TL;DR#
Existing LLM multi-agent systems struggle with managing communication and refining collaborative efforts, leading to issues such as incorrect outputs and biases. These problems are exacerbated in complex tasks that require multiple agents to coordinate. Many existing systems employ simplistic methods such as majority voting, which are not effective for handling diverse or conflicting information.
TalkHier offers a solution by introducing a well-structured communication protocol that facilitates clear and organized exchanges between agents. It also uses a hierarchical refinement system to process and integrate the feedback from multiple evaluators, ensuring that diverse opinions are carefully considered and integrated. This approach leads to significant improvements in accuracy and adaptability across various benchmarks, setting a new standard for LLM-MA system design. TalkHier’s superior performance stems from its well-defined structure and effective refinement strategies.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) and multi-agent systems. It directly addresses the significant challenges of communication and refinement in LLM-based collaborations, offering a novel framework and demonstrating state-of-the-art results. The proposed methods improve efficiency and accuracy, opening new avenues for building more effective and adaptable multi-agent systems.
Visual Insights#

🔼 This figure illustrates the limitations of existing Large Language Model Multi-Agent (LLM-MA) systems and how the proposed TalkHier framework addresses these issues. The left side shows traditional LLM-MA approaches which suffer from disorganized, lengthy text-based communication and simple, sequential refinement methods that struggle to manage multiple perspectives. This often leads to inconsistent or suboptimal outcomes. In contrast, the right side presents TalkHier, highlighting its key improvements: a well-structured communication protocol and a hierarchical refinement strategy. The structured protocol promotes clearer, more efficient information exchange, and hierarchical refinement enables a more controlled and effective synthesis of diverse opinions leading to superior decision-making.
read the caption
Figure 1: Existing LLM-MA methods (left) face two major challenges: 1) disorganized, lengthy text-based communication protocols, and 2) sequential or overly similar flat multi-agent refinements. In contrast, TalkHier (right) introduces a well-structured communication protocol and a hierarchical refinement approach.
| Models | Moral | Phys. | ML | FL | UFP | Avg. |
|---|---|---|---|---|---|---|
| GPT4o | 64.25 | 62.75 | 67.86 | 63.49 | 92.00 | 70.07 |
| GPT4o-3@ | 65.70 | 62.75 | 66.07 | 66.67 | 91.00 | 70.44 |
| GPT4o-5@ | 66.15 | 61.76 | 66.96 | 66.67 | 92.00 | 70.71 |
| GPT4o-7@ | 65.81 | 63.73 | 66.96 | 68.25 | 91.00 | 71.15 |
| ReAct | 69.61 | 72.55 | 59.82 | 32.54 | 58.00 | 58.50 |
| ReAct-3@ | 74.75 | 83.33 | 66.07 | 52.38 | 53.00 | 65.91 |
| ReAct-5@ | 74.97 | 82.35 | 66.96 | 46.83 | 63.00 | 66.82 |
| ReAct-7@ | 75.53 | 84.78 | 67.86 | 50.79 | 57.00 | 67.19 |
| AutoGPT | 66.37 | 78.43 | 64.29 | 60.83 | 90.00 | 71.98 |
| AgentVerse | 79.11 | 93.14 | 79.46 | 78.57 | 88.00 | 83.66 |
| GPTSwarm | 60.48 | 67.70 | 72.32 | 68.33 | 57.00 | 65.17 |
| AgentPrune | 70.84 | 91.18 | 81.25 | 81.75 | 93.00 | 83.60 |
| o1-preview | 82.57 | 91.17 | 85.71 | 83.33 | 95.00 | 87.56 |
| TalkHier (Ours) | 83.80 | 93.14 | 84.68 | 87.30 | 93.00 | 88.38 |
🔼 This table presents the performance of various language models on the Massive Multitask Language Understanding (MMLU) benchmark. It shows the accuracy (in percentage) achieved by different models across five specific domains within MMLU: Moral Scenarios, College Physics, Machine Learning, Formal Logic, and US Foreign Policy. The models tested include GPT-40 (with single runs and ensemble results using 3, 5, and 7 independent runs, denoted as 3@, 5@, and 7@ respectively), ReAct, AutoGPT, AgentVerse, and GPTSwarm. The table allows for a comparison of the performance of different models (single-agent, multi-agent, and open-source) and approaches (single-run versus ensemble) across a range of diverse knowledge areas.
