TL;DR#
Current benchmarks for evaluating large multimodal models (LMMs) are easily surpassed by rapid model advancements, leading to a lack of meaningful progress in the field. This paper highlights the urgent need for more challenging benchmarks to drive further innovation in visual understanding. Existing benchmarks quickly become obsolete, providing minimal headroom for improvement and failing to accurately assess the true capabilities of models.
To overcome this limitation, the researchers introduce ZeroBench, a new visual reasoning benchmark specifically designed to be currently impossible for top LMMs. It contains 100 manually curated, challenging questions, evaluated on 20 state-of-the-art LMMs, achieving a score of 0.0%. The detailed analysis of the models’ failures provides insights into the specific weaknesses of current visual understanding techniques. ZeroBench’s unique approach ensures its relevance for a longer time and challenges researchers to develop models with truly superior visual reasoning capabilities.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of benchmark stagnation in large multimodal models. Existing benchmarks are quickly solved, hindering meaningful progress. ZeroBench offers a much-needed solution by introducing an extremely difficult visual reasoning benchmark. This will spur innovation in visual understanding algorithms and improve the field’s long-term progress.
Visual Insights#

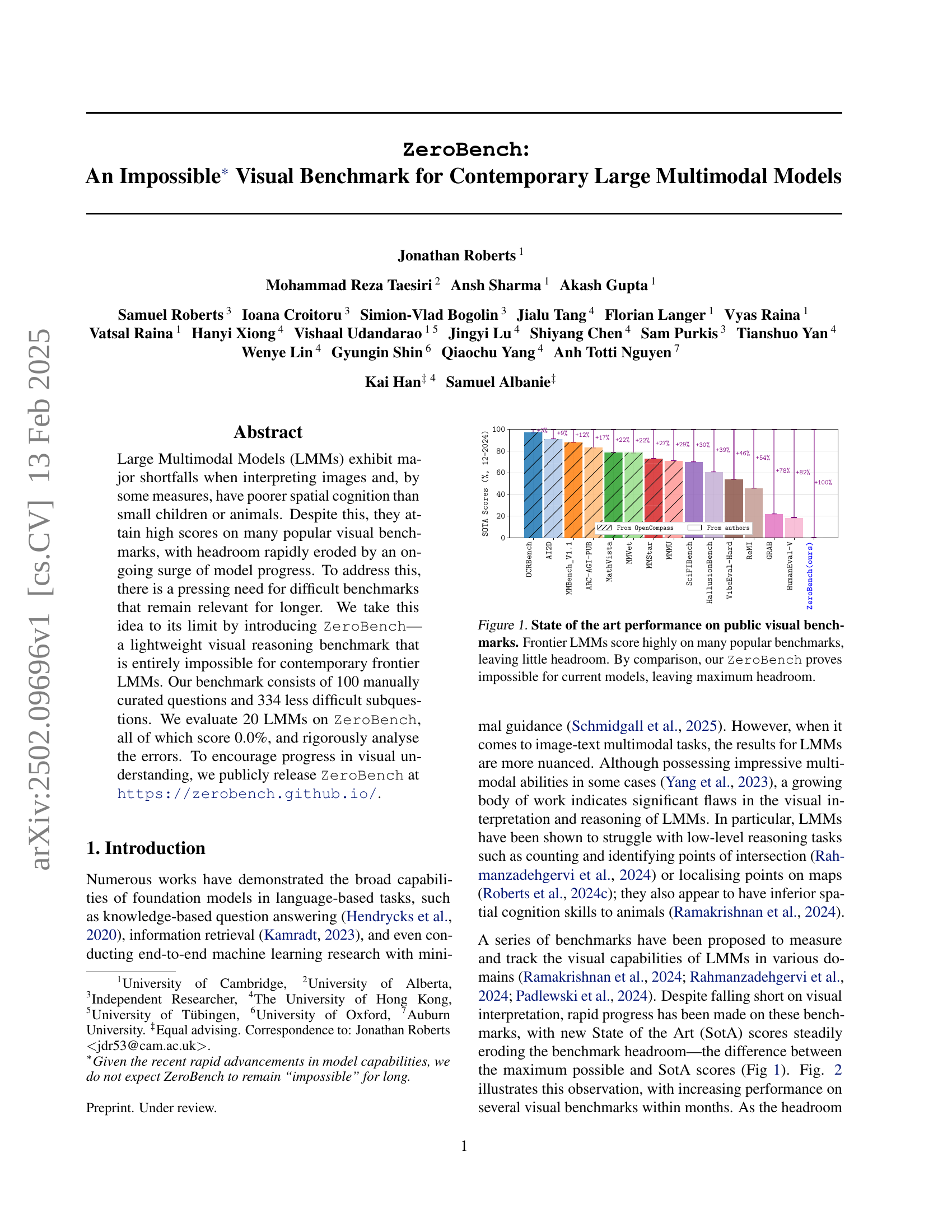
🔼 The figure displays the state-of-the-art performance of Large Multimodal Models (LMMs) on various public visual benchmarks. It showcases that while LMMs achieve high scores on many established benchmarks, the performance gains are rapidly diminishing, indicating that the benchmarks are becoming too easy and not effectively measuring true visual understanding capabilities. In contrast, the newly proposed ZeroBench benchmark demonstrates a significant challenge, as current LMMs score 0%, indicating there is ample room for improvement and a need for more challenging visual reasoning evaluations.
