paper. The table also includes the SelfCite model’s performance, with results from different approaches (best-of-N sampling, SimPO optimization, combined). The best-performing models in each category are highlighted in bold, while the best results from the prior state-of-the-art are underlined.
read the caption
Table 1: Citation recall (R), citation precision (P), citation F1 (F1), and citation length evaluated on LongBench-Cite benchmark. The best of our results are bolded. The best of previous state of the art are underlined. † indicates the results taken from Zhang et al. (2024). Our repro. means our reproduced results.
In-depth insights#
Self-Supervised Citation#
Self-supervised citation methods represent a significant advancement in natural language processing. By leveraging the model’s own internal mechanisms, these techniques avoid the need for expensive and time-consuming human annotation, a major bottleneck in traditional supervised citation generation. The core idea is to utilize the model’s capacity for self-evaluation, often through context ablation, to determine the necessity and sufficiency of generated citations. This allows the model to provide a reward signal for itself, guiding the learning process and enhancing citation quality without relying on external sources of feedback. The self-supervised approach also addresses the inherent limitations of human annotation, as it can be subjective and inconsistent. Furthermore, it holds the potential to greatly improve the scalability and efficiency of training models for citation tasks. The method’s effectiveness, as measured by metrics such as F1-score, suggests a promising avenue for improving the reliability and trustworthiness of large language models, particularly in generating factual responses grounded in evidence. However, further research is needed to explore the limitations of self-supervision and to investigate more robust ways to address any potential biases or inconsistencies in self-evaluation.
Context Ablation Reward#
The core idea behind the “Context Ablation Reward” is self-supervised learning for citation quality. Instead of relying on human annotations, which are expensive and time-consuming, the model itself assesses the quality of its generated citations using context ablation. By systematically removing or isolating cited text, the model evaluates the impact on the probability of generating the original statement. A large drop in probability after removing the cited text signifies its necessity, while maintaining high probability when only the cited text remains indicates sufficiency. This technique cleverly leverages the LLM’s inherent capabilities to provide feedback, enabling a self-evaluation mechanism. This self-generated reward signal is then used to guide a best-of-N sampling strategy or preference optimization, further enhancing citation quality without human intervention. The effectiveness lies in its ability to automate the quality evaluation process, making it highly scalable and cost-effective compared to traditional methods.
Best-of-N & SimPO#
The paper explores two key methods, Best-of-N sampling and SimPO (Simplified Preference Optimization), to enhance the quality of automatically generated citations by LLMs. Best-of-N is a straightforward approach that generates multiple citation candidates and selects the best one according to a reward function based on context ablation. This method directly improves citation quality but introduces extra computational cost. SimPO addresses this limitation by incorporating the reward signal directly into the model’s training process. This internalizes the reward, eliminating the need for the computationally expensive Best-of-N sampling during inference. The combination of these techniques proves highly effective, achieving significant improvements in citation F1 scores compared to baselines. The paper’s thoughtful exploration of these methods is particularly valuable in providing a practical and efficient solution to the challenging problem of generating high-quality, contextually relevant citations for LLM-generated text.
LongBench-Cite Results#
The LongBench-Cite results section would be crucial for evaluating the effectiveness of the proposed SelfCite method. It would present a detailed comparison of SelfCite’s performance against various baselines, likely including other citation generation methods and prompting-based approaches, across multiple datasets within the LongBench-Cite benchmark. Key metrics to look for would be citation recall, precision, and F1-score, as these directly assess the accuracy of the generated citations. Citation length is another important metric, as shorter, more precise citations are preferable to longer, less focused ones. A strong LongBench-Cite result would show SelfCite achieving higher F1-scores and shorter citation lengths compared to baselines, particularly in datasets with longer context documents which pose significant challenges for accurate citation generation. The analysis should discuss the dataset-specific performance, highlighting any trends or patterns, and it should relate the findings back to the core methodological claims made by SelfCite, ultimately demonstrating the system’s efficiency and reliability in generating high-quality citations within long-form QA settings.
Future Work & Limits#
The section on “Future Work & Limits” would ideally delve into the inherent constraints of the SelfCite approach and propose avenues for future research. Limitations might include the reliance on a specific LLM architecture, the potential for overfitting during preference optimization, and the need for further analysis to determine the generalizability across different model sizes and domains. Future work could involve exploring alternative reward functions beyond context ablation, investigating the effectiveness of different fine-tuning strategies (e.g., reinforcement learning), and assessing the impact of incorporating different citation styles or levels of granularity. The study should also evaluate the robustness of SelfCite to noisy or adversarial contexts, and extend the approach to handle multi-lingual data or more complex citation scenarios (like nested citations or citations within citations). Finally, it should be crucial to discuss plans for making the overall process more efficient. Improving speed and scalability is vital for practical applications. The authors could address the computational cost of the best-of-N sampling strategy and the memory requirements for handling long contexts. Overall, a comprehensive discussion of future work and limitations would strengthen the paper’s value and impact by outlining promising directions and highlighting remaining challenges.
