TL;DR#
Current text-to-image diffusion models struggle with complex reasoning tasks due to limitations in understanding and integrating multiple modalities. Existing methods often rely on pixel-level reconstruction, which is computationally expensive and does not effectively address higher-level reasoning. They also require large and specific datasets which are not always available.
ThinkDiff tackles these challenges by using vision-language models (VLMs) as a proxy for training. It aligns the VLM with the decoder of a large language model (LLM), creating a shared feature space that makes it easier to integrate the reasoning power of the VLM into the diffusion model. This approach improves accuracy significantly and offers better performance on in-context reasoning, requiring less training data and time.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances the capabilities of diffusion models, a leading technology in image generation. ThinkDiff’s novel alignment paradigm enables these models to perform complex reasoning tasks, opening up new possibilities for multimodal applications. This addresses a significant limitation of current diffusion models and is highly relevant to ongoing research in vision-language and AI reasoning.
Visual Insights#

🔼 Figure 1 illustrates ThinkDiff’s capabilities in multimodal in-context reasoning. (a) shows ThinkDiff’s ability to perform logical reasoning by combining visual information (images of a flying monkey and a flying cat) and textual cues (prompts mentioning ‘monkey’, ‘cat’, and ‘zebra’) to generate a new image of a ‘flying zebra’, demonstrating in-context understanding and generation. (b) demonstrates ThinkDiff’s capacity for image composition by generating a coherent image from multiple images and texts, highlighting its ability to create logically sound and reasonable outputs from complex multimodal inputs.
read the caption
Figure 1: (a) Our ThinkDiff reasons over interleaved images (a flying monkey and a flying cat) and text prompts (monkey, cat, and zebra) to generate a logically correct and high-quality image (a flying zebra). The ground truth reasoning answer is provided as a reference for readers. (b) ThinkDiff composes images and texts into a coherent and reasonable image.
| Color-I | Background-I | Style-I | Action-I | Texture-I | Color-II | Background-II | Style-II | Action-II | Texture-II | |
|---|---|---|---|---|---|---|---|---|---|---|
| SEED-LLaMA | 0.680 | 0.348 | 0.203 | 0.182 | 0.196 | 0.287 | 0.467 | 0.297 | 0.261 | 0.163 |
| Emu | 0.065 | 0.051 | 0.057 | 0.052 | 0.078 | 0.062 | 0.109 | 0.081 | 0.092 | 0.074 |
| GILL | 0.171 | 0.054 | 0.069 | 0.063 | 0.074 | 0.010 | 0.043 | 0.024 | 0.022 | 0.040 |
| ThinkDiff-LVLM | 0.622 | 0.349 | 0.237 | 0.459 | 0.290 | 0.511 | 0.534 | 0.340 | 0.534 | 0.292 |
🔼 This table presents the results of the ThinkDiff-LVLM model on the CoBSAT benchmark, specifically focusing on 2-shot scenarios. The benchmark consists of 10 different tasks, each evaluating a particular aspect of multimodal reasoning (e.g., understanding actions, colors, textures, background). ThinkDiff-LVLM shows state-of-the-art (SoTA) performance on 9 out of 10 tasks, significantly outperforming existing methods. Notably, the improvement is particularly significant (more than 20%) on tasks related to actions and colors, which have historically proven challenging for other models.
read the caption
Table 1: 2-shot CoBSAT accuracy of ThinkDiff-LVLM. It achieves SoTA accuracy on 9 of 10 tasks by large margins, increasing accuracy by more than 20% on Action-I, Color-II, Action-II tasks which are particularly hard for other methods.
In-depth insights#
Multimodal Reasoning#
Multimodal reasoning, as explored in the context of this research paper, presents a significant advancement in AI. It focuses on equipping AI models with the ability to integrate and reason across multiple modalities, such as text and images. This surpasses the limitations of unimodal models that only process a single data type. The core challenge lies in effectively aligning and harmonizing information from diverse sources to achieve logical and coherent outputs. The approach proposed, likely involving novel alignment paradigms and training strategies, aims to overcome the complexities of multimodal fusion, enabling the model to understand and respond effectively to nuanced and intertwined inputs. The success of this methodology is critically dependent on the availability and quality of training data, and benchmarks for evaluating performance in multimodal tasks. Ultimately, the goal is to create AI systems that not only understand but also exhibit robust reasoning abilities that are more human-like, leading to more powerful and versatile applications.
Vision-Language Fusion#
