TL;DR#
Information Extraction (IE) models have lagged behind Large Language Models (LLMs) due to the scarcity of high-quality pre-training data. Traditional IE pre-training requires labor-intensive annotation of data in specific formats, unlike LLMs which can use any token in a sentence for pre-training. This makes scaling up IE pre-training challenging.
This research introduces Cuckoo, a novel approach that addresses these issues. Instead of creating new data, Cuckoo cleverly repurposes the massive amounts of data already used to train LLMs. It does this by adapting the next-token prediction (NTP) paradigm used in LLM training to create a new paradigm called Next Tokens Extraction (NTE). This method allows Cuckoo to learn effectively from LLM data, eliminating the need for additional, expensive data annotation.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel and efficient method for information extraction (IE) pre-training, leveraging the massive datasets used for Large Language Models (LLMs). This addresses a major bottleneck in IE research—the scarcity of high-quality, pre-trained data. The ‘free-rider’ approach offers significant cost and time savings, paving the way for more accessible and advanced IE models. The findings will be especially valuable for researchers seeking to improve their IE models without the huge resource investment associated with traditional methods.
Visual Insights#

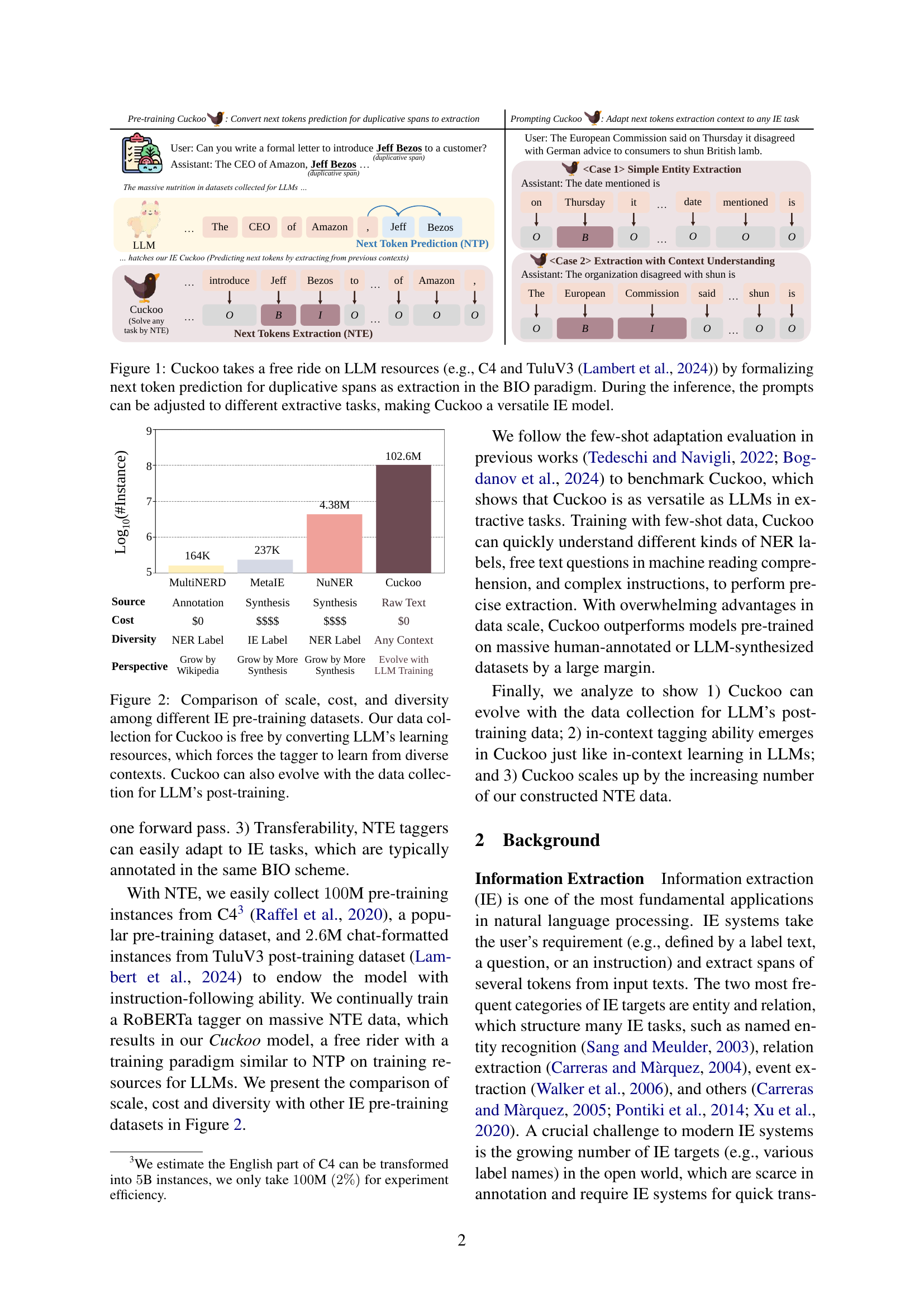
🔼 The figure illustrates how Cuckoo, an information extraction (IE) model, leverages the vast amount of data used to train large language models (LLMs). Instead of requiring separate, painstakingly annotated data for training, Cuckoo re-purposes the next-token prediction (NTP) task of LLMs. Specifically, it identifies duplicate spans of text within the LLM’s training data and frames the prediction of those spans as an extraction task. By assigning BIO tags (Begin, Inside, Outside) to these spans, Cuckoo efficiently creates a large, diverse training dataset. This allows it to adapt to various IE tasks during inference simply by modifying the prompt. This makes Cuckoo a flexible and effective IE model that benefits from ongoing LLM advancements without requiring extra manual annotation.
read the caption
