TL;DR#
Large Language Models (LLMs), despite their impressive abilities, lack a clear understanding of how they learn new information. Existing research often treats knowledge as isolated units, failing to capture the dynamic interplay within the model’s complex network. This limits our ability to improve continual learning in LLMs and their adaptability to new domains.
This research addresses this gap by investigating the process of knowledge acquisition through the lens of “knowledge circuits.” The authors analyze the evolution of these circuits during continual pre-training, revealing three key findings: 1) New knowledge is integrated more efficiently when relevant to existing knowledge; 2) Circuit evolution displays a distinct shift from formation to optimization; and 3) Knowledge circuit development follows a deep-to-shallow pattern. These findings offer invaluable insights into LLM learning mechanisms and suggest novel strategies for enhancing continual pre-training.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in large language models (LLMs) and mechanistic interpretability. It offers a novel perspective on how LLMs acquire new knowledge, moving beyond isolated components and exploring the dynamic evolution of knowledge circuits. This research opens new avenues for enhancing continual learning strategies and improving model adaptability.
Visual Insights#

🔼 This figure illustrates the key findings of the paper regarding the evolution of knowledge circuits in large language models (LLMs) during continual pre-training. It highlights a phase shift in the circuit evolution, transitioning from a ‘formation phase’ to an ‘optimization phase’. Each phase is characterized by specific traits related to model performance (e.g., Hit@10 accuracy), the topology of the knowledge circuits (e.g., the connectivity and structural organization of the circuit), and their components (e.g., the types and roles of attention heads). The figure visually depicts how these characteristics evolve and change between the two phases. This provides a concise overview of the paper’s central argument about how LLMs acquire and integrate new knowledge.
read the caption
Figure 1: Illustration of our findings: Phase shift from formation to optimization in the evolution of knowledge circuits, each phase characterized by distinct features at the performance, topology, and component levels.
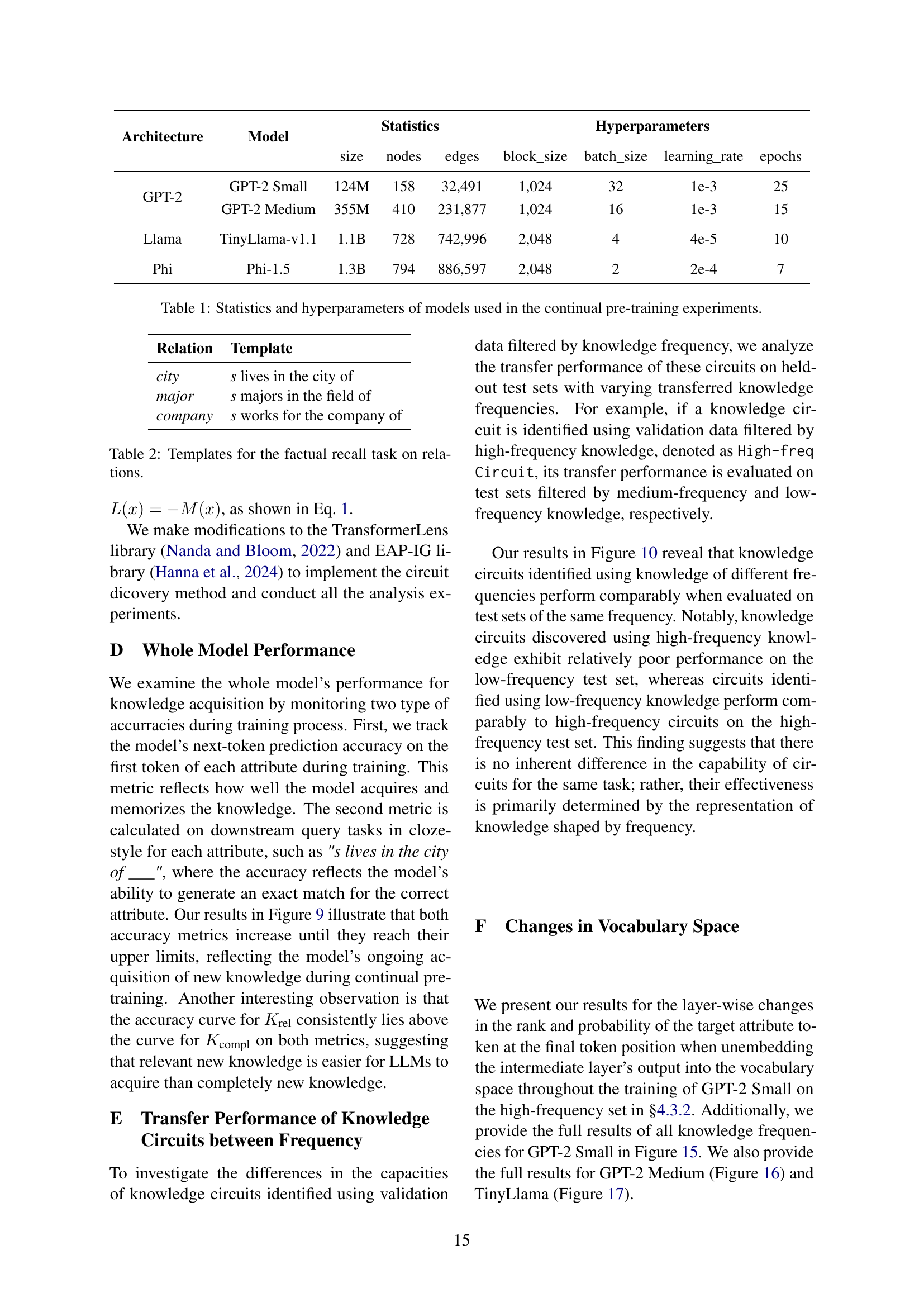
| Architecture | Model | Statistics | Hyperparameters | |||||
|---|---|---|---|---|---|---|---|---|
| size | nodes | edges | block_size | batch_size | learning_rate | epochs | ||
| GPT-2 | GPT-2 Small | 124M | 158 | 32,491 | 1,024 | 32 | 1e-3 | 25 |
| GPT-2 Medium | 355M | 410 | 231,877 | 1,024 | 16 | 1e-3 | 15 | |
| Llama | TinyLlama-v1.1 | 1.1B | 728 | 742,996 | 2,048 | 4 | 4e-5 | 10 |
| Phi | Phi-1.5 | 1.3B | 794 | 886,597 | 2,048 | 2 | 2e-4 | 7 |
🔼 This table presents the architecture, model name, size, number of nodes and edges, block size, batch size, learning rate, and number of training epochs used for four different language models in continual pre-training experiments. These details are crucial for understanding and replicating the experimental setup of the research.
read the caption
Table 1: Statistics and hyperparameters of models used in the continual pre-training experiments.
In-depth insights#
LLM Knowledge Circuits#
LLM Knowledge Circuits represent a novel approach to understanding how large language models (LLMs) acquire and utilize knowledge. Instead of viewing knowledge as isolated components within the model, this framework emphasizes the dynamic interplay and cooperation between different neural components, forming interconnected circuits. These circuits are not static; their structure and function evolve throughout continual pre-training, exhibiting distinct phases of formation and optimization. The evolution of these circuits is influenced by the relevance of new information to existing knowledge, with relevant information integrating more efficiently. This framework provides valuable insights into the mechanisms of LLM learning and suggests potential avenues for improving continual pre-training strategies to enhance model performance and adaptability. It also highlights a deep-to-shallow pattern in circuit evolution, where deeper layers initially develop the knowledge extraction function, and later, shallower layers refine and enrich knowledge representations.
Continual Pre-training#
Continual pre-training in LLMs focuses on the challenge of efficiently integrating new knowledge into existing models. The research highlights the crucial role of knowledge circuits, which are subgraphs of the model’s computation graph representing the dynamic interaction between various components to encode and retrieve knowledge. The process of knowledge acquisition involves a distinct phase shift: a formation phase characterized by circuit creation and then an optimization phase focused on refining these circuits. Relevance of new knowledge to pre-existing knowledge significantly impacts its integration: LLMs more readily absorb related information. The paper proposes that continual pre-training should be carefully designed considering these phases and the relationship between old and new knowledge. This involves understanding that circuit evolution follows a deep-to-shallow pattern, with deeper layers initially developing the knowledge extraction capabilities and later spreading to shallower layers for representation enrichment. This finding has implications for more effective strategies in continual learning and improving model adaptability.
Circuit Evolution Phases#
Analyzing the evolution of knowledge circuits reveals distinct phases. The formation phase is characterized by a rapid increase in circuit complexity, as the model initially integrates new knowledge. This phase shows a deep-to-shallow pattern, with deeper layers developing extraction mechanisms before shallower ones refine representations. A phase shift marks the transition to the optimization phase, where circuit structure stabilizes and performance improves significantly. The optimization phase is marked by increased topological centralization, with key components gaining dominance, and performance enhancement through fine-tuning rather than major structural changes. Understanding these distinct phases allows for the development of more effective continual pre-training strategies, potentially enhancing model adaptability and performance across diverse tasks. Relevance of new knowledge to existing knowledge significantly influences integration efficacy, suggesting potential benefits from curriculum-based learning.
Knowledge Acquisition#
The paper investigates how Large Language Models (LLMs) acquire new knowledge, focusing on the evolution of “knowledge circuits.” Key findings reveal a strong influence of pre-existing knowledge on new knowledge integration; relevant information is processed more efficiently than entirely novel data. The process itself demonstrates a distinct phase shift, moving from an initial “formation” phase where circuits are established, to an “optimization” phase where established structures are refined. Furthermore, circuit evolution follows a deep-to-shallow pattern, with deeper layers initially focusing on information extraction before shallower layers contribute to refined knowledge representation. These insights are valuable for enhancing LLM continual learning strategies, suggesting potential improvements through optimized data curriculums and techniques focusing on reactivating low-frequency knowledge. The study’s focus on circuit dynamics, rather than isolated knowledge blocks, offers a novel and potentially more comprehensive view of knowledge acquisition within LLMs.
Future of LLMs#
The future of LLMs hinges on addressing several key challenges and opportunities. Continual learning is paramount; current LLMs struggle with updating knowledge effectively, and techniques for seamlessly integrating new information are crucial. Mechanistic interpretability will be vital for building trust and understanding how LLMs arrive at their outputs, enabling better control and mitigation of biases. Efficiency improvements are also needed; current models require immense computational resources. Research into more efficient architectures and training methods is essential for widespread accessibility. Moreover, ethical considerations must be paramount. Addressing issues of bias, fairness, and potential misuse is crucial for responsible development and deployment. Finally, exploring the interaction between LLMs and other AI modalities is a significant area of future research, paving the way for more sophisticated and integrated AI systems capable of performing complex tasks and exhibiting more human-like intelligence.