read the caption
Figure 1: State of the art performance on public visual benchmarks. Frontier LMMs score highly on many popular benchmarks, leaving little headroom. By comparison, our ZeroBench proves impossible for current models, leaving maximum headroom.
| Property | Amount |
|---|---|
| Questions | 100 |
| Subquestions | 334 |
| Subquestions per question | 3.3 |
| Single-image questions | 93 |
| Multi-image questions | 7 |
| Synthetic image questions | 31 |
| Natural image questions | 69 |
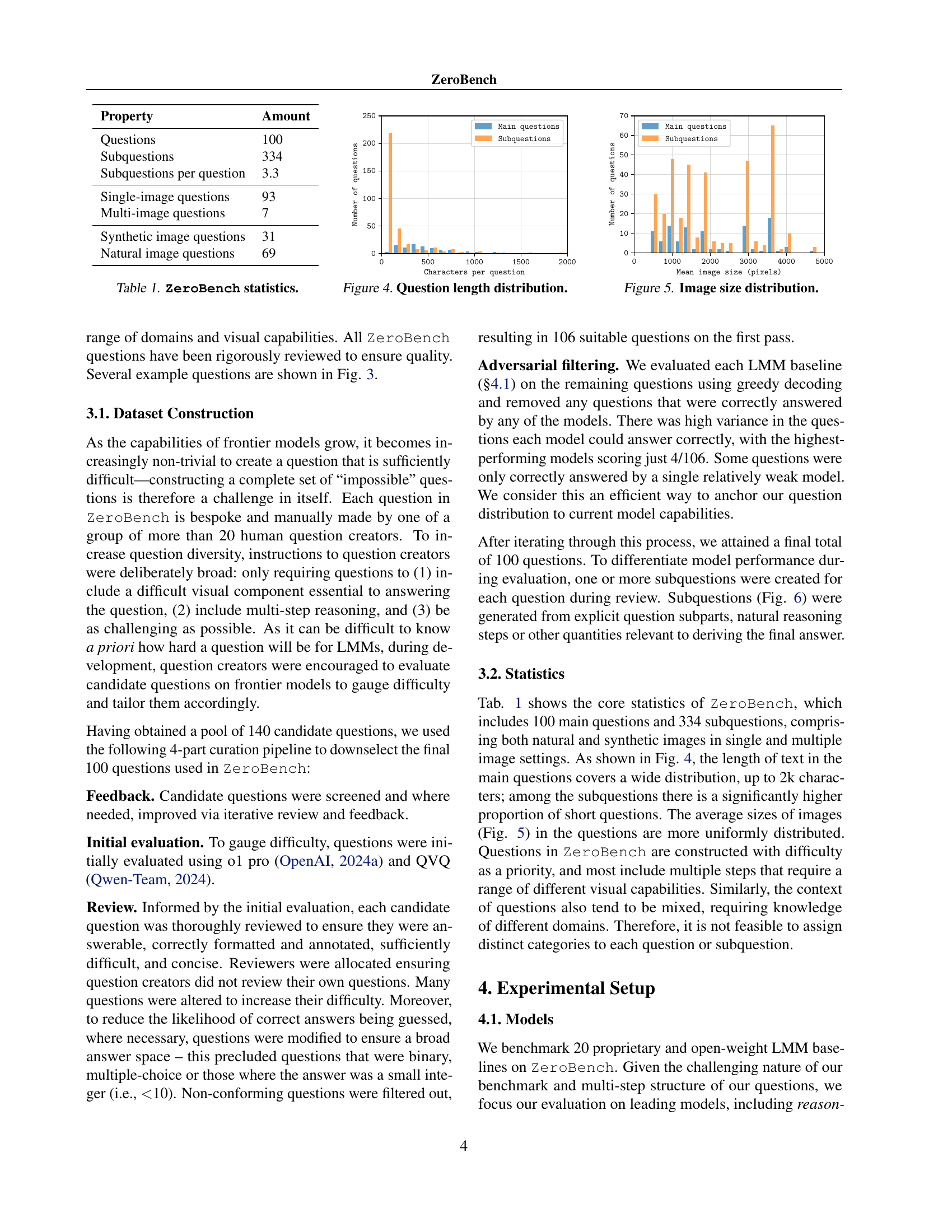
🔼 This table presents a summary of the key statistics for the ZeroBench dataset. It details the number of questions, subquestions, and the breakdown of question types based on the number of images involved (single vs. multi-image) and the image source (synthetic vs. natural). This provides a concise overview of the size and composition of the benchmark.
read the caption
Table 1: ZeroBench statistics.
