TL;DR#
Finding the right pre-trained model for a specific task is challenging due to the sheer number of available models and often insufficient documentation. Current model search methods primarily rely on text-based searches of metadata, which is often incomplete or inaccurate. This paper introduces ProbeLog, a novel method that directly analyzes model weights to identify suitable models for a given task, even without any prior knowledge of the model’s purpose.
ProbeLog uses a ‘probing’ approach, feeding a fixed set of inputs (probes) to the models and analyzing their outputs. It generates a unique descriptor for each output dimension (logit) of the model, allowing for efficient retrieval based on logit similarity. Furthermore, to reduce the computational cost of analyzing massive model repositories, Collaborative Probing, a matrix factorization based method is introduced to effectively reduce the number of probes required for gallery encoding. Experiments show ProbeLog achieves significantly higher retrieval accuracy compared to existing approaches, and demonstrates scalability to large repositories.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the critical issue of efficient model retrieval in the era of massive model repositories. Its novel method, ProbeLog, offers a significant advancement over existing text-based search approaches by enabling zero-shot search directly from model weights. This is crucial for researchers as it eliminates the reliance on often incomplete or inaccurate model documentation, thereby saving time and resources. The introduction of Collaborative Probing further enhances efficiency by reducing the computational cost of analyzing large model repositories. This work opens up new avenues for exploring weight-space representations, potentially influencing model design and improving the usability of model hubs.
Visual Insights#

🔼 The figure is a pie chart visualizing the state of documentation for 1.2 million models on the Hugging Face model repository. It reveals that a significant portion (39.5%) have either no documentation or only minimal documentation (rest). A smaller portion have template READMEs (16.6%) or completely empty READMEs (12.3%). Only a minority (31.6%) have adequate README files.
read the caption
Figure 1: Hugging Face Documentation. We analyze the model cards of 1.2M1.2𝑀1.2M1.2 italic_M Hugging Face models. We discover that the majority of models are either undocumented or poorly documented.
 |  |  |
🔼 This table presents the results of a model retrieval experiment using the ProbeLog method and two baseline methods (full query and model-level). The experiment evaluated both search-by-logit and search-by-text approaches. The table shows the Top-1 and Top-5 retrieval accuracies for each method across different scenarios (INet-to-INet, INet-to-HF, HF-to-INet, text-to-INet, and text-to-HF). All methods used 4000 COCO images as probes to ensure a fair comparison. INet refers to the ImageNet-based dataset of models, while HF refers to the HuggingFace-based dataset of models.
read the caption
Table 1: Retrieval Results. We evaluate the Top-1 and Top-5 retrieval accuracies of our method and the baselines for search-by-logit and search-by-text. All methods use COCO images as probes. For a fair comparison, all experiments are performed with 4,00040004,0004 , 000 probes.
In-depth insights#
Weight-Space Search#
Weight-space search represents a paradigm shift in model retrieval, moving beyond traditional text-based methods. Instead of relying on often-sparse or inaccurate model documentation, it leverages the inherent information encoded within the model’s weights. This approach offers the potential for more accurate and comprehensive model discovery, especially in scenarios with limited metadata. The challenge lies in the high dimensionality and complexity of weight spaces, requiring efficient and robust techniques to extract meaningful representations. ProbeLog, as presented in the paper, tackles this by focusing on logit-level descriptors, offering a scalable and effective method for both logit-based and zero-shot text-based retrieval. This allows for flexible querying, enabling researchers to find models based on desired functionality, regardless of the specific training data or model architecture. Collaborative probing significantly improves efficiency by reducing the number of costly feedforward passes needed. While still nascent, weight-space search holds immense promise for efficiently navigating the ever-expanding landscape of machine learning models, enabling easier discovery of pre-trained models suitable for various tasks and promoting broader accessibility of existing research.