Vision-language fusion is a crucial area in AI research, aiming to synergistically combine visual and textual information. Effective fusion is critical for enabling machines to understand complex scenes and perform higher-level reasoning tasks, going beyond simply identifying objects and captions. Current approaches often involve techniques like joint embedding, where visual and textual features are mapped to a shared latent space, facilitating cross-modal interaction and information exchange. Alternatively, attention mechanisms are utilized to selectively focus on relevant visual and textual elements, improving the accuracy and efficiency of the fusion process. Recent advances often incorporate large language models (LLMs) and vision transformers (ViTs), enabling richer contextual understanding and more sophisticated reasoning capabilities. However, challenges remain, including addressing the inherent heterogeneity of visual and textual data, handling noisy or incomplete information, and designing scalable and efficient fusion architectures capable of processing complex multimodal inputs. Future directions could explore more advanced fusion strategies leveraging graph neural networks or knowledge graphs, enabling more structured and interpretable multimodal reasoning. Furthermore, developing robust evaluation metrics for vision-language fusion remains an important area of research. Ultimately, the goal is to create truly integrated systems that seamlessly understand and reason about the world from both visual and textual perspectives.
ThinkDiff Framework#
The ThinkDiff framework presents a novel approach to integrating the strengths of Vision-Language Models (VLMs) into text-to-image diffusion models, enabling them to perform multimodal in-context reasoning. Instead of directly finetuning the diffusion model with multimodal data, which is complex and data-intensive, ThinkDiff leverages a proxy task. It aligns the VLM with the decoder of an encoder-decoder Large Language Model (LLM), exploiting the shared feature space between the LLM decoder and the diffusion decoder. This clever alignment strategy simplifies the training process and reduces the need for large, specifically curated reasoning datasets. ThinkDiff’s use of vision-language training as a proxy effectively transfers the reasoning capabilities of the VLM to the diffusion model, allowing it to handle complex instructions, solve visual analogies, and compose multimodal inputs logically. This innovative approach demonstrates significant performance improvements compared to existing methods, showcasing its effectiveness in multimodal in-context reasoning tasks. The framework’s efficiency and adaptability make it a promising advancement in the field of multimodal generative models.
Ablation Studies#
Ablation studies systematically remove or alter components of a model to determine their individual contributions. In the context of this research paper, ablation studies would likely focus on the impact of key design choices. For instance, the effectiveness of the aligner network, which bridges the VLM and the decoder, could be evaluated by removing it or replacing it with simpler architectures. This helps quantify its contribution to multimodal reasoning. Further, the paper probably investigates the effects of different loss functions or training methods. For example, removing the random masking component, used to prevent shortcut mappings, would demonstrate its importance in stable learning and robust feature alignment. The results of these experiments would pinpoint the most impactful components and critical design decisions in enabling multimodal in-context reasoning, thus providing valuable insights into the model’s architecture and its strengths.
Future Works#
Future research directions stemming from this work on multimodal in-context reasoning in diffusion models could focus on several key areas. Improving the handling of complex reasoning tasks remains crucial; current limitations suggest that more sophisticated VLMs or advanced training techniques are needed. Addressing the trade-off between reasoning accuracy and image fidelity is another important challenge; enhancing the model’s ability to generate high-fidelity images while maintaining strong logical reasoning capabilities is a significant area for improvement. Expanding the range of modalities beyond image and text to encompass audio and video would greatly broaden the applications. Finally, developing robust safeguards to mitigate potential misuse is paramount, given the potential for generating misleading or harmful content. Thorough investigation of bias and ethical concerns should accompany any further model development.
More visual insights#
More on figures

