TL;DR#
Many applications using Large Language Models (LLMs) rely on effective system messages to guide the model’s behavior, but publicly available datasets are often limited. This paper introduces SYSGEN, a novel pipeline designed to generate system messages tailored to user preferences. The lack of publicly available and properly aligned data is a significant challenge in the LLM field; SYSGEN aims to address this by leveraging open-source models to create high-quality system messages automatically.
SYSGEN’s pipeline involves four phases: generating system messages based on key functionalities, filtering and reorganizing them, verifying these functionalities, and generating new, well-aligned assistant responses. Experiments across various open-source models demonstrate substantial performance improvements on the Multifacet benchmark, showcasing better alignment between model responses and system messages, without sacrificing performance on other unseen benchmarks. The key contribution is the generation of diverse system messages that enhance model adaptability across diverse user requirements.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs). It addresses the critical challenge of generating effective system messages, which significantly impact LLM performance and alignment. The proposed method, SYSGEN, offers a data-efficient solution by automatically generating diverse and well-aligned system messages using open-source models, thereby overcoming limitations of existing datasets. This contribution is highly relevant to current research trends in improving LLM adaptability, safety, and ethical considerations, opening new avenues for data augmentation and fine-tuning techniques.
Visual Insights#
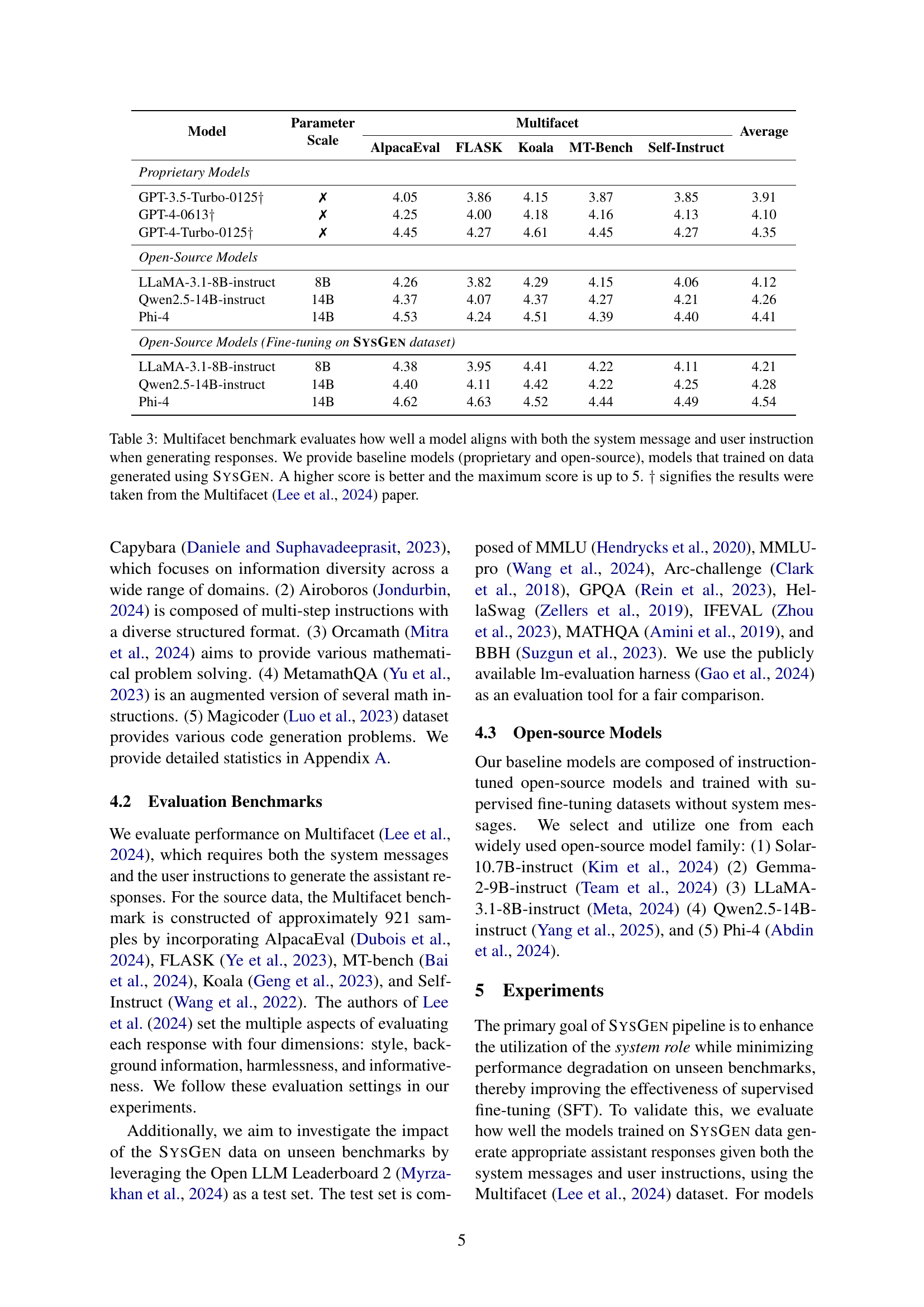
🔼 The SYSGEN pipeline consists of two stages: First, it automatically generates system messages by identifying eight key functionalities (role, content, task, action, style, background, tool, format) within existing supervised fine-tuning (SFT) datasets that lack system messages. These functionalities are tagged with specific phrases. Second, the pipeline leverages these newly generated system messages to produce better aligned assistant responses that are more consistent with user instructions.