In-depth insights#
Impossible Visual Benchmarks#
The concept of “Impossible Visual Benchmarks” in the context of large multimodal models (LMMs) presents a compelling argument for pushing the boundaries of current AI capabilities. Creating benchmarks that are genuinely challenging, yet still relevant to real-world applications, is crucial for fostering meaningful progress. Current benchmarks often show rapid improvement, quickly reaching a point where they become less informative. An “impossible” benchmark, initially unsolvable by state-of-the-art models, addresses this by providing a significant margin for advancement, encouraging the development of novel techniques, and promoting longer-term research. However, the challenge lies in designing such benchmarks that remain relevant and avoid becoming overly specialized or artificial. The difficulty must be intrinsic to the nature of visual understanding itself, rather than a result of clever, but ultimately unproductive, obfuscation. A truly “impossible” benchmark serves as a powerful catalyst, incentivizing research into areas like robust spatial reasoning, low-level visual interpretation, and improved common sense understanding, ultimately leading to more capable and reliable LMMs.
LMM Visual Reasoning#
Large Multimodal Models (LMMs) demonstrate significant potential in visual reasoning tasks, but their performance is often surprisingly limited. Current benchmarks frequently show high scores for LMMs, which may not reflect true capabilities because of issues such as dataset bias, headroom erosion due to rapid model advancements, and the possibility that benchmark designs are not sufficiently challenging. The development of more difficult, comprehensive, and reliable benchmarks is thus crucial to assess true visual understanding. This necessitates a shift away from focusing solely on easily attainable scores and emphasizing deeper evaluation that examines the nuances of LMM reasoning processes. In-depth error analysis is also critical, as it reveals common failure patterns (such as difficulties in handling fine-grained visual details or performing multi-step reasoning) and provides insights into the limitations and biases of current models. By overcoming these issues and creating rigorous evaluation methodologies, we can better understand and improve LMMs’ visual reasoning capabilities.
ZeroBench: Design & Eval#
The hypothetical section, ‘ZeroBench: Design & Eval,’ would delve into the meticulous creation and rigorous evaluation of the ZeroBench benchmark. The design would be discussed in detail, highlighting its unique characteristics, such as its focus on tasks deemed “impossible” for current large multimodal models (LMMs), its lightweight nature, enabling efficient evaluation despite its high difficulty, and its deliberate construction to avoid biases or label errors that plague other benchmarks. The evaluation process would be carefully detailed, explaining the selection of 20 diverse LMMs, the evaluation metrics used, and the strategies for analyzing both the overall performance and the specific error modes of the models. This analysis is crucial because it would uncover inherent weaknesses in current LMMs visual understanding and reasoning capabilities, paving the way for future improvements. The authors likely provide examples of common failure modes to illustrate the challenges posed by ZeroBench and suggest areas where models struggle. Overall, this section aims to present a compelling argument for ZeroBench as a superior benchmark, moving beyond simple quantitative results and offering qualitative insights into the current state and future trajectory of LMM development.
Error Analysis: Insights#
A dedicated ‘Error Analysis: Insights’ section would be crucial to understanding the paper’s core contribution. It should delve into why contemporary Large Multimodal Models (LMMs) fail on the ZeroBench, moving beyond simple accuracy scores. This necessitates a detailed qualitative analysis, presenting specific examples of model failures and categorizing them into distinct error types (e.g., visual interpretation errors, reasoning errors, spatial reasoning errors). Visual examples highlighting these errors, possibly with side-by-side comparisons of model outputs and ground truth, would significantly strengthen the analysis. The section should also examine the frequency of these error types, providing statistical insights into the models’ predominant weaknesses. Finally, linking these error patterns to inherent limitations in current LMM architectures, such as attention mechanisms or training data biases, would be essential for a complete and insightful error analysis.
Future of Visual AI#
The future of visual AI hinges on addressing current limitations. Robustness and generalization remain crucial, as current models struggle with variations in style, viewpoint, and lighting not seen in training data. Improved reasoning capabilities are vital for truly intelligent vision systems; current models often fail to interpret complex scenes or solve visual puzzles requiring multiple steps. Bridging the gap between perception and action is essential for applications like robotics and autonomous vehicles. This requires more sophisticated integration of visual data with other sensory inputs and enhanced decision-making processes. Ethical concerns related to bias, privacy, and misuse must be proactively addressed throughout the development cycle. Explainability is key to building trust and accountability in visual AI systems. We need better understanding of how these models reach their conclusions. Finally, efficient and scalable solutions will be critical for widespread adoption, especially considering the computational demands of advanced models.
More visual insights#
More on figures

🔼 The figure shows a line graph illustrating the rapid improvement in the state-of-the-art performance on several visual benchmarks throughout 2024. Each line represents a different benchmark, showing the increase in the highest-achieved score (SOTA) over time. The graph highlights the rapid reduction in benchmark headroom (the gap between perfect performance and the SOTA score), indicating that many existing benchmarks are becoming too easy for current large multimodal models.
read the caption
Figure 2: Rapid progress was made on visual benchmarks last year. Compiled from (OpenCompass Contributors, 2023).