More visual insights#
More on figures

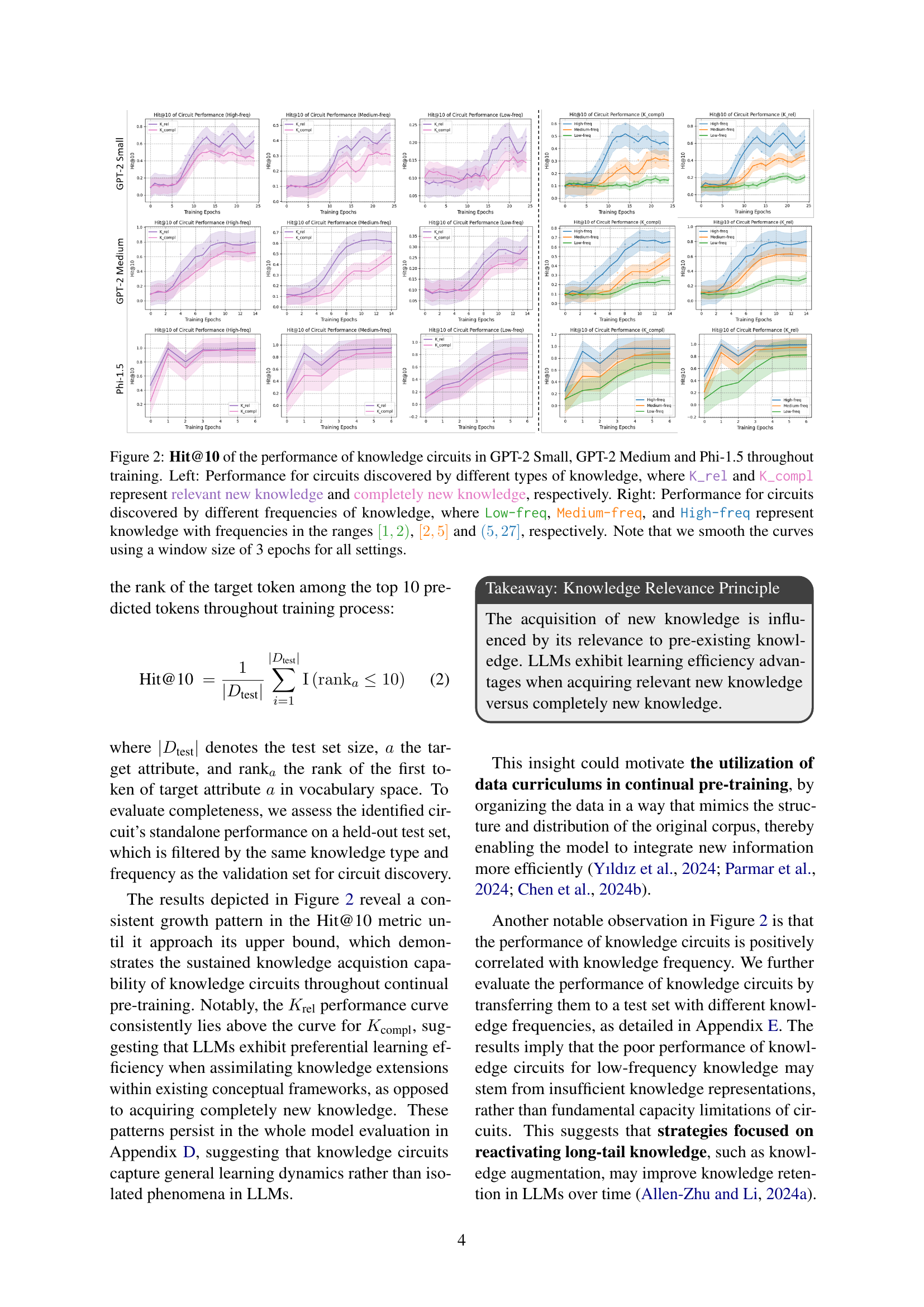
🔼 Figure 2 presents the Hit@10 performance of knowledge circuits across three different language models (GPT-2 Small, GPT-2 Medium, and Phi-1.5) during continual pre-training. The left side shows how the performance of circuits differs depending on whether the knowledge they represent is relevant new knowledge (K_rel; knowledge already known to the model but requiring further refinement), or completely new knowledge (K_compl; entirely novel knowledge not previously present in the model). The right side illustrates how circuit performance varies based on the frequency of the knowledge within the training data: low-frequency (Low-freq; [1,2)), medium-frequency (Medium-freq; [2,5]), and high-frequency (High-freq; (5,27]). The curves are smoothed using a 3-epoch window for improved readability.
read the caption
Figure 2: Hit@10 of the performance of knowledge circuits in GPT-2 Small, GPT-2 Medium and Phi-1.5 throughout training. Left: Performance for circuits discovered by different types of knowledge, where K_rel and K_compl represent relevant new knowledge and completely new knowledge, respectively. Right: Performance for circuits discovered by different frequencies of knowledge, where Low-freq, Medium-freq, and High-freq represent knowledge with frequencies in the ranges [1,2)12[1,2)[ 1 , 2 ), [2,5]25[2,5][ 2 , 5 ] and (5,27]527(5,27]( 5 , 27 ], respectively. Note that we smooth the curves using a window size of 3 epochs for all settings.

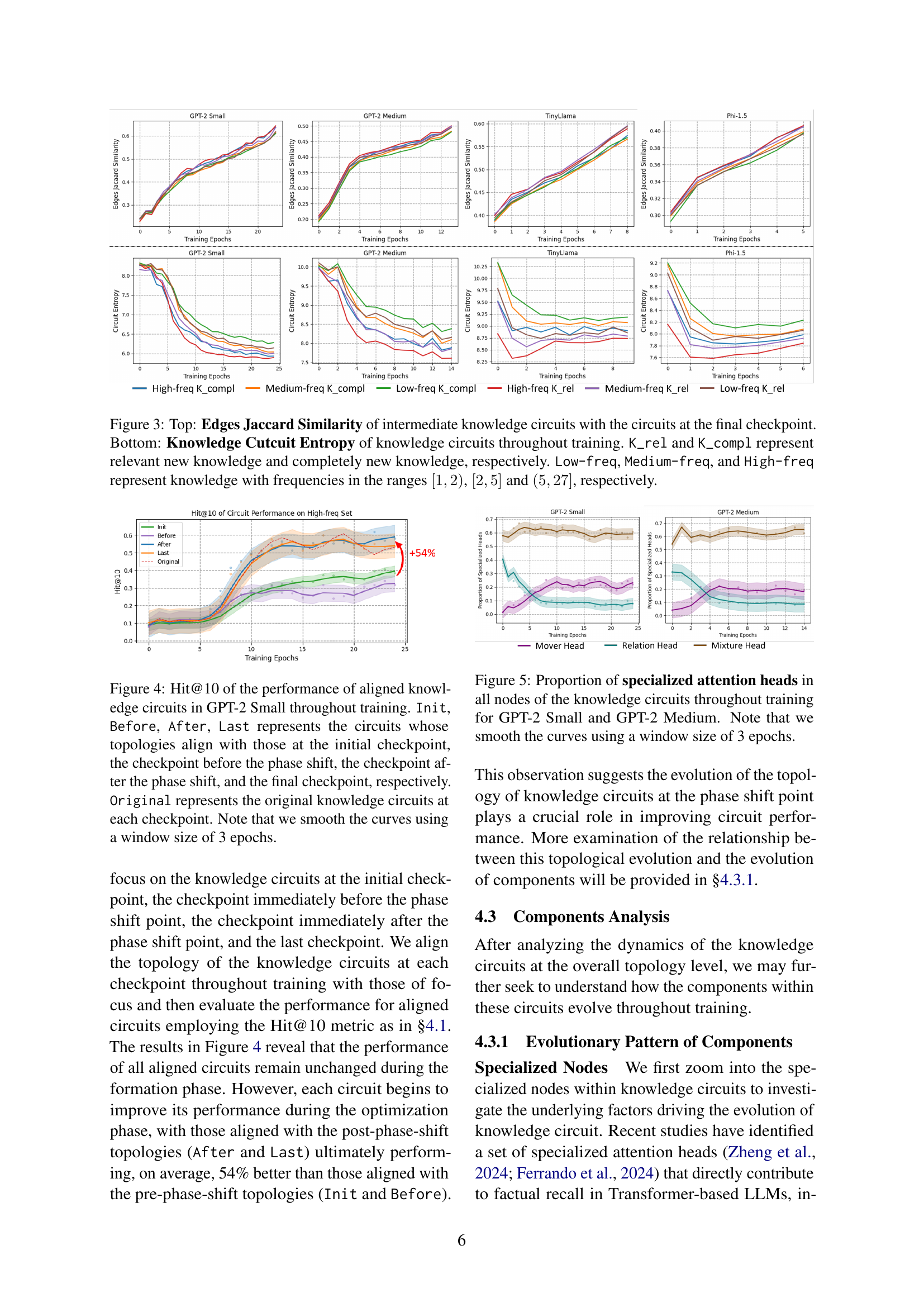
🔼 Figure 3 visualizes the evolution of knowledge circuits during continual pre-training. The top panel displays the Jaccard similarity between edge sets of intermediate knowledge circuits and the final circuit. This metric quantifies the structural consistency of circuits throughout the training process. The bottom panel shows the knowledge circuit entropy, measuring the concentration of edge importance within the circuits. Lower entropy indicates higher centralization, signifying fewer, more critical edges driving the knowledge processing. Different lines represent the evolution of circuits related to different types of knowledge (relevant vs. completely new) and knowledge frequencies (low, medium, high). This allows observation of how different factors influence the structural stabilization and information flow within the circuits over time.
read the caption
Figure 3: Top: Edges Jaccard Similarity of intermediate knowledge circuits with the circuits at the final checkpoint. Bottom: Knowledge Cutcuit Entropy of knowledge circuits throughout training. K_rel and K_compl represent relevant new knowledge and completely new knowledge, respectively. Low-freq, Medium-freq, and High-freq represent knowledge with frequencies in the ranges [1,2)12[1,2)[ 1 , 2 ), [2,5]25[2,5][ 2 , 5 ] and (5,27]527(5,27]( 5 , 27 ], respectively.

🔼 This figure displays the performance (Hit@10) of knowledge circuits in GPT-2 Small throughout continual pre-training. Four sets of aligned circuits are compared against the original circuits. ‘Init’ represents circuits aligned with the initial checkpoint’s topology, ‘Before’ with the topology before the observed phase shift, ‘After’ after the shift, and ‘Last’ at the final checkpoint. The curves are smoothed using a 3-epoch window for better visualization. The comparison shows how circuit performance changes as the model’s knowledge circuits evolve and stabilize.
read the caption
Figure 4: Hit@10 of the performance of aligned knowledge circuits in GPT-2 Small throughout training. Init, Before, After, Last represents the circuits whose topologies align with those at the initial checkpoint, the checkpoint before the phase shift, the checkpoint after the phase shift, and the final checkpoint, respectively. Original represents the original knowledge circuits at each checkpoint. Note that we smooth the curves using a window size of 3 epochs.