🔼 Figure 2 illustrates two different approaches to integrating vision-language models (VLMs) with diffusion models for image generation. Panel (a) shows reconstruction-based diffusion finetuning. This method focuses on pixel-level image reproduction by directly incorporating visual features into the diffusion model using a diffusion loss. This approach doesn’t explicitly support in-context reasoning. Panel (b) shows ThinkDiff’s approach. ThinkDiff leverages vision-language training to align the VLM with the decoder of a large language model (LLM). Because the LLM decoder and the diffusion decoder share the same feature space, this indirect alignment effectively transfers the reasoning capabilities of the VLM to the diffusion decoder, enabling multimodal in-context reasoning during inference. The dotted lines indicate the inference phase where the reasoning abilities are transferred.
read the caption
Figure 2: (a) Reconstruction-based diffusion finetuning integrates image features using a diffusion loss, focusing on pixel-level image reconstruction without reasoning. (b) ThinkDiff aligns a VLM to an LLM decoder by vision-language training on image-caption datasets. In inference (dotted lines), it transfers multimodal in-context reasoning capabilities from the VLM to a diffusion decoder.

🔼 This figure illustrates the shared architecture between several diffusion models and encoder-decoder large language models (LLMs). It highlights that many diffusion models utilize the same language encoder as LLMs. This shared encoder creates a common feature space, making it possible to align the Vision-Language Model (VLM) with the diffusion decoder indirectly by aligning it with the LLM decoder. This simplifies the training process and avoids the need for direct alignment between the VLM and the diffusion decoder, which is often complex and requires large datasets.
read the caption
Figure 3: Several diffusion models share a language encoder with encoder-decoder LLMs, allowing aligning with diffusion decoders through aligning with LLM decoders.

🔼 Figure 4 illustrates the training and inference processes of two ThinkDiff variants: (a) ThinkDiff-LVLM uses a large vision-language model (LVLM) to generate text tokens and features from an image and text prompt. Some features are randomly masked for training, while the unmasked features are fed into an aligner network and an LLM decoder. The decoder predicts the masked tokens, supervised by a cross-entropy loss. During inference, the LLM decoder is replaced by a diffusion decoder to generate images from multimodal input. (b) ThinkDiff-CLIP uses a CLIP vision model to extract image features. A portion of an image caption is encoded by an LLM encoder, which then concatenates with the image features. This combined input is fed to the LLM decoder, trained to predict the next part of the caption. During inference, this decoder is replaced by a diffusion decoder for coherent image generation based on multimodal input.
read the caption
Figure 4: (a) In ThinkDiff-LVLM training, the LVLM processes an image and a text to generate text tokens and token features, with some token features randomly masked. Unmasked token features are passed to a trainable aligner network and an LLM decoder, predicting masked text tokens supervised by cross-entropy loss. In inference, the LLM decoder is replaced by a diffusion decoder, enabling in-context reasoning image generation from interleaved images and texts. (b) In ThinkDiff-CLIP training, a CLIP vision model extracts image token features which are then mapped by a trainable aligner network. A part of the image caption is encoded by the LLM encoder and concatenated with image tokens. These combined tokens are passed to the LLM decoder to predict the next part of the caption supervised by cross-entropy loss. In inference, the LLM decoder is replaced by a diffusion encoder, allowing coherent image generation based on multimodal context.

🔼 This figure shows a comparison of different models’ performance on a 2-shot visual reasoning task from the CoBSAT benchmark. The input consists of images and text prompts designed to elicit the generation of a ‘wicker car.’ ThinkDiff-LVLM successfully generates a high-quality image matching this description, correctly identifying both the explicit (car) and implicit (wicker) attributes. In contrast, the baseline models SEED-LLaMA, Emu, and GILL fail to produce accurate or visually appealing results, demonstrating ThinkDiff-LVLM’s superior multimodal reasoning capabilities.
read the caption
Figure 5: 2-shot evaluation results on CoBSAT. The input structure is similar to Figure 1a. Given multimodal inputs, ThinkDiff-LVLM accurately captures both implicit attributes (e.g., wicker material) and explicit attributes (e.g. car), and generates a logically correct image (wicker car). In contrast, methods such as SEED-LLaMA (Ge et al., 2024), Emu (Sun et al., 2023) and GILL (Koh et al., 2024) produce inaccurate and lower-quality images. The ground truth implicit attribute is highlighted in red for readers’ reference. See more results in Appendix Figure 9 and 10.