ProbeLog Method#
The ProbeLog method is a novel approach to zero-shot model search that analyzes model weights without relying on metadata or training data. Its core innovation is representing each output dimension (logit) of a model individually, creating a descriptor for each logit based on its responses to a fixed set of input probes. This logit-level representation is crucial, as it addresses the limitations of model-level representations which are insensitive to specific target concepts and highly susceptible to variations in model structure or class order. ProbeLog leverages a collaborative filtering technique to reduce the computational cost of encoding large model repositories, achieving a 3x reduction in encoding time. Additionally, ProbeLog supports both logit-based and zero-shot text-based retrieval, allowing users to find models based on similarity to existing logits or directly search using a textual concept description. The method’s strength lies in its ability to effectively handle poorly documented models which represent a majority of the models available in public repositories. This is achieved by focusing on the functional properties revealed by the probing process rather than relying on often scarce or unreliable model descriptions. Overall, ProbeLog demonstrates promising results in both real-world and fine-grained search tasks, making it a practical and scalable solution to the challenging problem of efficient model search within massive model repositories.
Zero-Shot Retrieval#
Zero-shot retrieval, in the context of the research paper, signifies a model search technique capable of identifying relevant models without relying on explicit training data or metadata. This is a significant advance over traditional methods which heavily depend on text-based searches of model documentation, often inaccurate and incomplete. The core idea revolves around creating a robust model representation derived from the model’s weights or outputs, that captures its core functionality rather than relying on potentially scarce or misleading metadata. This representation allows the search to proceed based on functional similarity, leading to the possibility of identifying models suitable for a specific task even when information about those models is unavailable. The method’s effectiveness hinges on the ability to accurately encode the essence of a model’s task through these representations, often requiring innovative approaches in representing and comparing model characteristics, such as logit-level descriptors. Scalability to large model repositories is paramount, making efficient methods like collaborative filtering critical for practical deployment.
Collaborative Probing#
The concept of ‘Collaborative Probing’ presented in the research paper offers a highly efficient solution to the computational cost associated with creating comprehensive representations of model repositories. By strategically sampling only a subset of probes for each model and then leveraging matrix factorization techniques (like truncated SVD) to intelligently fill in the missing data, this method significantly reduces the number of required forward passes. This translates to substantial computational savings and improved scalability, making the proposed search technique applicable to much larger model repositories. The effectiveness of collaborative probing is demonstrably shown through experimental results, highlighting its ability to achieve comparable accuracy to the full probing approach, despite using a much smaller fraction of probes. This makes it a practical and vital component of the overall methodology, rendering the approach more accessible and feasible for real-world applications.
Future of Model Search#
The future of model search hinges on addressing the limitations of current methods. Moving beyond rudimentary keyword searches requires leveraging model weights directly, as demonstrated by ProbeLog’s success in retrieving models based on their functional capabilities rather than metadata. Logit-level representations, as opposed to whole-model representations, offer a more granular and robust approach. Collaborative filtering techniques will become crucial for efficiently managing the exponentially growing number of models, reducing the computational cost of searching massive repositories. Further research should explore more sophisticated probe selection methods, perhaps using adaptive sampling to improve accuracy and efficiency. Finally, integrating text-based search seamlessly with weight-based search is essential for truly zero-shot retrieval, enabling users to find appropriate models regardless of whether detailed documentation is available. Developing effective asymmetric discrepancy measures capable of evaluating the match between text descriptions and model logit capabilities will be key to enabling these advancements.
More visual insights#
More on figures

🔼 This figure illustrates the task of Classification Model Search. The goal is to identify classifiers from a large model repository that can recognize a specific target concept (e.g., ‘Dog’). Given a text prompt like ‘Dog’, the search aims to retrieve all classifiers that include ‘Dog’ as one of their classification classes. The challenge lies in the massive size of the model repository and the diversity of concepts within it. Successful retrieval replaces the need for model training, offering potential improvements in accuracy, cost reduction, and environmental benefits.
read the caption
Figure 2: Classification Model Search. We present a new task of Classification Model Search, where the goal is to find classifiers that can recognize a target concept. Concretely, given an input prompt, such as “Dog”, we wish to retrieve all classifiers that one of their classes is “Dog”. The search space is a large model repository, that contains many models and concepts to search from. The retrieved models can replace model training, increasing accuracy, reducing cost and environmental impact.

