TL;DR#
Traditional Text-to-SQL methods struggle when relevant training examples are unavailable. Many approaches rely on retrieving similar examples, which fails in real-world situations. This creates a need for methods that can handle the lack of suitable training data, improving the robustness of Text-to-SQL systems.
To address these issues, the authors introduce SAFE-SQL. This framework generates its own examples using LLMs and then applies a structured filtering mechanism to remove noisy ones. By carefully selecting high-quality synthetic examples, SAFE-SQL enhances in-context learning, leading to significant improvements in accuracy, especially when dealing with complex and previously unseen queries. The unsupervised nature of SAFE-SQL makes it a valuable contribution, avoiding the limitations and costs associated with supervised fine-tuning.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SAFE-SQL, a novel approach to improve Text-to-SQL systems. It addresses the limitations of existing methods by generating and filtering self-augmented examples, improving accuracy and robustness, especially in complex scenarios. This work is relevant to current research trends in in-context learning and synthetic data generation for NLP tasks and opens new avenues for exploring unsupervised learning techniques in the Text-to-SQL domain.
Visual Insights#
| Method | Model | Easy | Medium | Hard | Extra | All |
|---|---|---|---|---|---|---|
| Supervised Fine-Tuning (SFT) | ||||||
| SYN-SQL | Sense 13B | 95.2 | 88.6 | 75.9 | 60.3 | 83.5 |
| SQL-Palm | PaLM2 | 93.5 | 84.8 | 62.6 | 48.2 | 77.3 |
| Zero-shot Methods | ||||||
| Baseline | GPT-4 | 84.3 | 73.1 | 65.8 | 40.3 | 69.1 |
| Baseline | GPT-4o | 87.2 | 77.2 | 68.4 | 48.7 | 73.4 |
| Baseline | GPT-4o-mini | 84.8 | 75.6 | 67.0 | 46.1 | 71.5 |
| C3q-SQL | GPT-4 | 90.2 | 82.8 | 77.3 | 64.3 | 80.6 |
| Few-shot Methods | ||||||
| DIN-SQL | GPT-4 | 91.1 | 79.8 | 64.9 | 43.4 | 74.2 |
| DAIL-SQL | GPT-4 | 90.7 | 89.7 | 75.3 | 62.0 | 83.1 |
| ACT-SQL | GPT-4 | 91.1 | 79.4 | 67.2 | 44.0 | 74.5 |
| PTD-SQL | GPT-4 | 94.8 | 88.8 | 85.1 | 64.5 | 85.7 |
| DEA-SQL | GPT-4 | 88.7 | 89.5 | 85.6 | 70.5 | 85.6 |
| Self-augmented In-Context Learning | ||||||
| SAFE-SQL | GPT-4 | 93.2 | 88.9 | 85.8 | 74.7 | 86.8 |
| SAFE-SQL | GPT-4o | 93.4 | 89.3 | 88.4 | 75.8 | 87.9 |
| SAFE-SQL | GPT-4o-mini | 93.6 | 87.5 | 86.1 | 75.2 | 87.4 |
🔼 This table presents the execution accuracy of different models on the Spider development dataset, categorized by difficulty level (Easy, Medium, Hard, Extra). The results showcase the performance of various Text-to-SQL methods, including zero-shot, few-shot, and the proposed SAFE-SQL approach. The highest accuracy for each model is highlighted in bold, with the second-highest underlined, allowing for easy comparison of model performance across different difficulty levels.
read the caption
Table 1: Execution accuracy across difficulty levels on the Spider development set. The highest score per row is in bold, and the second highest is underlined.
