TL;DR#
Long-context modeling is crucial for next-generation language models but computationally expensive. Existing sparse attention methods often struggle to achieve sufficient speedups in practice or lack effective training-time support. This paper introduces Native Sparse Attention (NSA), which addresses these limitations.
NSA employs a dynamic hierarchical sparse strategy, combining coarse-grained token compression with fine-grained token selection to preserve both global context and local precision. The method is hardware-aligned for efficient computation, and importantly, enables end-to-end training. Extensive experiments demonstrate NSA’s superior performance and efficiency over full attention and other sparse attention methods, across various benchmarks and sequence lengths.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models and efficient attention mechanisms. It introduces a novel sparse attention method that significantly improves efficiency without sacrificing performance, addressing a major bottleneck in long-context modeling. The method’s end-to-end trainability and hardware alignment are particularly important advancements, opening new avenues for optimization and practical deployment of LLMs.
Visual Insights#

🔼 This figure compares the performance and efficiency of the proposed Native Sparse Attention (NSA) model against a full attention model. The left panel shows that despite its sparsity, NSA outperforms the full attention baseline on various benchmarks, including general tasks, long-context scenarios, and reasoning evaluations. The right panel demonstrates the significant speedup achieved by NSA over full attention for processing sequences of length 64k. This speed improvement is observed across all stages of the model’s lifecycle, namely decoding, forward propagation, and backward propagation.
read the caption
Figure 1: Comparison of performance and efficiency between Full Attention model and our NSA. Left: Despite being sparse, NSA surpasses Full Attention baseline on average across general benchmarks, long-context tasks, and reasoning evaluation. Right: For 64k-length sequence processing, NSA achieves substantial computational speedup compared to Full Attention in all stages: decoding, forward propagation, and backward propagation.
| Model | MMLU | MMLU-PRO | CMMLU | BBH | GSM8K | MATH | DROP | MBPP | HumanEval | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| Acc. 5-shot | Acc. 5-shot | Acc. 5-shot | Acc. 3-shot | Acc. 8-shot | Acc. 4-shot | F1 1-shot | Pass@1 3-shot | Pass@1 0-shot | ||