More visual insights#
More on tables
| Model | Long. | Multi. | Hot. | Dur. | Gov. | Avg |
|---|---|---|---|---|---|---|
| Answering without citations | ||||||
| LongSFT-8B† | 68.6 | 83.6 | 69.0 | 62.3 | 54.4 | 67.6 |
| LongSFT-9B† | 64.6 | 83.3 | 67.5 | 66.3 | 46.4 | 65.6 |
| Llama-3.1-8B-Instruct† | 61.6 | 73.3 | 64.5 | 39.4 | 62.1 | 60.2 |
| Answering with citations | ||||||
| LongCite-8B (Our repro.) | 67.6 | 86.7 | 69.3 | 64.0 | 60.4 | 69.6 |
| + SimPO | 67.4 | 86.7 | 67.5 | 66.0 | 61.3 | 69.8 |
| Llama-3.1-8B-Instruct | 67.4 | 87.9 | 73.5 | 67.8 | 62.1 | 71.7 |
| + SFT on ContextCite | 58.8 | 83.4 | 65.8 | 57.8 | 57.5 | 64.6 |
| + SimPO | 56.8 | 80.9 | 65.3 | 59.5 | 60.9 | 64.7 |
🔼 This table compares the correctness of model answers when generating responses with and without citations. The correctness is evaluated on five different datasets (Longbench-Chat, MultifieldQA, HotpotQA, DuReader, GovReport), using metrics such as exact match and F1 score. The results show whether including citations improves the overall correctness of the model’s answers. Results from a previous study by Zhang et al. (2024) are included for comparison.
read the caption
Table 2: Answer correctness when responding with or without citations. † indicates results taken from Zhang et al. (2024). The header contains abbreviations for the same five datasets in Table 1.
| Decoding Methods | HotpotQA | Citation | ||
| R | P | F1 | Length | |
| LongCite-8B (Our repro.) | 60.8 | 77.9 | 64.1 | 83.5 |
| + BoN by LM log prob | 62.7 | 75.5 | 63.4 | 74.6 |
| + BoN by max citation length | 66.5 | 73.6 | 65.1 | 139.8 |
| + BoN by Prob-Drop | 65.6 | 78.1 | 66.6 | 92.9 |
| + BoN by Prob-Hold | 66.2 | 78.1 | 67.0 | 93.4 |
| + BoN by SelfCite | 67.2 | 81.0 | 68.8 | 93.4 |
| w/ lower length limit (256) | 65.8 | 78.8 | 66.4 | 84.5 |
| w/ higher length limit (512) | 67.0 | 82.2 | 68.5 | 99.2 |
| w/o length limit () | 67.9 | 79.3 | 68.1 | 121.9 |
🔼 This ablation study analyzes the impact of different reward strategies on the quality of citations generated using best-of-N (BoN) sampling in the HotpotQA dataset. It compares the recall, precision, F1-score (a combined measure of recall and precision), and average citation length achieved by several variations of the reward function. Specifically, it evaluates the performance using the standard SelfCite reward, compared to alternative methods that rank candidates based on their log probabilities, maximum citation length, only the probability drop metric, or only the probability hold metric. The results provide insights into which aspects of the SelfCite reward are crucial for optimal citation quality.
read the caption
Table 3: Ablation study on HotpotQA citation recall, precision, and F1 (R, P, F1) and citation length for BoN decoding methods.
| Fine-tuning Methods | HotpotQA | Citation | ||
|---|---|---|---|---|
| R | P | F1 | Length | |
| LongCite-8B (Our repro.) | 60.8 | 77.9 | 64.1 | 83.5 |
| + SimPO | 69.4 | 82.3 | 71.5 | 105.7 |
| + SimPO + BoN | 72.0 | 82.7 | 72.9 | 126.9 |
| + SimPO w/ or w/o length balancing | ||||
| w/ length balancing | 69.4 | 82.3 | 71.5 | 105.7 |
| w/o length balancing | 64.4 | 62.9 | 60.5 | 152.9 |
| + SimPO w/ varying data sizes | ||||
| 1K examples | 62.5 | 78.9 | 65.7 | 90.1 |
| 2K examples | 69.4 | 82.3 | 71.5 | 105.7 |
| 4K examples | 68.5 | 80.4 | 70.3 | 134.1 |
| 8K examples | 63.6 | 75.3 | 64.4 | 195.2 |
| + SFT on BoN responses | 68.8 | 77.3 | 68.4 | 98.7 |
| + SimPO by denoising perturbed citations | ||||
| On original responses | 40.5 | 50.5 | 41.6 | 88.8 |
| On BoN responses | 42.6 | 50.7 | 42.3 | 79.7 |
🔼 This table presents the results of an ablation study conducted on the HotpotQA dataset to evaluate the impact of different fine-tuning methods on citation quality. Specifically, it examines the recall, precision, F1 score (harmonic mean of recall and precision), and average citation length resulting from several variations in the fine-tuning process. These variations include the application of SimPO (Simple Preference Optimization), best-of-N sampling with and without length balancing, and various training dataset sizes.
