TL;DR#
Current encoder-based 3D Large Multimodal Models (LMMs) face challenges adapting to varying point cloud resolutions and aligning encoder features with LLMs’ semantic needs. These limitations hinder the advancement of multimodal understanding. This often leads to performance degradation and inefficient model usage.
This paper introduces ENEL, the first comprehensive study of encoder-free architectures for 3D LMMs. It proposes two key strategies to overcome these limitations: LLM-embedded Semantic Encoding and Hierarchical Geometry Aggregation. The paper presents a novel Hybrid Semantic Loss for more effective high-level semantic extraction during pre-training. ENEL achieves state-of-the-art results in 3D classification, captioning, and visual question answering tasks, demonstrating the potential of encoder-free architectures for efficient and adaptive 3D LMMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the conventional encoder-based approach in 3D Large Multimodal Models (LMMs), a dominant paradigm in the field. By demonstrating a viable encoder-free alternative, it opens new avenues for research, particularly in handling varying point cloud resolutions and aligning encoder features with the semantic needs of LLMs. This work directly contributes to improving the efficiency and adaptability of 3D LMMs, impacting various downstream applications. Its findings encourage future exploration into improving LLM efficiency and reducing the computational burden of current encoder-based 3D LMMs.
Visual Insights#

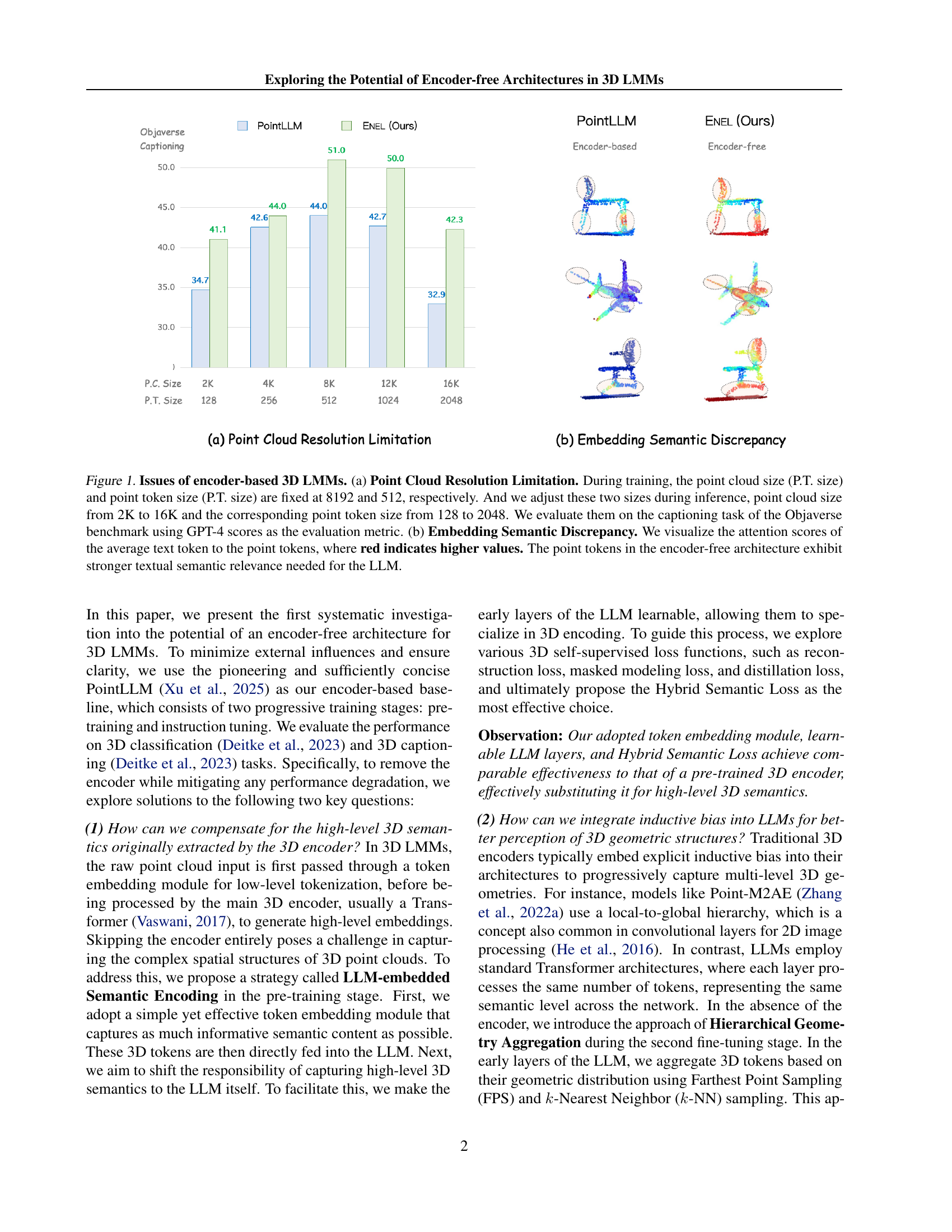
🔼 Figure 1 demonstrates the limitations of encoder-based 3D Large Multimodal Models (LMMs). Part (a) shows the impact of varying point cloud resolutions. During training, a fixed resolution (8192 points, 512 tokens) is used, but during inference, the resolution changes (2K-16K points, 128-2048 tokens). This mismatch causes a loss of information, significantly impacting performance as evaluated on the Objaverse captioning benchmark using GPT-4 scores. Part (b) illustrates the semantic mismatch between encoder embeddings and the LLM’s needs. By visualizing attention weights (red indicates stronger attention), it shows that an encoder-free architecture produces point tokens with stronger semantic relevance for the language model.