| Full Attn | 0.567 | 0.279 | 0.576 | 0.497 | 0.486 | 0.263 | 0.503 | 0.482 | 0.335 | 0.443 |
| NSA | 0.565 | 0.286 | 0.587 | 0.521 | 0.520 | 0.264 | 0.545 | 0.466 | 0.348 | 0.456 |
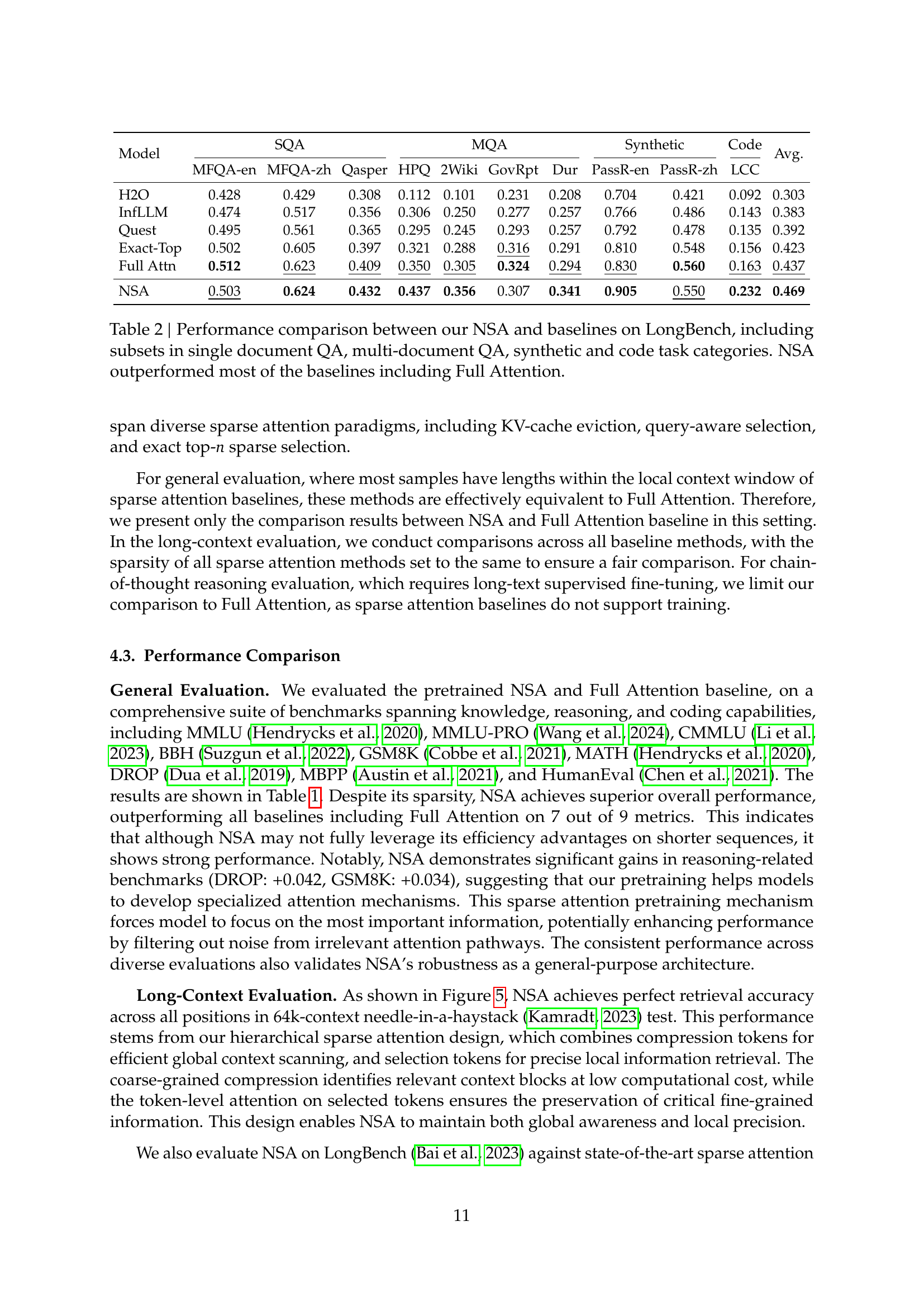
🔼 This table presents a comparison of the pretraining performance between a model using full attention and a model using the proposed Native Sparse Attention (NSA) mechanism. The comparison is made across a range of benchmark tasks categorized into three areas: knowledge, reasoning, and coding. Each area includes several specific benchmarks, providing a comprehensive evaluation of model performance across diverse task types. The results show NSA’s performance, despite its sparsity, is comparable to or better than the full attention model on most benchmarks.
read the caption
Table 1: Pretraining performance comparison between the full attention baseline and NSA on general benchmarks, across knowledge (MMLU, MMLU-PRO, CMMLU), reasoning (BBH, GSM8K, MATH, DROP), and coding (MBPP, HumanEval) tasks. NSA achieves superior average performance on most benchmarks despite high sparsity.
In-depth insights#
Long-Context Challenge#
The long-context challenge in large language models (LLMs) centers on the limitations of standard attention mechanisms when dealing with exceptionally long input sequences. Standard attention’s quadratic complexity with sequence length leads to prohibitive computational costs and memory requirements, making processing of lengthy documents or maintaining coherent multi-turn conversations extremely difficult. This significantly restricts the capabilities of LLMs in tasks requiring extensive contextual understanding, such as detailed reasoning, code generation from large codebases, or summarization of lengthy texts. Addressing this challenge requires efficient sparse attention mechanisms that cleverly reduce computational needs without sacrificing performance. Solutions often involve techniques to selectively focus attention on the most critical parts of the input, utilizing strategies like token pruning, hierarchical attention, or locality-sensitive hashing. The effectiveness of these approaches is evaluated against various benchmarks, demonstrating trade-offs between efficiency and performance. The ideal solution will balance high accuracy on long-context tasks with significant computational speedups during training and inference.