read the caption
Table 4: Ablation study on HotpotQA citation recall, precision, and F1 (R, P, F1) and citation length for finetuned models.
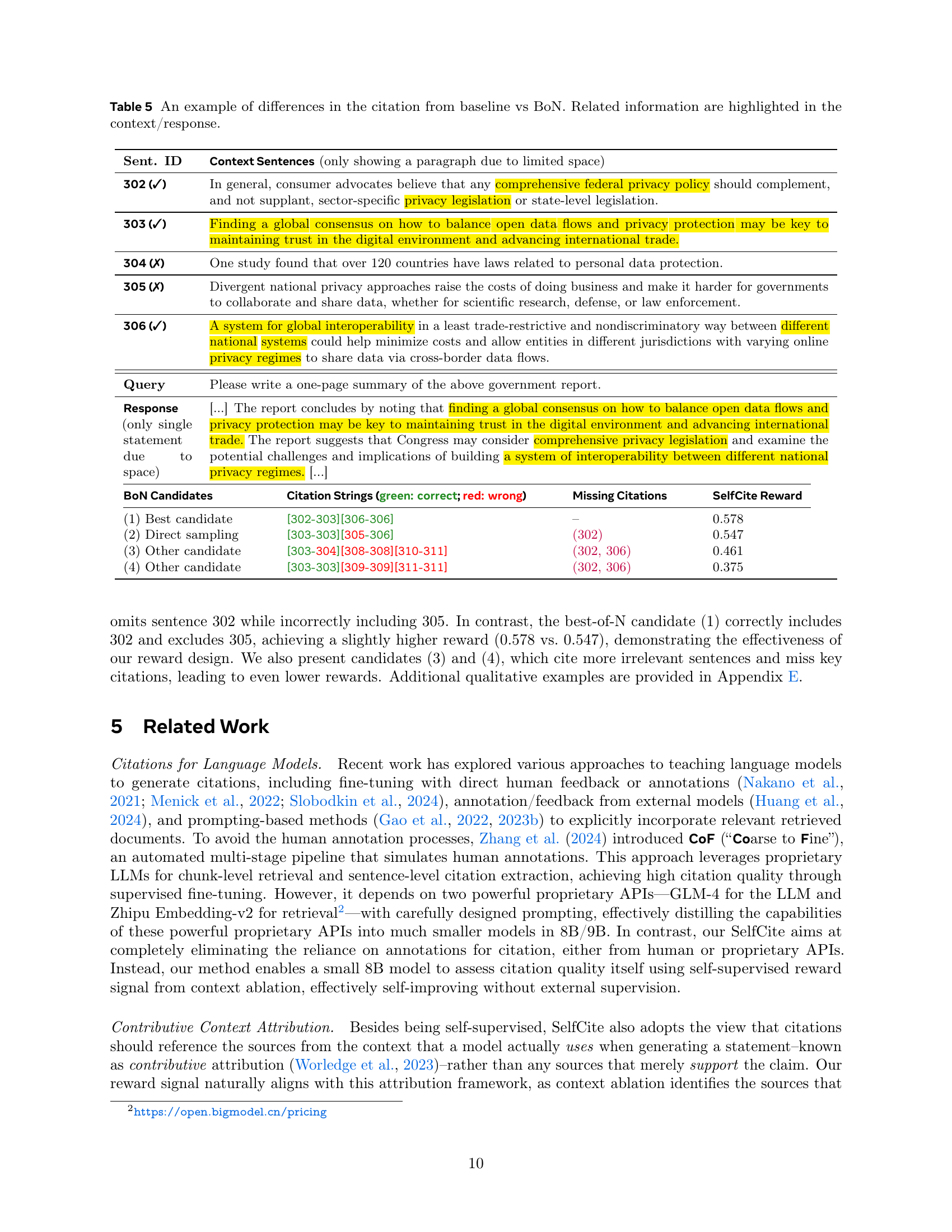
| Sent. ID | Context Sentences (only showing a paragraph due to limited space) | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 302 (✓) | In general, consumer advocates believe that any comprehensive federal privacy policy should complement, and not supplant, sector-specific privacy legislation or state-level legislation. | ||||||||||||||||||||
| 303 (✓) | Finding a global consensus on how to balance open data flows and privacy protection may be key to maintaining trust in the digital environment and advancing international trade. | ||||||||||||||||||||
| 304 (✗) | One study found that over 120 countries have laws related to personal data protection. | ||||||||||||||||||||
| 305 (✗) | Divergent national privacy approaches raise the costs of doing business and make it harder for governments to collaborate and share data, whether for scientific research, defense, or law enforcement. | ||||||||||||||||||||
| 306 (✓) | A system for global interoperability in a least trade-restrictive and nondiscriminatory way between different national systems could help minimize costs and allow entities in different jurisdictions with varying online privacy regimes to share data via cross-border data flows. | ||||||||||||||||||||
| Query | Please write a one-page summary of the above government report. | ||||||||||||||||||||
| Response (only single statement due to space) | […] The report concludes by noting that finding a global consensus on how to balance open data flows and privacy protection may be key to maintaining trust in the digital environment and advancing international trade. The report suggests that Congress may consider comprehensive privacy legislation and examine the potential challenges and implications of building a system of interoperability between different national privacy regimes. […] | ||||||||||||||||||||
| |||||||||||||||||||||