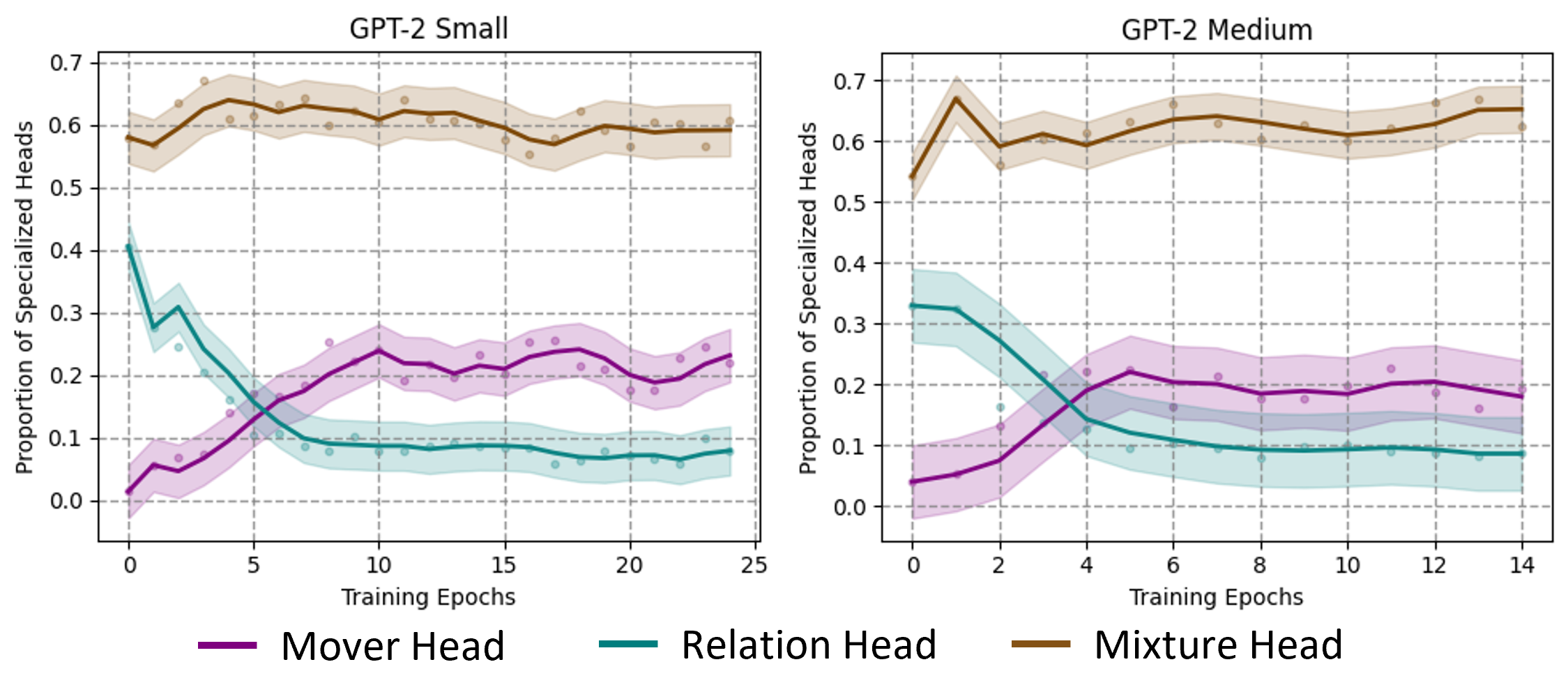
🔼 This figure visualizes the evolution of specialized attention heads within knowledge circuits during the continual pre-training process of GPT-2 Small and GPT-2 Medium language models. The proportion of three types of specialized attention heads – mover heads, relation heads, and mixture heads – are tracked across training epochs for all nodes within the identified knowledge circuits. The curves are smoothed using a 3-epoch window for better visualization of trends. The plot shows the dynamic shift in the prominence of different head types during the training process, offering insights into the mechanisms by which LLMs acquire and process new knowledge.
read the caption
Figure 5: Proportion of specialized attention heads in all nodes of the knowledge circuits throughout training for GPT-2 Small and GPT-2 Medium. Note that we smooth the curves using a window size of 3 epochs.

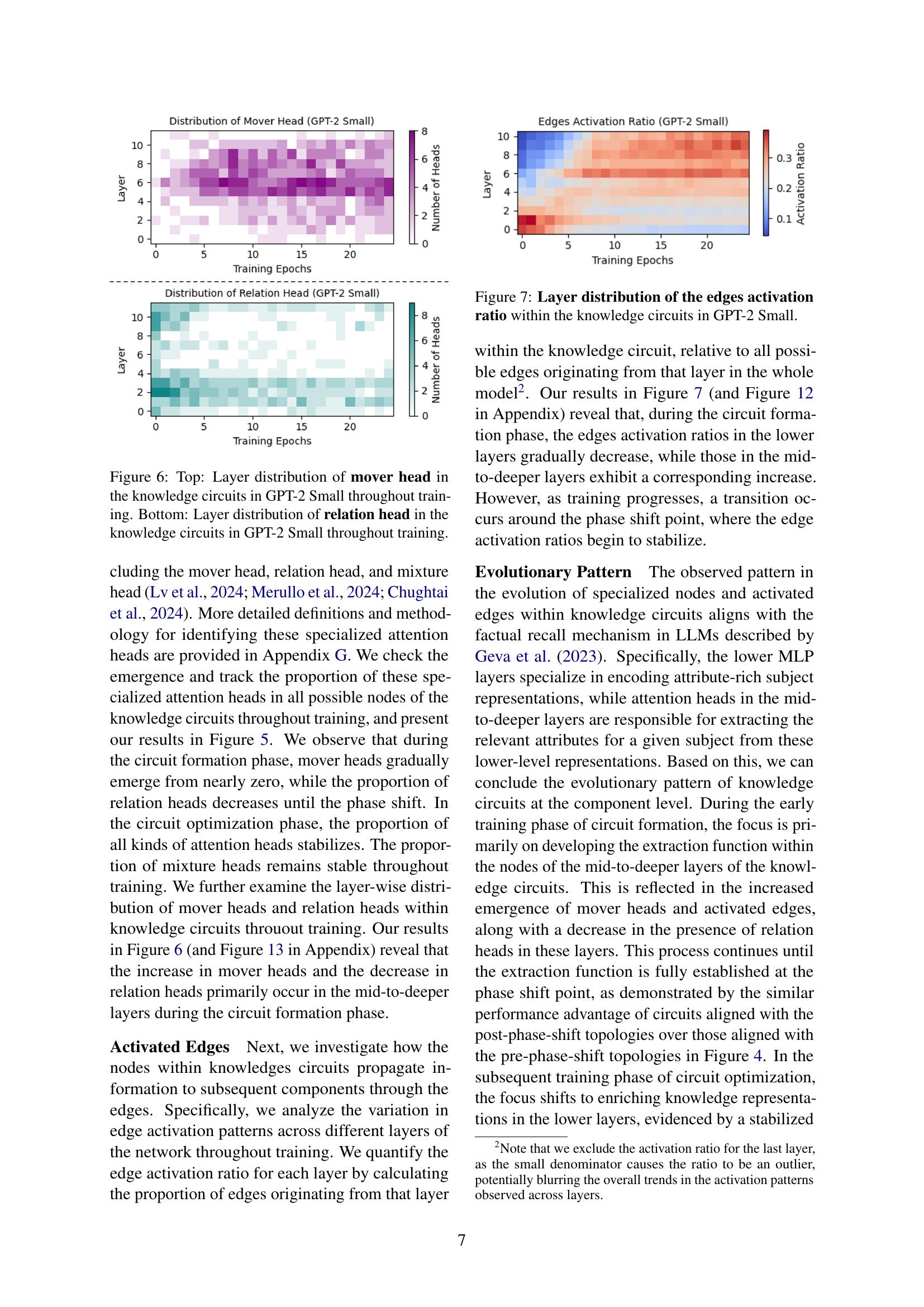
🔼 This figure visualizes the distribution of ‘mover’ and ‘relation’ attention heads across different layers of GPT-2 Small’s neural network during the continual pre-training process. The top panel shows the layer-wise distribution of mover heads, illustrating their prevalence at different layers throughout training. The bottom panel presents the corresponding distribution for relation heads, similarly showing their presence across layers during training. This visualization helps in understanding how these specialized attention heads contribute to knowledge acquisition and processing within the model, and how their distribution changes over time.
read the caption
Figure 6: Top: Layer distribution of mover head in the knowledge circuits in GPT-2 Small throughout training. Bottom: Layer distribution of relation head in the knowledge circuits in GPT-2 Small throughout training.

🔼 This figure shows how the activation of edges within knowledge circuits varies across different layers of the GPT-2 Small model. It visualizes the proportion of activated edges originating from each layer, providing insights into the flow of information through the knowledge circuit. This is useful for understanding the roles of different layers in knowledge processing and how information is integrated within the circuit.
read the caption
Figure 7: Layer distribution of the edges activation ratio within the knowledge circuits in GPT-2 Small.
![]()
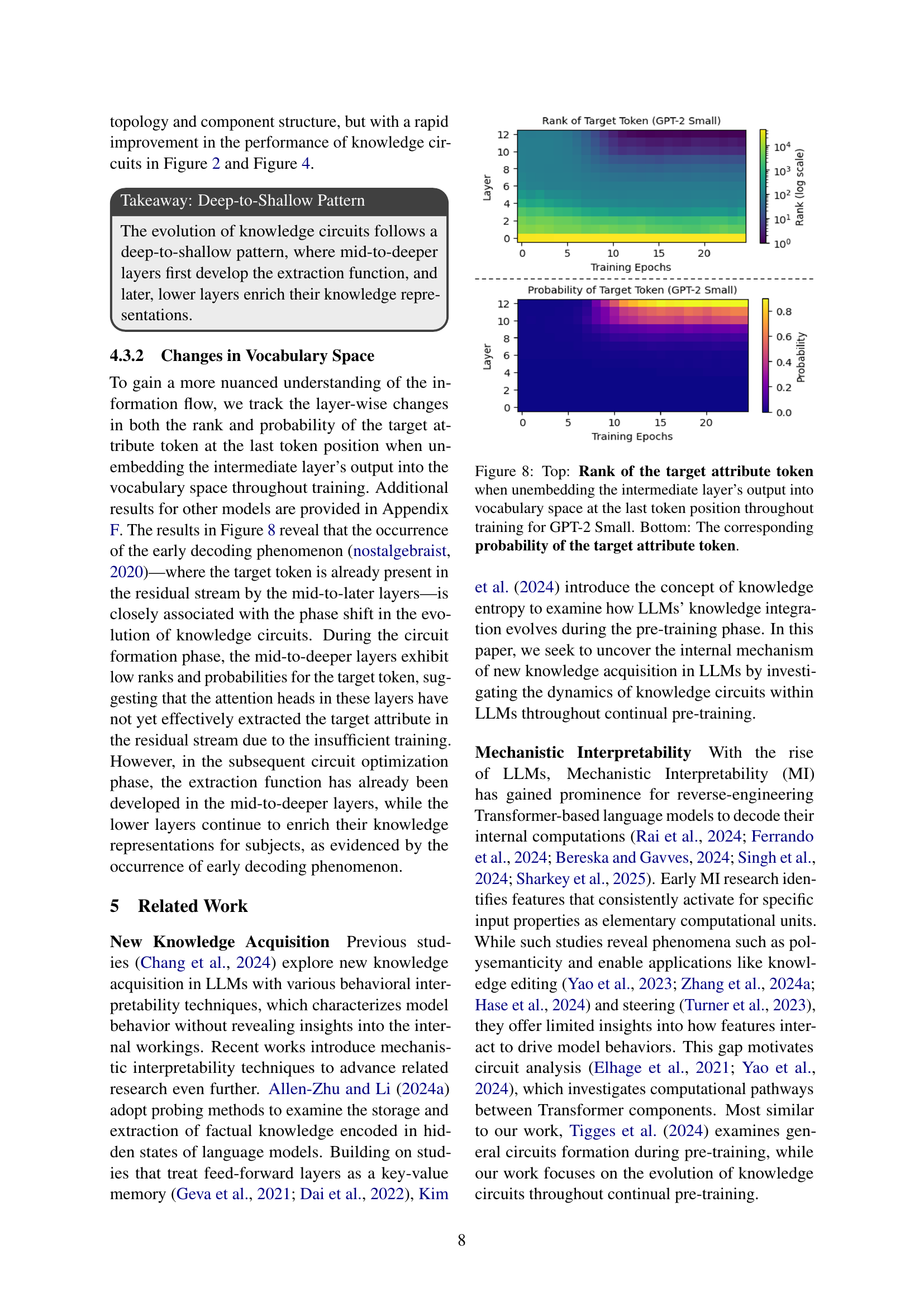
🔼 This figure visualizes the evolution of two key metrics related to the target attribute token during the training process of GPT-2 Small. The ‘Rank’ subplot (top) illustrates the ranking of the target attribute token among all predicted tokens at the last token position, as calculated by unembedding the intermediate layers’ outputs into the vocabulary space. The ‘Probability’ subplot (bottom) displays the probability of the target attribute token being predicted at the same last token position. The plots show these values across different layers and training epochs, offering insights into how the model’s predictions for the target attribute evolve during learning.