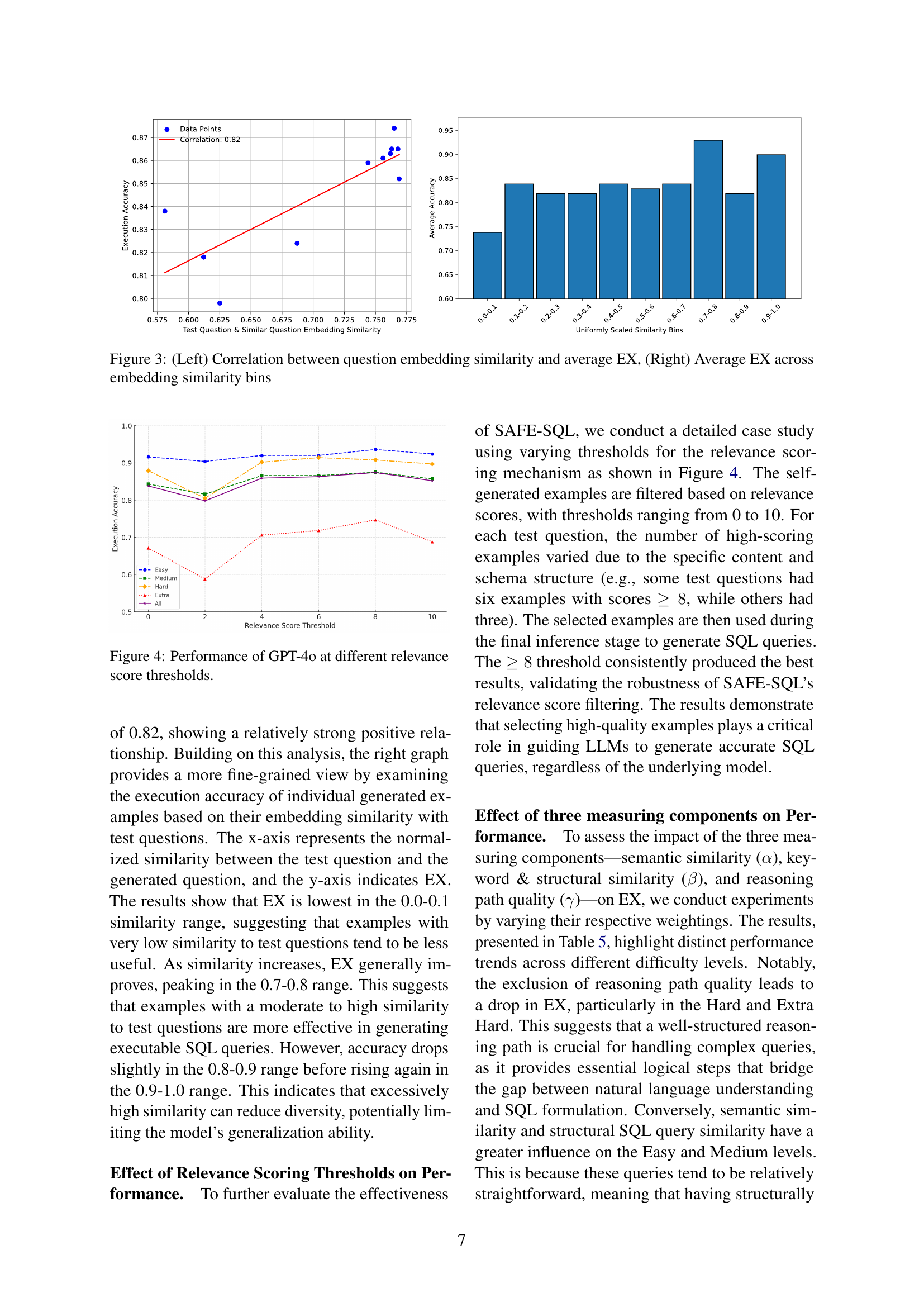
In-depth insights#
Self-Augmented Learning#
Self-augmented learning represents a paradigm shift in machine learning, moving away from reliance on solely externally provided data. It emphasizes the autonomous generation of training data by the model itself, fostering a more iterative and adaptive learning process. This approach addresses limitations of traditional methods, particularly when dealing with scarce or expensive labeled datasets. Key advantages include improved efficiency by reducing human annotation needs and enhanced generalization capabilities due to the model’s own exploration of the data space. However, challenges remain. Careful design of the data augmentation strategies is critical to avoid introducing noise and biases, which may hinder model performance. Effective filtering mechanisms are needed to select high-quality synthetic data, and careful consideration of the computational cost of generating the data is necessary. The success of self-augmented learning hinges on finding the right balance between exploration and exploitation, ensuring that the model generates informative and diverse examples without wasting resources on irrelevant ones. Therefore, future research should focus on developing more sophisticated data generation and filtering techniques, along with a deeper understanding of the theoretical properties of this approach.
