TL;DR#
Current reinforcement learning (RL) benchmarks lack a universal standard for evaluating agents’ memory capabilities, especially in complex scenarios like robotic manipulation. This makes it hard to compare different algorithms and assess their real-world applicability. Existing benchmarks are often narrow in scope, focusing on specific problem domains rather than offering a holistic evaluation across diverse memory tasks.
To address this, the researchers introduce MIKASA, a comprehensive benchmark with three main contributions: a new classification framework for memory-intensive tasks; MIKASA-Base, a unified benchmark for systematic evaluation; and MIKASA-Robo, a novel benchmark focusing on robotic manipulation. This allows researchers to evaluate memory mechanisms across different scenarios in a standardized way. The experiments show the effectiveness of the benchmark in identifying memory limitations in current algorithms and suggests new ways to improve memory-enhanced RL agents.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning and robotics. It addresses the critical need for standardized benchmarks to evaluate memory-enhanced agents, offering a structured framework and dataset for rigorous testing and comparison. This work opens avenues for developing more reliable and robust systems for real-world applications, particularly in complex robotic manipulation tasks. The unified framework facilitates systematic research and direct comparison of agent capabilities, fostering advancements in memory-enhanced RL.
Visual Insights#

🔼 This figure illustrates a systematic classification framework for memory-intensive reinforcement learning (RL) tasks. It highlights how different types of memory utilization (e.g., object memory, spatial memory, sequential memory, and memory capacity) lead to distinct problem characteristics. By categorizing problems in this way, the framework facilitates a more objective evaluation of various memory mechanisms across diverse RL agents. The figure contrasts the limitations of evaluating memory solely on a single task set versus the advantages of a more comprehensive benchmark that incorporates diverse task types and memory demands. This allows researchers to better understand and compare the strengths and weaknesses of different memory-enhanced agents.
read the caption
Figure 1: Systematic classification of problems with memory in RL reveals distinct memory utilization patterns and enables objective evaluation of memory mechanisms across different agents.
| Memory Task | Mode | Brief description of the task | T | Oracle Info | Prompt | Memory Task Type |
| ShellGame[Mode]-v0 | Touch Push Pick | Memorize the position of the ball after some time being covered by the cups and then interact with the cup the ball is under. | 90 | cup_with_ball_number | — | Object |
| Intercept[Mode]-v0 | Slow Medium Fast | Memorize the positions of the rolling ball, estimate its velocity through those positions, and then aim the ball at the target. | 90 | initial_velocity | — | Spatial |
| InterceptGrab[Mode]-v0 | Slow Medium Fast | Memorize the positions of the rolling ball, estimate its velocity through those positions, and then catch the ball with the gripper and lift it up. | 90 | initial_velocity | — | Spatial |
| RotateLenient[Mode]-v0 | Pos PosNeg | Memorize the initial position of the peg and rotate it by a given angle. | 90 | y_angle_diff | target_angle | Spatial |
| RotateStrict[Mode]-v0 | Pos PosNeg | Memorize the initial position of the peg and rotate it to a given angle without shifting its center. | 90 | y_angle_diff | target_angle | Object |
| TakeItBack-v0 | — | Memorize the initial position of the cube, move it to the target region, and then return it to its initial position. | 180 | xyz_initial | — | Spatial |
| RememberColor[Mode]-v0 | 3 \ 5 \ 9 | Memorize the color of the cube and choose among other colors. | 60 | true_color_indices | — | Object |
| RememberShape[Mode]-v0 | 3 \ 5 \ 9 | Memorize the shape of the cube and choose among other shapes. | 60 | true_shape_indices | — | Object |
| RememberShapeAndColor [Mode]-v0 | 32\33 53 | Memorize the shape and color of the cube and choose among other shapes and colors. | 60 | true_shapes_info true_colors_info | — | Object |
| BunchOfColors[Mode]-v0 | 3 \ 5 \ 7 | Remember the colors of the set of cubes shown simultaneously in the bunch and touch them in any order. | 120 | true_color_indices | — | Capacity |
| SeqOfColors[Mode]-v0 | 3 \ 5 \ 7 | Remember the colors of the set of cubes shown sequentially and then select them in any order. | 120 | true_color_indices | — | Capacity |
| ChainOfColors[Mode]-v0 | 3 \ 5 \ 7 | Remember the colors of the set of cubes shown sequentially and then select them in the same order. | 120 | true_color_indices | — | Sequential |
| Total: 32 tabletop robotic manipulation memory-intensive tasks in 12 groups | ||||||
🔼 Table 1 presents the MIKASA-Robo benchmark, a collection of 32 memory-intensive robotic manipulation tasks categorized into 12 groups. Each task’s complexity and setup can be modified, and the table details the episode time limit (T), the essential information the robot must remember (Oracle Info), and the instructions given to the robot (Prompt). Appendix E provides further details on each of the 32 tasks.
read the caption
Table 1: MIKASA-Robo: A benchmark comprising 32 memory-intensive robotic manipulation tasks across 12 categories. Each task varies in difficulty and configuration modes. The table specifies episode timeout (T), the necessary information that the agent must memorize in order to succeed (Oracle Info), and task instructions (Prompt) for each environment. See Appendix E for details.