Figure 1: \ourtakes a free ride on LLM resources (e.g., C4 and TuluV3 (Lambert et al., 2024)) by formalizing next token prediction for duplicative spans as extraction in the BIO paradigm. During the inference, the prompts can be adjusted to different extractive tasks, making \oura versatile IE model.
| Level | Example |
|---|---|
| Basic | Organization |
| Query | Which organization launched the campaign? |
| Instruction | Organization (Disambiguation: The organization entity must be a subject of any active action in the context.) |
🔼 This table categorizes information extraction (IE) tasks into three levels of complexity based on the level of understanding required to perform the task. Level 1 (Basic IE) involves simple entity extraction, such as named entity recognition, where the task is clearly defined by a single label. Level 2 (Query-based IE) requires understanding a sentence-level query, such as machine reading comprehension, where the goal is to extract information to answer a question. Level 3 (Instruction-following IE) necessitates understanding complex extraction instructions, similar to instructions given to large language models (LLMs), demanding a deeper level of comprehension.
read the caption
Table 1: IE targets of different understanding levels.
In-depth insights#
LLM-IE Synergy#
LLM-IE synergy explores the powerful combination of Large Language Models (LLMs) and Information Extraction (IE). LLMs provide the contextual understanding and fluency needed to improve IE’s accuracy and efficiency, especially in complex scenarios where traditional rule-based or machine learning methods struggle. Conversely, IE enhances LLMs by providing structured data that improves reasoning and knowledge grounding. This bidirectional improvement creates a potent feedback loop: better IE fuels superior LLM performance, which in turn leads to more effective IE. The key lies in finding innovative ways to leverage LLMs’ strengths for IE tasks, such as utilizing LLMs’ pre-trained knowledge or fine-tuning them for specific IE applications. This synergy also addresses the challenges of data scarcity in IE by enabling the creation of large-scale, high-quality training datasets derived from the massive datasets used for LLM training. The future of LLM-IE synergy involves exploring efficient transfer learning techniques and developing robust evaluation metrics that fully capture the benefits of this combined approach.