🔼 ProbeLog generates a descriptor for each model’s output dimension (logit) by feeding a fixed set of input samples (probes) into the model and observing its responses. The responses are normalized to create the ProbeLog descriptor, which is used to retrieve similar model logits. This figure illustrates how ProbeLog uses probes to create a vector representation for a specific logit, enabling comparison with other logits for retrieval. Figure 5 extends this concept to zero-shot retrieval from text.
read the caption
Figure 3: ProbeLog Descriptors. Our method generates a descriptor for individual output dimensions (logits) of models. First, we sample and a set of inputs (e.g., from the COCO dataset), and fix them as our set of probes. Then, to create a new ProbeLog descriptor for a model logit, we feed the set of ordered probes nto the model and observe their outputs. Finally, we take all values of the logit we wish to represent, and normalize them. We use this representation to accurately retrieve model logits associated with similar concepts. In Fig. 5, we extend this idea to zero-shot concept descriptors.

🔼 This figure compares the ProbeLog representations of CIFAR-10 logits using two different sets of probes: 1,000 out-of-distribution COCO images and 1,000 in-distribution CIFAR-10 images. Subfigure (a) shows the ground truth label for comparison. Subfigures (b) and (c) visualize the ProbeLog representations generated using the respective probe sets. The results demonstrate that while both sets of probes reveal meaningful similarities between logits, using in-distribution probes yields better results, highlighting the importance of probe selection in generating effective representations.
read the caption
Figure 4: CIFAR10 Logit Similarities.(a) Ground truth label. (b) ProbeLog representations using 1,00010001,0001 , 000 out-of-distribution COCO image probes. (c) ProbeLog representations using 1,00010001,0001 , 000 in-distribution CIFAR10 image probes. Both find meaningful similarities, although in-distribution probes work better.