In-depth insights#
Memory RL Tasks#
The concept of ‘Memory RL Tasks’ highlights the crucial role of memory in reinforcement learning, pushing beyond the limitations of traditional Markov Decision Processes (MDPs). These tasks necessitate agents to retain and utilize past experiences to make informed decisions, especially in scenarios involving partial observability, long-term dependencies, or delayed rewards. Effective memory mechanisms are critical for success in these settings. A key challenge lies in the design of these tasks, which must balance complexity with a meaningful assessment of memory capabilities. They need to differentiate between true memory utilization and other learning strategies, avoiding artificial inflation of memory performance. A good benchmark should contain a diverse range of memory-intensive tasks, categorized systematically to evaluate different aspects of memory (e.g., object, spatial, sequential, and capacity). The tasks should also consider the practical aspects of real-world applications, including the transition from simplified environments to more realistic, complex scenarios, such as robotic manipulation.
MIKASA Benchmark#
The MIKASA benchmark, as described in the research paper, is a significant contribution to the field of reinforcement learning (RL). It directly addresses the critical need for a unified and comprehensive evaluation framework for memory-enhanced RL agents. The benchmark’s strength lies in its three key contributions: a novel classification of memory-intensive RL tasks; MIKASA-Base, a unified benchmark enabling systematic evaluation; and MIKASA-Robo, a robotic manipulation benchmark designed to test memory in realistic scenarios. MIKASA-Base’s unified framework offers a solution to the current fragmentation of existing benchmarks, allowing for fairer comparisons between different memory mechanisms across diverse problem domains. MIKASA-Robo adds a crucial layer of physical interaction and complexity to the memory assessment, moving beyond abstract environments and making the benchmark more directly applicable to real-world robotic applications. The detailed classification framework provided further strengthens the benchmark by clarifying the types of memory challenges addressed, aiding in the design and analysis of future memory-enhanced RL systems.
Robotic Manipulation#
The research paper section on robotic manipulation highlights the critical need for memory in complex robotic tasks. While many robotic manipulation benchmarks exist, they often oversimplify the challenges of real-world scenarios by neglecting partial observability and memory requirements. The authors emphasize that current evaluation methods lack a unified framework, making it difficult to compare different memory-enhanced agents effectively. The paper’s contribution is a new benchmark, specifically designed to overcome this limitation by evaluating memory across diverse manipulation tasks. This involves carefully designed tasks assessing various aspects of memory including object, spatial, sequential, and capacity-based memory. The benchmark provides a structured approach for comparing and analyzing the impact of memory mechanisms in manipulation, addressing a crucial gap in current research. By using a combination of dense and sparse rewards, the benchmark more accurately reflects the complexity of real-world robotic manipulation where feedback is not always readily available.
Memory Mechanism#
Reinforcement learning (RL) agents often struggle with complex tasks involving temporal dependencies and partial observability. Memory mechanisms are crucial for addressing these challenges, enabling agents to retain and utilize past experiences to inform current decisions. The paper explores various memory mechanisms, including recurrent neural networks (RNNs), which use hidden states to store information; state-space models (SSMs), which represent the environment’s state; and transformers, which leverage attention mechanisms to capture long-range dependencies. The choice of memory mechanism significantly impacts an agent’s performance, particularly in tasks requiring long-term memory or the integration of diverse information streams. The effectiveness of different memory mechanisms varies across different tasks and scenarios. A key contribution of this paper is the development of a unified benchmark that allows for the systematic evaluation of memory-enhanced RL agents across a range of challenging tasks.
Future of Memory RL#
The future of Memory RL hinges on addressing current limitations. Improved memory mechanisms are crucial, moving beyond simple RNNs and LSTMs to explore more sophisticated architectures like transformers or graph neural networks capable of handling complex, long-range dependencies and high-dimensional data. Unified benchmarking is essential for fair comparison and progress tracking, enabling objective evaluations across various tasks and agent designs. Bridging the gap between simulated and real-world environments is vital for creating robust and reliable systems. This necessitates a shift toward more realistic and complex tasks that go beyond simple gridworlds and puzzles, including integrated physical manipulation and sensorimotor integration. Finally, incorporating cognitive principles from human memory research promises to create more efficient and effective memory-augmented RL agents. The intersection of RL and cognitive science will drive innovation in this field. More research into the specific aspects of human memory—including long-term and short-term memory—can inform the development of more advanced RL algorithms.
More visual insights#
More on figures