read the caption
Figure 8: Top: Rank of the target attribute token when unembedding the intermediate layer’s output into vocabulary space at the last token position throughout training for GPT-2 Small. Bottom: The corresponding probability of the target attribute token.

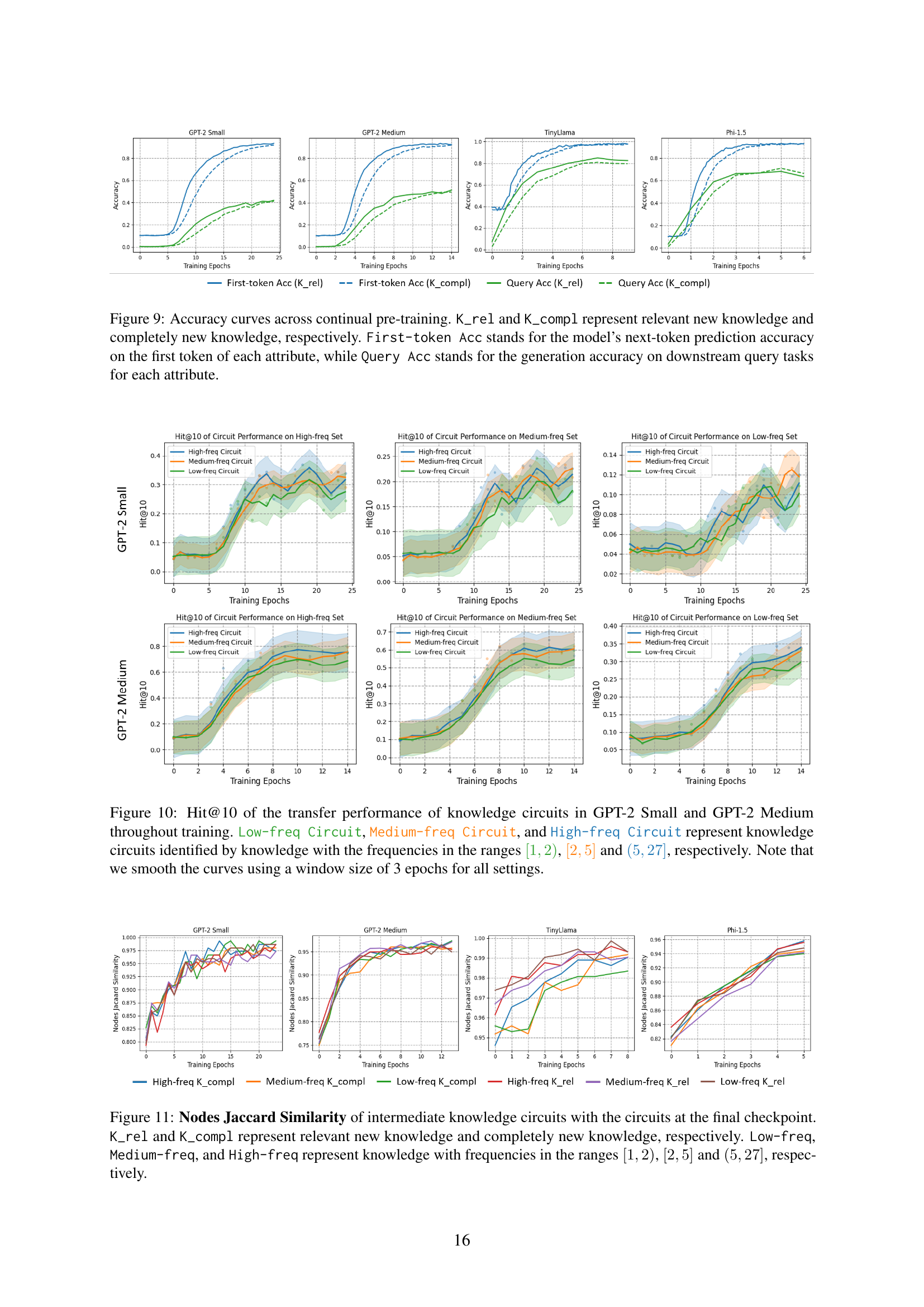
🔼 This figure displays the accuracy of two different metrics across continual pre-training of language models. The models are trained on two types of new knowledge: relevant new knowledge (K_rel), which builds upon existing knowledge, and completely new knowledge (K_compl), which is unrelated to prior knowledge. The ‘First-token Acc’ metric measures the model’s accuracy in predicting the next token, specifically the first token of an attribute in a knowledge triple (subject, relation, attribute). This assesses the immediate acquisition and memorization of the new knowledge. The ‘Query Acc’ metric evaluates the model’s overall accuracy when generating complete answers to downstream queries about these attributes. This shows the model’s ability to use the newly acquired knowledge to answer complex questions. The plots show that, for both metrics, accuracy improves over time during training, and accuracy is generally higher for relevant knowledge (K_rel) than for completely new knowledge (K_compl).
read the caption
Figure 9: Accuracy curves across continual pre-training. K_rel and K_compl represent relevant new knowledge and completely new knowledge, respectively. First-token Acc stands for the model’s next-token prediction accuracy on the first token of each attribute, while Query Acc stands for the generation accuracy on downstream query tasks for each attribute.
![]()
🔼 This figure displays the performance of knowledge circuits (evaluated using Hit@10 metric) when transferred to test sets with different knowledge frequencies. Three types of circuits were used: those identified using low-frequency knowledge (1-2 occurrences), medium-frequency knowledge (2-5 occurrences), and high-frequency knowledge (5-27 occurrences). The results show how well these circuits generalize to data outside of their training frequency range. Curves are smoothed using a 3-epoch window for better visualization.
read the caption
Figure 10: Hit@10 of the transfer performance of knowledge circuits in GPT-2 Small and GPT-2 Medium throughout training. Low-freq Circuit, Medium-freq Circuit, and High-freq Circuit represent knowledge circuits identified by knowledge with the frequencies in the ranges [1,2)12[1,2)[ 1 , 2 ), [2,5]25[2,5][ 2 , 5 ] and (5,27]527(5,27]( 5 , 27 ], respectively. Note that we smooth the curves using a window size of 3 epochs for all settings.

🔼 This figure displays the Jaccard similarity between the edge sets of intermediate knowledge circuits and the final knowledge circuits, across different models (GPT-2 Small, GPT-2 Medium, TinyLlama, and Phi-1.5). The Jaccard similarity, a measure of set similarity, quantifies the overlap in edges between the intermediate circuits at various training checkpoints and the final, fully formed circuits. Separate lines represent different types of newly acquired knowledge (K_rel - relevant new knowledge, K_compl - completely new knowledge) and different frequencies of knowledge entities within the training data (Low-freq, Medium-freq, High-freq). The x-axis represents the training epoch, illustrating the evolution of knowledge circuit structure during the training process. The y-axis shows the Jaccard similarity score, with a higher score indicating greater similarity between the intermediate and final knowledge circuits. The figure illustrates how the structure of the knowledge circuits evolves and stabilizes over time, and how this process might differ based on the type and frequency of new information.
read the caption
Figure 11: Nodes Jaccard Similarity of intermediate knowledge circuits with the circuits at the final checkpoint. K_rel and K_compl represent relevant new knowledge and completely new knowledge, respectively. Low-freq, Medium-freq, and High-freq represent knowledge with frequencies in the ranges [1,2)12[1,2)[ 1 , 2 ), [2,5]25[2,5][ 2 , 5 ] and (5,27]527(5,27]( 5 , 27 ], respectively.

🔼 This heatmap visualizes the distribution of edge activation ratios across different layers within the knowledge circuits of the GPT-2 Medium language model. The x-axis represents training epochs, the y-axis represents layers in the model, and the color intensity of each cell corresponds to the activation ratio. Darker colors indicate higher activation ratios, showing which layers contribute more to the knowledge circuit’s activation during training. The figure provides insights into how the importance of different layers for knowledge processing evolves throughout continual pre-training.
read the caption
Figure 12: Layer distribution of the edges activation ratio within the knowledge circuits in GPT-2 Medium.