read the caption
Figure 1: Our SysGen pipeline provides two main points: system message generation and newly-generated answer. We manually select eight key fuctionalities of system messages and generate phrases with specific tags to original SFT datasets that lack of system messages. Our pipeline generates better aligned assistant responses with system messages given user-oriented instruction.
| Models | Words Composition | BERTScore | BLEURT | GLEU | Len. | ||
| R1 | R2 | RL | |||||
| LLaMA-3.1-8B-instruct | 33.3 | 15.6 | 23.1 | 81.3 | 33.6 | 28.2 | 1.35 |
| Qwen2.5-14b-instruct | 44.9 | 23.2 | 30.7 | 85.9 | 39.9 | 39.2 | 1.55 |
| Phi-4 | 51.9 | 32.3 | 41.1 | 86.1 | 40.1 | 37.2 | 1.89 |
🔼 This table presents a quantitative comparison of the newly generated answers against the original answers, evaluating various aspects of quality. Specifically, it assesses word overlap using ROUGE scores (ROUGE-1, ROUGE-2, ROUGE-L), semantic similarity using BERTScore and BLEURT scores, fluency using GLEU score, and the average length of both the original and generated answers. The comparison allows for a detailed analysis of the impact of the system message generation on the quality and characteristics of the model’s responses.
read the caption
Table 1: A statistic that measures the words composition (Rouge-1,-2, and -L), semantic similarity (BERTScore and BLEURT), fluency (GLEU), and average context length of the newly-generated answer compared to average context length of the original answer.
In-depth insights#
SYSGEN Pipeline#
The SYSGEN pipeline is a novel approach to generating high-quality system messages for large language models (LLMs). Its core innovation lies in automatically generating diverse system messages tailored to user instructions, addressing the limitations of existing datasets which often lack system messages or are subject to strict licensing. The pipeline consists of four phases: (1) generating system messages using open-source models based on eight key functionalities; (2) filtering and reorganizing those messages for consistency; (3) verifying the accuracy of generated functionalities using a LLM-as-a-judge method; (4) generating refined assistant responses aligned with the improved system messages. This data augmentation process leads to substantial improvements in LLM performance, especially in aligning model responses with user instructions, without negatively affecting performance on unseen benchmarks. SYSGEN’s strength lies in its ability to overcome data limitations, creating training datasets that enable better adaptability and alignment in open-source LLMs.
Model Alignment#
Model alignment, in the context of large language models (LLMs), is a critical area focusing on ensuring that a model’s behavior aligns with the user’s intent and societal values. Misalignment can lead to outputs that are nonsensical, biased, toxic, or otherwise harmful. Effective alignment strategies are crucial for building trustworthy and beneficial AI systems. The paper likely explores various techniques for achieving better model alignment, such as reinforcement learning from human feedback (RLHF), adversarial training, or data augmentation to improve the quality of training data. Benchmarking plays a significant role in evaluating alignment success, measuring how well a model follows instructions and avoids generating unsafe or undesirable content. The research probably investigates the challenges of achieving robust alignment across various domains and user preferences, as well as the trade-offs between alignment and other model capabilities like fluency and efficiency. The ultimate goal is to develop methods that promote alignment while maintaining the utility and functionality of LLMs.
Benchmark Results#
A dedicated ‘Benchmark Results’ section in a research paper is crucial for establishing the validity and effectiveness of the proposed method. Comprehensive benchmarking should involve multiple established datasets, covering diverse aspects of the problem domain. The selection of benchmarks should be justified, highlighting their relevance and representativeness. Quantitative results, presented clearly through tables and graphs, are essential. Metrics used for evaluation need to be carefully chosen and their appropriateness explained. Statistical significance testing should be conducted to ensure the observed improvements are not due to random chance. Furthermore, the discussion should go beyond simply reporting numbers; it should analyze the results in depth, comparing performance across different benchmarks and relating the findings to the paper’s hypotheses. Limitations of the benchmarks should be acknowledged, along with potential biases. Finally, a comparison with state-of-the-art methods is crucial to position the proposed approach within the existing literature. A strong ‘Benchmark Results’ section convincingly demonstrates the practical value and potential impact of the research.