NTE Paradigm#
The core of the research paper revolves around the proposed “Next Tokens Extraction” (NTE) paradigm, a novel approach to information extraction (IE). NTE cleverly repurposes the next-token prediction (NTP) mechanism, a cornerstone of large language models (LLMs), for the task of IE. Instead of predicting the next token, NTE identifies tokens already present in the input context and assigns them BIO tags, effectively framing extraction as a modified form of prediction. This approach allows IE models to directly leverage the massive high-quality data used in LLM training, thus bypassing the need for laborious and costly manual annotation of IE-specific datasets. The significant advantage of this methodology is that it facilitates the creation of a large, diverse, and cost-effective training dataset, leading to enhanced IE model performance, particularly in few-shot scenarios. Moreover, NTE enables the IE models to adapt effectively to a range of IE tasks, from basic entity recognition to complex instruction-following tasks, without requiring extensive retraining or prompt engineering. The adaptability is crucial for efficient and versatile IE systems and is a key strength demonstrated by the Cuckoo model developed in the study.
Cuckoo’s Edge#
The heading “Cuckoo’s Edge” aptly captures the paper’s central theme: leveraging the massive datasets of Large Language Models (LLMs) for Information Extraction (IE) tasks. The paper cleverly positions IE models as “free riders,” benefiting from pre-trained LLM resources without the heavy cost of manual annotation. This approach, dubbed “Next Token Extraction” (NTE), transforms the LLM’s next-token prediction task into an extraction problem, achieving significant efficiency gains and data scaling. The name “Cuckoo,” a bird known for its parasitic breeding habits, metaphorically highlights this strategy of resourceful data utilization. The “edge” thus represents the model’s superior performance enabled by this innovative approach. By capitalizing on pre-trained LLM data, Cuckoo demonstrates scalability and adaptability, consistently outperforming traditional IE methods, particularly in few-shot learning scenarios. The paper further establishes that Cuckoo’s performance improves alongside advancements in LLM training, showcasing its ability to evolve with ongoing LLM progress without manual intervention. Therefore, the “Cuckoo’s Edge” speaks to the model’s competitive advantage due to its efficient use of existing resources and its capacity for future growth.
Scalability & Limits#
The scalability and limitations of any Information Extraction (IE) system are crucial. This paper’s approach, using Next Token Extraction (NTE) to leverage Large Language Model (LLM) data, offers significant scalability advantages. By reframing the problem as token extraction from existing LLM training data, the need for expensive, manually annotated IE datasets is largely mitigated. This allows the system to readily benefit from advancements in LLM training, achieving scalability without extensive manual effort. However, limits exist; the reliance on duplicated spans within the LLM data for NTE might lead to biases or missed opportunities for novel extraction patterns. The model’s performance is intrinsically linked to the quality and diversity of the LLM data. Additionally, while the NTE approach enhances efficiency, it might not fully capture the nuances of complex IE tasks that require sophisticated reasoning. Further research could explore diversifying data sources, incorporating specialized label embeddings, and refining the model architecture to fully address potential limitations and further enhance scalability.
Future of IE#
The future of information extraction (IE) is bright, driven by the synergy between large language models (LLMs) and innovative techniques like next token extraction (NTE). While traditional IE methods face limitations in scaling due to annotation costs, NTE leverages the massive datasets used to train LLMs, providing a cost-effective and efficient way to train powerful IE models. Future research could explore enhancing NTE by incorporating label embeddings for improved efficiency and advanced model architectures for greater accuracy and scalability. Combining diverse data sources, both pre-trained and post-trained, will lead to more robust and versatile IE models. The incorporation of in-context learning capabilities, already observed in LLMs, offers significant opportunities to adapt IE models to new tasks with minimal training. Lastly, investigation into different verbalization techniques for instructing the model will enhance performance and adaptability, paving the way for more human-friendly and powerful IE tools.