read the caption
Figure 1: Issues of encoder-based 3D LMMs. (a) Point Cloud Resolution Limitation. During training, the point cloud size (P.T. size) and point token size (P.T. size) are fixed at 8192 and 512, respectively. And we adjust these two sizes during inference, point cloud size from 2K to 16K and the corresponding point token size from 128 to 2048. We evaluate them on the captioning task of the Objaverse benchmark using GPT-4 scores as the evaluation metric. (b) Embedding Semantic Discrepancy. We visualize the attention scores of the average text token to the point tokens, where red indicates higher values. The point tokens in the encoder-free architecture exhibit stronger textual semantic relevance needed for the LLM.
| Method | Cls | Cap | |
| GPT-4 | GPT-4 | S-BERT | |
| PointLLM-7B | 53.00 | 44.85 | 47.47 |
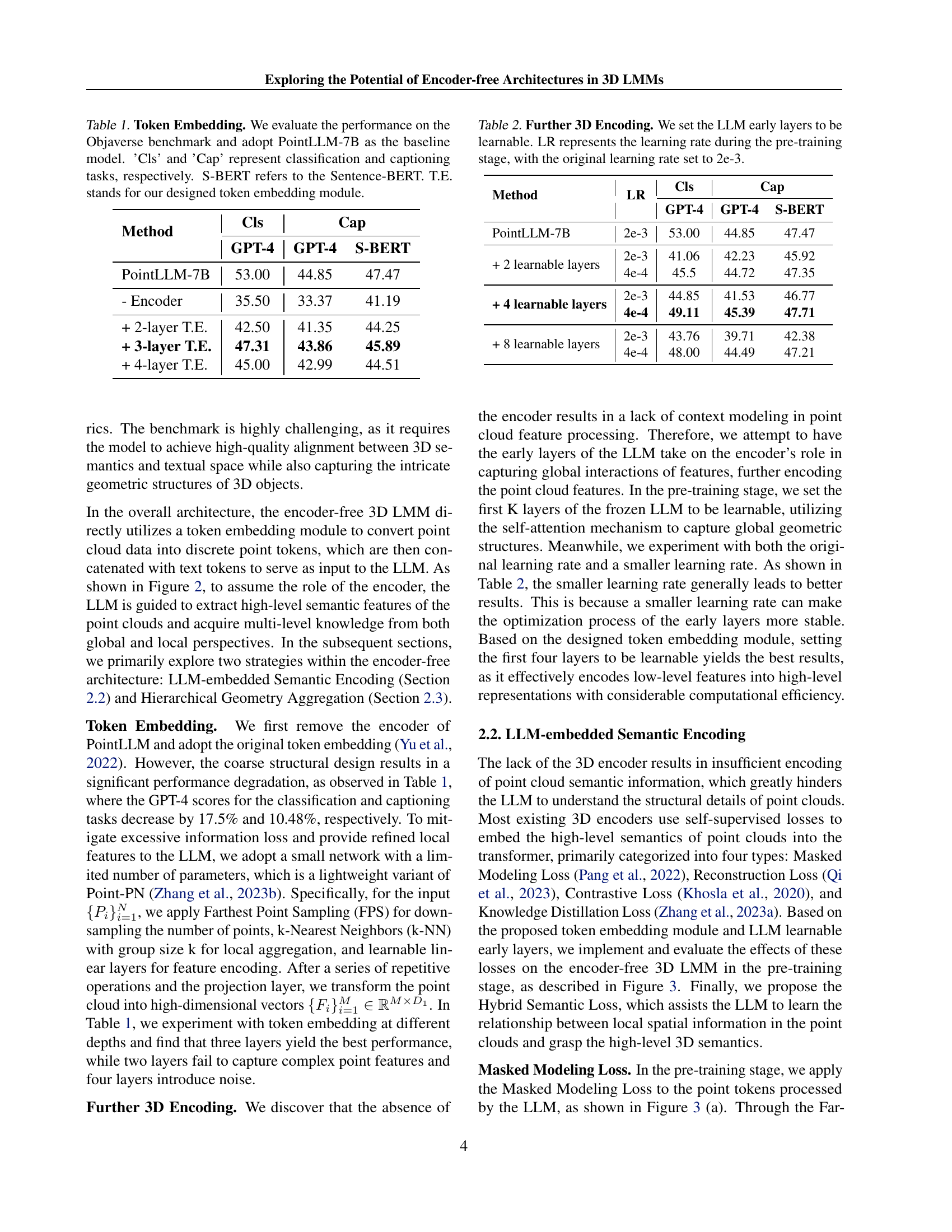
| - Encoder | 35.50 | 33.37 | 41.19 |
| + 2-layer T.E. | 42.50 | 41.35 | 44.25 |
| + 3-layer T.E. | 47.31 | 43.86 | 45.89 |
| + 4-layer T.E. | 45.00 | 42.99 | 44.51 |
🔼 This table presents a comparison of different token embedding methods for 3D Large Multimodal Models (LMMs) on the Objaverse benchmark. The baseline model used is PointLLM-7B. The performance is measured using two tasks: classification (‘Cls’) and captioning (‘Cap’). The results are evaluated using three metrics: GPT-4 scores, Sentence-BERT (S-BERT) scores, and a custom score. The table compares the baseline PointLLM-7B model with various versions that incorporate a custom designed token embedding module (‘T.E.’) with varying numbers of layers.
read the caption
Table 1: Token Embedding. We evaluate the performance on the Objaverse benchmark and adopt PointLLM-7B as the baseline model. ’Cls’ and ’Cap’ represent classification and captioning tasks, respectively. S-BERT refers to the Sentence-BERT. T.E. stands for our designed token embedding module.