🔼 Figure 2 showcases examples of tasks from the MIKASA-Robo benchmark, highlighting the memory requirements. The ShellGameTouch-v0 task tests object permanence; the agent must remember a ball’s location under cups and then touch the correct one. The RememberColor9-v0 task assesses object recognition and short-term memory; the agent must remember the color of a cube and later select the same color. Lastly, the RotateLenientPos-v0 task evaluates spatial-temporal reasoning and working memory; the agent must rotate a peg a certain angle while tracking how much it’s been rotated already. These diverse scenarios illustrate the various ways the benchmark assesses memory in robotic manipulation.
read the caption
Figure 2: Illustration of demonstrative memory-intensive tasks execution from the proposed MIKASA-Robo benchmark. The ShellGameTouch-v0 task requires the agent to memorize the ball’s location under mugs and touch the correct one. In RememberColor9-v0, the agent must memorize a cube’s color and later select the matching one. In RotateLenientPos-v0, the agent must rotate a peg while keeping track of its previous rotations.

🔼 This figure illustrates MIKASA’s position within the spectrum of memory complexity. Human memory is incredibly complex and nuanced, encompassing numerous aspects beyond the scope of current reinforcement learning (RL) agents. Conversely, simplistic RL tasks that only require remembering basic spatio-temporal information are insufficient for evaluating advanced memory capabilities. MIKASA successfully occupies a middle ground, offering a set of tasks that are challenging enough to probe various memory aspects in RL agents yet remain practical to implement and evaluate, bridging the gap between the complexity of human memory and the limitations of current RL agent capabilities.
read the caption
Figure 3: MIKASA bridges the gap between human-like memory complexity and RL agents requirements. While agents tasks don’t require the full spectrum of human memory capabilities, they can’t be reduced to simple spatio-temporal dependencies. MIKASA provides a balanced framework that captures essential memory aspects for agents tasks while maintaining practical simplicity.

🔼 Figure 4 presents the results of training a PPO agent with a Multilayer Perceptron (MLP) network in a fully observable environment (state mode). This means the agent is provided with the complete state information at each time step, effectively eliminating the need for memory. The plot shows that despite the variation in complexity among different tasks within the benchmark, all tasks achieve 100% success rate. This demonstrates the inherent solvability of the tasks in a fully observable setting and validates that the observed difficulties and performance differences in partially observable modes (using image or joint data, for instance) are directly due to the challenges in memory processing and information retrieval rather than issues in the task design itself.
read the caption
Figure 4: Performance of PPO-MLP trained in state mode, i.e., in MDP mode without the need for memory. These results suggest that the proposed tasks are inherently solvable with a success rate of 100%percent\%%.