Fine-grained Selection#
Fine-grained selection, in the context of a text-to-SQL system, signifies a crucial mechanism for enhancing the quality of in-context learning. It moves beyond simply retrieving similar examples, instead employing a multi-faceted assessment process to rigorously evaluate the relevance and accuracy of potential examples. This often involves evaluating semantic similarity, structural alignment between questions and SQL queries, and the logical soundness of the reasoning path employed to generate the SQL. The result is a highly curated subset of examples fed into the model, leading to more accurate and robust SQL generation. Threshold-based filtering further refines this selection, ensuring only high-quality examples contribute to the final model inference. The power of this approach lies in its ability to mitigate the impact of noisy or irrelevant examples, which is particularly important in scenarios where similar training data is scarce or unreliable. In essence, fine-grained selection is about precision over recall, prioritizing quality of examples to ensure reliable and accurate SQL generation, even in challenging real-world scenarios.
Synthetic Data#
The concept of synthetic data generation is crucial in addressing the limitations of real-world data scarcity in training effective Text-to-SQL models. SAFE-SQL leverages the power of LLMs to generate synthetic examples, addressing the challenge of unavailable similar examples in real-world scenarios where retrieval-based methods often fail. However, unfiltered self-generated data risks degrading model performance, introducing noise and inaccuracies. Therefore, SAFE-SQL incorporates a multi-stage filtering process to ensure high quality, relevant examples are used for in-context learning. This filtering, based on semantic similarity, structural alignment, and reasoning path validity, is key to mitigating the risks associated with using synthetic data. The effectiveness of this approach is evident in SAFE-SQL’s superior performance, particularly in complex and unseen scenarios, showcasing the potential of carefully curated synthetic data in enhancing Text-to-SQL model robustness.
LLM-based Inference#
LLM-based inference in the context of Text-to-SQL involves leveraging the capabilities of large language models (LLMs) to translate natural language questions into executable SQL queries. This approach offers several advantages, including the ability to handle complex and nuanced queries that traditional methods struggle with. The inherent ability of LLMs to understand context and semantics is particularly valuable for interpreting ambiguous natural language. However, directly applying LLMs to this task presents challenges. Generating high-quality, relevant examples is crucial for effective in-context learning. Relying solely on LLMs can lead to noisy or incorrect SQL queries due to the models’ susceptibility to hallucinations or flawed reasoning. Therefore, carefully designed filtering mechanisms are often necessary to curate training data and refine synthetic examples generated by the LLMs before they are used for inference. Furthermore, the performance of LLM-based inference can be highly dependent on the size and architecture of the LLM employed. Larger models generally exhibit better performance but require significantly more computational resources. The choice of LLM should also consider factors like the specific domain and dialect of SQL being targeted. Overall, while LLM-based inference holds significant promise for Text-to-SQL, effective implementation requires careful consideration of example generation, filtering, and model selection to achieve optimal accuracy and robustness.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency and scalability of the SAFE-SQL framework is crucial. The current reliance on large language models (LLMs) like GPT-40 limits applicability to resource-constrained settings. Investigating techniques for handling more complex and nuanced SQL queries involving intricate joins, subqueries, and aggregations is needed. Expanding the approach to handle diverse SQL dialects and databases would enhance its real-world applicability. Furthermore, thorough investigation into the impact of different LLMs on the framework’s performance is warranted. A comparative analysis could reveal the optimal model choice for various scenarios. Finally, a deeper exploration into the ethical implications of using LLMs for synthetic data generation is necessary. Addressing potential biases and ensuring fairness should be a primary focus.