🔼 This figure illustrates the process of generating Text-Aligned ProbeLog representations. First, a set of pre-selected image probes are encoded using the CLIP image encoder, creating a set of probe embeddings. Then, at the time of inference, a target text prompt is provided and embedded using the same CLIP text encoder. The similarity between the text embedding and each of the stored probe embeddings is computed using cosine similarity. These similarity scores form a new descriptor, representing the target concept. Finally, this zero-shot ProbeLog descriptor is normalized to be comparable to ProbeLog descriptors of actual model logits. The normalization enables the effective retrieval of relevant model logits that recognize similar concepts to the input text prompt.
read the caption
Figure 5: Text-Aligned ProbeLog Representation. We present a method to create ProbeLog-like representations for text prompts. We encode and store each of our ordered probes using the CLIP image encoder. At inference time, we embed the target text prompt, and compute its similarity with respect to the stored probe representations. We demonstrate that by normalizing this zero-shot ProbeLog descriptor, we can effectively search descriptors of real model logits, accurately retrieving similar concepts.

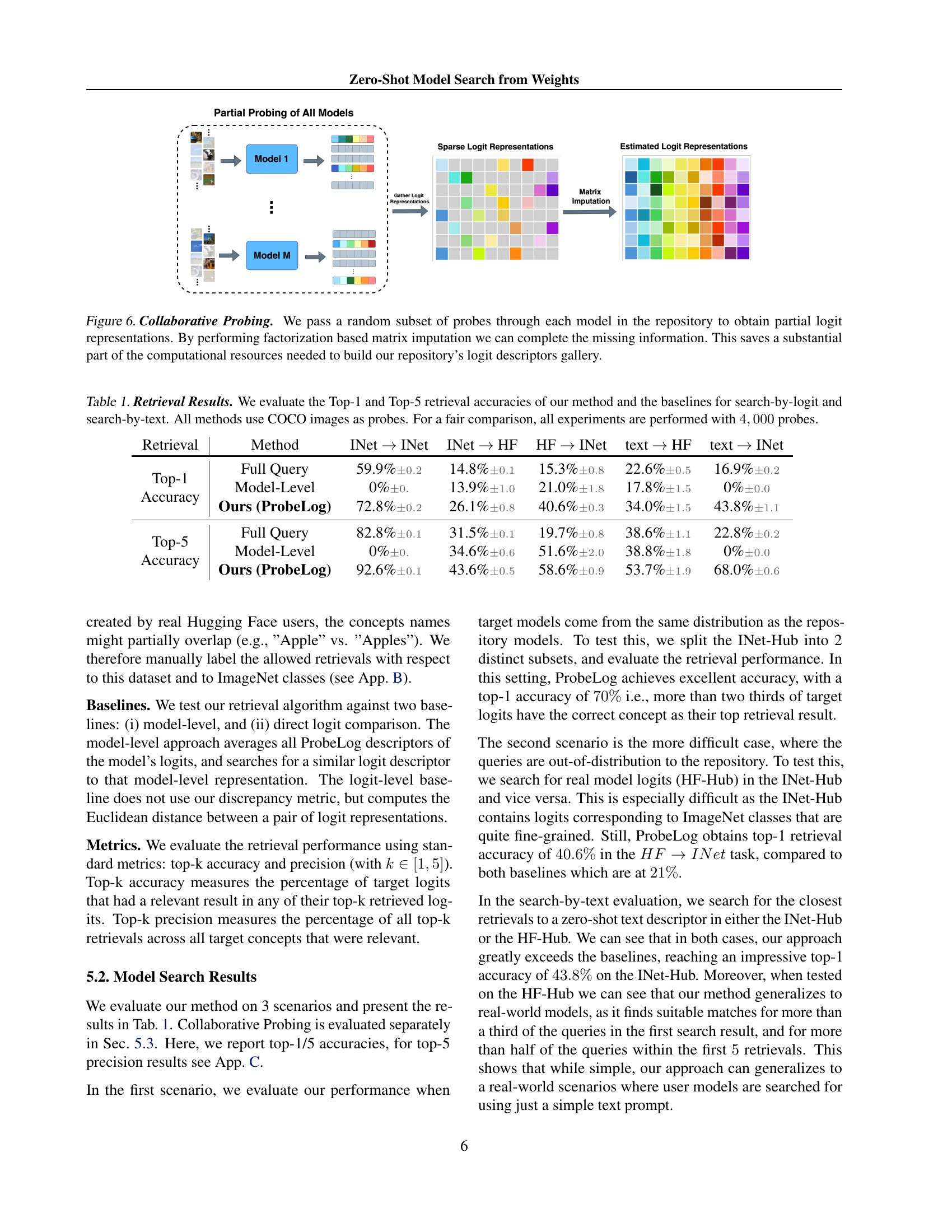
🔼 This figure illustrates the concept of collaborative probing, a technique to efficiently generate logit descriptors for a large model repository. Instead of running all probes through every model (which is computationally expensive), a random subset of probes is used for each model. This results in a sparse matrix of logit representations. Matrix factorization (specifically, truncated SVD) is then employed to impute the missing values, effectively reconstructing the complete matrix of logit descriptors. This method significantly reduces the computational cost compared to probing all models with all probes, making the process more scalable for large repositories.
read the caption
Figure 6: Collaborative Probing. We pass a random subset of probes through each model in the repository to obtain partial logit representations. By performing factorization based matrix imputation we can complete the missing information. This saves a substantial part of the computational resources needed to build our repository’s logit descriptors gallery.