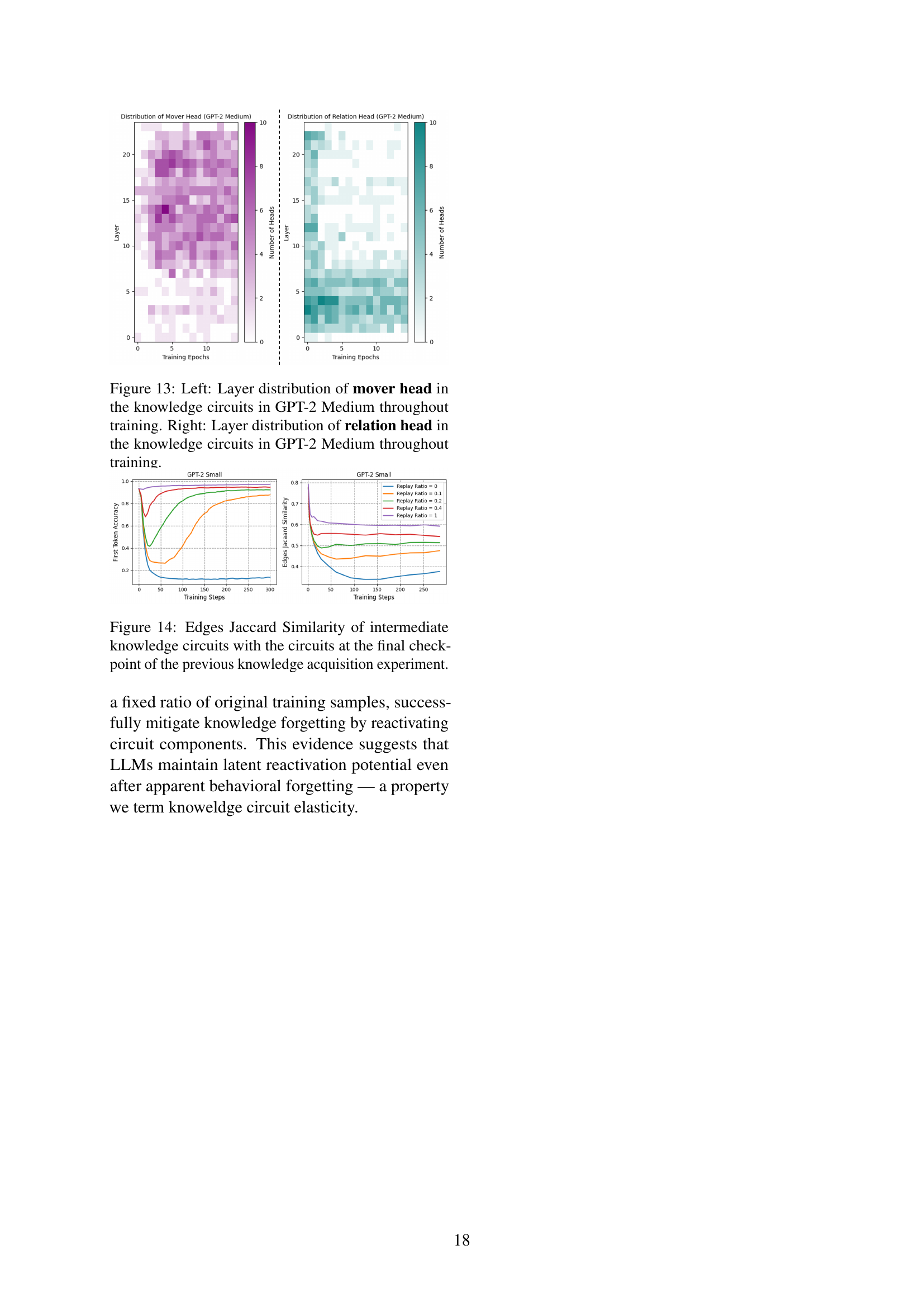
🔼 This figure visualizes the distribution of mover and relation heads within the knowledge circuits of the GPT-2 Medium model across different layers throughout the training process. The left panel shows the distribution of mover heads, while the right panel displays the distribution of relation heads. Each panel shows how the number of heads varies across different layers at various training epochs, offering insight into the evolution of these specialized attention heads during knowledge acquisition.
read the caption
Figure 13: Left: Layer distribution of mover head in the knowledge circuits in GPT-2 Medium throughout training. Right: Layer distribution of relation head in the knowledge circuits in GPT-2 Medium throughout training.

🔼 This figure displays the Jaccard similarity between the edge sets of intermediate knowledge circuits and the final knowledge circuit from a prior knowledge acquisition experiment. The Jaccard Similarity measures the overlap between two sets, in this case, the sets of edges in the knowledge circuits. A higher Jaccard similarity indicates that the structure of the intermediate knowledge circuits is more similar to the final knowledge circuit. The x-axis shows the number of training steps, while the y-axis represents the Jaccard similarity. Different lines represent different replay ratios, showing how often previous training data is reintroduced during continual learning. This visualization helps understand how the topology of the knowledge circuits evolves and stabilizes throughout the continual learning process, and the impact of replaying previous data on that stability.
read the caption
Figure 14: Edges Jaccard Similarity of intermediate knowledge circuits with the circuits at the final checkpoint of the previous knowledge acquisition experiment.
![]()
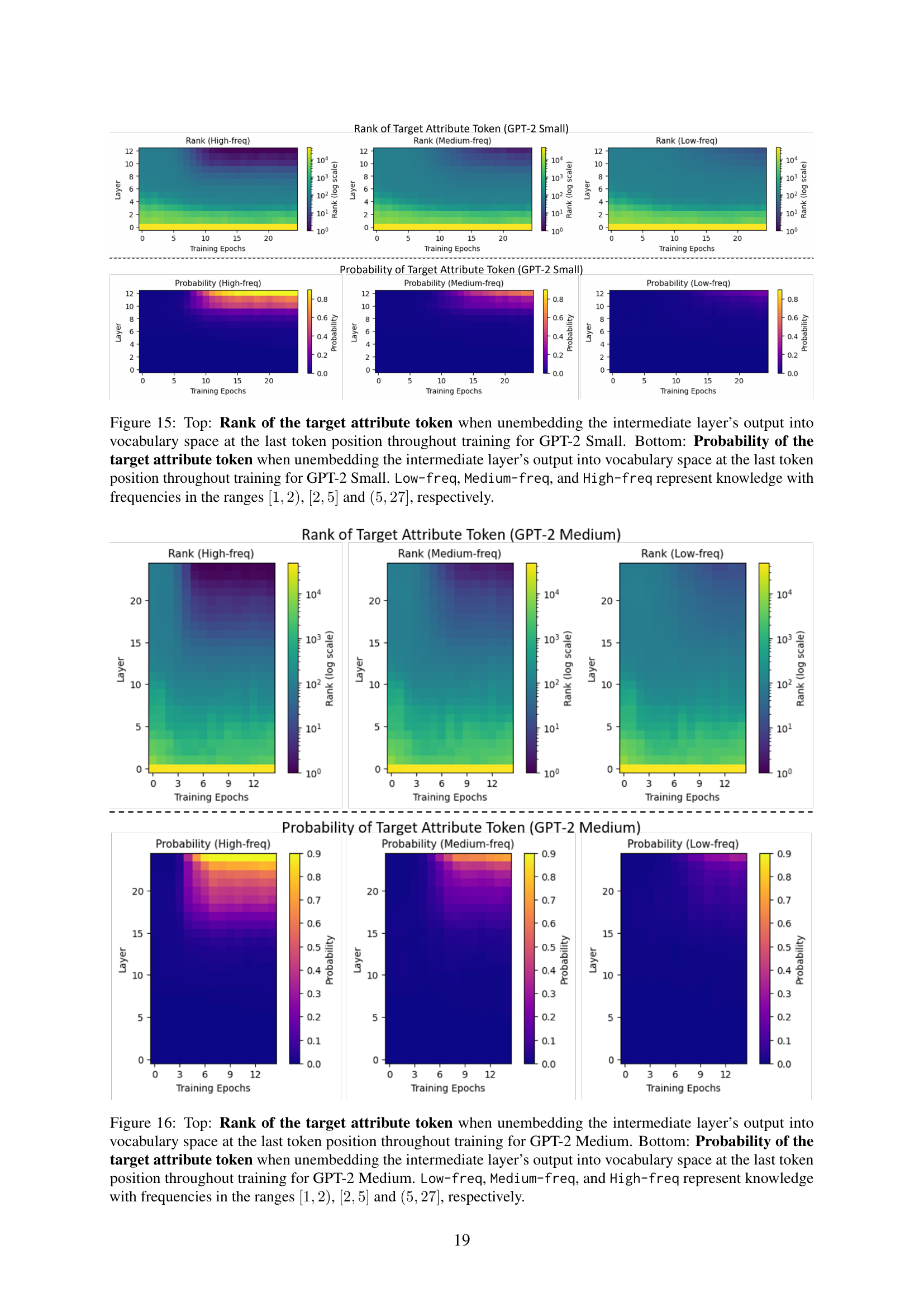
🔼 This figure visualizes the change in the rank and probability of the target attribute token at the final token position during the unembedding process for GPT-2 Small model across different training epochs. The visualizations are separated into top (rank) and bottom (probability) sections, each further divided into three sub-plots based on the frequency of the knowledge: low, medium, and high. The x-axis represents training epochs, and the y-axis represents the layer number, with color intensity reflecting the rank or probability values. The color scale helps to easily identify patterns in rank and probability variations as the model trains across different knowledge frequencies.
read the caption
Figure 15: Top: Rank of the target attribute token when unembedding the intermediate layer’s output into vocabulary space at the last token position throughout training for GPT-2 Small. Bottom: Probability of the target attribute token when unembedding the intermediate layer’s output into vocabulary space at the last token position throughout training for GPT-2 Small. Low-freq, Medium-freq, and High-freq represent knowledge with frequencies in the ranges [1,2)12[1,2)[ 1 , 2 ), [2,5]25[2,5][ 2 , 5 ] and (5,27]527(5,27]( 5 , 27 ], respectively.
![]()
🔼 This figure shows the rank and probability of the target attribute token at different layers of GPT-2 Medium throughout the training process. The top part displays the rank, while the bottom displays the probability. The results are broken down for three different frequencies of knowledge in the training data: low-frequency, medium-frequency, and high-frequency. The analysis helps in understanding how the model accesses and retrieves the knowledge at different stages of learning.
read the caption
Figure 16: Top: Rank of the target attribute token when unembedding the intermediate layer’s output into vocabulary space at the last token position throughout training for GPT-2 Medium. Bottom: Probability of the target attribute token when unembedding the intermediate layer’s output into vocabulary space at the last token position throughout training for GPT-2 Medium. Low-freq, Medium-freq, and High-freq represent knowledge with frequencies in the ranges [1,2)12[1,2)[ 1 , 2 ), [2,5]25[2,5][ 2 , 5 ] and (5,27]527(5,27]( 5 , 27 ], respectively.