NSA Architecture#
The NSA (Natively Sparse Attention) architecture is a novel approach to sparse attention that emphasizes hardware alignment and native trainability. It cleverly integrates three attention paths: compressed attention, capturing coarse-grained patterns; selected attention, focusing on important tokens; and sliding attention, preserving local context. This hierarchical strategy is crucial, balancing global context awareness with local precision, avoiding the pitfalls of solely focusing on one aspect. The architecture’s end-to-end trainability is a significant advantage, enhancing model performance without requiring separate pre- or post-processing steps. The hardware alignment, achieved through optimized kernel designs for efficient memory access and compute utilization on Tensor Cores, is key to NSA’s speed improvements. This design makes it highly efficient across decoding, forward, and backward propagation, particularly beneficial for long sequences. Overall, the NSA architecture offers a compelling solution for long-context modeling by combining algorithmic innovation and hardware optimization for superior efficiency and performance.
Hardware Alignment#
Hardware alignment in the context of sparse attention mechanisms for large language models is crucial for achieving significant speedups. It’s not just about reducing theoretical computational complexity; it’s about optimizing algorithms to work efficiently with the underlying hardware architecture. This often involves careful consideration of memory access patterns, leveraging specialized hardware instructions like Tensor Cores, and minimizing data movement between different memory hierarchies. Algorithmic innovations must be accompanied by efficient implementations that exploit the strengths of the hardware. For example, blockwise processing of data can dramatically improve performance by reducing the number of memory accesses and improving cache utilization. The design choices, such as block size and data layout, significantly impact performance. A well-aligned design minimizes memory bottlenecks, increases arithmetic intensity, and ensures that computation is efficiently mapped to hardware resources, ultimately translating theoretical gains in sparsity to practical speedups during both training and inference.
Trainable Sparsity#
The concept of “trainable sparsity” in the context of sparse attention mechanisms is crucial for efficient long-context modeling. Existing methods often treat sparsity as a post-hoc modification, applied after model pre-training, potentially hindering the model’s ability to fully leverage the benefits of sparsity and leading to performance degradation. Trainable sparsity, however, aims to integrate sparsity directly into the training process, allowing the model to learn optimal sparsity patterns during training itself. This approach offers several advantages: improved efficiency during both training and inference, reduced computational cost, and better model performance as the model learns to focus on the most important information. The challenge lies in designing algorithms and architectures that enable effective training of sparse models without sacrificing performance, requiring innovative techniques such as hardware-aligned designs and carefully-designed training procedures. This is important because simply applying sparsity post-training often results in suboptimal performance due to the incompatibility of the sparse method with the pre-trained dense model’s underlying optimization trajectory. Therefore, a natively trainable sparse attention mechanism is needed; one that integrates the sparsity directly within its architecture and training process.
Efficiency Gains#
The research paper’s findings on efficiency gains are significant, demonstrating substantial improvements in both training and inference phases. Native Sparse Attention (NSA), the proposed method, achieves this by integrating algorithmic innovations with hardware-aligned optimizations. The hierarchical sparse strategy of NSA, combining coarse-grained token compression and fine-grained token selection, is key to preserving both global context awareness and local precision. Hardware-aligned optimizations, such as balanced arithmetic intensity and efficient memory access patterns, are crucial for the speedups reported. The paper also highlights the importance of end-to-end training, showcasing that NSA maintains or exceeds the performance of full-attention models across various benchmarks while significantly reducing computational costs, particularly noticeable in long sequence processing. Speedups are substantial across decoding, forward, and backward propagation, making NSA a promising approach for next-generation large language models.
More visual insights#
More on figures

🔼 This figure illustrates the Native Sparse Attention (NSA) architecture. The left panel shows the three main processing pathways: compressed attention (coarse-grained patterns), selected attention (important token blocks), and sliding attention (local context). These pathways operate in parallel for each query. The right panel provides a visual representation of the attention patterns generated by each branch, showing where attention scores are computed (green) and skipped (white). This highlights NSA’s hierarchical approach to efficiently handling long sequences by prioritizing important information and contextual details while selectively omitting less critical parts.
read the caption
Figure 2: Overview of NSA’s architecture. Left: The framework processes input sequences through three parallel attention branches: For a given query, preceding keys and values are processed into compressed attention for coarse-grained patterns, selected attention for important token blocks, and sliding attention for local context. Right: Visualization of different attention patterns produced by each branch. Green areas indicate regions where attention scores need to be computed, while white areas represent regions that can be skipped.