🔼 Figure 6 presents a comparison of image generation results using different methods: ThinkDiff, and FLUX. The experiment uses two input conditions: a single image (I) and a single image with a text prompt (I+T). The results show that ThinkDiff effectively incorporates the semantic content of both the image and the text prompt to create a coherent, meaningful image. In contrast, FLUX is quite good at reproducing the input image but it struggles to incorporate additional text information and maintain consistency between image and text. This showcases ThinkDiff’s improved ability to handle multimodal in-context reasoning. More results are presented in Figure 11.
read the caption
Figure 6: Generation results for single image (I) and single image with text prompt (I + T) inputs. Our method effectively integrates semantic details of both image and text modalities to produce coherent images. FLUX excels at replicating the input image but struggles to maintain consistency with additional text prompts. See more results in Figure 11.

🔼 This figure shows the training loss curves of the ThinkDiff-LVLM model under three different conditions: 1) without RMSNorm; 2) with RMSNorm and default initialization; 3) with RMSNorm and the proposed initialization. The y-axis represents the training loss (on a logarithmic scale), and the x-axis represents training steps. The plot visually demonstrates that disabling RMSNorm or using default initialization leads to significantly unstable training, characterized by erratic fluctuations in the loss. In contrast, the proposed RMSNorm initialization ensures stable and convergent training.