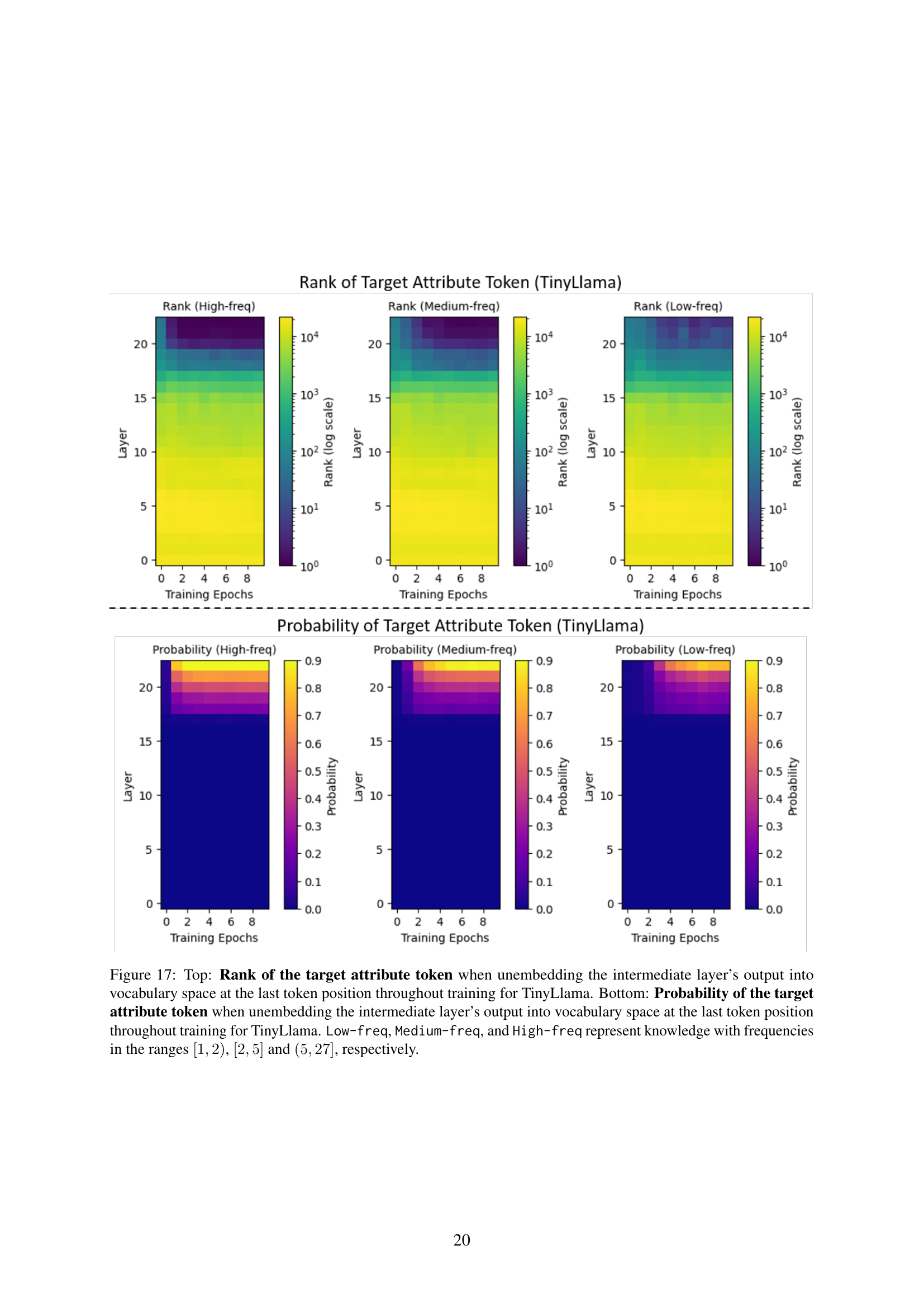
![]()
🔼 This figure displays the evolution of knowledge circuits in TinyLlama during continual pre-training. The top half shows the rank of the target attribute token at the last token position as it is unembedded from the intermediate layers into the vocabulary space at different training epochs. The bottom half shows the probability of that same target token at the same point. Different colors represent different frequencies of knowledge, ranging from low frequency to high frequency. This visualization helps in understanding how the model’s ability to access and utilize knowledge evolves over time and how that’s affected by knowledge frequency.
read the caption
Figure 17: Top: Rank of the target attribute token when unembedding the intermediate layer’s output into vocabulary space at the last token position throughout training for TinyLlama. Bottom: Probability of the target attribute token when unembedding the intermediate layer’s output into vocabulary space at the last token position throughout training for TinyLlama. Low-freq, Medium-freq, and High-freq represent knowledge with frequencies in the ranges [1,2)12[1,2)[ 1 , 2 ), [2,5]25[2,5][ 2 , 5 ] and (5,27]527(5,27]( 5 , 27 ], respectively.
More on tables
| Relation | Template |
|---|---|
| city | s lives in the city of |
| major | s majors in the field of |
| company | s works for the company of |
🔼 This table shows the templates used to create the queries for the factual recall tasks used in the circuit discovery experiments. Each template takes a subject (s) and a relation (r) as input and generates a question about the target attribute (a). For example, to predict the attribute ‘city’ given subject ‘Donald Trump’, the template would generate the sentence, ‘Donald Trump lives in the city of’.
read the caption
Table 2: Templates for the factual recall task on relations.
| Name | Possible Values |
|---|---|
| First Name | Aarav, Abbott, Aberdeen, Abilene, Acey, Adair, Adelia, Adriel, Afton, Aida, Ainsley, Aislinn, Alaric, Albin, Alden, Aleah, Alessandra, Alistair, Allegra, Alphonse, Althea, Amaury, Ambrose, Amelina, Amias, Anatole, Anders, Ansel, Anthea, Antonella, Anwen, Arden, Ariadne, Aric, Arlen, Armand, Armando, Arwen, Asa, Astra, Atticus, Aubrey, Auden, Aurelia, Aurora, Aveline, Aviana, Azariah, Baird, Basil, Bayard, Beauregard, Bellamy, Belvedere, Benedict, Bennett, Berenice, Bertram, Blaine, Blair, Blythe, Boaz, Bodhi, Boniface, Bram, Branwen, Brenna, Briar, Briony, Broderick, Bromley, Bronson, Cadence, Cael, Caelan, Caius, Caledon, Calista, Calliope, Callum, Calyx, Cambria, Camellia, Candela, Caspian, Cassian, Cassiopeia, Castor, Cecily, Celeste, Celestia, Cerelia, Cerys, Chalcedony, Chandra, Charlton, Cicero, Cillian, Clemence, Clementine, Cleo, Clio, Clovis, Colton, Conall, Conrad, Corbin, Cordelia, Cormac, Cosima, Cressida, Crispin, Cybele, Cyril, Dahlia, Damaris, Daphne, Darby, Darcy, Dario, Davina, Deirdre, Delaney, Delphine, Demelza, Desmond, Dexter, Dimitri, Dinah, Dorian, Dulcie, Eamon, Earlene, Eben, Edeline, Edmund, Eldon, Eleri, Elia, Elian, Elias, Elodie, Eloise, Elowen, Ember, Emeline, Emrys, Endellion, Ender, Ephraim, Erasmus, Esme, Eulalia, Evadne, Evander, Everard, Everett, Fable, Fanchon, Farrah, Faye, Felix, Fern, Finlay, Fiora, Fletcher, Florian, Forsythia, Freya, Frida, Gable, Galen, Gareth, Garnet, Garrick, Gelsey, Gemma, Genever, Genevieve, Ginevra, Grady, Griffin, Guinevere, Hadley, Halcyon, Hale, Harlan, Hart, Haven, Hawthorne, Hazel, Heath, Helena, Hesper, Hollis, Honora, Hyacinth, Idris, Ilaria, Ilona, Imara, Indigo, Ingrid, Ione, Iris, Isadora, Isolde, Ivor, Jago, Jareth, Jarvis, Jemima, Jericho, Jocasta, Jolyon, Jorah, Jory, Jovan, Jubilee, Jules, Junia, Juniper, Kael, Kaia, Kalista, Kalliope, Katriel, Keir, Kenna, Kerensa, Keturah, Keziah, Kieran, Kirby, Kismet, Kit, Knox, Kyrie, Lachlan, Lark, Larkin, Laszlo, Leda, Leif, Lennox, Leonie, Leopold, Leta, Linnea, Liora, Livia, Llewellyn, Locke, Lorcan, Lorelei, Lorna, Lucian, Lysandra, Lysander, Mabel, Macey, Maeve, Magnolia, Malachi, Malin, Manon, Marcel, Marcellus, Maren, Marius, Marisol, Maris, Mathis, Matilda, Mavis, Maximilian, Meadow, Merrick, Merritt, Micaiah, Micah, Mira, Mireille, Mireya, Mirren, Morrigan, Muir, Nadia, Nadine, Nairne, Nara, Nash, Navi, Naylor, Neve, Nico, Nina, Noble, Nolan, Nora, Nova, Nyssa, Oberon, Octavia, Odessa, Oisin, Oleander, Olwen, Onyx, Ophelia, Orion, Orla, Orson, Osiris, Osric, Ottilie, Ozias, Paisley, Paloma, Pax, Paz, Penelope, Peregrine, Persephone, Phaedra, Phineas, Phoenix, Pippa, Poppy, Portia, Posy, Primrose, Quill, Quinlan, Rafferty, Rain, Rainer, Raphael, Raven, Reeve, Reinette, Renata, Rhea, Rhiannon, Rhys, Riona, Roderick, Romilly, Rowan, Roxana, Rufus, Sable, Sabine, Saffron, Sage, Salem, Samara, Sancia, Saoirse, Sarai, Saskia, Selah, Seneca, Seraphina, Seren, Severin, Shai, Shiloh, Sibyl, Sidonie, Silas, Simeon, Simone, Sinclair, Sol, Solange, Sorrel, Sparrow, Stellan, Sullivan, Sylvain, Sybil, Sylvana, Tallulah, Tamsin, Tansy, Tarquin, Taryn, Tavish, Tegan, Thaddeus, Thelma, Theodora, Theron, Thorin, Thorne, Thora, Tiernan, Tristan, Tullia, Ursula, Valencia, Valerian, Vanya, Vesper, Vianne, Violetta, Virgil, Waverly, Wendell, Willa, Windsor, Winston, Wisteria, Wren, Wynn, Xanthe, Xavier, Xenia, Xerxes, Yara, Yasmin, Yelena, Ysabel, Yvaine, Zahra, Zara, Zephyr, Zinnia, Ziva, Zora |
| Middle Name | Abel, Abram, Ace, Adele, Ainsley, Alaric, Alcott, Alden, Allegra, Amara, Amethyst, Anders, Ansel, Arden, Arlo, Arrow, Asa, Asher, Aster, Astrid, Atticus, Auden, Aurora, Austen, Axel, Baird, Basil, Bay, Beau, Beck, Blaise, Blake, Blythe, Boden, Bodhi, Boone, Bram, Bran, Briar, Briggs, Brooks, Calla, Calvin, Caspian, Cassian, Cedar, Celeste, Chance, Channing, Cleo, Clove, Clyde, Cohen, Colt, Cove, Crew, Crosby, Cyrus, Dane, Dante, Dashiell, Dawn, Dax, Dean, Delta, Dimitri, Dove, Drake, Dune, Echo, Eden, Edison, Elara, Elian, Ellis, Elowen, Ember, Emrys, Eos, Esme, Evangeline, Ever, Everest, Ewan, Eyre, Fable, Fairfax, Fallon, Faye, Fenton, Fern, Finnian, Fleur, Flynn, Forrest, Fox, Gage, Gale, Garnet, Gideon, Gray, Greer, Halcyon, Hale, Harlow, Haven, Hawk, Hayes, Hollis, Hope, Hugo, Idris, Iker, Indigo, Ines, Iona, Iris, Isla, Iver, Jace, Jade, Jagger, Jem, Jet, Joaquin, Jude, Jules, Kai, Kane, Kash, Keats, Keira, Kellen, Kendrick, Kepler, Kian, Kit, Knox, Lake, Lark, Laurel, Layne, Leif, Lennox, Lester, Levi, Liam, Lila, Linnea, Locke, Lorcan, Lore, Luca, Lucian, Lux, Lyric, Maeve, Magnus, Maia, Malcolm, March, Maren, Marlow, Mason, Maverick, Meadow, Mercer, Merrick, Mica, Milan, Milo, Monroe, Moon, Nash, Nico, Noble, Noor, North, Oak, Oberon, Odette, Oisin, Oleander, Onyx, Opal, Orion, Otis, Otto, Pace, Parker, Pax, Paz, Penn, Perry, Phoenix, Pierce, Pine, Poe, Poet, Poppy, Porter, Prosper, Quill, Quincy, Rain, Reed, Reeve, Remy, Rex, Rhea, Ridge, Riven, Roan, Rogue, Roman, Rook, Rowan, Rune, Sable, Sage, Sailor, Saxon, Scout, Sequoia, Shane, Shiloh, Sierra, Sloane, Sol, Solstice, Soren, Sparrow, Star, Stone, Storm, Story, Sullivan, Sylvan, Talon, Tamsin, Tate, Teague, Teal, Thane, Thatcher, Thorn, Thornton, Tide, Torin, True, Vail, Valor, Veda, Vesper, Vince, Violette, Wade, Waverly, Wells, West, Wilder, Willow, Winter, Wren, Wynn, Xander, Xanthe, Xavier, Yara, York, Yule, Zane, Zara, Zephyr, Zinnia |
| Last Name | Abernathy, Ainsworth, Alberts, Ashcroft, Atwater, Babcock, Bader, Bagley, Bainbridge, Balfour, Barkley, Barlowe, Barnhill, Biddle, Billingsley, Birkett, Blakemore, Bleeker, Bliss, Bonham, Boswell, Braddock, Braithwaite, Briggs, Brockman, Bromley, Broughton, Burkhardt, Cadwallader, Calloway, Carmichael, Carrington, Cavanaugh, Chadwick, Chamberlain, Chilton, Claffey, Claypool, Clifton, Coffey, Colfax, Colquitt, Conway, Copley, Cotswold, Creighton, Crenshaw, Crowder, Culpepper, Cunningham, Dallimore, Darlington, Davenport, Delaney, Devlin, Doolittle, Dover, Driscoll, Dudley, Dunleavy, Eldridge, Elston, Fairfax, Farnsworth, Fitzgerald, Fitzroy, Flanders, Fleetwood, Gainsborough, Gatling, Goddard, Goodwin, Granger, Greenfield, Griffiths, Harcourt, Hargrove, Harkness, Haverford, Hawkins, Hawthorne, Heathcote, Holbrook, Hollingworth, Holloway, Holmes, Holtz, Howland, Ingles, Jardine, Kenworthy, Kingsley, Langford, Latham, Lathrop, Lockhart, Lodge, Loxley, Lyndon, MacAlister, MacGregor, Mansfield, Marston, Mather, Middleton, Millington, Milton, Montague, Montgomery, Montoya, Morgenthal, Mortimer, Nash, Newcomb, Newkirk, Nightingale, Norwood, Oakley, Ormsby, Osborne, Overton, Pemberton, Pennington, Percival, Pickering, Prescott, Prichard, Quimby, Radcliffe, Rafferty, Rainier, Ramsay, Rawlins, Renshaw, Ridley, Rivers, Rockwell, Roosevelt, Rothschild, Rutherford, Sanderson, Sedgwick, Selwyn, Severance, Sheffield, Sheridan, Sherwood, Shields, Sinclair, Slater, Somerset, Standish, Stanton, Stoddard, Stokes, Stratford, Strickland, Sutherland, Sutton, Talmadge, Tanner, Tennyson, Thackeray, Thatcher, Thorne, Thurston, Tilden, Townsend, Trent, Trevelyan, Trumbull, Underhill, Vanderbilt, Vandermeer, Vickers, Wadsworth, Wakefield, Walpole, Waring, Warwick, Weatherford, Webster, Wharton, Whittaker, Wickham, Wiggins, Wilcox, Winslow, Winthrop, Wolcott, Woodruff, Wycliffe, Yardley, Yates, Yeats, Yule, Zeller, Zimmerman |