🔼 Figure 3 showcases three example questions from the ZeroBench benchmark, each accompanied by its corresponding answer and a brief explanation. The questions require multi-step reasoning and visual interpretation to solve, highlighting the challenging nature of the benchmark. ZeroBench consists of 100 similar manually-curated questions designed to be impossible for current Large Multimodal Models (LMMs). These examples represent the diverse range of reasoning abilities and visual interpretation skills needed to answer ZeroBench questions.
read the caption
Figure 3: Example ZeroBench questions and answers††. Our benchmark contains 100 of these challenging questions.

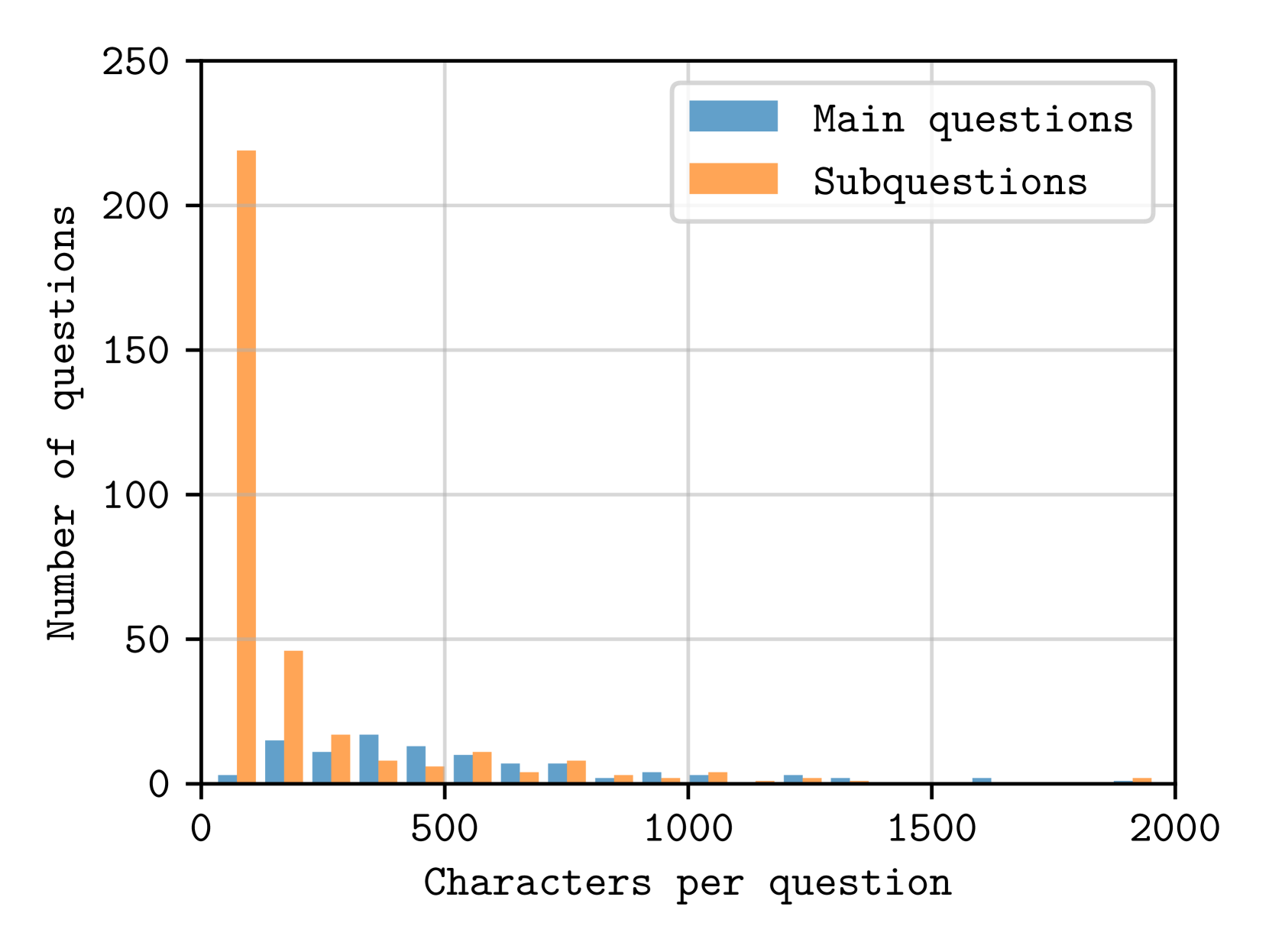
🔼 This histogram shows the distribution of question lengths in the ZeroBench dataset. The x-axis represents the length of a question in terms of the number of characters, and the y-axis shows the frequency of questions with that length. The distribution is heavily skewed towards shorter questions, with a long tail indicating that a small number of questions contain many more characters.
read the caption
Figure 4: Question length distribution.