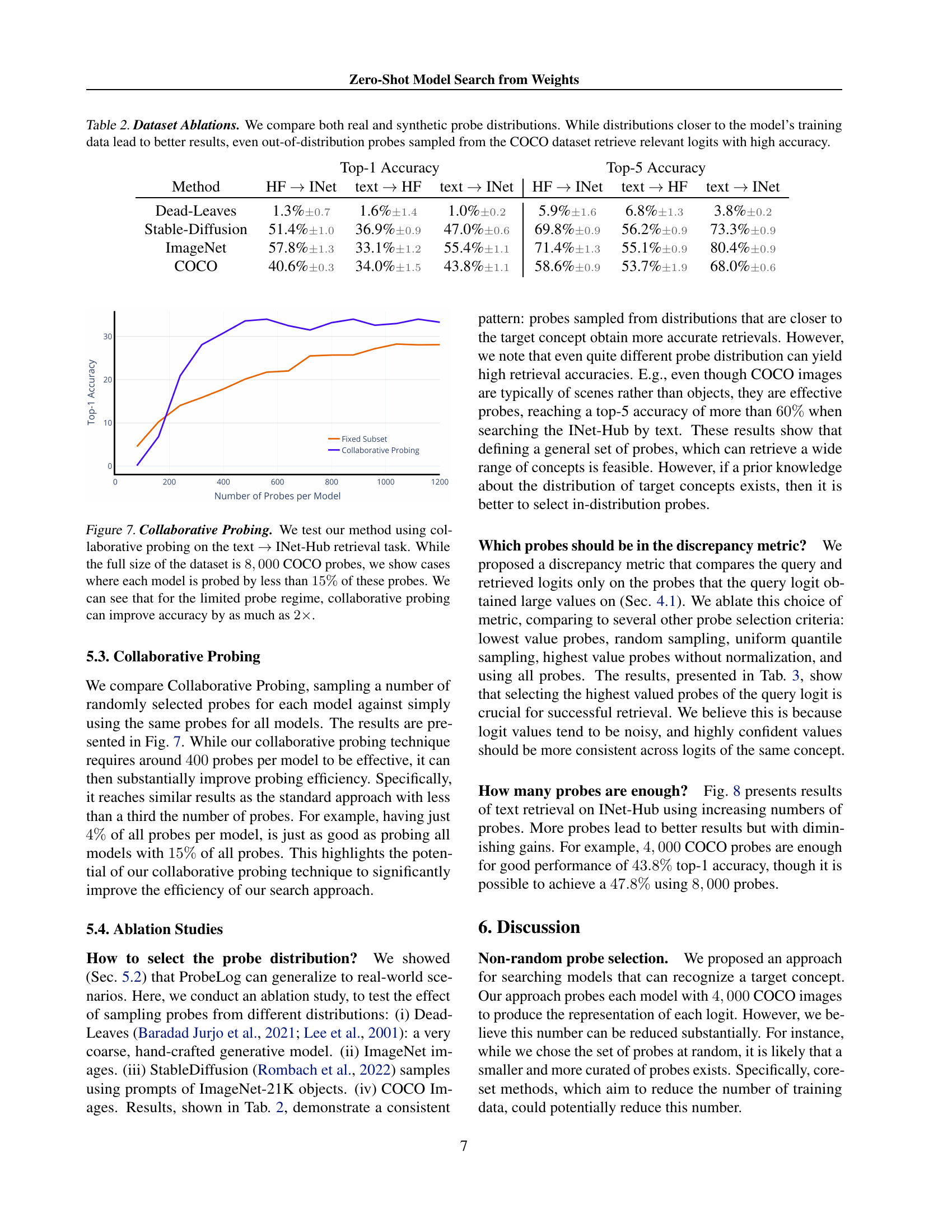
🔼 This figure demonstrates the effectiveness of Collaborative Probing, a technique to reduce the computational cost of creating ProbeLog representations. The experiment focuses on the text-based search task using the INet-Hub dataset. The standard approach uses 8000 COCO probes for each model. Collaborative Probing, however, uses significantly fewer probes (less than 15% of the 8000 probes) for each model. Despite this reduction, the figure shows that Collaborative Probing achieves comparable accuracy to the standard approach, often even doubling its accuracy for this limited probe regime.
read the caption
Figure 7: Collaborative Probing. We test our method using collaborative probing on the text →→\rightarrow→ INet-Hub retrieval task. While the full size of the dataset is 8,00080008,0008 , 000 COCO probes, we show cases where each model is probed by less than 15%percent1515\%15 % of these probes. We can see that for the limited probe regime, collaborative probing can improve accuracy by as much as 2×2\times2 ×.