🔼 This table lists all the possible first names, middle names, and last names used in generating the synthetic biographical data for the experiment. The names are randomly sampled from these lists to create unique identities for the fictional individuals in the dataset.
read the caption
Table 3: All possible values generated for the first name, middle name and last name.
| Relation | Possible Attributes |
|---|---|
| City | "Princeton, NJ", "New York, NY", "Los Angeles, CA", "Chicago, IL", "Houston, TX", "Phoenix, AZ", "Philadelphia, PA", "San Antonio, TX", "San Diego, CA", "Dallas, TX", "San Jose, CA", "Austin, TX", "Jacksonville, FL", "Fort Worth, TX", "Columbus, OH", "San Francisco, CA", "Charlotte, NC", "Indianapolis, IN", "Seattle, WA", "Denver, CO", "Washington, DC", "Boston, MA", "El Paso, TX", "Nashville, TN", "Detroit, MI", "Oklahoma City, OK", "Portland, OR", "Las Vegas, NV", "Memphis, TN", "Louisville, KY", "Baltimore, MD", "Milwaukee, WI", "Albuquerque, NM", "Tucson, AZ", "Fresno, CA", "Mesa, AZ", "Sacramento, CA", "Atlanta, GA", "Kansas City, MO", "Colorado Springs, CO", "Miami, FL", "Raleigh, NC", "Omaha, NE", "Long Beach, CA", "Virginia Beach, VA", "Oakland, CA", "Minneapolis, MN", "Tulsa, OK", "Arlington, TX", "Tampa, FL", "New Orleans, LA", "Wichita, KS", "Cleveland, OH", "Bakersfield, CA", "Aurora, CO", "Anaheim, CA", "Honolulu, HI", "Santa Ana, CA", "Riverside, CA", "Corpus Christi, TX", "Lexington, KY", "Stockton, CA", "Henderson, NV", "Saint Paul, MN", "St. Louis, MO", "Cincinnati, OH", "Pittsburgh, PA", "Greensboro, NC", "Anchorage, AK", "Plano, TX", "Lincoln, NE", "Orlando, FL", "Irvine, CA", "Newark, NJ", "Toledo, OH", "Durham, NC", "Chula Vista, CA", "Fort Wayne, IN", "Jersey City, NJ", "St. Petersburg, FL", "Laredo, TX", "Madison, WI", "Chandler, AZ", "Buffalo, NY", "Lubbock, TX", "Scottsdale, AZ", "Reno, NV", "Glendale, AZ", "Gilbert, AZ", "Winston-Salem, NC", "North Las Vegas, NV", "Norfolk, VA", "Chesapeake, VA", "Garland, TX", "Irving, TX", "Hialeah, FL", "Fremont, CA", "Boise, ID", "Richmond, VA", "Baton Rouge, LA", "Spokane, WA", "Des Moines, IA", "Tacoma, WA", "San Bernardino, CA", "Modesto, CA", "Fontana, CA", "Santa Clarita, CA", "Birmingham, AL", "Oxnard, CA", "Fayetteville, NC", "Moreno Valley, CA", "Rochester, NY", "Glendale, CA", "Huntington Beach, CA", "Salt Lake City, UT", "Grand Rapids, MI", "Amarillo, TX", "Yonkers, NY", "Aurora, IL", "Montgomery, AL", "Akron, OH", "Little Rock, AR", "Huntsville, AL", "Augusta, GA", "Port St. Lucie, FL", "Grand Prairie, TX", "Columbus, GA", "Tallahassee, FL", "Overland Park, KS", "Tempe, AZ", "McKinney, TX", "Mobile, AL", "Cape Coral, FL", "Shreveport, LA", "Frisco, TX", "Knoxville, TN", "Worcester, MA", "Brownsville, TX", "Vancouver, WA", "Fort Lauderdale, FL", "Sioux Falls, SD", "Ontario, CA", "Chattanooga, TN", "Providence, RI", "Newport News, VA", "Rancho Cucamonga, CA", "Santa Rosa, CA", "Peoria, AZ", "Oceanside, CA", "Elk Grove, CA", "Salem, OR", "Pembroke Pines, FL", "Eugene, OR", "Garden Grove, CA", "Cary, NC", "Fort Collins, CO", "Corona, CA", "Springfield, MO", "Jackson, MS", "Alexandria, VA", "Hayward, CA", "Clarksville, TN", "Lancaster, CA", "Lakewood, CO", "Palmdale, CA", "Salinas, CA", "Hollywood, FL", "Pasadena, TX", "Sunnyvale, CA", "Macon, GA", "Pomona, CA", "Escondido, CA", "Killeen, TX", "Naperville, IL", "Joliet, IL", "Bellevue, WA", "Rockford, IL", "Savannah, GA", "Paterson, NJ", "Torrance, CA", "Bridgeport, CT", "McAllen, TX", "Mesquite, TX", "Syracuse, NY", "Midland, TX", "Pasadena, CA", "Murfreesboro, TN", "Miramar, FL", "Dayton, OH", "Fullerton, CA", "Olathe, KS", "Orange, CA", "Thornton, CO", "Roseville, CA", "Denton, TX", "Waco, TX", "Surprise, AZ", "Carrollton, TX", "West Valley City, UT", "Charleston, SC", "Warren, MI", "Hampton, VA", "Gainesville, FL", "Visalia, CA", "Coral Springs, FL", "Columbia, SC", "Cedar Rapids, IA", "Sterling Heights, MI", "New Haven, CT", "Stamford, CT", "Concord, CA", "Kent, WA", "Santa Clara, CA", "Elizabeth, NJ", "Round Rock, TX", "Thousand Oaks, CA", "Lafayette, LA", "Athens, GA", "Topeka, KS", "Simi Valley, CA", "Fargo, ND" |
🔼 This table lists all the possible city attributes used in the synthetic dataset created for the continual pre-training experiments. The goal was to create realistic yet fictional data for evaluating LLMs’ ability to acquire new knowledge. The cities listed represent a diverse range of locations, with various sizes and geographic distributions, to make the dataset more comprehensive and less likely to be biased towards specific regions.
read the caption
Table 4: All possible attributes generated for city relation.
| Relation | Possible Attributes |
|---|---|
| Major | Accounting, Actuarial Science, Advertising, Aerospace Engineering, African American Studies, Agribusiness, Agricultural Engineering, Agriculture, Agronomy, Animal Science, Anthropology, Applied Mathematics, Architecture, Art History, Arts Management, Astronomy, Astrophysics, Athletic Training, Atmospheric Sciences, Biochemistry, Bioengineering, Biological Sciences, Biology, Biomedical Engineering, Biotechnology, Botany, Broadcast Journalism, Business Administration, Business Analytics, Business Economics, Business Information Systems, Chemical Engineering, Chemistry, Civil Engineering, Classics, Cognitive Science, Communication Studies, Communications, Comparative Literature, Computer Engineering, Computer Science, Construction Management, Counseling, Creative Writing, Criminal Justice, Criminology, Culinary Arts, Cybersecurity, Dance, Data Science, Dietetics, Digital Media, Drama, Earth Sciences, Ecology, Economics, Education, Electrical Engineering, Elementary Education, Engineering Physics, Engineering Technology, English, Entrepreneurship, Environmental Engineering, Environmental Science, Environmental Studies, Exercise Science, Fashion Design, Fashion Merchandising, Film Studies, Finance, Fine Arts, Fisheries and Wildlife, Food Science, Forensic Science, Forestry, French, Game Design, Genetics, Geography, Geology, German, Global Studies, Graphic Design, Health Administration, Health Education, Health Informatics, Health Sciences, Healthcare Management, History, Horticulture, Hospitality Management, Human Development, Human Resources Management, Human Services, Industrial Engineering, Information Systems, Information Technology, Interior Design, International Business, International Relations, Journalism, Kinesiology, Labor Studies, Landscape Architecture, Latin American Studies, Law, Legal Studies, Liberal Arts, Linguistics, Management, Management Information Systems, Marine Biology, Marketing, Mass Communications, Materials Science, Mathematics, Mechanical Engineering, Media Studies, Medical Technology, Medicine, Microbiology, Molecular Biology, Music, Music Education, Music Performance, Neuroscience, Nursing, Nutrition, Occupational Therapy, Oceanography, Operations Management, Optometry, Organizational Leadership, Paleontology, Paralegal Studies, Pharmacy, Philosophy, Photography, Physical Education, Physical Therapy, Physics, Physiology, Political Science, Pre-Dental, Pre-Law, Pre-Med, Pre-Pharmacy, Pre-Veterinary, Psychology, Public Administration, Public Health, Public Policy, Public Relations, Quantitative Analysis, Radiologic Technology, Real Estate, Recreation Management, Religious Studies, Renewable Energy, Respiratory Therapy, Risk Management, Robotics, Rural Studies, Sales, Social Work, Sociology, Software Engineering, Spanish, Special Education, Speech Pathology, Sports Management, Statistics, Supply Chain Management, Sustainability, Telecommunications, Theater, Tourism Management, Toxicology, Transportation, Urban Planning, Veterinary Medicine, Victimology, Video Production, Web Development, Wildlife Conservation, Women’s Studies, Zoology |
🔼 This table lists all 178 possible attributes that were generated for the ‘major’ relation in the synthetic dataset used for the continual pre-training experiments. These majors represent a diverse range of academic fields, covering arts, humanities, sciences, engineering, business, and other professional fields. The diversity of majors aims to reflect the broad range of knowledge that may be encountered in real-world scenarios.