More on tables
| Main questions (100) | Subquestions (334) | |||||
| k/k [%] (n) | pass@k [%] (n) | pass@k [%] () | Num. correct | |||
| Models | k=5 | k=1 | k=5 | k=1 | k=1 | |
| Reasoning LMMs | ||||||
| o1 pro⋄ | 0.0 (0) | 0.0 (0) | - | 22.40 (2.48) | 75 | |
| o1⋄ | 0.0 (0) | 0.0 (0) | 0.0 (0) | 19.93 (2.37) | 68 | |
| Gemini 2 Flash Thinking | 0.0 (0) | 0.0 (0) | 7.0 (7) | 19.67 (2.67) | 67 | |
| QVQ | 0.0 (0) | 0.0 (0) | 3.0 (3) | 19.78 (2.42) | 66 | |
| Proprietary LMMs | ||||||
| GPT-4o | 0.0 (0) | 0.0 (0) | 1.0 (1) | 21.18 (2.46) | 71 | |
| GPT-4o mini | 0.0 (0) | 0.0 (0) | 2.0 (2) | 16.98 (2.50) | 55 | |
| Gemini 2 Flash | 0.0 (0) | 0.0 (0) | 3.0 (3) | 22.47 (2.80) | 74 | |
| Gemini 1.5 Pro | 0.0 (0) | 0.0 (0) | 2.0 (2) | 20.25 (2.55) | 70 | |
| Gemini 1.5 Flash | 0.0 (0) | 0.0 (0) | 2.0 (2) | 18.02 (2.47) | 63 | |
| Gemini 1 Pro Vision | 0.0 (0) | 0.0 (0) | 1.0 (1) | 12.17 (2.19) | 44 | |
| Claude 3.5 Sonnet v2 | 0.0 (0) | 0.0 (0) | 2.0 (2) | 24.30 (2.73) | 81 | |
| Claude 3.5 Sonnet | 0.0 (0) | 0.0 (0) | 1.0 (1) | 19.73 (2.49) | 68 | |
| Claude 3 Opus | 0.0 (0) | 0.0 (0) | 0.0 (0) | 14.50 (2.27) | 46 | |
| Claude 3 Sonnet | 0.0 (0) | 0.0 (0) | 1.0 (1) | 16.25 (2.33) | 49 | |
| Claude 3 Haiku | 0.0 (0) | 0.0 (0) | 0.0 (0) | 12.12 (2.11) | 40 | |
| Reka Edge | 0.0 (0) | 0.0 (0) | 1.0 (1) | 3.38 (0.97) | 12 | |
| Open-weight LMMs | ||||||
| Llama 3.2 90B | 0.0 (0) | 0.0 (0) | 0.0 (0) | 13.07 (1.97) | 47 | |
| Qwen2-VL-72B-Instruct | 0.0 (0) | 0.0 (0) | 2.0 (2) | 11.90 (2.24) | 37 | |