More on tables
| Retrieval | Method | INet INet | INet HF | HF INet | text HF | text INet |
|---|---|---|---|---|---|---|
| Top-1 | Full Query | 59.9% | 14.8% | 15.3% | 22.6% | 16.9% |
| Accuracy | Model-Level | 0% | 13.9% | 21.0% | 17.8% | 0% |
| Ours (ProbeLog) | 72.8% | 26.1% | 40.6% | 34.0% | 43.8% | |
| Top-5 | Full Query | 82.8% | 31.5% | 19.7% | 38.6% | 22.8% |
| Accuracy | Model-Level | 0% | 34.6% | 51.6% | 38.8% | 0% |
| Ours (ProbeLog) | 92.6% | 43.6% | 58.6% | 53.7% | 68.0% |
🔼 This table presents an ablation study on the choice of probe datasets for the ProbeLog method. The study compares the performance of using different probe datasets, both real-world datasets (ImageNet, Stable Diffusion) and synthetic datasets (Dead Leaves, COCO), for retrieving relevant model logits. The results show that using probes from datasets closer to the models’ training data generally leads to better retrieval accuracy. However, even out-of-distribution probes sampled from the COCO dataset achieve surprisingly high accuracy, demonstrating the robustness of the proposed method.
read the caption
Table 2: Dataset Ablations. We compare both real and synthetic probe distributions. While distributions closer to the model’s training data lead to better results, even out-of-distribution probes sampled from the COCO dataset retrieve relevant logits with high accuracy.
| Top-1 Accuracy | Top-5 Accuracy | |||||
|---|---|---|---|---|---|---|
| Method | HF INet | text HF | text INet | HF INet | text HF | text INet |
| Dead-Leaves | 1.3% | 1.6% | 1.0% | 5.9% | 6.8% | 3.8% |
| Stable-Diffusion | 51.4% | 36.9% | 47.0% | 69.8% | 56.2% | 73.3% |
| ImageNet | 57.8% | 33.1% | 55.4% | 71.4% | 55.1% | 80.4% |
| COCO | 40.6% | 34.0% | 43.8% | 58.6% | 53.7% | 68.0% |
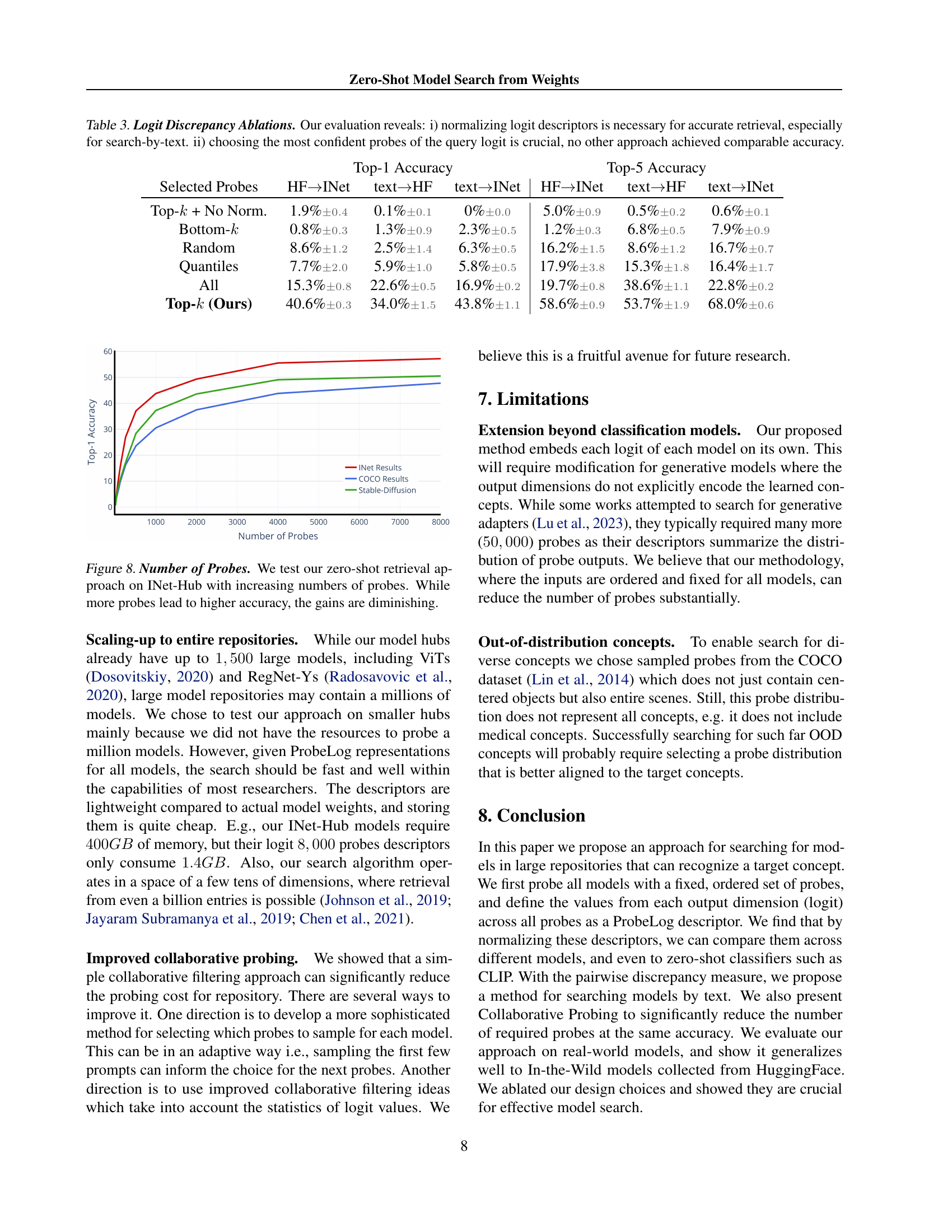