More visual insights#
More on figures

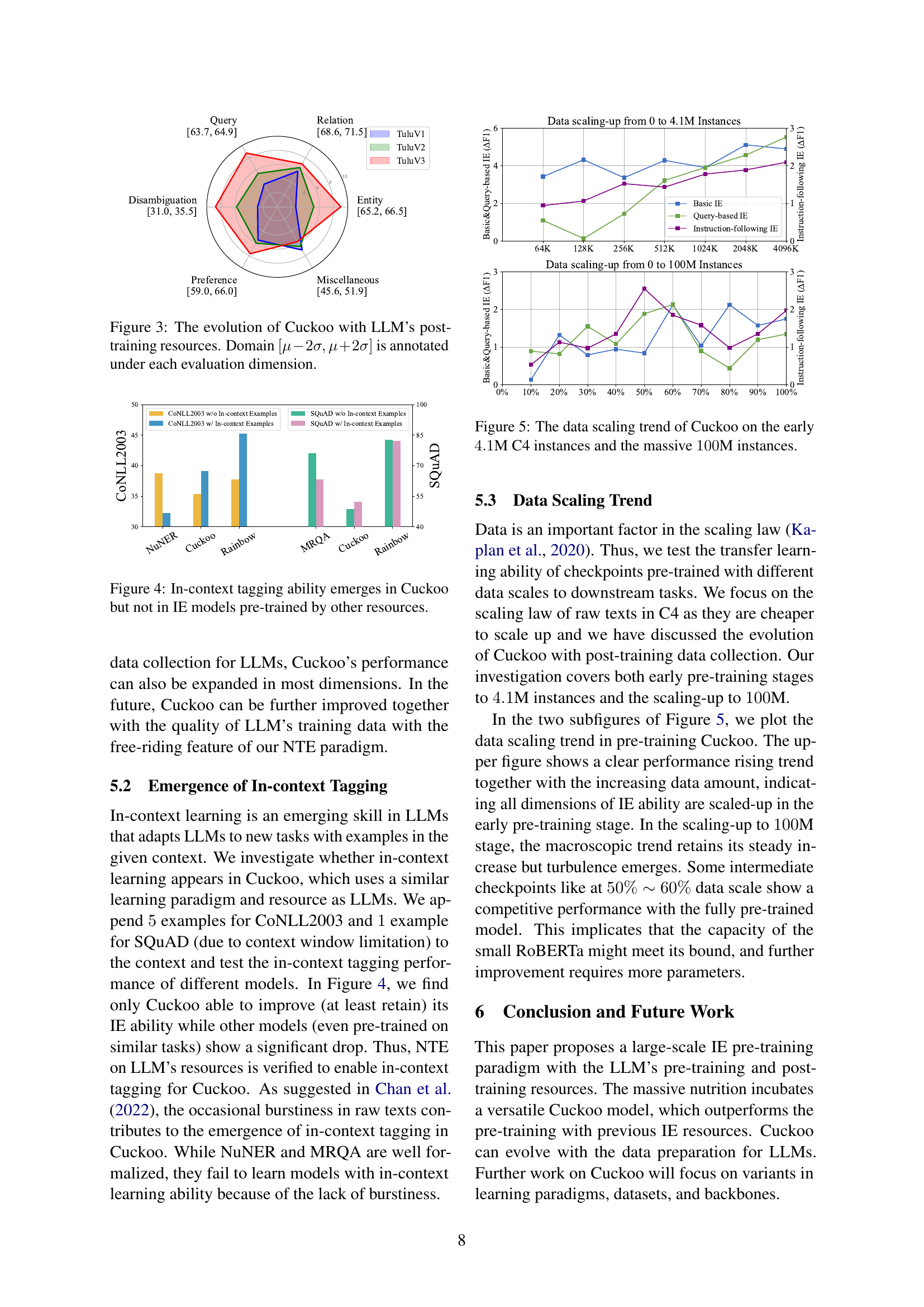
🔼 Figure 2 illustrates a comparison of several information extraction (IE) pre-training datasets across three key aspects: scale (number of instances), cost (financial resources needed for data acquisition), and diversity (variety of contexts and data sources). The figure highlights that the dataset used in the Cuckoo model stands out due to its massive scale (102.6M instances), zero cost (leveraging freely available LLM pre-training and post-training data), and high diversity (the model is trained on data from diverse sources, leading to improved adaptability). Importantly, the Cuckoo dataset’s unique characteristic is its ability to evolve with ongoing advancements in large language model (LLM) data preparation. Unlike traditional methods, the Cuckoo dataset requires no additional manual effort to adapt to improvements in LLM training pipelines.
read the caption
Figure 2: Comparison of scale, cost, and diversity among different IE pre-training datasets. Our data collection for \ouris free by converting LLM’s learning resources, which forces the tagger to learn from diverse contexts. \ourcan also evolve with the data collection for LLM’s post-training.