read the caption
Table 5: All possible attributes generated for major relation.
| Relation | Possible Attributes |
|---|---|
| Company | Apple, Microsoft, Amazon, Google, Facebook, Berkshire Hathaway, Visa, Johnson & Johnson, Walmart, Procter & Gamble, Nvidia, JPMorgan Chase, Home Depot, Mastercard, UnitedHealth Group, Verizon Communications, Pfizer, Chevron, Intel, Cisco Systems, Merck & Co., Coca-Cola, PepsiCo, Walt Disney, AbbVie, Comcast, Bank of America, ExxonMobil, Thermo Fisher Scientific, McDonald’s, Nike, AT&T, Abbott Laboratories, Wells Fargo, Amgen, Oracle, Costco Wholesale, Salesforce, Medtronic, Bristol-Myers Squibb, Starbucks, IBM, NextEra Energy, Broadcom, Danaher, Qualcomm, General Electric, Honeywell, Citigroup, Lockheed Martin, Union Pacific, Goldman Sachs, Raytheon Technologies, American Express, Boeing, Texas Instruments, Gilead Sciences, S&P Global, Deere & Company, Charles Schwab, Colgate-Palmolive, General Motors, Anthem, Philip Morris International, Caterpillar, Target, Intuitive Surgical, Northrop Grumman, Booking Holdings, ConocoPhillips, CVS Health, Altria Group, Eli Lilly and Company, Micron Technology, Fiserv, BlackRock, American Tower, General Dynamics, Lam Research, Zoetis, Applied Materials, Elevance Health, T-Mobile US, Automatic Data Processing, Marsh & McLennan, Mondelez International, Kroger, Crown Castle, Cigna, Analog Devices, FedEx, CSX, Uber Technologies, Moderna, Truist Financial, Kraft Heinz, HCA Healthcare, Dominion Energy, Cognizant Technology Solutions, Occidental Petroleum, Regeneron Pharmaceuticals, Freeport-McMoRan, eBay, O’Reilly Automotive, Southern Company, Duke Energy, Sherwin-Williams, PayPal, Nucor, Gartner, AutoZone, Cheniere Energy, ServiceNow, Constellation Brands, Discover Financial, U.S. Bancorp, Public Storage, Aflac, Lennar, Johnson Controls, Tyson Foods, Sempra Energy, Southwest Airlines, Las Vegas Sands, McKesson, Baxter International, KLA Corporation, Monster Beverage, Archer Daniels Midland, Eaton, Paccar, Illumina, Intercontinental Exchange, Clorox, Capital One Financial, Estee Lauder, Hess, Becton Dickinson, Parker-Hannifin, Cummins, Ameriprise Financial, Fidelity National Information Services, State Street, Xilinx, Chipotle Mexican Grill, Expeditors International, Roper Technologies, L3Harris Technologies, M&T Bank, Alcoa, Live Nation Entertainment, Marriott International, Norfolk Southern, DISH Network, Akamai Technologies, Fortinet, Ball Corporation, Corning, Nordstrom, CMS Energy, Nasdaq, BorgWarner, Liberty Media, Sealed Air, PulteGroup, General Mills, Ross Stores, Hewlett Packard Enterprise, Host Hotels & Resorts, Hilton Worldwide, Snap-on, Zebra Technologies, Leidos, Lincoln National, Weyerhaeuser, CarMax, Rockwell Automation, Allstate, Entergy, NRG Energy, AutoNation, LyondellBasell, Omnicom Group, HollyFrontier, Western Digital, International Flavors & Fragrances, Eastman Chemical, Xcel Energy, Xylem, Ansys, IPG Photonics, Digital Realty, First Solar, Jacobs Engineering, Cognex, Ingersoll Rand, Fastenal, Allegion, LKQ, AMETEK, WABCO Holdings, Keysight Technologies |
🔼 This table lists all the possible company names used as attributes for the ‘company’ relation in the synthetic dataset. These companies represent a diverse range of industries and sizes, and were chosen to be sufficiently realistic while remaining largely outside the factual knowledge likely present in large language models’ pre-training data. The inclusion of both well-known and less-known companies helps to test the model’s capacity to learn and retain new information across different levels of familiarity.
read the caption
Table 6: All possible attributes generated for company relation.
| Relation | Possible Attributes |
|---|---|
| University | Massachusetts Institute of Technology, Harvard University, Stanford University, California Institute of Technology, University of Chicago, Princeton University, Columbia University, Yale University, University of Pennsylvania, University of California, Berkeley, University of California, Los Angeles, University of Michigan, Ann Arbor, Duke University, Johns Hopkins University, Northwestern University, New York University, University of California, San Diego, University of Southern California, Cornell University, Rice University, University of California, Santa Barbara, University of Washington, University of Texas at Austin, University of Wisconsin-Madison, University of Illinois at Urbana-Champaign, University of North Carolina at Chapel Hill, Washington University in St. Louis, University of Florida, University of Virginia, Carnegie Mellon University, Emory University, Georgetown University, University of California, Irvine, University of Notre Dame, University of Rochester, Boston College, Boston University, Ohio State University, Pennsylvania State University, University of Miami, Purdue University, University of Minnesota, University of Maryland, Michigan State University, University of Colorado Boulder, University of Pittsburgh, University of Arizona, University of Utah, University of California, Davis, University of Massachusetts Amherst, Indiana University Bloomington, University of Connecticut, University of Iowa, University of Missouri, University of Kansas, University of Kentucky, University of Tennessee, University of Alabama, University of Oklahoma, University of Oregon, University of Nebraska-Lincoln, University of South Carolina, University of New Hampshire, University of Vermont, University of Delaware, University of Rhode Island, University of Arkansas, Auburn University, Baylor University, Brigham Young University, Clemson University, Colorado State University, Drexel University, Florida State University, George Washington University, Howard University, Iowa State University, Kansas State University, Louisiana State University, Marquette University, Mississippi State University, North Carolina State University, Northeastern University, Oklahoma State University, Oregon State University, Rutgers University, San Diego State University, Southern Methodist University, Stony Brook University, Syracuse University, Temple University, Texas A&M University, Texas Tech University, Tulane University, University of Alabama at Birmingham, University of Central Florida, University of Cincinnati, University of Dayton, University of Denver, University of Georgia, University of Houston, University of Idaho, University of Louisville, University of Maryland, Baltimore County, University of Memphis, University of Mississippi, University of Nevada, Las Vegas, University of New Mexico, University of North Texas, University of San Francisco, University of South Florida, University of Texas at Dallas, University of Toledo, University of Tulsa, University of Wyoming, Villanova University, Virginia Tech, Wake Forest University, West Virginia University, Wichita State University, Worcester Polytechnic Institute, Xavier University, Yeshiva University, American University, Arizona State University, Arkansas State University, Ball State University, Boise State University, Bowling Green State University, Bradley University, California Polytechnic State University, California State University, Long Beach, Central Michigan University, Chapman University, City University of New York, Claremont McKenna College, Clark University, College of William & Mary, DePaul University, Eastern Michigan University, Fairfield University, Florida Atlantic University, Fordham University, Hofstra University, Illinois Institute of Technology, James Madison University, Loyola Marymount University, Loyola University Chicago, Miami University, Middlebury College, New Jersey Institute of Technology, Northern Arizona University, Northern Illinois University, Pepperdine University, Pomona College, Rensselaer Polytechnic Institute, Rhode Island School of Design, Rollins College, Saint Louis University, San Francisco State University, San Jose State University, Santa Clara University, Seattle University, Seton Hall University, Southern Illinois University, Stevens Institute of Technology, SUNY College of Environmental Science and Forestry, SUNY Polytechnic Institute, Texas Christian University, The New School, Towson University, Trinity College, Trinity University, Tufts University, Union College, University at Albany, University at Buffalo, University of Akron, University of Alabama in Huntsville, University of Alaska Anchorage, University of Alaska Fairbanks, University of Baltimore, University of Bridgeport, University of Central Arkansas, University of Charleston, University of Dayton, University of Detroit Mercy, University of Evansville, University of Hartford, University of La Verne, University of Mary Washington, University of Michigan-Dearborn, University of Michigan-Flint, University of Montana, University of Nebraska Omaha, University of Nevada, Reno, University of North Dakota, University of North Florida, University of Northern Colorado, University of Redlands, University of Richmond, University of Saint Joseph, University of San Diego, University of Scranton, University of Sioux Falls, University of South Alabama, University of Southern Mississippi, University of St. Thomas, University of Tampa, University of the Pacific, University of the Sciences, University of Toledo, University of West Georgia, University of Wisconsin-Eau Claire, University of Wisconsin-Green Bay, University of Wisconsin-La Crosse, University of Wisconsin-Milwaukee, University of Wisconsin-Oshkosh, University of Wisconsin-Platteville, University of Wisconsin-River Falls, University of Wisconsin-Stevens Point, University of Wisconsin-Stout, University of Wisconsin-Superior, University of Wisconsin-Whitewater, Ursinus College, Utah State University, Valparaiso University, Vanderbilt University, Vassar College, Villanova University, Virginia Commonwealth University, Wabash College, Wagner College, Wayne State University, Webster University, Weber State University, Wellesley College, Wentworth Institute of Technology, Wesleyan University, Western Carolina University, Western Kentucky University, Western Michigan University, Western Washington University, Westminster College, Whitman College, Whittier College, Willamette University, Williams College, Wittenberg University, Wofford College, Woodbury University, Wright State University, Xavier University, Yale University, York College of Pennsylvania |
🔼 This table lists all the possible university names that were used as attributes for the ‘university’ relation in the synthetic dataset created for the study. The universities listed represent a diverse range of institutions, including large research universities, smaller liberal arts colleges, and public and private schools.
read the caption
Table 7: All possible attributes generated for university relation.
Full paper#