🔼 This figure illustrates the kernel design of the Native Sparse Attention (NSA) mechanism. It highlights the three main stages: the Grid Loop, the Inner Loop, and the attention computation on SRAM. The Grid Loop handles loading queries based on GQA groups. The Inner Loop focuses on sequentially loading the corresponding sparse key-value blocks into SRAM. Finally, the attention computation is performed efficiently within the SRAM. The color-coding helps differentiate data location: green blocks represent data residing in SRAM (fast access memory), whereas blue blocks denote data stored in HBM (high-bandwidth memory, slower access). This design prioritizes memory efficiency, minimizing data transfer between different memory levels and maximizing computational performance.
read the caption
Figure 3: Kernel design for NSA. The kernel loads queries by GQA groups (Grid Loop), fetches corresponding sparse KV blocks (Inner Loop), and performs attention computation on SRAM. Green blocks indicate data on SRAM, while blue indicates data on HBM.

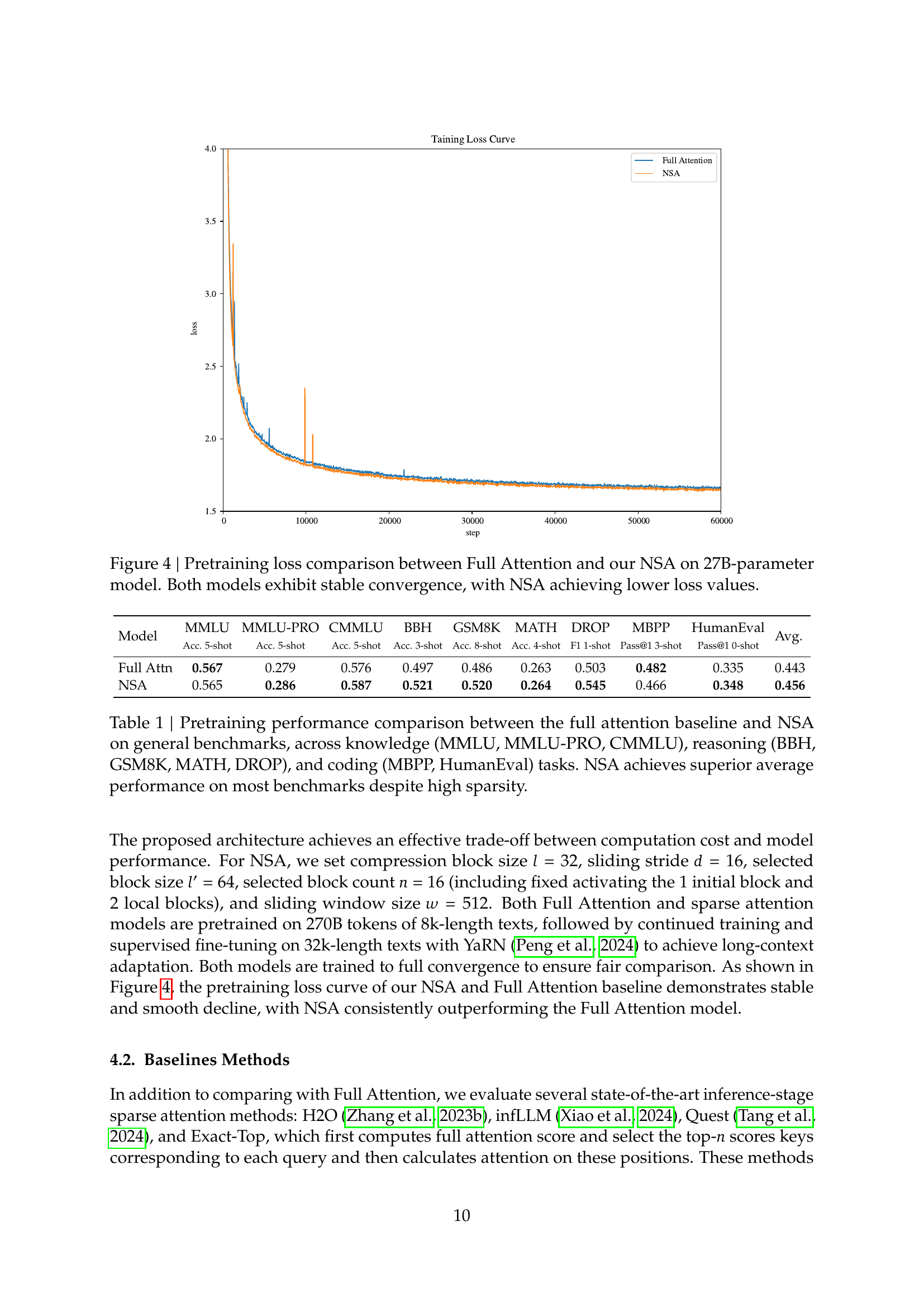