| NVLM-D-72B | 0.0 (0) | 0.0 (0) | 1.0 (1) | 13.78 (2.32) | 46 | |
| Pixtral-Large | 0.0 (0) | 0.0 (0) | 3.0 (3) | 13.50 (2.01) | 49 | |
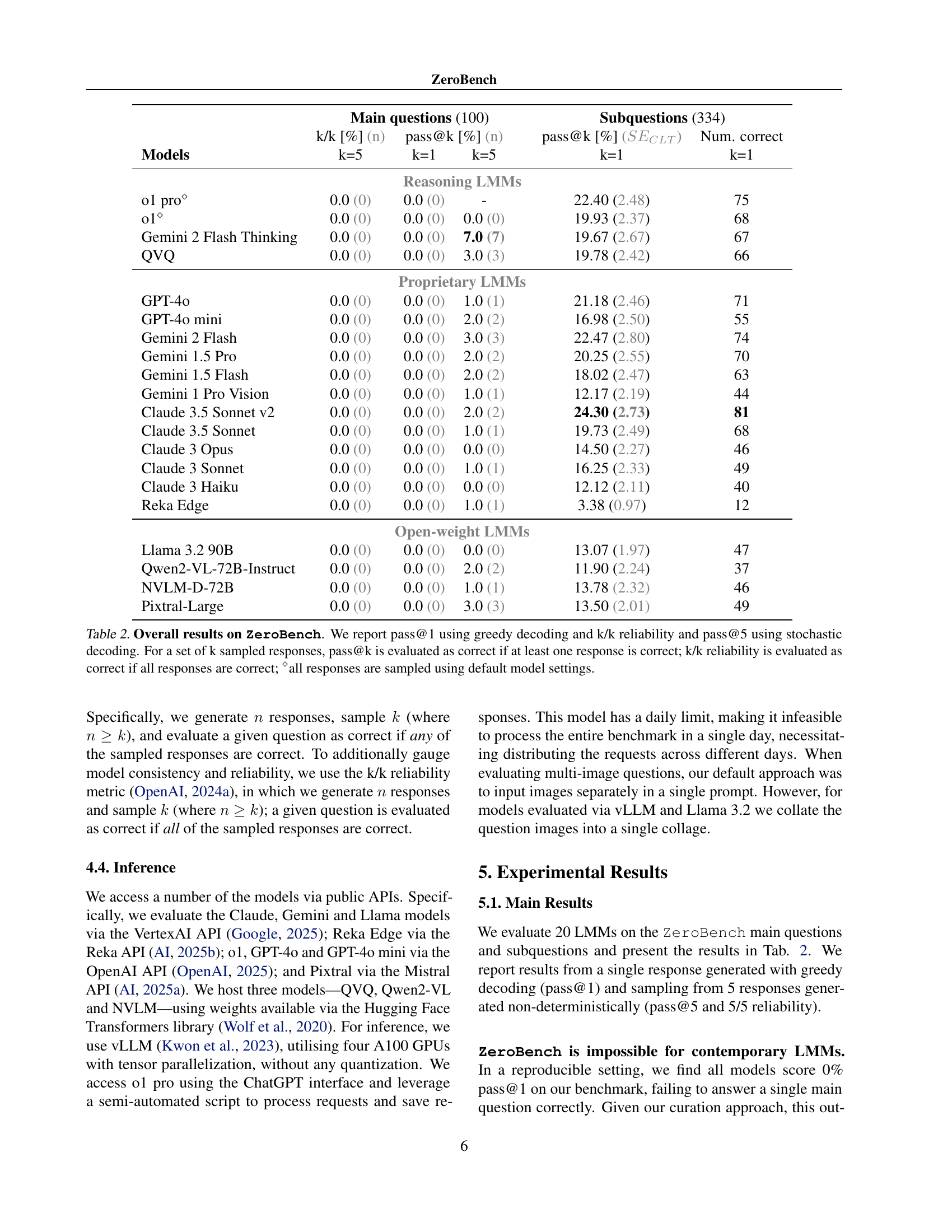
🔼 This table presents the performance of 20 different large multimodal models (LMMs) on the ZeroBench benchmark. ZeroBench is a challenging visual reasoning benchmark designed to be difficult even for state-of-the-art models. The table shows the accuracy of each model on two different metrics: pass@1 (using greedy decoding, indicating if the model gets the answer correct in the first try) and pass@k (using stochastic decoding, indicating if the model gets the answer correct in any of the k sampled responses). It also includes k/k reliability (which indicates if all k responses are correct). The results demonstrate that none of the models perform well on the primary questions of ZeroBench, highlighting the difficulty of the benchmark.
read the caption
Table 2: Overall results on ZeroBench. We report pass@1 using greedy decoding and k/k reliability and pass@5 using stochastic decoding. For a set of k sampled responses, pass@k is evaluated as correct if at least one response is correct; k/k reliability is evaluated as correct if all responses are correct; ⋄all responses are sampled using default model settings.
| Avg. per question | ||||
| Main questions | Subquestions | |||
| Model | #tkns | Cost ($)∗ | #tkns | Cost ($)∗ |
| Reasoning LMMs | ||||
| o1 pro⋄ | - | - | - | |
| o1⋄ | 7345 | 0.463 | 3749 | 0.236 |