read the caption
Figure 7: Training losses (log scale) of ThinkDiff-LVLM comparing different RMSNorm designs. Disabling RMSNorm (w/o RMSNorm) or using the default RMSNorm initialization (RMSNorm w/ Default init.) results in significantly unstable training.

🔼 ThinkDiff-CLIP successfully combines two input images into a single coherent image by creatively merging their semantic details. The model demonstrates its ability to understand and integrate visual information from multiple sources, rather than simply juxtaposing them.
read the caption
Figure 8: Results of ThinkDiff-CLIP composing two images. It creatively merge semantic details of both images. See more results in Appendix Figure 12.

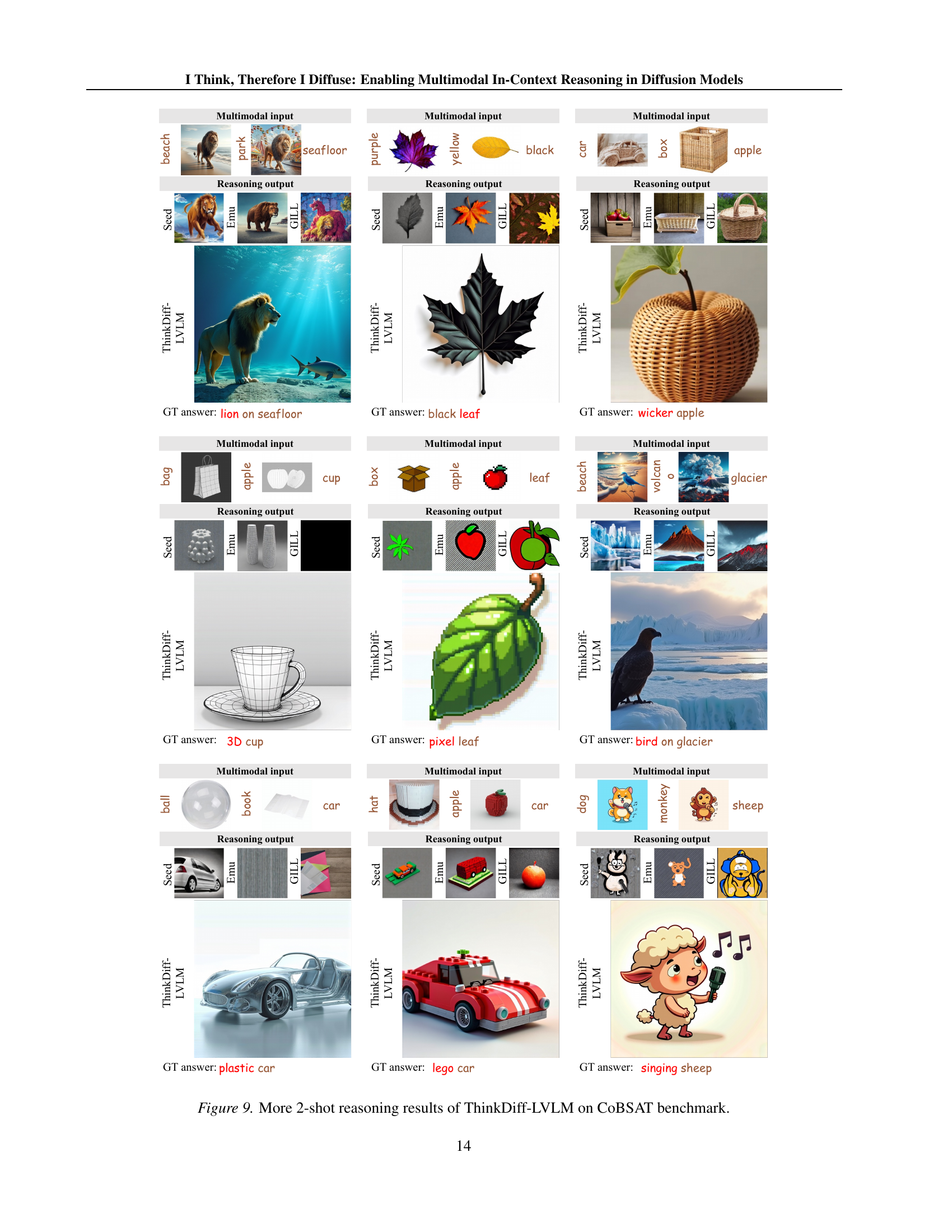
🔼 This figure showcases additional examples from the CoBSAT benchmark, demonstrating ThinkDiff-LVLM’s performance on more complex 2-shot reasoning tasks. Each row presents a different task, showing the multimodal inputs (images and text), the model’s generated reasoning output (image), and the ground truth. The figure highlights the model’s ability to correctly identify and synthesize visual features based on the given contextual clues and logic, even with limited input data.
read the caption
Figure 9: More 2-shot reasoning results of ThinkDiff-LVLM on CoBSAT benchmark.