SYSGEN Limitations#
The SYSGEN pipeline, while innovative, presents several limitations. Its reliance on single-turn conversations restricts its applicability to more complex, multi-turn interactions, a crucial aspect of real-world LLM deployments. The reliance on readily available datasets, while convenient, limits the diversity of system message functionalities explored, particularly noticeable in the underrepresentation of tools and background information. Furthermore, while the pipeline aims to mitigate performance degradation on unseen benchmarks, it doesn’t fully address potential bias introduced by the training data or the open-source models themselves. The need for future research is highlighted by the under-exploration of system message generation in various formats, such as multiple-choice questions, which are prevalent in evaluation benchmarks. Finally, the limited evaluation data, using only a subset of generated datasets for qualitative analysis, suggests the need for a more robust and comprehensive validation process to confidently assess the generalizability of SYSGEN’s output.
Future Directions#
Future research should prioritize expanding SYSGEN’s capabilities to handle multi-turn conversations, a crucial aspect of real-world interactions currently unsupported. Addressing this limitation would significantly enhance the system’s practical applicability. Further investigation into the impact of different data formats on SYSGEN’s performance is warranted, as the current evaluation may be skewed by the specific characteristics of the chosen datasets. Exploring alternative methods of generating system messages, potentially employing different open-source LLMs or incorporating human-in-the-loop strategies, could reveal additional improvements. A thorough comparative analysis against proprietary models will provide valuable insights into the relative strengths and weaknesses of the SYSGEN approach. Lastly, investigating the generalizability of SYSGEN across diverse languages and domains is crucial for establishing its broader relevance and impact. This multi-faceted approach would pave the way for a more robust and versatile system.
More visual insights#
More on figures

🔼 The SYSGEN pipeline consists of four phases. Phase 1 gathers SFT datasets lacking system messages and uses open-source LLMs to generate system messages with eight key functionality tags. Phase 2 filters out incorrectly generated tags and reorganizes them for consistency. Phase 3 employs an LLM-as-a-judge approach with self-model feedback to remove empty, overly specific, or unnatural phrases. Finally, Phase 4 removes tags to create natural system messages and generates new, aligned assistant responses along with user instructions.
read the caption
Figure 2: Overall SysGen data construction pipeline. Our pipeline consists of four phases: (Phase 1) We gather SFT datasets which do not contain system messages and use open-source models to generate system messages with manually selected eight key fuctionality tags. (Phase 2) We then remove incorrectly generated tag tokens and reorganize tags with phrases in a predefined order for consistency. (Phase 3) We use a LLM-as-a-judge approach with self-model feedback to filter out empty, overly specific, and unnatural phrases. (Phase 4) We finally remove tags to create natural system messages and generate new responses along with the user instructions.

🔼 This figure displays the results of a comparative analysis using GPT-4 to determine which response, the original or the newly generated one, is more appropriate for a given user query. The y-axis represents the percentage, indicating the likelihood of GPT-4 selecting the newly generated response as superior. Ideally, this percentage should be above 50%, suggesting that the newly generated responses are indeed better aligned with user intent. The chart presents the comparative results across various datasets, offering a visual representation of the model’s effectiveness in generating more appropriate responses.
read the caption
Figure 3: A statistic that verifies whether the newly-generated answer is more suitable for the user query than the original answer. It records the probability that GPT-4o would respond with the newly-generated answer being better than the original answer (the probability should ideally exceed 50%).

🔼 This figure displays the results of an evaluation performed using GPT-4, a large language model, to assess the alignment between newly generated system messages and their corresponding assistant responses. The evaluation involved 20 samples from each of several data sources, resulting in a total of 100 samples per model. The results visually represent the degree of alignment, likely showing the percentage of responses deemed aligned or not aligned with their corresponding system messages.
read the caption
Figure 4: The GPT4o LLM-as-a-judge results of measuring the alignment between generated system messages and new assistant responses. We use 20 samples for each data source which sums up to 100 samples in total per models.