read the caption
Table 1: General Performance on MMLU Dataset. The table reports accuracy (%) for various baselines across Moral Scenario (Moral), College Physics (Phys.), Machine Learning (ML), Formal Logic (FL) and US Foreign Policy (UFP) domains. The notations 3@, 5@, and 7@ represent majority voting results using 3, 5, and 7 independent runs, respectively.
In-depth insights#
LLM-MA Collab#
LLM-MA collaboration represents a significant advancement in AI, aiming to leverage the strengths of multiple Large Language Models (LLMs) for complex tasks. Effective communication protocols are crucial, moving beyond simple text exchanges to structured formats that include context, intermediate results, and clearly defined roles. A hierarchical refinement process, where agents specialize and their outputs are evaluated and iteratively improved by others, offers improved accuracy and reduces bias compared to flat, sequential approaches. Agent-specific memory is essential for maintaining coherent context and avoiding redundancy across interactions. This approach promises enhanced efficiency and scalability, tackling problems beyond the reach of single LLMs. However, challenges remain in optimizing communication topologies, managing the computational cost of multiple LLM agents, and ensuring fairness and balance across diverse agent contributions. Future work should focus on developing robust evaluation metrics and addressing scalability issues to realize the full potential of LLM-MA collaboration.
TalkHier Framework#
The TalkHier framework presents a novel approach to LLM-based multi-agent systems, addressing critical challenges in communication and refinement. Structured communication is key, enabling efficient context-rich exchanges between agents. A hierarchical refinement system manages the flow of opinions and feedback from multiple evaluators, improving accuracy and reducing bias. The framework’s hierarchical structure, with a supervisor agent coordinating tasks and managing agent roles, is crucial for handling complex problems. Agent-specific memory allows individual agents to retain relevant information, improving efficiency and preventing information loss. The combination of these elements results in a more effective and robust multi-agent system, exceeding state-of-the-art baselines on various benchmark tasks. TalkHier’s success highlights the importance of well-structured communication and a sophisticated refinement process in unlocking the full potential of LLM-based multi-agent collaboration.
Hierarchical Refinement#
Hierarchical refinement, in the context of multi-agent systems using Large Language Models (LLMs), represents a significant advancement in collaborative problem-solving. Instead of a flat, sequential evaluation process, it introduces a layered structure where agents specialize in specific tasks. Supervisory agents aggregate and summarize the evaluations of lower-level agents, ensuring a more robust and less biased final assessment. This approach mitigates the challenges associated with managing diverse opinions and feedback from numerous agents. By organizing evaluations hierarchically, it addresses issues such as order bias and the difficulty of summarizing multifaceted opinions from a large group. Improved accuracy and reduced redundancy are key benefits of this structured system, paving the way for more sophisticated collaborative LLMs capable of handling increasingly complex tasks. The hierarchical refinement also promotes efficiency by avoiding redundant computations and allowing for better prioritization of feedback. This makes it scalable for applications with many agents involved.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a multi-agent LLM system, this involves isolating specific agents or communication protocols to determine their impact on overall performance. By progressively removing elements such as hierarchical refinement, specific communication protocols (e.g., eliminating background information or intermediate outputs), or even entire agent types (evaluators or supervisors), researchers can pinpoint critical components. This process is crucial for understanding the system’s architecture and identifying areas for improvement. The results typically highlight the relative importance of each component, revealing which are most essential to achieving high accuracy. A well-designed ablation study should demonstrate that the removal of key features significantly degrades performance, validating the design choices of the system. This technique is essential in discerning essential functionality from superfluous features, optimizing efficiency and offering valuable insights for future system development.