More visual insights#
More on tables
| Models | EX | EM |
|---|---|---|
| GPT-4o + SAFE | 87.9 | 78.3 |
| w/o Reasoning path | 84.4 (-3.5) | 73.6(-4.7) |
| w/o Relevance filtering | 82.1 (-5.8) | 68.5(-9.7) |
| w/o Schema linking | 80.4 (-7.5) | 65.1(-13.2) |
| w/o Similar examples | 77.1 (-10.8) | 61.9(-16.4) |
🔼 This ablation study analyzes the impact of removing individual components from the SAFE-SQL model on its performance. By systematically removing components such as the Reasoning Path, Relevance Filtering, Schema Linking, and the use of Similar Examples, the table quantifies the contribution of each element to the overall accuracy. The results demonstrate that each component plays a crucial role in achieving the high performance of SAFE-SQL. Removing any one significantly reduces execution accuracy.
read the caption
Table 2: Ablation study results for SAFE-SQL, where removing each component leads to a performance drop.
| Score | cos | # of Generated EX | % Filtered EX |
|---|---|---|---|
| 0.581 | 10340 | 0 % | |
| 0.625 | 10185 | 1.50% (-155) | |
| 0.744 | 9883 | 4.41% (-457) | |
| 0.762 | 9378 | 9.30% (-962) | |
| 0.765 | 8606 | 16.76% (-1734) | |
| 0.769 | 6795 | 34.28% (-3545) |
🔼 This table presents a detailed analysis of the example generation and filtering process in the SAFE-SQL model. It shows the number of examples generated at different relevance score thresholds (0-10), the percentage of examples filtered out at each threshold, and the average cosine similarity between the embedding vectors of the filtered examples and the test question. Higher cosine similarity indicates a stronger semantic relationship between the generated examples and the original test question, suggesting that the filtering process effectively selects relevant and high-quality examples.
read the caption
Table 3: Summary of data generation, filtering results, and embedding similarity analysis by score.
| SQL Question | GOLD SQL Query | Augmented SQL Question | Generated Reasoning Path | Relevance Score |
|---|---|---|---|---|
| Question1: What are the names, countries, and ages for every singer in descending order of age? | SELECT name, country, age FROM singer ORDER BY age DESC | What are the names, ages, and countries of all singers from a specific country, sorted by age in descending order? | 1. Identify the desired columns: name, age, and country. | Semantic similarity = 10 Structural Similarity = 10 Reasoning path = 10 Relevance score = (10+10+10)/3 = 10 |
| Question2: Return the names and template ids for documents that contain the letter w in their description. | SELECT document_name, template_id FROM Documents WHERE Document_Description LIKE "%w%" | Retrieve the titles and category IDs of articles whose summaries contain the word "data". | 1. Identify the necessary columns: extract title and category_id from the Articles table. | Semantic similarity = 7 Structural Similarity = 9 Reasoning path = 8 Relevance score = (7+9+8)/3 = 8 |
| Question3: What is the number of car models that are produced by each maker and what is the id and full name of each maker? | SELECT Count(*), T2.FullName, T2.id FROM MODEL_LIST AS T1 JOIN CAR_MAKERS AS T2 ON T1.Maker = T2.id GROUP BY T2.id; | List all employees who work in the IT department along with their employee ID and hire date. | 1. Identify required details: employee ID and hire date. | Semantic similarity = 6 Structural Similarity = 3 Reasoning path = 2 Relevance score = (6+3+2)/3 = 3.67 |
🔼 This table showcases three examples of original SQL queries alongside their corresponding augmented versions, generated using GPT-40. Each example includes the original SQL query, the augmented (similar) SQL query, the reasoning steps detailing how the augmented query was derived from the original, and the relevance score based on semantic similarity, structural similarity, and reasoning path quality. The relevance scores offer insights into how well the augmented query aligns with the original in terms of both meaning and structure.