🔼 This figure shows more examples of ThinkDiff-LVLM’s performance on the CoBSAT benchmark’s 2-shot reasoning tasks. Each row displays a set of input images and text prompts, followed by the model’s generated image. The results demonstrate ThinkDiff-LVLM’s ability to integrate visual and textual information to generate images that are logically consistent with the input.
read the caption
Figure 10: More 2-shot reasoning results of ThinkDiff-LVLM on CoBSAT benchmark.

🔼 This figure compares the image generation results of three different methods: Flux Ultra with only image input, Flux Ultra with both image and text input, ThinkDiff-CLIP with only image input, and ThinkDiff-CLIP with both image and text input. Each row shows results using a different starting image. The results demonstrate ThinkDiff-CLIP’s ability to effectively integrate both image and text information to generate coherent images that align with the provided text prompt, unlike the Flux Ultra model which struggles to maintain consistency when additional text is added.
read the caption
Figure 11: Generation results of a single image and a text prompt of ThinkDiff-CLIP.

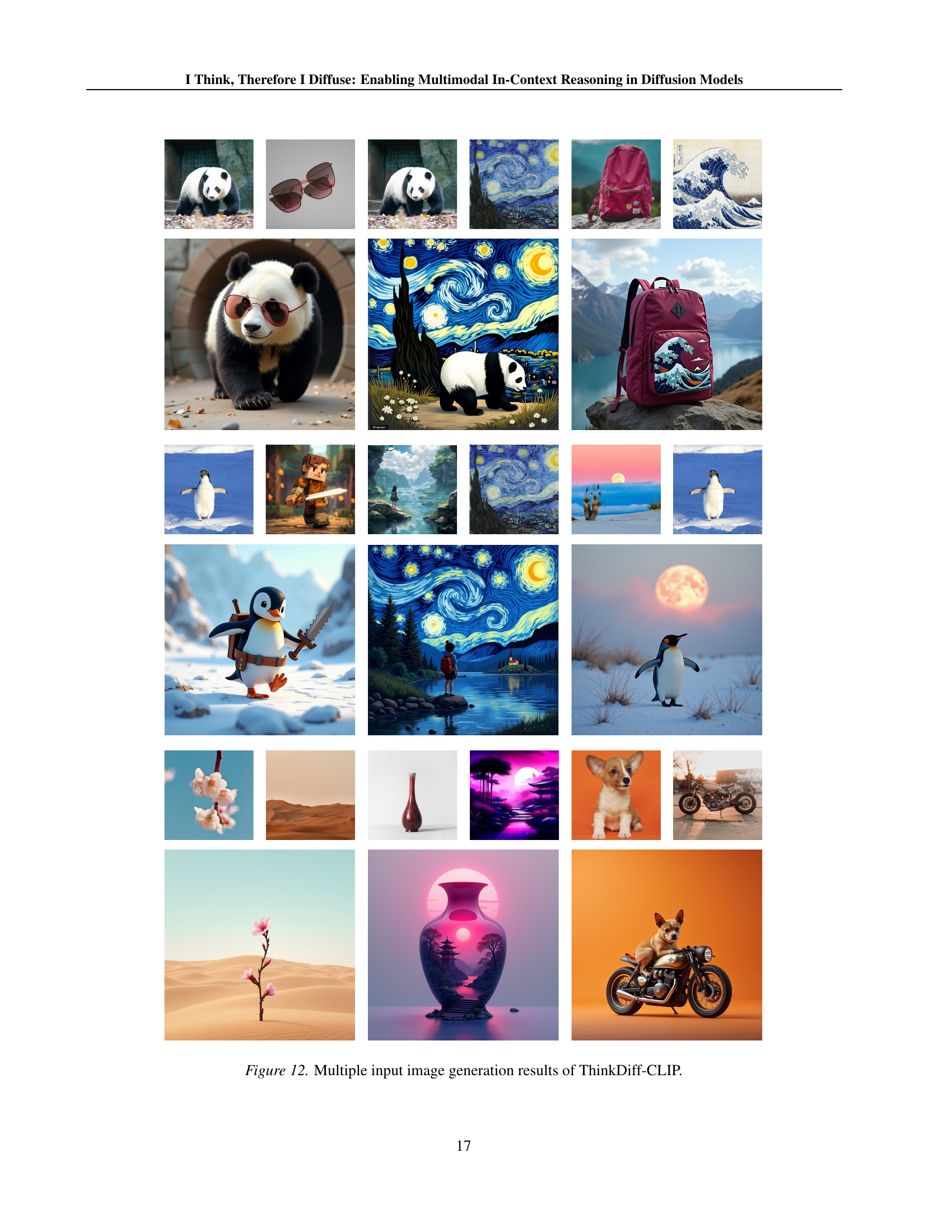
🔼 This figure showcases the capabilities of ThinkDiff-CLIP in generating images from multiple input images. It demonstrates the model’s ability to synthesize and combine visual elements from various sources into a single, coherent output image. The results highlight ThinkDiff-CLIP’s skill in integrating and harmonizing different visual styles and content, producing creative and visually interesting compositions.
read the caption
Figure 12: Multiple input image generation results of ThinkDiff-CLIP.