🔼 This figure illustrates how the performance of the Cuckoo model improves as it is trained on increasingly larger and more diverse datasets from LLMs’ post-training. The x-axis represents different dimensions of evaluation for information extraction (IE) tasks, while the y-axis shows the performance scores. The shaded region for each dimension represents the range from two standard deviations below the mean (μ-2σ) to two standard deviations above the mean (μ+2σ). The figure visually demonstrates Cuckoo’s ability to evolve its performance in various aspects of IE by leveraging improvements in LLM training data, highlighting its ‘free rider’ advantage.
read the caption
Figure 3: The evolution of Cuckoo with LLM’s post-training resources. Domain [μ−2σ,μ+2σ]𝜇2𝜎𝜇2𝜎[\mu-2\sigma,\mu+2\sigma][ italic_μ - 2 italic_σ , italic_μ + 2 italic_σ ] is annotated under each evaluation dimension.

🔼 Figure 4 investigates the in-context learning capabilities of Cuckoo and other IE models. In-context learning refers to a model’s ability to adapt to a new task using only a few examples provided within the input context. The figure compares Cuckoo’s performance on two datasets (CONLL2003 and SQUAD) with and without in-context examples against the performance of other IE models, such as NuNER and MRQA. It demonstrates that Cuckoo exhibits in-context learning ability, improving its performance with the addition of in-context examples. Conversely, other IE models pre-trained using different resources do not show a similar ability. This highlights Cuckoo’s unique capacity to adapt and learn in context, a characteristic often associated with large language models.
read the caption
Figure 4: In-context tagging ability emerges in Cuckoo but not in IE models pre-trained by other resources.
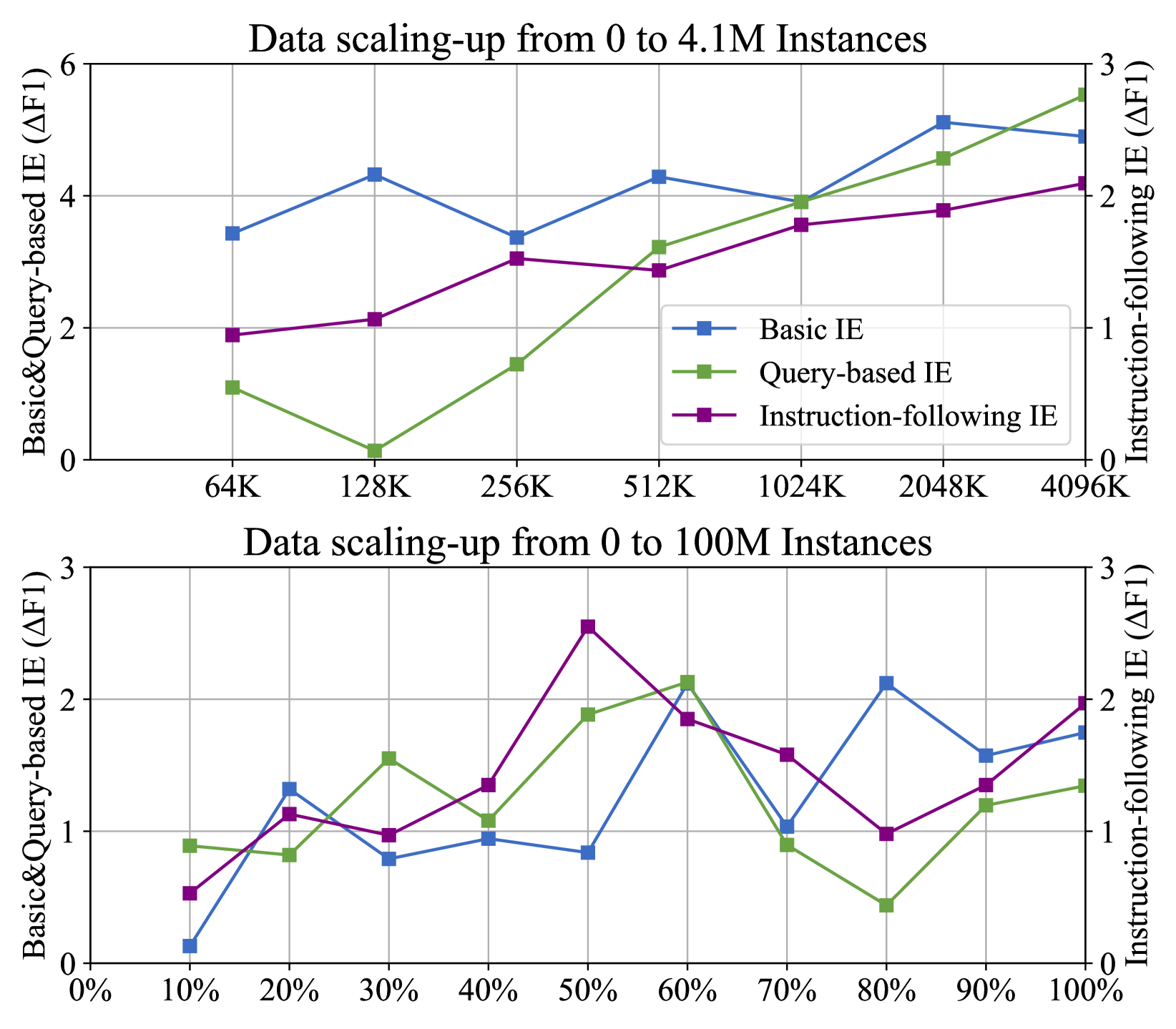