Future Work#
Future research directions stemming from this LLM-MA framework could explore more cost-effective methods for generating and evaluating responses, addressing the high API costs associated with the current approach. Investigating alternative architectures or training strategies that reduce reliance on expensive APIs is crucial for broader accessibility. Additionally, improving the framework’s adaptability to diverse domains and tasks beyond the benchmarks used would significantly broaden its impact. This could involve incorporating more diverse data sets and testing on a wider range of tasks, including more complex real-world scenarios. Another important area is to further enhance the framework’s ability to handle increasingly complex multi-agent interactions, perhaps by exploring novel communication protocols or refinement strategies, including more sophisticated approaches to handling biases and uncertainty. Furthermore, in-depth analysis of the hierarchical refinement process is needed to better understand its strengths and limitations, potentially leading to improved algorithms and more efficient feedback mechanisms. Finally, research into human-in-the-loop systems that leverage human expertise to guide and refine the multi-agent system’s decisions would enhance both accuracy and reliability.
More visual insights#
More on figures

🔼 Figure 2 presents a bar chart comparing the performance of different multi-agent systems on five subtasks of the Massive Multitask Language Understanding (MMLU) benchmark. The chart shows that the TalkHier model, built upon GPT-40, outperforms several state-of-the-art (SoTA) models. These SoTA models include inference scaling models (like OpenAI-01), open-source multi-agent systems (such as AgentVerse), and models that utilize majority voting strategies (like ReAct and GPT-40 with multiple runs). The chart highlights TalkHier’s superior accuracy across diverse tasks, demonstrating its effectiveness as a collaborative multi-agent framework.
read the caption
Figure 2: Our TalkHier built on GPT4o surpasses inference scaling models (OpenAI-o1), open-source multi-agent models (AgentVerse and etc.), and models with majority voting strategies (ReAct, GPT4o) on five subtasks of MMLU.

🔼 Figure 3 illustrates the core differences between traditional LLM-MA systems and the proposed TalkHier framework. The left side depicts existing methods characterized by disorganized textual communication and flat, sequential evaluation processes. This often leads to inconsistencies and biases. In contrast, TalkHier (right side) introduces a structured communication protocol (top) incorporating messages, intermediate outputs, and background information for context-rich exchanges. This is followed by a hierarchical refinement process (bottom) where evaluation teams provide summarized and coordinated feedback, addressing limitations of previous approaches. This hierarchical structure balances opinions, reduces bias, and improves overall accuracy.
read the caption
Figure 3: Comparisons between existing approaches (left) and ours (right). Our TalkHier proposes a new communication protocol (first row) featuring context-rich and well-structured communication information, along with a collaborative hierarchical refinement (second row) where evaluations provide summarized and coordinated feedback within an LLM-MA framework.

🔼 Figure 4 shows the prompt templates used in the TalkHier framework to facilitate context-rich and structured communication between agents. The
Supervisor Prompt Templateguides the supervisor agent in assigning tasks to other agents, providing necessary background information, intermediate outputs, and instructions for the next agent’s action. It ensures a well-structured flow of information. TheMember Prompt Templateguides the member agents in understanding their assigned subtasks, using the provided background and conversation history to generate accurate and relevant responses. Both prompts emphasize structured communication to maintain clarity and efficiency throughout the collaborative process.read the caption
Figure 4: Prompts for acquiring the contents of the context-rich, structured communication protocol in TalkHier.