🔼 This figure showcases the performance comparison of two different neural network architectures, MLP and LSTM, trained using Proximal Policy Optimization (PPO) algorithm. Both models were trained using RGB and joint data input, with dense reward settings on the RememberColor-v0 task. The results clearly demonstrate that neither architecture successfully solves the medium or high complexity variants of this task, which requires the agent to memorize and recall color information. This highlights the challenges posed by memory-intensive tasks even for advanced architectures like LSTMs.
read the caption
Figure 5: PPO with MLP and LSTM backbones trained in RGB+joints mode on the RememberColor-v0 environment with dense rewards. Both architectures fail to solve medium and high complexity tasks.

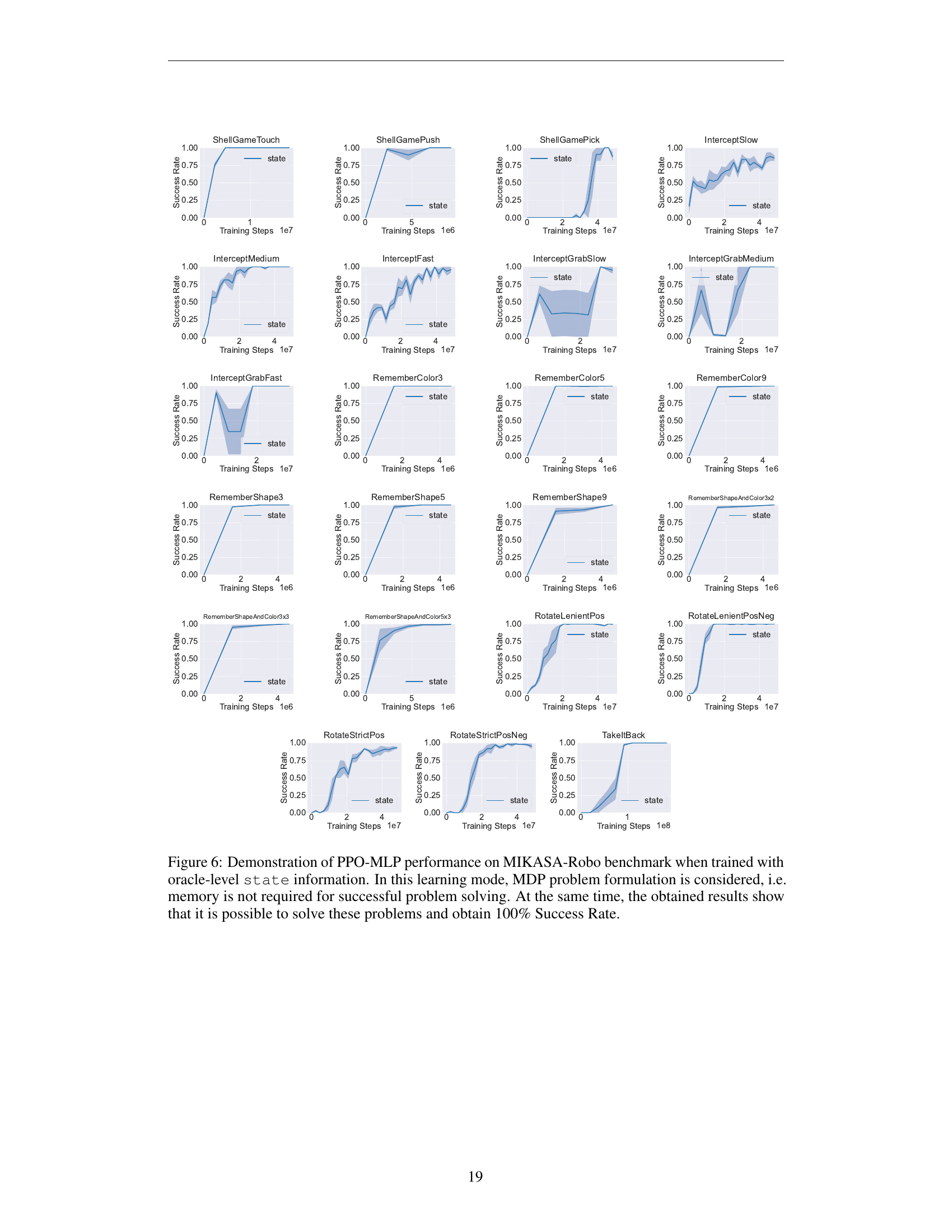
🔼 Figure 6 displays the success rates achieved by a PPO-MLP agent (without memory) across various tasks within the MIKASA-Robo benchmark. The key condition is that the agent is trained with complete state information (oracle-level), effectively transforming the tasks into Markov Decision Processes (MDPs). The results demonstrate that even without memory capabilities, the PPO-MLP agent can solve all presented tasks with 100% success rate, confirming the tasks’ inherent solvability and validating the benchmark’s design.
read the caption
Figure 6: Demonstration of PPO-MLP performance on MIKASA-Robo benchmark when trained with oracle-level state information. In this learning mode, MDP problem formulation is considered, i.e. memory is not required for successful problem solving. At the same time, the obtained results show that it is possible to solve these problems and obtain 100% Success Rate.