🔼 This figure displays the training loss curves for both the Full Attention model and the proposed NSA model, both trained on a 27B-parameter model. The x-axis represents the training steps, and the y-axis represents the training loss. Both curves show a steady decrease in loss as training progresses, indicating stable convergence. Notably, the NSA model consistently achieves a lower training loss compared to the Full Attention model, suggesting improved training efficiency and possibly better generalization potential.
read the caption
Figure 4: Pretraining loss comparison between Full Attention and our NSA on 27B-parameter model. Both models exhibit stable convergence, with NSA achieving lower loss values.

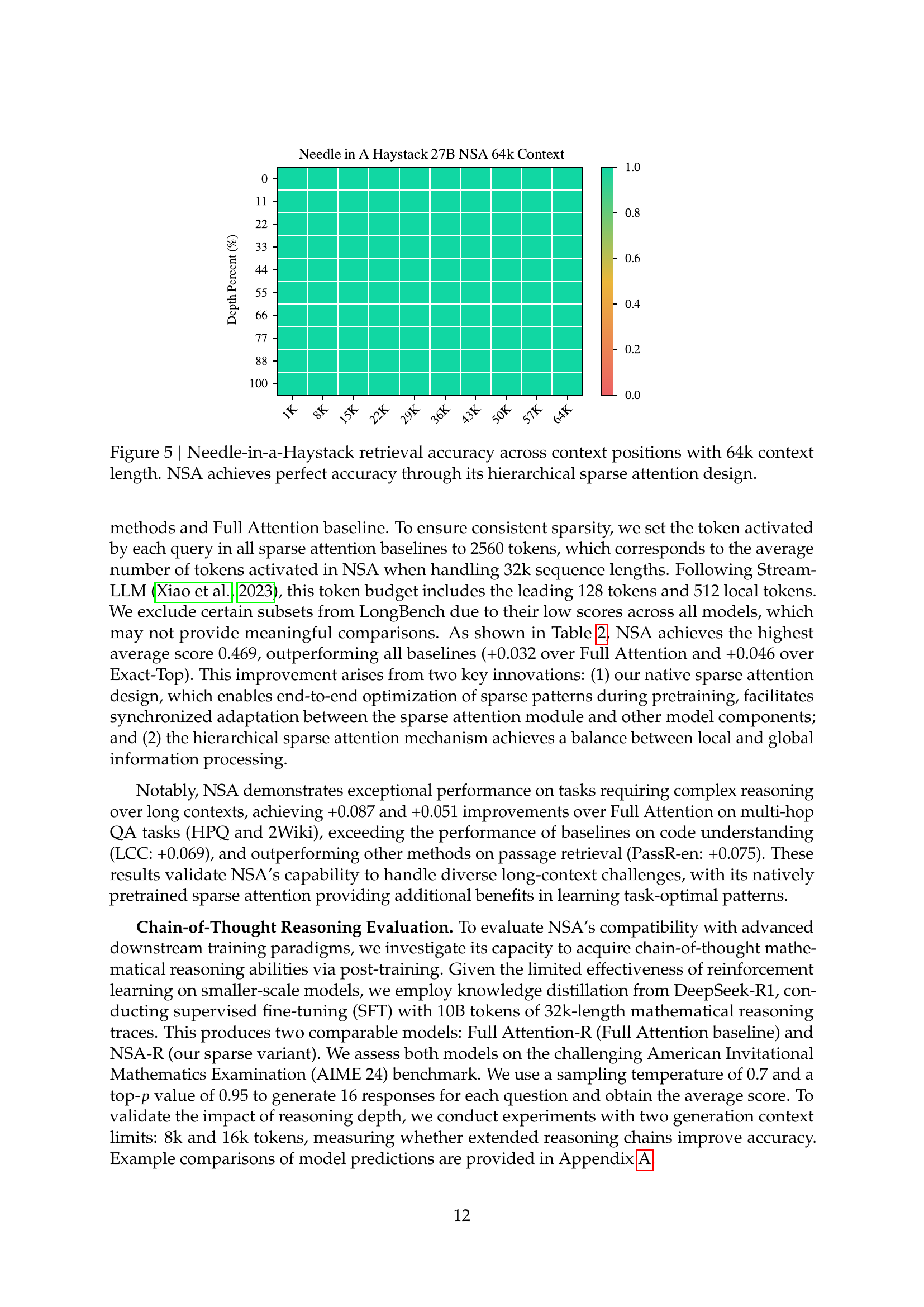
🔼 This figure displays the Needle-in-a-Haystack retrieval accuracy across different context positions within a 64k context length. The y-axis represents the retrieval accuracy (percentage), and the x-axis shows the context position. The heatmap visualization clearly demonstrates that NSA (Natively trainable Sparse Attention) achieves perfect (100%) accuracy across all positions. This highlights the effectiveness of NSA’s hierarchical sparse attention mechanism in accurately retrieving information even with extremely long contexts.
read the caption
Figure 5: Needle-in-a-Haystack retrieval accuracy across context positions with 64k context length. NSA achieves perfect accuracy through its hierarchical sparse attention design.

🔼 This figure compares the performance of the NSA (Natively trainable Sparse Attention) kernel with the FlashAttention-2 kernel, both implemented using Triton. The x-axis represents the input sequence length, and the y-axis shows the execution time in milliseconds for forward and backward propagation, as well as decoding. The results demonstrate that NSA significantly reduces latency across all sequence lengths tested, achieving a speedup of up to 9x for forward propagation and 6x for backward propagation at a sequence length of 64k. The speedup is more pronounced as the input sequence length increases.
read the caption
Figure 6: Comparison of Triton-based NSA kernel with Triton-based FlashAttention-2 kernel. Our implementation significantly reduces latency across all context lengths, with the improvement becoming more pronounced as input length increases.