In-depth insights#
Encoder-Free 3D LLMs#
Encoder-free 3D LLMs represent a significant departure from traditional encoder-based architectures. The core idea is to eliminate the need for a separate 3D encoder, which typically processes point cloud data into embeddings before feeding them to the Large Language Model (LLM). This approach directly integrates the 3D encoding function within the LLM, aiming to improve adaptability to varying point cloud resolutions and alleviate the semantic gap between encoder outputs and LLM requirements. Key challenges in realizing this include compensating for the loss of high-level 3D semantics usually extracted by encoders and integrating inductive biases for efficient 3D structure perception directly into the LLM. Solutions proposed often involve novel pre-training strategies, such as incorporating self-supervised losses that focus on semantic understanding within the LLM, and fine-tuning methodologies that introduce hierarchical geometry aggregation to capture local details. The potential benefits are substantial, including improved efficiency and flexibility, but the success heavily depends on effectively handling the aforementioned challenges.
Semantic Encoding#
The concept of semantic encoding in the context of 3D Large Multimodal Models (LMMs) is crucial for bridging the gap between raw point cloud data and the high-level semantic understanding required by Large Language Models (LLMs). Effective semantic encoding is paramount for enabling LLMs to interpret and reason about 3D scenes. The paper explores strategies to achieve this without relying on traditional 3D encoders, which often introduce limitations in terms of point cloud resolution adaptability and semantic alignment with LLMs. The proposed LLM-embedded Semantic Encoding strategy directly embeds semantic information within the LLM, leveraging self-supervised learning techniques to guide the LLM’s learning process. This innovative approach attempts to replace the role of the traditional 3D encoder, allowing the LLM itself to learn and extract meaningful 3D semantics. The study’s experiments show promising results, demonstrating the feasibility and potential of this encoder-free approach to improve the performance of 3D LMMs.
Geometric Aggregation#
The concept of ‘Geometric Aggregation’ in the context of 3D Large Multimodal Models (LMMs) addresses the challenge of incorporating inductive bias into LLMs for better 3D geometric structure perception. Traditional 3D encoders often embed this bias explicitly, but LLMs lack such inherent structure. The proposed strategy aims to compensate by introducing a hierarchical aggregation mechanism in the early LLM layers. This involves using techniques like farthest point sampling (FPS) and k-Nearest Neighbors (k-NN) to aggregate tokens based on geometric proximity, thereby mimicking the multi-level processing of traditional encoders. The integration of gated self-attention further enhances the process by adaptively focusing on relevant information. This hierarchical approach helps the LLM capture both local details and global relationships within the 3D point cloud, enabling more nuanced understanding. Experimental results showcase the effectiveness of this strategy, demonstrating improved performance on tasks requiring detailed 3D understanding. However, the optimal level of hierarchy requires careful tuning; excessive aggregation can lead to information loss, highlighting the need for a balanced approach that preserves both local and global contextual information.
ENEL Model Results#
An ‘ENEL Model Results’ section would ideally present a detailed analysis of the encoder-free 3D Large Multimodal Model’s performance across various tasks. It should begin by comparing ENEL’s results to existing state-of-the-art encoder-based models, highlighting any significant performance improvements or shortcomings. Key metrics such as accuracy, precision, recall, and F1-score for tasks like 3D classification, captioning, and visual question answering (VQA) should be meticulously reported. Furthermore, an ablation study demonstrating the impact of individual components, like the LLM-embedded semantic encoding strategy or hierarchical geometry aggregation, is crucial to validate the design choices. Error analysis should also be included, identifying specific types of inputs or tasks where ENEL struggles and suggesting potential areas for improvement. Finally, a discussion on the efficiency and scalability of ENEL compared to encoder-based methods would provide a complete picture of the model’s strengths and weaknesses, paving the way for future developments.
Future of Encoder-Free#
The “Future of Encoder-Free” architectures in 3D Large Multimodal Models (LMMs) is promising, but faces challenges. Encoder-free approaches offer potential advantages in handling varying point cloud resolutions and aligning embedding semantics with LLMs’ needs. However, successfully replacing encoders requires overcoming the inherent difficulty of capturing high-level 3D semantics and geometric structures directly within the LLM. Future research should focus on developing more sophisticated self-supervised learning strategies and inductive bias mechanisms integrated into LLMs. This might involve exploring novel loss functions tailored to 3D data or incorporating architectural modifications within the LLM to better process spatial information. Further investigation into efficient token embedding modules is crucial, as they are the direct interface between raw point cloud data and the LLM. Ultimately, the success of encoder-free 3D LMMs depends on achieving comparable or superior performance to encoder-based models while maintaining the benefits of simplicity and flexibility.