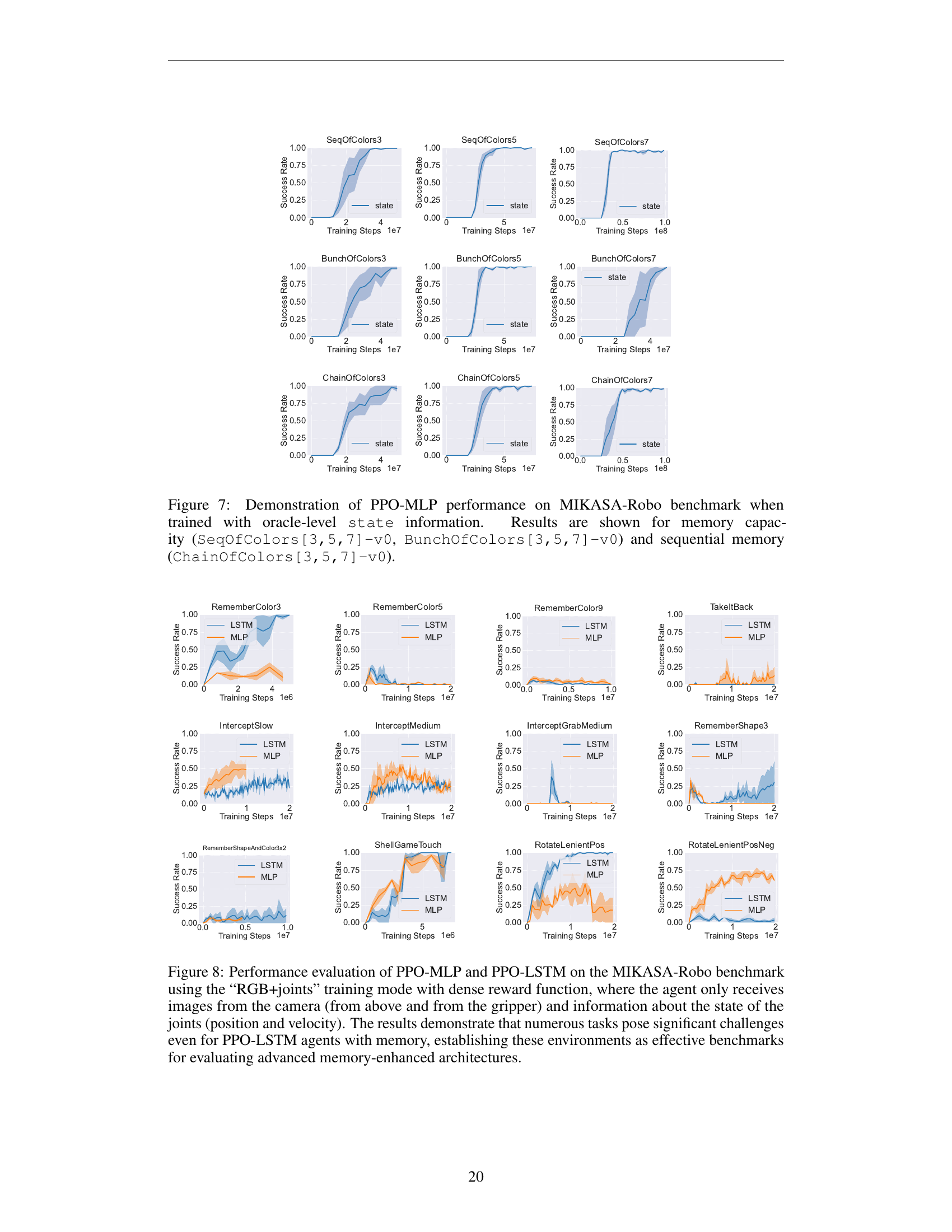
🔼 Figure 7 displays the performance of a Proximal Policy Optimization algorithm with a Multilayer Perceptron (PPO-MLP) network on a subset of tasks from the MIKASA-Robo benchmark. The key aspect is that the agent is trained with complete state information (oracle-level), meaning it doesn’t need memory to solve the problems. The figure shows the learning curves for tasks assessing memory capacity (SeqOfColors and BunchOfColors variants) and sequential memory (ChainOfColors variants), demonstrating that even without the need for memory, the PPO-MLP agent can solve these tasks. This provides a baseline for comparison to memory-enhanced agents in later experiments.
read the caption
Figure 7: Demonstration of PPO-MLP performance on MIKASA-Robo benchmark when trained with oracle-level state information. Results are shown for memory capacity (SeqOfColors[3,5,7]-v0, BunchOfColors[3,5,7]-v0) and sequential memory (ChainOfColors[3,5,7]-v0).