🔼 This table showcases a qualitative example illustrating how SelfCite’s best-of-N (BoN) sampling method improves citation selection compared to a baseline approach. It presents a query, the generated response, and the citations chosen by both the baseline and the BoN methods. The example highlights specific sentences from the context that are either correctly cited (green check marks) or missed/incorrectly included in the citations (red ‘x’ marks). The SelfCite reward score quantifies the quality of each citation selection, demonstrating how BoN consistently achieves higher scores by selecting more relevant and accurate citations.
read the caption
Table 5: An example of differences in the citation from baseline vs BoN. Related information are highlighted in the context/response.
| BoN Candidates | Citation Strings (green: correct; red: wrong) | Missing Citations | SelfCite Reward |
| (1) Best candidate | [302-303][306-306] | – | 0.578 |
| (2) Direct sampling | [303-303][305-306] | (302) | 0.547 |
| (3) Other candidate | [303-304][308-308][310-311] | (302, 306) | 0.461 |
| (4) Other candidate | [303-303][309-309][311-311] | (302, 306) | 0.375 |
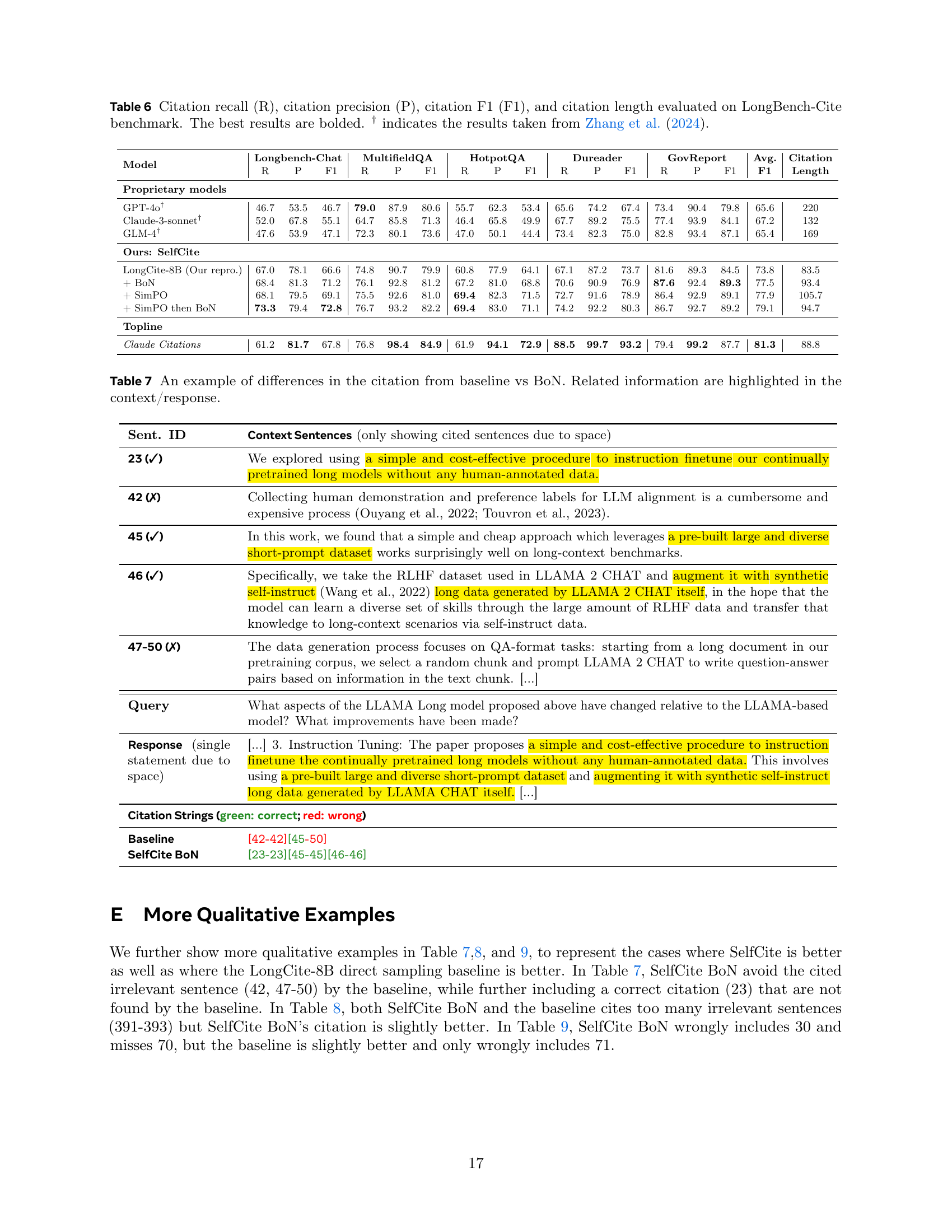
🔼 Table 6 presents a comprehensive evaluation of different models’ performance on the LongBench-Cite benchmark, focusing on citation quality. The metrics used are citation recall (R), citation precision (P), and the F1 score (harmonic mean of R and P), which collectively assess the accuracy and relevance of citations generated by each model. Citation length, measured in tokens, is also included to analyze the conciseness of the generated citations. Results are shown for various models, including proprietary models (GPT-4, Claude-3-sonnet, GLM-4) and open-source models. The table highlights the best performing models in bold and provides a comparison to results reported by Zhang et al. (2024) where applicable.
read the caption
Table 6: Citation recall (R), citation precision (P), citation F1 (F1), and citation length evaluated on LongBench-Cite benchmark. The best results are bolded. † indicates the results taken from Zhang et al. (2024).