More on tables
| Models |
| ||
| LLaMA-3.1-8B-instruct | 806,796 → 602,750 (74.7%) → 586,831 (72.7%) | ||
| Qwen2.5-14b-instruct | 806,796 → 806,602 (99.9%) → 775,830 (96.2%) | ||
| Phi-4 | 806,796 → 774,613 (96.0%) → 773,878 (95.9%) |
🔼 This table presents the number of data instances remaining after each processing stage of the SYSGEN pipeline and the corresponding percentage for various open-source language models. The stages include initial data gathering, filtering, and the generation of new assistant responses. It shows how the data size changes throughout the SYSGEN data augmentation process and provides a measure of data retention for each model.
read the caption
Table 2: We provide remaining instances and percentage after adopting SysGen data per open-source models.
| # of instances |
| (Original → P2 Filtering → P4 Answer Generation) |
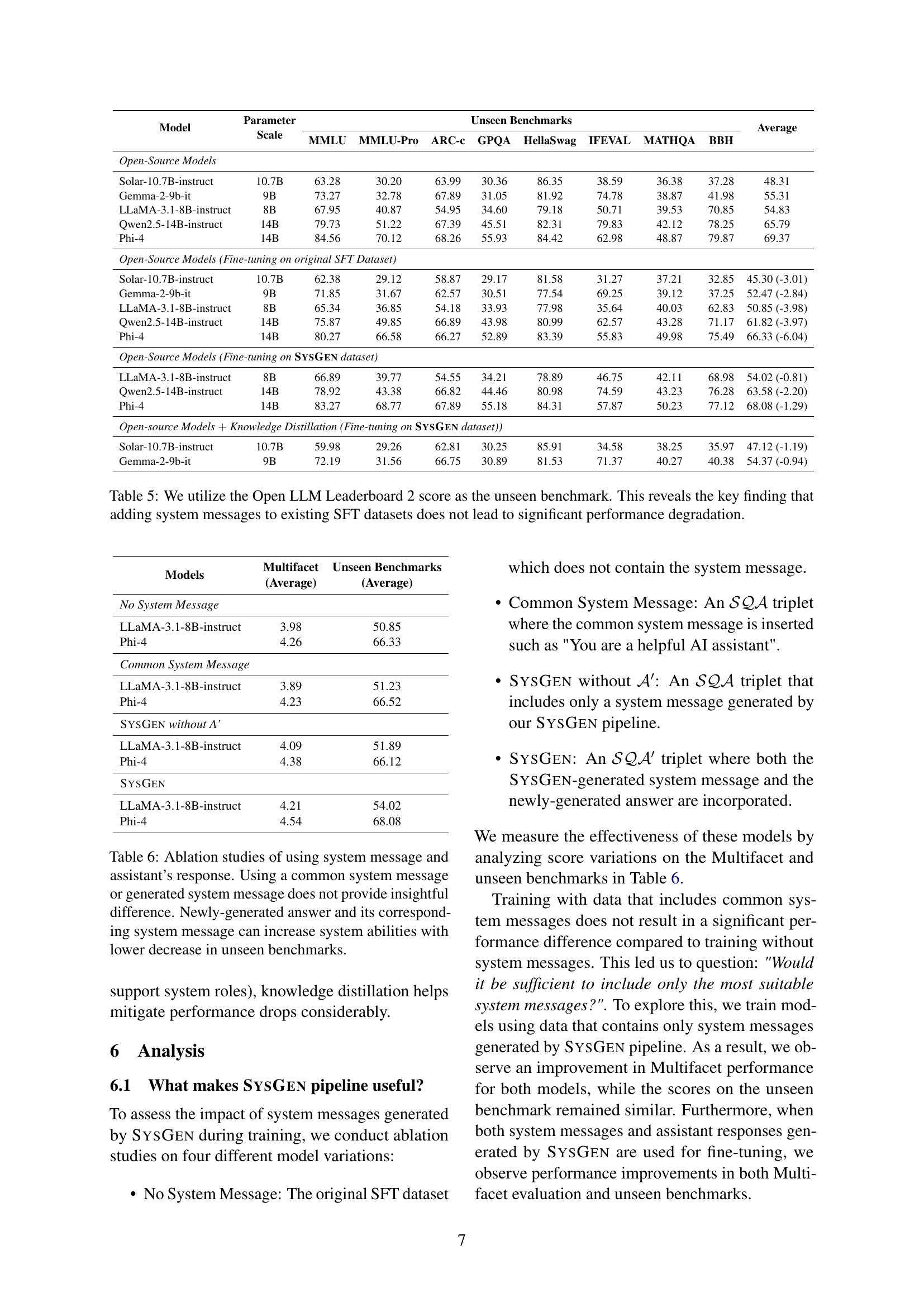
🔼 This table presents the results of the Multifacet benchmark, which assesses how well different language models align with both system messages and user instructions when generating responses. The benchmark scores range from 1 to 5, with higher scores indicating better alignment. The table includes results for both proprietary models (like GPT-3.5 and GPT-4) and open-source models (such as LLaMA, Qwen, and Phi-4). It also shows the improvement achieved by fine-tuning open-source models on data generated using the SysGen pipeline. The results marked with † were taken directly from the original Multifacet paper by Lee et al., 2024.