More on tables
| Models | Rouge-1 | BERTScore |
|---|---|---|
| GPT4o | 0.2777 | 0.5856 |
| ReAct | 0.2409 | 0.5415 |
| AutoGPT | 0.3286 | 0.5885 |
| AgentVerse | 0.2799 | 0.5716 |
| AgentPrune | 0.3027 | 0.5788 |
| GPTSwarm | 0.2302 | 0.5067 |
| o1-preview | 0.2631 | 0.5701 |
| TalkHier (Ours) | 0.3461 | 0.6079 |
🔼 This table presents the performance of different models on the WikiQA dataset, a benchmark for open-domain question answering. It shows the Rouge-1 and BERTScore for each model. Rouge-1 measures the overlap of unigrams between the generated and reference answers, while BERTScore evaluates semantic similarity. Higher scores indicate better performance in generating accurate and relevant answers to complex questions.
read the caption
Table 2: Evaluation Results on WikiQA. The table reports Rouge-1 and BERTScore for various models.
| Models | Moral | Phys. | ML | Avg. |
|---|---|---|---|---|
| w/o Eval. Sup. | 83.57 | 87.25 | 74.77 | 81.86 |
| w/o Eval. Team | 73.54 | 80.34 | 74.56 | 76.15 |
| w. Norm. Comm | 82.91 | 88.24 | 82.14 | 84.43 |
| React (Single Agent) | 69.61 | 72.55 | 59.82 | 67.33 |
| TalkHier (Ours) | 83.80 | 93.14 | 84.68 | 87.21 |
🔼 This table presents the ablation study results for the TalkHier model, evaluating the impact of removing key components on its performance across three domains: Physics, Machine Learning, and Moral. Specifically, it shows the accuracy achieved by TalkHier with the removal of the evaluation supervisor (TalkHier w/o Eval. Sup.), the removal of the evaluation team (TalkHier w/o Eval. Team), and the use of a normalized communication protocol instead of the model’s structured protocol (TalkHier w. Norm. Comm). The results help determine the relative importance of each component to the overall model’s accuracy.
read the caption
Table 3: Ablative Results on Main Components of TalkHier: Accuracy (%) across Physics, ML, and Moral domains. TalkHier w/o Eval. Sup. removes the evaluation supervisor. TalkHier w/o Eval. Team excludes the evaluation team component. TalkHier w. Norm. Comm uses a normalized communication protocol.
| Models | Moral | Phys. | ML | Avg. |
|---|---|---|---|---|
| w/o | 81.56 | 90.20 | 75.89 | 82.55 |
| w/o | 76.87 | 87.50 | 70.54 | 78.30 |
| w/o | 77.99 | 90.20 | 78.57 | 82.25 |
| TalkHier (Ours) | 83.80 | 93.14 | 84.68 | 87.21 |
🔼 This table presents the ablation study results for the TalkHier model, focusing on the impact of removing components from the structured communication protocol on accuracy across three MMLU domains: Physics, Machine Learning, and Moral. The study systematically removes elements from the protocol, namely messages, background information, and intermediate outputs, to assess their individual contributions to the overall performance. By comparing the performance of TalkHier with and without each component, the study reveals the importance of each element for achieving high accuracy. The results demonstrate the effectiveness of the structured communication protocol and its impact on the performance of TalkHier.
read the caption
Table 4: Ablative Results: Accuracy (%) across Physics, ML, and Moral domains. The study examines the impact of removing components from the structured communication protocol: message (𝐌ijsubscript𝐌𝑖𝑗\mathbf{M}_{ij}bold_M start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT), background (𝐁ijsubscript𝐁𝑖𝑗\mathbf{B}_{ij}bold_B start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT), and intermediate output (𝐈ijsubscript𝐈𝑖𝑗\mathbf{I}_{ij}bold_I start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT).