More visual insights#
More on figures

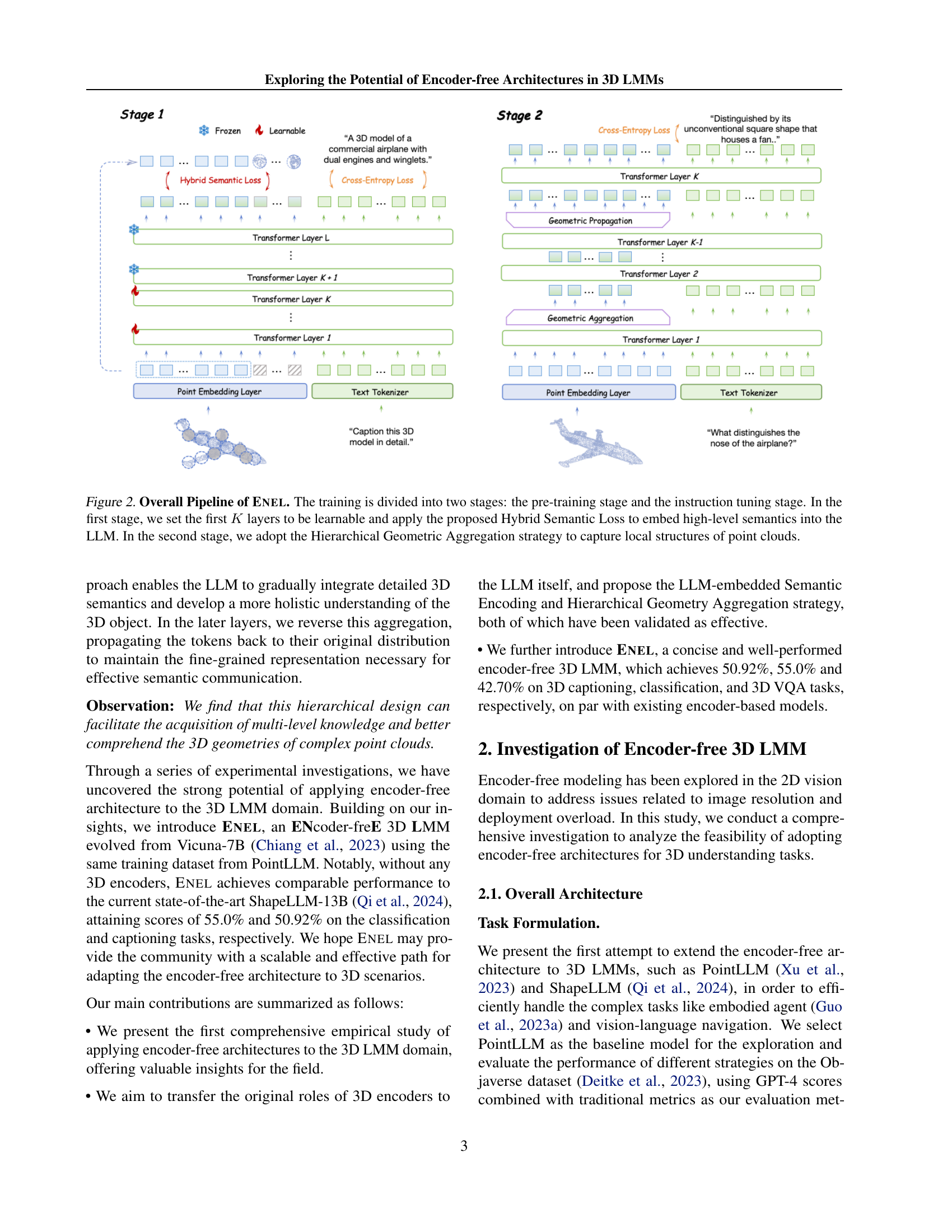
🔼 The figure illustrates the two-stage training pipeline of the ENEL model. Stage 1 (pre-training) focuses on embedding high-level 3D semantics into the LLM by making the first K layers learnable and utilizing the Hybrid Semantic Loss. Stage 2 (instruction tuning) employs the Hierarchical Geometric Aggregation strategy to enable the LLM to effectively capture the local geometric structures within the point cloud data.
read the caption
Figure 2: Overall Pipeline of Enel. The training is divided into two stages: the pre-training stage and the instruction tuning stage. In the first stage, we set the first K𝐾Kitalic_K layers to be learnable and apply the proposed Hybrid Semantic Loss to embed high-level semantics into the LLM. In the second stage, we adopt the Hierarchical Geometric Aggregation strategy to capture local structures of point clouds.

🔼 Figure 3 illustrates various self-supervised learning methods applied during the pre-training phase of an encoder-free 3D Large Multimodal Model (LMM). Subfigures (a) through (d) depict common approaches: Masked Modeling Loss, Reconstruction Loss, Contrastive Loss, and Knowledge Distillation Loss, respectively. Each method aims to learn high-level 3D semantic information from point cloud data without relying on a traditional 3D encoder. Subfigure (e) introduces a novel Hybrid Semantic Loss, specifically designed for this encoder-free architecture, combining aspects of the previous methods to achieve optimal performance.
read the caption
Figure 3: Point Cloud Self-Supervised Learning Losses. In the pre-training stage, we explore common self-supervised learning losses for the encoder-free 3D LMM: (a) Masked Modeling Loss, (b) Reconstruction Loss, (c) Contrastive Loss, and (d) Knowledge Distillation Loss. The (e) represents our proposed Hybrid Semantic Loss, specifically designed for the encoder-free architecture.