| Model | Longbench-Chat | MultifieldQA | HotpotQA | Dureader | GovReport | Avg. | Citation | ||||||||||
| R | P | F1 | R | P | F1 | R | P | F1 | R | P | F1 | R | P | F1 | F1 | Length | |
| Proprietary models | |||||||||||||||||
| GPT-4o† | 46.7 | 53.5 | 46.7 | 79.0 | 87.9 | 80.6 | 55.7 | 62.3 | 53.4 | 65.6 | 74.2 | 67.4 | 73.4 | 90.4 | 79.8 | 65.6 | 220 |
| Claude-3-sonnet† | 52.0 | 67.8 | 55.1 | 64.7 | 85.8 | 71.3 | 46.4 | 65.8 | 49.9 | 67.7 | 89.2 | 75.5 | 77.4 | 93.9 | 84.1 | 67.2 | 132 |
| GLM-4† | 47.6 | 53.9 | 47.1 | 72.3 | 80.1 | 73.6 | 47.0 | 50.1 | 44.4 | 73.4 | 82.3 | 75.0 | 82.8 | 93.4 | 87.1 | 65.4 | 169 |
| Ours: SelfCite | |||||||||||||||||
| LongCite-8B (Our repro.) | 67.0 | 78.1 | 66.6 | 74.8 | 90.7 | 79.9 | 60.8 | 77.9 | 64.1 | 67.1 | 87.2 | 73.7 | 81.6 | 89.3 | 84.5 | 73.8 | 83.5 |
| + BoN | 68.4 | 81.3 | 71.2 | 76.1 | 92.8 | 81.2 | 67.2 | 81.0 | 68.8 | 70.6 | 90.9 | 76.9 | 87.6 | 92.4 | 89.3 | 77.5 | 93.4 |
| + SimPO | 68.1 | 79.5 | 69.1 | 75.5 | 92.6 | 81.0 | 69.4 | 82.3 | 71.5 | 72.7 | 91.6 | 78.9 | 86.4 | 92.9 | 89.1 | 77.9 | 105.7 |
| + SimPO then BoN | 73.3 | 79.4 | 72.8 | 76.7 | 93.2 | 82.2 | 69.4 | 83.0 | 71.1 | 74.2 | 92.2 | 80.3 | 86.7 | 92.7 | 89.2 | 79.1 | 94.7 |
| Topline | |||||||||||||||||
| Claude Citations | 61.2 | 81.7 | 67.8 | 76.8 | 98.4 | 84.9 | 61.9 | 94.1 | 72.9 | 88.5 | 99.7 | 93.2 | 79.4 | 99.2 | 87.7 | 81.3 | 88.8 |
🔼 This table showcases a qualitative comparison of citation generation between the baseline model and the SelfCite model using best-of-N sampling (BoN). It highlights an example where SelfCite improves citation selection by correctly identifying relevant context sentences and excluding irrelevant ones. The table includes the context sentences, the query, the model’s generated response, the citation strings generated by both methods (with correct citations highlighted), and the associated SelfCite reward score. This detailed breakdown demonstrates how SelfCite outperforms the baseline in selecting precise and relevant supporting evidence for the generated statements.