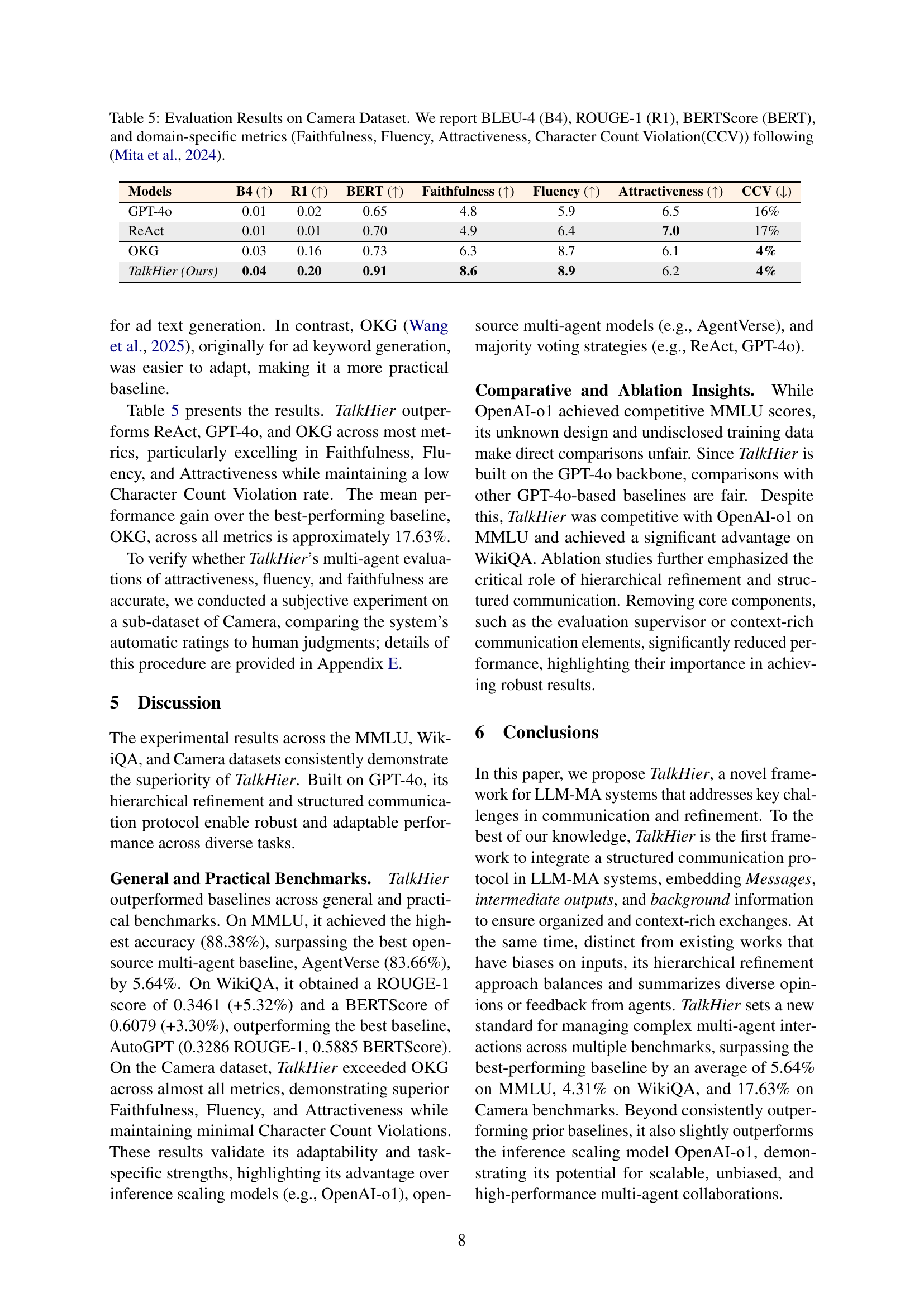
| Models | B4 (↑) | R1 (↑) | BERT (↑) | Faithfulness (↑) | Fluency (↑) | Attractiveness (↑) | CCV (↓) |
|---|---|---|---|---|---|---|---|
| GPT-4o | 0.01 | 0.02 | 0.65 | 4.8 | 5.9 | 6.5 | 16% |
| ReAct | 0.01 | 0.01 | 0.70 | 4.9 | 6.4 | 7.0 | 17% |
| OKG | 0.03 | 0.16 | 0.73 | 6.3 | 8.7 | 6.1 | 4% |
| TalkHier (Ours) | 0.04 | 0.20 | 0.91 | 8.6 | 8.9 | 6.2 | 4% |
🔼 This table presents the quantitative evaluation results of different models on the Camera dataset, a benchmark for Japanese ad text generation. The performance of each model is assessed using several metrics, which can be categorized into two groups: general-purpose metrics for evaluating text quality and domain-specific metrics for evaluating advertisement effectiveness. The general-purpose metrics include BLEU-4, ROUGE-1, and BERTScore, which measure aspects like fluency and semantic similarity. The domain-specific metrics are Faithfulness (how well the ad reflects the product), Fluency (how well-written the ad is), Attractiveness (how engaging the ad is), and Character Count Violation (how well the ad adheres to character limits). Higher scores generally indicate better performance.