🔼 This figure presents a comparison of image generation results using ThinkDiff-CLIP under different input conditions. The first column shows the input images used for generation, demonstrating examples with multiple images (2I). The second column displays the output generated by ThinkDiff-CLIP when given only the multiple images (2I) as input. The third column shows the text prompts accompanying the multiple images (2I + T). The fourth column showcases the generation results when both multiple images and the corresponding text prompts are provided as input (2I + T) to ThinkDiff-CLIP. This comparison highlights ThinkDiff-CLIP’s ability to generate semantically coherent images by effectively integrating both image and text information, exceeding the capabilities of simply replicating the input images.
read the caption
Figure 13: Generation results for multiple images (2I) and multiple images with a text prompt (2I + T) of ThinkDiff-CLIP.
More on tables
| Color-I | Background-I | Style-I | Action-I | Texture-I | Color-II | Background-II | Style-II | Action-II | Texture-II | |
|---|---|---|---|---|---|---|---|---|---|---|
| SEED-LLaMA | 0.482 | 0.211 | 0.141 | 0.053 | 0.122 | 0.252 | 0.076 | 0.268 | 0.207 | 0.105 |
| Emu | 0.063 | 0.018 | 0.045 | 0.048 | 0.097 | 0.037 | 0.122 | 0.109 | 0.077 | 0.088 |
| GILL | 0.106 | 0.044 | 0.041 | 0.073 | 0.087 | 0.022 | 0.059 | 0.044 | 0.032 | 0.067 |
| Ours | 0.638 | 0.362 | 0.254 | 0.434 | 0.317 | 0.610 | 0.590 | 0.432 | 0.664 | 0.332 |
| Improvement () | 32.4% | 71.6% | 80.1% | 718.9% | 159.8% | 142.1% | 676.3% | 61.2% | 220.8% | 216.2% |
🔼 This table presents the results of a 4-shot evaluation on the CoBSAT benchmark, focusing on the ThinkDiff-LVLM model’s ability to perform multimodal in-context reasoning. The benchmark consists of 10 tasks, each requiring the model to generate an image based on a sequence of images and text prompts. The table compares ThinkDiff-LVLM’s accuracy to three other state-of-the-art models (SEED-LLaMA, Emu, and GILL) across the 10 tasks. The results show that ThinkDiff-LVLM significantly outperforms the other models, achieving a 27% average improvement in accuracy. Furthermore, ThinkDiff-LVLM demonstrates a 4.7% increase in accuracy compared to its own 2-shot evaluation, highlighting its improved ability to manage the complexity of the 4-shot inputs. The table also includes the improvement ratios relative to the previous state-of-the-art model.
read the caption
Table 2: 4-shot CoBSAT accuracy of ThinkDiff-LVLM shows a 27% average improvement over other methods and a 4.7% increase over its 2-shot results, highlighting its ability to handle complex in-context reasoning. In contrast, SEED-LLaMA (Ge et al., 2024), Emu (Sun et al., 2023), and GILL (Koh et al., 2024) exhibit reduced performance in 4-shot evaluations, indicating their struggle with increased input complexity. Improvement ratios over SoTA are also provided.
| Color-I | Background-I | Style-I | Action-I | Texture-I | Color-II | Background-II | Style-II | Action-II | Texture-II | |
|---|---|---|---|---|---|---|---|---|---|---|
| Ours using input tokens | 0.024 | 0.004 | 0.03 | 0.011 | 0.032 | 0.007 | 0.008 | 0.012 | 0.019 | 0.011 |
| Ours w/o masked training | 0.548 | 0.215 | 0.105 | 0.256 | 0.187 | 0.510 | 0.338 | 0.156 | 0.325 | 0.228 |
| Ours | 0.622 | 0.349 | 0.237 | 0.459 | 0.290 | 0.511 | 0.534 | 0.340 | 0.534 | 0.292 |
🔼 This table presents the results of ablation studies conducted on the CoBSAT benchmark using the ThinkDiff-LVLM model. It compares the 2-shot accuracy across three different model configurations. The first configuration is the full ThinkDiff-LVLM model which uses both the random masking training strategy and the deep features generated by the LVLM decoder. The second configuration is the model without the random masking training. The third configuration uses the deep features of input tokens instead of the generated tokens by the LVLM decoder. This table allows for a quantitative analysis of the impact of the random masking training and the selection of input tokens on the model’s performance in multi-modal in-context reasoning.
read the caption
Table 3: 2-shot results on CoBSAT ablating models with and without masking, and using deep features of input tokens.
| GPU No. | Time / h | Average Acc. | |
|---|---|---|---|
| SEED-LLaMA | 64 A100 | 216 | 0.192 |
| Emu | 128 A100 | 48 | 0.070 |
| GILL | 2 A6000 | 48 | 0.058 |
| ThinkDiff-LVLM | 4 A100 | 5 | 0.463 |
🔼 This table compares the training resources (number of GPUs and training time) and 4-shot accuracy on the CoBSAT benchmark across different models: SEED-LLAMA, Emu, GILL, and ThinkDiff-LVLM. It highlights that ThinkDiff-LVLM significantly reduces the GPU usage and training time while achieving a substantial improvement in accuracy (from 0.192, 0.07, and 0.058 to 0.463). This demonstrates ThinkDiff-LVLM’s efficiency and effectiveness.
read the caption
Table 4: Training resources and 4-shot accuracy. ThinkDiff-LVLM drastically reduces GPU usage and training time and improves accuracy from 0.192, 0.07, and 0.058 to 0.463.
Full paper#