🔼 This figure displays the impact of increasing the size of the training dataset on the performance of the Cuckoo model. Two separate scaling experiments are shown: one starting with 4.1M instances from the C4 dataset, and another scaling up to 100M instances. The plots show how performance on three types of information extraction tasks (Basic IE, Query-based IE, and Instruction-following IE) varies with dataset size, demonstrating the effects of data scaling on Cuckoo’s capabilities.
read the caption
Figure 5: The data scaling trend of \ouron the early 4.14.14.14.1M C4 instances and the massive 100100100100M instances.

🔼 This figure compares the performance of Cuckoo and several LLMs on few-shot information extraction (IE) tasks. It shows that Cuckoo, even without extensive fine-tuning, outperforms both open-source and closed-source LLMs across various IE tasks. The results highlight Cuckoo’s superior efficiency and adaptability in learning from limited examples, demonstrating the effectiveness of its next token extraction (NTE) paradigm.
read the caption
Figure 6: The performance comparison between \ourand LLMs on few-shot IE performance.

🔼 This figure demonstrates how the performance of different pre-trained information extraction (IE) models changes as the amount of adaptive supervision data increases. Adaptive supervision refers to fine-tuning the model on a small set of examples for a specific task. The experiment uses the CoNLL2003 dataset and evaluates performance using the F1 score. The results show that as the number of training examples increases, the performance of all models improves. However, Cuckoo and Rainbow Cuckoo demonstrate significantly better scaling-up performance than NuNER, highlighting the effectiveness of the Cuckoo’s pre-training approach.
read the caption
Figure 7: The scaling-up performance on adaptive supervision from CoNLL2003 of pre-trained IE models.