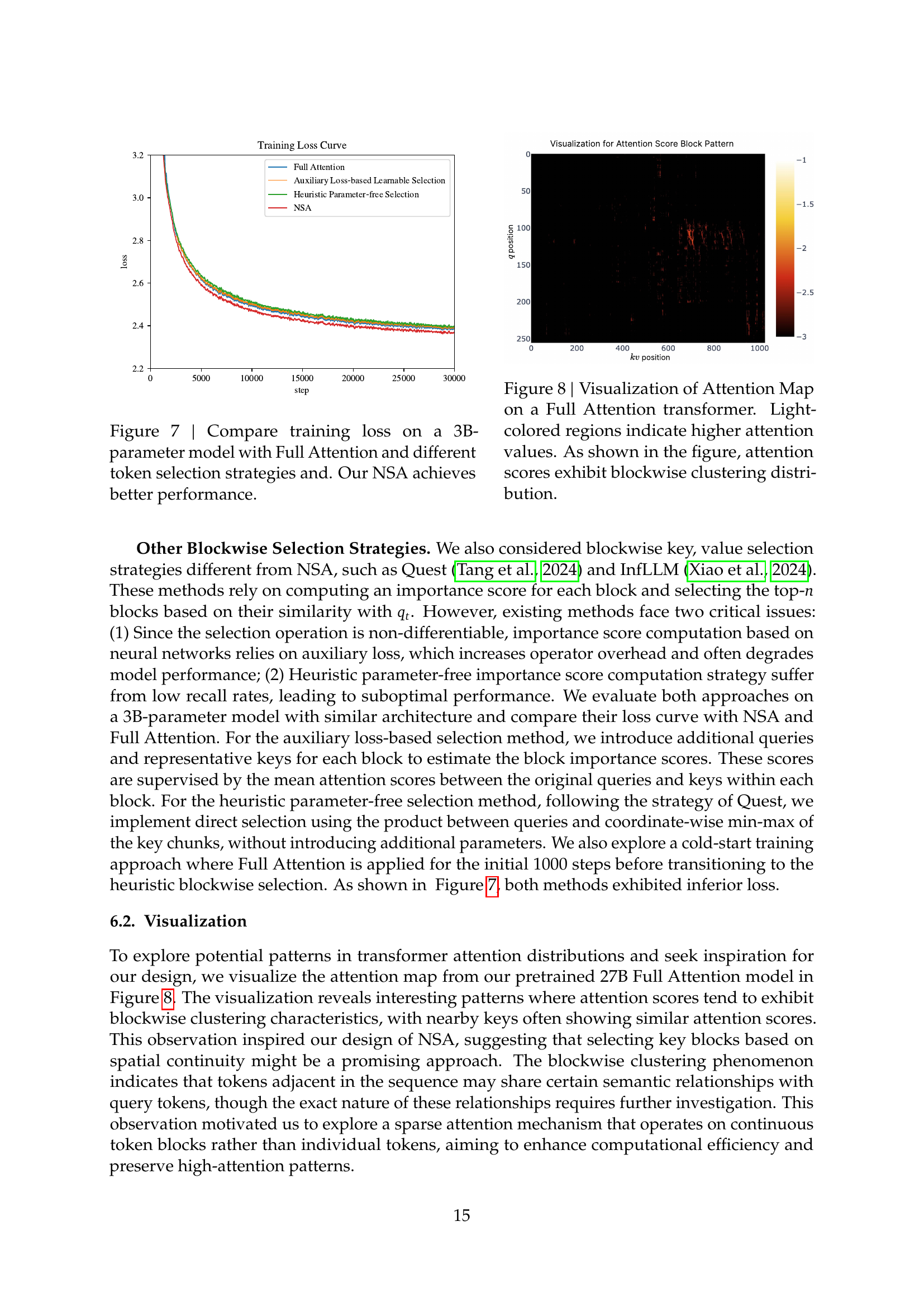
🔼 This figure compares the training loss curves for a 3-billion parameter model trained with different sparse attention methods and Full Attention. The x-axis shows training steps, and the y-axis shows the training loss. The curves show that a model using the proposed NSA (Natively Sparse Attention) method achieves significantly lower training loss compared to models using other token selection strategies and the baseline Full Attention method. This demonstrates the effectiveness of NSA in achieving efficient and accurate training.
read the caption
Figure 7: Compare training loss on a 3B-parameter model with Full Attention and different token selection strategies and. Our NSA achieves better performance.

🔼 This figure visualizes the attention map generated by a full attention transformer model. The heatmap shows the attention weights between different tokens in the input sequence. Lighter colors represent higher attention weights, indicating stronger relationships between the corresponding tokens. The visualization reveals a notable pattern: the attention scores exhibit a blockwise clustering distribution. This means that tokens within the same block tend to have stronger attention weights among themselves compared to tokens outside the block. This blockwise clustering behavior suggests that attention is not uniformly distributed but rather concentrated in specific regions or blocks of tokens, which is a key observation that inspired the design of the NSA architecture.
read the caption
Figure 8: Visualization of Attention Map on a Full Attention transformer. Light-colored regions indicate higher attention values. As shown in the figure, attention scores exhibit blockwise clustering distribution.