read the caption
Table 5: Evaluation Results on Camera Dataset. We report BLEU-4 (B4), ROUGE-1 (R1), BERTScore (BERT), and domain-specific metrics (Faithfulness, Fluency, Attractiveness, Character Count Violation(CCV)) following Mita et al. (2024).
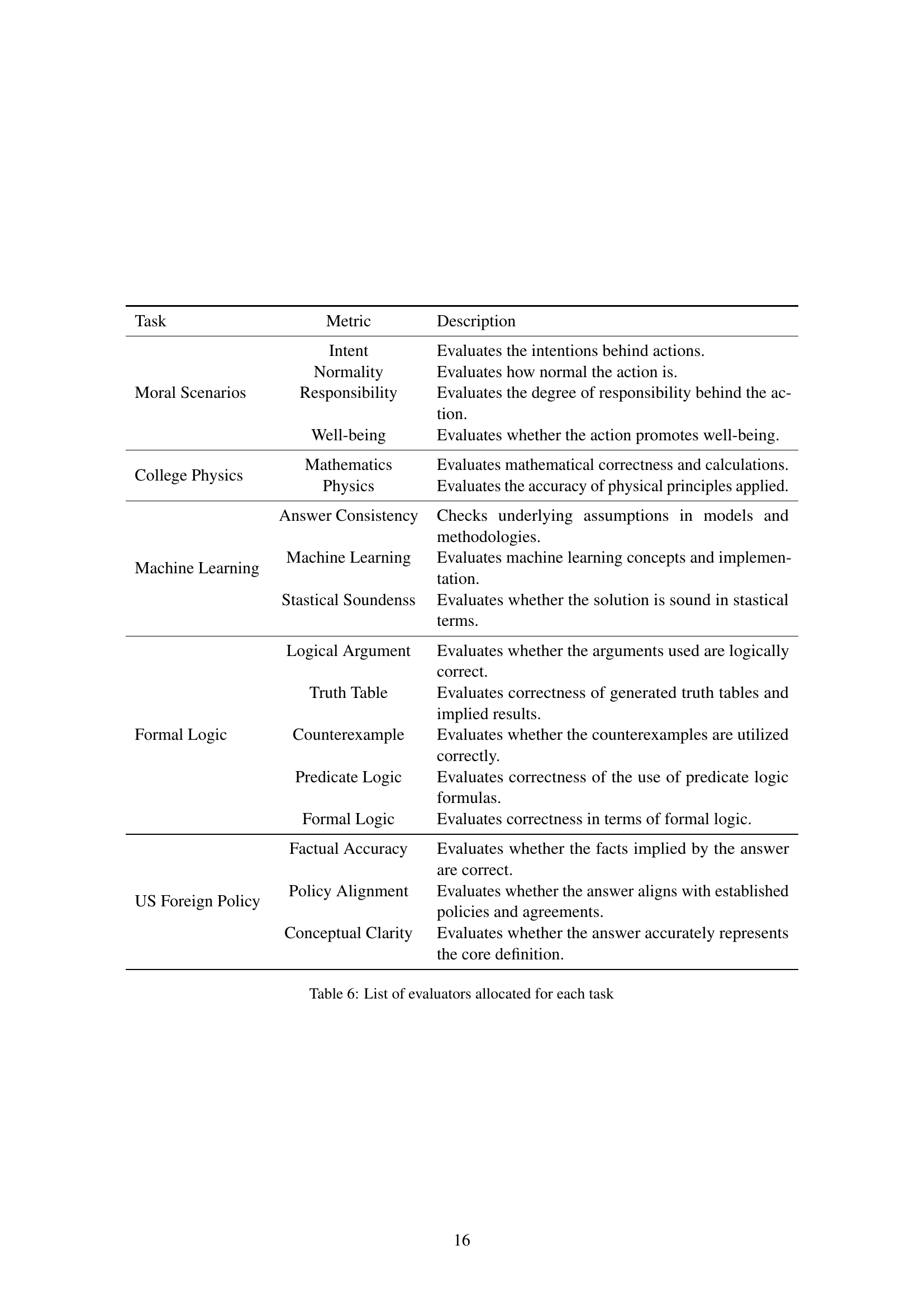
| Task | Metric | Description |
| Moral Scenarios | Intent | Evaluates the intentions behind actions. |
| Normality | Evaluates how normal the action is. | |
| Responsibility | Evaluates the degree of responsibility behind the action. | |
| Well-being | Evaluates whether the action promotes well-being. | |
| College Physics | Mathematics | Evaluates mathematical correctness and calculations. |
| Physics | Evaluates the accuracy of physical principles applied. | |
| Machine Learning | Answer Consistency | Checks underlying assumptions in models and methodologies. |
| Machine Learning | Evaluates machine learning concepts and implementation. | |
| Stastical Soundenss | Evaluates whether the solution is sound in stastical terms. | |
| Formal Logic | Logical Argument | Evaluates whether the arguments used are logically correct. |
| Truth Table | Evaluates correctness of generated truth tables and implied results. | |
| Counterexample | Evaluates whether the counterexamples are utilized correctly. | |
| Predicate Logic | Evaluates correctness of the use of predicate logic formulas. | |
| Formal Logic | Evaluates correctness in terms of formal logic. | |
| US Foreign Policy | Factual Accuracy | Evaluates whether the facts implied by the answer are correct. |
| Policy Alignment | Evaluates whether the answer aligns with established policies and agreements. | |
| Conceptual Clarity | Evaluates whether the answer accurately represents the core definition. |