🔼 This figure showcases the performance comparison of two reinforcement learning (RL) agents, PPO-MLP (a memory-less agent) and PPO-LSTM (an agent with memory), on the MIKASA-Robo benchmark. The agents were trained under the “RGB+joints” training mode, which means they only received visual input (images from cameras above and on the gripper) and joint state information (position and velocity). A dense reward system was used. The results reveal significant performance differences between the agents across the various tasks. While the PPO-LSTM (memory-enhanced) agent outperforms PPO-MLP in simpler tasks, the performance of both agents degrades as the tasks become more complex, highlighting the challenges posed by memory-intensive tasks. The overall results support the effectiveness of the MIKASA-Robo benchmark for evaluating advanced memory-enhanced architectures.
read the caption
Figure 8: Performance evaluation of PPO-MLP and PPO-LSTM on the MIKASA-Robo benchmark using the “RGB+joints” training mode with dense reward function, where the agent only receives images from the camera (from above and from the gripper) and information about the state of the joints (position and velocity). The results demonstrate that numerous tasks pose significant challenges even for PPO-LSTM agents with memory, establishing these environments as effective benchmarks for evaluating advanced memory-enhanced architectures.

🔼 Figure 9 displays the performance comparison of two different reinforcement learning agents (PPO-MLP and PPO-LSTM) trained on the MIKASA-Robo benchmark under specific conditions. The agents were trained using the “RGB+joints” mode, receiving only visual data from cameras (above and gripper views) and joint states (position and velocity). Crucially, the training utilized a sparse reward system, meaning that the agents only received rewards upon successful task completion, instead of receiving rewards at every step. This created a much more difficult training scenario. The results demonstrate the significant challenge posed by the combination of partial observability (limited RGB and joint information) and sparse rewards, highlighting the difficulty of these memory-intensive tasks. Even the PPO-LSTM agent, which incorporates an LSTM (a recurrent neural network suitable for sequential tasks), struggled significantly, suggesting that the challenging task conditions strongly impact even advanced memory-enhanced RL agents.
read the caption
Figure 9: Performance evaluation of PPO-MLP and PPO-LSTM on the MIKASA-Robo benchmark using the “RGB+joints” with sparse reward function training mode, where the agent only receives images from the camera (from above and from the gripper) and information about the state of the joints (position and velocity). This training mode with sparse reward function causes even more difficulty for the agent to learn, making this mode even more challenging for memory-enhanced agents.