read the caption
Table 3: Multifacet benchmark evaluates how well a model aligns with both the system message and user instruction when generating responses. We provide baseline models (proprietary and open-source), models that trained on data generated using SysGen. A higher score is better and the maximum score is up to 5. ††\dagger† signifies the results were taken from the Multifacet (Lee et al., 2024) paper.
| Model | Parameter Scale | Multifacet | Average | ||||
| AlpacaEval | FLASK | Koala | MT-Bench | Self-Instruct | |||
| Proprietary Models | |||||||
| GPT-3.5-Turbo-0125 | ✗ | 4.05 | 3.86 | 4.15 | 3.87 | 3.85 | 3.91 |
| GPT-4-0613 | ✗ | 4.25 | 4.00 | 4.18 | 4.16 | 4.13 | 4.10 |
| GPT-4-Turbo-0125 | ✗ | 4.45 | 4.27 | 4.61 | 4.45 | 4.27 | 4.35 |
| Open-Source Models | |||||||
| LLaMA-3.1-8B-instruct | 8B | 4.26 | 3.82 | 4.29 | 4.15 | 4.06 | 4.12 |
| Qwen2.5-14B-instruct | 14B | 4.37 | 4.07 | 4.37 | 4.27 | 4.21 | 4.26 |
| Phi-4 | 14B | 4.53 | 4.24 | 4.51 | 4.39 | 4.40 | 4.41 |
| Open-Source Models (Fine-tuning on SysGen dataset) | |||||||
| LLaMA-3.1-8B-instruct | 8B | 4.38 | 3.95 | 4.41 | 4.22 | 4.11 | 4.21 |
| Qwen2.5-14B-instruct | 14B | 4.40 | 4.11 | 4.42 | 4.22 | 4.25 | 4.28 |
| Phi-4 | 14B | 4.62 | 4.63 | 4.52 | 4.44 | 4.49 | 4.54 |
🔼 This table presents the results of knowledge distillation (KD) experiments. The experiments used data generated by the SYSGEN pipeline, specifically using the Phi-4 model as the source. The table likely shows performance metrics (e.g., accuracy, F1-score) on a benchmark dataset for various open-source language models, both before and after knowledge distillation from the SYSGEN-generated data. This demonstrates the effectiveness of the SYSGEN-generated data in improving model performance, even when the models weren’t originally trained with system messages.
read the caption
Table 4: We conduct a knowledge distillation (KD) experiments leveraging data generated by SysGen pipeline using Phi-4.
| Model | Parameter Scale | Multifacet | Average | ||||
| AE | FL | Ko | MT | SI | |||
| Open-Source Models | |||||||
| Solar-10.7B-instruct | 10.7B | 3.30 | 3.31 | 3.09 | 3.19 | 3.08 | 3.19 |
| Gemma-2-9b-it | 9B | 4.10 | 3.80 | 4.26 | 4.15 | 3.92 | 4.05 |
| Open-source Models KD (Fine-tuning on SysGen dataset) | |||||||
| Solar-10.7B-instruct | 10.7B | 3.97 | 3.73 | 3.64 | 3.98 | 3.52 | 3.76 (+0.57) |
| Gemma-2-9b-it | 9B | 4.40 | 4.04 | 4.30 | 4.23 | 4.18 | 4.23 (+0.18) |
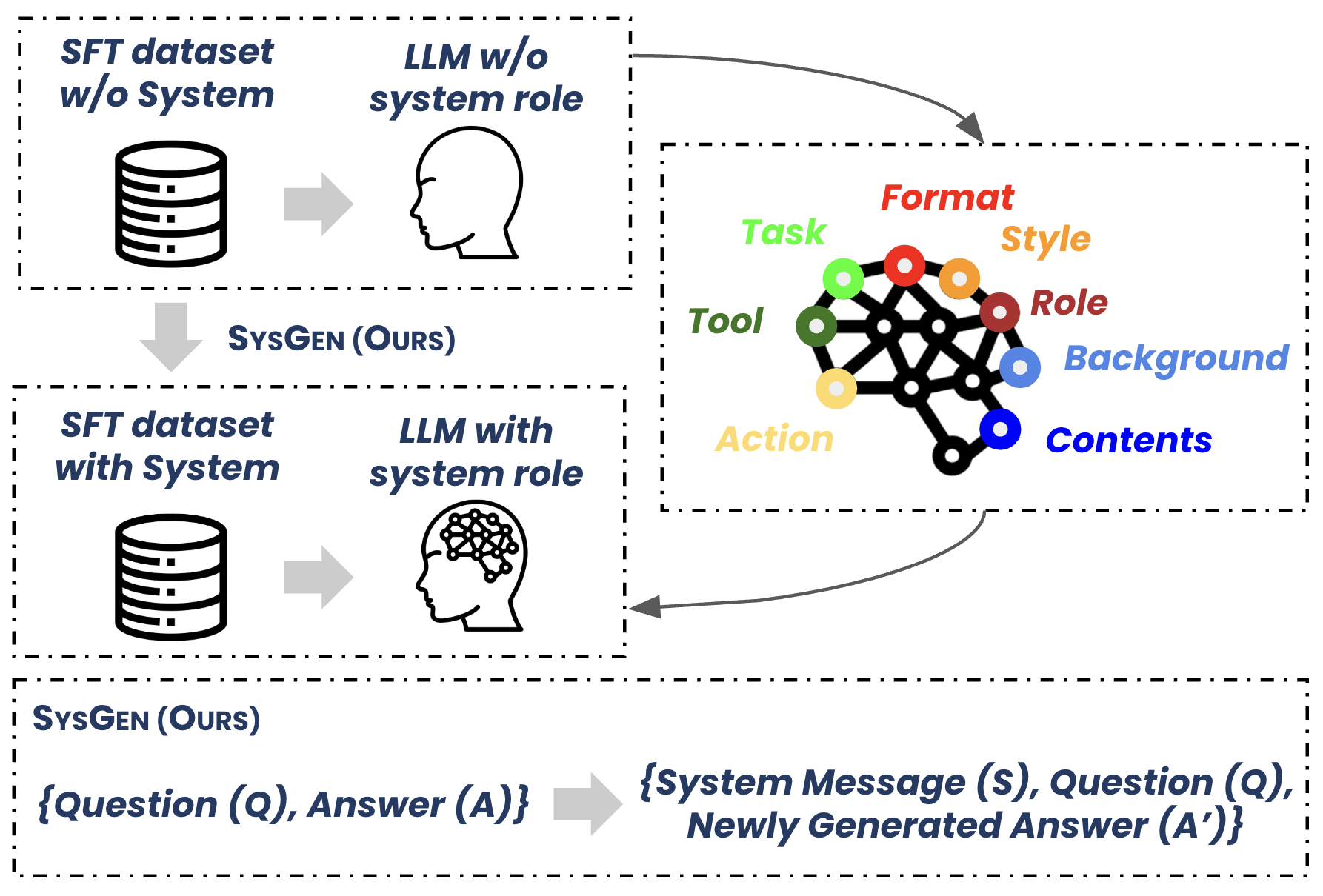
🔼 This table presents the results of evaluating the performance of various open-source language models on the Open LLM Leaderboard 2 benchmark. The models were tested under different conditions: using their original, unmodified weights; fine-tuned on standard supervised fine-tuning (SFT) datasets; fine-tuned on datasets augmented with system messages generated by the SYSGEN pipeline; and finally, models that underwent knowledge distillation using data from the SYSGEN pipeline. The key finding highlighted is that incorporating system messages into the training process does not cause a substantial decrease in the performance on unseen benchmarks, indicating that the SYSGEN pipeline successfully enhances model performance without negative side effects.