read the caption
Table 4: Examples of original and augmented SQL questions with reasoning paths by GPT-4o.
| Easy | Medium | Hard | Extra | EX | |||
|---|---|---|---|---|---|---|---|
| 0.33 | 0.33 | 0.33 | 93.4 | 89.3 | 88.4 | 75.8 | 87.9 |
| 1 | 0 | 0 | 90.7 | 84.2 | 82.3 | 68.3 | 82.8 |
| 0 | 1 | 0 | 89.8 | 85.6 | 81.2 | 69.2 | 83.1 |
| 0 | 0 | 1 | 89.2 | 85.1 | 84.3 | 71.7 | 83.7 |
| 0.5 | 0.5 | 0 | 91.2 | 87.3 | 82.5 | 69.4 | 84.4 |
| 0.5 | 0 | 0.5 | 92.5 | 87.9 | 83.5 | 70.3 | 85.3 |
| 0 | 0.5 | 0.5 | 92.7 | 86.8 | 88.5 | 72.4 | 86.1 |
🔼 This table presents the execution accuracy of the SAFE-SQL model across different difficulty levels of the Spider dataset. The accuracy is evaluated under varying weights assigned to three key components: semantic similarity (α), structural similarity (β), and reasoning path quality (γ). By adjusting these weights, the impact of each component on overall model performance can be analyzed for different query complexities.
read the caption
Table 5: Execution accuracy across difficulty levels under different weights: semantic similarity (α𝛼\alphaitalic_α), Structural similarity (β𝛽\betaitalic_β), and reasoning path quality (γ𝛾\gammaitalic_γ).
|
🔼 This table presents the zero-shot prompt used within the SAFE-SQL framework for generating examples. The prompt instructs a large language model (LLM) to produce ten similar questions, ten corresponding SQL queries, and ten detailed reasoning paths illustrating how each SQL query was derived. Emphasis is placed on maintaining semantic, structural, and reasoning path similarity between the generated examples and the test question. The prompt also includes placeholders for schema linking information (schema_linking[i]), table information (test_table[i]), foreign keys (test_foreign_keys[i]), and the original test question (test_question[i]).
read the caption
Table 6: The zero-shot prompt used for example generation
| You are a powerful text-to-SQL reasoner. Your task is to generate ten similar questions, ten SQL queries, and ten reasoning paths for how the SQL queries are derived. To ensure high-quality examples, focus on the following three key aspects: |
| Semantic Similarity |
| Ensure that all generated questions have the same underlying meaning as the test question. Variations in wording, synonyms, and phrasing are allowed as long as they preserve the intended query objective. Avoid introducing ambiguity or additional constraints that alter the intent. |
| Structural Similarity |
| While key terms (such as table names, column names, and numerical values) may vary, their functional roles and relationships should remain intact. |
| Reasoning Path Similarity |
| The logical reasoning required to construct the SQL query should remain consistent across examples.Clearly outline each step, including how key conditions are identified and mapped to SQL operations.Maintain coherence in how joins, aggregations, filters, and sorting operations are applied. Do not explain me about the result and just give me ten examples. |
| ## Schema linking: schema_linking[i] |
| ## Tables: test_table[i] |
| ## Foreign keys: test_foreign_keys[i] |
| ## Question: test_question[i] |
| ## Similar Question: |
| ## SQL query: |
| ## Reasoning Path: |
🔼 This table presents the zero-shot prompt utilized in the SAFE-SQL framework for filtering generated examples. The prompt instructs the language model to evaluate example questions based on semantic similarity to the test question, structural similarity (alignment of key elements and relationships), and the quality of the reasoning paths provided. It assigns scores (0-10) for each aspect, allowing for a comprehensive assessment of example relevance before including them in the final inference process.