🔼 The ShellGameTouch-v0 task is a robotic manipulation task where the robot initially observes a ball placed under one of three cups. The cups are then moved to obscure the ball’s location. The robot’s objective is to identify and touch the cup concealing the ball, demonstrating object permanence and spatial reasoning skills.
read the caption
Figure 10: ShellGameTouch-v0: The robot observes a ball in front of it. next, this ball is covered by a mug and then the robot has to touch the mug with the ball underneath.

🔼 The RememberColor9-v0 task evaluates an agent’s ability to remember and identify objects based on their visual properties. This capability is essential for real-world robotics applications where agents must recall and match object characteristics across time intervals. The environment presents a sequence of colored cubes on a table. The task proceeds in three phases: 1. Observation Phase (steps 0-4): A cube of a specific color is displayed, and the agent must memorize its color. 2. Delay Phase (steps 5-9): The cube disappears, leaving an empty table. 3. Selection Phase (steps 10+): Multiple cubes of different colors appear (3, 5, or 9 depending on the selected difficulty level), and the agent must identify and touch the cube matching the original color.
read the caption
Figure 11: RememberColor9-v0: The robot observes a colored cube in front of it, then this cube disappears and an empty table is shown. Then 9 cubes appear on the table, and the agent must touch a cube of the same color as the one it observed at the beginning of the episode.

🔼 The task RememberShape-v0 evaluates the agent’s ability to remember and identify objects based on their geometric properties. The environment first shows a single object (cube, sphere, cylinder, etc.). Then, after a delay, 3, 5 or 9 objects of various shapes appear, and the agent must select the object with the same shape as the one shown initially. This tests the agent’s object permanence and shape recognition memory. The figure shows a sequence of images illustrating the task’s progression.
read the caption
Figure 12: RememberShape9-v0: The robot observes an object with specific shape in front of it, then the object disappears and an empty table appears. Then 9 objects of different shapes appear on the table, and the agent must touch an object of the same shape as the one it observed at the beginning of the episode.

🔼 The RememberShapeAndColor5x3-v0 task presents a sequence of three phases. Initially, the robot observes an object with a specific shape and color. This object is then removed, leaving an empty table. Finally, the robot is presented with a set of fifteen objects (five shapes and three colors). The robot must successfully identify and touch the object whose shape and color matched the one observed in the first phase, demonstrating the robot’s ability to remember visual characteristics (shape and color) across time.
read the caption
Figure 13: RememberShapeAndColor5x3-v0: An object of a certain shape and color appears in front of the agent. Then the object disappears and the agent sees an empty table. Then objects of 5 different shapes and 3 different colors appear on the table and the agent has to touch what it observed at the beginning of the episode.

🔼 The environment includes a ball rolling across a table and a target zone. The agent must observe the ball’s initial position and velocity, predict its trajectory, and then guide the ball into the target zone by interacting with it (e.g., pushing or hitting). The task has three difficulty levels based on the ball’s velocity.
read the caption
Figure 14: InterceptMedium-v0: A ball rolls on the table in front of the agent with a random initial velocity, and the agent’s task is to intercept this ball and direct it at the target zone.

🔼 The figure shows a screenshot sequence of a robot attempting the InterceptGrabMedium-v0 task. A ball is launched across a table at a random initial velocity. The robot must predict the ball’s trajectory, precisely time its movement using its gripper to catch the ball, and then successfully lift the ball. The screenshot sequence illustrates the challenge of requiring both precise prediction of the ball’s motion and dexterous manipulation skills.
read the caption
Figure 15: InterceptGrabMedium-v0: A ball rolls on the table in front of the agent with a random initial velocity, and the agent’s task is to intercept this ball with a gripper and lift it up.