🔼 This figure illustrates the Hierarchical Geometry Aggregation strategy used in the instruction tuning stage of the ENEL model. The strategy aims to incorporate inductive bias into the LLM’s early layers, allowing it to focus on local details within the point cloud data. This is achieved through a series of aggregation and propagation operations applied to the point tokens. Aggregation combines information from neighboring points, effectively capturing local geometric structures. Propagation then spreads this aggregated information back to the original point tokens, ensuring that local details are integrated into the higher-level semantic understanding of the point cloud by the LLM.
read the caption
Figure 4: Hierarchical Geometry Aggregation Strategy. In the instruction tuning stage, we apply aggregation and propagation operations to the point tokens to capture the local structural details.

🔼 Figure 5 visualizes the attention weights between the average word embedding and point cloud embeddings for encoder-based (PointLLM) and encoder-free (ENEL) models. The heatmaps show the attention scores, with redder colors indicating stronger attention. The figure demonstrates how the encoder-free model attends more directly to semantically relevant parts of the 3D object, whereas the encoder-based model’s attention is more diffuse. Three object categories are shown: chairs (a), airplanes (b), and lamps (c), illustrating this difference in attention across various object types. The results support the claim that the encoder-free architecture achieves better semantic encoding.
read the caption
Figure 5: Difference in Semantic Encoding. By visualizing the attention scores of the average text token to the point tokens on the Objaverse dataset, we compare the semantic encoding potential of encoder-based and encoder-free architectures, where red indicates higher values. And (a) represents chairs, (b) represents airplanes, and (c) represents lamps.

🔼 Figure 6 illustrates three variations of self-supervised learning strategies used for point cloud data in the context of encoder-free 3D large multimodal models (LMMs). Each subfigure shows a different loss function applied during pre-training to embed high-level semantics into the language model without explicit 3D encoders: (a) Masked Modeling Loss: A portion of the point tokens are masked, and the model attempts to predict their values. (b) Reconstruction Loss: The model reconstructs the original point cloud from a learned representation. (c) Hybrid Semantic Loss: Combines Masked Modeling and Reconstruction Losses, aiming to capture both high-level semantic information and fine-grained geometric details.
read the caption
Figure 6: Variants of Point Cloud Self-Supervised Learning Losses. (a) The Variant of Masked Modeling Loss, (b) The Variant of Reconstruction Loss, (c) The Variant of Hybrid Semantic Loss.

🔼 Figure 7 showcases several examples of ENEL’s responses to various prompts involving 3D models. The prompts range from detailed descriptions to more specific questions requiring object recognition and property analysis. The examples demonstrate ENEL’s ability to produce both precise and varied answers, highlighting its capability for nuanced understanding and generation within the context of 3D multimodal data.
read the caption
Figure 7: Enel Output Examples. We demonstrate that Enel provides precise and diverse responses when addressing different problems.
More on tables
| Method | LR | Cls | Cap | |
| GPT-4 | GPT-4 | S-BERT | ||
| PointLLM-7B | 2e-3 | 53.00 | 44.85 | 47.47 |
| + 2 learnable layers | 2e-3 | 41.06 | 42.23 | 45.92 |
| 4e-4 | 45.5 | 44.72 | 47.35 | |
| + 4 learnable layers | 2e-3 | 44.85 | 41.53 | 46.77 |
| 4e-4 | 49.11 | 45.39 | 47.71 | |
| + 8 learnable layers | 2e-3 | 43.76 | 39.71 | 42.38 |
| 4e-4 | 48.00 | 44.49 | 47.21 | |
🔼 This table presents ablation study results on further 3D encoding by making early layers of the LLM learnable. It shows the impact of varying the number of learnable layers (2, 4, or 8) and learning rates (2e-3 and 4e-4) during pre-training on the performance of the model in terms of GPT-4 scores for classification and captioning tasks, as well as S-BERT scores. The original learning rate used is 2e-3. The results demonstrate how making the LLM layers learnable, in combination with adjustments to the learning rate, contributes to improved performance, effectively emulating a 3D encoder’s functionality within the LLM.
read the caption
Table 2: Further 3D Encoding. We set the LLM early layers to be learnable. LR represents the learning rate during the pre-training stage, with the original learning rate set to 2e-3.
| Method | Cls | Cap | |
| GPT-4 | GPT-4 | S-BERT | |
| PointLLM-7B | 53.00 | 44.85 | 47.47 |
| Masked Modeling LossΨ | 48.50 | 45.34 | 46.36 |
| Masked Modeling LossΦ | 50.00 | 46.80 | 47.29 |
| Masked Modeling LossΨ | 50.00 | 45.80 | 46.29 |
| Masked Modeling LossΦ | 49.50 | 47.35 | 47.93 |
| Reconstruction Loss | 49.50 | 46.96 | 47.33 |
| Reconstruction Loss | 48.50 | 45.95 | 47.18 |
| Contrastive Loss | 43.50 | 42.91 | 44.77 |
| Knowledge Distillation Loss | 49.50 | 45.43 | 47.09 |
| Hybrid Semantic Loss | 50.50 | 46.84 | 47.59 |
| Hybrid Semantic Loss | 52.00 | 48.51 | 48.06 |
| + Position Embedding | 53.00 | 48.85 | 48.00 |
🔼 This table presents results from experiments on different self-supervised learning methods used in the pre-training stage of the ENEL model. The goal was to determine how effectively these losses can help the language model learn high-level semantic representations of 3D point cloud data without an explicit encoder. The experiments involved variations of Masked Modeling Loss, Reconstruction Loss, Contrastive Loss, Knowledge Distillation Loss, and a novel Hybrid Semantic Loss. The results are shown in terms of the model’s performance on classification and captioning tasks, using GPT-4 and other metrics for evaluation. The mask ratio (proportion of tokens masked) is varied (30% and 60%) to assess its impact on performance. The Hybrid Semantic Loss combines masked modeling and reconstruction losses, targeting both point tokens and patches.