🔼 This table presents an ablation study on the choice of discrepancy metric used in ProbeLog for comparing logit-level descriptors. It investigates two key aspects: (i) the impact of normalizing logit descriptors before comparison, particularly for text-based search, and (ii) the effect of selecting only the most confident probes (those with the highest values) when calculating the discrepancy. The results demonstrate that normalizing logit descriptors is vital for good performance, especially for text-based searches, and that choosing the top-k most confident probes is far superior to other strategies. No other probe selection method achieved comparable accuracy.
read the caption
Table 3: Logit Discrepancy Ablations. Our evaluation reveals: i) normalizing logit descriptors is necessary for accurate retrieval, especially for search-by-text. ii) choosing the most confident probes of the query logit is crucial, no other approach achieved comparable accuracy.
| Top-1 Accuracy | Top-5 Accuracy | |||||
|---|---|---|---|---|---|---|
| Selected Probes | HFINet | textHF | textINet | HFINet | textHF | textINet |
| Top- + No Norm. | 1.9% | 0.1% | 0% | 5.0% | 0.5% | 0.6% |
| Bottom- | 0.8% | 1.3% | 2.3% | 1.2% | 6.8% | 7.9% |
| Random | 8.6% | 2.5% | 6.3% | 16.2% | 8.6% | 16.7% |
| Quantiles | 7.7% | 5.9% | 5.8% | 17.9% | 15.3% | 16.4% |
| All | 15.3% | 22.6% | 16.9% | 19.7% | 38.6% | 22.8% |
| Top- (Ours) | 40.6% | 34.0% | 43.8% | 58.6% | 53.7% | 68.0% |
🔼 Table 4 presents a comprehensive evaluation of the proposed ProbeLog method and baseline approaches for model retrieval. It shows the top-1 and top-5 retrieval accuracy and precision across different scenarios: INet-to-INet (models from the same distribution), INet-to-HF (models from different distributions), HF-to-INet (models from different distributions), text-to-INet, and text-to-HF. The results highlight the superior performance of ProbeLog in all scenarios, demonstrating its effectiveness in retrieving relevant models even when the query and model repositories originate from different distributions or when using zero-shot text-based search. All experiments use COCO images as probes, ensuring consistent evaluation.
read the caption
Table 4: Retrieval Results. We provide the additional Top-5 retrieval precisions of our method and the baselines, over several scenarios. All methods use COCO images as probes.
Full paper#