🔼 This table details the evaluation metrics used for each task in the MMLU benchmark. For each task (Moral Scenarios, College Physics, Machine Learning, Formal Logic, and US Foreign Policy), the table lists the specific metrics used to assess the quality of generated answers. These metrics include aspects such as the logical soundness of arguments, the accuracy of mathematical calculations, the ethical considerations of responses, and the alignment with established policies (where applicable). The descriptions provide a clear understanding of what each metric evaluates in the context of its corresponding task.
read the caption
Table 6: List of evaluators allocated for each task
| Before Revision | After Revision |
|---|---|
| Challenge prestigious school entrance exams | Support your challenge to enter prestigious schools |
| Guidance from professional home tutors | High-quality guidance from professional home tutors |
| We provide sure-win exam preparation | We provide reliable exam preparation |
| Improve grades with a customized curriculum | Boost grades with a customized curriculum |
| Prepare for exams online | Effective exam preparation online |
🔼 This table showcases examples of how ad headlines for educational services were improved through revisions. The original headlines, written in Japanese, were translated into English for clarity. The table highlights specific changes made to the headlines (shown in green text) to enhance readability, appeal, and persuasiveness without altering the original intent. It demonstrates how refinements focused on strengthening key selling points, enhancing emotional impact, and ensuring clear communication with potential customers.
read the caption
Table 7: Revisions of Educational Ad Headlines with Highlights (Original: Japanese, Translated: English). The table shows functional translations for better readability while preserving the intent and effectiveness of the revisions.