read the caption
Table 5: We utilize the Open LLM Leaderboard 2 score as the unseen benchmark. This reveals the key finding that adding system messages to existing SFT datasets does not lead to significant performance degradation.
| Model | Parameter Scale | Unseen Benchmarks | Average | |||||||
| MMLU | MMLU-Pro | ARC-c | GPQA | HellaSwag | IFEVAL | MATHQA | BBH | |||
| Open-Source Models | ||||||||||
| Solar-10.7B-instruct | 10.7B | 63.28 | 30.20 | 63.99 | 30.36 | 86.35 | 38.59 | 36.38 | 37.28 | 48.31 |
| Gemma-2-9b-it | 9B | 73.27 | 32.78 | 67.89 | 31.05 | 81.92 | 74.78 | 38.87 | 41.98 | 55.31 |
| LLaMA-3.1-8B-instruct | 8B | 67.95 | 40.87 | 54.95 | 34.60 | 79.18 | 50.71 | 39.53 | 70.85 | 54.83 |
| Qwen2.5-14B-instruct | 14B | 79.73 | 51.22 | 67.39 | 45.51 | 82.31 | 79.83 | 42.12 | 78.25 | 65.79 |
| Phi-4 | 14B | 84.56 | 70.12 | 68.26 | 55.93 | 84.42 | 62.98 | 48.87 | 79.87 | 69.37 |
| Open-Source Models (Fine-tuning on original SFT Dataset) | ||||||||||
| Solar-10.7B-instruct | 10.7B | 62.38 | 29.12 | 58.87 | 29.17 | 81.58 | 31.27 | 37.21 | 32.85 | 45.30 (-3.01) |
| Gemma-2-9b-it | 9B | 71.85 | 31.67 | 62.57 | 30.51 | 77.54 | 69.25 | 39.12 | 37.25 | 52.47 (-2.84) |
| LLaMA-3.1-8B-instruct | 8B | 65.34 | 36.85 | 54.18 | 33.93 | 77.98 | 35.64 | 40.03 | 62.83 | 50.85 (-3.98) |
| Qwen2.5-14B-instruct | 14B | 75.87 | 49.85 | 66.89 | 43.98 | 80.99 | 62.57 | 43.28 | 71.17 | 61.82 (-3.97) |
| Phi-4 | 14B | 80.27 | 66.58 | 66.27 | 52.89 | 83.39 | 55.83 | 49.98 | 75.49 | 66.33 (-6.04) |
| Open-Source Models (Fine-tuning on SysGen dataset) | ||||||||||
| LLaMA-3.1-8B-instruct | 8B | 66.89 | 39.77 | 54.55 | 34.21 | 78.89 | 46.75 | 42.11 | 68.98 | 54.02 (-0.81) |
| Qwen2.5-14B-instruct | 14B | 78.92 | 43.38 | 66.82 | 44.46 | 80.98 | 74.59 | 43.23 | 76.28 | 63.58 (-2.20) |
| Phi-4 | 14B | 83.27 | 68.77 | 67.89 | 55.18 | 84.31 | 57.87 | 50.23 | 77.12 | 68.08 (-1.29) |
| Open-source Models Knowledge Distillation (Fine-tuning on SysGen dataset)) | ||||||||||
| Solar-10.7B-instruct | 10.7B | 59.98 | 29.26 | 62.81 | 30.25 | 85.91 | 34.58 | 38.25 | 35.97 | 47.12 (-1.19) |
| Gemma-2-9b-it | 9B | 72.19 | 31.56 | 66.75 | 30.89 | 81.53 | 71.37 | 40.27 | 40.38 | 54.37 (-0.94) |