More on tables
| Model | SQA | MQA | Synthetic | Code | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MFQA-en | MFQA-zh | Qasper | HPQ | 2Wiki | GovRpt | Dur | PassR-en | PassR-zh | LCC | ||
| H2O | 0.428 | 0.429 | 0.308 | 0.112 | 0.101 | 0.231 | 0.208 | 0.704 | 0.421 | 0.092 | 0.303 |
| InfLLM | 0.474 | 0.517 | 0.356 | 0.306 | 0.250 | 0.277 | 0.257 | 0.766 | 0.486 | 0.143 | 0.383 |
| Quest | 0.495 | 0.561 | 0.365 | 0.295 | 0.245 | 0.293 | 0.257 | 0.792 | 0.478 | 0.135 | 0.392 |
| Exact-Top | 0.502 | 0.605 | 0.397 | 0.321 | 0.288 | 0.316 | 0.291 | 0.810 | 0.548 | 0.156 | 0.423 |
| Full Attn | 0.512 | 0.623 | 0.409 | 0.350 | 0.305 | 0.324 | 0.294 | 0.830 | 0.560 | 0.163 | 0.437 |
| NSA | 0.503 | 0.624 | 0.432 | 0.437 | 0.356 | 0.307 | 0.341 | 0.905 | 0.550 | 0.232 | 0.469 |
🔼 This table presents a performance comparison of different sparse attention methods, including the proposed NSA (Natively trainable Sparse Attention) model and several baseline methods, on the LongBench benchmark. LongBench is a comprehensive benchmark dataset that evaluates long-context understanding performance across diverse tasks such as single-document question answering, multi-document question answering, synthetic tasks, and code-related tasks. The table shows the performance of each model on each of these tasks, indicating that NSA outperforms most other methods, including the Full Attention model which serves as a strong baseline.
read the caption
Table 2: Performance comparison between our NSA and baselines on LongBench, including subsets in single document QA, multi-document QA, synthetic and code task categories. NSA outperformed most of the baselines including Full Attention.
| Generation Token Limit | 8192 | 16384 |
|---|---|---|
| Full Attention-R | 0.046 | 0.092 |
| NSA-R | 0.121 | 0.146 |
🔼 This table presents the results of evaluating two models, NSA-R (Natively trainable Sparse Attention) and Full Attention-R, on the American Invitational Mathematics Examination (AIME) after supervised fine-tuning. Both models underwent fine-tuning using 10B tokens of 32k-length mathematical reasoning traces. The evaluation focused on instruction-based reasoning tasks and assessed performance at both 8k and 16k sequence lengths. The key metric is the accuracy of the models in solving the AIME problems. The table aims to showcase the superior performance of NSA-R compared to the Full Attention-R model for instruction-based reasoning tasks, specifically highlighting its effectiveness at different sequence lengths. This demonstrates that the NSA-R’s architectural design and training approach are beneficial for long-context, complex reasoning tasks.
read the caption
Table 3: AIME Instruction-based Evaluating after supervised fine-tuning. Our NSA-R demonstrates better performance than Full Attention-R at both 8k and 16k sequence lengths
| Context Length | 8192 | 16384 | 32768 | 65536 |
|---|---|---|---|---|
| Full Attention | 8192 | 16384 | 32768 | 65536 |
| NSA | 2048 | 2560 | 3584 | 5632 |
| Expected Speedup | 4 | 6.4 | 9.1 | 11.6 |
🔼 This table presents the memory access volume during the decoding phase for both the Full Attention model and the NSA model, measured in equivalent numbers of tokens. The low arithmetic intensity and memory-bound nature of the decoding process lead to a nearly linear relationship between memory access volume and speedup. Specifically, it shows how many tokens are accessed in each model during decoding for different sequence lengths (8192, 16384, 32768, and 65536 tokens). The expected speedup of the NSA model is also calculated and presented, demonstrating the significant efficiency gains achieved by the model.
read the caption
Table 4: Memory access volume (in equivalent number of tokens) per attention operation during decoding. Due to the low arithmetic intensity and memory-bound nature of decoding, the expected speedup is approximately linear with the volume of memory access.
Full paper#