read the caption
Table 3: LLM-embedded Semantic Encoding. In the pre-training stage, we explore the effects of various self-supervised learning losses targeting point tokens. ΨΨ\Psiroman_Ψ represents a mask ratio of 60%, while ΦΦ\Phiroman_Φ represents a mask ratio of 30%. The subscript patch and feat represent the loss target. For Hybrid Semantic Loss, the subscript patch and feat represent the masked modeling target, while the reconstruction target is the corresponding feat and patch.
| Method | Cls | Cap | |
| GPT-4 | GPT-4 | S-BERT | |
| PointLLM-7B | 53.00 | 44.85 | 47.47 |
| =1 | 52.50 | 48.86 | 48.14 |
| =2 | 50.00 | 46.76 | 47.95 |
| =3 | 48.00 | 45.51 | 46.85 |
| =2 | 53.50 | 49.13 | 48.33 |
| =4 | 52.50 | 48.39 | 47.75 |
| =8 | 51.00 | 48.95 | 47.97 |
| + Self-Attn. | 55.00 | 50.92 | 48.61 |
🔼 This table presents ablation study results on the Hierarchical Geometry Aggregation strategy used in the instruction tuning stage of the ENEL model. It shows the impact of varying the number of aggregation and propagation operations (l), the number of LLM layers between these operations (H), and the inclusion of gated self-attention on the model’s performance. The results are evaluated using GPT-4 scores for classification and captioning tasks, along with Sentence-BERT and SimCSE metrics. This allows for a comprehensive analysis of how different architectural choices in the Hierarchical Geometry Aggregation affect the model’s ability to understand 3D geometric structures.
read the caption
Table 4: Hierarchical Geometry Aggregation. In the instruction tuning stage, we conduct the experiments of Hierarchical Geometry Aggregation strategy. l𝑙litalic_l represents the number of aggregation and propagation operations. H𝐻Hitalic_H refers to the LLM layers between l𝑙litalic_l aggregation and l𝑙litalic_l propagation operations. + Self-Attn. represents the incorporation of the gated self-attention in the aggregation.
| Model | Cap | Cls | QA | |||||
| GPT-4 | Sentence-BERT | SimCSE | BLEU-1 | ROUGE-L | METEOR | GPT-4 | GPT-4 | |