read the caption
Table 7: An example of differences in the citation from baseline vs BoN. Related information are highlighted in the context/response.
| Sent. ID | Context Sentences (only showing cited sentences due to space) |
|---|---|
| 23 (✓) | We explored using a simple and cost-effective procedure to instruction finetune our continually pretrained long models without any human-annotated data. |
| 42 (✗) | Collecting human demonstration and preference labels for LLM alignment is a cumbersome and expensive process (Ouyang et al., 2022; Touvron et al., 2023). |
| 45 (✓) | In this work, we found that a simple and cheap approach which leverages a pre-built large and diverse short-prompt dataset works surprisingly well on long-context benchmarks. |
| 46 (✓) | Specifically, we take the RLHF dataset used in LLAMA 2 CHAT and augment it with synthetic self-instruct (Wang et al., 2022) long data generated by LLAMA 2 CHAT itself, in the hope that the model can learn a diverse set of skills through the large amount of RLHF data and transfer that knowledge to long-context scenarios via self-instruct data. |
| 47-50 (✗) | The data generation process focuses on QA-format tasks: starting from a long document in our pretraining corpus, we select a random chunk and prompt LLAMA 2 CHAT to write question-answer pairs based on information in the text chunk. […] |
| Query | What aspects of the LLAMA Long model proposed above have changed relative to the LLAMA-based model? What improvements have been made? |
| Response (single statement due to space) | […] 3. Instruction Tuning: The paper proposes a simple and cost-effective procedure to instruction finetune the continually pretrained long models without any human-annotated data. This involves using a pre-built large and diverse short-prompt dataset and augmenting it with synthetic self-instruct long data generated by LLAMA CHAT itself. […] |
| Citation Strings (green: correct; red: wrong) | |
| Baseline | [42-42][45-50] |
| SelfCite BoN | [23-23][45-45][46-46] |
🔼 This table showcases a qualitative example from the paper illustrating how SelfCite’s Best-of-N (BoN) sampling approach improves citation selection compared to a baseline method. It highlights the differences in citations generated by the baseline and SelfCite BoN for a specific response. The table shows the context sentences, the query, the generated response statement, the baseline and BoN citation selections, the missing citations in each case, and the SelfCite reward for each. This allows for a direct comparison of citation accuracy and relevance between the methods, demonstrating the effectiveness of SelfCite in selecting appropriate and relevant citations from the context.
read the caption
Table 8: An example of differences in the citation from baseline vs BoN. Related information are highlighted in the context/response.