More on tables
| Method | Named Entity Recognition | Relation Extraction | |||||||
|---|---|---|---|---|---|---|---|---|---|
| CoNLL2003 | BioNLP2004 | MIT-Restaurant | MIT-Movie | Avg. | CoNLL2004 | ADE | Avg. | ||
| zero | \our | ||||||||
| Rainbow \our | |||||||||
| few-shot | OPT-C4-TuluV3 | ||||||||
| RoBERTa | |||||||||
| MRQA | |||||||||
| \our | 66.34 | 70.63 | |||||||
| Only Pre-train | |||||||||
| Only Post-train | |||||||||
| MultiNERD† | |||||||||
| NuNER† | |||||||||
| MetaIE† | |||||||||
| Rainbow \our† | 68.91 | 73.26 | |||||||
🔼 Table 2 presents a comparison of the performance of various models on basic information extraction (IE) tasks. It compares Cuckoo, a novel IE model introduced in the paper, against several existing state-of-the-art IE models and different pre-training approaches. The evaluation focuses on named entity recognition and relationship extraction tasks using established benchmark datasets. The table highlights Cuckoo’s superior performance, particularly in few-shot scenarios, indicating its effectiveness in adapting to diverse IE tasks. It also analyzes variations of the Cuckoo model—specifically, models trained only with pre-training or post-training data—to understand the impact of each stage on its overall performance. The results show that Cuckoo benefits significantly from the massive pre-training data used by LLMs and efficiently leverages both pre-training and post-training data. The ‘In-domain Transfer’ results illustrate Cuckoo’s improved performance when the test data matches the pre-training data format and task, confirming the impact of data-centric training paradigm.
read the caption
Table 2: Performance comparison on Basic IE Tasks. ††{\dagger}†: In-domain Transfer. (Transfer learning on the same task and format as the pre-training stage.)
| Method | SQuAD | SQuAD-V2 | DROP | Avg. | |
|---|---|---|---|---|---|
| zero | \our | ||||
| Rainbow \our | |||||
| few-shot | OPT-C4-TuluV3 | ||||
| RoBERTa | |||||
| MultiNERD | |||||
| NuNER | |||||
| MetaIE | |||||
| \our | 65.26 | ||||
| Only Pre-train | |||||
| Only Post-train | |||||
| MRQA† | |||||
| Rainbow \our† | 73.54 | ||||
🔼 This table presents a performance comparison of different models on query-based information extraction (IE) tasks. The models are evaluated using three well-known datasets: SQUAD, SQUAD-V2, and DROP. The results show the F1 score for each model on each dataset, indicating their ability to accurately answer questions based on provided contexts. The ‘In-domain Transfer’ designation (’†’) signifies the performance of a model trained on data from the same task and format as that of the evaluation, allowing for a comparison of in-domain versus out-of-domain generalization.
read the caption
Table 3: Performance comparison on Query-based IE Tasks. ††{\dagger}†: In-domain Transfer.
| Method | Disamb. | Prefer. | Misc. | |
|---|---|---|---|---|
| Base Task | NER | MRC | NER | |
| zero | \our | |||
| Rainbow \our | ||||
| few-shot | OPT-C4-TuluV3 | |||
| RoBERTa | ||||
| MultiNERD | ||||
| NuNER | ||||
| MetaIE | ||||
| \our | 34.97 | 49.17 | ||
| Only Pre-train | ||||
| Only Post-train | 64.37 | |||
| MRQA | ||||
| Rainbow \our | ||||
🔼 This table presents a comparison of the performance of different models on instruction-following information extraction (IE) tasks. Three types of instruction-following IE tasks are evaluated: disambiguation, preference, and miscellaneous. The table shows the performance of Cuckoo and its variants, as well as other baseline models, on these tasks. The ‘In-domain Transfer’ mark indicates when a model is evaluated on the same task as its pre-training stage. Results highlight Cuckoo’s ability to adapt to various instruction-following IE scenarios, demonstrating its versatility and effectiveness compared to other methods.
read the caption
Table 4: Performance comparison on Instruction-following IE tasks for disambiguation (Disamb.), preference (Prefer.), and miscellaneous (Misc.). ††{\dagger}†: In-domain Transfer.