🔼 This table presents an ablation study comparing different approaches to using system messages and their impact on model performance. The study examines four conditions: (1) No system message, using the original supervised fine-tuning (SFT) dataset; (2) A common system message, where a generic prompt like ‘You are a helpful AI assistant’ is used; (3) A system message generated by the SYSGEN pipeline but without the newly generated assistant response, to isolate the impact of the system message itself; (4) The full SYSGEN approach, utilizing both the generated system message and the newly generated assistant response. The results show that simply using a generic system message doesn’t significantly improve the model, while the complete SYSGEN method yields better performance on the Multifacet benchmark and avoids substantial degradation on unseen benchmarks.
read the caption
Table 6: Ablation studies of using system message and assistant’s response. Using a common system message or generated system message does not provide insightful difference. Newly-generated answer and its corresponding system message can increase system abilities with lower decrease in unseen benchmarks.
| Models |
|
| ||||
| No System Message | ||||||
| LLaMA-3.1-8B-instruct | 3.98 | 50.85 | ||||
| Phi-4 | 4.26 | 66.33 | ||||
| Common System Message | ||||||
| LLaMA-3.1-8B-instruct | 3.89 | 51.23 | ||||
| Phi-4 | 4.23 | 66.52 | ||||
| SysGen without A’ | ||||||
| LLaMA-3.1-8B-instruct | 4.09 | 51.89 | ||||
| Phi-4 | 4.38 | 66.12 | ||||
| SysGen | ||||||
| LLaMA-3.1-8B-instruct | 4.21 | 54.02 | ||||
| Phi-4 | 4.54 | 68.08 |
🔼 This table presents the results of an experiment investigating the impact of incorporating system messages into user instructions. It shows that performance tends to decrease when system messages are included within the user’s instructions, rather than being presented separately in the designated system message field. The degree of this performance decrease is impacted by the model’s training history with system messages—models trained extensively on system messages show less of a performance decline when system messages are included in the user instruction. The table further indicates that knowledge distillation (KD) techniques were employed, highlighting this method’s role in the experiment.
read the caption
Table 7: There is a tendency for the score to decrease when the system message is reflected in the user instruction. The more a model is trained on system messages, the better it is to place them in the system role. KD indicates the knowledge distillation.
| Multifacet |
| (Average) |
🔼 This table presents the quantitative results of the system message generation phase within the SYSGEN pipeline. It details the frequency of each of eight key functionality tags (Role, Content, Task, Action, Style, Background, Tool, Format) generated by the pipeline across three different open-source language models (LLaMA-3.1-8B-instruct, Qwen2.5-14b-instruct, and Phi-4). The counts represent the number of times each tag successfully appeared in the generated system messages. This data offers insights into the effectiveness and balance of the tag generation process within the SYSGEN pipeline for each model.
read the caption
Table 8: Statistics of generated tags using SysGen pipeline.