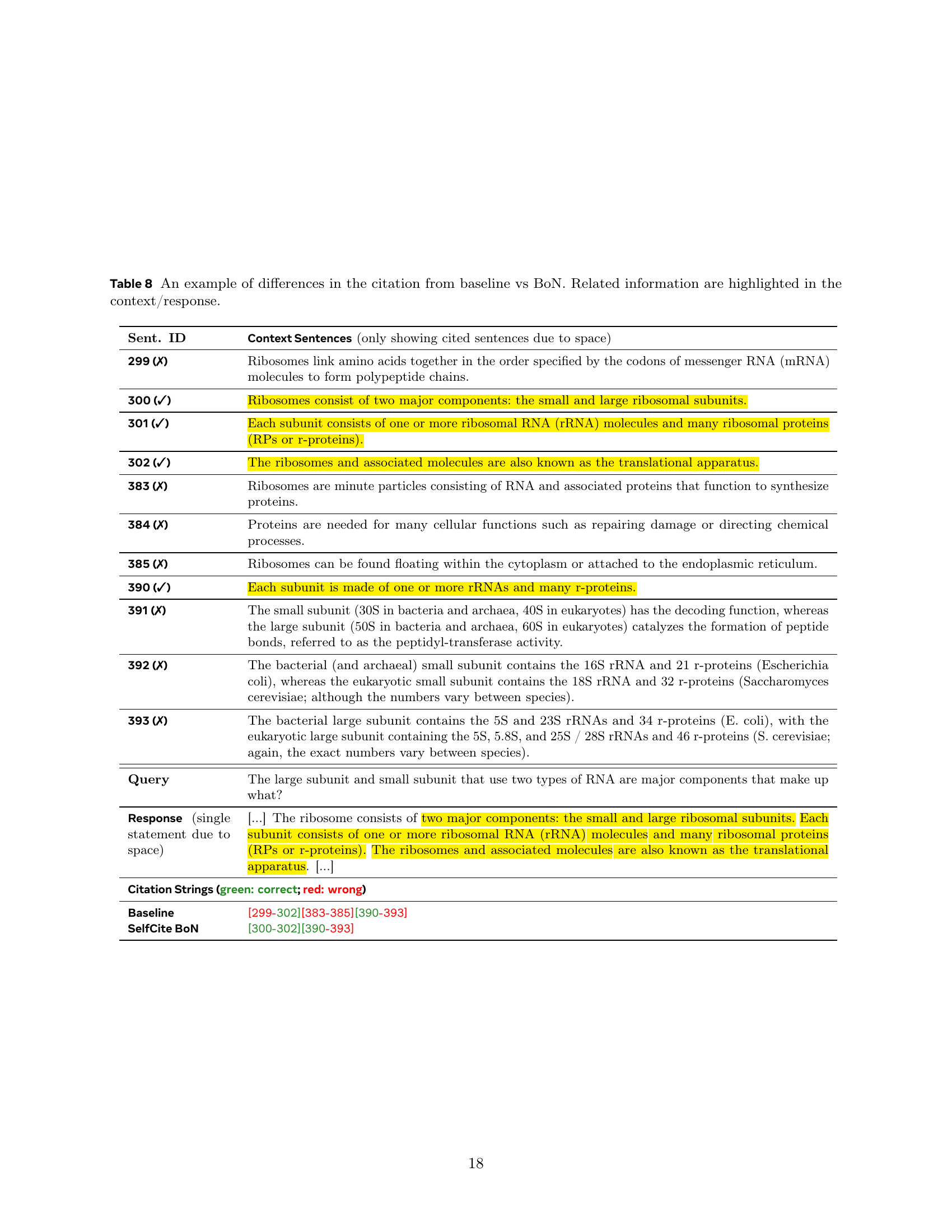
| Sent. ID | Context Sentences (only showing cited sentences due to space) |
|---|---|
| 299 (✗) | Ribosomes link amino acids together in the order specified by the codons of messenger RNA (mRNA) molecules to form polypeptide chains. |
| 300 (✓) | Ribosomes consist of two major components: the small and large ribosomal subunits. |
| 301 (✓) | Each subunit consists of one or more ribosomal RNA (rRNA) molecules and many ribosomal proteins (RPs or r-proteins). |
| 302 (✓) | The ribosomes and associated molecules are also known as the translational apparatus. |
| 383 (✗) | Ribosomes are minute particles consisting of RNA and associated proteins that function to synthesize proteins. |
| 384 (✗) | Proteins are needed for many cellular functions such as repairing damage or directing chemical processes. |
| 385 (✗) | Ribosomes can be found floating within the cytoplasm or attached to the endoplasmic reticulum. |
| 390 (✓) | Each subunit is made of one or more rRNAs and many r-proteins. |
| 391 (✗) | The small subunit (30S in bacteria and archaea, 40S in eukaryotes) has the decoding function, whereas the large subunit (50S in bacteria and archaea, 60S in eukaryotes) catalyzes the formation of peptide bonds, referred to as the peptidyl-transferase activity. |
| 392 (✗) | The bacterial (and archaeal) small subunit contains the 16S rRNA and 21 r-proteins (Escherichia coli), whereas the eukaryotic small subunit contains the 18S rRNA and 32 r-proteins (Saccharomyces cerevisiae; although the numbers vary between species). |