| InstructBLIP-7B (Dai et al., 2023) | 45.34 | 47.41 | 48.48 | 4.27 | 8.28 | 12.99 | 43.50 | – |
| InstructBLIP-13B (Dai et al., 2023) | 44.97 | 45.90 | 48.86 | 4.65 | 8.85 | 13.23 | 34.25 | – |
| LLaVA-7B (Liu et al., 2024) | 46.71 | 45.61 | 47.10 | 3.64 | 7.70 | 12.14 | 50.00 | – |
| LLaVA-13B (Liu et al., 2024) | 38.28 | 46.37 | 45.90 | 4.02 | 8.15 | 12.58 | 51.75 | 47.90 |
| 3D-LLM (Hong et al., 2023) | 33.42 | 44.48 | 43.68 | 16.91 | 19.48 | 19.73 | 45.25 | – |
| PointLLM-7B (Xu et al., 2023) | 44.85 | 47.47 | 48.55 | 3.87 | 7.30 | 11.92 | 53.00 | 41.20 |
| PointLLM-13B (Xu et al., 2023) | 48.15 | 47.91 | 49.12 | 3.83 | 7.23 | 12.26 | 54.00 | 46.60 |
| ShapeLLM-7B (Qi et al., 2024) | 46.92 | 48.20 | 49.23 | – | – | – | 54.50 | 47.40 |
| ShapeLLM-13B (Qi et al., 2024) | 48.94 | 48.52 | 49.98 | – | – | – | 54.00 | 53.10 |
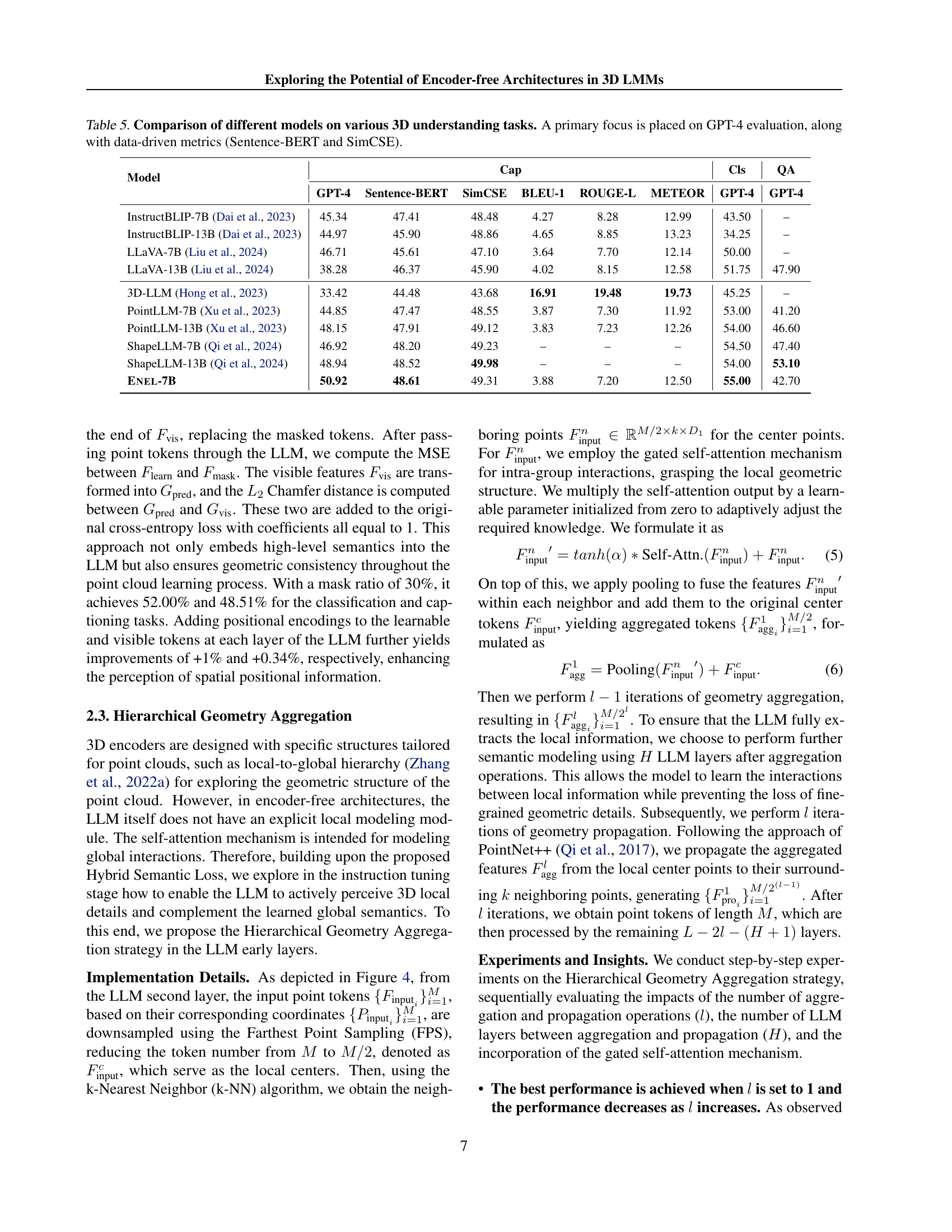
| Enel-7B | 50.92 | 48.61 | 49.31 | 3.88 | 7.20 | 12.50 | 55.00 | 42.70 |
🔼 Table 5 presents a comparative analysis of various models’ performance on diverse 3D understanding tasks. The primary evaluation metric is GPT-4 scores, providing a comprehensive assessment of the models’ ability to understand and generate human-quality text descriptions and answers related to 3D data. To complement the GPT-4 scores and offer a more nuanced perspective, the table also includes data-driven metrics such as Sentence-BERT and SimCSE scores, providing additional quantitative insights into the models’ performance.
read the caption
Table 5: Comparison of different models on various 3D understanding tasks. A primary focus is placed on GPT-4 evaluation, along with data-driven metrics (Sentence-BERT and SimCSE).
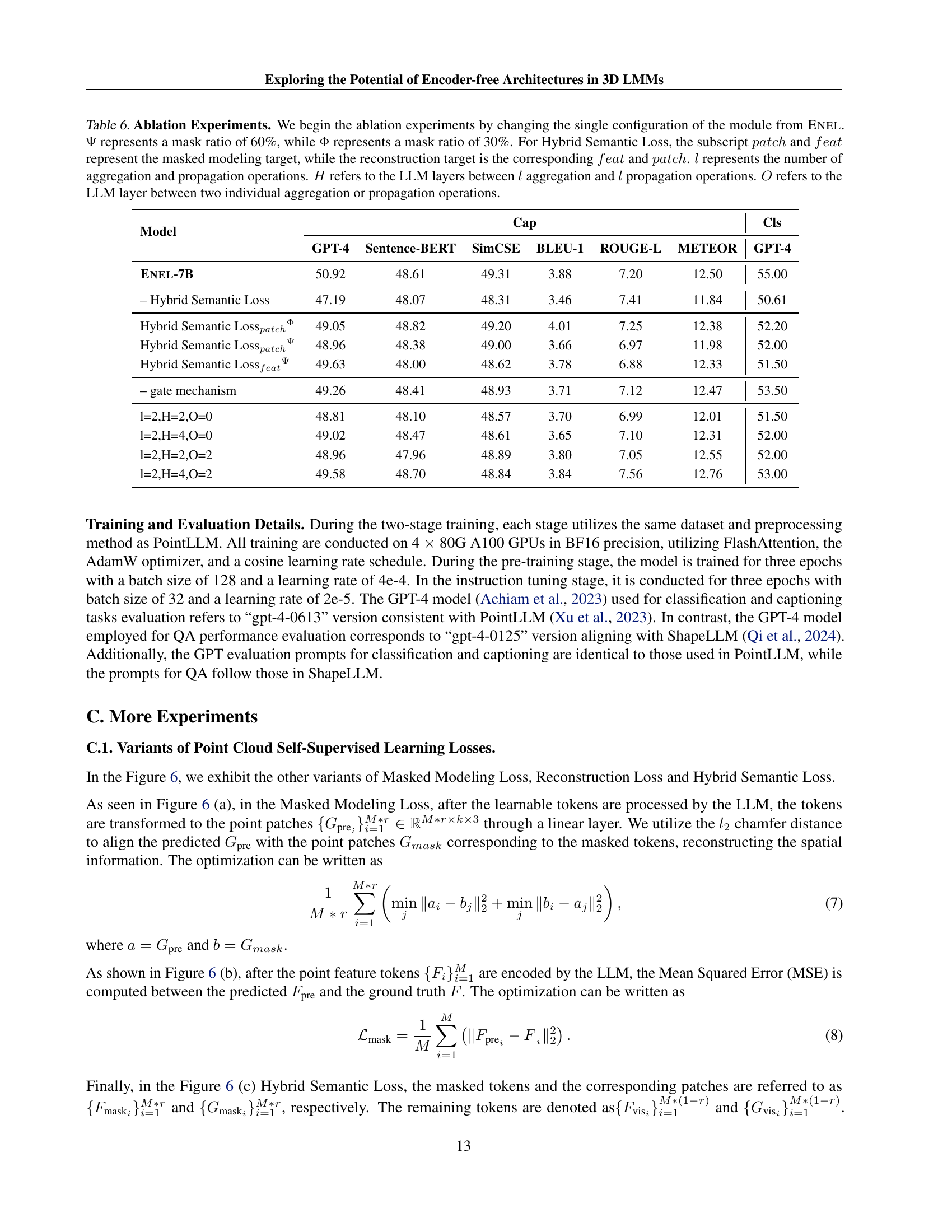
| Model | Cap | Cls | |||||
| GPT-4 | Sentence-BERT | SimCSE | BLEU-1 | ROUGE-L | METEOR | GPT-4 | |
| Enel-7B | 50.92 | 48.61 | 49.31 | 3.88 | 7.20 | 12.50 | 55.00 |
| – Hybrid Semantic Loss | 47.19 | 48.07 | 48.31 | 3.46 | 7.41 | 11.84 | 50.61 |
| Hybrid Semantic LosspatchΦ | 49.05 | 48.82 | 49.20 | 4.01 | 7.25 | 12.38 | 52.20 |
| Hybrid Semantic LosspatchΨ | 48.96 | 48.38 | 49.00 | 3.66 | 6.97 | 11.98 | 52.00 |