| Method | Long | Short | AnsSim | DualEM |
|---|---|---|---|---|
| \our | 40.48 | |||
| MRQA | ||||
| Rainbow \our | 67.20 | 63.67 | 18.95 |
🔼 This table presents a detailed analysis of instruction-following capabilities in different information extraction (IE) models. Focusing on the ‘preference’ instruction type as an example, it compares the performance of various models in handling instructions to select either the longest or shortest answers. The analysis delves into the models’ ability to distinguish between and correctly respond to different instruction types, revealing insights into their adaptability and nuanced understanding of instructions.
read the caption
Table 5: Detailed analysis on the instruction-following ability of IE models with preference as an example.
| Target | Template |
|---|---|
| Entity | User: [Context] Question: What is the [Label] mentioned? Assistant: Answer: The [Label] is |
| Relation (Kill) | User: [Context] Question: Who does [Entity] kill? Assistant: Answer: [Entity] kills |
| Relation (Live) | User: [Context] Question: Where does [Entity] live in? Assistant: Answer: [Entity] lives in |
| Relation (Work) | User: [Context] Question: Who does [Entity] work for? Assistant: Answer: [Entity] works for |
| Relation (Located) | User: [Context] Question: Where is [Entity] located in? Assistant: Answer: [Entity] is located in |
| Relation (Based) | User: [Context] Question: Where is [Entity] based in? Assistant: Answer: [Entity] is based in |
| Relation (Adverse) | User: [Context] Question: What is the adverse effect of [Entity]? Assistant: Answer: The adverse effect of [Entity] is |
| Query | User: [Context] Question: [Question] Assistant: Answer: |
| Instruction (Entity) | User: [Context] Question: What is the [Label] mentioned? ([Instruction]) Assistant: Answer: The [Label] is |
| Instruction (Query) | User: [Context] Question: [Question] ([Instruction]) Assistant: Answer: |
🔼 Table 6 presents the various templates used in the paper’s experiments across different information extraction (IE) tasks. These templates guide the interaction between a user and an AI assistant, providing clear instructions for extracting specific information. The templates are categorized to facilitate different IE tasks such as simple entity extraction, extraction with context understanding, and relation extraction. Each template showcases how the user provides context and asks a question, while the assistant’s expected response demonstrates the desired extraction type.
read the caption
Table 6: The templates used in our experiments for different tasks.
| Task | Dataset | Instruction |
| Disamb. | CoNLL2003 | The organization entity must be a subject of any active action in the context. |
| BioBLP2004 | The provided context must contain some descriptive information about the protein. | |
| Restaurant | The rating should describe a food or drink mentioned in the sentence. | |
| Prefer. | SQuAD | Give the longest answer |
| Give the shortest answer | ||
| Give a concise answer | ||
| Misc. | CoNLL2003 | Miscellaneous includes events, nationalities and products but not person, location or organization. |
| Restaurant | Miscellaneous includes amenity, hours and price but not rating, dish, or location. | |
| Movie | Miscellaneous includes actor, soundtrack and quote but not director, opinion, or plot. |
🔼 Table 7 details the specific instructions used for the instruction-following IE experiments. It lists three instruction types (Disambiguation, Preference, Miscellaneous) and the specific instructions used within each type for several datasets (CoNLL2003, BioNLP2004, Restaurant, Movie, SQUAD). The instructions aim to test the model’s ability to follow instructions of varying complexity and specificity for different IE tasks.
read the caption
Table 7: The specific instructions used for instruction-following IE.
| Rephrase | New Template/Label |
|---|---|
| Template | User: [Context] Instruction: Extract [Label] from the text above. Assistant: [Label]: |
| User: List all [Label] entities: [Context] Assistant: Here are [Label] entities: 1. | |
| Label | (CoNLL2003) Person Name |
| (BioBLP2004) DNA Deoxyribonucleic acid | |
| (Restaurant) Rating Recommendation | |
| (Movie) Genre Category |
🔼 This table presents variations of the templates and labels used to test the robustness of the Cuckoo model. It shows different ways of phrasing instructions or naming entities, to evaluate how well the model handles variations in wording, ensuring its adaptability and reliability across different forms of expression.
read the caption
Table 8: The template/label variants used for robustness testing.
Full paper#