🔼 The figure shows a robotic manipulation task called RotateLenientPos-v0. A randomly oriented peg is presented to the robot arm. The goal is for the robot to rotate the peg by a specific angle. Importantly, the robot is allowed to slightly shift the peg’s position while performing the rotation, making the task less precise than a strict rotation around a fixed point. This allows for evaluation of an agent’s ability to accomplish a task while accounting for minor positional deviations.
read the caption
Figure 16: RotateLenientPos-v0: A randomly oriented peg is placed in front of the agent. The agent’s task is to rotate this peg by a certain angle (the center of the peg can be shifted).

🔼 The figure shows a robotic manipulation task where an agent needs to rotate a peg to a specific angle without moving its center. The task involves precise motor control and demonstrates a memory challenge because the agent needs to keep track of how much it has already rotated the peg.
read the caption
Figure 17: RotateStrictPos-v0: A randomly oriented peg is placed in front of the agent. The agent’s task is to rotate this peg by a certain angle (it is not allowed to move the center of the peg)

🔼 The task starts with a green cube on a table. The agent must move this cube to a red target zone. Once the cube reaches the target, the target zone changes color to violet, indicating the agent must now return the cube to its original starting position. The challenge is that the initial position of the cube is not visible to the agent after it has been moved to the red target zone; the agent must remember it from the first phase of the task.
read the caption
Figure 18: TakeItBack-v0: The agent observes a green cube in front of him. The agent’s task is to move the green cube to the red target, and as soon as it lights up violet, return the cube to its original position (the agent does not observes the original position of the cube).

🔼 The task presented in Figure 19, SeqOfColors7-v0, evaluates the agent’s sequential memory. Initially, seven uniquely colored cubes are sequentially displayed to the agent, each for five time steps. A delay period follows, showing an empty table. Finally, nine cubes (including those from the initial sequence) are displayed, and the agent must touch any of the seven cubes from the initial sequence. The order in which the agent touches the cubes does not matter; only the selection of the correct seven cubes is assessed. This design tests the ability to remember a sequence of items and retrieve them from a larger set, emphasizing the unordered retrieval aspect of sequential memory.
read the caption
Figure 19: SeqOfColors7-v0: In front of the agent, 7 cubes of different colors appear sequentially. After the last cube is shown, the agent observes an empty table. Then 9 cubes of different colors appear on the table and the agent has to touch the cubes that were shown at the beginning of the episode in any order.

🔼 This figure illustrates the BunchOfColors7-v0 task, part of the MIKASA-Robo benchmark. The task begins with seven cubes of different colors presented simultaneously to the agent. After a brief pause (empty table), nine cubes of varying colors appear. The agent’s objective is to touch only the seven cubes that were shown initially, in any order. This tests the agent’s ability to remember and recall a set of items presented at once, demonstrating memory capacity.
read the caption
Figure 20: BunchOfColors7-v0: 7 cubes of different colors appear simultaneously in front of the agent. After the agent observes an empty table. Then, 9 cubes of different colors appear on the table and the agent has to touch the cubes that were shown at the beginning of the episode in any order.

🔼 The figure demonstrates the ChainOfColors7-v0 task from the MIKASA-Robo benchmark. First, seven uniquely colored cubes are shown to the agent one at a time. Then, the cubes disappear, and nine new cubes of various colors are displayed. The agent’s task is to touch the initial seven cubes in the exact order they were initially presented. Success requires perfect sequential memory of the colors. This tests the agent’s capacity for sequential memory and precise action sequencing.
read the caption
Figure 21: ChainOfColors7-v0: In front of the agent, 7 cubes of different colors appear sequentially. After the last cube is shown, the agent sees an empty table. Then 9 cubes of different colors appear on the table and the agent must unmistakably touch the cubes that were shown at the beginning of the episode, in the same strict order.
Full paper#