| Hybrid Semantic LossfeatΨ | 49.63 | 48.00 | 48.62 | 3.78 | 6.88 | 12.33 | 51.50 |
| – gate mechanism | 49.26 | 48.41 | 48.93 | 3.71 | 7.12 | 12.47 | 53.50 |
| l=2,H=2,O=0 | 48.81 | 48.10 | 48.57 | 3.70 | 6.99 | 12.01 | 51.50 |
| l=2,H=4,O=0 | 49.02 | 48.47 | 48.61 | 3.65 | 7.10 | 12.31 | 52.00 |
| l=2,H=2,O=2 | 48.96 | 47.96 | 48.89 | 3.80 | 7.05 | 12.55 | 52.00 |
| l=2,H=4,O=2 | 49.58 | 48.70 | 48.84 | 3.84 | 7.56 | 12.76 | 53.00 |
🔼 This table presents the results of ablation experiments conducted on the ENEL model. The experiments systematically removed or altered components of the model to assess their individual contributions to the overall performance. Specifically, it investigates the impact of different mask ratios (30% and 60%) in the Hybrid Semantic Loss, the effect of using only the patch or feature reconstruction targets within the loss function, and the influence of varying the number of hierarchical geometry aggregation and propagation operations and the number of layers within the LLM between these operations. The performance metrics across different variants are evaluated using GPT-4 scores for classification and captioning tasks, along with sentence-BERT and SimCSE metrics.
read the caption
Table 6: Ablation Experiments. We begin the ablation experiments by changing the single configuration of the module from Enel. ΨΨ\Psiroman_Ψ represents a mask ratio of 60%, while ΦΦ\Phiroman_Φ represents a mask ratio of 30%. For Hybrid Semantic Loss, the subscript patch𝑝𝑎𝑡𝑐ℎpatchitalic_p italic_a italic_t italic_c italic_h and feat𝑓𝑒𝑎𝑡featitalic_f italic_e italic_a italic_t represent the masked modeling target, while the reconstruction target is the corresponding feat𝑓𝑒𝑎𝑡featitalic_f italic_e italic_a italic_t and patch𝑝𝑎𝑡𝑐ℎpatchitalic_p italic_a italic_t italic_c italic_h. l𝑙litalic_l represents the number of aggregation and propagation operations. H𝐻Hitalic_H refers to the LLM layers between l𝑙litalic_l aggregation and l𝑙litalic_l propagation operations. O𝑂Oitalic_O refers to the LLM layer between two individual aggregation or propagation operations.
Full paper#