TL;DR#
Many studies assess large language models’ (LLMs) mathematical abilities solely based on the correctness of their final answers. This approach overlooks crucial details about the reasoning process. This paper addresses this gap by evaluating eight state-of-the-art LLMs on 50 newly constructed high-school level word problems. The study moves beyond simple accuracy checks, meticulously analyzing both the final answers and the solution steps to uncover reasoning failures.
The researchers found that while newer models performed better, all models demonstrated weaknesses in several areas, including spatial reasoning, strategic planning, and basic arithmetic. Common errors included unwarranted assumptions, over-reliance on numerical patterns, and an inability to translate physical intuition into mathematical steps. The findings underscore the importance of evaluating the entire reasoning process and highlight the need for targeted improvements in LLMs’ structured reasoning and constraint handling capabilities. The study’s findings caution against overestimating LLMs’ problem-solving proficiency and emphasize the need for more sophisticated evaluation methods.
Key Takeaways#
Why does it matter?#
This paper is crucial as it reveals significant shortcomings in LLMs’ mathematical reasoning abilities, prompting researchers to focus on improving structured reasoning and constraint handling in future model development. It challenges the overestimation of LLMs’ problem-solving capabilities and emphasizes the need for more rigorous evaluation methods.
Visual Insights#
| Model | Correct | Ans | Sol |
|---|---|---|---|
| mixtral-8x7B | 0 | 4 | 0 |
| llama-3.3-70B | 10 | 1 | 0 |
| gemini-2.0-pro-exp | 23 | 3 | 1 |
| gpt-4o | 14 | 3 | 2 |
| o1-preview | 30 | 2 | 2 |
| o1 | 37 | 2 | 1 |
| o3-mini | 40 | 2 | 0 |
| deepseek-r1 | 36 | 4 | 0 |
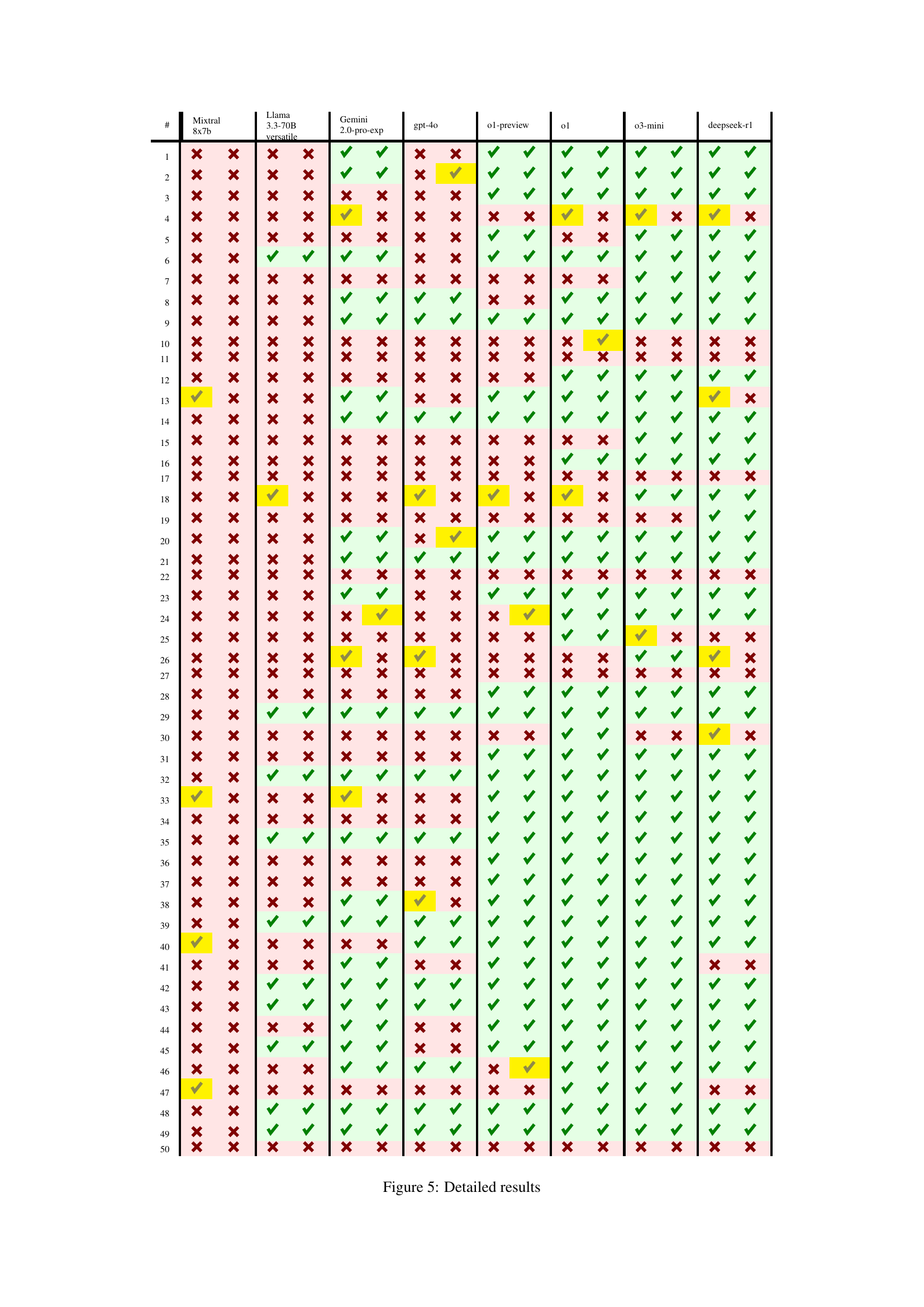
🔼 This table presents the performance of eight different large language models (LLMs) on a set of 50 newly created high-school level mathematical word problems. The table shows the number of problems each LLM solved correctly, along with breakdowns for two categories of errors: ‘Ans’ (correct answer, incorrect solution) and ‘Sol’ (incorrect answer, correct solution steps). This allows for a more nuanced evaluation than simply focusing on whether the final answer was correct, offering insight into the models’ reasoning processes.
read the caption
Table 1: The number of problems correctly solved and answered (out of 50). Ans = correct answer but wrong solution. Sol = correct solution but wrong final answer.
Full paper#