| Before Revision | After Revision |
|---|---|
| Get a job with Baitoru NEXT | Find your ideal job with Baitoru NEXT |
| Job change and employment with Baitoru NEXT | For career change and employment, use Baitoru NEXT |
| Aim to debut with Baitoru NEXT | Start your career with Baitoru NEXT |
| Start your job search | Take the first step in your career |
| Find a new workplace | Discover new job opportunities |
| Opportunity to aim for a debut | Opportunities for a successful debut |
🔼 This table presents before-and-after revisions of employment ad headlines originally written in Japanese and then translated into English. The ‘Before Revision’ column shows the original Japanese headline’s English translation, while the ‘After Revision’ column displays the revised version. The revisions aim to improve readability and effectiveness, preserving the original intent. Highlighted text indicates specific changes made to improve the headline’s clarity, appeal, or impact. This allows readers to directly observe the types of modifications done to enhance the ads.
read the caption
Table 8: Revisions of Employment Ad Headlines with Highlights (Original: Japanese, Translated: English). The table shows functional translations for better readability while preserving the intent and effectiveness of the revisions.
| Headline | Method | Generated Headline (English) | Human1 | Human2 | Human… | TalkHier |
| H1_card | TalkHier | LifeCard with No Annual Fee | 4.33 | 4.33 | … | 5 |
| H2_card | TalkHier | Receive Your Card in Two Business Days | 5 | 4.66 | … | 4 |
| H3_card | TalkHier | Earn Points for Every ¥100 You Spend | 4.33 | 5 | … | 4.33 |
| H4_card | TalkHier | Triple Points on Your Birthday Month | 4.33 | 4.33 | … | 5 |
| H5_card | TalkHier | A Card That Fits Your Lifestyle | 2.33 | 4 | … | 4 |
| H6_card | ReAct | Full of Benefits, LifeCard is Here | 3.66 | 3 | … | 3 |
| H7_card | ReAct | Start a New Life with LifeCard | 2.33 | 3.66 | … | 2.33 |
| H8_card | ReAct | Save Smartly with LifeCard | 3.66 | 4.33 | … | 3 |
| H9_card | ReAct | Shop with LifeCard | 3.66 | 3.66 | … | 3 |
| H10_card | ReAct | Trusted and Reliable Life Card | 3.66 | 4 | … | 3.66 |
| …(remaining headlines not shown) | ||||||
🔼 Table 9 presents a subset of the data used in a subjective human evaluation experiment comparing headline quality generated by the TalkHier model and a baseline (ReAct) model. The table shows 10 headlines for a ‘credit card’ product. For each headline, the table indicates whether it was generated by TalkHier or ReAct, and shows the ratings provided by three of four human evaluators, along with a rating from the TalkHier evaluation team. This allows a comparison of the relative performance of TalkHier versus ReAct, highlighting the tendency for TalkHier to receive higher scores.
read the caption
Table 9: A sample of 10 headlines for the “credit card” product (LifeCard). Five are generated by TalkHier, and five by the baseline ReAct. We show partial ratings (three of the four human raters plus the TalkHier evaluation team) to illustrate how TalkHier generally receives higher scores than the Baseline.
| Metric | Value | p-value |
|---|---|---|
| Pearson Correlation | 0.67 | 0.036 |
| Spearman Correlation | 0.68 | 0.030 |
| ICC (2,1) | 0.23 | – |
| ICC (2,4) | 0.33 | – |
🔼 This table presents the results of an evaluation comparing TalkHier’s headline ratings to human ratings. It shows how well TalkHier’s automated scoring aligns with human judgment on the quality of generated ad headlines. Specifically, it reports the Pearson and Spearman correlations between TalkHier’s ratings and the average human ratings, as well as the Intraclass Correlation Coefficient (ICC). The ICC is presented in two forms: ICC(2,1), assessing agreement with individual human raters, and ICC(2,4), assessing agreement with the overall human consensus. Because of the small number of headlines evaluated (10), confidence intervals are not reported.
read the caption
Table 10: Summary of evaluation metrics demonstrating how closely TalkHier’s scores align with human ratings for the 10 generated headlines. Confidence intervals (CIs) are not reported due to the small sample size.
Full paper#