| Gemini 2 Flash Thinking∗∗ | 520 | - | 228 | - |
| QVQ | 2794 | 0.003 | 1741 | 0.002 |
| Proprietary LMMs | ||||
| GPT-4o | 452 | 0.005 | 228 | 0.002 |
| GPT-4o mini | 896 | 0.001 | 214 | 0.001 |
| Gemini 2 Flash | 1267 | 0.013 | 490 | 0.005 |
| Gemini 1.5 Pro | 266 | 0.002 | 114 | 0.001 |
| Gemini 1.5 Flash | 276 | 0.001 | 122 | 0.001 |
| Gemini 1 Pro Vision | 211 | 0.001 | 99 | 0.001 |
| Claude 3.5 Sonnet v2 | 254 | 0.004 | 163 | 0.003 |
| Claude 3.5 Sonnet | 294 | 0.005 | 217 | 0.003 |
| Claude 3 Opus | 267 | 0.021 | 168 | 0.013 |
| Claude 3 Sonnet | 279 | 0.004 | 175 | 0.003 |
| Claude 3 Haiku | 315 | 0.001 | 132 | 0.001 |
| Reka Edge∗∗ | 514 | - | 189 | - |
| Open-weight LMMs | ||||
| Llama 3.2 90B | 663 | 0.001 | 264 | 0.001 |
| Qwen2-VL-72B-Instruct | 457 | 0.001 | 476 | 0.001 |
| NVLM-D-72B∗∗ | 389 | - | 151 | - |
| Pixtral-Large | 553 | 0.001 | 279 | 0.001 |
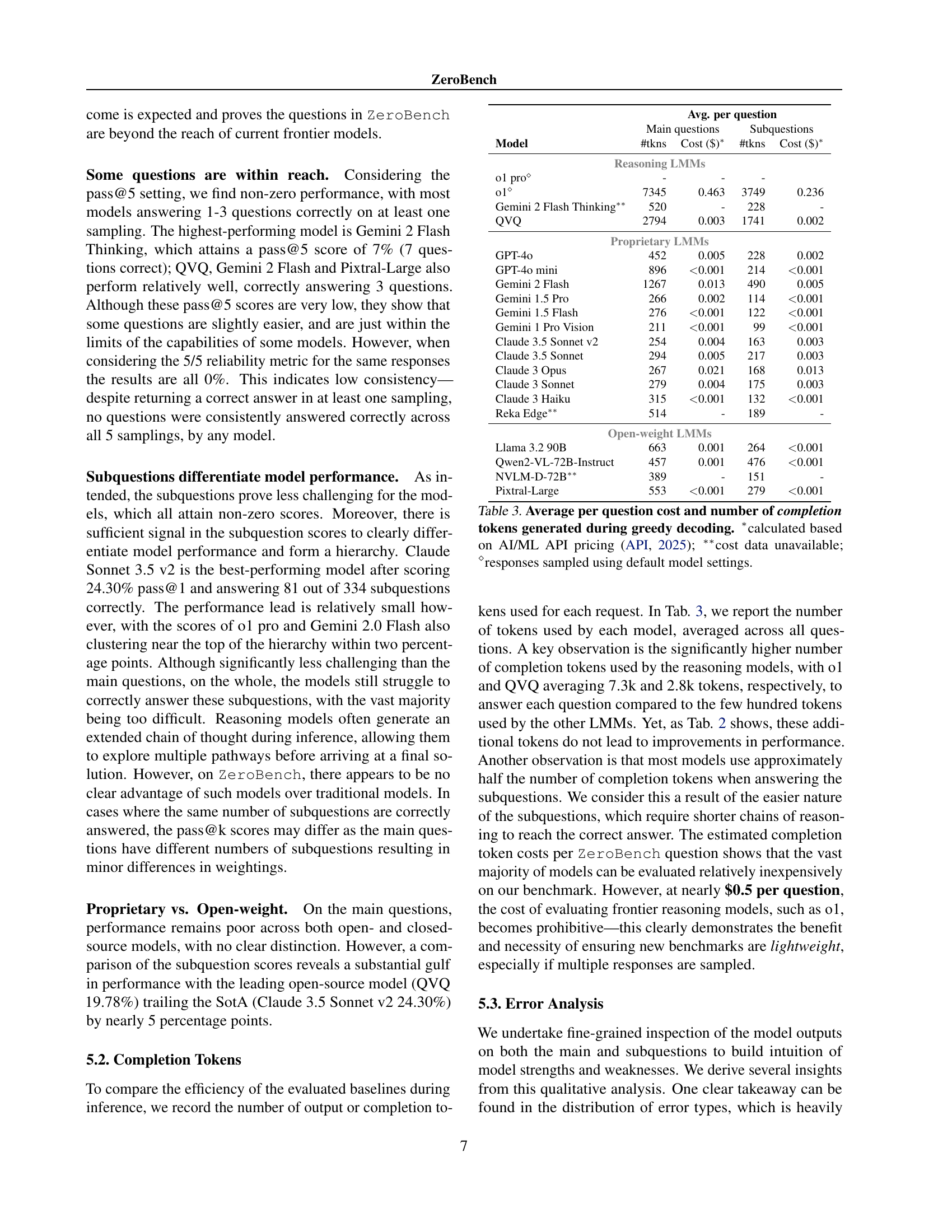
🔼 This table presents the average cost and the number of tokens used for each model during inference using greedy decoding. The cost is calculated based on the pricing of various AI/ML APIs, as of 2025. Note that cost data was unavailable for certain models. The table also indicates that the responses were generated using the default hyperparameters for each model.
read the caption
Table 3: Average per question cost and number of completion tokens generated during greedy decoding. ∗calculated based on AI/ML API pricing (API, 2025); ∗∗cost data unavailable; ⋄responses sampled using default model settings.