read the caption
Table 7: The zero-shot prompt used for filtering examples.
|
🔼 This table displays the zero-shot prompt used in the final inference stage of the SAFE-SQL model. The prompt instructs the language model to generate the final SQL query based on a set of previously selected examples. These examples contain natural language questions, corresponding SQL queries, and detailed reasoning paths to guide the model in accurately constructing the final SQL query. The prompt emphasizes semantic similarity, structural similarity, and reasoning path similarity between the test question and selected examples.
read the caption
Table 8: The zero-shot prompt used for Final SQL query inference.
| You are a powerful text-to-SQL reasoner. Given a test question and a set of examples, compute the relevance score for each example based on the following criteria. Do not explain me about the answer, just give me scores. |
| Semantic Similarity of Questions |
| Compare the overall meaning of the test question and the example question. Higher scores should be assigned if the two questions have the same intent, even if they are phrased differently. Consider synonyms, paraphrasing, and minor wording variations that do not alter the fundamental meaning. Assign lower scores if the test and example questions focus on different database operations (e.g., aggregation vs. filtering) or require fundamentally different types of information.(up to 10 points). |
| 10: Almost identical meaning and intent. |
| 7–9: Minor paraphrasing but highly relevant. |
| 4–6: Some overlap but different focus. |
| 1–3: Mostly unrelated meaning. |
| 0: Completely different intent. |
| Keyword & Structural Similarity |
| Evaluate the structural alignment between the test question and the example question by analyzing how key elements (such as entities, attributes, and numerical values) are connected. Even if individual nouns, verbs, or numbers differ, the overall relational structure should be considered. Focus on whether the dependencies between key components (e.g., how entities relate to each other in the database) remain consistent.(up to 10 points). |
| 10: Nearly identical structural relationships and dependencies. |
| 7–9: Mostly similar structure, with minor differences in entity connections. |
| 4–6: Some overlap, but noticeable differences in how key components interact. |
| 1–3: Few shared structural relationships, making alignment weak. |
| 0: No meaningful structural similarities. |
| Reasoning Path Similarity |
| Evaluate whether the logical steps needed to answer the example question align with those required for the test question. Consider whether the database operations (e.g., filtering, aggregation, joins, subqueries) are similar.A high score should be given if the example follows the same logical sequence to derive the SQL query.Lower scores should be assigned if the reasoning process differs significantly, even if the questions seem similar at a surface level.(up to 10 points). |
| 10: Exact reasoning process to get right SQL query. |
| 7–9: Mostly similar but with minor differences. |
| 4–6: Some alignment but different key steps. |
| 1–3: Largely different reasoning. |
| 0: Completely unrelated logic. |
| ## Question: test_question[i] |
| ## Similar Question: similar_question[i] |
| ## Reasoning Path: reasoning_path[i] |
| ## Relevance score: |
🔼 This table presents the execution accuracy achieved by different sized models in the Qwen series across various difficulty levels of the Spider dev set. It demonstrates how model size impacts the performance of a Text-to-SQL model, showcasing the results for Easy, Medium, Hard, Extra, and overall accuracy.
read the caption
Table 9: Execution accuracy performance of different size of models of Qwen series across difficulty levels of spider dev set.