| Unseen Benchmarks |
| (Average) |
🔼 Table 9 presents a statistical overview of several Supervised Fine-Tuning (SFT) datasets. For each dataset, it shows the average length of user queries and model responses, indicates whether system messages are present in the dataset, and lists the domains covered by the data within the dataset. This allows for a comparison of dataset characteristics and helps to understand the nature of the training data used for various large language models.
read the caption
Table 9: Data statistics of SFT datasets. We provide the average length of query and answer, the presence of system messages, and covering domains.
| Models |
| ||
| Open-source Models | |||
| Solar-10.7B-instruct | 3.19 → 2.98 | ||
| LLaMA-3.1-8B-instruct | 4.12 → 4.09 | ||
| Qwen2.5-14b-instruct | 4.26 → 4.13 | ||
| Phi-4 | 4.41 → 4.26 | ||
| Open-source Models (with SysGen) | |||
| LLaMA-3.1-8B-instruct | 4.21 → 4.13 | ||
| Qwen2.5-14B-instruct | 4.28 → 4.16 | ||
| Phi-4 | 4.54 → 4.38 | ||
| Open-source Models KD (with SysGen) | |||
| Solar-10.7b-instruct | 3.76 → 3.64 | ||
🔼 This table presents a sample of system messages and corresponding assistant responses generated using the SYSGEN pipeline. It showcases the pipeline’s ability to create diverse and contextually relevant system messages from a dataset that originally lacked them. The example shown originates from the Airoboros dataset (Jondurbin, 2024), illustrating the system messages’ impact on aligning assistant responses with user instructions.
read the caption
Table 10: Generated instance of SysGen data. The original data is originated from Airoboros (Jondurbin, 2024).
| Multifacet Average |
| (Use system role → Use user role) |
🔼 Table 11 shows the prompt used to instruct open-source large language models (LLMs) to generate system messages. The prompt provides examples of well-formed system messages, highlighting eight key functionalities (task, tool, style, action, content, background, role, format) that should be included. The instruction is to generate a system message based on a given conversational history, using the specified formatting for each functionality. The prompt is designed to guide the model in creating effective and relevant system messages by providing clear examples and instructions on how to structure the output.
read the caption
Table 11: The prompt of generating system messages using open-source models. Italic text part such as “Conversational History” is filled with input text.
| Tags | LLaMA-3.1-8B-instruct | Qwen2.5-14b-instruct | Phi-4 |
| Role | 576,341 | 753,579 | 745,751 |
| Content | 580,231 | 739,892 | 743,311 |
| Task | 579,558 | 765,331 | 735,298 |
| Action | 495,301 | 382,358 | 662,589 |
| Style | 283,579 | 598,553 | 603,918 |
| Background | 293,791 | 539,757 | 553,791 |
| Tool | 10,238 | 132,038 | 90,989 |
| Format | 327,909 | 401,593 | 538,973 |
🔼 This table presents the prompt used in Phase 3 of the SYSGEN pipeline. The prompt instructs an LLM to act as a verifier, evaluating the accuracy of tags applied to system messages. The LLM is given a ‘filtered system message’ (a cleaned-up version) and an ‘annotated system message’ (the original, tagged version). It must compare these, assessing each tag’s accuracy based on eight specified functionalities (task, tool, style, action, content, background, role, format). The LLM then provides feedback for each tag, labeling them as ‘Good’, ‘Bad’, or ‘None’ to indicate whether the tag is correct, incorrect, or missing.
read the caption
Table 12: The prompt of verification of key functionalities (phase 3) using open-source models with annotated system messages and filtered system messages. Italic text part is filled with input text.
| Dataset | # of instances | Avg. Query Length | Avg. Answer Length | Containing System Message | Covering Domains |
| Capybara | 41,301 | 300.24 | 1423.28 | ✗ | reasoning, logic, subjects, conversations, pop-culture, STEM |
| Airoboros | 59,277 | 507.26 | 1110.62 | simple system message | mathematics, MATHJSON, character’s descriptions |
| OrcaMath | 200,035 | 238.87 | 878.43 | ✗ | school mathematics, math word problems |
| Magicoder | 111,183 | 652.53 | 1552.41 | ✗ | code solution |
| MetaMath | 395,000 | 213.53 | 498.24 | ✗ | mathematics |
🔼 This table details the prompt used to assess the quality of responses generated by the system. It outlines the method for using a proprietary language model (like GPT-4) to compare an original response against a newly generated response. The user provides an instruction and two responses—one original and one new. The evaluator uses the prompt to determine which response better aligns with the given instruction.
read the caption
Table 13: The prompt of answer quality check through the proprietary model (e.g., GPT4o). Italic text part is filled with input text.
Full paper#