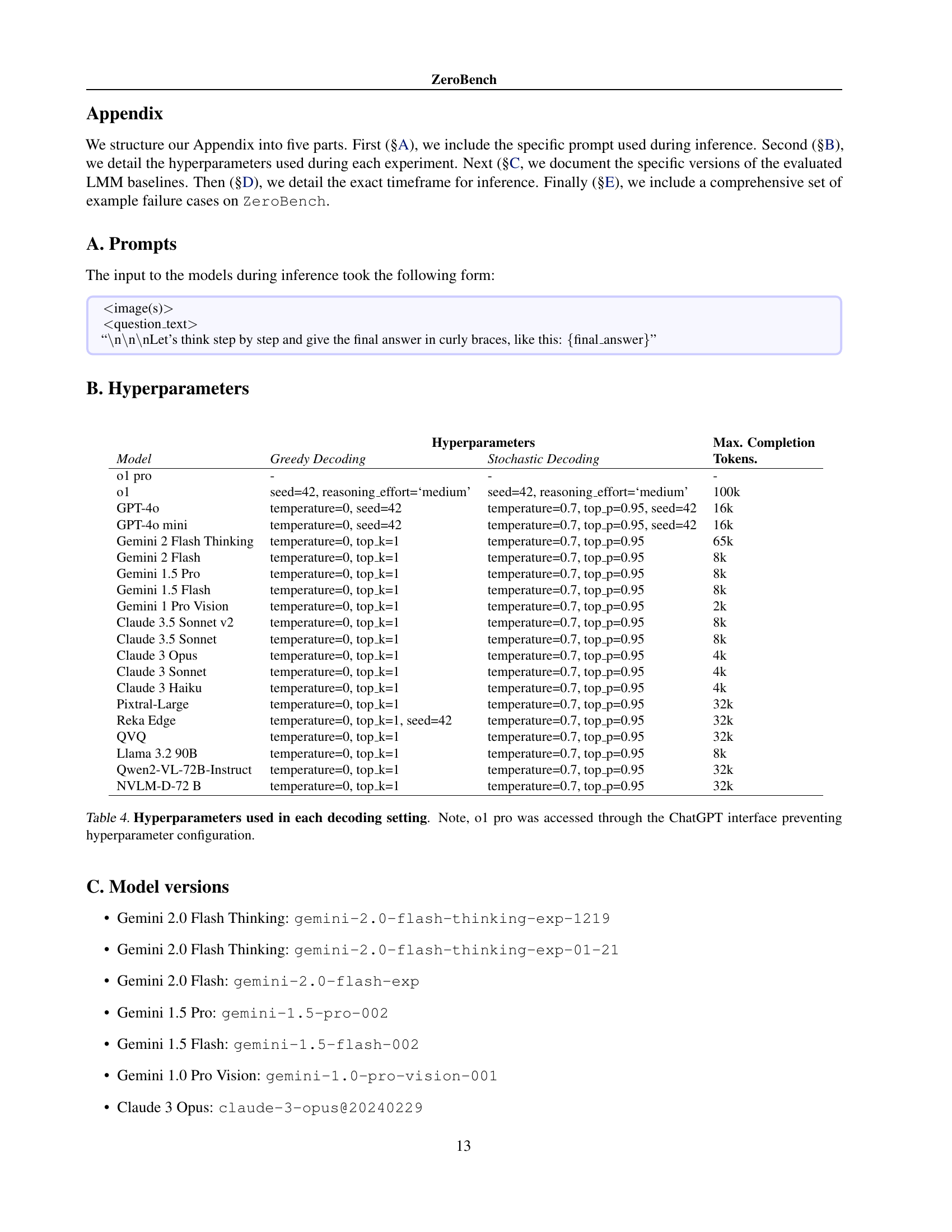
| Hyperparameters | Max. Completion | ||
|---|---|---|---|
| Model | Greedy Decoding | Stochastic Decoding | Tokens. |
| o1 pro | - | - | - |
| o1 | seed=42, reasoning_effort=‘medium’ | seed=42, reasoning_effort=‘medium’ | 100k |
| GPT-4o | temperature=0, seed=42 | temperature=0.7, top_p=0.95, seed=42 | 16k |
| GPT-4o mini | temperature=0, seed=42 | temperature=0.7, top_p=0.95, seed=42 | 16k |
| Gemini 2 Flash Thinking | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 65k |
| Gemini 2 Flash | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 8k |
| Gemini 1.5 Pro | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 8k |
| Gemini 1.5 Flash | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 8k |
| Gemini 1 Pro Vision | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 2k |
| Claude 3.5 Sonnet v2 | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 8k |
| Claude 3.5 Sonnet | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 8k |
| Claude 3 Opus | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 4k |
| Claude 3 Sonnet | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 4k |
| Claude 3 Haiku | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 4k |
| Pixtral-Large | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 32k |
| Reka Edge | temperature=0, top_k=1, seed=42 | temperature=0.7, top_p=0.95 | 32k |
| QVQ | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 32k |
| Llama 3.2 90B | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 8k |
| Qwen2-VL-72B-Instruct | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 32k |
| NVLM-D-72 B | temperature=0, top_k=1 | temperature=0.7, top_p=0.95 | 32k |
🔼 This table details the hyperparameters used for both greedy and stochastic decoding methods across various large language models (LLMs). It shows the specific settings such as temperature, top_k, top_p and seed values used for each model during the experiments. Note that for the o1 pro model, hyperparameters could not be set due to the model being accessed via the ChatGPT interface.
read the caption
Table 4: Hyperparameters used in each decoding setting. Note, o1 pro was accessed through the ChatGPT interface preventing hyperparameter configuration.
Full paper#