| 393 (✗) | The bacterial large subunit contains the 5S and 23S rRNAs and 34 r-proteins (E. coli), with the eukaryotic large subunit containing the 5S, 5.8S, and 25S / 28S rRNAs and 46 r-proteins (S. cerevisiae; again, the exact numbers vary between species). |
| Query | The large subunit and small subunit that use two types of RNA are major components that make up what? |
| Response (single statement due to space) | […] The ribosome consists of two major components: the small and large ribosomal subunits. Each subunit consists of one or more ribosomal RNA (rRNA) molecules and many ribosomal proteins (RPs or r-proteins). The ribosomes and associated molecules are also known as the translational apparatus. […] |
| Citation Strings (green: correct; red: wrong) | |
| Baseline | [299-302][383-385][390-393] |
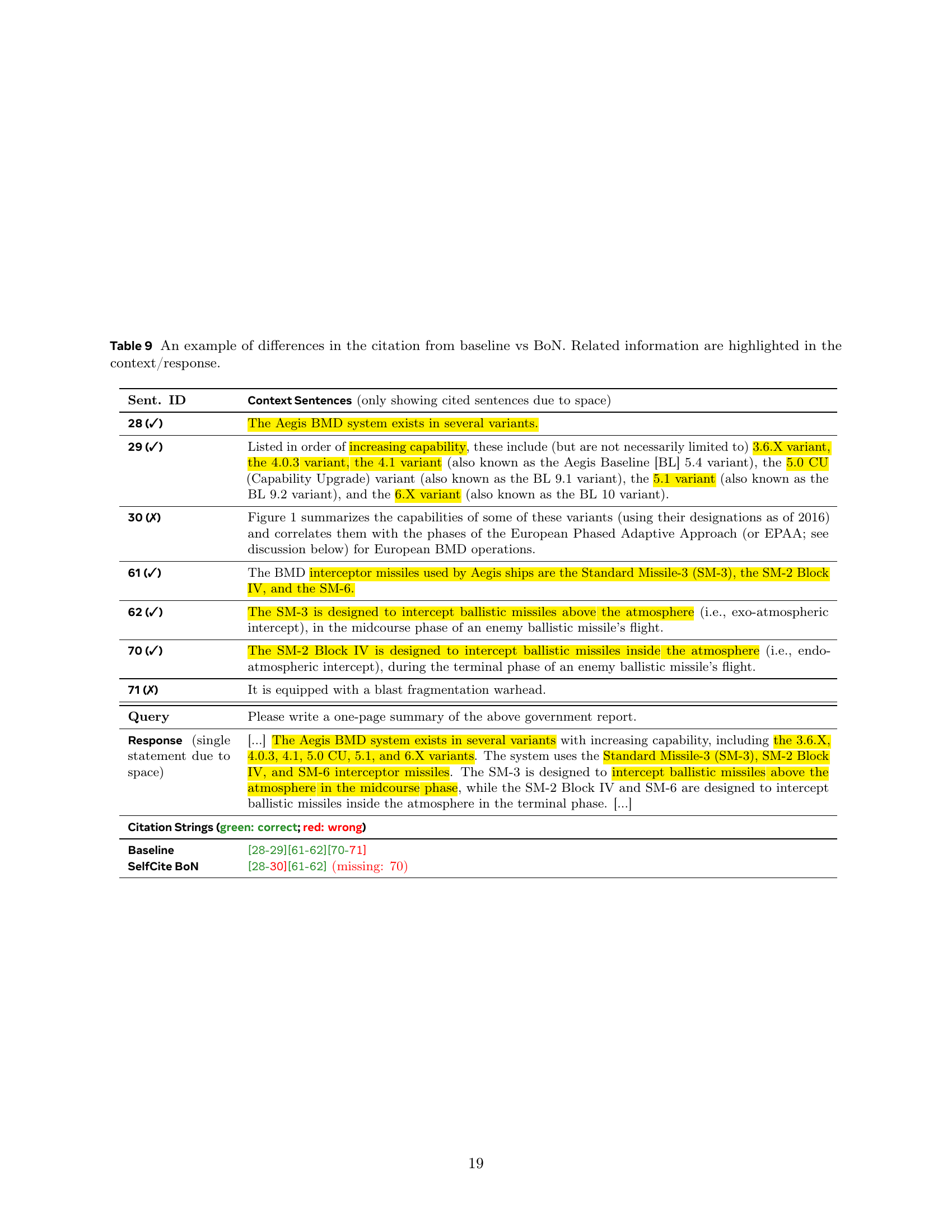
| SelfCite BoN | [300-302][390-393] |
🔼 This table showcases a specific example to illustrate how SelfCite’s best-of-N (BoN) sampling method improves citation selection compared to a baseline approach. It highlights the differences in citation selection between the baseline and BoN methods for a single statement within a generated response. The example includes the relevant context sentences, the generated response statement, the citation strings chosen by both the baseline and BoN methods, and the SelfCite reward score for each. The table helps demonstrate how BoN can select more relevant citations while excluding irrelevant ones, leading to a higher reward and potentially a better-quality response.
read the caption
Table 9: An example of differences in the citation from baseline vs BoN. Related information are highlighted in the context/response.
Full paper#