|
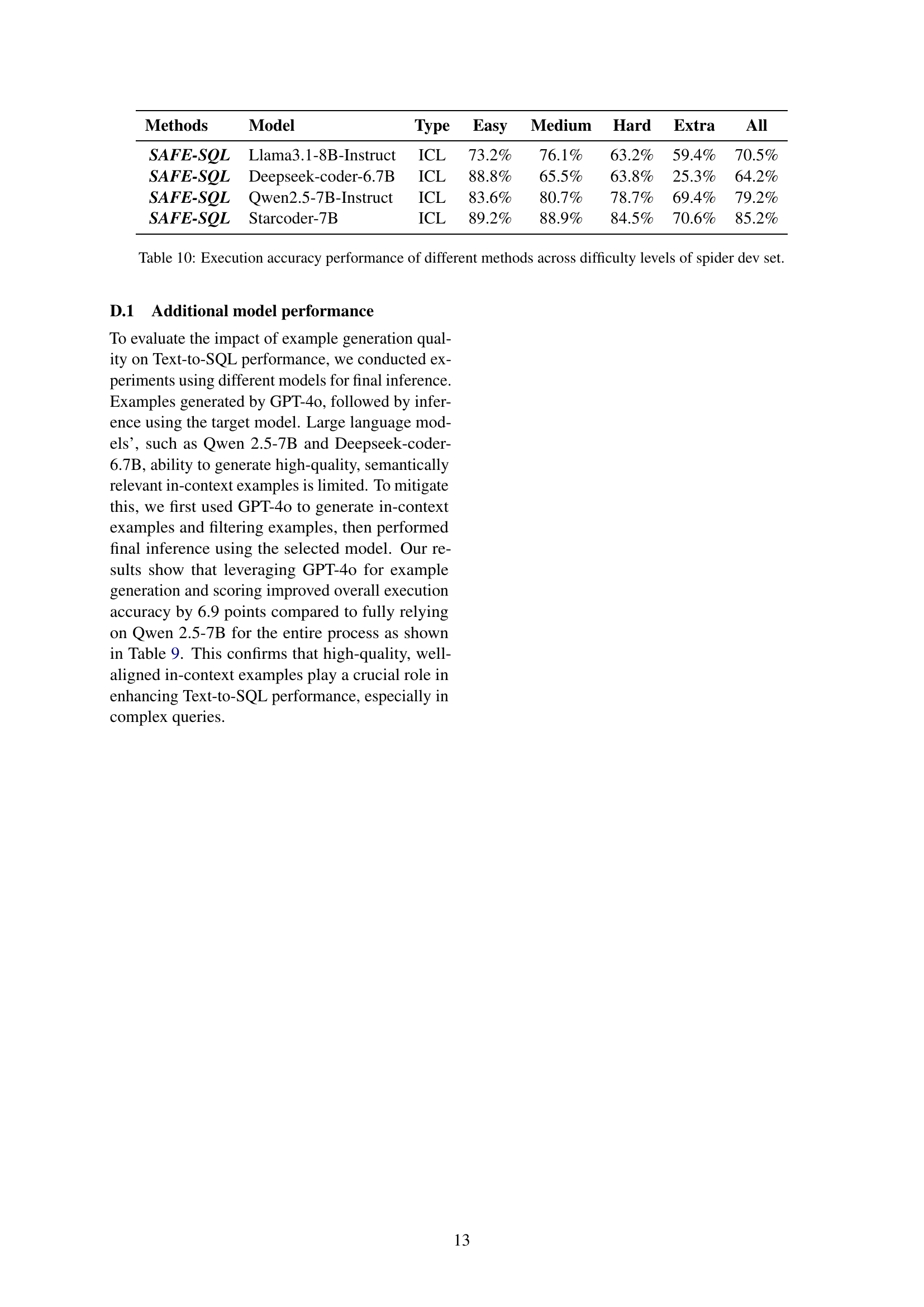
🔼 This table presents a comparison of the execution accuracy achieved by different Text-to-SQL methods across various difficulty levels in the Spider development dataset. The methods include SAFE-SQL (using four different LLMs for example generation and inference), and several baselines (Zero-shot, Few-shot and Supervised Fine-Tuning). The difficulty levels represent the complexity of the SQL queries required to answer the questions, categorized as Easy, Medium, Hard, and Extra Hard. The ‘All’ column shows the overall accuracy across all difficulty levels.
read the caption
Table 10: Execution accuracy performance of different methods across difficulty levels of spider dev set.
Full paper#